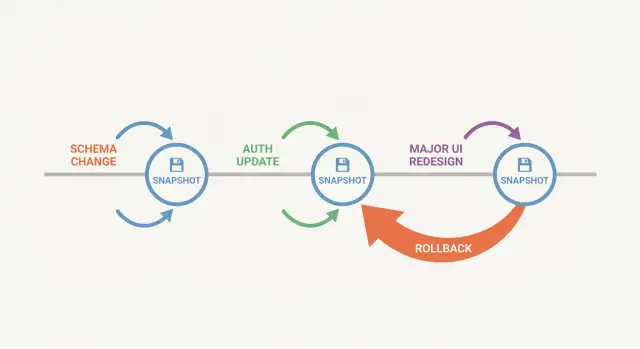
Was „Snapshot‑first“ bedeutet und warum es hilft
Ein Snapshot‑first‑Workflow bedeutet, dass Sie einen Wiederherstellungspunkt erstellen, bevor Sie eine Änderung vornehmen, die Ihre App kaputtmachen könnte. Ein Snapshot ist eine eingefrorene Kopie Ihres Projekts zu einem bestimmten Zeitpunkt. Wenn der nächste Schritt schiefgeht, können Sie zu genau diesem Zustand zurückkehren, anstatt das Chaos von Hand rückgängig zu machen.
Große Änderungen schlagen selten nur auf eine offensichtliche Weise fehl. Ein Schema‑Update kann einen Bericht drei Screens weiter kaputtmachen. Eine Auth‑Anpassung kann Sie aussperren. Eine UI‑Überarbeitung kann mit Beispieldaten gut aussehen und mit echten Accounts und Randfällen auseinanderfallen. Ohne klaren Wiederherstellungspunkt raten Sie, welche Änderung das Problem verursacht hat, oder Sie patchen solange an einer kaputten Version herum, bis Sie vergessen, wie „funktionierend“ aussah.
Snapshots helfen, weil sie Ihnen eine bekannte, funktionierende Basis geben, es billiger machen, mutige Ideen auszuprobieren, und Tests einfacher machen. Wenn etwas kaputtgeht, können Sie fragen: „War es direkt nach Snapshot X noch okay?“
Es hilft auch, klar zu sein, was ein Snapshot schützen kann und was nicht. Ein Snapshot bewahrt Ihren Code und Ihre Konfiguration so, wie sie waren (und auf Plattformen wie Koder.ai kann er auch den vollständigen App‑Zustand speichern). Er behebt aber keine falschen Annahmen. Wenn Ihre neue Funktion eine Datenbankspalte erwartet, die in Produktion nicht existiert, macht ein Zurückrollen des Codes die Tatsache nicht rückgängig, dass eine Migration bereits ausgeführt wurde. Sie brauchen weiterhin einen Plan für Datenänderungen, Kompatibilität und Reihenfolge der Deployments.
Die Denkweise ändert sich: Betrachten Sie Snapshotting als Gewohnheit, nicht als Rettungs‑Knopf. Erstellen Sie Snapshots direkt vor riskanten Schritten, nicht erst nachdem etwas gebrochen ist. Sie werden schneller und entspannter arbeiten, weil Sie immer einen sauberen „letzten bekannten guten“ Zustand haben, zu dem Sie zurückkehren können.
Welche Änderungen einen Save‑Point verdienen
Ein Snapshot zahlt sich am meisten aus, wenn eine Änderung viele Dinge auf einmal kaputtmachen kann.
Schema‑Arbeit ist das Offensichtliche: Benennen Sie eine Spalte um und Sie könnten stillschweigend APIs, Background‑Jobs, Exporte und Berichte brechen, die noch den alten Namen erwarten. Auth‑Änderungen sind ein weiteres Risiko: Eine kleine Regeländerung kann Admins aussperren oder Zugriff gewähren, den Sie nicht wollten. UI‑Überarbeitungen sind tückisch, weil sie oft visuelle Änderungen mit Verhaltensänderungen mischen, und Regressionen sich in Randzuständen verstecken.
Wenn Sie eine einfache Regel wollen: Erstellen Sie einen Snapshot vor allem, was die Datenstruktur, Identität/Berechtigungen oder mehrere Bildschirme gleichzeitig ändert.
Niedrigrisiko‑Änderungen benötigen normalerweise keinen Stopp‑und‑Snapshot‑Moment. Textänderungen, kleine Abstandsanpassungen, eine kleine Validierungsregel oder eine winzige Helferfunktionen‑Bereinigung haben meist eine geringe Blast‑Radius. Sie können trotzdem einen Snapshot machen, wenn es Ihnen beim Fokussieren hilft, aber Sie müssen nicht jede Kleinigkeit unterbrechen.
Hochrisiko‑Änderungen sind anders. Sie funktionieren oft in Ihren „Happy‑Path“‑Tests, versagen aber bei Null‑Werten in alten Zeilen, Nutzern mit ungewöhnlichen Rollen‑Kombinationen oder UI‑Zuständen, die Sie manuell nicht erreichen.
Wie man Snapshots so benennt, dass sie unter Druck nützlich bleiben
Ein Snapshot hilft nur, wenn Sie ihn in einer Stress‑Situation schnell wiedererkennen können. Name und Notizen verwandeln ein Zurückrollen in eine ruhige, schnelle Entscheidung.
Ein guter Label beantwortet drei Fragen:
- Was hat sich geändert?
- Warum wurde es geändert?
- Was war der nächste Schritt?
Halten Sie es kurz, aber spezifisch. Vermeiden Sie vage Namen wie „before update“ oder „try again“.
Ein Namensmuster, das lesbar bleibt
Wählen Sie ein Muster und bleiben Sie dabei. Zum Beispiel:
[WIP] Auth: Magic‑Link hinzufügen (nächster: OAuth)[GOLD] DB: users table v2 (smoke tests bestanden)[WIP] UI: Dashboard‑Layout‑Refactor (nächster: Charts)[GOLD] Release: Billing‑Fixes (deployed)Hotfix: Login‑Redirect‑Loop (Root‑Cause vermerkt)
Status zuerst, dann Bereich, dann Aktion, dann ein kurzes „nächster Schritt“. Dieser letzte Teil ist überraschend hilfreich eine Woche später.
Namen allein reichen nicht. Nutzen Sie Notizen, um festzuhalten, was Ihr zukünftiges Ich vergessen wird: Annahmen, was Sie getestet haben, was noch kaputt ist und was Sie bewusst ignoriert haben.
Gute Notizen enthalten meist Annahmen, 2–3 kurze Testschritte, bekannte Probleme und alle riskanten Details (Schema‑Änderungen, Berechtigungsänderungen, Routing‑Änderungen).
„GOLD“ vs „Work in Progress“
Markieren Sie einen Snapshot als GOLD nur, wenn es sicher ist, ohne Überraschungen zu diesem Punkt zurückzukehren: Grundlegende Flows funktionieren, Fehler sind verstanden, und Sie könnten dort weiterarbeiten. Alles andere ist WIP. Diese kleine Gewohnheit verhindert, dass Sie zu einem Punkt zurückrollen, der nur stabil aussah, weil Sie einen großen Bug vergessen hatten.
Schritt‑für‑Schritt: eine einfache Snapshot‑First‑Schleife
Eine solide Schleife ist simpel: Gehen Sie nur von bekannten guten Punkten aus vorwärts.
1) Starten Sie von „es funktioniert“
Bevor Sie einen Snapshot erstellen, vergewissern Sie sich, dass die App tatsächlich läuft und die wichtigsten Flows funktionieren. Halten Sie es klein: Können Sie den Hauptscreen öffnen, sich anmelden (falls Ihre App das hat) und eine Kernaktion ohne Fehler abschließen? Wenn etwas schon wackelig ist, beheben Sie das zuerst. Ansonsten konserviert Ihr Snapshot ein Problem.
2) Erstellen Sie den Snapshot und schreiben Sie die Absicht auf
Erstellen Sie einen Snapshot und fügen Sie dann eine einzeilige Notiz hinzu, warum er existiert. Beschreiben Sie das bevorstehende Risiko, nicht nur den aktuellen Zustand.
Beispiel: „Vor Änderung der users‑Tabelle + Hinzufügen von organization_id“ oder „Vor Refactor der Auth‑Middleware zur Unterstützung von SSO“.
3) Machen Sie eine fokussierte Änderung
Vermeiden Sie es, mehrere große Änderungen in einer Iteration zu stapeln (Schema plus Auth plus UI). Wählen Sie eine einzelne Scheibe, schließen Sie sie ab und stoppen Sie.
Eine gute „eine Änderung“ ist: „neue Spalte hinzufügen und alten Code weiter funktionieren lassen“ statt „das gesamte Datenmodell ersetzen und jeden Screen aktualisieren“.
4) Führen Sie nach jedem Schritt einen kleinen, wiederholbaren Check aus
Führen Sie nach jedem Schritt die gleichen schnellen Prüfungen aus, damit die Ergebnisse vergleichbar sind. Halten Sie es kurz, damit Sie es tatsächlich tun.
- App startet ohne Fehler
- Ein zentraler Flow funktioniert Ende‑zu‑Ende
- Keine neuen Konsolen/Server‑Fehler während dieses Flows
- Jeder neue Randfall, den Sie eingeführt haben, ist abgedeckt (z. B. ein Leere‑Zustand)
5) Snapshotten Sie erneut am neuen stabilen Punkt
Wenn die Änderung funktioniert und Sie wieder eine saubere Basis haben, erstellen Sie einen weiteren Snapshot. Das wird Ihr neuer sicherer Punkt für den nächsten Schritt.
Vor Schema‑Änderungen: Wo Save‑Points setzen
Schema‑Änderungen sicher üben
Führen Sie Migrationen mit klaren Save‑Points für Add, Backfill und Switch durch.
Datenbankänderungen wirken „klein“, bis sie Signup, Berichte oder einen Background‑Job, den Sie vergessen hatten, kaputtmachen. Behandeln Sie Schema‑Arbeit als eine Abfolge sicherer Checkpoints, nicht als einen großen Sprung.
Beginnen Sie mit einem Snapshot, bevor Sie etwas anfassen. Schreiben Sie dann eine leicht verständliche Basislinie: welche Tabellen sind betroffen, welche Screens oder API‑Aufrufe lesen sie und wie sieht „korrekt“ aus (Pflichtfelder, Unique‑Regeln, erwartete Zeilenanzahlen). Das dauert Minuten und spart Stunden, wenn Sie später Verhalten vergleichen müssen.
Eine praktische Reihe von Save‑Points für die meisten Schema‑Änderungen sieht so aus:
- Snapshot 1 (Baseline): vor der ersten Migration. Notieren Sie Schlüssel‑Tabellen, wichtige Queries und die Nutzerflüsse, die Sie zur Verifizierung verwenden.
- Snapshot 2 (Additive Änderungen): nach dem Hinzufügen neuer Tabellen/Spalten (noch keine Löschungen). Altes Verhalten sollte weiterhin funktionieren.
- Snapshot 3 (Backfill): nach dem Kopieren/Berechnen von Daten in neue Spalten, mit einigen Stichprobenprüfungen.
- Snapshot 4 (Code‑Switch): nachdem die App die neue Struktur liest.
- Snapshot 5 (Cleanup): erst nach realen Nutzungschecks alte Spalten entfernen oder Constraints verschärfen.
Vermeiden Sie eine einzige große Migration, die alles auf einmal umbenennt. Teilen Sie sie in kleinere Schritte, die Sie testen und zurückrollen können.
Nach jedem Checkpoint verifizieren Sie mehr als nur den Happy‑Path. CRUD‑Flows, die auf geänderten Tabellen beruhen, sind wichtig, aber Exporte (CSV‑Downloads, Rechnungen, Admin‑Reports) sind genauso relevant, weil sie oft ältere Queries nutzen.
Planen Sie den Rollback‑Pfad, bevor Sie starten. Wenn Sie eine neue Spalte hinzufügen und anfangen, in sie zu schreiben, entscheiden Sie, was passiert, wenn Sie zurücksetzen: Ignoriert der alte Code die Spalte sicher, oder brauchen Sie eine Reverse‑Migration? Wenn Sie teilweise migrierte Daten haben könnten, legen Sie fest, wie Sie das erkennen und vervollständigen oder sauber verwerfen.
Vor Auth‑Änderungen: Wie Sie Sperrungen vermeiden
Auth‑Änderungen sind eine der schnellsten Möglichkeiten, sich selbst (und Ihre Nutzer) auszusperren. Ein Save‑Point hilft, weil Sie eine riskante Änderung ausprobieren, testen und bei Bedarf schnell zurückrollen können.
Machen Sie einen Snapshot direkt bevor Sie Auth anfassen. Schreiben Sie dann auf, was Sie heute haben, auch wenn es offensichtlich erscheint. Das verhindert Überraschungen wie „Ich dachte, Admins könnten sich noch einloggen“.
Erfassen Sie die Grundlagen:
- Aktuelle Anmelde‑Methoden (Email/Passwort, Magic Link, SSO/OAuth, etc.)
- Rollen und Berechtigungen (was „User“ vs „Admin“ darf)
- Spezielle Regeln (Invite‑Only, 2FA, IP‑Allowlist)
- Testkonten (ein normaler Nutzer, ein Admin)
- Secrets und Umgebungswerte, die mit Auth verknüpft sind (Keys, Callback‑URLs, Token‑Laufzeiten)
Ändern Sie jeweils nur eine Regel. Wenn Sie Rollenprüfungen, Token‑Logik und Login‑Bildschirme gleichzeitig ändern, wissen Sie nicht, was den Fehler verursacht hat.
Ein guter Rhythmus ist: Eine Komponente ändern, die gleichen kleinen Checks ausführen, dann erneut snapshotten, wenn alles sauber ist. Zum Beispiel: Beim Hinzufügen einer „Editor“‑Rolle implementieren Sie zuerst Erstellung und Zuweisung und bestätigen, dass Logins weiterhin funktionieren. Dann fügen Sie ein Berechtigungstor hinzu und testen erneut.
Nach der Änderung verifizieren Sie die Zugriffskontrolle aus drei Blickwinkeln. Normale Nutzer sollten Admin‑Aktionen nicht sehen. Admins müssen weiterhin Einstellungen und Nutzerverwaltung erreichen. Testen Sie dann Randfälle: abgelaufene Sessions, Passwort‑Reset, deaktivierte Accounts und Nutzer, die sich mit einer Methode anmelden, die Sie während des Tests nicht genutzt haben.
Ein Detail, das oft übersehen wird: Secrets liegen oft außerhalb des Codes. Wenn Sie den Code zurückrollen, aber neue Keys und Callback‑Einstellungen behalten, kann Auth auf verwirrende Weise kaputtgehen. Hinterlassen Sie klare Notizen zu allen Umgebungsänderungen, die Sie gemacht haben oder zurücksetzen müssen.
Vor UI‑Rewrites: Fortschritt behalten ohne Chaos
UI schrittweise überarbeiten
Schreiben Sie React‑Screens schrittweise neu und speichern Sie stabile Punkte unterwegs.
UI‑Rewrites sind riskant, weil sie visuelle Änderungen mit Verhaltensänderungen verknüpfen. Erstellen Sie einen Save‑Point, wenn die UI stabil und vorhersehbar ist, auch wenn sie nicht schön ist. Dieser Snapshot wird Ihre Arbeitsbasis: die letzte Version, die Sie noch ausliefern würden, wenn es sein muss.
Zerlegen Sie die Überarbeitung in Scheiben
UI‑Rewrites scheitern, wenn man sie als einen großen Schalter behandelt. Teilen Sie die Arbeit in Scheiben, die für sich stehen können: ein Screen, eine Route oder eine Komponente.
Wenn Sie den Checkout neu schreiben, teilen Sie ihn in Cart, Address, Payment und Confirmation. Nach jeder Scheibe stellen Sie zuerst das alte Verhalten sicher. Dann verbessern Sie Layout, Texte und kleine Interaktionen. Wenn diese Scheibe „gut genug“ ist, snapshotten Sie sie.
Retesten Sie die Teile, die typischerweise kaputtgehen
Nach jeder Scheibe führen Sie einen schnellen Retest durch, fokussiert auf typische Probleme bei Rewrites:
- Navigation: Erreichen Sie den Screen noch über die Hauptpfade?
- Formulare: Validierung, Pflichtfelder, Absenden
- Lade‑ und Leere‑Zustände
- Fehlerzustände (fehlgeschlagene Requests, Berechtigungsfehler, Wiederholungen)
- Mobile Verhalten (kleine Bildschirme, Scrollen, Tap‑Ziele)
Ein häufiges Versagen sieht so aus: Der neue Profil‑Screen ist hübscher, aber ein Feld speichert nicht mehr, weil eine Komponente die Payload‑Form verändert hat. Mit einem guten Checkpoint können Sie zurückrollen, vergleichen und die visuellen Verbesserungen neu anwenden, ohne Tage an Arbeit zu verlieren.
Wie Sie sicher zurückrollen, ohne gute Arbeit zu verlieren
Zurückrollen sollte kontrolliert wirken, nicht panisch. Entscheiden Sie zuerst, ob Sie einen vollständigen Rollback zu einem bekannten guten Punkt brauchen oder nur eine partielle Rücknahme einer einzelnen Änderung.
Ein vollständiger Rollback ist sinnvoll, wenn die App an vielen Stellen kaputt ist (Tests schlagen fehl, Server startet nicht, Login ist gesperrt). Ein partielles Undo passt, wenn nur ein Teil schiefging, z. B. eine einzelne Migration, ein Route‑Guard oder eine Komponente, die Abstürze verursacht.
Eine sichere Rollback‑Abfolge
Behandeln Sie Ihren letzten stabilen Snapshot als Home‑Base:
- Rollen Sie zum letzten stabilen Snapshot zurück.
- Bestätigen Sie, dass die Schlüssel‑Flows wieder funktionieren (App starten, einloggen, Hauptscreen erreichen, eine kritische Aktion ausführen).
- Erstellen Sie sofort einen frischen Snapshot, zum Beispiel „stable‑after‑rollback“.
- Wenden Sie die gute Iteration in kleineren Schritten wieder an (eine Migration, eine Auth‑Regel, ein UI‑Chunk).
- Snapshotten Sie nach jedem sauberen Schritt, damit Sie kurz vor dem nächsten riskanten Teil stoppen können.
Nehmen Sie sich danach fünf Minuten für die Basics. Es ist leicht, zurückzurollen und dennoch einen stillen Bruch zu übersehen, etwa einen Background‑Job, der nicht mehr läuft.
Schnelle Prüfungen, die die meisten Probleme entdecken:
- Kann sich ein neuer Nutzer registrieren und einloggen?
- Lädt die Hauptseite ohne Fehler?
- Funktionieren Erstellen‑ und Speichern‑Aktionen (der „Money‑Path“)?
- Sind Daten noch vorhanden und lesbar?
Beispiel: Sie haben einen großen Auth‑Refactor versucht und Ihren Admin‑Account blockiert. Rollen Sie zum Snapshot direkt vor der Änderung zurück, verifizieren Sie, dass Sie sich einloggen können, und spielen Sie die Änderungen dann in kleineren Schritten wieder ein: zuerst Rollen, dann Middleware, dann UI‑Gates. Wenn es wieder bricht, wissen Sie genau, welcher Schritt es war.
Hinterlassen Sie schließlich eine kurze Notiz: Was war kaputt, wie haben Sie es bemerkt, was hat es behoben und was werden Sie nächstes Mal anders machen. So werden Rollbacks zu Lernmomenten statt zu verlorener Zeit.
Häufige Fehler, die Rollbacks schmerzhaft machen
Änderungen an Auth mit Vertrauen angehen
Snapshotten Sie vor Auth‑Änderungen, um schnell von Sperrungen zu erholen.
Rollback‑Schmerz entsteht meistens durch unklare Save‑Points, gemischte Änderungen und übersprungene Checks.
Zu seltenes Speichern ist ein Klassiker. Leute führen eine „schnelle“ Schema‑Änderung, eine kleine Auth‑Regel‑Anpassung und eine UI‑Änderung durch und merken dann, dass die App kaputt ist und es keinen sauberen Punkt zum Zurückkehren gibt.
Das Gegenproblem ist zu häufiges Speichern ohne Notizen. Zehn Snapshots mit dem Namen „test“ oder „wip“ sind praktisch ein Snapshot, weil Sie nicht erkennen können, welcher sicher ist.
Mehrere riskante Änderungen in einer Iteration zu mischen ist eine weitere Falle. Wenn Schema, Berechtigungen und UI zusammenkommen, wird ein Rollback zur Ratespiel. Sie verlieren auch die Möglichkeit, den guten Teil (z. B. eine UI‑Verbesserung) zu behalten und den riskanten Teil (z. B. eine Migration) zurückzunehmen.
Ein weiteres Problem: Rollback ohne Prüfung von Datenannahmen und Berechtigungen. Nach einem Rollback kann die Datenbank noch neue Spalten, unerwartete NULLs oder teilweise migrierte Zeilen enthalten. Oder Sie stellen alte Auth‑Logik wieder her, während Nutzerrollen unter neuen Regeln erstellt wurden. Dieser Mismatch kann so aussehen, als habe das Rollback nicht funktioniert, obwohl es das tat.
Einfaches Rezept, um die meisten Probleme zu vermeiden:
- Snapshotten Sie an Entscheidungspunkten (vor und nach einer riskanten Änderung), nicht nur am Ende des Tages.
- Schreiben Sie einen Satz Notizen: was geändert wurde, was Sie getestet haben, wie „gut“ aussieht.
- Teilen Sie große Arbeit in separate Brocken: erst Schema, dann Auth, dann UI.
- Prüfen Sie nach einem Rollback Datenzustand und einen echten Berechtigungsweg.
- Reproduzieren Sie den genauen Fehler, der das Rollback ausgelöst hat, und bestätigen Sie, dass er verschwunden ist.
Checkliste, ein realistisches Beispiel und nächste Schritte
Snapshots funktionieren am besten in Kombination mit kurzen Prüfungen. Diese Checks sind kein kompletter Testplan. Sie sind eine kleine Menge Aktionen, die Ihnen schnell sagen, ob Sie weitermachen oder zurückrollen sollten.
Schnelle Prüfungen vor einer riskanten Änderung
Führen Sie diese direkt vor dem Erstellen des Snapshots aus. Sie beweisen, dass die aktuelle Version das Speichern wert ist.
- Die App startet und lädt ohne Fehler.
- Login funktioniert mit mindestens einem realen Nutzer (oder einem Testnutzer).
- Ein Kern‑Flow funktioniert Ende‑zu‑Ende (erstellt etwas, speichert es, zeigt es wieder).
- Die Datenbank ist erreichbar und einfache Reads funktionieren.
- Sie können in einem Satz sagen, was Sie als Nächstes ändern werden.
Wenn etwas bereits kaputt ist, beheben Sie das zuerst. Snapshotten eines Problems macht nur Sinn, wenn Sie es bewusst zu Debug‑Zwecken konservieren.
Schnelle Prüfungen nach einer riskanten Änderung
Zielen Sie auf einen Happy‑Path, einen Error‑Path und eine Berechtigungs‑Sanity‑Check.
- Happy‑Path: Schließen Sie die Hauptaktion ab, die Sie berührt haben.
- Error‑Path: Provizieren Sie einen bekannten Fehler und prüfen Sie, ob die Meldung sinnvoll ist.
- Berechtigungen: Verifizieren Sie, dass ein Nutzer mit Zugriff ihn hat und einer ohne Zugriff ihn nicht hat.
- Aktualisieren/erneut besuchen: Seite neu laden und bestätigen, dass kein Zustand verloren geht.
- Bei Migration: Prüfen Sie einen alten Datensatz und einen neuen Datensatz.
Beispiel: neue Nutzerrolle plus Redesign des Einstellungs‑Screens
Stellen Sie sich vor, Sie fügen eine neue Rolle „Manager“ hinzu und gestalten den Settings‑Screen neu.
-
Starten Sie mit einem stabilen Build. Führen Sie die Vor‑Änderungs‑Checks durch und snapshotten Sie mit einem klaren Namen, z. B.: „pre‑manager‑role + pre‑settings‑redesign“.
-
Machen Sie zuerst die Backend‑Rollenarbeit (Tabellen, Berechtigungen, API). Wenn Rollen und Zugriffsregeln korrekt funktionieren, snapshotten Sie erneut: „roles‑working".
-
Beginnen Sie dann mit dem Settings‑UI‑Redesign. Vor einem großen Layout‑Rewrite snapshotten Sie: "pre‑settings‑ui‑rewrite". Wenn die UI unübersichtlich wird, rollen Sie zu diesem Punkt zurück und versuchen Sie einen saubereren Ansatz, ohne die gute Rollenarbeit zu verlieren.
-
Wenn das neue Settings‑UI brauchbar ist, snapshotten Sie: "settings‑ui‑clean". Erst dann polieren Sie weiter.
Nächste Schritte
Probieren Sie das diese Woche an einem kleinen Feature. Wählen Sie eine riskante Änderung, setzen Sie zwei Snapshots darum (vor und nach), und üben Sie absichtlich ein Rollback.
Wenn Sie auf Koder.ai (koder.ai) arbeiten, machen die eingebauten Snapshots und das Rollback dieses Workflow leicht beizubehalten, während Sie iterieren. Das Ziel ist einfach: Große Änderungen sollen sich reversibel anfühlen, damit Sie schnell arbeiten können, ohne Ihre beste funktionierende Version aufs Spiel zu setzen.