Was dieser Beitrag abdeckt (und warum es wichtig ist)
Snowflake machte eine einfache, aber weitreichende Idee im Cloud‑Data‑Warehousing populär: Speicher und Abfrage‑Compute getrennt halten. Diese Trennung verändert zwei alltägliche Schmerzpunkte für Datenteams — wie Warehouses skalieren und wie man für sie zahlt.
Anstatt das Warehouse wie eine fixe „Box“ zu behandeln (in der mehr Nutzer, mehr Daten oder komplexere Abfragen um dieselben Ressourcen kämpfen), erlaubt Snowflakes Modell, Daten einmal zu speichern und bei Bedarf die passende Menge an Compute hochzufahren. Das Ergebnis ist häufig schnellere Time‑to‑Answer, weniger Engpässe in Spitzenzeiten und klarere Kontrolle darüber, was wann Geld kostet.
Thema #1: Leistung und Skalierung ohne die üblichen Kompromisse
Dieser Beitrag erklärt in einfacher Sprache, was es wirklich bedeutet, Storage und Compute zu trennen — und wie sich das auf auswirkt:
- Parallelität (viele Nutzer führen gleichzeitig Abfragen aus)
- Elastische Skalierung (Compute hoch-/runterschalten)
- Kostenverhalten (nur für laufenden Compute zahlen, plus fortlaufender Storage)
Wir zeigen auch, wo das Modell nicht alle Probleme automatisch löst — denn manche Kosten‑ und Performance‑Überraschungen kommen aus dem Workload‑Design, nicht aus der Plattform selbst.
Thema #2: Warum das Ökosystem genauso wichtig sein kann wie rohe Geschwindigkeit
Eine schnelle Plattform ist nicht die ganze Geschichte. Für viele Teams hängt Time‑to‑Value davon ab, ob das Warehouse leicht an die Tools anschließbar ist, die man bereits nutzt — ETL/ELT‑Pipelines, BI‑Dashboards, Katalog-/Governance‑Tools, Sicherheitskontrollen und Datenpartner.
Snowflakes Ökosystem (inklusive Datenfreigabe‑Muster und marktplatzähnlicher Distribution) kann Implementierungszeiten verkürzen und individuellen Engineering‑Aufwand reduzieren. Dieser Beitrag beschreibt, wie „Ökosystemtiefe“ in der Praxis aussieht und wie Sie sie für Ihre Organisation bewerten.
Für wen das ist
Diese Anleitung richtet sich an Data‑Leader, Analysten und nicht‑spezialisierte Entscheidungsträger — also an alle, die die Trade‑offs hinter Snowflake‑Architektur, Skalierung, Kosten und Integrationsentscheidungen verstehen müssen, ohne in Vendor‑Jargon zu versinken.
Vor der Trennung: Warum traditionelle Warehouses an Grenzen stoßen
Traditionelle Data Warehouses basierten auf einer einfachen Annahme: Sie kaufen (oder mieten) eine feste Menge an Hardware und führen dann alles auf derselben Box oder demselben Cluster aus. Das funktionierte, solange Workloads vorhersehbar und Wachstum moderat waren — aber es schuf strukturelle Limits, sobald Datenmengen und Nutzerzahlen schneller wuchsen.
Das klassische Modell: feste Cluster und sorgfältige Kapazitätsplanung
On‑Prem Systeme (und frühe Cloud „Lift‑and‑Shift“ Deployments) sahen typischerweise so aus:
- Ein einzelner MPP‑Cluster (massively parallel processing) handhabte Storage, CPU und RAM zusammen.
- Sie dimensionierten den Cluster für die Spitzenlast, weil Resize langsam, riskant oder mit Downtime verbunden war.
- Kapazitätsplanung wurde ein wiederkehrendes Projekt: Wachstum vorhersagen, Budget rechtfertigen, Hardware bestellen, installieren, migrieren.
Selbst wenn Anbieter „Nodes“ anboten, blieb das Muster: Skalierung bedeutete meist größere oder mehr Nodes zu einem gemeinsamen Environment hinzuzufügen.
Die Schmerzpunkte: langsame Skalierung, verschwendete Ausgaben und Warteschlangen
Dieses Design erzeugt einige typische Probleme:
- Langsame Skalierung: Wenn ein Quartals‑Reporting‑Crunch plötzlich mehr Rechenleistung braucht, kann man nicht immer schnell nachlegen. Entweder warten Sie oder Sie überprovisionieren „für den Fall“.
- Leerlaufende Kapazität: Für Spitzen ausgelegte Cluster sind die meiste Zeit unterausgelastet — trotzdem zahlt man (Hardware, Lizenzen, Ops‑Zeit).
- Warteschlangen unter Last: Wenn mehrere Teams gleichzeitig Abfragen ausführen, konkurrieren sie um dieselben Ressourcen. Schwere Jobs können interaktive Dashboards blockieren, was zu Timeouts und frustrierten Stakeholdern führt und zu Regeln wie „diese Abfrage nicht während der Geschäftszeiten ausführen“.
Weil diese Warehouses eng an ihre Umgebung gekoppelt waren, wuchsen Integrationen oft organisch: Custom‑ETL‑Skripte, handgebaute Konnektoren und One‑Off‑Pipelines. Sie funktionierten — bis ein Schema sich änderte, ein Upstream‑System wegzog oder ein neues Tool eingeführt wurde. Den Betrieb am Laufen zu halten, fühlte sich oft wie ständige Wartung statt wie kontinuierlicher Fortschritt an.
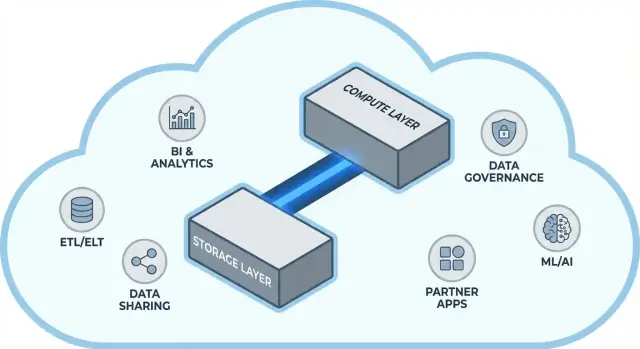
Die Kernidee: Storage und Compute trennen
Traditionelle Warehouses koppeln oft zwei sehr unterschiedliche Aufgaben: Storage (wo Ihre Daten liegen) und Compute (die Rechenleistung, die die Daten liest, joinet, aggregiert und schreibt).
Storage vs. Compute (in einfachen Worten)
Storage ist wie eine Vorratskammer: Tabellen, Dateien und Metadaten werden sicher und kostengünstig gehalten, langlebig und immer verfügbar.
Compute ist wie das Küchenteam: CPUs und Arbeitsspeicher, die Abfragen „kochen“ — SQL ausführen, sortieren, scannen, Ergebnisse erstellen und mehrere Nutzer gleichzeitig bedienen.
Die entscheidende Verschiebung: getrennt skalieren
Snowflake trennt diese beiden Bereiche, sodass Sie jeden Teil unabhängig anpassen können.
- Wächst das Datenvolumen, fügen Sie mehr Storage hinzu (meist inkrementell und vorhersehbar).
- Trifft ein Traffic‑Spike ein, fügen Sie mehr Compute hinzu (durch Größenänderung oder Hinzufügen virtueller Warehouses), ohne die Basisdaten zu verschieben oder zu duplizieren.
Praktisch verändert das den Alltag: Sie müssen Compute nicht „überkaufen“, nur weil Storage wächst, und Sie können Workloads isolieren (z. B. Analysten vs. ETL), damit sie sich nicht gegenseitig ausbremsen.
Was es nicht ist
Die Trennung ist mächtig, aber kein Zauber:
- Es ist keine kostenlose Skalierung. Mehr oder größere Warehouses bedeuten in der Regel höhere Compute‑Kosten.
- Es ist nicht automatisch eine Einsparung. Schlecht geschriebene Abfragen, unnötige Refresh‑Jobs oder immer eingeschaltete Warehouses können Kosten treiben.
- Es ist kein Freibrief für fehlende Planung. Sie müssen Warehouse‑Größen wählen, Auto‑Suspend‑Regeln setzen und Compute an Geschäftsanforderungen ausrichten.
Der Wert liegt in der Kontrolle: Storage und Compute getrennt zu bezahlen und beides passend zu den Bedürfnissen Ihrer Teams einzusetzen.
Snowflake‑Architektur in einfachen Worten
Snowflake lässt sich am leichtesten als drei Schichten verstehen, die zusammenarbeiten, aber unabhängig skalieren können.
1) Storage: Cloud‑Objektspeicher
Ihre Tabellen liegen letztlich als Dateien im Objektspeicher Ihres Cloud‑Providers (S3, Azure Blob oder GCS). Snowflake verwaltet Dateiformate, Kompression und Organisation. Sie „stecken keine Disks an“ oder müssen Volumes dimensionieren — der Storage wächst mit den Daten.
2) Compute: virtuelle Warehouses
Compute wird als virtuelle Warehouses verpackt: unabhängige Cluster aus CPU/RAM, die Abfragen ausführen. Mehrere Warehouses können gleichzeitig gegen dieselben Daten laufen. Das ist der Unterschied zu älteren Systemen, in denen schwere Workloads um denselben Pool kämpften.
Eine separate Service‑Schicht übernimmt das „Gehirn“ des Systems: Authentifizierung, Query‑Parsing und Optimierung, Transaktions‑/Metadaten‑Management und Koordination. Diese Schicht entscheidet, wie eine Abfrage effizient ausgeführt wird, bevor Compute die Daten berührt.
Wie eine Abfrage fließt
Wenn Sie SQL absenden, parst die Services‑Schicht die Abfrage, erstellt einen Ausführungsplan und übergibt diesen Plan an ein gewähltes virtuelles Warehouse. Das Warehouse liest nur die notwendigen Datenfiles aus dem Objektspeicher (und profitiert wenn möglich vom Caching), verarbeitet sie und liefert Ergebnisse zurück — ohne Ihre Basisdaten permanent ins Warehouse zu verschieben.
Parallelität und Isolation (ohne Fachchinesisch)
Wenn viele Leute gleichzeitig Abfragen ausführen, können Sie entweder:
- separate Warehouses für unterschiedliche Teams/Workloads verwenden (Workload‑Isolation), oder
- Multi‑Cluster‑Warehouses aktivieren, sodass Snowflake bei Bedarf zusätzliche Compute‑Cluster hinzufügt und später wieder herunterfährt.
Das ist die architektonische Grundlage für Snowflakes Performance und Kontrolle über „noisy neighbors“.
Skalierung und Parallelität: Was sich wirklich ändert
Die große praktische Veränderung ist, dass Sie Compute unabhängig von den Daten skalieren. Anstatt „das Warehouse wird größer“, können Sie Ressourcen pro Workload hoch- oder herunterdrehen — ohne Tabellen zu kopieren, Disks neu zu partitionieren oder Downtimes zu planen.
Elastizität: Compute resize ohne Datenbewegung
In Snowflake ist ein virtuelles Warehouse die Compute‑Engine, die Abfragen ausführt. Sie können es in Sekunden skalieren (z. B. von Small auf Large), während die Daten im gemeinsamen Storage bleiben. Performance‑Tuning wird so oft zur einfachen Frage: „Braucht diese Arbeitslast gerade mehr Rechenleistung?“
Das ermöglicht auch temporäre Bursts: fürs Monats‑Close hochskalieren und danach wieder zurückdrehen.
Parallelität: weniger Warteschlangen
Traditionelle Systeme zwangen oft verschiedene Teams dazu, denselben Compute zu teilen, was Stoßzeiten wie eine Warteschlange erscheinen ließ.
Snowflake erlaubt separate Warehouses pro Team oder Workload — z. B. eines für Analysten, eines für Dashboards und eines für ETL. Da diese Warehouses auf dieselben Daten zugreifen, reduziert sich das Problem „mein Dashboard hat deinen Report verlangsamt“ und Performance wird vorhersagbarer.
Beobachtbare Tradeoffs
Elastischer Compute garantiert keinen automatischen Erfolg. Häufige Fallstricke:
- Cold Starts: suspendierte Warehouses brauchen einen Moment zum Resumieren, was Latenz für seltene Jobs erzeugen kann.
- Right‑Sizing: zu groß ist Geldverschwendung; zu klein bringt langsame Queries und Frust.
- Guardrails nötig: Auto‑Suspend/Resume, Resource‑Monitore und klare Verantwortlichkeiten verhindern, dass Warehouses idle laufen oder unkontrolliert wachsen.
Die Folge: Skalierung und Parallelität werden von Infrastrukturprojekten zu alltäglichen Betriebsentscheidungen.
Kostenmodell: Wo Einsparungen möglich sind (und wo nicht)
Ops-Dashboard bereitstellen
Erstelle ein internes Ops-Portal, das Snowflake-Daten liest, ohne den gesamten Stack manuell aufzubauen.
Wie Snowflake tatsächlich abrechnet
Snowflakes „Pay‑for‑what‑you‑use“ ist im Grunde zwei parallele Zähler:
- Compute: wird nach Laufzeit des virtuellen Warehouses in Credits abgerechnet. Wenn es an ist, läuft der Zähler.
- Storage: wird nach der Menge gespeicherter Daten abgerechnet (plus Zusatz‑Storage für Features wie Time Travel/Fail‑safe).
Diese Trennung ist der Ort, an dem Einsparungen möglich sind: Sie können viele Daten relativ günstig speichern und Compute nur dann einschalten, wenn es nötig ist.
Wo Kosten hochlaufen
Die meisten „unerwarteten“ Ausgaben kommen vom Compute‑Verhalten, nicht vom reinen Storage. Häufige Treiber sind:
- Überdimensionierte Warehouses
- Immer‑laufende Workloads (Warehouses, die nachts oder am Wochenende laufen)
- Ineffiziente Abfragen (ungefilteter Scan, unnötige Joins, schwere Transformationen, die wiederholt laufen)
- Hohe Parallelitätsmuster (viele kleine Dashboards, die ständig refreshen)
Die Trennung macht Abfragen nicht automatisch effizient — schlechtes SQL verbrennt weiter Credits.
Praktische Kontrollen, die im echten Leben funktionieren
Sie brauchen keine Finanzabteilung für das Management — nur ein paar Guardrails:
- Auto‑Suspend / Auto‑Resume, um für Leerlauf nicht zu bezahlen
- Resource‑Monitore, um Credits pro Warehouse/Team zu alarmieren oder zu begrenzen
- Scheduling (Batchjobs in definierten Fenstern laufen lassen; Dev/Test außerhalb der Arbeitszeit pausieren)
- Right‑Sizing und Tests mit kleineren Warehouse‑Größen, bevor Sie hochskalieren
Richtig eingesetzt belohnt das Modell Disziplin: kurz laufender, passend dimensionierter Compute gekoppelt mit vorhersehbarem Storage‑Wachstum.
Datenfreigabe und Zusammenarbeit als erstklassiges Feature
Snowflake betrachtet Sharing als eingebauten Designpunkt — nicht als nachträglich angehängte Export/Datei‑Drops/One‑Off‑ETL.
Teilen ohne Kopien (in vielen Fällen)
Anstatt Extrakte zu versenden, kann Snowflake einem anderen Account erlauben, dieselben zugrunde liegenden Daten über ein sicheres „Share“ abzufragen. In vielen Szenarien müssen die Daten nicht in ein zweites Warehouse dupliziert oder ins Objekt‑Storage zum Download gepusht werden. Der Konsument sieht die geteilte Datenbank/Tabelle wie lokal, während der Anbieter steuert, was sichtbar ist.
Dieser „entkoppelte“ Ansatz reduziert Daten‑Sprawl, beschleunigt den Zugriff und verringert die Zahl der zu bauenden Pipelines.
Häufige Kollaborationsmuster
Partner‑ und Kundenfreigaben: Ein Anbieter kann kuratierte Datensätze für Kunden veröffentlichen (z. B. Nutzungs‑ oder Referenzdaten) mit klaren Grenzen — nur erlaubte Schemata, Tabellen oder Views.
Interne Domain‑Freigabe: Zentrale Teams können zertifizierte Datensätze für Produkt, Finanzen und Betrieb bereitstellen, ohne dass jede Einheit eigene Kopien erzeugt. Das unterstützt eine „one set of numbers“‑Kultur, während Teams dennoch eigenen Compute fahren.
Gesteuerte Zusammenarbeit: Gemeinsame Projekte (z. B. mit Agenturen, Lieferanten oder Tochterfirmen) können auf einem gemeinsamen Dataset arbeiten, während sensitive Spalten maskiert und Zugriffe protokolliert werden.
Grenzen, die geplant werden müssen
Sharing ist nicht „einmal einstellen und vergessen“. Sie brauchen weiterhin:
- Governance: klare Eigentumsverhältnisse, regelmäßige Zugriffsüberprüfungen und Richtlinien für PII/regulated data.
- Verträge und Erwartungen: wer zahlt Compute, SLAs, Retention und was passiert bei Definition‑Änderungen.
- Auffindbarkeit: ohne Katalog und sinnvolle Namensgebung finden oder vertrauen Nutzer die richtigen geteilten Daten nicht. Stimmen Sie Shares mit Dokumentation und Ihrem Datenkatalog ab, falls vorhanden.
Ein schnelles Warehouse ist wertvoll, aber Geschwindigkeit allein entscheidet selten, ob ein Projekt termingerecht ausgeliefert wird. Häufig macht das Ökosystem rund um die Plattform — die vorhandenen Verbindungen, Tools und Expertise — den Unterschied, weil es individuellen Aufwand reduziert.
In der Praxis umfasst ein Ökosystem:
- Konnektoren zu Quellen und Zielen (SaaS‑Apps, Datenbanken, Streaming‑Tools)
- Partner‑Tools für Ingest, Transformation, BI, Datenqualität und Observability
- Apps und native Integrationen, die nahe an den Daten laufen
- Templates und Referenz‑Architekturen (Standardmodelle, Patterns, Deployment‑Guides)
- Community‑Wissen: Beispiele, Foren, Meetups und Einstellungsverfügbarkeit
Warum Ökosysteme schneller zur Auslieferung führen als Benchmarks
Benchmarks messen einen engen Performance‑Ausschnitt unter kontrollierten Bedingungen. Reale Projekte verbringen die meiste Zeit mit:
- Zuverlässigem, inkrementellem Datentransfer
- Modellieren, Testen und Dokumentieren von Datensätzen
- Operativen Aufgaben (Monitoring, Alerting, Kostenkontrolle)
- Sicherheitsprüfungen, Zugriffskontrollen und Audits
Hat Ihre Plattform reife Integrationen für diese Schritte, vermeiden Sie viel Glue‑Code. Das verkürzt Implementierungszeiten, erhöht Zuverlässigkeit und erleichtert den Wechsel von Teams oder Tools ohne komplettes Rewriting.
Ein einfaches Bewertungsraster: Abdeckung, Qualität, Wartbarkeit
Beim Bewerten eines Ökosystems achten Sie auf:
- Abdeckung: Unterstützt es Ihre Schlüsselquellen, BI‑Tools, Orchestrierung und Governance‑Bedürfnisse?
- Qualität: Werden Konnektoren gepflegt, gut dokumentiert und auf Ihrer Skala getestet?
- Wartbarkeit: Wie viel laufender Aufwand entsteht durch Upgrades, Breaking Changes, Debugging und Support?
Performance gibt Ihnen Fähigkeit; das Ökosystem bestimmt oft, wie schnell diese Fähigkeit in Geschäftswert verwandelt wird.
Integrations‑Ökosystem: Daten rein, raus und genutzt
Governance nutzbar machen
Richte eine einfache, geregelte Datenanforderungs-Workflow-App ein, die eure Teams wirklich nutzen können.
Snowflake kann Abfragen schnell ausführen, aber echter Mehrwert entsteht, wenn Daten zuverlässig durch Ihren Stack fließen: von Quellen nach Snowflake und wieder raus in Tools, die Menschen täglich nutzen. Die „letzte Meile“ entscheidet oft, ob eine Plattform mühelos oder ständig fragil wirkt.
Hauptkategorien von Integrationen
Die meisten Teams benötigen eine Mischung aus:
- ELT/ETL für Ingest aus Datenbanken, SaaS‑Apps, Dateien und Objektspeicher
- BI und Analytics für Dashboards, Self‑Service‑Exploration und semantische Schichten
- Reverse ETL zum Zurückschreiben kuratierter Daten in CRM, Marketing und Support‑Systeme
- Orchestrierung für Scheduling, Abhängigkeiten, Backfills und Promotion zwischen Umgebungen
- Streaming für Near‑Realtime‑Events und Change‑Data‑Capture
- ML‑Tools für Feature‑Pipelines, Trainings‑Workflows und Model‑Monitoring
Fragen, die Sie vor der Auswahl von Konnektoren stellen sollten
Nicht alle „Snowflake‑kompatiblen“ Tools verhalten sich gleich. Achten Sie auf praktische Details:
- Ist der Konnektor zertifiziert/unterstützt (und von wem)? Wie ist der Eskalationspfad?
- Kann er inkrementelle Ladevorgänge sauber abbilden (CDC, Timestamps, High‑Water‑Marks)?
- Wie geht er mit Schema‑Drift um — neue Spalten, Typänderungen, gelöschte Felder?
- Welche Garantien gibt es zu Retries, Deduplication und exactly‑once vs at‑least‑once?
Operations nicht vergessen
Integrationen brauchen auch Day‑2‑Readiness: Monitoring und Alerting, Lineage/Katalog‑Hooks und Incident‑Response‑Workflows (Ticketing, On‑Call, Runbooks). Ein starkes Ökosystem bedeutet nicht nur mehr Logos — es bedeutet weniger Überraschungen, wenn Pipelines um 2 Uhr morgens ausfallen.
Governance, Sicherheit und Vertrauen im großen Maßstab
Wenn Teams wachsen, ist die schwierigste Aufgabe im Analytics‑Betrieb oft nicht die Geschwindigkeit, sondern sicherzustellen, dass die richtigen Menschen die richtigen Daten für den richtigen Zweck mit nachweisbaren Kontrollen nutzen. Snowflakes Governance‑Funktionen sind auf diese Realität ausgelegt: viele Nutzer, viele Datenprodukte und häufiges Teilen.
Governance‑Basics, die tatsächlich halten
Starten Sie mit klaren Rollen und einem Least‑Privilege‑Ansatz. Statt Zugänge direkt an Personen zu vergeben, definieren Sie Rollen wie ANALYST_FINANCE oder ETL_MARKETING und gewähren diesen Rollen Zugriff auf bestimmte Databases, Schemas, Tabellen und bei Bedarf Views.
Für sensitive Felder (PII, Finanzkennzahlen) nutzen Sie Masking‑Policies, sodass Personen Daten abfragen können, ohne rohe Werte zu sehen, sofern ihre Rolle das nicht erlaubt. Kombinieren Sie das mit Auditing: protokollieren Sie, wer was wann abgefragt hat, damit Security‑ und Compliance‑Teams Fragen ohne Rätselraten beantworten können.
Warum Governance Sharing und Self‑Service ändert
Gute Governance macht Sharing sicherer und skalierbarer. Wenn Ihr Sharing‑Modell auf Rollen, Policies und geprüften Zugriffen basiert, können Sie Self‑Service (mehr Nutzer, die Daten explorieren) ermöglichen, ohne versehentliche Offenlegungen zu riskieren.
Sie reduziert auch Reibung bei Compliance: Policies werden zu wiederholbaren Kontrollen statt zu Einzelfällen. Das ist wichtig, wenn Datensätze über Projekte, Abteilungen oder externe Partner hinweg wiederverwendet werden.
Praktische Tipps, die zukünftigen Schmerz verhindern
- Namenskonventionen: Standardisieren Sie Namen für Databases/Schemas, die Zweck und Sensitivität signalisieren (z. B.
PROD_FINANCE, DEV_MARKETING, SHARED_PARTNER_X). Konsistenz beschleunigt Reviews und reduziert Fehler.
- Umgebungs‑Trennung: Halten Sie DEV/TEST/PROD logisch getrennt und mit strengeren Kontrollen in PROD. Behandeln Sie Produktionsdaten als Ausnahme, nicht als Standard.
- Access‑Reviews: Setzen Sie einen Rhythmus (monatlich für Hochrisiko‑Daten, sonst vierteljährlich). Überprüfen Sie Rollenmitgliedschaften, inaktive Nutzer und privilegierte Rollen.
Vertrauen im großen Maßstab ist weniger eine perfekte Kontrolle als ein System kleiner, verlässlicher Gewohnheiten, die Zugriff intentional und erklärbar halten.
Workloads und Best‑Practice‑Muster
KPIs mobil anzeigen
Erstelle eine Flutter-App für KPI-Checks und Alerts, die dein bestehendes Datenmodell nutzt.
Snowflake glänzt oft, wenn viele Menschen und Tools dieselben Daten aus unterschiedlichen Gründen abfragen müssen. Weil Compute in unabhängige Warehouses verpackt ist, können Sie jede Arbeitslast einer passenden Form und Zeitplanung zuordnen.
Häufige Workload‑Zuordnung
Analytics & Dashboards: Platzieren Sie BI‑Tools auf einem dedizierten Warehouse, dimensioniert für gleichmäßiges, vorhersehbares Query‑Volumen. So werden Dashboard‑Refreshes nicht durch Ad‑hoc‑Exploration verlangsamt.
Ad‑hoc‑Analyse: Geben Sie Analysten ein eigenes Warehouse (meist kleiner) mit Auto‑Suspend. So erhalten sie schnelle Iteration ohne Idle‑Kosten.
Data Science & Experimentation: Verwenden Sie ein Warehouse, das für größere Scans und gelegentliche Bursts dimensioniert ist. Bei Bedarf skalieren Sie dieses Warehouse temporär hoch, ohne BI‑Nutzer zu beeinträchtigen.
Data Apps & Embedded Analytics: Behandeln Sie App‑Traffic wie einen Produktionsservice — separates Warehouse, konservative Timeouts und Resource‑Monitore, um Überraschungskosten zu vermeiden.
Wenn Sie leichte interne Data‑Apps bauen (z. B. ein Ops‑Portal, das Snowflake abfragt und KPIs anzeigt), ist ein schneller Weg, ein React + API‑Gerüst zu erstellen und mit Stakeholdern iterativ zu arbeiten. Plattformen wie Koder.ai (ein vibe‑coding‑Tool, das Web/Server/Mobile‑Apps aus Chat generiert) können helfen, solche Snowflake‑gestützten Apps schnell zu prototypen und später den Source‑Code zu exportieren.
Bewährte Muster, die halten
Eine einfache Regel: separieren Sie Warehouses nach Zielgruppe und Zweck (BI, ELT, Ad‑hoc, ML, App). Kombinieren Sie das mit guten Query‑Gewohnheiten — vermeiden Sie broad SELECT *, filtern Sie früh und achten Sie auf ineffiziente Joins. Modellseitig priorisieren Sie Strukturen, die dem Abfrageverhalten entsprechen (oft eine saubere semantische Schicht oder wohldefinierte Marts), statt physische Layouts zu überoptimieren.
Wann Alternativen oder Ergänzungen sinnvoll sind
Snowflake ersetzt nicht alles. Für sehr hochvolumige, latenzkritische transaktionale Workloads (klassisches OLTP) ist in der Regel eine spezialisierte Datenbank besser geeignet; Snowflake dient dann für Analytics, Reporting, Sharing und downstream Data Products. Hybride Setups sind üblich und oft die praktischste Lösung.
Migrationsüberlegungen: Was Sie vor dem Wechsel planen sollten
Eine Snowflake‑Migration ist selten ein reines „Lift and Shift“. Die Storage/Compute‑Trennung verändert die Art, wie Sie dimensionieren, tunen und bezahlen — gute Planung verhindert Überraschungen.
Eine praktische Migrationsabfolge
Beginnen Sie mit einem Inventar: Welche Quellen speisen das Warehouse, welche Pipelines transformieren Daten, welche Dashboards hängen daran und wer ist zuständig? Priorisieren Sie nach Geschäftswichtigkeit und Komplexität (z. B. Finance‑Reporting zuerst, experimentelle Sandboxes später).
Konvertieren Sie dann SQL und ETL‑Logik. Viel Standard‑SQL lässt sich übernehmen, aber Details wie Funktionen, Datumsbehandlung, prozedurale Logik und Temp‑Table‑Muster brauchen oft Anpassungen. Validieren Sie früh: parallele Outputs laufen lassen, Zeilenanzahl und Aggregate vergleichen und Edge‑Cases prüfen (Nulls, Zeitzonen, Dedup‑Logik). Planen Sie abschließend den Cutover: Freeze‑Fenster, Rollback‑Pfad und eine klare Definition of Done für jedes Dataset und jeden Report.
Typische Risiken
Hidden Dependencies sind am häufigsten: ein Spreadsheet‑Export, ein hardcodierter Connection‑String, ein downstream Job, an den sich niemand mehr erinnert. Performance‑Überraschungen treten auf, wenn alte Tuning‑Annahmen nicht mehr gelten (z. B. viele kleine Warehouses oder viele kleine Queries ohne Parallelitätsbetrachtung). Kosten‑Spikes kommen meist von laufenden Warehouses, unkontrollierten Retries oder duplizierten Dev/Test‑Workloads. Berechtigungs‑Lücken erscheinen beim Übergang von groben Rollen zu granularem Governance — testen Sie mit Least‑Privilege‑Nutzerläufen.
Change‑Management (nicht überspringen)
Definieren Sie ein Ownership‑Modell (wer besitzt Daten, Pipelines und Kosten), liefern Sie rollenbasierte Schulungen für Analysten und Ingenieure und planen Sie einen Supportzeitraum nach dem Cutover (On‑Call‑Rotation, Incident‑Runbook und ein Ort zum Melden von Problemen).
Eine moderne Datenplattform auszuwählen heißt nicht nur, nach Spitzenbenchmark‑Geschwindigkeit zu schauen. Es geht darum, ob die Plattform zu Ihren realen Workloads, Ihrer Arbeitsweise und den Tools passt, auf die Sie angewiesen sind.
Praktische Bewertungscheckliste
Nutzen Sie diese Fragen für Shortlist und Vendor‑Gespräche:
- Workloads: Führen Sie hauptsächlich geplante Dashboards, Ad‑hoc‑Analysen, Data Science, ELT/ETL oder Kunden‑Apps aus? Brauchen Sie vorhersehbare Batch‑Fenster oder elastische Burst‑Kapazität?
- Parallelitätsbedarf: Wie viele Personen/Applikationen fragen gleichzeitig ab, und wie „spiky“ ist die Nutzung?
- Datenfreigabe: Müssen Sie Live‑Daten mit Partnern oder Kunden teilen, ohne Dateien zu verschicken? Erwarten Sie Drittanbieter‑Datensätze?
- Tooling‑Fit: Integrieren Ihre BI‑Tools, Orchestrierung, Katalog und CI/CD‑Workflows sauber? Was bricht bei einem Umzug?
- Governance & Security: Brauchen Sie feingranulare Zugriffssteuerung, Audit‑Trails, Masking, Aufbewahrungsregeln und klare Trennung der Aufgaben?
- Kostenrahmen: Welche Kosten sind kritisch — laufende Grundkosten, Spitzenlastkosten oder die Fähigkeit, Compute auszuschalten? Wie verhindern Sie „Always‑On“‑Verschwendung?
Kurzer Pilotplan (2–4 Wochen)
Wählen Sie zwei bis drei repräsentative Datensätze (keine Toy‑Samples): eine große Faktentabelle, eine unordentliche semistrukturierte Quelle und eine geschäftskritische Domäne.
Führen Sie dann reale Nutzerabfragen aus: Dashboard‑Peaks, Analysten‑Exploration, geplante Loads und einige Worst‑Case‑Joins. Erfassen Sie: Query‑Zeit, Parallelitätsverhalten, Ingest‑Zeit, operativen Aufwand und Kosten pro Workload.
Wenn Ihre Evaluation auch die Frage „Wie schnell können wir etwas liefern, das Menschen wirklich nutzen?“ umfasst, fügen Sie dem Pilot ein kleines Lieferziel hinzu — z. B. eine interne Metrik‑App oder einen gesteuerten Data‑Request‑Workflow, der Snowflake abfragt. Das Aufbauen dieser dünnen Schicht deckt Integrations‑ und Sicherheitsrealitäten schneller auf als reine Benchmarks. Tools wie Koder.ai können helfen, vom Prototyp zum Produktionscode zu kommen, indem sie App‑Strukturen per Chat generieren und den Export des Codes ermöglichen.
Vorgeschlagene nächste Schritte
Wenn Sie Hilfe bei Kostenschätzungen und Vergleichen brauchen, starten Sie mit /pricing.
Für Migrations‑ und Governance‑Tipps stöbern Sie in verwandten Artikeln auf /blog.