29. Apr. 2025·8 Min
Wie man eine Web-App für Preisexperimente baut
Plane, entwerfe und liefere eine Web-App zur Verwaltung von Preisexperimenten: Varianten, Traffic-Splits, Zuweisung, Metriken, Dashboards und sichere Rollout-Guardrails.
Plane, entwerfe und liefere eine Web-App zur Verwaltung von Preisexperimenten: Varianten, Traffic-Splits, Zuweisung, Metriken, Dashboards und sichere Rollout-Guardrails.
Preisexperimente sind strukturierte Tests, bei denen verschiedenen Kundengruppen unterschiedliche Preise (oder Packaging) gezeigt werden, um zu messen, was sich ändert — Conversion, Upgrades, Churn, Umsatz pro Besucher und mehr. Es ist die Preisversion eines A/B-Tests, bringt aber zusätzliches Risiko mit sich: ein Fehler kann Kunden verwirren, Supporttickets verursachen oder interne Regeln verletzen.
Ein Pricing-Experiment-Manager ist das System, das diese Tests kontrolliert, beobachtbar und umkehrbar macht.
Kontrolle: Teams brauchen einen zentralen Ort, um zu definieren, was getestet wird, wo und für wen. „Wir haben den Preis geändert“ ist kein Plan — ein Experiment braucht eine klare Hypothese, Daten, Targeting-Regeln und einen Kill-Switch.
Tracking: Ohne konsistente Identifier (experiment key, variant key, assignment timestamp) wird die Analyse geraten. Der Manager sollte sicherstellen, dass jede Exposition und jeder Kauf dem richtigen Test zugeordnet werden kann.
Konsistenz: Kunden sollten nicht einen Preis auf der Pricing-Seite sehen und einen anderen beim Checkout. Der Manager muss koordinieren, wie Varianten über Oberflächen angewendet werden, damit die Erfahrung kohärent bleibt.
Sicherheit: Preisfehler sind teuer. Ihr braucht Guardrails wie Traffic-Limits, Eligibility-Regeln (z. B. nur Neukunden), Genehmigungsschritte und Auditierbarkeit.
Dieser Beitrag konzentriert sich auf eine interne Web-App, die Experimente verwaltet: Erstellung, Zuweisung von Varianten, Sammeln von Events und Reporting.
Es ist nicht eine vollständige Preis-Engine (Steuerberechnung, Rechnungsstellung, Multiwährungs-Kataloge, Proration usw.). Stattdessen ist es das Kontrollpanel und die Tracking-Schicht, die Preistests sicher genug macht, um sie regelmäßig durchzuführen.
Ein Pricing-Experiment-Manager ist nur nützlich, wenn klar ist, was er tun wird — und was nicht. Ein enger Scope hält das Produkt einfach zu bedienen und sicher zu deployen, besonders wenn echter Umsatz betroffen ist.
Mindestens sollte eure Web-App einer nicht-technischen Person erlauben, ein Experiment Ende-zu-Ende durchzuführen:
Wenn ihr sonst nichts baut, baut diese Punkte gut — mit klaren Defaults und Guardrails.
Entscheidet früh, welche Formate ihr unterstützt, damit UI, Datenmodell und Zuweisungslogik konsistent bleiben:
Seid explizit, um Scope-Creep zu vermeiden, der das Tool zu einem fragilen, geschäftskritischen System macht:
Definiert Erfolg in operationellen Begriffen, nicht nur statistisch:
Eine Pricing-Experiment-App lebt oder stirbt am Datenmodell. Wenn ihr nicht zuverlässig beantworten könnt: „Welchen Preis hat dieser Kunde gesehen und wann?“, werden die Metriken laut und das Team verliert Vertrauen.
Beginnt mit einer kleinen Menge Kernobjekten, die abbilden, wie Pricing tatsächlich im Produkt funktioniert:
Verwendet stabile Identifier über Systeme hinweg (product_id, plan_id, customer_id). Vermeidet "sprechende" Keys — sie ändern sich.
Zeitfelder sind ebenso wichtig:
Erwägt außerdem effective_from / effective_to bei Price-Records, damit ihr Preise zu jedem Zeitpunkt rekonstruieren könnt.
Definiert Beziehungen explizit:
Praktisch bedeutet das: Ein Event sollte customer_id, experiment_id und variant_id tragen (oder joinbar sein). Wenn ihr nur customer_id speichert und die Zuweisung später nachschlagt, riskiert ihr falsche Joins, wenn Assignments sich geändert haben.
Preisexperimente brauchen eine revisionssichere Historie. Macht wichtige Datensätze append-only:
Dieser Ansatz hält Reporting konsistent und erleichtert Governance-Funktionen wie Audit-Logs.
Ein Pricing-Experiment-Manager braucht einen klaren Lifecycle, damit alle wissen, was editierbar ist, was gesperrt ist und was mit Kunden passiert, wenn sich der Experiment-Status ändert.
Draft → Scheduled → Running → Stopped → Analyzed → Archived
Um riskante Starts zu reduzieren, zwingt Required-Felder durch den Ablauf:
Für Pricing fügt optionale Gates für Finance und Legal/Compliance hinzu. Nur Approver dürfen Scheduled → Running überführen. Falls Overrides unterstützt werden (z. B. dringendes Rollback), protokolliert, wer übersteuert hat, warum und wann, im Audit-Log.
Wenn ein Experiment Stopped wird, definiert zwei explizite Verhaltensweisen:
Macht dies bei Stop zur Pflichtentscheidung, sodass das Team nicht ohne Kenntnis der Kundenwirkung stoppen kann.
Die richtige Zuweisung unterscheidet einen vertrauenswürdigen Preistest von verrauschten Ergebnissen. Eure App sollte es einfach machen zu definieren, wer einen Preis bekommt, und sicherstellen, dass diese Person ihn konsistent sieht.
Ein Kunde sollte dieselbe Variante über Sessions, Geräte (wenn möglich) und Reloads hinweg sehen. Das bedeutet: Zuweisung muss deterministisch sein: bei gleichem Assignment-Key und Experiment ist das Ergebnis immer dasselbe.
Gängige Ansätze:
(experiment_id + assignment_key) berechnen und auf eine Variante mappen.Viele Teams verwenden hash-basierte Zuweisung standardmäßig und speichern Assignments nur bei Bedarf (Supportfälle, Governance).
Eure App sollte mehrere Keys unterstützen, denn Pricing kann auf Benutzer- oder Account-Ebene wirken:
user_id nach Signup/Login.Dieser Upgrade-Pfad ist wichtig: wenn jemand anonym browsed und später ein Konto erstellt, müsst ihr entscheiden, ob seine ursprüngliche Variante beibehalten oder neu zugewiesen wird. Macht das als explizite Einstellung.
Unterstützt flexible Allokation:
Beim Ramping bleiben Assignments sticky: erhöhte Traffic-Anteile fügen neue Nutzer zum Experiment hinzu, ohne bestehende umzuschichten.
Gleichzeitige Tests können kollidieren. Baut Guardrails für:
Ein klares "Assignment-Preview"-Screen (für eine Beispiel-Benutzer/Account) hilft nicht-technischen Teams, Regeln vor Launch zu prüfen.
Preisexperimente scheitern meist an der Integrationsschicht — nicht weil die Experimentlogik falsch ist, sondern weil Produkt einen Preis zeigt und ein anderer berechnet wird. Eure Web-App sollte „was der Preis ist“ und „wie das Produkt ihn nutzt“ sehr explizit machen.
Behandelt Preisdefinition als Source of Truth (Variant-Preisregeln, Gültigkeitsdaten, Währung, Steuerbehandlung usw.). Behandelt Preislieferung als Mechanismus, um den gewählten Variant-Preis per API-Endpoint oder SDK abzurufen.
Diese Trennung hält das Experiment-Management sauber: Nicht-technische Teams editieren Definitionen, Engineers integrieren einen stabilen Delivery-Contract wie GET /pricing?sku=....
Zwei gängige Muster:
Praktisch: „client-side anzeigen, server-side verifizieren und berechnen", beide mit derselben Experiment-Zuweisung.
Varianten müssen dieselben Regeln verwenden für:
Speichert diese Regeln zusammen mit dem Preis, damit alle Varianten vergleichbar und finance-freundlich sind.
Wenn der Experiment-Service langsam oder ausgefallen ist, sollte euer Produkt einen sicheren Default-Preis zurückgeben (meist die aktuelle Baseline). Definiert Timeouts, Caching und eine klare "fail closed"-Policy, sodass Checkout nicht kaputtgeht — und loggt Fallbacks, um ihren Einfluss zu quantifizieren.
Preisexperimente leben oder sterben an Messung. Eure Web-App sollte es schwer machen, einfach "ship and hope" zu machen, indem sie klare Entscheidungsmetriken, saubere Events und eine konsistente Attribution verlangt, bevor ein Experiment startet.
Beginnt mit einer oder zwei Metriken, die ihr zur Entscheidung heranzieht. Häufig bei Pricing:
Eine Regel: Wenn Teams nach dem Test streiten, war die Entscheidungsmetrik wahrscheinlich nicht klar genug definiert.
Guardrails fangen Schäden auf, die ein höherer Preis verursachen kann, auch wenn kurzfristiger Umsatz gut aussieht:
Eure App kann Guardrails durch notwendige Schwellenwerte erzwingen (z. B. "Refund-Rate darf nicht um mehr als 0,3% steigen") und Verstöße prominent auf der Experiment-Seite anzeigen.
Mindestens muss euer Tracking stabile Identifier für Experiment und Variant auf jedem relevanten Event enthalten.
{
"event": "purchase_completed",
"timestamp": "2025-01-15T12:34:56Z",
"user_id": "u_123",
"experiment_id": "exp_earlybird_2025_01",
"variant_id": "v_price_29",
"currency": "USD",
"amount": 29.00
}
Macht diese Properties bei der Ingestion verpflichtend, nicht "Best Effort". Wenn ein Event ohne experiment_id/variant_id ankommt, route es in einen "unattributed" Bucket und flaggt Data-Quality-Probleme.
Pricing-Ergebnisse sind oft verzögert (Renewals, Upgrades, Churn). Definiert:
Das hält Teams auf einem Konsens darüber, wann ein Ergebnis vertrauenswürdig ist — und verhindert voreilige Entscheidungen.
Ein Pricing-Experiment-Tool funktioniert nur, wenn PMs, Marketer und Finance es ohne Engineering-Hilfe nutzen können. Die UI sollte drei Fragen schnell beantworten: Was läuft? Was ändert sich für Kunden? Was ist passiert und warum?
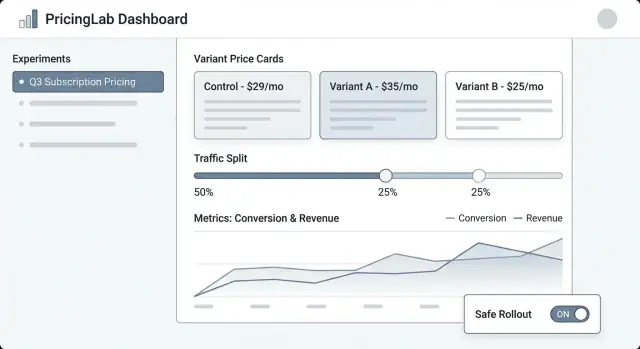
Experiment-Liste sollte sich wie ein Operations-Dashboard anfühlen. Zeigt: Name, Status (Draft/Scheduled/Running/Paused/Ended), Start/End-Daten, Traffic-Split, primäre Metrik und Owner. Fügt ein sichtbares "zuletzt aktualisiert von" und Zeitstempel hinzu, damit Leute dem Stand vertrauen.
Experiment-Detail ist die Homebase. Oben eine kompakte Zusammenfassung (Status, Daten, Audience, Split, primäre Metrik). Darunter Tabs wie Variants, Targeting, Metrics, Change log und Results.
Variant-Editor muss einfach und meinungsstark sein. Jede Variante als Zeile mit Preis (oder Preisregel), Währung, Abrechnungsperiode und einer Plain-English-Beschreibung (z. B. "Jährlich: $120 → $108"). Macht es schwer, eine live Variante versehentlich zu ändern, z. B. durch Bestätigungsdialoge.
Results-View sollte mit der Entscheidung beginnen, nicht nur mit Charts: "Variante B erhöhte die Checkout-Conversion um 2.1% (95% CI …)." Dann unterstützende Drilldowns und Filter anbieten.
Nutzt konsistente Status-Badges und zeigt eine Timeline wichtiger Daten. Stellt den Traffic-Split als Prozent und als kleine Balkengrafik dar. Fügt ein "Wer hat was geändert"-Panel hinzu, das Edits an Varianten, Targeting und Metriken listet.
Vor dem Start verlangt mindestens: eine primäre Metrik ausgewählt, mindestens zwei Varianten mit validen Preisen, ein Ramp-Plan (optional, empfohlen) und ein Rollback-Plan oder Fallback-Preis. Wenn etwas fehlt, zeigt interaktive Fehler: "Füge eine primäre Metrik hinzu, um Ergebnisse zu aktivieren".
Bietet sichere, prominente Aktionen: Pause, Stop, Ramp up (z. B. 10% → 25% → 50%) und Duplicate (Einstellungen in einen neuen Draft kopieren). Für riskante Aktionen Bestätigungen mit Zusammenfassung des Impacts.
Wenn ihr Workflows (Draft → Scheduled → Running) validieren wollt, bevor ihr voll baut, können Vibe-Coding-Plattformen wie Koder.ai helfen, intern schnell eine Web-App aus Specs zu generieren — dann iteriert ihr mit rollenbasierten Screens, Audit-Logs und einfachen Dashboards. Das ist nützlich für frühe Prototypen mit einer React-UI und Go/Postgres-Backend, das später exportiert und gehärtet werden kann.
Ein Pricing-Experiment-Dashboard sollte eine Frage schnell beantworten: „Sollen wir diesen Preis behalten, zurückrollen oder weiter lernen?“ Das beste Reporting ist nicht das Raffinierteste, sondern das Vertrauenswürdigste und Einfachste zu erklären.
Startet mit wenigen Trendcharts, die automatisch aktualisieren:
Unter den Charts eine Variante-Vergleichstabelle: Variantenname, Traffic-Anteil, Besucher, Käufe, Conversion-Rate, Umsatz pro Besucher und die Delta vs Control.
Für Konfidenz-Indikatoren vermeidet akademische Sprache. Verwendet Labels wie:
Ein Tooltip kann erklären, dass Konfidenz mit Stichprobengröße und Zeit wächst.
Pricing gewinnt oft insgesamt, versagt aber in wichtigen Gruppen. Macht Segment-Tabs einfach wechselbar:
Haltet die gleichen Metriken überall, damit Vergleiche konsistent sind.
Fügt leichte Alerts direkt im Dashboard hinzu:
Beim Auftreten eines Alerts zeigt das betroffene Fenster und einen Link zum Raw-Event-Status.
Macht Reporting portabel: CSV-Download für die aktuelle Ansicht (inkl. Segmente) und einen teilbaren internen Link zur Experiment-Report-Seite. Falls hilfreich, verlinkt einen kurzen Guide wie /blog/metric-guide, damit Stakeholder verstehen, was sie sehen, ohne ein Meeting zu brauchen.
Preisexperimente betreffen Umsatz, Kundenvertrauen und oft reguliertes Reporting. Ein simples Berechtigungsmodell und eine klare Audit-Historie reduzieren versehentliche Starts, endlose "Wer hat das geändert?"-Diskussionen und helfen, schneller mit weniger Rückabwicklungen zu deployen.
Haltet Rollen einfach zu erklären und schwer zu missbrauchen:
Wenn ihr mehrere Produkte/Regionen habt, scope Rollen pro Workspace (z. B. "EU Pricing"), damit ein Editor in einem Bereich keinen anderen beeinflusst.
Eure App sollte jede Änderung mit wer, was, wann protokollieren, idealerweise mit Before/After-Diffs. Mindest-Events:
Macht Logs durchsuchbar und exportierbar (CSV/JSON) und verlinkt sie direkt von der Experiment-Seite. Eine eigene /audit-log-Ansicht hilft Compliance-Teams.
Behandelt Kunden-Identifier und Umsatz standardmäßig als sensibel:
Fügt leichte Notizen pro Experiment hinzu: Hypothese, erwarteter Impact, Genehmigungsbegründung und ein "Warum wir gestoppt haben"-Summary. In sechs Monaten verhindern diese Notizen das Wiederholen gescheiterter Ideen und machen Reporting glaubwürdiger.
Preisexperimente scheitern subtil: ein 50/50 Split driftet zu 62/38, eine Kohorte sieht die falsche Währung oder Events kommen nie im Reporting an. Behandelt das Experiment-System wie ein Payment-Feature — validiert Verhalten, Daten und Failure-Modes bevor echte Kunden beteiligt werden.
Beginnt mit deterministischen Testfällen, um zu beweisen, dass die Zuweisungslogik stabil über Services und Releases ist. Verwendet fixe Inputs (Customer IDs, Experiment-Keys, Salt) und assertet, dass immer dieselbe Variante zurückkommt.
customer_id=123, experiment=pro_annual_price_v2 -> variant=B
customer_id=124, experiment=pro_annual_price_v2 -> variant=A
Testet dann Verteilung in großem Maßstab: generiert z. B. 1M synthetische Customer-IDs und prüft, dass die beobachtete Verteilung innerhalb enger Toleranzen bleibt (z. B. 50% ± 0.5%). Überprüft auch Edge-Cases wie Traffic-Caps (nur 10% enrolled) und Holdouts.
Hört nicht bei "Event fired" auf. Fügt einen automatisierten Flow hinzu, der eine Test-Zuweisung erstellt, ein Checkout/Purchase-Event triggert und verifiziert:
Führt das in Staging und in Production aus mit einem Test-Experiment, das auf interne Nutzer begrenzt ist.
Gebt QA und PMs ein einfaches "Preview"-Tool: Customer-ID (oder Session-ID) eingeben und die zugewiesene Variante und den exakten Preis sehen, der gerendert würde. Das fängt falsche Rundungen, falsche Währung, Steuer-Anzeige und "falscher Plan"-Fehler vor dem Launch.
Denkt an eine sichere interne Route wie /experiments/preview, die niemals reale Assignments verändert.
Probt die hässlichen Szenarien:
Wenn ihr nicht sicher beantworten könnt: "Was passiert, wenn X ausfällt?", seid ihr nicht bereit zu shippn.
Das Ausrollen eines Pricing-Experiment-Managers ist weniger "Screen shippen" als sicherstellen, dass ihr Blast Radius kontrolliert, Verhalten schnell beobachtet und sicher wiederherstellen könnt.
Startet mit einem Pfad, der zu eurer Confidence und Produkt-Constraints passt:
Behandelt Monitoring als Release-Requirement, nicht als "nice to have". Setzt Alerts für:
Erstellt schriftliche Runbooks für Ops und On-Call:
Wenn der Kernworkflow stabil ist, priorisiert Verbesserungen, die bessere Entscheidungen ermöglichen: erweitertes Targeting (Geo, Plan, Kundentyp), stärkere Stats und Guardrails sowie Integrationen (Data Warehouse, Billing, CRM). Wenn ihr Tiers/Packaging habt, überlegt, Experiment-Fähigkeiten auf /pricing zu dokumentieren, damit Teams wissen, was unterstützt wird.
Es ist ein internes Bedienfeld und eine Tracking-Ebene für Preistests. Es hilft Teams, Experimente zu definieren (Hypothese, Zielgruppe, Varianten), einen konsistenten Preis über alle Berührungspunkte auszuliefern, attributionstaugliche Ereignisse zu sammeln und Experimente sicher zu starten/pausieren/stoppen mit voller Auditierbarkeit.
Es ist bewusst nicht als komplettes Abrechnungssystem oder Steuer-Engine gedacht; es orchestriert Experimente rund um euren vorhandenen Preis-/Billing-Stack.
Ein praktisches MVP enthält:
Wenn diese Funktionen zuverlässig sind, könnt ihr später aufwändigere Targeting- und Reporting-Funktionen ergänzen.
Modelliert die Kernobjekte, die die Frage beantworten: „Welchen Preis hat dieser Kunde gesehen und wann?" Typischerweise:
Vermeidet mutable Änderungen an Schlüsselhistorie: Preise versionieren und Assignment-Einträge anhängen statt zu überschreiben.
Definiert einen Lebenszyklus wie Draft → Scheduled → Running → Stopped → Analyzed → Archived.
Sperrt risikoreiche Felder sobald ein Experiment "Running" ist (Varianten, Targeting, Split) und verlangt Validierungsschritte bevor man Zustände wechselt (Metriken gewählt, Tracking bestätigt, Rollback-Plan). Das verhindert Änderungen während des Tests, die Ergebnisse unbrauchbar machen und Kunden inkonsistente Erfahrungen geben.
Verwendet eine sticky Zuordnung, sodass derselbe Kunde möglichst über Sessions und Geräte hinweg dieselbe Variante sieht.
Gängige Muster:
(experiment_id + assignment_key) und Mapping in Variant-BucketsViele Teams nutzen Hash-First und speichern Zuweisungen nur bei Bedarf für Governance oder Support-Workflows.
Wählt den Key, der zur Pricing-Experience passt:
Wenn ihr anonym startet, legt eine explizite Regel für das "Identity Upgrade" beim Signup/Login fest (behalte die ursprüngliche Variante zur Kontinuität vs. neu zuweisen für saubere Identitätsregeln).
Behandelt "Stop" als zwei getrennte Entscheidungen:
Macht die Serving-Policy zur Pflichtentscheidung beim Stop, damit Teams die Kundenwirkung bestätigen müssen.
Sorgt dafür, dass dieselbe Variante sowohl für Anzeige als auch für Abrechnung verwendet wird:
Legt außerdem ein sicheres Fallback fest, wenn der Experiment-Service langsam oder down ist (meist Baseline-Preis) und loggt jeden Fallback zur Nachverfolgung.
Erzwingt ein kleines, konsistentes Event-Schema, wobei jedes relevante Event experiment_id und variant_id enthält.
Typischerweise definiert ihr:
Wenn ein Event ohne experiment-/variant-Felder ankommt, routet es in einen "unattributed" Bucket und markiert Data-Quality-Probleme.
Verwendet ein einfaches Rollenmodell und ein vollständiges Audit-Log:
Das reduziert versehentliche Launches und macht Prüfungen durch Finance/Compliance sowie spätere Retrospektiven einfacher.