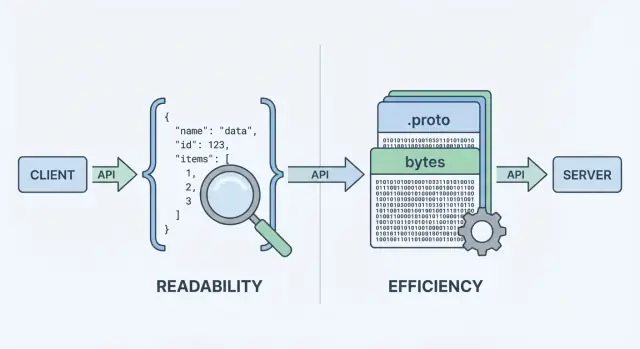
Was Protobuf und JSON sind (und warum sie wichtig sind)
Wenn Ihre API Daten sendet oder empfängt, braucht sie ein Datenformat — eine standardisierte Art, Informationen in Request- und Response-Bodies darzustellen. Dieses Format wird serialisiert (in Bytes verwandelt) für den Transport über das Netzwerk und auf der Gegenseite wieder deserialisiert in nutzbare Objekte auf Client und Server.
Zwei der häufigsten Optionen sind JSON und Protocol Buffers (Protobuf). Sie können dieselben Geschäftsobjekte darstellen (User, Bestellungen, Timestamps, Listen von Items), aber sie treffen unterschiedliche Kompromisse bei Performance, Nutzlastgröße und Entwickler-Workflow.
JSON: menschenlesbarer Text
JSON (JavaScript Object Notation) ist ein textbasiertes Format aus einfachen Strukturen wie Objekten und Arrays. Es ist beliebt für REST-APIs, weil es leicht lesbar ist, sich einfach protokollieren lässt und mit Tools wie curl und den Browser-DevTools einfach zu inspizieren ist.
Ein großer Grund für die weite Verbreitung von JSON: die meisten Sprachen unterstützen es exzellent, und man kann eine Antwort visuell sofort verstehen.
Protobuf ist ein binäres Serialisierungsformat, das von Google entwickelt wurde. Statt Text zu senden, überträgt es eine kompakte Binärrepräsentation, definiert durch ein Schema (eine .proto-Datei). Das Schema beschreibt Felder, Typen und ihre numerischen Tags.
Da es binär und schema-getrieben ist, erzeugt Protobuf in der Regel kleinere Nutzlasten und kann schneller geparst werden — das zählt besonders bei hohem Anfrageaufkommen, mobilen Netzen oder latenzsensitiven Diensten (häufig in gRPC-Setups, aber nicht darauf beschränkt).
Gleiche Daten, unterschiedliche Kompromisse
Wichtig ist, was Sie senden von wie es kodiert wird zu trennen. Ein „User“ mit id, name und email lässt sich sowohl in JSON als auch in Protobuf modellieren. Der Unterschied liegt in den Kosten, die Sie zahlen in:
- Nutzlastgröße (Text vs kompaktes Binär)
- CPU-Zeit für (De-)Serialisierung
- Debugging und Observability (lesbare Logs vs Binär-Tools)
- Kompatibilität und Evolution (informelle JSON-Konventionen vs durchgesetzte Schemata)
Es gibt keine Universalantwort. Für viele öffentliche APIs bleibt JSON der Standard wegen Zugänglichkeit und Flexibilität. Für interne Service-zu-Service-Kommunikation, performancekritische Systeme oder strikte Verträge kann Protobuf besser passen. Ziel dieses Leitfadens ist es, bei Entscheidungen die Constraints und nicht Ideologie zu berücksichtigen.
Wie API-Daten serialisiert und gesendet werden
Wenn eine API Daten zurückgibt, kann sie keine „Objekte“ direkt übers Netz schicken. Sie muss sie zuerst in einen Bytestrom verwandeln. Diese Umwandlung heißt Serialisierung — denken Sie daran als Verpacken Ihrer Daten. Auf der Gegenseite macht der Client das Gegenteil (Deserialisierung) und packt die Bytes wieder in nutzbare Datenstrukturen aus.
Ein kurzer Weg vom Server zum Client
Ein typischer Request/Response-Flow sieht so aus:
- Server baut eine Antwort in seinen eigenen In-Memory-Typen (Objekte/Structs/Klassen).\n2. Serializer kodiert diese Antwort in eine Nutzlast (JSON-Text oder Protobuf-Binär).\n3. Die Nutzlast wird als Bytes über HTTP/1.1, HTTP/2 oder HTTP/3 gesendet.\n4. Client empfängt Bytes und dekodiert sie in seine eigenen In-Memory-Typen.
Dieser „Encodierungs-Schritt“ ist, wo die Formatwahl wichtig wird. JSON-Encoding erzeugt lesbaren Text wie {\"id\":123,\"name\":\"Ava\"}. Protobuf-Encoding erzeugt kompakte Binärbytes, die ohne Tooling nicht menschenverständlich sind.
Weil jede Antwort verpackt und wieder ausgepackt werden muss, beeinflusst das Format:
- Bandbreite (Nutzlastgröße): Kleinere Nutzlasten senken Übertragungskosten, was auf mobilen Netzen und bei hohem Traffic hilft.\n- Latenz: Weniger Daten können schnellere Antworten bedeuten; schnelleres Kodieren/Dekodieren reduziert CPU-Zeit.\n- Entwickler-Workflow: JSON ist einfach inspectbar in DevTools und Logs; Protobuf benötigt oft generierte Typen und spezifische Dekodier-Tools.
API-Stil kann die Entscheidung beeinflussen
Ihr API-Stil neigt oft in eine Richtung:
- REST-Style JSON-APIs nutzen typischerweise JSON, weil es weit unterstützt wird und einfach mit
curl zu testen, zu loggen und zu inspizieren ist.\n- gRPC ist standardmäßig auf Protobuf ausgelegt. Es nutzt HTTP/2 und Code-Generierung, was gut mit stark typisierten Protobuf-Nachrichten harmoniert.
Sie können JSON mit gRPC verwenden (via Transcoding) oder Protobuf über plain HTTP senden, aber die Standard-Ökosystem-Ergonomie — Frameworks, Gateways, Client-Libs und Debug-Gewohnheiten — entscheidet oft, was sich im Alltag am besten betreiben lässt.
Nutzlastgröße und Geschwindigkeit: Was man üblicherweise gewinnt oder verliert
Wenn Leute protobuf vs json vergleichen, beginnen sie meist mit zwei Metriken: wie groß die Nutzlast ist und wie lange das (De-)Serialisieren dauert. Die Kurzfassung: JSON ist Text und tendenziell ausführlicher; Protobuf ist binär und meist kompakt.
Nutzlastgröße: kompaktes Binär vs lesbarer Text
JSON wiederholt Feldnamen und nutzt Text-Repräsentationen für Zahlen, Booleans und Struktur, daher werden oft mehr Bytes übertragen. Protobuf ersetzt Feldnamen durch numerische Tags und packt Werte effizient, was besonders bei großen Objekten, wiederholten Feldern und tief verschachtelten Daten zu deutlich kleineren Nutzlasten führen kann.
Allerdings kann Kompression die Lücke verkleinern. Mit gzip oder brotli komprimieren sich die wiederholten JSON-Schlüssel sehr gut, sodass Unterschiede in realen Deployments schrumpfen können. Protobuf lässt sich ebenfalls komprimieren, aber der relative Vorteil ist dann oft kleiner.
CPU-Kosten: Text parsen vs Binär dekodieren
JSON-Parser müssen tokenisieren und Text validieren, Strings in Zahlen umwandeln und Randfälle (Escapes, Whitespace, Unicode) behandeln. Protobuf-Decoding ist direkter: Tag lesen → typisierten Wert lesen. In vielen Diensten reduziert Protobuf CPU-Zeit und Garbage-Erzeugung, was unter Last die Tail-Latenz verbessern kann.
Netzwerkauswirkung: Mobil- und latenzarme Verbindungen
Auf Mobilnetzen oder in hochlatenzigen Umgebungen bedeuten weniger Bytes in der Regel schnellere Übertragungen und weniger Radio-Zeit (was auch Akku sparen kann). Wenn Ihre Antworten jedoch schon sehr klein sind, dominieren Handshake-Overhead, TLS und Serververarbeitung — dann ist die Formatwahl weniger sichtbar.
Wie Sie in Ihrem System benchmarken
Messen Sie mit Ihren echten Nutzdaten:
- Wählen Sie repräsentative Requests/Responses (klein, typisch, Worst-Case).\n- Vergleichen Sie: rohe Größe, komprimierte Größe (gzip/brotli), Encode/Decode-Zeit und End-to-End-Latenz.\n- Führen Sie Tests bei realistischer Konkurrenz aus und erfassen Sie p50/p95/p99.
So machen Sie die Debatte um API-Serialisierung zu datengetriebener Entscheidungsfindung für Ihre API.
Developer Experience: Lesbarkeit, Debugging und Logging
Hier gewinnt JSON oft standardmäßig. Sie können eine JSON-Anfrage/-Antwort nahezu überall inspizieren: in den Browser-DevTools, curl-Ausgaben, Postman, Reverse-Proxies und reinen Text-Logs. Wenn etwas schiefgeht, ist „Was haben wir tatsächlich gesendet?“ normalerweise per Copy/Paste erreichbar.
Protobuf dagegen ist kompakt und strikt, aber nicht menschenlesbar. Wenn Sie rohe Protobuf-Bytes protokollieren, sehen Sie Base64-Blobs oder unlesbare Binärdaten. Um die Nutzlast zu verstehen, brauchen Sie das richtige .proto-Schema und einen Decoder (z. B. protoc, sprachspezifische Tools oder die generierten Typen Ihres Services).
Debugging-Workflows in der Praxis
Mit JSON ist das Reproduzieren einfach: Nutzlast aus Logs kopieren, Secrets redigieren, mit curl wiederholen — und Sie haben meist einen minimalen Testfall.
Mit Protobuf debuggen Sie typischerweise so:
- die Binär-Payload (häufig base64-codiert) erfassen,\n- mit der korrekten Schema-Version dekodieren,\n- neu kodieren, um die Anfrage zu reprozdizieren.
Dieser zusätzliche Schritt ist handhabbar — vorausgesetzt, das Team hat einen reproduzierbaren Workflow.
Tipps, um Protobuf (und JSON) besser debugbar zu machen
Strukturiertes Logging hilft bei beiden Formaten. Protokollieren Sie Request-IDs, Methodennamen, User-/Account-IDs und Schlüsselfelder statt ganzer Bodies.
Für Protobuf speziell:
- Protokollieren Sie eine dekodierte, redigierte „Debug-Ansicht“ (z. B. JSON-Darstellung) neben der Binär-Payload, wenn es sicher ist.\n- Speichern Sie die Schema-Version oder Nachrichtentyp in Logs, damit nicht die Frage entsteht „Welche
.proto-Version war das?“\n- Fügen Sie ein kleines internes Skript (oder ein Make-Target) hinzu, das „diese Base64-Payload mit dem richtigen Schema dekodiert“ für On-Call-Fälle.
Für JSON: erwägen Sie, kanonisierte JSON-Ausgaben (stabile Key-Reihenfolgen) zu protokollieren, um Diffs und Incident-Timelines leichter lesbar zu machen.
Schema und Typsicherheit: Flexibilität vs Leitplanken
APIs bewegen nicht nur Daten — sie transportieren Bedeutung. Der größte Unterschied zwischen JSON und Protobuf ist, wie klar diese Bedeutung definiert und durchgesetzt ist.
JSON: flexibles Shape, flexible Interpretation
JSON ist standardmäßig „schema-less“: Sie können beliebige Objekte mit beliebigen Feldern senden, und viele Clients akzeptieren sie, solange sie vernünftig aussehen.
Diese Flexibilität ist anfangs praktisch, kann aber Fehler verbergen. Typische Probleme:
- Inkonsistente Felder:
userId in einer Antwort, user_id in einer anderen, oder fehlende Felder je nach Codepfad.\n- Stringly-typed Daten: Zahlen, Booleans oder Datumsangaben als Strings wie "42", "true" oder "2025-12-23" — einfach zu erzeugen, leicht zu missverstehen.\n- Mehrdeutige nulls: null kann „unbekannt“, „nicht gesetzt“ oder „absichtlich leer“ bedeuten, und unterschiedliche Clients interpretieren das unterschiedlich.
Sie können ein JSON-Schema oder OpenAPI-Spec hinzufügen, aber JSON selbst erzwingt das nicht.
Protobuf: ein expliziter Vertrag via .proto
Protobuf verlangt ein Schema in einer .proto-Datei. Ein Schema ist ein gemeinsamer Vertrag, der festlegt:
- welche Felder existieren,\n- welche Typen sie haben (string, integer, enum, message, etc.),\n- und welche Feldnummer jedes Feld auf dem Wire identifiziert.
Dieser Vertrag hilft, versehentliche Änderungen zu verhindern — z. B. eine Zahl in einen String zu verwandeln — weil der generierte Code bestimmte Typen erwartet.
Typensicherheits-Details, die wichtig sind
Bei Protobuf bleiben Zahlen Zahlen, Enums sind auf bekannte Werte begrenzt, und Timestamps werden typischerweise mit well-known types modelliert (statt ad-hoc-String-Formaten). „Nicht gesetzt“ ist auch klarer: in proto3 ist Abwesenheit unterscheidbar vom Default, wenn Sie optional-Felder oder Wrapper-Typen verwenden.
Wenn Ihre API auf präzise Typen und vorhersehbares Parsen zwischen Teams und Sprachen angewiesen ist, bietet Protobuf Leitplanken, die JSON meist durch Konventionen erreichen muss.
Versionierung und Schema-Evolution ohne Clients zu brechen
APIs entwickeln sich: Sie fügen Felder hinzu, ändern Verhalten und entfernen alte Teile. Ziel ist es, den Vertrag zu ändern, ohne Verbraucher zu überraschen.
Rückwärts- vs. Vorwärtskompatibilität (in einfachen Worten)
- Rückwärtskompatibel: neue Server können mit alten Clients sprechen. Alte Clients ignorieren Unbekanntes und funktionieren weiter.\n- Vorwärtskompatibel: neue Clients können mit alten Servern sprechen. Neue Clients können fehlende Felder handhaben und auf Defaults zurückfallen.
Ein guter Evolutionsansatz zielt auf beides ab, aber Rückwärtskompatibilität ist meist die Mindestanforderung.
Protobuf: Feldnummern sind die eigentliche Identität
In Protobuf hat jedes Feld eine Nummer (z. B. email = 3). Diese Nummer — nicht der Feldname — kommt auf das Wire. Namen sind vor allem für Menschen und generierten Code wichtig.
Deshalb:
- Sichere Änderungen (gewöhnlich):\n - Neue optionale Felder mit neuen, nie genutzten Nummern hinzufügen.\n - Neue Enum-Werte hinzufügen (idealerweise ohne bestehende umzunummerieren).\n - Ein Feld deprecaten, aber die Nummer reservieren.\n
- Riskante Änderungen (oft brechend):\n - Ein Feldnummer wiederverwenden für eine andere Bedeutung oder einen anderen Typ.\n - Den Typ eines Felds inkompatibel ändern (z. B. string → int).\n - Ein Feld entfernen, ohne seine Nummer zu reservieren (spätere Wiederverwendung könnte Bedeutung korrupt machen).\n - Umbenennen ist „auf dem Wire“ sicher, kann jedoch generierten Code und Annahmen brechen.
Beste Praxis: verwenden Sie reserved für alte Nummern/Namen und führen Sie ein Changelog.
JSON: Versionierung durch Konvention und Disziplin
JSON hat kein eingebautes Schema, daher hängt Kompatibilität von Ihren Mustern ab:
- Bevorzugen Sie additive Änderungen: neue Felder hinzufügen statt bestehende zu ändern.\n- Behandeln Sie unbekannte Felder als ignorierbar und fehlende Felder als „vernünftiges Default“.\n- Vermeiden Sie Typänderungen (z. B. number → string). Falls nötig, führen Sie ein neues Feld ein.
Deprecations und klare Richtlinien
Dokumentieren Sie Deprecations früh: wann ein Feld entfernt wird, wie lange es unterstützt bleibt und was es ersetzt. Veröffentlichen Sie eine einfache Versionierungs-Policy (z. B. „additive Änderungen sind non-breaking; Entfernen erfordert Major-Version“) und halten Sie sich daran.
Die Wahl zwischen JSON und Protobuf hängt oft davon ab, wo Ihre API laufen muss — und was Ihr Team pflegen möchte.
Browser vs Server: der „Default“-Vorteil von JSON
JSON ist faktisch universell: jeder Browser und jedes Backend-Runtime kann es parsen, ohne zusätzliche Abhängigkeiten. In einer Web-App ist fetch() + JSON.parse() der Standard, und Proxies, API-Gateways und Observability-Tools „verstehen“ JSON oft von Haus aus.
Protobuf läuft auch im Browser, ist aber kein Null-Kosten-Default. Sie fügen typischerweise eine Protobuf-Library (oder generierten JS/TS-Code) hinzu, managen Bundlesize und entscheiden, ob Sie Protobuf über HTTP-Endpunkte senden, die Ihre Browser-Tools leicht inspizieren können.
Mobile- und Backend-SDKs: hier glänzt Protobuf
Auf iOS/Android und in Backend-Sprachen (Go, Java, Kotlin, C#, Python etc.) ist Protobuf-Support ausgereift. Protobuf geht davon aus, dass Sie plattformspezifische Bibliotheken nutzen und üblicherweise Code aus .proto-Dateien generieren.
Code-Generierung bringt echte Vorteile:
- Typisierte Modelle und Enums, mit früheren Fehlern, wenn Clients vom Vertrag abweichen\n- Schnellere Serialisierungs-Libraries und konsistente Datenformen zwischen Services
Sie bringt auch Kosten mit sich:
- Build-Schritte (Code-Generierung in CI, synchron gehaltene generierte Artefakte)\n- Repo-/Prozess-Komplexität (gemeinsame
.proto-Pakete veröffentlichen, Version-Pinning)
gRPC: starkes Ökosystem, einschränkende Annahmen
Protobuf ist eng mit gRPC verbunden, welches eine vollständige Tooling-Story liefert: Service-Definitionen, Client-Stubs, Streaming und Interceptors. Wenn Sie gRPC in Betracht ziehen, ist Protobuf die natürliche Wahl.
Wenn Sie eine traditionelle JSON-REST-API bauen, bleibt das Werkzeug-Ökosystem (Browser-DevTools, curl-freundliches Debugging, generische Gateways) einfacher — besonders für öffentliche APIs und schnelle Integrationen.
Prototyping beider Optionen ohne frühe Bindung
Wenn Sie die API-Fläche noch erkunden, kann es helfen, schnell in beiden Stilen zu prototypen, bevor Sie standardisieren. Zum Beispiel erstellen Teams oft eine JSON-REST-API für breite Kompatibilität und einen internen gRPC/Protobuf-Service für Effizienz und benchmarken dann reale Nutzdaten, bevor sie sich festlegen. Wenn Sie Werkzeuge zur Generierung kompletter Stacks nutzen, ist iteratives Ändern von Verträgen praktikabel, ohne eine teure Refactor-Phase zu erzwingen.
Operative Passung: Caching, Gateways und Observability
Die Wahl zwischen JSON und Protobuf betrifft nicht nur Nutzlastgröße oder Geschwindigkeit. Sie beeinflusst auch, wie gut Ihre API zu Caching-Layern, Gateways und den Tools passt, auf die Ihr Team bei Incidents vertraut.
Caching und CDNs
Die meisten HTTP-Caching-Infrastrukturen (Browser-Caches, Reverse-Proxies, CDNs) sind um HTTP-Semantik optimiert, nicht um ein bestimmtes Body-Format. Ein CDN kann beliebige Bytes cachen, solange die Antwort cachebar ist.
Viele Teams erwarten jedoch HTTP/JSON am Edge, weil es leicht zu inspizieren und zu debuggen ist. Mit Protobuf funktioniert Caching weiterhin, aber Sie sollten bewusst sein über:
- Cache-Keys (URL, Query-Parameter und besonders
Vary)\n- Klare Cacheability-Header (Cache-Control, ETag, Last-Modified)\n- Vermeidung versehentlicher Cache-Fragmentierung bei Unterstützung mehrerer Formate
Content Negotiation (Content-Type und Accept)
Wenn Sie sowohl JSON als auch Protobuf unterstützen, nutzen Sie Content-Negotiation:
- Clients senden
Accept: application/json oder Accept: application/x-protobuf\n- Server antworten mit dem passenden Content-Type
Stellen Sie sicher, dass Caches Vary: Accept verstehen, sonst kann ein Cache eine JSON-Antwort speichern und sie an einen Protobuf-Client ausliefern (oder umgekehrt).
Gateways, Proxies und Observability
API-Gateways, WAFs, Request/Response-Transformer und Observability-Tools gehen oft von JSON-Bodies aus für:
- Request-Validierung und Schema-Checks\n- Feldweises Logging und Redaction\n- Metriken, die aus Payload-Feldern abgeleitet werden\n- Debugging in Dashboards und Trace-Viewern
Binäres Protobuf kann diese Features einschränken, sofern Ihr Tooling nicht Protobuf-aware ist (oder Sie Dekodier-Schritte hinzufügen).
Praktische Empfehlung für gemischte Umgebungen
Ein verbreitetes Muster ist JSON an den Rändern, Protobuf innen:
- Öffentliche REST-Endpunkte: JSON für Kompatibilität und einfachere Operations\n- Interne Service-zu-Service-Aufrufe: Protobuf (oft via gRPC) für Effizienz
So bleiben externe Integrationen simpel, während Sie Protobufs Performancevorteile dort nutzen, wo Sie beide Enden kontrollieren.
Sicherheits- und Zuverlässigkeitsüberlegungen
Die Entscheidung JSON oder Protobuf ändert, wie Daten kodiert und geparst werden — aber sie ersetzt nicht grundlegende Sicherheitsanforderungen wie Authentifizierung, Verschlüsselung, Autorisierung und serverseitige Validierung. Ein schneller Serializer rettet keine API, die ungeprüfte Eingaben akzeptiert.
Es ist verlockend, Protobuf als „sicherer“ zu sehen, weil es binär und weniger lesbar ist. Das ist jedoch keine Sicherheitsstrategie. Angreifer benötigen Ihre Nutzlasten nicht menschenlesbar — sie brauchen nur den Endpoint. Wenn die API sensible Felder preisgibt, ungültige Zustände akzeptiert oder schwache Auth hat, ändert das Format nichts daran.
Verschlüsseln Sie den Transport (TLS), erzwingen Sie Authorisierung, validieren Sie Eingaben und protokollieren Sie sicher — egal ob JSON REST API oder grpc protobuf.
Angriffsfläche: Payloads, Parser und Validierung
Beide Formate teilen gemeinsame Risiken:
- Übergroße Payloads: Große JSON-Dokumente oder riesige Protobuf-Nachrichten können Memory-Pressure, langsames Parsing oder DoS auslösen.\n- Parser-Bugs: Jeder Parser ist Code und kann Schwachstellen haben. Das Risiko ist eher welche Bibliotheken Sie verwenden und ob sie aktuell sind, als „JSON vs Protobuf“.\n- Lücken in Schema-Validierung: JSON ist flexibel und akzeptiert eventuell unerwartete Felder oder Typen, sofern Sie nicht validieren. Protobuf fügt Typgrenzen hinzu, aber semantisch ungültige Daten (z. B. negative Mengen) müssen Sie trotzdem validieren.
Zuverlässigkeit: Limits, Timeouts und Striktheit
Um APIs unter Last und Missbrauch zuverlässig zu halten, wenden Sie dieselben Leitplanken an beide Formate an:
- Setzen Sie maximale Request-Größe und maximale Message-Größe (inkl. Dekomprimierter Größe).\n- Verwenden Sie Timeouts und Cancellation, um Ressourcenbindung durch langsame Clients oder Parser zu vermeiden.\n- Bevorzugen Sie strikte Validierung: lehnen Sie fehlende geschäftsrelevante Felder, ungültige Bereiche und unbekannte Enum-Werte ab, wo sinnvoll.\n- Vorsicht beim Logging: JSON ist leicht zu inspizieren, aber beide Formate können versehentlich Geheimnisse offenlegen, wenn Roh-Payloads protokolliert werden.
Fazit: „Binär vs Text“ betrifft vor allem Performance und Ergonomie. Sicherheit und Zuverlässigkeit entstehen durch konsistente Limits, aktuelle Abhängigkeiten und explizite Validierung — unabhängig vom Serializer.
Wann JSON wählen vs. Wann Protobuf wählen
Die Wahl ist weniger eine Frage, welches Format „besser“ ist, als was Ihre API optimieren muss: Menschliche Zugänglichkeit und Reichweite oder Effizienz und strikte Verträge.
Wann JSON die Standardwahl ist
JSON ist meist die sichere Default-Wahl, wenn Sie breite Kompatibilität und einfaches Troubleshooting brauchen.
Typische Szenarien:
- Öffentliche APIs, bei denen Sie die Clients nicht kontrollieren (Partner, Dritte, unbekannte Tools)\n- Browser- und Web-Clients (native JSON-Unterstützung, einfache Inspektion in DevTools)\n- Schnelles Iterieren in frühen Produktphasen (weniger Zeremonie, einfachere Payloads)\n- Debugging-first Workflows (Copy/Paste-Requests, lesbare Logs, schnelles cURL-Testing)\n- REST-Endpunkte, die weit gecached oder proxied werden (häufige Gateway-Unterstützung)
Wann Protobuf glänzt
Protobuf gewinnt typischerweise, wenn Performance und Konsistenz wichtiger sind als Lesbarkeit.
Typische Szenarien:
- Hoher Durchsatz bei APIs, wo Bandbreite Geld kostet oder Sie in großem Maßstab operieren\n- Viele kleine Calls (chatty Services), wo Serialisierungs-Overhead ins Gewicht fällt\n- Interne Microservices, bei denen Sie beide Seiten kontrollieren und Schemata durchsetzen können\n- gRPC-basierte Systeme (Protobuf ist natürliche Wahl und ermöglicht starkes Tooling)\n- Mobile/Edge-Umgebungen, wo kleinere Payloads Latenz und Akkuverbrauch verbessern
Entscheidungsfragen
Nutzen Sie diese Fragen, um die Wahl einzugrenzen:
- Wer konsumiert die API? Externe/public Clients tendieren zu JSON.\n- Kontrollieren Sie alle Clients und Deployments? Wenn ja, ist Protobuf leichter einzuführen.\n- Ist Performance ein echter Engpass? Messen: p95 Latenz, CPU und Egress-Kosten.\n- Wie wichtig sind strikte Typen und Schema-Verträge? Protobuf bietet stärkere Leitplanken.\n- Ist Ihr Tooling reif genug? Berücksichtigen Sie Code-Generierung, CI-Checks und Onboarding.
Wenn Sie unschlüssig sind, ist „JSON an der Kante, Protobuf innen“ oft ein pragmatischer Kompromiss.
Migrationsstrategien: Wechsel zwischen JSON und Protobuf
Migration ist weniger ein kompletter Rewrite als riskominimierende Schritte für Konsumenten. Sicherste Ansätze halten die API während der Transition nutzbar und rollback-freundlich.
1) Klein anfangen: ein Endpoint oder ein interner Service
Wählen Sie eine risikoarme Fläche — typischerweise ein interner Service-zu-Service-Call oder ein einzelner read-only Endpoint. So validieren Sie Schema, generierte Clients und Observability-Änderungen, ohne die ganze API auf einmal umzubauen.
Ein praktischer erster Schritt: eine Protobuf-Repräsentation für ein bestehendes Resource hinzufügen und die JSON-Form beibehalten. So finden Sie schnell uneindeutige Stellen (null vs missing, number vs string, Datumsformate) und können das Schema schärfen.
2) JSON und Protobuf parallel betreiben (vorübergehend)
Für externe APIs ist Dual-Support meist der schonendste Pfad:
- Format über
Content-Type und Accept aushandeln.\n- Falls Verhandlung toolbedingt schwierig ist, einen separaten Endpunkt (z. B. /v2/...) anbieten.
Stellen Sie sicher, dass beide Formate aus derselben Source-of-Truth erzeugt werden, um Drift zu vermeiden.
3) Tests wie bei Produktänderungen planen
Planen Sie für:
- Kompatibilitätstests: alte Clients gegen neue Server, neue Clients gegen alte Server.\n- Contract-Tests: erforderliche Felder, Default-Verhalten und Fehlerantworten validieren.\n- Benchmarks: messen Sie Nutzlastgröße, CPU und Latenz (inkl. Kompression und TLS), nicht nur reine „Wire-Speed“.
4) Schema dokumentieren und Beispiele liefern
Veröffentlichen Sie .proto-Dateien, Feldkommentare und konkrete Request-/Response-Beispiele (JSON und Protobuf), damit Konsumenten prüfen können, ob sie die Daten korrekt interpretieren. Ein kurzes „Migration Guide“ und Changelog reduziert Support-Aufwand und beschleunigt Adoption.
Praktische Best Practices und eine kurze Checkliste
Die Wahl zwischen JSON und Protobuf ist oft pragmatisch und hängt von Traffic, Clients und operativen Constraints ab. Der verlässlichste Weg ist messen, Entscheidungen dokumentieren und API-Änderungen langweilig halten.
Vor dem Optimieren messen
Führen Sie ein kleines Experiment auf repräsentativen Endpunkten durch.
Tracken Sie:
- Nutzlastgröße (Median und p95)\n- End-to-End-Latenz (Client → Server → Client)\n- CPU und Speicher auf Services, die (De-)Serialisierung durchführen\n- Fehlerquoten und Timeouts
Machen Sie das in Staging mit produktähnlichen Daten, dann validieren Sie in Produktion mit einem kleinen Traffic-Slice.
Schemata und Verträge vorhersehbar halten
Ob mittels JSON Schema/OpenAPI oder .proto-Dateien:
- Konsistente Namenskonventionen über Endpunkte und Felder hinweg verwenden.\n- Klare Defaults definieren und dokumentieren. „Fehlend“ vs „leer“ sollte keine Überraschung sein.\n- Additive Änderungen bevorzugen: neue optionale Felder statt Bedeutungsänderungen.\n- Felder deprecaten mit Angaben und Migrationshinweisen; behalten Sie deprecated Felder solange, bis Clients migriert sind.
Developer Experience wichtig nehmen
Auch wenn Sie Protobuf für Performance wählen, machen Sie Ihre Docs freundlich:
- Fügen Sie Beispiel-Requests/Responses bei (Happy Path und übliche Fehler).\n- Bieten Sie Copy-Paste-Client-Snippets für gängige Sprachen.\n- Dokumentieren Sie, wie Payloads in Logs oder mit Tools zu inspizieren sind.
Wenn Sie Docs oder SDK-Guides pflegen, verlinken Sie klar (zum Beispiel: /docs und /blog). Wenn Pricing oder Nutzungslimits Formatentscheidungen beeinflussen, machen Sie das ebenfalls sichtbar (/pricing).
Kurze Checkliste