Was eine SaaS-Statusseite ist (und warum sie wichtig ist)
Eine SaaS-Statusseite ist eine öffentliche (oder nur für Kunden zugängliche) Website, die zeigt, ob Ihr Produkt gerade funktioniert — und was Sie tun, wenn das nicht der Fall ist. Sie wird zur einzigen Quelle der Wahrheit während Vorfällen, getrennt von Social Media, Support-Tickets und Gerüchten.
Sie hilft mehr Menschen, als Sie vielleicht erwarten:
- Kunden können schnell prüfen: „Bin ich der Einzige?“, und entscheiden, ob sie warten, es erneut versuchen oder eine Umgehungslösung nutzen.
- Support-Teams können auf ein einziges offizielles Update verweisen, statt Erklärungen in Dutzenden Tickets zu wiederholen.
- Sales- und Customer-Success-Teams können proaktiv Verlängerungen und Schlüsselkunden betreuen mit genauen, zeitgestempelten Informationen.
Echtzeit-Status vs. Vorfallhistorie vs. Postmortems
Eine gute Service-Status-Website enthält normalerweise drei verwandte (aber unterschiedliche) Ebenen:
- Echtzeit-Status: was jetzt gerade über Ihre Komponenten (API, Dashboard, Billing usw.) funktioniert, eingeschränkt ist oder ausgefallen ist.
- Vorfallhistorie: eine Zeitleiste vergangener Vorfälle und Wartungen, damit Kunden Muster erkennen und sehen, dass Probleme bearbeitet wurden.
- Post-Incident-Reviews (Postmortems): ausführlichere Berichte, die Ursachen, Behebungen und Präventionsmaßnahmen erklären. Diese können öffentlich sein oder privat mit betroffenen Kunden geteilt werden.
Das Ziel ist Klarheit: Echtzeit-Status beantwortet „Kann ich das Produkt nutzen?“, die Historie beantwortet „Wie oft passiert das?“, und Postmortems beantworten „Warum ist das passiert und was hat sich geändert?"
Erwartungen setzen: Transparenz, Geschwindigkeit und Klarheit
Eine Statusseite funktioniert, wenn Updates schnell, in einfachem Sprachstil und ehrlich über den Umfang sind. Sie brauchen keine perfekte Diagnose, um zu kommunizieren. Sie brauchen Zeitstempel, Umfang (wer ist betroffen) und die Zeit des nächsten Updates.
Typische Momente, in denen Sie sie nutzen
Sie werden die Seite während Ausfällen, degradierter Leistung (langsame Logins, verzögerte Webhooks) und geplanter Wartung, die kurzzeitige Unterbrechungen verursachen kann, verwenden.
Wenn Sie die Statusseite als Produktfläche behandeln (nicht als einmalige Ops-Seite), wird der Rest der Einrichtung viel einfacher: Sie können Eigentümer definieren, Vorlagen erstellen und Monitoring verbinden, ohne den Prozess bei jedem Vorfall neu erfinden zu müssen.
Ziele, Publikum und Ownership festlegen
Bevor Sie ein Tool wählen oder ein Layout entwerfen, entscheiden Sie, was Ihre Statusseite erreichen soll. Ein klares Ziel und ein klarer Eigentümer halten Statusseiten während eines Vorfalls nützlich — wenn alle beschäftigt sind und Informationen chaotisch sind.
Ziel definieren (wie „Erfolg“ aussieht)
Die meisten SaaS-Teams erstellen eine Statusseite für drei praktische Ergebnisse:
- Support-Tickets reduzieren, indem die Frage „Ist es down?“ an einem öffentlichen Ort beantwortet wird
- Vertrauen aufbauen, indem zeitnahe, in einfacher Sprache verfasste Updates geteilt werden
- Kommunikation beschleunigen zwischen Support, Engineering, Sales und Customer Success
Schreiben Sie 2–3 messbare Signale auf, die Sie nach dem Start verfolgen können: weniger doppelte Tickets bei Ausfällen, schnellere Zeit bis zum ersten Update oder mehr Kunden, die Abonnements nutzen.
Publikum und Lesestufe identifizieren
Ihr primärer Leser ist meist ein nicht-technischer Kunde, der wissen möchte:
- Funktioniert das Produkt gerade?
- Was ist betroffen (Login, API, Billing etc.)?
- Was soll ich als Nächstes tun?
- Wann wird es behoben sein?
Das bedeutet: Minimieren Sie Fachjargon. Bevorzugen Sie „Einige Kunden können sich nicht anmelden“ statt „Erhöhte 5xx-Raten auf Auth“. Falls technische Details nötig sind, halten Sie sie als kurze sekundäre Erklärung.
Ton, Regeln und Ownership wählen
Wählen Sie einen Ton, den Sie unter Druck beibehalten können: ruhig, sachlich und transparent. Entscheiden Sie im Voraus:
- Wer Updates posten darf (eine einzelne Rolle oder die on-call Rotation)
- Wer Updates genehmigt (falls nötig) und wie lange die Genehmigung dauern darf
- Mindest-Update-Frequenz während eines aktiven Vorfalls (z. B. alle 30 Minuten)
Machen Sie die Verantwortung explizit: Die Statusseite sollte nicht „Jedermanns Aufgabe“ sein, sonst wird sie niemandes Aufgabe.
Wo die Seite liegt
Sie haben zwei gängige Optionen:
- Stand-alone Site (z. B. status.ihrefirma.com): klare Trennung und oft ausfallsicherer
- Subpath (z. B. /status): einfachere Markenführung und Analytics
Wenn Ihre Haupt-App ausfallen kann, ist eine eigenständige Statusseite meist sicherer. Sie können trotzdem prominent von Ihrer App und Ihrem Help-Center darauf verlinken (z. B. /help).
Dienste abbilden und Komponentenstatus-Modell erstellen
Eine Statusseite ist nur so nützlich wie die „Karte“, die dahintersteht. Bevor Sie Farben wählen oder Texte schreiben, entscheiden Sie, worüber Sie tatsächlich berichten. Ziel ist es, widerzuspiegeln, wie Kunden Ihr Produkt erleben — nicht, wie Ihre Organisationsstruktur aussieht.
Mit einem Komponenten-Inventar beginnen
Listen Sie die Teile auf, die ein Kunde meinen könnte, wenn er sagt „es ist kaputt“. Für viele SaaS-Produkte ist ein praktischer Ausgangspunkt:
- API
- Web App
- Dashboard / Admin
- Authentifizierung (Login, SSO)
- Billing
- Integrationen (Slack, Salesforce, Webhooks usw.)
Wenn Sie mehrere Regionen oder Tiers anbieten, erfassen Sie das ebenfalls (z. B. „API – US“ und „API – EU“). Wählen Sie für Kunden verständliche Namen: „Login“ ist klarer als „IdP Gateway".
Gruppierung der Komponenten entscheiden
Wählen Sie eine Gruppierung, die der Denkweise der Kunden entspricht:
- Nach Produkt: sinnvoll, wenn Sie unterschiedliche Angebote haben (Produkt A vs. Produkt B)
- Nach Region: sinnvoll, wenn die Verfügbarkeit geografisch stark variiert
- Nach Funktion/Workflow: sinnvoll, wenn Kunden auf bestimmte Jobs angewiesen sind (Reporting, Imports, Notifications)
Vermeiden Sie eine endlose Liste. Wenn Sie Dutzende Integrationen haben, überlegen Sie, eine übergeordnete Komponente („Integrationen") plus einige besonders wichtige Kinder (z. B. „Salesforce“, „Webhooks") anzuzeigen.
Statusstufen definieren (und was sie bedeuten)
Ein einfaches, konsistentes Modell verhindert Verwirrung während Vorfällen. Gängige Stufen sind:
- Operational: funktioniert wie erwartet
- Degraded Performance: langsamer als üblich oder intermittierende Fehler
- Partial Outage: ein relevanter Teil der Nutzer/Funktionen ist nicht verfügbar
- Major Outage: der Dienst ist großflächig nicht verfügbar
Schreiben Sie interne Kriterien für jede Stufe (auch wenn Sie diese nicht veröffentlichen). Zum Beispiel: „Partial Outage = eine Region ausgefallen“ oder „Degraded = p95-Latenz über X für Y Minuten“. Konsistenz schafft Vertrauen.
Abhängigkeiten erfassen — und entscheiden, was angezeigt wird
Die meisten Ausfälle involvieren Drittanbieter: Cloud-Hosting, E-Mail-Zustellung, Zahlungsdienstleister oder Identitätsanbieter. Dokumentieren Sie diese Abhängigkeiten, damit Ihre Incident-Updates korrekt sind.
Ob Sie diese öffentlich anzeigen, hängt vom Publikum ab. Wenn Kunden direkt betroffen sein können (z. B. Zahlungen), kann das Anzeigen einer Abhängigkeitskomponente hilfreich sein. Wenn es nur Rauschen erzeugt oder Schuldzuweisungen fördert, halten Sie Abhängigkeiten intern, verweisen Sie aber in Updates bei Bedarf darauf (z. B. „Wir untersuchen erhöhte Fehler beim Zahlungsanbieter").
Sobald Sie dieses Komponentenmodell haben, wird der Rest der Einrichtung viel einfacher: Jeder Vorfall hat von Anfang an ein klares „wo" (Komponente) und „wie schlimm" (Status).
Eine einfache, kundenfreundliche Statusseite gestalten
Eine Statusseite ist am nützlichsten, wenn sie Kundenfragen in Sekunden beantwortet. Besucher sind oft gestresst und wollen Klarheit — keine umfangreiche Navigation.
Beginnen Sie mit dem, was Kunden zuerst brauchen
Priorisieren Sie das Wesentliche oben:
- Aktueller Zustand: Operational, Degraded oder Down?
- Auswirkung: Was ist betroffen (wer/region/funktionen) und was Nutzer erleben könnten
- ETA (falls vorhanden): Vorsicht — geben Sie nur Schätzungen an, die Sie verteidigen können
- Nächstes Update: Eine spezifische Zusage wie „Nächstes Update bis 14:30 UTC" reduziert wiederholte Tickets
Schreiben Sie in klarer Sprache. „Erhöhte Fehlerrate bei API-Anfragen" ist klarer als „Partial outage in upstream dependency". Wenn technische Begriffe nötig sind, fügen Sie eine kurze Übersetzung hinzu („Einige Anfragen können fehlschlagen oder timeouts erzeugen").
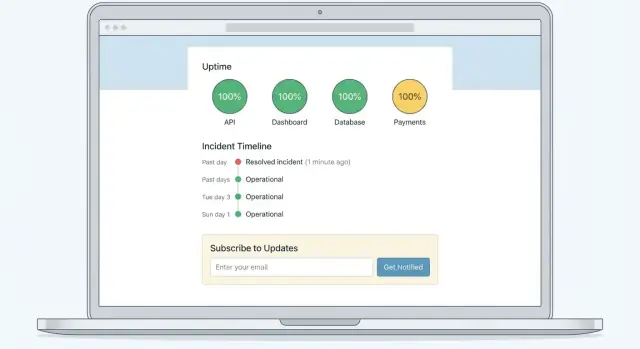
Ein einfaches, übersichtliches Layout verwenden
Ein verlässliches Muster ist:
- Top-Banner für den Gesamtstatus (All Systems Operational / Degraded Performance / Major Outage)
- Komponentenliste mit klaren Statusanzeigen (Web App, API, Billing, Integrationen usw.)
- Aktive Vorfälle und geplante Wartungen direkt darunter, sortiert nach neuestem Update
Für die Komponentenliste behalten Sie kundenfreundliche Bezeichnungen. Wenn Ihr interner Service „k8s-cluster-2" heißt, brauchen Kunden vermutlich „API" oder „Background Jobs".
Barrierefreiheit und Mobile-Grundlagen
Machen Sie die Seite in Stresssituationen lesbar:
- Starker Kontrast und Textlabels (verlassen Sie sich nicht nur auf Farbe)
- Klare Icons mit konsistenter Bedeutung (z. B. grün = operational, gelb = degraded, rot = outage)
- Mobile-freundliche Abstände und Touch-Ziele; viele Nutzer prüfen den Status vom Smartphone
Schnelle Links dort hinzufügen, wo Nutzer sie erwarten
Platzieren Sie eine kleine Linkgruppe in der Nähe des Tops (Header oder direkt unter dem Banner):
- Subscribe (für E-Mail/SMS/Webhook-Benachrichtigungen)
- Incident History (für vergangene Vorfälle und Zeitleisten)
- Contact Support unter /support
Ziel ist Vertrauen: Kunden sollten sofort verstehen, was passiert, was betroffen ist und wann sie wieder von Ihnen hören.
Vorlagen für Vorfall- und Wartungsupdates erstellen
Wenn ein Vorfall eintritt, jongliert Ihr Team mit Diagnose, Behebung und Kundenfragen gleichzeitig. Vorlagen nehmen die Unsicherheit weg, sodass Updates konsistent, klar und schnell bleiben — besonders wenn verschiedene Personen posten.
Felder definieren, die Sie immer veröffentlichen
Ein gutes Update beginnt jedes Mal mit denselben Kerninformationen. Mindestens standardisieren Sie diese Felder, damit Kunden schnell erfassen, was los ist:
- Vorfall-Startzeit (mit Zeitzone)
- Betroffene Komponenten/Services (abgebildet nach Ihrem Statusmodell)
- Kundenwirkung (wer ist betroffen und wie)
- Aktueller Status (Investigating, Identified, Monitoring, Resolved)
- Updates-Log (mit Zeitstempeln)
- Endzeit (wenn der Dienst wieder normal läuft)
Wenn Sie eine Vorfallhistorie veröffentlichen, macht die Konsistenz dieser Felder vergangene Vorfälle leicht vergleichbar.
Eine einfache, wiederholbare Incident-Update-Vorlage
Zielen Sie auf kurze Updates, die stets dieselben Fragen beantworten. Hier eine praktische Vorlage, die Sie in Ihr Status-Tool kopieren können:
Title: Kurz und präzise (z. B. „API-Fehler in EU-Region")
Start time: YYYY-MM-DD HH:MM (TZ)
Affected components: API, Dashboard, Payments
Impact: Was Nutzer sehen (Fehler, Timeouts, degradierte Performance) und wer betroffen ist
What we know: Ein Satz zur Ursache falls bestätigt (keine Spekulationen)
What we’re doing: Konkrete Maßnahmen (Rollback, Skalierung, Vendor-Eskalation)
Next update: Zeit des nächsten geplanten Updates
Updates:
- HH:MM (TZ) — Investigating: …
- HH:MM (TZ) — Identified: …
- HH:MM (TZ) — Monitoring: …
- HH:MM (TZ) — Resolved: …
Update-Kadenz-Regeln festlegen
Kunden wollen nicht nur Informationen — sie wollen Vorhersehbarkeit.
- Bei großen Vorfällen verpflichten Sie sich zu Updates alle 30–60 Minuten, auch wenn die Mitteilung lautet: „Wir untersuchen weiterhin; kein ETA; nächstes Update um X."
- Bei kleineren Problemen können Updates seltener sein, aber geben Sie immer eine versprochene „nächste Update“-Zeit an.
- Wenn Sie die Kadenz nicht einhalten können, posten Sie schnell eine kurze Notiz, die den Verzug erklärt und Erwartungen neu setzt.
Wartungsankündigungs-Vorlagen hinzufügen
Geplante Wartung sollte ruhig und strukturiert wirken. Standardisieren Sie Wartungsbeiträge mit:
- Wartungsfenster: Start-/Endzeit (mit Zeitzone)
- Erwartete Auswirkungen: none / degraded / intermittent / downtime
- Betroffene Komponenten
- Kundenaktionen (falls nötig): „Keine Aktion erforderlich" oder klare Schritte
- Erinnerungs-Updates: kurze Mitteilung beim Beginn und eine weitere nach Ende
Halten Sie die Sprache spezifisch (was sich ändert, was Nutzer bemerken könnten) und versprechen Sie nicht zu viel — Kunden schätzen Genauigkeit mehr als Optimismus.
Eine Vorfallhistorie erstellen, die leicht zu scannen ist
Eine Vorfallhistorie ist mehr als ein Log — sie ermöglicht Kunden (und Ihrem Team), schnell zu verstehen, wie oft Probleme auftreten, welche Arten von Problemen sich wiederholen und wie Sie reagieren.
Warum sich Vorfallhistorie lohnt
Eine klare Historie schafft Vertrauen durch Transparenz. Sie erzeugt auch Trend-Sichtbarkeit: Wiederkehrende „API-Latenz“-Vorfälle alle paar Wochen signalisieren, dass in Performance investiert werden sollte (und priorisieren Post-Incident-Reviews). Konsistente Berichterstattung reduziert langfristig Support-Tickets, weil Kunden Antworten selbst finden.
Aufbewahrungsdauer entscheiden: Wie weit zurück?
Wählen Sie eine Retentions-Periode, die zu Kundenerwartungen und Produktreife passt.
- 90 Tage: üblich für Early-Stage SaaS, hält die Seite schlank
- 6–12 Monate: besser für Enterprise-Kunden, die Zuverlässigkeit bewerten
- Länger: Überlegen Sie, ältere Einträge in eine separate Archivseite zu exportieren, wenn die Timeline zu unübersichtlich wird
Was auch immer Sie wählen, geben Sie es klar an (z. B. „Vorfallhistorie wird 12 Monate aufbewahrt").
Jeder Eintrag sollte sofort verständlich sein
Konsistenz erleichtert das Scannen. Verwenden Sie ein vorhersehbares Namensformat wie:
YYYY-MM-DD — Kurze Zusammenfassung (z. B. „2025-10-14 — Verzögerte E-Mail-Zustellung")
Zeigen Sie für jeden Vorfall mindestens:
- betroffene Komponenten
- Start-/Endzeit (mit Zeitzone)
- Impact-Level (minor/major)
- eine kurze Abschlussnotiz
Bei Bedarf auf tiefere Analysen verlinken
Wenn Sie Postmortems veröffentlichen, verlinken Sie von der Vorfalldetailseite zum Bericht (z. B. „Read the postmortem" verlinkt zu /blog/postmortems/2025-10-14-email-delays). So bleibt die Timeline übersichtlich, während interessierte Kunden Details finden.
Abonnements und Benachrichtigungen hinzufügen
Eine Statusseite hilft nur, wenn Kunden daran denken, sie zu prüfen. Abonnements kehren das um: Kunden erhalten Updates automatisch, ohne die Seite zu aktualisieren oder den Support zu fragen.
Bieten Sie die Kanäle an, die Kunden bereits nutzen
Die meisten Teams bieten mindestens ein paar Optionen an:
- E-Mail (Standard für viele Kunden)
- SMS (für dringende, hochrelevante Alerts)
- Slack oder Microsoft Teams (ideal für Geschäftskunden und Ops-Teams)
- RSS/Atom (bei technischen Nutzern und für interne Tools beliebt)
Wenn Sie mehrere Kanäle unterstützen, gestalten Sie den Setup-Prozess konsistent, damit sich Kunden nicht fühlen, als müssten sie vier verschiedene Anmeldungen durchführen.
Opt-in und Präferenzen klar machen
Abonnements sollten immer opt-in sein. Machen Sie deutlich, was Nutzer erhalten, bevor sie bestätigen — besonders bei SMS.
Geben Sie Abonnenten Kontrolle über:
- Umfang: alle Vorfälle vs. nur ausgewählte Komponenten (z. B. „API" aber nicht „Marketing-Site")
- Typ: nur Vorfälle, nur Wartung oder beides
- Schweregrad (optional): nur „Major outage" vs. „Alle Updates"
Diese Präferenzen reduzieren Alert-Fatigue und halten Ihre Benachrichtigungen vertrauenswürdig. Falls Sie noch keine komponentenspezifischen Abos haben, starten Sie mit „Alle Updates" und fügen Filter später hinzu.
Verhindern, dass Benachrichtigungen genau dann ausfallen, wenn sie gebraucht werden
Während eines Vorfalls steigt die Nachrichtenmenge und Drittanbieter können Traffic drosseln. Prüfen Sie:
- Zustellbarkeit: SPF/DKIM/DMARC für E-Mail; verifizierte Absenderdomains; erkennbare „from"-Adressen
- Rate-Limits und Throttling: Limits Ihres E-Mail-/SMS-Anbieters, Slack/Teams-Webhook-Limits und Retry-Verhalten
- Fallbacks: Wenn Slack-Posts fehlschlagen, wird trotzdem gemailt? Wenn SMS verzögert sind, zeigen Sie ein klares Banner auf der Status-Homepage?
Es lohnt sich, regelmäßige Tests (z. B. quartalsweise) durchzuführen, um sicherzustellen, dass Abonnements wie erwartet funktionieren.
„Subscribe to updates" so platzieren, dass es niemand übersehen kann
Fügen Sie einen deutlichen Callout auf der Status-Homepage hinzu — möglichst above the fold — damit Kunden sich vor dem nächsten Vorfall anmelden können. Machen Sie ihn auf Mobilgeräten sichtbar und verlinken Sie ihn an Stellen, an denen Kunden Hilfe suchen (z. B. im Support-Portal oder /help Center).
Die Entscheidung, wie Sie Ihre Statusseite bauen, geht weniger um „Können wir es bauen?“ und mehr darum, worauf Sie optimieren möchten: Zeit bis zum Launch, Zuverlässigkeit bei Vorfällen und laufender Wartungsaufwand.
Ein gehostetes Tool ist meist der schnellste Weg. Sie erhalten eine fertige Statusseite, Abonnements, Vorfallszeitleisten und oft Integrationen mit gängigen Monitoring-Systemen.
Worauf Sie bei einem gehosteten Tool achten sollten:
- Zuverlässigkeit und Unabhängigkeit: Die Statusseite sollte erreichbar bleiben, selbst wenn Ihre Haupt-App ausfällt
- API und Automatisierung: Vorfälle erstellen, Komponenten updaten und Fortschrittsupdates per API/Webhooks posten
- Zugriffssteuerung: Rollen für „wer kann veröffentlichen" vs. „wer kann Entwürfe erstellen"; SSO ist ein Plus
- Branding und Custom Domain: Ihr Logo/Farben und eine Domain wie status.ihrefirma.com
- Analytics: Abonnentenanzahl, Aufrufe von Updates und E-Mail-Zustellungsmetriken
- Compliance: Audit-Logs und Retention, falls Sie in regulierten Umgebungen arbeiten
Option 2: Selbst bauen (DIY)
DIY kann sinnvoll sein, wenn Sie volle Kontrolle über Design, Datenaufbewahrung und Vorfallhistorie haben möchten. Der Kompromiss ist, dass Sie für Zuverlässigkeit und Betrieb verantwortlich sind.
Eine praktikable DIY-Architektur ist:
- Statische Seite (schnell, cache-freundlich) für UI und Vorfallhistorie
- API-gestützte Datenquelle (oder ein leichtes CMS) zur Speicherung von Vorfällen, Komponenten und Updates
- Aggressive Caching + CDN, damit die Statusseite auch bei Traffic-Spitzen schnell bleibt
Planen Sie Ausfallfälle ein: Was passiert, wenn Ihre Primärdatenbank nicht verfügbar ist oder Ihre Deploy-Pipeline ausfällt? Viele Teams hosten die Statusseite auf separater Infrastruktur (oder sogar bei einem anderen Anbieter) als das Hauptprodukt.
Wenn Sie die Kontrolle von DIY wollen, aber nicht alles neu bauen möchten, kann eine Chat-gesteuerte Plattform wie Koder.ai helfen, schnell eine maßgeschneiderte Statusseite (Web-UI plus kleine Incident-API) aus einer Spezifikation zu erstellen. Das ist nützlich für Teams, die ein spezifisches Komponentenmodell, individuelles Vorfallhistorie-UX oder interne Admin-Workflows möchten — und trotzdem den Quellcode exportieren, deployen und schnell iterieren wollen.
Kostenplanung
Gehostete Tools haben oft vorhersehbare monatliche Preise; DIY hat Engineering-Zeit, Hosting-/CDN-Kosten und laufenden Wartungsaufwand. Wenn Sie Optionen vergleichen, legen Sie die erwarteten monatlichen Kosten und die interne Zeit fest — und prüfen Sie das gegen Ihr Budget (siehe /pricing).
Monitoring und Incident-Workflow verbinden
Eine Statusseite ist nur nützlich, wenn sie die Realität schnell widerspiegelt. Der einfachste Weg ist, die Systeme, die Probleme erkennen (Monitoring), mit denen zu verbinden, die Ihre Reaktion koordinieren (Incident-Workflow), damit Updates konsistent und zeitnah sind.
Woher Status-Updates kommen sollten
Die meisten Teams kombinieren drei Datenquellen:
- Monitoring-Alerts (Health Checks, Synthetische Tests, Fehlerraten, Latenz, Queue-Tiefe). Diese sind gut zur Erkennung, beschreiben aber nicht immer den Kundenimpact.
- Manuelle Updates durch die on-call/Support-Teams. Menschen fügen Kontext hinzu: wer ist betroffen, welche Workarounds es gibt, was sich geändert hat.
- Incident-Management-Tools (PagerDuty, Opsgenie, Jira Service Management etc.). Diese liefern die Timeline, Rollen und Resolutionsnotizen, die Ihre Statusseite zusammenfassen kann.
Eine praktische Regel: Monitoring erkennt; Incident-Workflow koordiniert; die Statusseite kommuniziert.
Automatisierung, die hilft (ohne zu viel zu versprechen)
Automatisierung spart Minuten, wenn es zählt:
- Incident aus einem Alert erstellen, wenn ein hoher Monitor auslöst (z. B. „API-Fehlerrate > 5% für 5 Minuten"). Titel, betroffene Komponenten und anfängliche Schwere können vorausgefüllt werden.
- Komponenten aus Health-Checks updaten für objektive Signale (z. B. „Web App: Degraded Performance" wenn Latenz-Schwellen überschritten werden).
- Status-Änderungen in Ihren Incident-Channel synchronisieren (Slack/Teams), damit Mitarbeitende sehen, was Kunden sehen.
Halten Sie die erste öffentliche Nachricht konservativ. „Untersuchung erhöhter Fehlerraten" ist sicherer als „Ausfall bestätigt", wenn Sie noch validieren.
Nicht alles automatisch ohne menschliche Prüfung veröffentlichen
Vollautomatische Nachrichten können nach hinten losgehen:
- Ein lauter Alert kann falsche Vorfälle posten.
- Ein partieller Fehler kann einen Dienst „down" erscheinen lassen, obwohl Kunden nicht betroffen sind.
- Auto-resolved Updates können einen Vorfall schließen, während Nutzer noch betroffen sind.
Nutzen Sie Automatisierung, um Entwürfe und Vorschläge zu erstellen, verlangen Sie aber eine menschliche Freigabe für kundenseitige Formulierungen — besonders für Zustände wie Identified, Mitigated und Resolved.
Audit-Trail führen
Behandeln Sie die Statusseite wie ein kundenorientiertes Logbuch. Stellen Sie sicher, dass Sie beantworten können:
- Wer hat den Vorfallsstatus geändert?
- Was wurde geändert (Text, Komponenten, Zeitstempel)?
- Wann wurde es geändert?
Dieser Audit-Trail hilft bei Post-Incident-Reviews, reduziert Verwirrung bei Übergaben und schafft Vertrauen, wenn Kunden Klarstellungen wünschen.
Zuverlässigkeit: Hosting, DNS und Ausfallsicherheit
Eine Statusseite hilft nur, wenn sie erreichbar ist, während Ihr Produkt nicht erreichbar ist. Der häufigste Fehler ist, die Statusseite auf derselben Infrastruktur wie die App zu hosten — wenn die App ausfällt, verschwindet auch die Statusseite und Kunden haben keine Quelle der Wahrheit mehr.
Von Ihrem Core-Stack isolieren
Hosten Sie die Statusseite wenn möglich bei einem anderen Anbieter als Ihre Produktions-App (oder zumindest in einem anderen Account/Region). Ziel ist es, die Blast-Radius-Separation zu reduzieren: Ein Ausfall auf Ihrer App-Plattform sollte nicht gleichzeitig Ihre Kommunikationskanäle lahmlegen.
Überlegen Sie außerdem, DNS zu trennen. Wenn die DNS der Hauptdomain im selben Ort wie Ihr App-Edge/CDN verwaltet wird, kann ein DNS- oder Zertifikatsproblem beide blockieren. Viele Teams verwenden eine eigene Subdomain (z. B. status.ihrefirma.com) mit separat gehostetem DNS.
Die Seite schnell und resilient machen
Halten Sie Assets leichtgewichtig: minimales JavaScript, komprimiertes CSS und keine Abhängigkeiten, die die APIs Ihrer App zum Rendern benötigen. Legen Sie ein CDN vor die Statusseite und aktivieren Sie Caching für statische Ressourcen, sodass sie auch bei hohem Traffic lädt.
Ein praktisches Sicherheitsnetz ist ein Fallback-Static-Modus:
- Das zuletzt bekannte Status- und Incident-Banner prerendern
- Von Objektspeicher oder statischem Hosting ausliefern
- Dynamisch updaten, wenn Systeme gesund sind, aber bei Problemen graceful degradieren
Öffentlich standardmäßig, mit sicherem Admin-Zugang
Kunden sollten sich nicht einloggen müssen, um die Service-Gesundheit zu sehen. Halten Sie die Statusseite öffentlich, aber legen Sie Admin-/Editor-Tools hinter Authentifizierung (SSO, falls vorhanden) mit starken Zugriffsregeln und Audit-Logs.
Testen Sie schließlich Ausfallszenarien: Sperren Sie in einer Staging-Umgebung vorübergehend Ihren App-Origin und prüfen Sie, ob die Statusseite weiterhin aufgelöst wird, schnell lädt und aktualisiert werden kann, wenn Sie sie am dringendsten benötigen.
Operativer Prozess: Wer updatet und wann
Eine Statusseite baut nur Vertrauen auf, wenn sie während echter Vorfälle konsistent aktualisiert wird. Diese Konsistenz entsteht nicht zufällig — Sie brauchen klare Verantwortung, einfache Regeln und eine vorhersehbare Kadenz.
Rollen definieren (bevor etwas schiefgeht)
Halten Sie das Kernteam klein und explizit:
- Incident Commander (IC): leitet die Reaktion, entscheidet über Priorität und bestätigt, wann Sie stabil sind
- Communications Lead: postet Updates auf der Statusseite und sorgt für kundenfreundliche Formulierungen
- On-Call Engineers: untersuchen, beheben und liefern bestätigte Fakten an den IC
Bei kleinen Teams kann eine Person zwei Rollen übernehmen — entscheiden Sie das im Voraus. Dokumentieren Sie Rollenhandoffs und Eskalationswege im On-Call-Handbuch (siehe /docs/on-call).
Einfache Update-Checkliste für jeden Vorfall
Wenn ein Alert zu einem kundenrelevanten Vorfall wird, folgen Sie einem wiederholbaren Ablauf:
- Acknowledge: schnelles „Investigating"-Update posten (auch bei begrenzten Details)
- Impact einschätzen: bestätigen, welche Komponenten, Regionen oder Kundensegmente betroffen sind
- Update posten: was Nutzer bemerken, Workarounds (falls vorhanden) und wann das nächste Update kommt
- Resolve: bestätigen, dass der Dienst wiederhergestellt ist und was weiter überwacht wird
- Recap: kurze Zusammenfassung hinzufügen und auf das vollständige Review verlinken, wenn verfügbar
Eine praktische Regel: posten Sie das erste Update innerhalb von 10–15 Minuten, dann alle 30–60 Minuten solange der Impact besteht — auch wenn die Botschaft lautet „Kein Fortschritt, wir untersuchen weiterhin."
Nach der Wiederherstellung: Review und Verbesserung
Führen Sie innerhalb von 1–3 Arbeitstagen ein leichtes Post-Incident-Review durch:
- Timeline: Schlüsselmomente von Erkennung bis Wiederherstellung
- Root Cause (best-knowledge): in einfacher Sprache erklären
- Action Items: konkrete Fixes, Verantwortliche und Fälligkeiten
Aktualisieren Sie dann den Vorfall-Eintrag mit der finalen Zusammenfassung, damit Ihre Vorfallhistorie nützlich bleibt — nicht nur ein Log von „resolved"-Nachrichten.
Launch-Checklist und laufende Verbesserungen
Eine Statusseite ist nur nützlich, wenn sie leicht zu finden, vertrauenswürdig und konsequent aktuell ist. Bevor Sie sie ankündigen, führen Sie einen kurzen „production-ready"-Check durch — und legen Sie danach eine leichte Routine zur Verbesserung fest.
Launch-Checkliste (praktisch)
Text und Struktur
- Prüfen Sie, dass Ihre Komponentennamen zu dem passen, was Kunden erkennen (z. B. „Dashboard" statt interner Servicenamen).
- Fügen Sie eine kurze „Was diese Seite zeigt"-Einleitung und einen klaren Link zum Support (/support) für konto-spezifische Probleme hinzu.
- Stellen Sie sicher, dass Vorfall-Updates die Kundenwirkung erklären („Zahlungen schlagen fehl") und nächste Schritte angeben („erneut versuchen nach 10 Minuten").
Branding und Vertrauen
- Logo, Favicon und ein einfaches Farbsystem für Statusanzeigen hinzufügen (vermeiden Sie zu subtile Farbtöne).
- Format und Zeitzone der Zeitstempel klar angeben.
Zugriff und Berechtigungen
- Verifizieren Sie, wer Vorfälle veröffentlichen, Wartungen planen und Seiteneinstellungen editieren darf.
- Richten Sie eine On-Call-Backup-Person ein, damit Updates nicht von einer einzelnen Person blockiert werden.
Workflow testen
- Führen Sie einen Testvorfall durch (als „test" markieren und als gelöst kennzeichnen).
- Abonnieren Sie per E-Mail/SMS und prüfen Sie, ob Benachrichtigungen ankommen und korrekte Links enthalten.
Ankündigen
- Fügen Sie den Statusseiten-Link in Footer der App, Hilfezentrum und Support-Autorespondern hinzu.
- Senden Sie eine kurze Kundenankündigung mit Erklärung, was zu erwarten ist und wie man abonniert.
Wenn Sie eine eigene Statusseite bauen, führen Sie dieselbe Checkliste zunächst in einer Staging-Umgebung durch. Tools wie Koder.ai können diesen Iterationszyklus beschleunigen, indem sie UI, Admin-Screens und Backend-Endpunkte aus einem einzigen Spec generieren — und Ihnen dann erlauben, den Code zu exportieren und überall zu deployen.
Messen, was „besser" bedeutet
Verfolgen Sie einige einfache Kennzahlen und prüfen Sie sie monatlich:
- Reduzierte Tickets: Vorfallbezogene Ticketmengen vor/nach Launch vergleichen
- Schnelleres erstes Update: Zeit von Erkennung bis erstem öffentlichen Update messen
- Abonnentenwachstum: Abonnenten nach Kanal und nach verfolgten Komponenten
Aus Vorfallmustern lernen
Führen Sie eine grundlegende Taxonomie, damit die Historie handlungsfähig wird:
- Taggen Sie Vorfälle nach Kategorie (Performance, Partial Outage, Drittanbieter, Wartung, Security)
- Notieren Sie wiederkehrende Komponenten und Problemverursacher
- Nutzen Sie das, um Fixes zu priorisieren und den Post-Incident-Review-Prozess zu informieren
SEO-Grundlagen (damit Kunden die Seite finden)
- Verwenden Sie klare Seitentitel wie „Service Status" und „Incident History".
- Strukturieren Sie Überschriften (H2/H3) so, dass Historie-Seiten leicht zu scannen sind.
- Bevorzugen Sie indexierbare Vorfallhistorie-Seiten (sofern keine Sicherheits-/Datenschutzgründe dagegen sprechen) und stellen Sie sicher, dass Links zwischen Hauptstatusseite und einzelnen Vorfällen crawlbar sind.
Im Laufe der Zeit addieren sich kleine Verbesserungen — klarere Formulierungen, schnellere Updates, bessere Kategorisierung — zu weniger Unterbrechungen, weniger Tickets und mehr Kundenvertrauen.