Was hier mit „Palantir“ und „traditioneller Unternehmenssoftware" gemeint ist
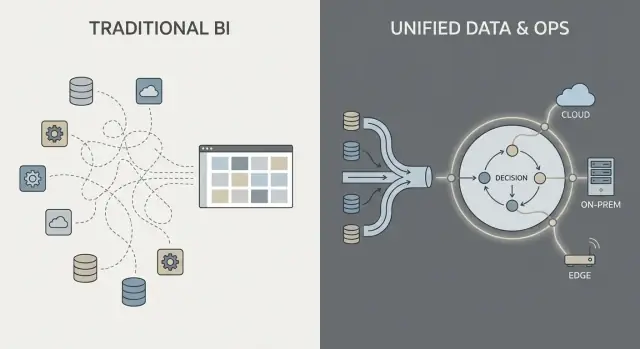
Menschen verwenden „Palantir“ oft als Kurzform für einige verwandte Produkte und einen bestimmten Weg, datengetriebene Operationen aufzubauen. Um den Vergleich klar zu halten, hilft es, zu benennen, was genau gemeint ist — und was nicht.
Was „Palantir“ in diesem Beitrag bezeichnet
Wenn jemand im Unternehmenskontext „Palantir“ sagt, meint er typischerweise eines (oder mehrere) der folgenden:
- Foundry: Palantirs kommerzielle Plattform, fokussiert auf Datenintegration, Modellierung und die Ermöglichung operativer Entscheidungen.
- Gotham: Oft mit Verteidigungs‑ und öffentlichem Sektor assoziiert, mit ähnlichen Themen, aber anderer Historie und Positionierung.
- Apollo: Ein Bereitstellungs‑/Delivery‑System, das zum Ausliefern und Verwalten von Software über viele Umgebungen hinweg genutzt wird (einschließlich eingeschränkter Umgebungen).
Dieser Text verwendet „Palantir‑ähnlich“, um die Kombination aus (1) starker Datenintegration, (2) einer semantischen/Ontologie‑Schicht, die Teams auf gemeinsame Bedeutung ausrichtet, und (3) Bereitstellungsmustern zu beschreiben, die Cloud, On‑Prem und getrennte Setups umfassen können.
Was „traditionelle Unternehmenssoftware" hier bedeutet
„Traditionelle Unternehmenssoftware" ist kein einzelnes Produkt — es ist der typische Stack, den viele Organisationen im Laufe der Zeit zusammensetzen, z. B.:
- ERP‑ und CRM‑Systeme (Systeme of Record für Finanzen, Supply Chain, Vertrieb)
- Ein Data Warehouse oder Lake plus BI‑Dashboards (Reporting und Analytik)
- Integrations‑Middleware (ETL/ELT‑Tools, iPaaS, Message Queues, APIs)
In diesem Ansatz werden Integration, Analytik und Betrieb häufig von separaten Tools und Teams gehandhabt, verbunden durch Projekte und Governance‑Prozesse.
Was dieser Vergleich ist (und was nicht)
Dies ist ein Ansatz‑Vergleich, keine Anbieter‑Verkaufsförderung. Viele Organisationen haben Erfolg mit konventionellen Stacks; andere profitieren von einem stärker vereinheitlichten Plattformmodell.
Die praktische Frage lautet: welche Kompromisse gehen Sie in Bezug auf Geschwindigkeit, Kontrolle und die unmittelbare Verbindung von Analytik zu täglicher Arbeit ein?
Um den Rest des Artikels geerdet zu halten, konzentrieren wir uns auf drei Bereiche:
- Datenintegration: wie Daten verbunden, gepflegt und verwaltet werden
- Operative Analytik: wie Analysen über Dashboards hinaus in Entscheidungen übersetzt werden
- Bereitstellungsmodelle: Cloud, On‑Prem und netzgetrennte/air‑gapped Realitäten
Datenintegration: Pipelines und Verantwortlichkeiten
Die meisten Datenprozesse in „traditioneller Unternehmenssoftware" folgen einer vertrauten Kette: Daten aus Systemen (ERP, CRM, Logs) ziehen, transformieren, in ein Warehouse/Lake laden und dann BI‑Dashboards plus einige nachgelagerte Apps bauen.
Dieses Muster kann gut funktionieren, aber oft wird Integration zu einer Reihe fragiler Übergaben: Ein Team besitzt Extraktionsskripte, ein anderes Warehouse‑Modelle, ein drittes Dashboard‑Definitionen, und Business‑Teams pflegen Tabellenkalkulationen, die heimlich die „wahre Zahl“ neu definieren.
Das traditionelle Muster: ETL/ELT als Staffelstab
Bei ETL/ELT neigen Änderungen dazu, Wellen zu schlagen. Ein neues Feld im Quellsystem kann eine Pipeline zum Absturz bringen. Ein „Quick Fix“ erzeugt eine zweite Pipeline. Bald gibt es duplizierte Metriken („Umsatz“ an drei Stellen), und es ist unklar, wer verantwortlich ist, wenn Zahlen nicht übereinstimmen.
Batch‑Verarbeitung ist hier üblich: Daten landen nachts, Dashboards aktualisieren sich am Morgen. Near‑Realtime ist möglich, wird aber oft zu einem separaten Streaming‑Stack mit eigener Toolchain und eigenen Besitzern.
Das Palantir‑ähnliche Muster: integrieren, Bedeutung standardisieren, überall wiederverwenden
Ein Palantir‑ähnlicher Ansatz zielt darauf ab, Quellen zu vereinheitlichen und konsistente Semantik (Definitionen, Beziehungen, Regeln) früher anzuwenden und dann dieselben kuratierten Daten für Analysen und operative Workflows bereitzustellen.
Einfach gesagt: Anstatt dass jedes Dashboard oder jede App selbst „erkennt“, was ein Kunde, Asset, Fall oder eine Sendung bedeutet, wird diese Bedeutung einmal definiert und wiederverwendet. Das verringert duplizierte Logik und macht Verantwortlichkeiten klarer — denn wenn eine Definition sich ändert, wissen Sie, wo sie liegt und wer sie genehmigt.
Häufige Schmerzpunkte, auf die Sie achten sollten
Integration scheitert meist an Verantwortlichkeiten, nicht an Konnektoren:
- Brüchige Pipelines, die durch kleine Quelländerungen brechen
- Duplizierte Metriken, die von Teams unterschiedlich definiert werden
- Unklare Ownership für Datenqualität, Definitionen und Fehlerbehebung
Die Schlüsselfrage ist nicht nur „Können wir System X anbinden?“, sondern „Wer besitzt die Pipeline, die Metrikdefinitionen und die geschäftliche Bedeutung über die Zeit?"
Semantische Schicht und Ontologie: ein anderer Schwerpunkt
Traditionelle Unternehmenssoftware behandelt „Bedeutung" oft als Nebensache: Daten liegen in vielen anwendungs‑spezifischen Schemata, Metrikdefinitionen leben in einzelnen Dashboards, und Teams pflegen stillschweigend ihre eigene Auffassung davon, was ein Auftrag ist oder wann ein Fall als gelöst gilt. Das Ergebnis ist bekannt — unterschiedliche Zahlen an unterschiedlichen Orten, langwierige Reconciliation‑Meetings und unklare Verantwortlichkeit bei Auffälligkeiten.
Ontologie, einfach erklärt
In einem Palantir‑ähnlichen Ansatz ist die semantische Schicht nicht nur ein Reporting‑Komfort. Eine Ontologie fungiert als gemeinsames Geschäftsmodell, das definiert:
- Entitäten (Dinge, die Ihrem Geschäft wichtig sind): Auftrag, Kunde, Asset, Sendung, Fall
- Beziehungen (wie diese Dinge verbunden sind): ein Auftrag gehört zu einem Kunden; eine Sendung erfüllt einen Auftrag; ein Asset ist installiert bei einem Standort
- Aktionen (was Menschen damit tun): freigeben, veranlassen, eskalieren, außer Dienst stellen, erstatten
Das wird zur „Schwerkraft“ für Analysen und Operationen: Mehrere Datenquellen können weiterhin existieren, aber sie werden auf einen gemeinsamen Satz von Geschäftsobjekten mit konsistenten Definitionen abgebildet.
Warum Semantik wichtiger ist, als viele erwarten
Ein gemeinsames Modell reduziert widersprüchliche Zahlen, weil Teams nicht in jedem Report oder jeder App Definitionen neu erfinden. Es verbessert auch die Verantwortlichkeit: Wenn „Pünktliche Lieferung" gegen Sendungsereignisse in der Ontologie definiert ist, ist klarer, wer die zugrunde liegenden Daten und die Geschäftslogik besitzt.
Praktische Beispiele
- Aufträge: Vertrieb, Finanzen und Support sehen dasselbe Auftragsobjekt mit Status, Wert, Genehmigungen und Ausnahmen — keine separaten „Auftrags‑Tabellen“ pro Abteilung.\n- Assets: Instandhaltung, Betrieb und Compliance teilen einen Asset‑Datensatz mit Standort, Prüfgeschichte und Risikoflaggen.\n- Fälle: Support‑Fälle sind mit Kunden, Aufträgen und Sendungen verknüpft, sodass Eskalationsregeln und Service‑Metriken nicht abdriften.
Wird es gut gemacht, macht eine Ontologie nicht nur Dashboards sauberer — sie beschleunigt tägliche Entscheidungen und reduziert Streitigkeiten.
Operative Analytik vs. BI‑Dashboards
BI‑Dashboards und klassisches Reporting dienen primär der Rückschau und Überwachung. Sie beantworten Fragen wie „Was ist letzte Woche passiert?“ oder „Sind wir auf Kurs bei den KPIs?" Ein Sales‑Dashboard, ein Monatsabschluss‑Report oder ein Executive‑Scorecard sind wertvoll — doch oft endet ihre Wirkung bei der Sichtbarkeit.
Operative Analytik ist anders: Sie ist Analytik, die in den täglichen Entscheidungen und der Ausführung verankert ist. Anstatt ein separates „Analytik‑Ziel“ zu sein, erscheint die Analyse direkt im Workflow, wo Arbeit ausgeführt wird, und sie treibt einen konkreten nächsten Schritt an.
BI: beobachten und erklären
BI/Reporting fokussiert typischerweise auf:
- Standardisierte Metriken und KPI‑Definitionen
- Geplante Aktualisierungen und wöchentliche/monatliche Reviews
- Aggregierte Sichten (Teams, Regionen, Zeiträume)
- Ursachenforschung, nachdem Ergebnisse bekannt sind
Das ist hervorragend für Governance, Performance‑Management und Verantwortlichkeit.
Operative Analytik: entscheiden und handeln
Operative Analytik konzentriert sich auf:
- Echtzeit‑ oder Near‑Realtime‑Signale
- Entscheidungsunterstützung im Moment der Aktion
- Empfehlungen, Priorisierung und Ausnahmebehandlung
- Feedback‑Schleifen (hat die Maßnahme gewirkt und was hat sich geändert?)
Konkrete Beispiele sehen weniger aus wie „ein Chart“ und mehr wie eine Arbeitsliste mit Kontext:
- Dispo/Dispatch: Auswahl, welchen Auftrag welche Crew erhält, unter Berücksichtigung von Standort, Qualifikation, SLA und Teileverfügbarkeit
- Inventarzuweisung: Entscheiden, wohin begrenzte Bestände geschickt werden, um Rückstände zu reduzieren
- Betrugstriage: Fälle nach Risiko priorisieren und an Ermittler mit passender Evidenz routen
- Wartungsplanung: Ausfälle vorhersagen und Stillstand so planen, dass Produktion minimal gestört wird
Der entscheidende Wechsel: vom „Ansehen“ zum „Handeln"
Die wichtigste Änderung ist, dass Analyse an einen konkreten Arbeitsschritt gebunden ist. Ein BI‑Dashboard mag anzeigen „verspätete Lieferungen nehmen zu“. Operative Analytik wandelt das in „hier sind die 37 Sendungen, die heute gefährdet sind, mögliche Ursachen und empfohlene Maßnahmen“, mit der Möglichkeit, die nächste Aktion sofort auszuführen oder zuzuweisen.
Von Erkenntnissen zu Aktionen: Workflow‑zentriertes Design
Traditionelle Unternehmensanalytik endet oft beim Dashboard: Jemand entdeckt ein Problem, exportiert eine CSV, schickt eine Mail, und ein separates Team „macht später etwas“. Ein Palantir‑ähnlicher Ansatz ist darauf ausgelegt, diese Lücke zu verkürzen, indem Analytik direkt in den Workflow eingebettet wird, in dem Entscheidungen getroffen werden.
Mensch‑in‑der‑Schleife‑Entscheidungen (nicht Autopilot)
Workflow‑zentrierte Systeme erzeugen typischerweise Empfehlungen (z. B. „priorisiere diese 12 Sendungen“, „markiere diese 3 Lieferanten“, „plane Wartung innerhalb von 72 Stunden“), benötigen aber weiterhin explizite Genehmigungen. Dieser Genehmigungsschritt ist wichtig, weil er schafft:
- Verantwortlichkeit: wer genehmigt hat, wann und auf welcher Datenbasis
- Audit‑Spuren: eine dokumentierte Kette von Eingabedaten → Logik/Modell → Empfehlung → Aktion
- Kontrollierte Ausnahmen: Operatoren können mit Begründung überstimmen anstatt das Tool zu umgehen
Das ist besonders nützlich in regulierten oder risikobehafteten Abläufen, in denen „das Modell sagte so“ keine ausreichende Begründung ist.
Workflows ersetzen die „Report‑Übergabe"
Anstatt Analytik als separates Ziel zu behandeln, kann die Benutzeroberfläche Erkenntnisse in Aufgaben routen: Zu einer Queue zuweisen, Sign‑off anfragen, Benachrichtigung auslösen, einen Fall eröffnen oder einen Arbeitsauftrag erstellen. Wichtig ist, dass Ergebnisse im selben System nachverfolgt werden — so lässt sich messen, ob Aktionen Risiko, Kosten oder Verzögerungen reduziert haben.
Rollenspezifische Erfahrungen und Entscheidungsrechte
Workflow‑zentriertes Design trennt normalerweise Erfahrungen nach Rolle:
- Frontline‑Operatoren: schnelle Queues, klare Next‑Best‑Action, minimaler Kontextbedarf
- Analysten: tiefere Drill‑downs, Szenarien‑Tests und Monitoring von Daten/Modellqualität
- Führungskräfte: KPIs verknüpft mit operativer Durchsatzleistung und Engpässen, nicht nur Charts
Erfolgsfaktor ist die Ausrichtung des Produkts an Entscheidungsrechten und Betriebsverfahren: wer darf handeln, welche Genehmigungen sind nötig und was bedeutet „erledigt“ operativ.
Governance, Sicherheit und Vertrauen in die Daten
Behalte die volle Kontrolle
Nimm den generierten Quellcode und setze ihn in deiner eigenen Pipeline weiter ein.
Governance entscheidet darüber, ob Analyseprogramme Erfolg haben oder ins Stocken geraten. Es ist nicht nur „Sicherheitseinstellungen“ — es sind praktische Regeln und Nachweise, die Menschen vertrauen lassen, Daten zu nutzen, sicher zu teilen und auf ihrer Basis zu entscheiden.
Was Governance abdecken muss (über Login hinaus)
Die meisten Unternehmen brauchen dieselben Kernkontrollen, unabhängig vom Anbieter:
- Zugriffsrechte: wer Daten, Modelle und operative Outputs sehen, bearbeiten oder genehmigen darf
- Datenherkunft (Lineage): woher eine Metrik stammt, welche Quellen sie fütterten und welche Transformationen geschahen
- Audit‑Logs: eine rechtssichere Aufzeichnung, wer was wann geändert hat
- Genehmigungen und Change‑Control: besonders für „offizielle“ Metriken, geteilte Datensätze und Produktionsworkflows
Das ist keine Bürokratie um ihrer selbst willen. So verhindern Sie das „zwei Versionen der Wahrheit“‑Problem und reduzieren Risiko, wenn Analytik näher an Operationen rückt.
„Sicherheit am Dashboard" vs. Sicherheit über die ganze Kette
Traditionelle BI‑Implementierungen legen Sicherheit häufig vor allem auf der Reporting‑Ebene fest: Benutzer dürfen bestimmte Dashboards sehen, Administratoren verwalten dort Rechte. Das kann funktionieren, wenn Analytik überwiegend deskriptiv ist.
Ein Palantir‑ähnlicher Ansatz verankert Sicherheit und Governance durch die gesamte Kette: von der Rohdatenerfassung über die semantische Schicht (Objekte, Beziehungen, Definitionen), zu Modellen und sogar zu Aktionen, die aus Erkenntnissen ausgelöst werden. Das Ziel ist, dass eine operative Entscheidung (z. B. Crew disponieren, Inventar freigeben, Fälle priorisieren) dieselben Kontrollen erbt wie die dahinterliegenden Daten.
Least Privilege und Segregation of Duties (in einfachen Worten)
Zwei Prinzipien sind zentral für Sicherheit und Verantwortlichkeit:
- Least Privilege: Personen erhalten nur den Zugriff, den sie für ihre Aufgabe benötigen
- Segregation of Duties: die Person, die Logik ändert oder erstellt, ist nicht dieselbe, die sie für die Produktion genehmigt
Beispielsweise schlägt ein Analyst eine Metrikdefinition vor, ein Data Steward genehmigt sie, und das Operations‑Team nutzt sie — mit einer klaren Audit‑Spur.
Warum Governance Adoption antreibt
Gute Governance ist nicht nur für Compliance‑Teams wichtig. Wenn Business‑Nutzer Lineage anklicken, Definitionen sehen und sich auf konsistente Berechtigungen verlassen können, hören sie auf, sich über Tabellenkalkulationen zu streiten, und beginnen, auf Erkenntnisse zu handeln. Dieses Vertrauen verwandelt Analytik von „interessanten Reports“ in operationales Verhalten.
Bereitstellungsmodelle: Cloud, On‑Prem und getrennte Umgebungen
Wo Unternehmenssoftware läuft, ist heute kein reines IT‑Detail mehr — es beeinflusst, was Sie mit Daten tun können, wie schnell Sie Änderungen einführen und welches Risiko Sie akzeptieren. Käufer bewerten üblicherweise vier Bereitstellungsmuster.
Public Cloud
Public Cloud (AWS/Azure/GCP) optimiert für Geschwindigkeit: Provisionierung ist schnell, Managed‑Services reduzieren Infrastrukturarbeit und Skalierung ist unkompliziert. Hauptfragen für Käufer sind Datenresidenz (Region, Backups, Supportzugriff), Integration zu On‑Prem‑Systemen und ob Ihr Sicherheitsmodell Cloud‑Netzwerkkonnektivität toleriert.
Private Cloud
Eine Private Cloud (Single‑Tenant oder kundenseitig verwaltetes Kubernetes/VMs) wird oft gewählt, wenn man cloud‑ähnliche Automatisierung, aber engere Kontrolle über Netzwerkgrenzen und Audit‑Anforderungen braucht. Sie kann Compliance‑Reibung reduzieren, verlangt aber diszipliniertes Patch‑, Monitoring‑ und Zugriffsmangement.
On‑Prem
On‑Prem‑Deployments sind in Fertigung, Energie und stark regulierten Branchen weiterhin verbreitet, wo Kernsysteme und Daten die Einrichtung nicht verlassen dürfen. Der Kompromiss ist operativer Overhead: Hardware‑Lifecycle, Kapazitätsplanung und mehr Aufwand, Umgebungen konsistent (Dev/Test/Prod) zu halten. Wenn Ihre Organisation Schwierigkeiten hat, Plattformen zuverlässig zu betreiben, kann On‑Prem die Time‑to‑Value verlangsamen.
Getrennt / air‑gapped
Netzgetrennte (air‑gapped) Umgebungen sind ein Spezialfall: Verteidigung, kritische Infrastruktur oder Standorte mit limitierten Verbindungen. Dort muss das Bereitstellungsmodell strikte Update‑Kontrollen unterstützen — signierte Artefakte, kontrollierte Promotion von Releases und wiederholbare Installationen in isolierten Netzen.
Netzwerkbeschränkungen beeinflussen auch die Datenbewegung: Statt kontinuierlichem Sync sind gestaffelte Transfers und „Export/Import“‑Workflows üblich.
Die wichtigsten Abwägungen
In der Praxis ist es ein Dreieck: Flexibilität (Cloud), Kontrolle (On‑Prem/air‑gapped) und Geschwindigkeit der Änderung (Automatisierung + Updates). Die richtige Wahl hängt von Residenzregeln, Netzwerkrealitäten und davon ab, wie viel Plattform‑Betrieb Ihr Team übernehmen will.
Betrieb von Updates: Was Apollo‑ähnliche Delivery verändert
Zeigen, nicht erklären
Stelle deinen Prototyp bereit und teile ihn mit Stakeholdern für echtes Feedback.
„Apollo‑ähnliche Delivery“ ist im Grunde kontinuierliche Auslieferung für hochkritische Umgebungen: Sie können Verbesserungen häufig (wöchentlich, täglich, sogar mehrfach am Tag) ausliefern und dabei den Betrieb stabil halten.
Das Ziel ist nicht „schnell und kaputtmachen", sondern „häufig liefern und nichts kaputtmachen".
Kontinuierliche Auslieferung, einfach erklärt
Statt Änderungen in ein großes Quartals‑Release zu bündeln, liefern Teams kleine, reversierbare Updates. Jedes Update ist leichter zu testen, zu erklären und zurückzunehmen, falls etwas schiefgeht.
Für operative Analytik ist das wichtig, weil Ihre „Software" nicht nur eine UI ist — es sind Datenpipelines, Business‑Logik und Workflows, auf die Menschen angewiesen sind. Ein sicherer Update‑Prozess wird so Teil des täglichen Betriebs.
Wie sich das von traditionellen Enterprise‑Zyklen unterscheidet
Traditionelle Software‑Upgrades sehen oft wie Projekte aus: lange Planungsfenster, Koordination von Downtime, Kompatibilitätsfragen, Schulungen und ein harter Cutover‑Termin. Selbst wenn Anbieter Patches liefern, verzögern viele Organisationen Updates, weil Risiko und Aufwand schwer kalkulierbar sind.
Apollo‑ähnliche Tools wollen Upgrades zur Routine machen — eher Wartung als Großmigration.
Bau und Auslieferung trennen
Moderne Deployment‑Tools erlauben Teams, in isolierten Umgebungen zu entwickeln und zu testen und dann dasselbe Build durch Stufen zu „promoten" (dev → test → staging → prod) mit konsistenten Kontrollen. Diese Trennung reduziert Überraschungen durch Unterschiede zwischen Umgebungen.
Fragen an Anbieter
- Wie handhaben Sie Rollbacks — ein Klick, partiell oder komplexe Wiederherstellungsschritte?\n- Welche Versionierung gibt es für Pipelines, Modelle und Ontologie‑Änderungen (nicht nur für die UI)?\n- Wie funktioniert Environment‑Promotion und wer kann sie genehmigen?\n- Kann man Canary‑Releases oder Feature‑Flags nutzen?\n- Welcher Audit‑Trail zeigt, wer was wann und warum ausgeliefert hat?\n- Welche Ausfallzeit ist bei typischen Updates zu erwarten — idealerweise keine?
Implementierung und Time‑to‑Value: Was tatsächlich Aufwand kostet
Time‑to‑Value hängt weniger davon ab, wie schnell etwas „installiert“ ist, sondern wie schnell Teams sich auf Definitionen einigen, unordentliche Daten anbinden und Erkenntnisse in tägliche Entscheidungen übersetzen.
Implementierungsstile: konfigurieren, zusammensetzen oder bauen
Traditionelle Software betont oft Konfiguration: Sie übernehmen ein vordefiniertes Datenmodell und Workflows und mappen Ihr Geschäft darauf.
Palantir‑ähnliche Plattformen mischen typischerweise drei Modi:
- Konfiguration für Zugriffskontrollen, Datenverbindungen und Standardkomponenten
- Wiederverwendbare Bausteine (Templates, Komponenten, Patterns), die zu neuen Use Cases zusammengesetzt werden können
- Custom‑Anwendungsentwicklung wenn der Workflow einzigartig ist (z. B. Genehmigungen, Ausnahmebehandlung, operative Übergaben)
Das Versprechen ist Flexibilität — aber es bedeutet auch, dass Sie klar definieren müssen, was Sie bauen vs. was Sie standardisieren.
Eine praktische Option in der frühen Discovery ist schnelles Prototyping von Workflow‑Apps, bevor Sie sich auf eine große Plattform‑Rollout festlegen. Beispielsweise nutzen Teams manchmal Koder.ai (eine Vibe‑Coding‑Plattform), um eine Workflow‑Beschreibung via Chat in eine funktionierende Web‑App zu überführen und dann mit Stakeholdern im Planning‑Modus, mit Snapshots und Rollback zu iterieren. Weil Koder.ai Source‑Code‑Export und typische Produktionsstacks unterstützt (React im Web; Go + PostgreSQL im Backend; Flutter für Mobil), kann es ein niedrigschwelliges Mittel sein, um die „Erkenntnis → Aufgabe → Audit‑Trail"‑UX und Integrationsanforderungen in einem Proof‑of‑Value zu validieren.
Woran Teams tatsächlich Zeit verbringen
Die meiste Arbeit entfällt in der Regel auf vier Bereiche:
- Daten‑Onboarding: Quell‑Owner zur Zugangsgewährung bringen, Felder dokumentieren, Qualitätslücken behandeln und Aktualisierungsfrequenz klären\n2. Modellierung und Semantik: Geschäftsdefinitionen abstimmen (was „aktiv“, „verspätet", „verfügbar" bedeutet) und konsistent halten\n3. Workflow‑Design: Festlegen, wer auf Alerts reagiert, welche Entscheidungen erlaubt sind und was „erledigt" heißt\n4. Schulung und Adoption: ein Tool zur Gewohnheit machen — besonders bei Frontline‑Nutzern, die Komplexität nicht tolerieren
Warnsignale, die Wert mindern oder killen
Achten Sie auf unklare Ownership (kein verantwortlicher Daten/Product‑Owner), zu viele bespoke Definitionen (jedes Team erfindet eigene Metriken) und keinen Pfad vom Pilot zur Skalierung (eine Demo, die nicht operationalisierbar, supportbar oder governbar ist).
Einen Pilot so strukturieren, dass er skaliert
Ein guter Pilot ist bewusst eng: wählen Sie einen Workflow, definieren Sie konkrete Nutzer und verpflichten Sie sich zu messbaren Ergebnissen (z. B. Durchlaufzeit um 15% reduzieren, Ausnahmerückstand um 30% senken). Entwerfen Sie den Pilot so, dass dieselben Daten, Semantiken und Kontrollen auf den nächsten Use Case erweitert werden können — statt neu anzufangen.
Kosten‑Gespräche werden schnell unübersichtlich, weil eine „Plattform" Fähigkeiten bündelt, die sonst als separate Tools eingekauft werden. Wichtig ist, Preisgestaltung an den benötigten Ergebnissen zu messen (Integration + Modellierung + Governance + operative Apps), nicht nur an der Zeile „Software".
Die meisten Plattform‑Deals werden von einigen Variablen geprägt:
- Nutzerzahl und Rollen: Builder (Ingenieure, Modeler) vs. Konsumenten (Operatoren, Analysten)\n- Compute und Storage: intensive Workloads (Echtzeit, Simulation, große Joins) erhöhen Infrastrukturkosten\n- Anzahl der Umgebungen: dev/test/prod plus regulierte oder getrennte Umgebungen erhöhen Overhead\n- Support‑ und Verfügbarkeitsanforderungen: 24/7‑Support, Incident‑SLAs und dedizierte Success‑Teams verändern den Preis\n- Professional Services: initiales Daten‑Onboarding, Ontologie‑Design und Workflow‑Build sind oft der echte Early‑Cost‑Treiber
Was die Kosten des „traditionellen Stacks" verschleiern
Ein Punkt‑Lösungsansatz kann zunächst günstiger erscheinen, aber die Gesamtkosten verteilen sich auf:
- Mehrere Lizenzen (ETL/ELT, BI, Catalog, Governance, Workflow, Feature Store usw.)\n- Integrationsarbeit zwischen Tools (Connectoren, Identity, Berechtigungs‑/Metadaten‑Sync)\n- Laufende Wartung (Upgrade‑Arbeiten, gebrochene Pipelines, duplizierte Metrikdefinitionen)
Plattformen reduzieren oft Tool‑Sprawl, aber Sie tauschen das gegen einen größeren, strategischeren Vertrag.
Beim Kauf einer Plattform sollte die Beschaffung sie als gemeinsame Infrastruktur behandeln: definieren Sie Enterprise‑Scope, Datendomänen, Sicherheitsanforderungen und Liefermeilensteine. Fordern Sie eine klare Trennung zwischen Lizenz, Cloud/Infra und Services, damit Sie Angebote vergleichbar machen können.
Einfache Budget‑Checkliste
- Welche Teams bauen aktiv und welche sehen nur?\n- Welche Workflows müssen in Produktion laufen (nicht nur Dashboards)?\n- Wie viele Umgebungen und Regionen werden benötigt?\n- Gibt es air‑gapped oder offline Standorte?\n- Erwartetes Wachstum an Datenvolumen/Aktualisierungsfrequenz?\n- Benötigte Services für die ersten 90 Tage?
Wenn Sie eine schnelle Methode zur Strukturierung von Annahmen wollen, siehe /pricing.
Wann Palantir‑ähnliche Ansätze passen (und wann nicht)
Für Governance gestalten
Füge menschliche Kontrollschritte hinzu, damit Empfehlungen zu prüfbaren Entscheidungen werden.
Palantir‑ähnliche Plattformen glänzen tendenziell, wenn das Problem operational ist (Menschen müssen Entscheidungen treffen und Aktionen über Systeme hinweg ausführen), nicht nur analytisch (man braucht einen Report). Der Kompromiss ist, dass Sie einen stärkeren „Plattform"‑Ansatz übernehmen — mächtig, aber organisatorisch anspruchsvoller als ein einfacher BI‑Rollout.
Szenarien mit guter Passung
Ein Palantir‑ähnlicher Ansatz passt oft, wenn Arbeit mehrere Systeme und Teams überspannt und Sie sich keine brüchigen Übergaben leisten können.
Gängige Beispiele sind bereichsübergreifende Operationen wie Supply‑Chain‑Koordination, Betrugs‑ und Risikooperationen, Missionsplanung, Case‑Management oder Flotten‑ und Wartungsworkflows — Situationen, in denen dieselben Daten von unterschiedlichen Rollen konsistent interpretiert werden müssen.
Er passt auch gut, wenn Berechtigungen komplex sind (Row/Column‑Level, Multi‑Tenant, Need‑to‑Know) und wenn Sie eine klare Audit‑Spur benötigen, wie Daten verwendet wurden. Schließlich eignet er sich für regulierte oder eingeschränkte Umgebungen: On‑Prem‑Anforderungen, air‑gapped Deployments oder strenge Sicherheitsakkreditierungen, bei denen das Bereitstellungsmodell eine Kernanforderung ist.
Szenarien mit geringer Passung
Wenn das Ziel vorwiegend einfaches Reporting ist — wöchentliche KPIs, einige Dashboards, grundlegende Finanzkonsolidierung — kann traditionelles BI auf einem gut verwalteten Warehouse schneller und günstiger sein.
Es ist auch überdimensioniert für kleine Datensätze, stabile Schemata oder Single‑Department‑Analytik, wo ein Team die Quellen und Definitionen kontrolliert und die Hauptaktionen außerhalb des Tools stattfinden.
Entscheidungskriterien (Fit‑to‑Problem)
Stellen Sie drei praktische Fragen:
- Dringlichkeit: Brauchen Teams in Wochen funktionierende Workflows, oder ist das ein langer Modernisierungsweg?\n- Datenkomplexität: Hindern inkonsistente Definitionen und fragmentierte Quellen entscheidende Entscheidungen?\n- Änderungskapazität: Haben Sie Produktverantwortung, SMEs und Governance‑Bandbreite, um eine Plattform zu übernehmen und aktuell zu halten?
Die besten Ergebnisse entstehen, wenn man es als „Fit‑to‑Problem" behandelt, nicht als „ein Tool ersetzt alles". Viele Organisationen behalten bestehendes BI für breit angelegtes Reporting und nutzen einen Palantir‑ähnlichen Ansatz für die geschäftskritischsten operativen Bereiche.
Käufer‑Checkliste und nächste Schritte
Der Kauf einer „Palantir‑ähnlichen" Plattform vs. traditioneller Unternehmenssoftware dreht sich weniger um Feature‑Checkboxen und mehr darum, wo die tatsächliche Arbeit landet: Integration, gemeinsame Bedeutung (Semantik) und tägliche operative Nutzung. Nutzen Sie die Checkliste unten, um frühzeitig Klarheit zu erzwingen, bevor Sie in eine lange Implementierung oder ein enges Point‑Tool gebunden werden.
Praktische Vendor‑Vergleichs‑Checkliste
Bitten Sie jeden Anbieter, konkret zu sagen, wer was macht, wie es konsistent bleibt und wie es in realen Operationen genutzt wird.
- Integrationsaufwand: Welche Datenquellen sind typisch (ERP, Logs, Tabellen, Partnerfeeds)? Was ist vorgefertigt vs. custom? Wer pflegt Pipelines nach Go‑Live — IT, Data Engineering oder der Anbieter?\n- Semantische Konsistenz: Wie verhindern sie, dass fünf Teams „Kunde“, „Asset“ oder „mission‑ready" unterschiedlich definieren? Können sie eine governte Business‑Ebene (Ontologie/semantisches Modell) zeigen und wie Änderungen sich auswirken?\n- Workflow‑Unterstützung: Können Frontline‑Teams eine Aufgabe (triage, freigeben, dispatch, untersuchen) im Produkt abschließen, oder ist es „hier analysieren, anderswo handeln"? Wie werden Ausnahmen gehandhabt?\n- Governance und Sicherheit: Feingranulare Zugriffsregeln, Audit‑Logs und Policy‑Management — können Daten‑Owner kontrollieren, wer was in welcher Granularität und warum sieht?\n- Bereitstellungsbeschränkungen: Läuft es in Ihrer geforderten Umgebung (Cloud, On‑Prem, air‑gapped)? Was funktioniert nicht bei eingeschränkter Konnektivität? Wie ist der Upgrade‑Pfad?
Demo‑Prüfungen (keine Slides akzeptieren)
- Lineage zeigen: Wählen Sie eine kritische KPI und verfolgen Sie sie von der Quelle bis zur finalen Metrik. Wo kann sie falsch sein und wie würden Sie das erkennen?\n2. Workflow Ende‑zu‑Ende demonstrieren: Starten Sie mit Rohdaten, dann Alert → Entscheidung → Aktion → Audit‑Trail. Schließen Sie Genehmigungen und „wer hat was geändert" ein.\n3. Ausfall/Rollback simulieren: Was passiert, wenn eine Pipeline fehlschlägt oder ein Release Regressionen verursacht? Können sie sauber zurückrollen und wie schnell?
Wer muss im Raum sein
Beziehen Sie Stakeholder ein, die mit den Kompromissen leben müssen:
- IT und Platform‑Owner (Integrationsverantwortung, Zuverlässigkeit, Kosten)\n- Security und Compliance (Kontrollen, Audits, Bereitstellungsfreigaben)\n- Daten‑Owner/Stewards (Definitionen, Zugriffregeln, Verantwortlichkeit)\n- Operations‑Leiter (Prozessauswirkung, Adoption)\n- Frontline‑Nutzer (hilft es ihnen wirklich, schneller zu arbeiten?)
Nächste Schritte
Führen Sie einen zeitlich begrenzten Proof‑of‑Value durch, der sich auf einen hochkritischen operativen Workflow konzentriert (nicht ein generisches Dashboard). Definieren Sie Erfolgskriterien im Voraus: Entscheidungszeit, Fehlerreduktion, Prüfbarkeit und Ownership der laufenden Datenarbeit.
Wenn Sie mehr Anleitung zu Evaluationsmustern möchten, siehe /blog. Für Hilfe beim Scoping eines Proof‑of‑Value oder bei der Anbieterauswahl, kontaktieren Sie uns unter /contact.