08. Aug. 2025·8 Min
Roy Fieldings REST: Einschränkungen, die moderne Web‑APIs prägen
Verstehe Roy Fieldings REST‑Einschränkungen und wie sie praktisches API‑ und Web‑App‑Design prägen: Client‑Server, Zustandslosigkeit, Caching, einheitliche Schnittstelle, Schichten und mehr.
Warum Roy Fieldings REST noch immer wichtig ist
Roy Fielding ist nicht nur ein Name, der an einem API‑Buzzword klebt. Er war einer der Hauptautoren der HTTP‑ und URI‑Spezifikationen und hat in seiner Dissertation einen architektonischen Stil beschrieben, den er REST (Representational State Transfer) nannte, um zu erklären, warum das Web so gut funktioniert.
Dieser Ursprung ist wichtig, weil REST nicht erfunden wurde, um „schick aussehende Endpunkte“ zu schaffen. Es war ein Weg, die Einschränkungen zu beschreiben, die ein globales, chaotisches Netzwerk dennoch skalierbar machen: viele Clients, viele Server, Vermittler, Caching, partielle Ausfälle und kontinuierliche Veränderungen.
Was du aus diesem Beitrag mitnimmst
Wenn du dich jemals gefragt hast, warum zwei „REST‑APIs“ sich komplett unterschiedlich anfühlen — oder warum eine kleine Designentscheidung später zu Problemen mit Paginierung, Caching oder Breaking Changes führt — soll dieser Leitfaden helfen, diese Überraschungen zu verringern.
Du gehst weg mit:\n\n- klareren Entscheidungen beim Entwurf oder der Bewertung einer API,\n- einem besseren Vokabular, um Trade‑offs im Team zu besprechen,\n- einem praktischen Gefühl dafür, welche REST‑Ideen in echten Projekten am wichtigsten sind.
REST in einer Seite: Stil, kein Standard
REST ist keine Checkliste, kein Protokoll und keine Zertifizierung. Fielding beschrieb es als einen architektonischen Stil: eine Menge von Einschränkungen, die, wenn sie zusammen angewendet werden, Systeme erzeugen, die wie das Web skalieren — einfach zu benutzen, in der Lage, sich über die Zeit zu verändern, und freundlich gegenüber Vermittlern (Proxies, Caches, Gateways) ohne ständige Koordination.
Das Problem, das REST löste
Das frühe Web musste über viele Organisationen, Server, Netzwerke und Client‑Typen hinweg funktionieren. Es musste ohne zentrale Kontrolle wachsen, partielle Ausfälle überstehen und neue Funktionen erlauben, ohne alte zu brechen. REST geht das an, indem es einige wenige weit verbreitete Konzepte (wie Identifikatoren, Repräsentationen und standardisierte Operationen) gegenüber proprietären, eng gekoppelten Verträgen bevorzugt.
„Architektonische Einschränkungen“ ganz praktisch
Eine Einschränkung ist eine Regel, die die Designfreiheit einschränkt, um Vorteile zu erhalten. Zum Beispiel gibst du vielleicht Server‑seitigen Session‑State auf, damit Anfragen von jedem Serverknoten bearbeitet werden können, was Zuverlässigkeit und Skalierbarkeit erhöht. Jede REST‑Einschränkung macht einen ähnlichen Tausch: weniger ad‑hoc‑Flexibilität, mehr Vorhersagbarkeit und Evolvierbarkeit.
REST vs. „REST‑ähnliche“ APIs
Viele HTTP‑APIs übernehmen REST‑Ideen (JSON über HTTP, URL‑Endpunkte, vielleicht Statuscodes), wenden aber nicht die vollständige Menge der Einschränkungen an. Das ist nicht „falsch“ — oft spiegelt es Produkttermine oder interne Bedürfnisse wider. Es ist einfach nützlich, den Unterschied zu benennen: Eine API kann ressourcenorientiert sein, ohne vollständig REST zu sein.
Ein Ein‑Satz‑Gedankenmodell
Stell dir ein REST‑System als Ressourcen (Dinge, die du mit URLs benennst) vor, mit denen Clients über Repräsentationen (die aktuelle Ansicht einer Ressource, z. B. JSON oder HTML) interagieren und die durch Links (nächste Aktionen und verwandte Ressourcen) geführt werden. Der Client braucht keine geheimen out‑of‑band Regeln; er folgt Standardsemantiken und navigiert mit Links, so wie ein Browser durchs Web geht.
Ressourcen und Repräsentationen: Das Kernvokabular
Bevor du dich in Einschränkungen und HTTP‑Details verlierst, beginnt REST mit einem einfachen Vokabelwechsel: Denke in Ressourcen statt in Aktionen.
Ressource = ein Nomen, das du identifizieren kannst
Eine Ressource ist ein adressierbares „Ding“ in deinem System: ein Benutzer, eine Rechnung, eine Produktkategorie, ein Warenkorb. Wichtig ist, dass es eine Identität hat.
Deshalb liest sich /users/123 natürlich: es identifiziert den Benutzer mit der ID 123. Im Vergleich dazu beschreiben Aktions‑URLs wie /getUser oder /updateUserPassword Verben — Operationen, nicht das Ding, auf dem du operierst.
REST sagt nicht, dass du keine Aktionen ausführen darfst. Es sagt, Aktionen sollten über die einheitliche Schnittstelle ausgedrückt werden (für HTTP‑APIs bedeutet das normalerweise Methoden wie GET/POST/PUT/PATCH/DELETE), die auf Ressourcen‑Identifiers wirken.
Repräsentation = eine Sicht auf die Ressource
Eine Repräsentation ist das, was du als Momentaufnahme oder Ansicht der Ressource über das Netz sendest. Dieselbe Ressource kann mehrere Repräsentationen haben.
Beispielsweise könnte die Ressource /users/123 als JSON für eine App oder als HTML für einen Browser repräsentiert werden.
GET /users/123
Accept: application/json
Might return:
{
"id": 123,
"name": "Asha",
"email": "[email protected]"
}
While:
GET /users/123
Accept: text/html
Might return an HTML page rendering the same user details.
Der wichtige Punkt: die Ressource ist nicht das JSON und sie ist nicht das HTML. Das sind nur Formate, um sie zu repräsentieren.
Warum diese Sichtweise API‑Design verändert
Wenn du deine API um Ressourcen und Repräsentationen modellierst, werden mehrere praktische Entscheidungen einfacher:\n\n- Namen bleiben stabil. /users/123 bleibt gültig, auch wenn UI, Workflows oder Datenmodell sich ändern.\n- Endpunkte werden einfacher. Statt für jede Operation eine neue URL zu erfinden, wiederverwendest du Ressourcen‑URLs und variierst die Methode oder Repräsentation.\n- Client‑Code wird weniger gekoppelt. Clients konzentrieren sich auf „hole den Benutzer“ oder „aktualisiere Felder des Benutzers“ statt ein Verzeichnis von Aktionsendpunkten zu memorieren.
Diese ressourcen‑zuerst Denkweise ist das Fundament, auf dem die REST‑Einschränkungen aufbauen. Ohne sie reduziert sich „REST“ oft zu „JSON über HTTP mit ein paar hübschen URL‑Mustern“.
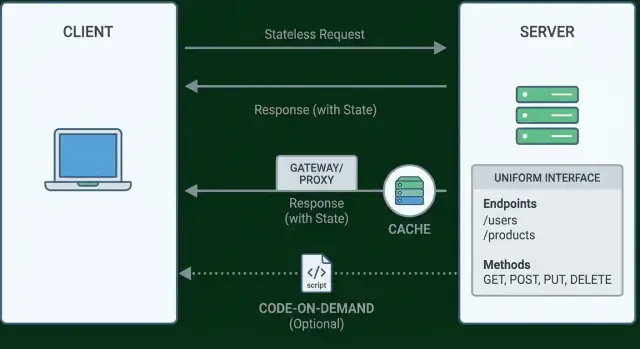
Einschränkung 1: Client–Server‑Trennung
Die Client–Server‑Trennung ist RESTs Art, eine klare Aufgabentrennung durchzusetzen. Der Client konzentriert sich auf die Benutzererfahrung (was Nutzer sehen und tun), der Server auf Daten, Regeln und Persistenz (was wahr ist und was erlaubt ist). Wenn du diese Verantwortlichkeiten trennst, kann jede Seite sich ändern, ohne die andere umzuschreiben.
Was gehört auf Client vs. Server?
Alltagsmäßig ist der Client die „Präsentationsschicht“: Bildschirme, Navigation, Formular‑Validierung für schnelles Feedback und optimistische UI‑Verhalten (z. B. einen neuen Kommentar sofort anzeigen). Der Server ist die „Quelle der Wahrheit“: Authentifizierung, Autorisierung, Geschäftsregeln, Datenspeicherung, Audit‑Logs und alles, was geräteübergreifend konsistent bleiben muss.
Eine praktische Regel: Wenn eine Entscheidung Sicherheit, Geld, Berechtigungen oder gemeinsame Datenkonsistenz betrifft, gehört sie auf den Server. Betrifft sie nur das Look & Feel (Layout, lokale Eingabehinweise, Ladezustände), gehört sie auf den Client.
Warum es zu modernen App‑Mustern passt
Diese Einschränkung bildet die Grundlage für gängige Setups:\n\n- SPA + API: eine Web‑App (React/Vue/etc.) iteriert an der UI, während die API weiter Ressourcen bereitstellt.\n- Mobile Apps: iOS‑ und Android‑Clients können dieselben Serverregeln und Endpunkte teilen.\n- Drittanbieter‑Integrationen: Partner nutzen dieselben Server‑Fähigkeiten ohne dein UI zu brauchen.
Client–Server‑Trennung macht „ein Backend, viele Frontends“ realistisch.
Häufiger Fehler: UI‑Zustand in Server‑Sessions leaken
Ein häufiger Fehler ist, UI‑Workflow‑State auf dem Server zu speichern (z. B. „welcher Checkout‑Schritt der Nutzer ist“). Das koppelt das Backend an einen speziellen Bildschirmfluss und erschwert Skalierung.
Bevorzuge es, den nötigen Kontext mit jeder Anfrage zu senden (oder ihn aus gespeicherten Ressourcen abzuleiten), sodass der Server bei Ressourcen und Regeln bleibt — nicht damit, sich an den Fortschritt einer spezifischen UI zu erinnern.
Einschränkung 2: Zustandslose Interaktionen
Zustandslosigkeit bedeutet, dass der Server nichts über einen Client zwischen Anfragen behalten muss. Jede Anfrage enthält alle Informationen, die nötig sind, um sie zu verstehen und korrekt zu beantworten — wer anruft, was gewünscht ist und welcher Kontext gebraucht wird.
Warum das wichtig ist
Wenn Anfragen unabhängig sind, kannst du Server hinter einem Load Balancer hinzufügen oder entfernen, ohne dich um „welcher Server kennt meine Session“ zu sorgen. Das verbessert Skalierbarkeit und Resilienz: jede Instanz kann jede Anfrage verarbeiten.
Es vereinfacht auch den Betrieb. Debugging ist oft leichter, weil der vollständige Kontext in der Anfrage (und den Logs) sichtbar ist, statt in Server‑seitigem Session‑Speicher verborgen zu sein.
Die Trade‑offs, die du in echten APIs spürst
Zustandslose APIs verschicken typischerweise etwas mehr Daten pro Aufruf. Statt sich auf eine gespeicherte Server‑Session zu verlassen, beinhaltet der Client jedes Mal Credentials und Kontext.
Du musst auch explizit mit „zustandsbehafteten“ Nutzerabläufen umgehen (Paginierung, mehrstufige Checkouts). REST verbietet mehrstufige Erlebnisse nicht — es verschiebt den State aber auf den Client oder auf serverseitige Ressourcen, die identifizierbar und abrufbar sind.
Praktische Muster (und was sie lösen)
- Auth‑Tokens (z. B. Bearer JWTs): Jede Anfrage enthält einen
Authorization: Bearer …Header, sodass jeder Server sie authentifizieren kann.\n- Idempotency‑Keys: Für Operationen wie „Zahlung erstellen“ senden Clients einenIdempotency-Key, damit Wiederholungen keine doppelten Arbeiten erzeugen.\n- Correlation‑IDs: Ein Header wieX-Correlation-Iderlaubt es, eine Nutzeraktion über Dienste und Logs hinweg zu verfolgen.
Bei Paginierung: vermeide „Server merkt Seite 3“. Bevorzuge explizite Parameter wie ?cursor=abc oder einen next‑Link, den der Client folgen kann — so bleibt der Navigationskontext in den Antworten und nicht im Server‑Speicher.
Einschränkung 3: Cachebare Antworten
Flutter-App für deine API
Erstelle eine Flutter-App, die deine API nutzt und Paginierung sowie Wiederholversuche handhabt.
Caching bedeutet, eine frühere Antwort sicher wiederzuverwenden, damit der Client (oder ein Vermittler) nicht immer wieder die gleiche Arbeit vom Server anfordern muss. Gut gemacht reduziert es Latenz für Nutzer und Last für dich — ohne die Bedeutung der API zu verändern.
Was „cachebar“ praktisch bedeutet
Eine Antwort ist cachebar, wenn es sicher ist, dass eine andere Anfrage für eine gewisse Zeit dieselbe Nutzlast erhalten kann. In HTTP kommunizierst du das mit Cache‑Headern:\n\n- Cache-Control: die zentrale Steuerung (wie lange, ob geteilter Cache erlaubt ist usw.)\n- ETag und Last-Modified: Validatoren, mit denen Clients fragen können „hat sich das geändert?“ und eine günstige „Not Modified“‑Antwort bekommen\n- Expires: eine ältere Art, Frische auszudrücken, die noch vereinzelt vorkommt
Das ist mehr als „Browser‑Caching“. Proxies, CDNs, API‑Gateways und sogar mobile Apps können Antworten wiederverwenden, wenn die Regeln klar sind.
Was üblicherweise sicher zu cachen ist (und was nicht)
Gute Kandidaten:
\n- Öffentliche, für alle identische Daten (Produktkataloge, Dokumentation, Feature‑Flags, die nicht nutzerspezifisch sind)\n- Read‑Only‑Ressourcen, die sich selten ändern (statische Konfiguration, Referenzdaten)\n- GET‑Antworten, die nicht von Cookies oder Autorisierung abhängen
Meist schlechte Kandidaten:
\n- Persönliche Daten, die mit einem Account verknüpft sind (Profile, Bestellungen, Nachrichten)\n- Auth‑bezogene Antworten (Token‑Austausch, Session‑State)\n- Alles, das nutzerspezifisch variiert, es sei denn, du handhabst das ausdrücklich (z. B. mit private‑Caching‑Regeln)
Praktische Auswirkungen, die du bemerkst
- Schnellere Seiten und flüssigere Apps (weniger Warten auf das Netzwerk)\n- Niedrigere Server‑ und DB‑Kosten (weniger wiederholte Berechnungen)\n- Weniger Rate‑Limit‑Fälle (gecachete Reads verringern Anfragevolumen)
Die Kernidee: Caching ist kein Nachgedanke. Es ist eine REST‑Einschränkung, die APIs belohnt, die Frische und Validierung klar kommunizieren.
Einschränkung 4: Die einheitliche Schnittstelle (was sie wirklich bedeutet)
Die einheitliche Schnittstelle wird oft als „nutze GET zum Lesen und POST zum Erstellen“ missverstanden. Das ist nur ein kleiner Ausschnitt. Fieldings Idee ist größer: APIs sollten so konsistent wirken, dass Clients nicht für jeden Endpunkt spezielles Wissen benötigen.
Die vier Teile der einheitlichen Schnittstelle
- Identifikation von Ressourcen: Du benennst Dinge (Ressourcen) mit stabilen Identifikatoren (typischerweise URLs), nicht Aktionen. Denk an
/orders/123, nicht/createOrder.\n\n2) Manipulation über Repräsentationen: Clients ändern eine Ressource, indem sie eine Repräsentation (JSON, HTML etc.) senden. Der Server kontrolliert die Ressource; der Client tauscht Repräsentationen mit ihr aus.\n\n3) Selbstbeschreibende Nachrichten: Jede Anfrage/Antwort sollte genug Informationen tragen, um zu verstehen, wie sie zu verarbeiten ist — Methode, Statuscode, Header, Medientyp und ein klarer Body. Wenn Bedeutung in out‑of‑band Docs versteckt ist, werden Clients stark gekoppelt.\n\n4) Hypermedia (HATEOAS): Antworten sollten Links und erlaubte Aktionen enthalten, damit Clients ohne festverdrahtete URL‑Muster den Workflow folgen können.
Warum es Kopplung reduziert
Eine konsistente Schnittstelle macht Clients weniger abhängig von internen Serverdetails. Im Laufe der Zeit bedeutet das weniger Breaking Changes, weniger „Special Cases“ und weniger Arbeit, wenn Teams Endpunkte weiterentwickeln.
Praktische Heuristiken, die du anwenden kannst
- Nutze Statuscodes konsistent: z. B.
200für erfolgreiche Reads,201für erstellte Ressourcen (mitLocation),400für Validierungsfehler,401/403für Auth,404wenn eine Ressource nicht existiert.\n- Standardisiere dein Fehlerformat über die API hinweg. Beispielhafte Felder:code,message,details,requestId.\n- Halte Medientypen und Header aussagekräftig (Content-Type, Caching‑Header), sodass Nachrichten sich selbst erklären.
Die einheitliche Schnittstelle zielt auf Vorhersagbarkeit und Evolvierbarkeit ab, nicht nur auf „korrekte Verben“.
Selbstbeschreibende Nachrichten: Designen für Verstehbarkeit
Starter für zustandslose APIs
Erzeuge tokenbasierte Authentifizierung und Anfragemuster, die gut hinter einem Load Balancer funktionieren.
Eine „selbstbeschreibende“ Nachricht gibt dem Empfänger genug Hinweise, um sie zu interpretieren — ohne auf out‑of‑band Stammeswissen angewiesen zu sein. Wenn ein Client (oder Vermittler) nicht aus Headern und Body ableiten kann, was eine Antwort bedeutet, hast du ein privates Protokoll auf HTTP gebaut.
Nutze Medientypen, um die Nutzlast zu erklären
Der einfachste Gewinn ist, explizit Content-Type (was du sendest) und oft Accept (was du zurückhaben willst) zu setzen. Eine Antwort mit Content-Type: application/json sagt einem Client die grundlegenden Parsing‑Regeln, aber du kannst weiter gehen mit Vendor‑ oder Profil‑Medientypen, wenn die Bedeutung wichtig ist.
Beispiele von Ansätzen:\n\n- Generischer Medientyp + stabile Felder: application/json mit einem gepflegten Schema. Am einfachsten für die meisten Teams.\n- Vendor‑Medientypen: application/vnd.acme.invoice+json, um eine spezifische Repräsentation zu signalisieren.\n- Profile: Behalte application/json bei, füge einen profile‑Parameter oder Link zu einem Profil hinzu, das Semantik definiert.
Versionierung und Kompatibilität (ohne Clients zu brechen)
Versionierung soll bestehende Clients schützen. Beliebte Optionen sind:\n\n- URL‑Versionierung (/v1/orders): offensichtlich, kann aber dazu führen, dass Repräsentationen eher geforkt werden, statt evolviert.\n- Header‑ oder Medientyp‑Versionierung (via Accept): hält URLs stabil und macht „was das bedeutet“ zum Teil der Nachricht.\n- Additive Evolution: bevorzuge das Hinzufügen neuer Felder und halte alte weiter funktionsfähig; deprezieren schrittweise.
Was auch immer du wählst: strebe Rückwärtskompatibilität als Default an: benenne Felder nicht leichtfertig um, ändere Bedeutungen nicht stillschweigend und behandle Entfernen als Breaking Change.
Konsistente Fehler und klare Namensgebung
Clients lernen schneller, wenn Fehler überall gleich aussehen. Wähle eine Fehlerform (z. B. code, message, details, traceId) und benutze sie durchgängig. Verwende klare, vorhersehbare Feldnamen (createdAt statt created_at) und halte dich an eine Konvention.
Dokumentation hilft — aber Klarheit muss in der Nachricht leben
Gute Docs beschleunigen die Adoption, aber sie dürfen nicht der einzige Ort sein, wo Bedeutung existiert. Wenn ein Client ein Wiki lesen muss, um zu wissen, ob status: 2 „bezahlt“ oder „ausstehend“ heißt, ist die Nachricht nicht selbstbeschreibend. Gut gestaltete Header, Medientypen und lesbare Payloads reduzieren diese Abhängigkeit und machen Systeme leichter evolvierbar.
Hypermedia (HATEOAS): Die meistübersprungene REST‑Idee
Hypermedia (oft als HATEOAS zusammengefasst: Hypermedia As The Engine Of Application State) bedeutet, dass ein Client nicht die API‑URLs im Voraus kennen muss. Stattdessen enthält jede Antwort entdeckbare nächste Schritte als Links: wohin als Nächstes, welche Aktionen möglich sind und manchmal welche HTTP‑Methode zu verwenden ist.
Wie das in der Praxis aussieht
Anstatt Pfade wie /orders/{id}/cancel fest zu kodieren, folgt der Client Links, die der Server bereitstellt. Der Server sagt damit praktisch: „Angesichts des aktuellen Zustands dieser Ressource sind dies die validen Züge.“
{
"id": "ord_123",
"status": "pending",
"total": 49.90,
"_links": {
"self": { "href": "/orders/ord_123" },
"payment":{ "href": "/orders/ord_123/payment", "method": "POST" },
"cancel": { "href": "/orders/ord_123", "method": "DELETE" }
}
}
Wenn die Bestellung später paid wird, könnte der Server cancel entfernen und refund hinzufügen — ohne einen gut geschriebenen Client zu brechen.
Wann Hypermedia am meisten hilft
Hypermedia glänzt, wenn Abläufe sich entwickeln: Onboarding‑Schritte, Checkout, Genehmigungen, Abonnements oder jeder Prozess, bei dem „was als Nächstes erlaubt ist“ sich je nach Zustand, Berechtigungen oder Geschäftsregeln ändert.
Es reduziert auch hartverdrahtete URLs und brüchige Client‑Annahmen. Du kannst Routen umorganisieren, neue Aktionen einführen oder alte deprecaten, solange du die Bedeutung der Link‑Relationen beibehältst.
Warum Teams es überspringen (und was sie verlieren)
Teams überspringen HATEOAS oft, weil es sich nach zusätzlicher Arbeit anfühlt: Link‑Formate definieren, Relationsnamen abstimmen und Client‑Entwickler darin schulen, Links zu folgen statt URLs zusammenzusetzen.
Was du verlierst, ist ein zentraler REST‑Gewinn: lose Kopplung. Ohne Hypermedia werden viele APIs zu „RPC über HTTP“ — sie nutzen HTTP, aber Clients sind stark von out‑of‑band Dokumentation und festen URL‑Templates abhängig.
Einschränkung 5: Geschichtetes System
Ein geschichtetes System bedeutet, dass ein Client nicht wissen muss (und es oft nicht kann), ob er mit dem „echten“ Origin‑Server oder mit Vermittlern unterwegs ist. Diese Schichten können API‑Gateways, Reverse‑Proxies, CDNs, Auth‑Services, WAFs, Service‑Meshes und sogar internes Routing zwischen Microservices umfassen.
Warum Schichten nützlich sind
Schichten schaffen klare Grenzen. Sicherheitsteams können TLS, Rate‑Limits, Authentifizierung und Request‑Validierung am Edge erzwingen, ohne jeden Backend‑Service zu ändern. Operations‑Teams können horizontal skalieren hinter einem Gateway, Caching in einer CDN‑Schicht hinzufügen oder Traffic während Vorfällen umleiten. Für Clients kann das vereinfachend sein: ein stabiler API‑Endpunkt, konsistente Header und vorhersehbare Fehlerformate.
Die Trade‑offs, die du praktisch spürst
Vermittler können versteckte Latenz einführen (zusätzliche Hops, Handshakes) und Debugging erschweren: der Fehler kann in Gateway‑Regeln, CDN‑Cache oder Origin‑Code liegen. Caching wird kompliziert, wenn verschiedene Schichten unterschiedlich cachen oder ein Gateway Header umschreibt, die Cache‑Keys beeinflussen.
Praktische Tipps, damit Schichten nicht schaden
- Nutze Tracing‑IDs Ende‑zu‑Ende: Akzeptiere eine Request‑ID (oder generiere eine) und propagiere sie durch jeden Hop; gib sie in Antworten und Logs zurück.\n- Mach Fehlerpropagation explizit: standardisiere Fehlerkörper und mappe Upstream‑Fehler transparent (verwandle nicht alles in ein generisches 500).\n- Setze Timeouts pro Hop: Gateway‑Timeouts, Upstream‑Timeouts und Client‑Timeouts sollten abgestimmt sein, um mysteriöse Verbindungsabbrüche zu vermeiden.\n- Dokumentiere Caching‑Verhalten: sei klar, welche Antworten cachebar sind und welche Header Vermittler bewahren müssen.
Schichten sind mächtig — wenn das System beobachtbar und vorhersagbar bleibt.
Einschränkung 6 (optional): Code‑on‑Demand
Caching richtig gemacht
Füge Cache-Control- und ETag-Verarbeitung zu GET-Antworten hinzu, ohne manuellen Boilerplate-Code.
Code‑on‑demand ist die einzige REST‑Einschränkung, die ausdrücklich optional ist. Sie bedeutet, dass ein Server einen Client erweitern kann, indem er ausführbaren Code sendet, der auf dem Client läuft. Anstatt jede Funktionalität im Client vorab zu verteilen, kann der Client neue Logik bei Bedarf herunterladen.
Das vertraute Web‑Beispiel: JavaScript
Wenn du schon einmal eine Webseite geladen hast, die danach interaktiv wird — Formulare validiert, Diagramme rendert, Tabellen filtert — hast du Code‑on‑demand benutzt. Der Server liefert HTML und Daten sowie JavaScript, das im Browser läuft, um Verhalten bereitzustellen.
Das ist ein großer Grund, warum das Web sich schnell weiterentwickeln kann: Ein Browser bleibt ein generalisierter Client, während Sites neue Funktionalität liefern, ohne dass Nutzer eine ganze neue Anwendung installieren müssen.
Warum es optional ist (und warum viele APIs es vermeiden)
REST funktioniert auch ohne Code‑on‑demand, weil die anderen Einschränkungen bereits Skalierbarkeit, Einfachheit und Interoperabilität ermöglichen. Eine API kann rein ressourcenorientiert sein und Repräsentationen wie JSON liefern, während Clients ihr Verhalten selbst implementieren.
Viele moderne Web‑APIs vermeiden das Senden ausführbaren Codes, weil es kompliziert:\n\n- Sicherheit: ausführbarer Code vergrößert die Angriffsfläche (Injection, Supply‑Chain),\n- Content‑Policies: Browser erzwingen CSP und Organisationen blockieren möglicherweise Inline‑Skripte oder unbekannte Quellen,\n- Auditing und Compliance: schwer nachzuweisen, welcher Code wann auf einem Client lief, besonders wenn er dynamisch geladen wurde.
Wann Code‑on‑Demand trotzdem Sinn machen kann
Code‑on‑demand kann nützlich sein, wenn du die Client‑Umgebung kontrollierst und UI‑Verhalten schnell ausrollen musst, oder wenn du einen dünnen Client willst, der „Plugins“ oder Regeln vom Server lädt. Es ist jedoch besser als zusätzliches Werkzeug zu gelten, nicht als Requirement.
Kernaussage: du kannst REST vollständig befolgen ohne Code‑on‑demand — viele Produktions‑APIs tun genau das, weil die Einschränkung optionale Erweiterbarkeit betrifft, nicht die Grundlage der ressourcenbasierten Interaktion.
REST heute anwenden: Praktische Entscheidungen und häufige Fehltritte
Die meisten Teams lehnen REST nicht ab — sie adoptieren einen „REST‑ish“ Stil, der HTTP als Transport nutzt, während wichtige Einschränkungen stillschweigend fallen gelassen werden. Das kann okay sein, solange es bewusste Trade‑offs sind und nicht später als brüchige Clients und teure Rewrites zurückkommen.
Häufige REST‑ish Abkürzungen (und warum sie passieren)
Wiederkehrende Muster sind:\n\n- RPC‑Endpunkte: /doThing, /runReport, /users/activate — leicht zu benennen, schnell zu verbinden.\n- Verb‑schwere URLs: /createOrder, /updateProfile, /deleteItem — HTTP‑Methoden werden zur Nebensache.\n- Versteckte Sessions: „Zustandslose“ APIs, die dennoch auf Sticky Sessions, Server‑Speicher oder impliziten Workflow‑State bauen.
Diese Entscheidungen fühlen sich anfangs produktiv, weil sie interne Funktionsnamen und Geschäftsoperationen spiegeln.
Konsequenzen, die du später bemerkst
- Brüchige Clients: Wenn Clients von spezifischen Endpunktformen und ad‑hoc Verhalten abhängen, werden kleine Server‑Refactorings zu Breaking Changes.\n- Schwierige Versionierung: Wenn URLs Verhalten kodieren statt stabile Ressourcen, versiehst du Versionierung eher im Verhalten statt die Repräsentation weiterzuentwickeln.\n- Cache‑Misses (und höhere Latenz): POST für alles oder ignorierte Cache‑Header verhindern, dass Vermittler und Browser helfen.\n- Skalierungsprobleme: Versteckter Session‑State erschwert horizontales Skalieren und macht Fehlerwiederherstellung schwieriger.
Eine pragmatische Checkliste zur Selbstüberprüfung
Nutze das als „Wie REST‑konform sind wir wirklich?“‑Review:\n\n1. Nenne Ressourcen, nicht Aktionen: bevorzuge /orders/{id} gegenüber /createOrder.\n2. Verwende HTTP‑Methoden gezielt: GET für Retrieval, POST für Erstellung, PUT/PATCH für Updates, DELETE für Löschung.\n3. Mache Anfragen unabhängig: kein Server‑Speicher, um zu verstehen „in welchem Schritt der Client ist“.\n4. Nutze Caching wo sicher: definiere Cache‑Control, ETag und Vary für GET‑Antworten.\n5. Standardisiere Fehler und Medientypen: konsistente Statuscodes und Antwortformen reduzieren Spezialfälle.
Wie sich das beim Bauen zeigt
REST‑Einschränkungen sind kein bloßer Theorie‑Katalog — sie sind Leitplanken, die du beim Ausliefern spürst. Wenn du schnell eine API generierst (z. B. eine React‑Frontend‑Scaffold mit Go + PostgreSQL Backend), ist der einfachste Fehler, „was am schnellsten zusammenzubauen ist“ das Interface bestimmen zu lassen.
Wenn du eine Plattform für Rapid‑Development wie Koder.ai benutzt, hilft es, diese REST‑Einschränkungen früh in die Diskussion zu bringen — Ressourcen zuerst benennen, zustandslos bleiben, konsistente Fehlerformen definieren und entscheiden, wo Caching sicher ist. So produziert auch schnelle Iteration APIs, die vorhersagbar und leichter zu evolvieren sind. (Und da Koder.ai Quellcode‑Export unterstützt, kannst du API‑Contract und Implementierung weiter verfeinern, während Anforderungen reifen.)
Fazit für API‑ und Web‑App‑Teams
Definiert zuerst eure Schlüsselressourcen und trefft dann bewusste Entscheidungen zu Einschränkungen: Wenn ihr Caching oder Hypermedia überspringt, dokumentiert warum und womit ihr ersetzt. Ziel ist keine Reinheit, sondern Klarheit: stabile Ressourcen‑Identifikatoren, vorhersehbare Semantik und explizite Trade‑offs, die Clients resilient halten, während euer System wächst.
FAQ
Was meinte Roy Fielding mit „REST“ und warum ist es kein Standard?
REST (Representational State Transfer) ist ein architektonischer Stil, den Roy Fielding beschrieben hat, um zu erklären, warum das Web skaliert.
Es ist kein Protokoll oder eine Zertifizierung — es ist eine Menge von Einschränkungen (Client–Server, Zustandslosigkeit, Cachebarkeit, einheitliche Schnittstelle, geschichtetes System, optionaler Code‑on‑Demand), die etwas Flexibilität gegen Skalierbarkeit, Weiterentwickelbarkeit und Interoperabilität eintauschen.
Warum fühlen sich zwei „REST APIs“ oft komplett unterschiedlich an?
Weil viele APIs nur einige REST‑Ideen übernehmen (z. B. JSON über HTTP und hübsche URLs), andere aber weglassen (z. B. Cache‑Regeln oder Hypermedia).
Zwei „REST APIs“ können sich sehr unterschiedlich anfühlen, je nachdem ob sie:\n\n- stabile Ressourcen modellieren oder Aktionsendpunkte,\n- HTTP‑Semantik konsequent nutzen (Methoden, Statuscodes, Header),\n- Caching und Vermittler unterstützen,\n- die Kopplung durch entdeckbare Links reduzieren.
Was ist der praktische Unterschied zwischen „Ressourcen“ und „Aktionen“ im URL‑Design?
Eine Ressource ist ein Nomen, das du identifizieren kannst (z. B. /users/123). Ein Aktionsendpunkt ist ein Verb, das in die URL eingebettet ist (z. B. /getUser, /updatePassword).
Ressourcenorientiertes Design altert in der Regel besser, weil Identifikatoren stabil bleiben, während Workflows und UI sich ändern. Aktionen können weiterhin existieren, sollten aber üblicherweise über HTTP‑Methoden und Repräsentationen ausgedrückt werden statt über verbförmige Pfade.
Was ist eine „Repräsentation“ und warum ist die Ressource nicht das JSON?
Eine Ressource ist das Konzept („User 123“). Eine Repräsentation ist der Schnappschuss, den du überträgst (JSON, HTML usw.).
Das ist wichtig, weil du Repräsentationen erweitern oder hinzufügen kannst, ohne die Ressourcen‑Identifikatoren zu ändern. Clients sollten sich auf die Bedeutung der Ressource verlassen, nicht auf ein einzelnes Payload‑Format.
Wie hilft die Client–Server‑Trennung echten API‑Teams?
Die Trennung Client–Server hält Verantwortlichkeiten unabhängig:
- Client: UI, Interaktion, Navigation, lokale Validierung, Ladezustände
- Server: Authentifizierung/Autorisierung, Geschäftsregeln, Persistenz, Auditierung
Wenn eine Entscheidung Sicherheit, Geld, Berechtigungen oder gemeinsame Konsistenz betrifft, gehört sie auf den Server. Diese Trennung ermöglicht „ein Backend, viele Frontends“ (Web, Mobile, Partner).
Was bedeutet „zustandslos“ für eine HTTP‑API und was ändert sich praktisch?
Zustandslosigkeit bedeutet, dass der Server sich zwischen Anfragen nichts über den Client merken muss. Jede Anfrage trägt alle nötigen Informationen (Authentifizierung + Kontext).
Vorteile: einfacheres horizontales Skalieren (jeder Knoten kann jede Anfrage verarbeiten) und einfacheres Debugging (Kontext ist in der Anfrage/den Logs sichtbar).
Gängige Muster:
\n- Authorization: Bearer … bei jedem Aufruf
Welche Cache‑Header sind am wichtigsten und wann sollte ich sie verwenden?
Cachebare Antworten erlauben es Clients und Vermittlern, frühere Antworten sicher wiederzuverwenden, was Latenz und Last reduziert.
Wichtige HTTP‑Hilfen:
\n- Cache-Control für Frische und Bereich
Ist REST nur „verwende GET/POST/PUT/DELETE korrekt“, oder ist es mehr?
Die einheitliche Schnittstelle geht über „nutze GET/POST/PUT/DELETE korrekt“ hinaus: sie sorgt dafür, dass Clients nicht für jeden Endpunkt Spezialwissen brauchen.
Praktische Punkte:\n\n- stabile Ressourcen‑IDs,\n- korrekte HTTP‑Methoden,\n- konsistente Statuscodes (, + , , , ),\n- standardisiertes Fehlerformat (z. B. , , , ).
Was ist HATEOAS (Hypermedia) und wann lohnt es sich wirklich?
Hypermedia bedeutet, dass Antworten Links zu gültigen nächsten Aktionen enthalten, sodass Clients Links folgen statt URL‑Templates zu verfestigen.
Es hilft besonders, wenn Abläufe sich je nach Zustand oder Berechtigungen ändern (Checkout, Genehmigungen, Onboarding). Viele Teams überspringen es, weil es mehr Designarbeit bedeutet (Link‑Formate, Relation‑Namen), verlieren aber dadurch die Lose Kopplung zugunsten starrer Dokumentation und fixer Routen.
Wie beeinflussen „geschichtete Systeme“ API‑Verhalten, Performance und Debugging?
Ein geschichtetes System ermöglicht Vermittler (CDNs, Gateways, Proxies etc.), sodass der Client nicht wissen muss, welches Komponent die Antwort geliefert hat.
Um Layers nicht zum Debugging‑Albtraum werden zu lassen:\n\n- Request/Correlation‑IDs durch alle Hops propagieren,\n- Fehlertransparentes Mapping (nicht alles in einen generischen 500 verwandeln),\n- Timeouts pro Hop angleichen (Client, Gateway, Upstream),\n- Caching‑Verhalten dokumentieren und cache‑relevante Header bewahren.
Schichten sind ein Vorteil, wenn das System beobachtbar und vorhersagbar bleibt.