Worum es in diesem Vergleich wirklich geht
Die meisten „BI vs Foundry“-Debatten bleiben bei Features stecken: welches Tool hat bessere Charts, schnellere Abfragen oder hübschere Dashboards. Das ist selten das entscheidende Kriterium. Der eigentliche Vergleich richtet sich danach, was Sie erreichen wollen.
Ein Dashboard kann zeigen, was passiert ist (oder gerade passiert). Ein operationales Entscheidungssystem ist dagegen darauf ausgelegt, Menschen dabei zu unterstützen, zu entscheiden, was als Nächstes zu tun ist — und diese Entscheidung wiederholbar, prüfbar und an die Ausführung angebunden zu machen.
Erkenntnis ist nicht gleich Aktion. Zu wissen, dass der Lagerbestand niedrig ist, ist etwas anderes als eine Nachbestellung auszulösen, die Lieferung umzuleiten, einen Plan zu aktualisieren und nachzuverfolgen, ob die Entscheidung Wirkung gezeigt hat.
Was Sie in diesem Leitfaden lernen
Dieser Artikel zerlegt:
- die funktionalen Unterschiede zwischen traditioneller Business Intelligence und operationalen Entscheidungssystemen
- die Trade‑offs: Geschwindigkeit der Einführung vs Tiefe der Integration, Flexibilität vs Standardisierung, Exploration vs Ausführung
- praktische Auswahlkriterien, damit Sie nach Ihrem Betriebsmodell entscheiden — nicht nach Marketing‑Sprache
Umfang (größer als ein einzelner Anbieter)
Obwohl Palantir Foundry ein nützlicher Referenzpunkt ist, gelten die Konzepte allgemein. Jede Plattform, die Daten, Entscheidungslogik und Workflows verbindet, verhält sich anders als Tools, die primär für Dashboards und Reporting gedacht sind.
Für wen das gedacht ist
Wenn Sie Operations, Analytics oder eine Geschäftsfunktion führen, in der Entscheidungen unter Zeitdruck getroffen werden (Supply Chain, Fertigung, Customer Ops, Risiko, Field Service), hilft Ihnen dieser Vergleich, Tools an der tatsächlichen Arbeitsweise auszurichten — und zu identifizieren, wo heute Entscheidungen scheitern.
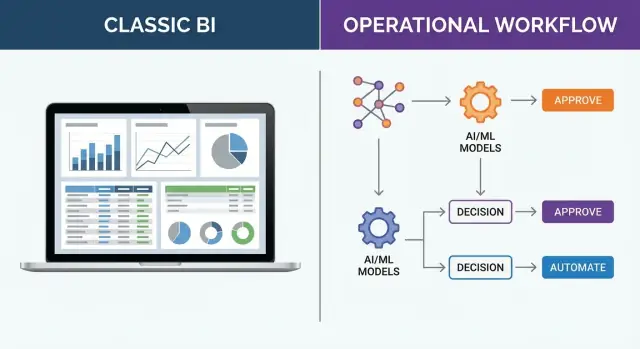
Traditionelle Business Intelligence (BI) ist darauf ausgelegt, Organisationen zu helfen, zu sehen, was passiert — durch Dashboards und Reporting. Sie sind exzellent darin, Daten in gemeinsame Metriken, Trends und Zusammenfassungen zu überführen, die Führungskräfte und Teams zur Leistungsüberwachung nutzen können.
Dashboards: Monitoring und Leistungsübersicht
Dashboards sind für schnelles Situationsbewusstsein konzipiert: Sind die Umsätze gestiegen oder gefallen? Sind Service‑Levels im Zielbereich? Welche Regionen performen schwach?
Gute Dashboards machen Schlüsselkennzahlen leicht erfassbar, vergleichbar und drill‑fähig. Sie geben Teams eine gemeinsame Sprache („das ist die Zahl, der wir vertrauen“) und helfen, Veränderungen früh zu erkennen — besonders in Kombination mit Alerts oder geplanten Aktualisierungen.
Reporting: standardisierte Metriken und periodische Zusammenfassungen
Reporting fokussiert auf Konsistenz und Wiederholbarkeit: Monatsabschlussberichte, wöchentliche Operations‑Packs, Compliance‑Zusammenfassungen und Executive‑Scorecards.
Ziel sind stabile Definitionen und vorhersehbare Lieferung: dieselben KPIs, auf dieselbe Weise berechnet, nach einem Rhythmus verteilt. Hier sind Konzepte wie semantische Ebenen und zertifizierte Metriken wichtig — damit alle Ergebnisse gleich interpretieren.
Ad‑hoc‑Analyse: Exploration und neue Fragen beantworten
BI‑Tools unterstützen auch Exploration, wenn neue Fragen auftauchen: Warum ist die Conversion letzte Woche gesunken? Welche Produkte treiben Retouren? Was hat sich nach der Preisänderung verändert?
Analysten können nach Segmenten schneiden, filtern, neue Views bauen und Hypothesen testen, ohne auf Engineering‑Aufwand warten zu müssen. Dieser niedrigschwellige Zugang zu Insights ist ein Hauptgrund, warum traditionelle BI unverzichtbar bleibt.
Wo BI am stärksten ist (und oft endet)
BI glänzt, wenn das Ergebnis Verständnis ist: schnelle Dashboard‑Auslieferung, vertraute UX und breite Adoption bei Business‑Usern.
Die übliche Grenze ist das, was danach passiert. Ein Dashboard kann ein Problem hervorheben, führt aber meist nicht die Reaktion aus: Aufgaben zuweisen, Entscheidungslogik durchsetzen, operative Systeme aktualisieren oder nachverfolgen, ob die Maßnahme umgesetzt wurde.
Diese „und jetzt?“‑Lücke ist ein zentraler Grund, warum Teams über Dashboards und Reporting hinausblicken, wenn sie echtes „analytics to action“ und Entscheidungsworkflows benötigen.
Was ein operationales Entscheidungssystem bedeutet
Ein operationales Entscheidungssystem ist für die Entscheidungen gebaut, die ein Unternehmen während der Arbeit trifft — nicht danach. Diese Entscheidungen sind häufig, zeitkritisch und wiederholbar: „Was sollen wir als Nächstes tun?“ statt „Was ist letzten Monat passiert?“
Traditionelle BI ist hervorragend für Dashboards und Reporting. Ein operationales Entscheidungssystem geht weiter, indem es Daten + Logik + Workflow + Verantwortlichkeit verpackt, sodass Analytics zuverlässig in Aktionen innerhalb eines realen Geschäftsprozesses übergehen.
Welche Arten von Entscheidungen es unterstützt
Operative Entscheidungen teilen typischerweise einige Merkmale:
- Sie passieren viele Male am Tag (oder pro Stunde)
- Die „richtige“ Antwort hängt von den aktuellsten Daten ab
- Konsistenz ist wichtig: zwei Teams sollten bei ähnlichen Fakten zu ähnlichen Entscheidungen kommen
- Es besteht Bedarf, warum eine Entscheidung getroffen wurde, zu erklären und zu prüfen
Wie das Ergebnis aussieht (es ist kein Diagramm)
Statt eines Dashboard‑Tiles produziert das System handlungsfähige Outputs, die in die Arbeit passen:
- empfohlene Aktionen (mit Begründung)
- Ausnahmen, die Aufmerksamkeit benötigen
- Genehmigungsschritte und Sign‑offs
- Aufgaben‑Queues und Zuweisungen
Beispielsweise könnte statt Inventartrends ein operationales Entscheidungssystem Nachbestellungsvorschläge mit Schwellen, Lieferantenbeschränkungen und einem menschlichen Genehmigungsschritt erzeugen. Statt eines Customer‑Service‑Dashboards könnte es Fallpriorisierung mit Regeln, Risikobewertung und Audit‑Trail erzeugen. In der Feld‑Operation könnte es Schicht‑ oder Tourenänderungen vorschlagen, basierend auf Kapazität und neuen Einschränkungen.
Wie Erfolg gemessen wird
Erfolg ist nicht „mehr Reports wurden angesehen“. Er ist in verbesserten Ergebnissen des Geschäftsprozesses zu messen: weniger Stockouts, schnellere Lösungszeiten, geringere Kosten, höhere SLA‑Einhaltung und klarere Verantwortlichkeit.
Von Insight zu Aktion: Open Loop vs Closed Loop
Der wichtigste Unterschied in Palantir Foundry vs BI ist nicht der Chart‑Typ oder das Dashboard‑Polish. Es ist die Frage, ob das System bei Insight stehenbleibt (open loop) oder durch Ausführung und Lernen fortfährt (closed loop).
Open Loop: BI verwandelt Daten in Ansichten
Traditionelle BI ist für Dashboards und Reporting optimiert. Ein typischer Ablauf sieht so aus:
- BI‑Flow: ingest → model → visualize → human interprets
Der letzte Schritt ist entscheidend: die „Entscheidung“ findet im Kopf einer Person, in einem Meeting oder in E‑Mail‑Threads statt. Das funktioniert gut für explorative Analysen, Quartalsreviews und Fragen, bei denen die nächste Aktion unklar ist.
Verzögerungen treten in BI‑Only‑Ansätzen meist zwischen „Ich sehe das Problem“ und „wir haben etwas unternommen“ auf:
- die richtige Person schaut nicht aufs Dashboard
- Metrikdefinitionen werden diskutiert (Mismatch in der semantischen Ebene)
- Aktionen erfordern Koordination über Teams und Tools
- es gibt keine konsistente Methode, zu bestätigen, ob die Aktion gewirkt hat
Closed Loop: Entscheidungssysteme produktivieren Aktion
Ein operationales Entscheidungssystem erweitert die Pipeline jenseits von Insight:
- Decision System Flow: ingest → model → decide → execute → learn
Der Unterschied ist, dass „decide“ und „execute“ Teil des Produkts sind, nicht ein manueller Handover. Wenn Entscheidungen wiederholbar sind (approve/deny, priorisieren, zuweisen, routen, planen), reduziert das Kodifizieren dieser Entscheidungen als Workflows plus Entscheidungslogik Latenz und Inkonsistenzen.
Warum Closed‑Loop‑Feedback Ergebnisse verändert
Closed Loop bedeutet, dass jede Entscheidung rückverfolgbar ist auf Inputs, Logik und Outcomes. Sie können messen: Was haben wir gewählt? Was ist danach passiert? Sollte sich die Regel, das Modell oder der Schwellenwert ändern?
Im Laufe der Zeit entsteht so kontinuierliche Verbesserung: das System lernt aus echten Operationen, nicht nur daraus, was Menschen später im Meeting erinnern. Das ist die praktische Brücke von Analytics zu Action.
Wie sich die Architekturen typischerweise unterscheiden
Ein traditionelles BI‑Setup ist meistens eine Kette von Komponenten, jede optimiert für einen bestimmten Schritt: ein Warehouse oder Lake zur Speicherung, ETL/ELT‑Pipelines zur Bewegung und Formung von Daten, eine semantische Ebene zur Standardisierung von Metriken und Dashboards/Reports zur Visualisierung.
Das funktioniert gut, wenn das Ziel konsistentes Reporting und Analyse ist, aber die „Aktion“ passiert oft außerhalb des Systems — per Meeting, E‑Mail und manuellen Übergaben.
Ein Foundry‑ähnlicher Ansatz sieht eher wie eine Plattform aus, in der Daten, Transformationslogik und operative Oberflächen enger zusammenleben. Statt Analytics als Schlusspunkt der Pipeline zu behandeln, sieht er Analytics als einen Bestandteil eines Workflows, der eine Entscheidung erzeugt, eine Aufgabe auslöst oder ein operatives System aktualisiert.
Datenprodukte vs One‑off‑Datasets
In vielen BI‑Umgebungen erstellen Teams Datasets für ein spezifisches Dashboard oder eine Frage („Umsatz nach Region für Q3“). Mit der Zeit entstehen viele ähnliche Tabellen, die auseinanderdriften.
Mit einer „Datenprodukt“-Mentalität ist das Ziel ein wiederverwendbares, klar definiertes Asset (Inputs, Owner, Refresh‑Verhalten, Qualitätschecks und erwartete Konsumenten). Das erleichtert den Aufbau mehrerer Anwendungen und Workflows auf denselben vertrauenswürdigen Bausteinen.
Wo Compute stattfindet (und warum das wichtig ist)
Traditionelle BI setzt oft auf Batch‑Updates: nächtliche Loads, geplante Modell‑Refreshes und periodisches Reporting. Operative Entscheidungen benötigen häufig frischere Daten — manchmal nahezu in Echtzeit — weil verspätetes Handeln teuer ist (verpasste Lieferungen, Stockouts, verzögerte Interventionen).
Schnittstellen jenseits von Charts
Dashboards sind großartig zur Überwachung, aber operative Systeme brauchen oft Oberflächen, die Arbeit erfassen und routen: Formulare, Aufgaben‑Queues, Genehmigungen und leichtgewichtige Apps. Das ist der architektonische Wechsel von „Zahlen sehen“ zu „Schritt abschließen“.
Höhere Anforderungen an Datenintegration für den operativen Einsatz
Die Lücke zwischen Erkenntnis und Handlung schließen
Nutzen Sie Koder.ai, um die UX für Aktionen zu validieren, nicht nur für Berichte.
Dashboards tolerieren manchmal „mehr oder weniger richtige“ Daten: wenn zwei Teams Kunden unterschiedlich zählen, kann man trotzdem ein Chart erstellen und die Abweichung im Meeting erklären. Operative Entscheidungssysteme haben diesen Luxus nicht.
Wenn eine Entscheidung Arbeit auslöst — eine Lieferung genehmigen, eine Wartung priorisieren, eine Zahlung blocken — müssen Definitionen zwischen Teams und Systemen konsistent sein, sonst wird Automatisierung schnell unsicher.
Konsistente Definitionen über Teams hinweg
Operative Entscheidungen hängen von gemeinsamen Semantiken ab: was ist ein „aktiver Kunde“, eine „erfüllte Bestellung“ oder eine „verspätete Lieferung“? Ohne konsistente Definitionen wird ein Workflow‑Schritt denselben Datensatz anders interpretieren als der nächste.
Hier sind semantische Ebenen und gut verwaltete Datenprodukte wichtiger als perfekte Visualisierungen.
Entity‑Resolution und Referenz‑Ausrichtung
Automatisierung bricht zusammen, wenn das System nicht zuverlässig beantworten kann: „Ist das derselbe Lieferant?“ Operative Setups erfordern normalerweise:
- Entity Resolution (Abgleich von Datensätzen über Quellen hinweg)
- Master Data (autoritative IDs und Attribute)
- Referenzdaten‑Ausrichtung (Währungen, Standorte, Statuscodes, Kalender)
Fehlen diese Grundlagen, wird jede Integration zu einer Einmal‑Zuordnung, die scheitert, sobald sich ein Quellsystem ändert.
Datenqualitätsprobleme, die Automatisierung brechen
Multi‑Source‑Datenqualität ist häufig — doppelte IDs, fehlende Zeitstempel, inkonsistente Einheiten. Ein Dashboard kann filtern oder annotieren; ein operativer Workflow braucht explizite Behandlung: Validierungsregeln, Fallbacks und Exception‑Queues, damit Menschen intervenieren können, ohne den ganzen Prozess zu stoppen.
Modelle für Entscheidungen, nicht nur Reporting
Operative Modelle benötigen Entitäten, Zustände, Constraints und Regeln (z. B. „order → packed → shipped“, Kapazitätsgrenzen, Compliance‑Beschränkungen).
Pipelines um diese Konzepte herum zu entwerfen — mit der Erwartung von Änderungen — hilft, brittle Integrationen zu vermeiden, die bei neuen Produkten, Regionen oder Richtlinien zusammenbrechen.
Governance, Sicherheit und Audit‑Trails
Wenn Sie vom „Insights‑Anzeigen“ zum „Aktionen‑Auslösen“ übergehen, wird Governance nicht mehr nur zur Compliance‑Aufgabe, sondern zum operativen Sicherheitsmechanismus.
Automatisierung kann die Auswirkung eines Fehlers vervielfachen: ein einziger falscher Join, eine veraltete Tabelle oder eine zu breite Berechtigung kann Hunderte Entscheidungen in Minuten beeinflussen.
Warum Automatisierung die Messlatte höher legt
Bei traditioneller BI führt falsche Daten oft zu einer falschen Interpretation. In einem operationalen System führen falsche Daten zu einem falschen Ergebnis — Lagerbestand umverteilt, Bestellungen umgeleitet, Kunden abgewiesen, Preise geändert.
Deshalb muss Governance direkt im Pfad von Daten → Entscheidung → Aktion sitzen.
Rollenbasierte Zugriffe: wer sehen darf vs wer handeln darf
Dashboards konzentrieren sich meist auf „wer darf was sehen“. Operative Systeme brauchen feinere Trennung:
- Ansichtsrechte (Daten, Metriken und Erklärungen inspizieren)
- Aktionsrechte (genehmigen, ausführen oder nachgelagerte Systeme triggern)
- Kontextuelle Einschränkungen (nur auf eine Region, Produktlinie oder Kundentier handeln)
Das reduziert das Risiko, dass „Leserechte“ unbeabsichtigt zu Schreib‑Impact werden, besonders wenn Workflows mit Ticketing, ERP oder Order‑Management integriert sind.
Lineage und Auditierbarkeit
Gute Lineage ist nicht nur Datenherkunft — sie ist Entscheidungsprovenienz. Teams sollten eine Empfehlung oder Aktion zurückverfolgen können bis zu:
- Transformationsschritten
- den verwendeten Eingaben und deren Versionen
- der angewendeten Entscheidungslogik
- den originären Quellsystemen
Ebenso wichtig ist Auditierbarkeit: zu protokollieren, warum eine Empfehlung gemacht wurde (Inputs, Schwellen, Modell‑Version, Regel‑Hits), nicht nur was empfohlen wurde.
Trennung der Aufgaben und Exception‑Handling
Operative Entscheidungen erfordern oft Genehmigungen, Overrides und kontrollierte Ausnahmen. Trennung der Aufgaben — Ersteller vs Genehmiger, Empfehlender vs Ausführender — verhindert stille Fehler und schafft eine prüfbare Spur, wenn das System an Randfällen scheitert.
Entscheidungslogik: Regeln, Optimierung und ML im Kontext
Späteren Lock-in vermeiden
Behalten Sie die Kontrolle mit Source-Code-Export, wenn Sie Implementation verschieben oder prüfen müssen.
Dashboards beantworten „was ist passiert?“ Entscheidungslogik beantwortet „was sollten wir als Nächstes tun, und warum?“ In operativen Settings muss diese Logik explizit, testbar und sicher veränderbar sein — weil sie Genehmigungen, Umleitungen, Holds oder Outreach auslösen kann.
Regelbasierte Logik: klare Policies, konsistente Ergebnisse
Regelbasierte Entscheidungen funktionieren gut, wenn die Policy einfach ist: „Wenn Bestand < X, Nachbeschleunigen“ oder „Wenn einem Fall Dokumente fehlen, vor der Prüfung nachfordern.“
Vorteil ist Vorhersagbarkeit und Prüfbarkeit. Risiko ist Bruchbarkeit: Regeln können sich widersprechen oder mit der Zeit veralten.
Optimierung: Trade‑offs unter Constraints
Viele reale Entscheidungen sind keine Binärfragen — es sind Allokationsprobleme. Optimierung hilft, wenn begrenzte Ressourcen (Technikerstunden, Fahrzeuge, Budget) und konkurrierende Ziele (Geschwindigkeit vs Kosten vs Fairness) vorliegen.
Statt eines einzelnen Schwellenwerts definieren Sie Constraints und Prioritäten und generieren dann den „bestmöglichen“ Plan. Wichtig ist, dass die Constraints für Business‑Owner lesbar sind, nicht nur für Modellierer.
ML‑Scoring: Priorisierung mit menschlicher Überprüfung
Machine Learning passt oft als Scoring‑Schritt: Leads ranken, Risiko markieren, Verzögerungen vorhersagen. In operativen Workflows sollte ML typischerweise empfehlen, nicht heimlich entscheiden — besonders wenn Ergebnisse Kunden oder Compliance betreffen.
Erklärbarkeit: Vertrauen schaffen und Compliance erfüllen
Menschen müssen die treibenden Faktoren einer Empfehlung sehen: verwendete Inputs, Reason‑Codes und was die Entscheidung verändern würde. Das schafft Vertrauen und unterstützt Audits.
Drift überwachen und sicher updaten
Operative Logik muss überwacht werden: Input‑Daten verschieben sich, Performance ändert sich, unbeabsichtigte Verzerrungen treten auf.
Nutzen Sie kontrollierte Releases (z. B. Shadow‑Mode, limitierte Rollouts) und Versionierung, damit Sie Ergebnisse vergleichen und bei Bedarf schnell zurückrollen können.
User Experience: Dashboards vs Workflows
Traditionelle BI ist für Ansehen optimiert: ein Dashboard, ein Report, ein Slice‑and‑Dice‑View, der hilft zu verstehen, was passiert ist und warum.
Operative Entscheidungssysteme sind für Tun optimiert. Die Hauptnutzer sind Planer, Dispatcher, Case‑Worker und Supervisoren — Menschen, die viele kleine, zeitkritische Entscheidungen treffen, bei denen der „nächste Schritt“ kein Meeting oder ein Ticket in einem anderen Tool sein darf.
Dashboards: gut für Awareness, schwach in der Ausführung
Dashboards sind großartig für breite Sichtbarkeit und Storytelling, erzeugen aber oft Reibung, wenn es Zeit zur Aktion ist:
- Sie sehen eine KPI ist abweichend
- Sie kopieren IDs in ein anderes System
- Sie gleichen Kontext über Tabs hinweg ab
- Sie dokumentieren die Entscheidung anderswo
Dieser Kontextwechsel erzeugt Verzögerungen, Fehler und inkonsistente Entscheidungen.
Workflows: handeln, wo Sie das Problem sehen
Operative UX nutzt Muster, die den Nutzer von Signal zu Lösung führen:
- Alerts, die auslösen, wenn Schwellen, Anomalien oder SLA‑Risiken auftreten
- Exception Queues, die die wenigen Items priorisieren, die jetzt Aufmerksamkeit brauchen
- Geführte Workflows, die Pflichtfelder, empfohlene Aktionen und Einschränkungen (Policy, Kapazität, Eligibility) anzeigen
Statt „hier ist das Chart“ beantwortet die Oberfläche: Welche Entscheidung ist nötig, welche Informationen sind relevant und welche Aktion kann ich direkt hier ausführen?
In Plattformen wie Palantir Foundry bedeutet das häufig, Entscheidungsschritte direkt in derselben Umgebung einzubetten, die die zugrundeliegenden Daten und Logik zusammenstellt.
Adoption messen: jenseits von Page‑Views
BI‑Erfolg wird oft an Report‑Nutzung gemessen. Operative Systeme sollten wie Produktionstools bewertet werden:
- Abschlussraten (wie viele Fälle/Items werden gelöst)
- Time‑to‑Decision (von Alert bis Aktion)
- Override‑Raten (wie oft Nutzer Empfehlungen umgehen und warum)
Diese Metriken zeigen, ob das System wirklich Ergebnisse verändert — nicht nur Insights generiert.
Use‑Cases, in denen operative Entscheidungssysteme glänzen
Operative Entscheidungssysteme zahlen sich aus, wenn das Ziel nicht „wissen, was passiert ist“ ist, sondern „entscheiden, was als Nächstes zu tun ist“ — und das konsistent, schnell und nachvollziehbar.
Supply Chain: Inventar, Allokation und Fulfillment
Dashboards können Stockouts oder verspätete Lieferungen hervorheben; ein operatives System hilft bei der Lösung.
Es kann Umlagerungsempfehlungen zwischen DCs geben, Bestellungen nach SLA und Marge priorisieren und Nachbestellungen auslösen — und dabei dokumentieren, warum eine Entscheidung getroffen wurde (Constraints, Kosten, Ausnahmen).
Fertigung: Qualität, Wartung und Durchsatz
Bei Qualitätsproblemen brauchen Teams mehr als Defekt‑Rate‑Charts. Ein Entscheidungsworkflow kann Vorfälle routen, Containment‑Maßnahmen vorschlagen, betroffene Chargen identifizieren und Linienwechsel koordinieren.
Für Wartungsplanung kann er Risiko, Technikerverfügbarkeit und Produktionsziele abwägen und dann den freigegebenen Plan in tägliche Arbeitsanweisungen pushen.
Gesundheitswesen und Versicherung: Case‑Triage und Kapazitätsplanung
In klinischen Operationen und Schadenbearbeitung ist Priorisierung oft der Engpass. Operative Systeme können Fälle mittels Policies und Signalen (Schweregrad, Wartezeit, fehlende Dokumente) triagieren, sie in die richtige Queue zuweisen und Kapazitäts‑What‑Ifs unterstützen — ohne Nachvollziehbarkeit zu verlieren.
Energie und Versorger: Störungsbehebung und Field‑Operations
Während Ausfällen müssen Entscheidungen schnell und koordiniert getroffen werden. Ein operatives System kann SCADA/Telemetry, Wetter, Crew‑Positionen und Asset‑Historie zusammenführen, um Dispositionspläne, Wiederherstellungssequenzen und Kundenkommunikation zu empfehlen — und die Ausführung zu verfolgen, während sich Bedingungen ändern.
Back Office: Fraud‑Review, Kreditentscheidungen und Support‑Routing
Fraud‑ und Kreditteams arbeiten in Workflows: prüfen, Informationen anfordern, genehmigen/ablehnen, eskalieren. Operative Systeme können diese Schritte standardisieren, konsistente Entscheidungslogik anwenden und Items an die richtigen Prüfer routen.
Im Kundensupport können sie Tickets nach Intent, Kundenwert und benötigten Skills steuern — und damit Ergebnisse verbessern, nicht nur darüber berichten.
Implementierungsansatz, der Risiko reduziert
Erste Version generieren
Beschreiben Sie den Ablauf im Chat und erhalten Sie ein React-UI mit einem Go-Backend-Gerüst.
Operative Entscheidungssysteme scheitern seltener, wenn man sie wie ein Produkt implementiert, nicht wie ein reines Datenprojekt. Ziel ist, eine Entscheidungs‑Schleife End‑to‑End zu beweisen — Daten rein, Entscheidung getroffen, Aktion ausgeführt und Outcomes gemessen — bevor man skaliert.
Mit einer einzelnen, verantworteten Entscheidung starten
Wählen Sie eine Entscheidung mit klarem Business‑Wert und einem echten Owner. Dokumentieren Sie die Grundlagen:
- Inputs: welche Daten, aus welchen Quellen, wie frisch
- Owner: wer für die Entscheidung und Eskalation verantwortlich ist
- Frequenz: stündlich, täglich, wöchentlich
- SLA: wie schnell die Entscheidung getroffen und umgesetzt werden muss
Das hält den Scope eng und macht Erfolg messbar.
„Done“ definieren als veränderte Aktion
Insights sind nicht das Ende. Definieren Sie „done“ dadurch, welche Aktion geändert wird und wo sie geändert wird — z. B. ein Status‑Update im Ticketing, eine Genehmigung im ERP, eine Anrufliste im CRM.
Eine gute Definition beinhaltet das Zielsystem, das genaue Feld/Zustand, der sich ändert, und wie Sie verifizieren, dass die Änderung stattgefunden hat.
Minimalen Workflow bauen (Exceptions zuerst)
Vermeiden Sie alles auf einmal zu automatisieren. Starten Sie mit einem exceptions‑first‑Workflow: das System markiert Items, die Aufmerksamkeit brauchen, routet sie an die richtige Person und verfolgt die Auflösung.
Nur notwendige Integrationen mit klaren Genehmigungspfaden
Priorisieren Sie wenige, hochwirksame Integrationspunkte (ERP/CRM/Ticketing) und machen Sie Genehmigungsschritte explizit. Das reduziert Risiko, weil es „Schattenentscheidungen“ außerhalb des Systems verhindert.
Change‑Management als Teil des Builds planen
Operative Tools verändern Verhalten. Beziehen Sie Schulung, Anreize und neue Rollen (z. B. Workflow‑Owner, Data‑Stewards) in den Rollout ein, damit der Prozess tatsächlich greift.
Workflows schneller prototypen (wo Koder.ai helfen kann)
Eine praktische Herausforderung ist, dass Sie oft leichtgewichtige Apps — Queues, Genehmigungsansichten, Exception‑Handling und Status‑Updates — brauchen, bevor Sie Wert beweisen können.
Plattformen wie Koder.ai können Teams helfen, diese Workflow‑Oberflächen schnell zu prototypisieren mit einem chat‑gesteuerten, vibe‑coding Ansatz: beschreiben Sie den Entscheidungsfluss, Datenentitäten und Rollen, und generieren Sie eine erste Web‑App (oft React) und Backend (Go + PostgreSQL), die Sie iterativ verbessern können.
Das ersetzt nicht die Notwendigkeit solider Datenintegration und Governance, kann aber die Zeit von Entscheidungsdefinition zu nutzbarem Workflow verkürzen — besonders wenn Sie Planning‑Mode zur Stakeholder‑Ausrichtung und Snapshots/Rollback zum sicheren Testen nutzen. Falls die App später in eine andere Umgebung migriert werden muss, kann Source‑Code‑Export Lock‑in reduzieren.
Wie Sie wählen: eine praktische Checkliste
Der einfachste Weg, zwischen Palantir Foundry vs BI zu entscheiden, ist, bei der Entscheidung zu beginnen, die Sie verbessern wollen — nicht bei den Features, die Sie kaufen möchten.
1) Wann traditionelle BI ausreicht
Wählen Sie traditionelle Business Intelligence (Dashboards und Reporting), wenn Ihr Ziel Sichtbarkeit und Lernen ist:
- KPI‑Monitoring, Trends und Ausnahmen ("was hat sich geändert?")
- Ad‑hoc‑Exploration und Slice‑and‑Dice ("warum ist das passiert?")
- Periodisches Reporting für Führung und Compliance
Wenn das Hauptergebnis besseres Verständnis ist (nicht eine unmittelbare operative Aktion), ist BI in der Regel die richtige Wahl.
2) Wann Sie ein operationales Entscheidungssystem brauchen
Ein operatives Entscheidungssystem passt besser, wenn Entscheidungen wiederkehrend sind und Ergebnisse von konsistenter Ausführung abhängen:
- die Entscheidung hat eine klare Aktion (approve/deny, allokieren, umleiten, planen)
- viele Personen treffen dieselbe Entscheidung cross‑teams oder Standorten
- Geschwindigkeit ist wichtig und das Warten auf ein Meeting/report kostet Geld
Hier ist das Ziel Analytics to Action: Daten in Entscheidungsworkflows zu verwandeln, die zuverlässig den nächsten Schritt auslösen.
3) Evaluationsfragen (bevor Sie Anbieter vergleichen)
- Decision Inventory: Was sind die Top‑10 wiederkehrenden Entscheidungen und wer besitzt sie?
- Datenintegration: Haben Sie die operativen Daten an einem Ort, oder sind sie verteilt?
- Governance: Können Sie erklären, „wer was wann und warum“ für wichtige Outputs geändert hat?
- UX: Brauchen Nutzer ein Dashboard oder einen geführten Workflow mit Guardrails?
- Time‑to‑Value: Können Sie eine Decision‑Pilotierung End‑to‑End in 6–10 Wochen durchführen?
4) Ein praktischer Hybridansatz
Viele Organisationen behalten BI für breite Sichtbarkeit und fügen Entscheidungsworkflows (plus governance‑gerechte Datenprodukte und eine semantische Ebene) dort hinzu, wo Ausführung standardisiert werden muss.
5) Nächste Schritte
Erstellen Sie ein Decision‑Inventory, bewerten Sie jede Entscheidung nach Business‑Impact und Machbarkeit, und wählen Sie eine hochwirksame Entscheidung für einen Pilot mit klaren Erfolgsmetriken.