23. Okt. 2025·5 Min
Serverseitige vs. clientseitige Filterung: eine Entscheidungs-Checkliste
Checkliste für serverseitige vs. clientseitige Filterung: Entscheiden Sie anhand von Datenmenge, Latenz, Berechtigungen und Caching — ohne UI‑Lecks oder Verzögerungen.
Das eigentliche Problem: Lecks, Verzögerung und inkonsistente Ergebnisse
Filtering in einer UI ist mehr als ein einzelnes Suchfeld. Meist umfasst es mehrere verwandte Aktionen, die alle ändern, was der Nutzer sieht: Textsuche (Name, E‑Mail, Bestell‑ID), Facetten (Status, Eigentümer, Datumsbereich, Tags) und Sortierung (neueste, höchster Wert, letzte Aktivität).
Die zentrale Frage ist nicht, welche Technik „besser“ ist. Sondern: Wo liegt der vollständige Datensatz und wer darf darauf zugreifen. Wenn der Browser Datensätze erhält, die der Nutzer nicht sehen darf, kann die UI sensible Daten offenlegen, selbst wenn Sie sie visuell ausblenden.
Die meisten Debatten über serverseitige vs. clientseitige Filterung sind eigentlich Reaktionen auf zwei Fehler, die Nutzer sofort bemerken:
- Lecks: Daten tauchen in Netzwerk‑Payloads, gecachten Antworten oder durch unerwartete Filter auf, die verborgene Zeilen enthüllen.
- Verzögerung: Der Bildschirm wirkt langsam, weil Sie zu viele Daten senden und das Gerät bei jedem Tastenanschlag schwere Arbeit leisten muss.
Es gibt ein drittes Problem, das endlose Bug‑Reports erzeugt: inkonsistente Ergebnisse. Wenn einige Filter clientseitig und andere serverseitig laufen, sehen Nutzer Zählungen, Seiten und Totals, die nicht übereinstimmen. Das bricht Vertrauen schnell, besonders bei paginierten Listen.
Eine praktische Default‑Regel ist einfach: Wenn der Nutzer keinen Zugriff auf den vollständigen Datensatz haben darf, filtern Sie auf dem Server. Wenn er Zugriff hat und das Dataset klein genug ist, um schnell zu laden, kann clientseitige Filterung in Ordnung sein.
Kurze Definitionen in einfacher Sprache
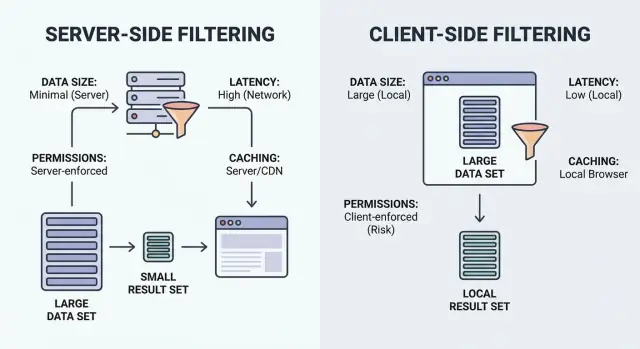
Filterung heißt einfach „zeige mir die Elemente, die passen“. Die Frage ist, wo das Matching passiert: im Browser des Nutzers (Client) oder auf Ihrem Backend (Server).
Clientseitige Filterung läuft im Browser. Die App lädt einen Satz von Datensätzen (oft JSON) herunter und wendet dann lokal Filter an. Es kann sich nach dem Laden sofort anfühlen, funktioniert aber nur, wenn das Dataset klein genug ist, um es zu verschicken und sicher genug ist, um es offenzulegen.
Serverseitige Filterung läuft auf Ihrem Backend. Der Browser sendet Filtereingaben (z. B. status=open, owner=me, createdAfter=Jan 1) und der Server liefert nur die passenden Ergebnisse zurück. In der Praxis ist das meist ein API‑Endpunkt, der Filter akzeptiert, eine Datenbankabfrage baut und eine paginierte Liste plus Totals zurückgibt.
Ein einfaches mentales Modell:
- Clientseitig: viele Daten herunterladen, hier filtern.
- Serverseitig: genau das anfragen, was Sie brauchen.
Hybride Setups sind üblich. Ein gutes Muster ist, „große“ Filter serverseitig durchzusetzen (Berechtigungen, Ownership, Datumsbereich, Suche) und dann kleine UI‑only Umschalter lokal zu nutzen (Archivierte Einträge ausblenden, schnelle Tag‑Chips, Spalten‑Sichtbarkeit) ohne weiteren Request.
Sortierung, Pagination und Suche gehören meist zur selben Entscheidung. Sie beeinflussen Payload‑Größe, Nutzergefühl und welche Daten Sie preisgeben.
Entscheidungsfaktor 1: Datenmenge und Payload‑Kosten
Beginnen Sie mit der praktischsten Frage: Wie viele Daten würden Sie an den Browser senden, wenn Sie clientseitig filtern? Wenn die ehrliche Antwort „mehr als ein paar Bildschirme“ ist, zahlen Sie dafür in Download‑Zeit, Speicherverbrauch und langsameren Interaktionen.
Sie brauchen keine genauen Schätzungen. Holen Sie sich nur die Größenordnung: wie viele Zeilen könnte der Nutzer sehen und wie groß ist eine Zeile im Durchschnitt? Eine Liste mit 500 Items und wenigen kurzen Feldern ist sehr unterschiedlich zu 50.000 Items, bei denen jede Zeile lange Notizen, Rich‑Text oder verschachtelte Objekte enthält.
Breite Datensätze sind die leisen Payload‑Killer. Eine Tabelle kann nach Zeilenanzahl klein wirken, ist aber schwer, wenn jede Zeile viele Felder, große Strings oder gemergte Daten (Kontakt + Firma + letzte Aktivität + vollständige Adresse + Tags) enthält. Selbst wenn Sie nur drei Spalten zeigen, senden Teams oft „alles, nur für den Fall“ und die Payload bläht sich auf.
Denken Sie auch an Wachstum. Ein Dataset, das heute passt, kann nach ein paar Monaten problematisch werden. Wenn die Daten schnell wachsen, betrachten Sie clientseitige Filterung als kurzfristige Abkürzung, nicht als Standard.
Faustregeln:
- Wenn Sie den vollständigen Datensatz über eine typische Mobilverbindung nicht komfortabel senden können, filtern Sie auf dem Server.
- Wenn Nutzer nur selten einen kleinen Ausschnitt brauchen, holen Sie genau diesen Ausschnitt und filtern serverseitig.
- Ist das Dataset klein, stabil und wirklich sicher offenlegbar, fühlt sich clientseitige Filterung großartig an.
Der letzte Punkt betrifft nicht nur Performance. „Können wir das ganze Dataset an den Browser senden?“ ist auch eine Sicherheitsfrage. Wenn die Antwort kein klares Ja ist, senden Sie es nicht.
Entscheidungsfaktor 2: Latenz und Nutzererlebnis
Filterungsentscheidungen scheitern oft am Gefühl, nicht an der Korrektheit. Nutzer messen keine Millisekunden. Sie bemerken Pausen, Flackern und Ergebnisse, die beim Tippen herumhüpfen.
Zeit geht an verschiedenen Stellen verloren:
- Netzwerk: Request/Response‑Zeit und Payload‑Größe
- Server: DB‑Queries, Joins, Sortierung, Berechtigungschecks
- Browser: JSON parsen, Zeilen rendern, große Arrays filtern
Definieren Sie, was „schnell genug“ für diesen Screen bedeutet. Eine Listenansicht braucht möglicherweise reaktionsschnelles Tippen und flüssiges Scrollen, während eine Berichtseite eine kurze Wartezeit verkraftet, solange das erste Ergebnis schnell erscheint.
Beurteilen Sie nicht nur nach Büro‑WLAN. Bei langsamen Verbindungen fühlt sich clientseitige Filterung nach dem ersten Laden großartig an, aber dieser erste Laden könnte sehr langsam sein. Serverseitige Filterung hält Payloads klein, kann sich aber zäh anfühlen, wenn Sie bei jedem Tastendruck eine Anfrage abschicken.
Designen Sie um menschliche Eingabe herum. Debouncen Sie Requests beim Tippen. Für große Ergebnissets nutzen Sie progressives Laden, sodass die Seite schnell etwas zeigt und beim Scrollen glatt bleibt.
Entscheidionsfaktor 3: Berechtigungen und Datenausgabe
Langsame Abfragen in Produktion vermeiden
Fügen Sie maximale Seitengröße, Timeouts und sichere Defaults hinzu, damit Filterung responsiv bleibt.
Berechtigungen sollten Ihre Filterungsentscheidung stärker bestimmen als die Geschwindigkeit. Wenn der Browser jemals Daten erhält, die ein Nutzer nicht sehen darf, haben Sie bereits ein Problem — selbst wenn Sie sie inaktivieren oder eine Spalte einklappen.
Nennen Sie zuerst, was auf diesem Screen sensibel ist. Manche Felder sind offensichtlich (E‑Mails, Telefonnummern, Adressen). Andere werden leicht übersehen: interne Notizen, Kosten oder Marge, Sonderpreisregeln, Risikoscores, Moderationsflags.
Die große Falle ist „wir filtern im Client, zeigen aber nur erlaubte Zeilen“. Das bedeutet immer noch, dass der vollständige Datensatz heruntergeladen wurde. Jeder kann die Netzwerkantwort inspizieren, DevTools öffnen oder die Payload speichern. Spalten in der UI auszublenden ist keine Zugriffskontrolle.
Wann serverseitige Filterung die sichere Default‑Wahl ist
Serverseitige Filterung ist die sichere Default‑Wahl, wenn die Autorisierung pro Nutzer variiert, besonders wenn verschiedene Nutzer verschiedene Zeilen oder Felder sehen können.
Kurzer Check:
- Sehen verschiedene Rollen unterschiedliche Zeilen (nur Team, nur Region, nur zugewiesene)?
- Sehen verschiedene Rollen unterschiedliche Felder (Notizen, Preise, PII)?
- Gibt es zeilenbezogene Regeln (Account‑Owner, Deal‑Stage, „privat“ Flag)?
- Könnten Exporte, Sortierung oder Totals eingeschränkte Infos offenbaren?
- Würde ein geleakter Payload ein Compliance‑Problem erzeugen?
Wenn eine dieser Fragen mit Ja beantwortet wird, halten Sie Filterung und Feldauswahl auf dem Server. Senden Sie nur, was der Nutzer sehen darf, und wenden Sie dieselben Regeln auf Suche, Sortierung, Pagination und Export an.
Beispiel: In einer CRM‑Kontaktliste dürfen Vertriebsmitarbeiter nur ihre eigenen Accounts sehen, Manager alle. Wenn der Browser alle Kontakte herunterlädt und lokal filtert, kann ein Mitarbeiter trotzdem versteckte Accounts aus der Antwort rekonstruieren. Serverseitige Filterung verhindert das, indem diese Zeilen nie gesendet werden.
Entscheidungsfaktor 4: Caching und Aktualität
Caching kann einen Screen sofort wirken lassen. Es kann aber auch die falsche Wahrheit zeigen. Entscheidend ist, was Sie wiederverwenden dürfen, wie lange und welche Ereignisse eine Invalidierung erzwingen.
Beginnen Sie mit der Wahl der Cache‑Einheit. Einen kompletten Listcache anzulegen ist einfach, verschwendet aber meist Bandbreite und wird schnell veraltet. Seitenweise Caching funktioniert gut für Infinite Scroll. Caching von Query‑Ergebnissen (Filter + Sort + Suche) ist genau, kann aber schnell wachsen, wenn Nutzer viele Kombinationen ausprobieren.
Aktualität ist in manchen Bereichen wichtiger als in anderen. Änderungsschnelle Daten (Lagerbestand, Kontostände, Lieferstatus) können bereits nach 30 Sekunden verwirren. Bei langsam ändernden Daten (Archiv, Referenzdaten) sind längere Caches meist in Ordnung.
Planen Sie Invalidierung, bevor Sie coden. Neben Zeitablauf: welche Aktionen müssen ein Refresh erzwingen — Creates/Edits/Deletes, Berechtigungsänderungen, Bulk‑Imports oder Merges, Status‑Übergänge, Undo/Rollback, Hintergrundjobs, die gefilterte Felder verändern.
Entscheiden Sie auch, wo das Caching lebt. Browser‑Speicher macht Zurück/Vorwärts schnell, kann aber Daten über Accounts hinweg leaken, wenn Sie es nicht nach Nutzer und Organisation schlüsseln. Backend‑Caching ist sicherer für Berechtigungen und Konsistenz, muss aber die vollständige Filter‑Signatur und den Aufruferidentifikator enthalten, damit Ergebnisse nicht vermischt werden.
Schritt für Schritt: Wie man für einen neuen Screen entscheidet
Ziel: Der Screen soll schnell wirken, ohne Daten zu leaken.
Ein praktischer Entscheidungsfluss
- Beginnen Sie mit der stärksten Einschränkung. Wenn Zugriff nach Rolle, Team, Region, Org oder Subscription variiert, gewinnen die Berechtigungen. Wenn das Dataset groß ist oder schnell wachsen kann, gewinnt die Größe.
- Default zu serverseitig, wenn Daten groß oder sensibel sind. Wenn Sie den vollständigen Datensatz nicht bequem im Browser-Console‑Log sehen möchten, senden Sie ihn nicht.
- Clientseitige Filterung nur für kleine, sichere, wiederverwendbare Listen. Status‑Dropdowns, kleine Tag‑Listen, eine einzelne Seite bereits genehmigter Ergebnisse.
- Definieren Sie die API‑Form, bevor die UI entsteht. Schreiben Sie Filter, Sortierung, Pagination und Defaults auf, damit Server und UI nicht auseinanderlaufen.
- Fügen Sie Schutzmaßnahmen hinzu. Erzwingen Sie maximale Seitengröße, setzen Sie Timeouts und legen Sie fest, wie die UI sich verhält, wenn Filterung langsam ist (Spinner zeigen, alte Ergebnisse behalten, Retry anbieten).
Häufige Fehler, die zu Lecks oder Verzögerung führen
Den Filtervertrag früh festlegen
Nutzen Sie den Planungsmodus, um Filter, Sortierung, Pagination und Berechtigungen vor dem Bau festzulegen.
Die meisten Teams stolpern über dieselben Muster: Eine UI, die in einer Demo gut aussieht, aber echte Daten, echte Berechtigungen und reale Netzwerkgeschwindigkeiten entlarven die Schwächen.
Fehler, die Daten leaken
Das schwerwiegendste Versagen ist, Filterung als reine Präsentation zu behandeln. Wenn der Browser Datensätze erhält, die er nicht sehen darf, ist bereits etwas verloren.
Zwei häufige Ursachen:
- Den vollständigen Datensatz an den Browser senden und lokal filtern „für die Geschwindigkeit“. Jeder kann die Antwort inspizieren oder im Speicher abfragen.
- Gefilterte Antworten cachen, ohne den Cache‑Schlüssel an Nutzeridentität, Org, Rolle oder Policy‑Version zu binden. Eine Berechtigungsänderung kann alte Daten stillschweigend offenlegen.
Beispiel: Praktikanten dürfen nur Leads aus ihrer Region sehen. Wenn die API alle Regionen zurückliefert und das Dropdown in React lokal filtert, können Praktikanten trotzdem die komplette Liste extrahieren.
Fehler, die den Screen langsam machen
Verzögerung kommt oft von falschen Annahmen:
- Annahme, dass clientseitige Filterung immer schneller ist. Bei 50.000 Zeilen kann das Herunterladen und Parsen länger dauern als eine fokussierte Abfrage.
- Pagination und Ladezustände vergessen. Ein Screen, der beim Rendern einer riesigen Liste blockiert, fühlt sich kaputt an, selbst wenn die Query korrekt ist.
Ein subtiler, aber schmerzhafter Fehler sind nicht übereinstimmende Regeln. Wenn der Server „starts with“ anders behandelt als die UI, sehen Nutzer Zählungen, die nicht passen, oder Elemente, die nach einem Refresh verschwinden.
Schnelle Checkliste vor dem Release
Machen Sie einen finalen Durchgang mit zwei Denkweisen: ein neugieriger Nutzer und ein schlechter Netztag.
- Payload‑Sanity: Bestätigen Sie, dass Antworten niemals Zeilen oder Felder enthalten, die der Nutzer nicht sehen darf, selbst wenn die UI sie ausblendet. Achten Sie auf Totals, Gruppenzählungen oder IDs, mit denen jemand eingeschränkte Daten ableiten könnte.
- Sicheres Logging: Filter enthalten oft E‑Mails, Namen oder IDs. Protokollieren Sie keine sensiblen Filterwerte, kein komplettes SQL oder komplette Request‑Bodies an Orte, die viele Leute einsehen können.
- Konsistenz über Geräte: Wenden Sie dieselben Filter auf Desktop und Mobile an. Unterschiede entstehen oft durch clientseitige Sortierung, Locale‑Regeln (Groß/Kleinschreibung, Akzente) oder Default‑Werte.
- Klare Zustände: Lade-, Leer‑ und Fehlerzustände sollten eindeutig sein. Testen Sie schnelle Änderungen (Tippen, Rückschritt, Umschalter), damit die UI nicht flackert oder veraltete Ergebnisse zeigt.
- Worst‑Case Schutz: Maximale Seitengröße, maximaler Datumsbereich und Timeouts. Schützen Sie gegen teure Abfragen (Wildcards, zu viele OR‑Bedingungen, nicht indizierte Felder).
Ein einfacher Test: Erstellen Sie einen eingeschränkten Datensatz und bestätigen Sie, dass er niemals in Payload, Totals oder Cache auftaucht, selbst wenn Sie breit filtern oder Filter löschen.
Beispiel: eine CRM‑Kontaktliste
Fehlende Übereinstimmung bei Counts und Seiten beheben
Erzeugen Sie konsistente Totals und Seiten, indem Sie Sortierung und Pagination im Backend belassen.
Stellen Sie sich ein CRM mit 200.000 Kontakten vor. Vertriebsmitarbeiter sehen nur ihre Accounts, Manager ihr Team, Admins alles. Der Screen bietet Suche, Filter (Status, Owner, letzte Aktivität) und Sortierung.
Clientseitige Filterung scheitert hier schnell. Die Payload wird schwer, der erste Ladevorgang langsam und das Risiko eines Datenlecks hoch. Selbst wenn die UI Zeilen ausblendet, hat der Browser die Daten bereits empfangen. Außerdem belasten Sie das Gerät: große Arrays, schwere Sortierung, wiederholte Filterläufe, hoher Speicherverbrauch und Abstürze auf älteren Phones.
Sicherer ist serverseitige Filterung mit Pagination. Der Client sendet Filterentscheidungen und Suchtext, der Server liefert nur die Zeilen, die der Nutzer sehen darf, bereits gefiltert und sortiert.
Ein praktisches Muster:
- Berechtigungen zuerst anwenden, dann Filter und Sortierung.
- Eine Seite auf einmal zurückgeben (z. B. 50 Zeilen) plus eine Gesamtanzahl.
- Vorsichtig cachen (pro Nutzer oder pro Rolle), damit Ergebnisse nicht über Berechtigungen hinweg vermischt werden.
Eine kleine Ausnahme, in der clientseitige Filterung in Ordnung ist: winzige, statische Daten. Ein Dropdown „Kontaktstatus“ mit 8 Werten kann einmal geladen und lokal gefiltert werden, mit geringem Risiko oder Kosten.
Nächste Schritte: Entscheidungen dokumentieren und weniger neu schreiben müssen
Teams werden nicht dadurch abgebrannt, dass sie einmal die „falsche“ Wahl treffen. Sie werden abgebrannt, weil auf jedem Screen eine andere Entscheidung fällt und dann versucht wird, Lecks und langsame Seiten unter Druck zu beheben.
Schreiben Sie eine kurze Entscheidungsnotiz pro Screen: Dataset‑Größe, Kosten des Sendens, was „schnell genug“ ist, welche Felder sensibel sind und wie Ergebnisse gecacht werden sollen (oder nicht). Halten Sie Server und UI auf derselben Seite, damit Sie nicht zwei Wahrheiten für Filterung haben.
Wenn Sie schnell Bildschirme in Koder.ai (koder.ai) bauen, lohnt es sich, vorher zu entscheiden, welche Filter auf dem Backend durchgesetzt werden müssen (Berechtigungen und zeilenbasiertes Zugriffsrecht) und welche kleinen UI‑only Umschalter in der React‑Schicht bleiben können. Diese eine Entscheidung verhindert meistens die teuersten Rewrites später.
FAQ
Wann sollte ich serverseitige Filterung statt clientseitiger Filterung einsetzen?
Standardmäßig serverseitig filtern, wenn Nutzer unterschiedliche Berechtigungen haben, das Dataset groß ist oder Sie konsistente Pagination und Totals benötigen. Clientseitig nur verwenden, wenn das komplette Dataset klein, unkritisch und schnell herunterladbar ist.
Warum ist clientseitige Filterung ein Sicherheitsrisiko, selbst wenn ich Zeilen in der UI ausblende?
Weil alles, was der Browser erhält, einsehbar ist. Selbst wenn Sie Zeilen oder Spalten in der UI ausblenden, kann ein Nutzer Netzwerkantworten, gecachte Payloads oder im Speicher gehaltene Objekte inspizieren.
Was verursacht, dass Filterung für Nutzer träge wirkt?
Meistens passiert es, weil Sie zu viele Daten versenden und dann bei jedem Tastenanschlag große Arrays filtern/sortieren lassen oder weil Sie bei jedem Anschlag eine Server-Anfrage ohne Debounce schicken. Halten Sie Payloads klein und vermeiden Sie schwere Arbeit bei jeder Eingabeänderung.
Wie vermeide ich inkonsistente Ergebnisse beim Mischen von Client- und Server-Filterung?
Halten Sie eine einzige Quelle der Wahrheit für die „echten“ Filter: Berechtigungen, Suche, Sortierung und Pagination sollten gemeinsam auf dem Server durchgesetzt werden. Begrenzen Sie clientseitische Logik auf kleine UI-only Umschalter, die das zugrunde liegende Dataset nicht verändern.
Was ist die sicherste Art, gefilterte Listen zu cachen?
Clientseitiges Caching kann veraltete oder falsche Daten anzeigen und über Accounts hinweg leaken, wenn der Cache-Schlüssel nicht richtig ist. Serverseitiges Caching ist sicherer für Berechtigungen, muss aber die vollständige Filter-Signatur und die Identität des Aufrufers enthalten.
Wie schätze ich, ob ein Dataset „klein genug" für clientseitige Filterung ist?
Stellen Sie zwei Fragen: Wie viele Zeilen kann ein Nutzer realistisch haben und wie groß ist eine Zeile in Bytes? Wenn Sie es auf einer typischen Mobilverbindung oder auf älteren Geräten nicht bequem laden würden, verschieben Sie die Filterung auf den Server und verwenden Sie Pagination.
Was ist, wenn unterschiedliche Rollen unterschiedliche Zeilen oder Felder sehen können?
Serverseitig. Wenn Rollen, Teams, Regionen oder Ownership-Regeln beeinflussen, was jemand sehen darf, muss der Server Zeilen- und Feldzugriff durchsetzen. Der Client darf nur die Datensätze und Felder erhalten, die der Nutzer sehen darf.
Wie sollte ich die API für serverseitige Filterung gestalten?
Definieren Sie zuerst Vertrag und Form der API: akzeptierte Filterfelder, Standard-Sortierung, Pagination-Regeln und wie Suche gematcht wird (Groß-/Kleinschreibung, Akzente, Teilmatches). Implementieren Sie dann dieselbe Logik konsistent im Backend und testen Sie, dass Totals und Seiten übereinstimmen.
Wie kann ich serverseitige Filterung UI-schnell erscheinen lassen?
Debouncen Sie die Eingabe, damit Sie nicht auf jeden Tastenanschlag anfragen, und behalten Sie alte Ergebnisse sichtbar, bis neue eintreffen, um Flackern zu vermeiden. Nutzen Sie Pagination oder progressive Laden, damit der Nutzer schnell etwas sieht, ohne auf eine riesige Antwort warten zu müssen.
Was ist ein guter Ansatz für eine CRM-Liste mit vielen Datensätzen und strikten Berechtigungen?
Wenden Sie zuerst Berechtigungen an, dann Filter und Sortierung, und geben Sie nur eine Seite plus eine Gesamtanzahl zurück. Vermeiden Sie das Senden „zusätzlicher Felder für den Fall“ und stellen Sie sicher, dass Cache-Schlüssel Nutzer/Org/Rolle enthalten, damit z. B. ein Vertriebsmitarbeiter niemals Daten eines Managers erhält.