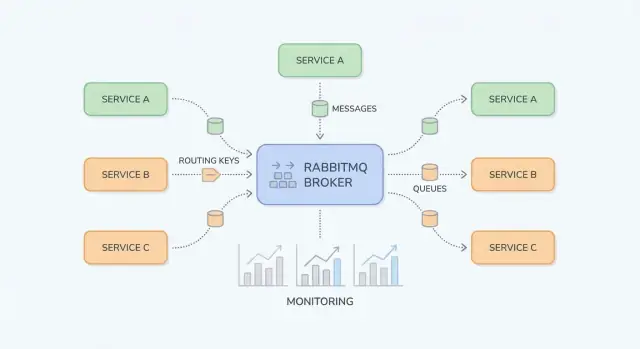
Warum RabbitMQ für Anwendungsteams wichtig ist
RabbitMQ ist ein Nachrichtenbroker: Er steht zwischen Teilen Ihres Systems und transportiert zuverlässig "Arbeit" (Nachrichten) von Produzenten zu Konsumenten. Anwendungsteams greifen häufig darauf zurück, wenn direkte synchrone Aufrufe (Service-zu-Service-HTTP, gemeinsame Datenbanken, Cron-Jobs) fragile Abhängigkeiten, ungleichmäßige Last und schwer zu debuggende Fehlerketten erzeugen.
Welche Probleme RabbitMQ löst
Verkehrsspitzen und ungleichmäßige Lasten. Wenn Ihre App in kurzer Zeit 10× mehr Anmeldungen oder Bestellungen erhält, kann das sofortige Verarbeiten alles nach unten überlasten. Mit RabbitMQ legen Produzenten Aufgaben schnell in eine Queue, und Konsumenten arbeiten sie in kontrolliertem Tempo ab.
Enge Kopplung zwischen Services. Wenn Service A Service B aufrufen und warten muss, propagieren Fehler und Latenz. Messaging entkoppelt: A veröffentlicht eine Nachricht und macht weiter; B verarbeitet sie, wenn es verfügbar ist.
Sichereres Fehlerhandling. Nicht jeder Fehler muss als sichtbarer Fehler für den Nutzer enden. RabbitMQ hilft beim Hinter-den-Szenen-Retry, isoliert "poison"-Nachrichten und verhindert, dass Arbeit bei temporären Ausfällen verloren geht.
Typische Ergebnisse für Teams
Teams erreichen meist gleichmäßigere Lasten (Spitzen puffern), entkoppelte Services (weniger Laufzeitabhängigkeiten) und kontrollierte Retries (weniger manuelle Nachbearbeitung). Ebenso wichtig: Es wird einfacher zu verstehen, wo Arbeit hängt — beim Produzenten, in einer Queue oder im Konsumenten.
Was dieser Leitfaden abdeckt (und was nicht)
Dieser Leitfaden konzentriert sich auf praktisches RabbitMQ für Anwendungsteams: Kernkonzepte, gebräuchliche Muster (pub/sub, Work-Queues, Retries und Dead-Letter-Queues) sowie operative Aspekte (Sicherheit, Skalierung, Observability, Troubleshooting).
Er ist nicht als vollständige AMQP-Spezifikation oder tiefgehende Dokumentation zu jedem RabbitMQ-Plugin gedacht. Ziel ist, Ihnen zu helfen, Nachrichtenflüsse zu entwerfen, die in realen Systemen wartbar bleiben.
Kurzes Glossar
- Producer: eine App-Komponente, die Nachrichten sendet.
- Consumer: eine App-Komponente, die Nachrichten empfängt und verarbeitet.
- Queue: ein Puffer, der Nachrichten hält, bis ein Consumer sie abarbeitet.
- Exchange: der Einstiegspunkt, der Nachrichten an eine oder mehrere Queues routet.
- Routing key: ein Label, das Exchanges zur Entscheidungsfindung nutzt, wohin eine Nachricht gehen soll.
RabbitMQ-Grundlagen: Was es ist und wann man es benutzt
RabbitMQ ist ein Nachrichtenbroker, der Nachrichten zwischen Teilen Ihres Systems routet, sodass Produzenten Arbeit abgeben und Konsumenten sie verarbeiten können, wenn sie bereit sind.
AMQP-Messaging vs direkte HTTP-Aufrufe
Bei einem direkten HTTP-Aufruf schickt Service A eine Anfrage an Service B und wartet meist auf eine Antwort. Ist Service B langsam oder down, schlägt Service A fehl oder blockiert, und Zeitüberschreitungen, Retries und Backpressure müssen bei jedem Caller gehandhabt werden.
Mit RabbitMQ (häufig via AMQP) veröffentlicht Service A eine Nachricht an den Broker. RabbitMQ speichert und routet sie zu den richtigen Queue(s), und Service B konsumiert asynchron. Der wesentliche Unterschied ist, dass Sie über eine dauerhafte Zwischenschicht kommunizieren, die Spitzen puffert und ungleichmäßige Lasten glättet.
Wann Messaging passt (und wann nicht)
Messaging passt, wenn Sie:
- Services/Teams entkoppeln wollen, damit sie unabhängig deployen und skalieren können.
- Asynchrone Arbeit benötigen (E-Mail, PDF-Generierung, Betrugsprüfungen), ohne eine Nutzeranfrage zu blockieren.
- Bursty Traffic erwarten und Spitzen mit Queues abfangen möchten.
- Zuverlässige Zustellung mit Acknowledgements, Retries und Dead-Letter-Queues brauchen.
Messaging ist jedoch ungeeignet, wenn Sie:
- Wirklich eine sofortige Antwort benötigen (z. B. "ist dieses Passwort gültig?").
- Einfache synchrone Lesezugriffe haben, bei denen ein direkter Aufruf klarer und leichter zu debuggen ist.
- Keine Strategie für Versionierung, Retries und Monitoring haben — dann verlagern Sie Komplexität, statt sie zu reduzieren.
Request/Response vs Async-Workflow (einfaches Beispiel)
Synchron (HTTP):
Ein Checkout-Service ruft per HTTP einen Invoicing-Service auf: "Create invoice." Der Nutzer wartet, bis die Rechnung erstellt ist. Ist die Rechnungsstellung langsam oder down, steigt die Checkout-Latenz oder der Checkout schlägt fehl.
Asynchron (RabbitMQ):
Der Checkout veröffentlicht invoice.requested mit der Bestell-ID. Der Nutzer erhält sofort eine Bestätigung, dass die Bestellung eingegangen ist. Invoicing konsumiert die Nachricht, erstellt die Rechnung und veröffentlicht invoice.created für E-Mail/Notifications. Jeder Schritt kann unabhängig retried werden — temporäre Ausfälle brechen den Flow nicht automatisch.
Kernbausteine: Exchanges, Queues und Routing
RabbitMQ lässt sich leichter verstehen, wenn Sie "wo Nachrichten veröffentlicht werden" von "wo Nachrichten gespeichert werden" trennen. Produzenten veröffentlichen an Exchanges; Exchanges routen zu Queues; Konsumenten lesen aus Queues.
Exchanges: wie RabbitMQ entscheidet, wohin eine Nachricht geht
Ein Exchange speichert Nachrichten nicht. Er bewertet Regeln und leitet Nachrichten an eine oder mehrere Queues weiter.
- Direct Exchange: routet per exaktem Routing-Key. Nützlich, wenn Sie klare, explizite Ziele wollen (z. B.
billing oder email).
- Topic Exchange: routet mit Mustern im Routing-Key. Gut für flexibles Pub/Sub und "auf eine Kategorie abonnieren".
- Fanout Exchange: broadcastet an alle gebundenen Queues und ignoriert Routing-Keys. Gut, wenn jeder Konsument jedes Event bekommen soll (z. B. Cache-Invalidierung).
- Headers Exchange: routet anhand von Nachrichten-Headern statt Routing-Key. Nützlich, wenn die Weiterleitung von mehreren Attributen abhängt (z. B.
region=eu UND tier=premium), aber nur für Spezialfälle—es ist schwerer zu überblicken.
Queues und Bindings: wie Nachrichten am richtigen Ort landen
Eine Queue ist der Ort, an dem Nachrichten sitzen, bis ein Consumer sie abarbeitet. Eine Queue kann einen oder viele Konsumenten haben (competing consumers), und Nachrichten werden typischerweise jeweils einem Consumer zugestellt.
Ein Binding verbindet einen Exchange mit einer Queue und definiert die Routing-Regel. Denken Sie: „Wenn eine Nachricht Exchange X mit Routing-Key Y trifft, liefere sie an Queue Q.“ Sie können mehrere Queues an dasselbe Exchange binden (pub/sub) oder eine Queue mehrfach für verschiedene Routing-Keys binden.
Routing-Keys und Muster (Topic Exchanges)
Bei Direct Exchanges ist Routing exakt. Bei Topic Exchanges sehen Routing-Keys wie punktgetrennte Wörter aus, z. B.: orders.created, orders.eu.refunded.
Bindings können Wildcards enthalten:
* passt genau auf ein Wort (z. B. orders.* matched orders.created).# passt auf null oder mehrere Wörter (z. B. orders.# matched orders.created und orders.eu.refunded).
So können Sie neue Konsumenten hinzufügen, ohne Produzenten zu ändern — erstellen Sie einfach eine neue Queue und binden Sie sie mit dem benötigten Muster.
Message-Acknowledgements: ack, nack, requeue
Nachdem RabbitMQ eine Nachricht zugestellt hat, meldet der Konsument das Ergebnis:
- ack: „Erfolgreich verarbeitet.“ RabbitMQ entfernt die Nachricht aus der Queue.
- nack (oder reject): „Fehlgeschlagen.“ Sie können wählen, die Nachricht zu verwerfen oder requeue.
- requeue: legt die Nachricht zurück, damit sie erneut versucht wird (oft sofort).
Vorsicht bei Requeue: Eine Nachricht, die immer fehlschlägt, kann endlos schleifen und die Queue blockieren. Viele Teams koppeln nacks mit einer Retry-Strategie und einer Dead-Letter-Queue (weiter unten beschrieben), sodass Fehler vorhersehbar gehandhabt werden.
Häufige Anwendungsfälle in realen Applikationen
RabbitMQ eignet sich, wenn Sie Arbeit oder Benachrichtigungen zwischen Teilen Ihres Systems bewegen wollen, ohne alles an einen langsamen Schritt zu binden. Nachfolgend praktische Muster aus dem Alltag.
Publish/Subscribe-Benachrichtigungen (fanout/topic)
Wenn mehrere Konsumenten auf dasselbe Ereignis reagieren sollen — ohne dass der Publisher weiß, wer sie sind — ist Pub/Sub passend.
Beispiel: Aktualisiert ein Nutzer sein Profil, möchten Sie Indexierung für Suche, Analytics und CRM-Sync parallel benachrichtigen. Mit einem fanout-Exchange broadcasten Sie an alle gebundenen Queues; mit einem topic-Exchange routen Sie selektiv (z. B. user.updated, user.deleted). Das vermeidet enge Kopplung und erlaubt es Teams, später neue Subscriber hinzuzufügen, ohne den Producer zu ändern.
Work-Queues für Hintergrundjobs
Wenn eine Aufgabe Zeit braucht, legen Sie sie in eine Queue und lassen Worker sie asynchron abarbeiten:
- Bild-/Videoverarbeitung
- Versand von Transaktions-E-Mails
- Erstellen von PDFs oder Reports
- Import/Export von Daten
So bleiben Web-Requests schnell und Sie können Worker unabhängig skalieren. Die Queue ist Ihre "To-Do-Liste"; die Anzahl der Worker ist Ihr "Durchsatz-Knopf".
Ereignisgetriebene Integration zwischen Services
Viele Workflows überschreiten Service-Grenzen: order → billing → shipping ist das klassische Beispiel. Statt dass ein Service den nächsten blockierend aufruft, veröffentlicht jeder Service ein Event nach Abschluss seines Schritts. Downstream-Services konsumieren Events und setzen den Workflow fort.
Das erhöht die Resilienz (ein temporärer Ausfall im Shipping bricht den Checkout nicht) und macht Zuständigkeiten klarer: Jeder Service reagiert nur auf die Events, die ihn interessieren.
Brücke zu langsamen oder unzuverlässigen Abhängigkeiten
RabbitMQ puffert zwischen Ihrer App und Abhängigkeiten, die langsam oder fehlerhaft sein können (Third-Party-APIs, Legacy-Systeme, Batch-Datenbanken). Sie enqueuen Anfragen schnell und verarbeiten sie mit kontrollierten Retries. Wenn die Abhängigkeit down ist, sammelt sich Arbeit sicher an und wird später abgearbeitet — statt dass Zeitüberschreitungen Ihre gesamte Anwendung beeinträchtigen.
Wenn Sie Queues schrittweise einführen möchten, ist ein kleines "async outbox" oder eine einzelne Background-Job-Queue ein guter erster Schritt (siehe /blog/next-steps-rollout-plan).
Nachrichtenflüsse entwerfen, die wartbar bleiben
Ein RabbitMQ-Setup ist angenehm, wenn Routen vorhersehbar sind, Namen konsistent gewählt werden und Payloads sich weiterentwickeln können, ohne ältere Konsumenten zu brechen. Bevor Sie eine neue Queue hinzufügen, stellen Sie sicher, dass die "Geschichte" einer Nachricht offensichtlich ist: wo sie entsteht, wie sie geroutet wird und wie ein Kollege sie end-to-end debuggt.
Wählen Sie den Exchange-Typ entsprechend Ihrem Routing-Bedarf
Die richtige Wahl verringert Spezialfälle und überraschende Fan-Outs:
- Direct Exchange: wenn ein Routing-Key zu einer spezifischen Queue gehört (z. B.
billing.invoice.created).
- Topic Exchange: für flexibles Pub/Sub mit Mustern (z. B.
billing.*.created, *.invoice.*). Häufig die beste Wahl für wartbare Ereignis-Weiterleitungen.
- Fanout Exchange: wenn jeder Konsument jede Nachricht erhalten soll (seltener für Business-Events; eher für Broadcast-Signale).
Faustregel: Wenn Sie komplexe Routing-Logik im Code „erfinden“, gehört sie oft in ein topic exchange-Muster.
Grundlagen des Nachrichtenschemas: Versionierung und Abwärtskompatibilität
Behandeln Sie Message-Bodies wie öffentliche APIs. Nutzen Sie klare Versionierung (z. B. ein Top-Level-Feld schema_version: 2) und streben Sie Abwärtskompatibilität an:
- Felder hinzufügen; nicht umbenennen/entfernen.
- Bevorzugen Sie optionale Felder mit sicheren Defaults.
- Ist ein Breaking Change unumgänglich, veröffentlichen Sie einen neuen Nachrichtentyp/Routing-Key statt das alte stillschweigend zu ändern.
So funktionieren ältere Konsumenten weiter, während neue schrittweise migrieren.
Correlation IDs und Trace IDs zum Debuggen über Services hinweg
Machen Sie Troubleshooting einfach, indem Sie Metadaten standardisieren:
correlation_id: verknüpft Kommandos/Events, die zu derselben Geschäftsaktion gehören.trace_id (oder W3C traceparent): verbindet Nachrichten mit verteiltem Tracing über HTTP- und asynchrone Flows.
Wenn jeder Publisher diese konsistent setzt, können Sie eine Transaktion über mehrere Services hinweg verfolgen, ohne raten zu müssen.
Namenskonventionen, die mit Ihrem System skalieren
Verwenden Sie vorhersehbare, durchsuchbare Namen. Ein gängiges Muster:
- Exchanges:
<domain>.<type> (z. B. billing.events)
- Routing-Keys:
<domain>.<entity>.<verb> (z. B. billing.invoice.created)
- Queues:
<service>.<purpose> (z. B. reporting.invoice_created.worker)
Konsistenz schlägt Cleverness: Ihr zukünftiges Ich (und Ihre On-Call-Rotation) wird es Ihnen danken.
Zuverlässigkeitsmuster: Retries, DLQs und Idempotenz
Von Idee zur Bereitstellung
Stelle deine Queue-basierte App bereit und hoste sie, nachdem du den Ablauf im Chat validiert hast.
Zuverlässiges Messaging heißt vor allem, für Fehler zu planen: Konsumenten stürzen ab, Downstream-APIs timen aus und manche Events sind fehlerhaft. RabbitMQ stellt Werkzeuge bereit — Ihre Anwendung muss damit zusammenarbeiten.
At-least-once-Delivery (und was das für Ihren Code bedeutet)
Ein häufiges Setup ist at-least-once delivery: eine Nachricht kann mehrmals zugestellt werden, darf aber nicht stillschweigend verloren gehen. Das passiert typischerweise, wenn ein Consumer eine Nachricht erhält, mit der Arbeit beginnt und dann vor dem Acknowledge abstürzt — RabbitMQ requeueed und liefert neu.
Praktische Konsequenz: Duplikate sind normal; Ihr Handler muss mehrfaches Ausführen vertragen.
Idempotenz-Strategien für Konsumenten
Idempotenz bedeutet: dieselbe Nachricht mehrmals zu verarbeiten hat denselben Effekt wie einmal.
Nützliche Ansätze:
- Dedupe-Keys: setzen Sie eine stabile
message_id (oder einen Geschäftsschlüssel wie order_id + event_type + version) und speichern Sie sie in einer "processed"-Tabelle/einem Cache mit TTL.
- Sichere Updates: verwenden Sie bedingte Writes (z. B. Update nur, wenn Status noch
PENDING) oder Datenbank-Constraints, um Double-Creates zu verhindern.
- Outbox/Inbox-Muster: persistent zuerst den Empfang des Events, dann die Verarbeitung — so wiederholen Retries keine Seiteneffekte.
Retries mit TTL + DLX/DLQ
Retries behandeln Sie am besten als separaten Flow, nicht als tight loop im Consumer.
Ein verbreitetes Muster:
- Bei transientem Fehler reject und an eine Retry-Queue routen, die eine per-Queue (oder per-Nachricht) TTL hat.
- Wenn die TTL abläuft, wird die Nachricht über eine Dead-Letter-Exchange (DLX) zurück an die Original-Queue geschickt.
- Verfolgen Sie die Anzahl der Versuche über einen Header (oder im Routing-Key) und stoppen Sie nach N Versuchen.
So erreichen Sie Backoff, ohne Nachrichten als unacked stecken zu lassen.
Poison Messages: Quarantäne und Replay
Manche Nachrichten werden nie erfolgreich verarbeitet (falsches Schema, fehlende referenzierte Daten, Programmfehler). Erkennen Sie sie durch:
- Erreichte maximale Retry-Anzahl
- Wiederholte Fehler mit derselben Fehler-Signatur
Routen Sie diese in eine DLQ zur Quarantäne. Behandeln Sie die DLQ wie ein operatives Postfach: payloads inspizieren, das zugrundeliegende Problem beheben und danach manuell ausgewählte Nachrichten wieder abspielen (idealerweise über ein kontrolliertes Tool/Skript), statt alles blind zurück in die Hauptqueue zu schmuggeln.
Die RabbitMQ-Performance wird meist durch einige praktische Faktoren begrenzt: wie Sie Verbindungen managen, wie schnell Konsumenten Arbeit sicher abarbeiten und ob Queues als "Lager" missbraucht werden. Ziel ist stetiger Durchsatz ohne wachsenden Rückstand.
Verbindungen vs Channels (Wiederverwendung und Limits)
Ein häufiger Fehler ist, für jeden Publisher/Konsumenten eine neue TCP-Verbindung zu öffnen. Verbindungen sind schwerer als gedacht (Handshakes, Heartbeats, TLS), also halten Sie sie persistent und wiederverwendbar.
Verwenden Sie Channels, um über weniger Verbindungen zu multiplexen. Faustregel: wenige Verbindungen, viele Channels. Erzeugen Sie dennoch nicht blind tausende Channels — jeder Channel hat Overhead, und Ihre Client-Bibliothek hat möglicherweise eigene Limits. Bevorzugen Sie einen kleinen Channel-Pool pro Service und wiederverwenden Sie Channels zum Publizieren.
Prefetch und Concurrency (Durchsatz ohne Überlast)
Wenn Konsumenten zu viele Nachrichten auf einmal ziehen, sehen Sie Speicher-Spikes, lange Verarbeitungszeiten und ungleichmäßige Latenz. Setzen Sie einen Prefetch (QoS), sodass jeder Consumer nur eine kontrollierte Anzahl unacked Nachrichten hält.
Praktische Empfehlungen:
- Für langsamere Jobs (API-Aufrufe, Datei-Verarbeitung) starten Sie mit Prefetch 1–10 pro Consumer.
- Für schnelle, CPU-leichte Handler erhöhen Sie Prefetch schrittweise, während Sie Ack-Raten und Host-Ressourcen beobachten.
- Skalieren Sie, indem Sie mehr Consumer-Instanzen (oder Threads) hinzufügen, bevor Sie den Prefetch stark erhöhen.
Nachrichtengröße: Payloads schlank halten
Große Nachrichten reduzieren Durchsatz und erhöhen Speicherbelastung (bei Publishern, Broker und Konsumenten). Wenn die Nutzlast groß ist (Dokumente, Bilder, große JSONs), speichern Sie sie extern (Object Storage oder DB) und senden nur eine ID + Metadaten über RabbitMQ.
Faustregel: Nachrichten in den KB-Bereich, nicht MB.
Backpressure: "unendliches Queue-Wachstum" verhindern
Wachstum der Queue ist ein Symptom, kein Plan. Fügen Sie Backpressure ein, damit Produzenten langsamer werden, wenn Konsumenten nicht nachkommen:
- Begrenzen Sie Consumer-Arbeit: Kapazitäten und Prefetch so einstellen, dass In-Flight-Arbeit vorhersehbar bleibt.
- Wachstum erkennen und reagieren: Alerts auf Queue-Depth, Publish-Rate vs Ack-Rate.
- Load Shedding: bei nicht-kritischen Events während Spitzen Nachrichten droppen oder sampeln.
Wenn Sie unsicher sind, ändern Sie immer nur einen Parameter und messen: Publish-Rate, Ack-Rate, Queue-Länge und End-to-End-Latenz.
Sicherheits-Checklist für RabbitMQ-Deployments
Wechsle zu asynchronen Workflows
Entwerfe einen ereignisgesteuerten Workflow und halte Services entkoppelt — ohne komplexe HTTP-Ketten.
Sicherheit bei RabbitMQ bedeutet vor allem, die „Ränder“ zu härten: wie Clients sich verbinden, wer was darf und wie Credentials geschützt werden. Nutzen Sie diese Checkliste als Basis und passen Sie sie an Ihre Compliance-Anforderungen an.
Verbindungen mit TLS verschlüsseln
- Aktivieren Sie TLS für alle Client-Verbindungen (AMQP over TLS auf 5671 oder Ihrem gewählten Port) und bevorzugen Sie moderne TLS-Versionen und Cipher.
- Verwenden Sie Zertifikate, die zum Broker-Hostname passen, mit dem Clients verbinden.
- Planen Sie Zertifikatsrotation: Ablaufdaten überwachen, Erneuerungen automatisieren, Reload-Prozeduren testen, damit Rotation kein Ausfall wird.
- Wo möglich, validieren Sie Clients per mTLS für interne Services, die sensible Daten handhaben.
Authentifizierung und Autorisierung
RabbitMQ-Berechtigungen sind mächtig, wenn Sie sie konsistent nutzen:
- Legen Sie separate Benutzer für jede Anwendung an (keine gemeinsamen "app"-Accounts).
- Nutzen Sie Vhosts, um Tenants/Systeme zu partitionieren (z. B. ein Vhost pro Produkt/Team).
- Wenden Sie das Least-Privilege-Prinzip pro Vhost an:
- Configure (Ressourcen erstellen/ändern)
- Write (publizieren)
- Read (konsumieren)
Dev/Staging/Prod sauber trennen
- Betreiben Sie nach Möglichkeit separate Cluster pro Umgebung. Muss Infrastruktur geteilt werden, isolieren Sie mit strikten Vhost-Grenzen und separaten Credentials.
- Lassen Sie niemals eine Dev-App standardmäßig auf einen Prod-Broker zeigen. Machen Sie das per Netzwerk-Policy und DNS-Namen unmöglich.
Secrets richtig handhaben in Anwendungen
- Keine hartkodierten Credentials in Code, in Repositories oder Container-Images.
- Injizieren Sie Secrets zur Laufzeit über Ihre Plattform (Kubernetes-Secrets, Secret-Manager, verschlüsselte CI-Variablen).
- Rotieren Sie Credentials regelmäßig und entfernen Sie ungenutzte Benutzer.
Für operative Härtung (Ports, Firewalls, Auditing) halten Sie ein kurzes internes Runbook und verlinken es von /docs/security, damit Teams einem Standard folgen.
Monitoring und Observability: Was messen
Wenn RabbitMQ Probleme hat, zeigt sich das meist zuerst in Ihrer Anwendung: langsame Endpunkte, Timeouts, fehlende Updates oder Jobs, die "nie fertig werden". Gute Observability hilft zu bestätigen, ob der Broker die Ursache ist, den Engpass zu finden (Producer, Broker oder Consumer) und zu handeln, bevor Nutzer es merken.
Wichtige Broker-Metriken
Beginnen Sie mit einer kleinen Menge Signale, die zeigen, ob Nachrichten fließen:
- Queue-Depth (messages ready + unacked): Wachsende Tiefe zeigt, dass Konsumenten nicht nachkommen oder hängen.
- Publish-Rate und Ack-Rate: Publishes steigen, während Acks stagnieren = Backlog.
- Consumer-Auslastung: Sind Konsumenten idle, gesättigt oder starten sie häufig neu?
- Redeliveries / Requeues: Starkes Signal für Verarbeitungsfehler, schlechte Retry-Policy oder Poison-Messages.
Alerting-Signale, die Vorfälle früh erfassen
Alarmieren Sie auf Trends, nicht nur auf absolute Schwellwerte:
- Backlog, das über N Minuten wächst ist handlungsfähiger als „Depth > X“.
- Wiederholte Requeues/Redeliveries deuten auf einen Fehlerloop hin, der CPU verbrennt und die Queue blockiert.
- Connection- und Channel-Churn kann auf App-Crashes, Netzwerkprobleme oder falsche Heartbeats hinweisen.
- Lang andauernd hohe Unacked-Zahlen suggerieren hängende oder zu lange verarbeitende Konsumenten.
Logs und Message-Tracing in Vorfällen
Broker-Logs helfen zu unterscheiden, ob "RabbitMQ down" oder "Clients missbrauchen es". Achten Sie auf Authentifizierungsfehler, blocked connections (Resource Alarms) und häufige Channel-Fehler. Auf Applikationsseite sollten Verarbeitungsversuche correlation_id, Queue-Name und Ergebnis (acked, rejected, retried) protokollieren.
Wenn Sie verteiltes Tracing nutzen, propagieren Sie Trace-Header durch Message-Properties, damit Sie "API-Request → veröffentlichte Nachricht → Consumer-Arbeit" verbinden können.
Dashboards und interne Runbooks
Bauen Sie ein Dashboard pro kritischem Flow: Publish-Rate, Ack-Rate, Depth, Unacked, Requeues und Consumer-Count. Fügen Sie direkte Links zum internen Runbook hinzu (z. B. /docs/monitoring) und eine "Was zuerst prüfen"-Checkliste für On-Call.
Troubleshooting häufiger RabbitMQ-Probleme
Wenn etwas in RabbitMQ "einfach nicht mehr läuft", widerstehen Sie dem Drang, sofort neu zu starten. Die meisten Probleme werden klar, wenn Sie (1) Bindings und Routing, (2) Konsumenten-Health und (3) Resource-Alarms prüfen.
Nachrichten werden nicht konsumiert
Wenn Publisher "erfolgreich gesendet" melden, aber Queues leer bleiben (oder die falsche Queue füllt), prüfen Sie Routing vor Code.
Starten Sie in der Management-UI:
- Prüfen Sie den Exchange-Typ und ob die Queue die erwarteten Bindings hat.
- Bestätigen Sie, dass der vom Producer genutzte Routing-Key zum Binding-Muster passt (besonders bei
topic).
- Stellen Sie sicher, dass Sie im korrekten vhost veröffentlichen.
Wenn die Queue Nachrichten enthält, aber nichts konsumiert wird, prüfen Sie:
- Ob ein Konsument verbunden und an der richtigen Queue abonniert ist.
- Ob der Konsument durch Prefetch falsch konfiguriert ist oder auf langsame Downstream-Arbeit blockiert.
- Ob Acks stattfinden (wachsende unacked-Zahlen deuten darauf hin, dass der Konsument nicht ackt oder überlastet ist).
Duplikate und aus der Reihenfolge gelieferte Nachrichten
Duplikate entstehen typischerweise durch Retries (Consumer stürzt nach Verarbeitung, aber vor dem Ack ab), Netzwerkunterbrechungen oder manuelles Requeueing. Mildern Sie das durch idempotente Handler (z. B. Dedupe per message ID in der DB).
Out-of-Order-Delivery ist zu erwarten, wenn mehrere Konsumenten oder Requeues im Spiel sind. Wenn Reihenfolge wichtig ist, nutzen Sie einen einzelnen Konsumenten für diese Queue oder partitionieren Sie nach Key in mehrere Queues.
Memory-/Disk-Alarme
Alarme zeigen, dass RabbitMQ sich schützt.
- Disk-Alarm: freien Plattenplatz schaffen, Logs verschieben oder Volume erweitern; bestätigen, dass der Alarm verschwindet.
- Memory-Alarm: In-Flight-Nachrichten reduzieren (Prefetch senken, Publisher drosseln), und auf zu große Nachrichten prüfen.
Sicheres Replay aus einer DLQ
Bevor Sie replays starten, beheben Sie die Ursache und verhindern Sie Poison-Loops. Requeueen Sie in kleinen Chargen, setzen Sie eine Retry-Grenze und versehen Sie Fehlschläge mit Metadaten (Attempt-Count, letzter Fehler). Überlegen Sie, Replay-Nachrichten zuerst in eine separate Queue zu schicken, damit Sie schnell stoppen können, falls derselbe Fehler wieder auftritt.
Entwerfe einen sicheren Nachrichtenfluss
Skizziere Wiederholungen, DLQ‑Abläufe und Nachrichtenversionen im Planungsmodus, bevor du implementierst.
Die Wahl eines Messaging-Tools hängt von Ihrem Traffic-Muster, Ihrer Fehler-Toleranz und Ihrem betrieblichen Komfort ab.
Wann RabbitMQ passt
RabbitMQ ist stark, wenn Sie zuverlässige Zustellung und flexibles Routing zwischen Applikationskomponenten brauchen. Es ist eine gute Wahl für klassische asynchrone Workflows — Commands, Background-Jobs, Fan-Out-Notifications und Request/Response-Muster — vor allem, wenn Sie:
- Pro-Nachricht Acknowledgements und Backpressure brauchen (langsamer Konsument droppt nicht stillschweigend Arbeit)
- Reiches Routing (Topics, Headers, Direct) ohne Eigenbau wollen
- Operativ einfaches Skalieren (Consumer hinzufügen, Prefetch anpassen, Queues managen) bevorzugen
Wenn Ihr Ziel ist, Arbeit zu bewegen und kein langes Event-Archiv zu behalten, ist RabbitMQ oft der komfortable Default.
RabbitMQ vs Kafka-ähnliche Streaming-Systeme
Kafka und ähnliche Plattformen sind auf hohen Durchsatz und langlebige Event-Logs ausgelegt. Wählen Sie ein Kafka-ähnliches System, wenn Sie brauchen:
- Replaybarkeit (Konsumenten können Historie erneut verarbeiten)
- Sehr hohen Durchsatz mit partitionierter Skalierung
- Einen einzigen "Source of Truth" Event-Stream für Analytics und Services
Nachteile: Kafka-Systeme können höheren operationalen Overhead haben und zwingen oft zu durchsatzorientiertem Design (Batching, Partition-Strategien). RabbitMQ ist meist einfacher für niedrigen bis mittleren Durchsatz mit niedriger Latenz und komplexem Routing.
Wann eine einfache Task-Queue reicht
Wenn Sie nur eine App haben, die Jobs produziert, und einen Worker-Pool, der sie konsumiert — und Sie mit einfacheren Semantiken leben können — reicht eine Redis-basierte Queue (oder ein Managed Task Service) oft aus. Teams wachsen darüber hinaus, wenn Sie stärkere Zustellgarantien, Dead-Lettering, mehrere Routing-Muster oder eine klarere Trennung von Produzenten und Konsumenten brauchen.
Migrationsüberlegungen, falls sich Bedürfnisse ändern
Gestalten Sie Nachrichtenschemata so, als könnten Sie später umziehen:
- Halten Sie Message-Schemata versioniert und abwärtskompatibel.
- Vermeiden Sie Broker-spezifische Features in der Nutzlast (Routing in Header/Metadaten, nicht im Body).
- Bauen Sie Producer/Consumer so, dass sie während einer Migration parallel laufen können.
Wenn Sie später Replay-fähige Streams brauchen, können Sie RabbitMQ-Events oft in ein Log-basiertes System überführen, während RabbitMQ für operative Workflows bleibt. Für einen praktischen Rollout-Plan siehe /blog/rabbitmq-rollout-plan-and-checklist.
Nächste Schritte: Rollout-Plan und Team-Checklist
Ein RabbitMQ-Rollout funktioniert am besten, wenn Sie es als Produkt behandeln: klein starten, Ownership definieren und Zuverlässigkeit beweisen, bevor Sie auf mehr Services ausweiten.
Starter-Checklist (Ein-Service-Einführung)
Wählen Sie einen Workflow, der von Async-Verarbeitung profitiert (z. B. E-Mails, Reports, Sync zu Drittanbieter-API).
- Definieren Sie den Message-Contract: Pflichtfelder, Version und was "Erfolg" bedeutet.
- Erstellen Sie einen Exchange + eine Queue mit klarer Namenskonvention.
- Setzen Sie Consumer-Concurrency-Limits und Prefetch, um Downstream-Systeme nicht zu überlasten.
- Implementieren Sie Retry-Verhalten (mit Backoff) und eine Dead-Letter-Queue (DLQ) von Anfang an.
- Machen Sie Handler idempotent (sicher mehrfach ausführbar).
- Dokumentieren Sie operative "Stop the bleeding"-Schritte (Consumer pausieren, Queue drainen, DLQ replay).
Wenn Sie ein Referenztemplate für Naming, Retry-Tiers und Policies brauchen, zentralisieren Sie es in /docs.
Bei Implementierung überlegen Sie, die Scaffolding-Teile teamübergreifend zu standardisieren. Beispielsweise generieren Teams mit Koder.ai oft ein kleines Producer/Consumer-Skeleton aus einem Chat-Prompt (inkl. Naming-Konventionen, Retry/DLQ-Wiring und Trace/Correlation-Headern), exportieren den Source-Code zur Review und iterieren in der Planungsphase vor dem Rollout.
Operative Ownership (explizit machen)
RabbitMQ funktioniert, wenn "jemand die Queue besitzt". Legen Sie das vor dem Go-Live fest:
- Wer überwacht: üblicherweise die Plattform-/SRE-Teams für Broker-Health; Service-Teams für ihre Queues und Konsumenten.
- Wer kümmert sich um DLQ: das Service-Team on-call (mit klaren Eskalationswegen).
- Runbooks: ein Broker-Level-Runbook und ein Service-Level-Runbook pro kritischer Queue.
Wenn Sie Support oder Managed Hosting formalisieren, stimmen Sie Erwartungen früh ab (siehe /pricing) und setzen Sie einen Kontakt für Incidents/Onboarding unter /contact.
Nächste Experimente (Proof before Scaling)
Führen Sie kleine, zeitlich begrenzte Übungen durch, um Vertrauen aufzubauen:
- Load Test: validieren Sie Durchsatz, Consumer-Concurrency und Latenz unter peak-ähnlichen Bedingungen.
- Failure Drills: Consumer killen, Broker-Restarts simulieren, Netzwerkverzögerung erzwingen, Retries und DLQ-Verhalten prüfen.
- Schema-Versionierung: führen Sie eine v2-Nachricht ein, während v1-Konsumenten weiterlaufen; prüfen Sie Kompatibilität und Rollout.
Wenn ein Service mehrere Wochen stabil läuft, replizieren Sie die Muster — erfinden Sie sie nicht für jedes Team neu.