Warum Speicherverwaltung Leistung und Sicherheit beeinflusst
Speicherverwaltung ist die Menge an Regeln und Mechanismen, die ein Programm nutzt, um Speicher anzufordern, zu benutzen und wieder freizugeben. Jedes laufende Programm braucht Speicher für Dinge wie Variablen, Nutzerdaten, Netzwerkpuffer, Bilder und Zwischenergebnisse. Da Speicher begrenzt ist und mit dem Betriebssystem sowie anderen Anwendungen geteilt wird, müssen Sprachen entscheiden, wer dafür verantwortlich ist, ihn freizugeben, und wann das passiert.
Diese Entscheidungen formen zwei Ergebnisse, die den meisten Leuten wichtig sind: wie schnell ein Programm sich anfühlt und wie zuverlässig es sich unter Last verhält.
Performance ist keine einzelne Zahl. Speicherverwaltung kann beeinflussen:
- Durchsatz: wie viel Arbeit pro Sekunde abgeschlossen werden kann (verarbeitete Requests, gerenderte Frames, verarbeitete Dateien).
- Latenz: wie lange eine einzelne Operation dauert, besonders Tail-Latenz-Spitzen, die durch Pausen oder langsame Allokationen entstehen.
- Speicher-Footprint: wie viel RAM das Programm während der Ausführung belegt, was Kosten, Akkulaufzeit und Swapping-Verhalten beeinflusst.
Eine Sprache, die schnell allokiert, aber gelegentlich pausiert, kann in Benchmarks gut aussehen, sich in interaktiven Anwendungen jedoch ruckelig anfühlen. Ein anderes Modell, das Pausen vermeidet, erfordert möglicherweise sorgfältigeres Design, um Lecks und Lifetime-Fehler zu verhindern.
Was „Sicherheit“ hier bedeutet
Sicherheit bedeutet, speicherbezogene Fehler zu verhindern, wie:
- Abstürze (Zugriff auf ungültigen Speicher)
- Datenkorruption (Schreiben an falsche Stellen)
- Sicherheitslücken (Bugs, die Angreifer ausnutzen können)
Viele schwerwiegende Sicherheitsprobleme lassen sich auf Speicherfehler wie Use-after-free oder Buffer-Overflows zurückführen.
Dieser Leitfaden ist ein nicht-technischer Überblick über die wichtigsten Speicher-Modelle populärer Sprachen, was sie optimieren und welche Kompromisse Sie eingehen, wenn Sie sich für eines entscheiden.
Kernkonzepte: Stack, Heap und Objekt-Lebensdauern
Speicher ist der Ort, an dem Ihr Programm Daten hält, während es läuft. Die meisten Sprachen ordnen das um zwei Hauptbereiche: den Stack und den Heap.
Stack: schnelle, temporäre Speicherung
Denken Sie an den Stack wie an einen sauberen Stapel Notizzettel für die aktuelle Aufgabe. Wenn eine Funktion beginnt, bekommt sie einen kleinen "Frame" auf dem Stack für lokale Variablen. Wenn die Funktion endet, wird dieser gesamte Frame auf einmal entfernt.
Das ist schnell und vorhersehbar – funktioniert aber nur für Werte, deren Größe bekannt ist und deren Lebensdauer mit dem Funktionsaufruf endet.
Heap: flexible, längerlebige Speicherung
Der Heap ist mehr wie ein Lagerraum, in dem Sie Objekte so lange aufbewahren können, wie Sie möchten. Er ist nützlich für dynamisch große Listen, Strings oder Objekte, die von verschiedenen Teilen des Programms geteilt werden.
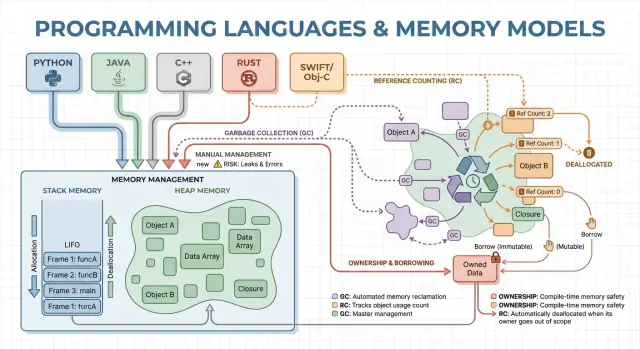
Da Heap-Objekte länger als eine einzelne Funktion leben können, wird die zentrale Frage: wer ist verantwortlich für das Freigeben und wann geschieht das? Diese Verantwortung ist das "Speicherverwaltungsmodell" einer Sprache.
Lebensdauern und warum Pointer/Referenzen wichtig sind
Ein Pointer oder Referenz ist ein indirekter Zugriff auf ein Objekt – wie die Regalfach-Nummer für eine Kiste im Lager. Wenn die Kiste weggeworfen wird, Sie aber noch die Regalfach-Nummer haben, können Sie Müll lesen oder abstürzen (klassischer Use-after-free-Bug).
Ein einfaches Szenario
Stellen Sie sich eine Schleife vor, die einen Kunden-Datensatz erstellt, eine Nachricht formatiert und sie verwirft:
- Auf dem Stack: kleine temporäre Variablen, die nur während der Formatierung gebraucht werden.
- Auf dem Heap: der Kunden-Datensatz und die Nachrichtentexte (unterschiedliche Größen).
Einige Sprachen verbergen diese Details (automatische Aufräumlogik), andere machen sie sichtbar (Sie geben Speicher explizit frei oder müssen Regeln zum Besitz eines Objekts befolgen). Der Rest dieses Artikels untersucht, wie diese Entscheidungen Geschwindigkeit, Pausen und Sicherheit beeinflussen.
Manuelle Speicherverwaltung: Kontrolle mit höherem Risiko
Manuelle Speicherverwaltung bedeutet, dass das Programm (und damit der Entwickler) Speicher explizit anfordert und später freigibt. Praktisch sieht das so aus wie malloc/free in C oder new/delete in C++. Es ist in der Systemprogrammierung weiterhin verbreitet, wenn Sie präzise Kontrolle darüber brauchen, wann Speicher belegt und zurückgegeben wird.
Wofür explizite Allokation/Freigabe eingesetzt wird
Sie allokieren typischerweise Speicher, wenn ein Objekt länger als der aktuelle Funktionsaufruf leben muss, dynamisch wächst (z. B. ein veränderlicher Puffer) oder ein bestimmtes Layout für Interoperabilität mit Hardware, Betriebssystemen oder Netzwerken benötigt.
Ohne einen Garbage Collector im Hintergrund gibt es weniger überraschende Pausen. Allokation und Deallokation können sehr vorhersehbar gestaltet werden, besonders in Kombination mit benutzerdefinierten Allokatoren, Pools oder Fixed-Size-Buffern.
Manuelle Kontrolle kann auch Overhead reduzieren: kein Tracing, keine Write-Barrieren und oft weniger Metadaten pro Objekt. Bei sorgfältigem Design erreichen Sie enge Latenzziele und halten den Speicherverbrauch in engen Grenzen.
Sicherheitsrisiken: klassische Fehlerarten
Der Kompromiss besteht darin, dass das Programm Fehler machen kann, die die Laufzeit nicht automatisch verhindert:
- Speicherlecks (vergessen zu freeen)
- Double-free (zweimal freigeben)
- Use-after-free (Zugriff nach Freigabe)
Diese Bugs können Abstürze, Datenkorruption und Sicherheitslücken verursachen.
Übliche Gegenmaßnahmen
Teams reduzieren Risiken, indem sie einschränken, wo rohe Allokation erlaubt ist, und auf Muster setzen wie:
- RAII in C++ (Ressourcen werden beim Verlassen des Scopes automatisch freigegeben)
- Smart Pointers (z. B.
std::unique_ptr) zur Kodierung von Besitzverhältnissen
- Coding-Standards, Code-Reviews, Sanitizer und statische Analyse
Wann es gut passt
Manuelle Speicherverwaltung ist oft eine starke Wahl für Embedded-Software, Echtzeitsysteme, OS-Komponenten und performancekritische Bibliotheken – Bereiche, in denen enge Kontrolle und vorhersehbare Latenz wichtiger sind als Entwicklerkomfort.
Garbage Collection: Produktivität und vorhersehbare Sicherheit
Garbage Collection (GC) ist automatische Speicherbereinigung: Anstatt dass Sie Speicher selbst freigeben, verfolgt die Laufzeit Objekte und gibt jene zurück, die nicht mehr erreichbar sind. Das erlaubt, sich stärker auf Verhalten und Datenfluss zu konzentrieren, während das System die meisten Allokations- und Deallokationsentscheidungen übernimmt.
Wie GC ungenutzte Objekte findet
Die meisten Collector identifizieren zuerst lebendige Objekte und geben dann den Rest frei.
Tracing-GC startet bei den "Roots" (z. B. Stack-Variablen, globale Referenzen, Register), folgt Referenzen, markiert alles Erreichbare und säubert danach den Heap. Wenn nichts auf ein Objekt zeigt, ist es sammelbar.
Gängige GC-Stile (auf hohem Niveau)
Generational GC beruht auf der Beobachtung, dass viele Objekte jung sterben. Der Heap wird in Generationen aufgeteilt und der junge Bereich häufiger gesammelt, was meist günstiger ist und die Effizienz verbessert.
Concurrent GC führt Teile der Sammlung neben den Anwendungsthreads aus, um lange Pausen zu reduzieren. Dazu ist mehr Buchhaltung nötig, damit während der Laufzeit eine konsistente Sicht auf den Speicher erhalten bleibt.
GC tauscht typischerweise manuelle Kontrolle gegen Laufzeitarbeit. Manche Systeme priorisieren konstanten Durchsatz (viel Arbeit pro Sekunde), können aber Stop-the-World-Pausen verursachen. Andere minimieren Pausen für latenzsensitive Apps, fügen dabei aber Laufzeit-Overhead hinzu.
Warum Entwickler es mögen
GC entfernt eine ganze Klasse von Lifetime-Bugs (besonders Use-after-free), weil Objekte nicht zurückgegeben werden, solange sie erreichbar sind. Es reduziert auch Leaks, die durch vergessenes Freigeben entstehen (obwohl man durch zu lange gehaltene Referenzen immer noch "leaken" kann). In großen Codebasen, in denen Besitz schwer nachzuverfolgen ist, beschleunigt das oft Iteration und Entwicklung.
Wo Sie GC finden
Garbage-collected Runtimes sind üblich in der JVM (Java, Kotlin), .NET (C#, F#), Go und in JavaScript-Engines (Browser, Node.js).
Referenzzählung: sofortiges Aufräumen mit Kompromissen
Mobile Version prototypen
Teste denselben Workflow in Flutter, um den Speicherbedarf auf mobilen Geräten zu vergleichen.
Referenzzählung ist eine Strategie, bei der jedes Objekt zählt, wie viele "Besitzer" (Referenzen) darauf zeigen. Fällt der Zähler auf null, wird das Objekt sofort freigegeben. Diese Unmittelbarkeit fühlt sich intuitiv an: Sobald nichts das Objekt erreicht, wird sein Speicher freigegeben.
Wie es funktioniert (und warum es attraktiv ist)
Jedes Mal, wenn Sie eine Referenz kopieren oder speichern, erhöht die Laufzeit den Zähler; verschwindet eine Referenz, wird er verringert. Null führt zur sofortigen Bereinigung.
Das macht Ressourcenmanagement einfach: Objekte werden oft direkt nach dem letzten Gebrauch freigegeben, was den Spitzen-Speicherbedarf reduzieren und verzögerte Freigaben vermeiden kann.
Referenzzählung erzeugt meist gleichmäßigen, konstanten Overhead: Inkrement-/Dekrement-Operationen passieren bei vielen Zuweisungen und Funktionsaufrufen. Dieser Overhead ist klein, aber allgegenwärtig.
Der Vorteil ist, dass Sie typischerweise keine großen Stop-the-World-Pausen wie bei manchen Tracing-GCs bekommen. Die Latenz ist oft ruhiger, obwohl Entfaltungsstöße von Deallokationen auftreten können, wenn große Objektgraphen ihren letzten Besitzer verlieren.
Die große Schwäche: Zyklen
Referenzzählung kann Objekte in Zyklen nicht aufräumen. Wenn A B referenziert und B A, bleiben beide Zähler über null, selbst wenn niemand sonst darauf zugreift — das erzeugt ein Speicherleck.
Ökosysteme gehen damit unterschiedlich um:
- Weak References (nicht-besitzende Pointer) zum Aufbrechen typischer Zyklen (Delegates, Parent/Child-Links)
- Zyklendetektion als zusätzliche Schicht über Referenzzählung (Tracing-Pass zur Sammlung zyklischer Garbage)
Wo Sie es sehen
- Swift / Objective-C nutzen ARC (Automatic Reference Counting) mit „strong/weak/unowned“-Referenzen zur Zyklusverwaltung.
- Python verwendet Referenzzählung für sofortiges Aufräumen und ergänzt das durch einen Zyklendetektor.
Ownership und Borrowing: Compile-Time-Speichersicherheit
Ownership und Borrowing ist ein Speicher-Modell, das am engsten mit Rust verbunden ist. Die Idee: Der Compiler erzwingt Regeln, die es schwer machen, dangling pointers, double-frees und viele Datenrennen zu erzeugen – ganz ohne Garbage Collector zur Laufzeit.
Ownership: ein klarer Besitzer, deterministisches Aufräumen
Jeder Wert hat genau einen Besitzer. Wenn der Besitzer aus dem Scope geht, wird der Wert sofort und vorhersehbar freigegeben. Das gibt deterministisches Ressourcenmanagement (Speicher, Dateihandles, Sockets) ähnlich der manuellen Freigabe, aber mit deutlich weniger Fehlerquellen.
Besitz kann auch verschoben werden: Eine Zuweisung oder ein Funktionsaufruf kann Responsibility transferieren. Nach einem Move kann die alte Bindung nicht mehr genutzt werden, wodurch Use-after-free durch Konstruktion verhindert wird.
Borrowing: temporärer Zugriff ohne Besitzübernahme
Borrowing erlaubt die Nutzung eines Werts, ohne dessen Besitzer zu werden.
Ein Shared Borrow erlaubt nur Lesezugriff und kann frei kopiert werden.
Ein Mutable Borrow erlaubt Änderungen, muss aber exklusiv sein: Solange es existiert, darf nichts anderes denselben Wert lesen oder schreiben. Diese "ein Schreiber oder viele Leser"-Regel wird zur Compile-Zeit geprüft.
Sicherheitsvorteile — und die Kosten
Da Lifetimes nachverfolgt werden, kann der Compiler Code ablehnen, der länger leben würde als die Daten, auf die er zeigt. Viele dangling-reference-Bugs werden so eliminiert. Dieselben Regeln verhindern zudem eine große Klasse von Race Conditions in nebenläufigem Code.
Der Nachteil ist eine Lernkurve und einige Designbeschränkungen. Sie müssen möglicherweise Datenflüsse umstrukturieren, klarere Besitzgrenzen einführen oder spezielle Typen für gemeinsam mutable Zustände nutzen.
Wo es glänzt
Dieses Modell passt sehr gut zu Systemcode — Dienste, Embedded, Networking und performancekritische Komponenten — wenn Sie deterministisches Aufräumen und niedrige Latenz ohne GC-Pausen wollen.
Arenas, Regionen und Pools: schnelle Allokationsmuster
Bereitstellen und Verhalten prüfen
Stelle eine funktionierende App bereit und beobachte, wie der Speicherbedarf unter realer Last variiert.
Wenn Sie viele kurzlebige Objekte erzeugen (AST-Knoten im Parser, Entities in einem Spiel-Frame, temporäre Daten während einer Web-Anfrage), können Allokations- und Freigabekosten pro Objekt zur dominierenden Laufzeit werden. Arenas (auch Regionen) und Pools tauschen feingranulares Freigeben gegen schnelles Bulk-Management ein.
Was Arenas/Regionen sind
Eine Arena ist eine Speicherzone, in der Sie viele Objekte allokieren und dann alle auf einmal freigeben, indem Sie die Arena droppen oder zurücksetzen.
Statt jede Lebensdauer einzeln zu verfolgen, binden Sie sie an eine klare Grenze: „alles, was für diese Anfrage alloziert wurde“ oder „alles, was beim Kompilieren dieser Funktion alloziert wurde".
Warum das schnell sein kann
Arenas sind oft schnell, weil sie:
- Allokationsaufrufe reduzieren (häufig nur Pointer-Bumping)
- Kosten pro Objekt-Freigabe vermeiden
- Cache-Lokalität verbessern, da verwandte Objekte nahe beieinander liegen
Das kann Durchsatz verbessern und Latenzspitzen reduzieren, die durch häufige Freigaben oder Allokator-Contention entstehen.
Typische Anwendungsfälle
Arenas und Pools tauchen auf in:
- Parsern und Compilern (Syntaxbäume, Symboltabellen)
- Request-scoped Serverdaten (allokieren während Anfrage, freigeben am Ende)
- Spielen (pro-Frame-Allokationen, die jeden Frame zurückgesetzt werden)
- Simulationen und Batch-Jobs
Sicherheitsaspekte
Die Hauptregel ist einfach: Lassen Sie Referenzen nicht aus der Region entweichen, die den Speicher besitzt. Wenn etwas aus einer Arena global gespeichert oder über die Lebenszeit der Arena zurückgegeben wird, riskieren Sie Use-after-free-Bugs.
Sprachen und Bibliotheken handhaben das unterschiedlich: Manche verlassen sich auf Disziplin und APIs, andere kodieren die Regionsgrenze in Typen.
Wie es andere Ansätze ergänzt
Arenas und Pools sind keine Alternative zu GC oder Ownership — sie sind oft ein Zusatz. GC-Sprachen nutzen Object-Pools für heiße Pfade; ownership-basierte Sprachen verwenden Arenas, um Allokationen zu gruppieren und Lebensdauern explizit zu machen. Richtig eingesetzt liefern sie „fast by default“-Allokation ohne Verlust an Klarheit, wann Speicher freigegeben wird.
Compiler- und Laufzeitoptimierungen, die die Geschichte verändern
Das Speicher-Modell einer Sprache ist nur ein Teil der Performance- und Sicherheitsgeschichte. Moderne Compiler und Runtimes überarbeiten Ihr Programm, um weniger zu allozieren, früher freizugeben und zusätzliche Buchhaltung zu vermeiden. Deshalb brechen einfache Faustregeln wie „GC ist langsam“ oder „manuell ist am schnellsten“ oft in realen Anwendungen zusammen.
Escape-Analyse: wenn der Heap unnötig ist
Viele Allokationen dienen nur dazu, Daten zwischen Funktionen zu übergeben. Mit Escape-Analyse kann ein Compiler beweisen, dass ein Objekt nie den aktuellen Scope verlässt und es stattdessen auf dem Stack belassen.
Das kann eine Heap-Allokation ganz entfernen, ebenso die damit verbundenen Kosten (GC-Tracking, Referenzzähler-Updates, Allokator-Locks). In Managed-Sprachen ist das ein wichtiger Grund, warum kleine Objekte günstiger sein können als erwartet.
Inlining und Allokationsentfernung
Wenn ein Compiler eine Funktion inlined (den Aufruf durch den Funktionskörper ersetzt), sieht er oft durch Abstraktionsschichten hindurch. Diese Sichtbarkeit ermöglicht Optimierungen wie:
- Eliminieren temporärer Objekte
- Scalar Replacement (Umwandlung eines Objekts in ein paar lokale Variablen)
- Entfernen von Referenzzählungsverkehr, wenn Lifetimes offensichtlich werden
Gut gestaltete APIs können nach Optimierung "zero-cost" werden, selbst wenn sie im Quellcode allokationsintensiv wirken.
JIT vs. Ahead-of-Time-Compilation
Ein JIT kann anhand realer Produktionsdaten optimieren: welche Pfade heiß laufen, typische Objektgrößen und Allokationsmuster. Das verbessert oft den Durchsatz, kann aber Warm-up-Zeit und gelegentliche Pausen für Re-Kompilierung oder GC bedeuten.
Ahead-of-Time-Compiler müssen mehr raten, liefern dafür aber vorhersehbares Startup und gleichmäßigere Latenz.
Laufzeit-Tuninghebel (und wann man sie nutzt)
GC-basierte Runtimes bieten Einstellungen wie Heap-Größe, Pausezeitziele und Generationen-Schwellen. Passen Sie diese nur an, wenn gemessene Indikatoren (Latenzspitzen, Speicherdruck) das rechtfertigen.
Zwei Implementierungen desselben Algorithmus können in versteckten Allokationszahlen, temporären Objekten und Pointer-Chasing variieren. Diese Unterschiede interagieren mit Optimierungen, Allokatoren und Cache-Verhalten — Performance-Vergleiche brauchen Profiling, nicht Annahmen.
Benutzerseitige Latenz prüfen
Kombiniere ein responsives React-Frontend mit einer API, um Latenzspitzen schnell zu erkennen.
Speicherverwaltungsentscheidungen verändern nicht nur, wie Sie Code schreiben — sie ändern wann Arbeit geschieht, wie viel Speicher reserviert werden muss und wie konsistent die Performance für Nutzer wirkt.
Durchsatz vs. Latenz (konkretes Beispiel)
Durchsatz ist "wie viel Arbeit pro Zeiteinheit". Denken Sie an einen nächtlichen Batch-Job, der 10 Millionen Datensätze verarbeitet: Wenn GC oder Referenzzählung kleinen Overhead hinzufügen, aber die Entwicklerproduktivität erhöhen, sind Sie möglicherweise insgesamt am schnellsten.
Latenz ist "wie lange eine einzelne Operation dauert". Für einen Web-Request schadet eine einzelne langsame Antwort die Nutzererfahrung, auch wenn der Durchschnittsdurchsatz hoch ist. Ein Runtime, das gelegentlich zur Speicherbereinigung pausiert, kann für Batch-Processing in Ordnung sein, aber in interaktiven Apps auffallen.
Ein größerer Speicher-Footprint erhöht Cloud-Kosten und kann Programme verlangsamen. Passt der Working-Set nicht gut in CPU-Caches, wartet die CPU häufiger auf Daten aus RAM. Manche Strategien opfern Speicher für Geschwindigkeit (z. B. gecachte/freigehaltene Objekte), andere reduzieren Speicher mit zusätzlicher Buchhaltung.
Fragmentierung und Cache-Lokalität (einfach erklärt)
Fragmentierung entsteht, wenn freier Speicher in viele kleine Lücken aufgeteilt ist — wie einen Parkplatz mit verstreuten Mini-Plätzen. Allokatoren verbringen mehr Zeit mit der Suche nach Platz, und der Speicherbedarf wächst, obwohl technisch genug frei ist.
Cache-Lokalität bedeutet, dass verwandte Daten nahe beieinander liegen. Pool-/Arena-Allokationen verbessern oft die Lokaliät, während langlebige Heaps mit gemischten Objektgrößen in weniger cache-freundliche Layouts abdriften können.
Vorhersehbare Timing-Anforderungen
Wenn Sie konsistente Antwortzeiten brauchen — Spiele, Audio-Apps, Trading-Systeme, Embedded- oder Echtzeit-Controller — ist "meist schnell, aber gelegentlich langsam" oft schlechter als "etwas langsamer, aber konsistent". Hier zählen vorhersehbare Deallokationen und enge Kontrolle über Allokationen.
Mess-Checkliste
- Benchmarken Sie sowohl Durchsatz (Jobs/sec) als auch Tail-Latenz (p95/p99)
- Profilieren Sie Allokationen: Allokationsrate, Pausenzeiten und Zeit in Alloc/Free
- Verwenden Sie repräsentative Lasten (echte Traffic-Formen, Datengrößen, Parallelität)
- Verfolgen Sie Speicher: Peak RSS, Heap-Größe über Zeit, Fragmentierungsmetriken (falls verfügbar)
- Wiederholen Sie Läufe, um Variabilität zu erfassen (Warm-up-Effekte, Hintergrund-GC-Zyklen)
Sicherheit und Schutz: Wie Speicher-Modelle häufige Fehler verhindern
Speicherfehler sind nicht nur "Programmiererfehler". In vielen realen Systemen werden sie zu Sicherheitsproblemen: plötzliche Abstürze (Denial of Service), versehentliche Datenfreigabe (Lesen freigegebenen oder uninitialisierten Speichers) oder ausnutzbare Bedingungen, bei denen Angreifer ein Programm dazu bringen, unerwünschten Code auszuführen.
Wie Bugs zu Speicher-Modellen passen
Verschiedene Speicherverwaltungsstrategien haben tendenziell unterschiedliche Ausfallarten:
- Manuelle Verwaltung (z. B. C/C++) riskiert häufig Use-after-free, Double-free und Buffer Overflows — Probleme, die Speicher korruptieren und ausnutzbar machen können.
- Garbage Collection entfernt die meisten Use-after-free-Fehler, weil Objekte nicht freigegeben werden, solange sie erreichbar sind. Allerdings bleiben Speicherlecks (durch zu lange gehaltene Referenzen) und unsichere native Interop-Pfade mögliche Probleme.
- Referenzzählung sorgt für vorhersehbares Aufräumen, kann aber durch Zyklen lecken und weist subtile Lifetime-Fragen bei gemeinsamem mutablen Zustand auf.
- Ownership/Borrowing (z. B. Rust) verhindert viele Klassen von UAF- und Datenrace-Fehlern bereits zur Compile-Zeit, indem es Dangling-Referenzen und unsynchronisierte gemeinsame Mutation erschwert.
Threadsicherheit und Parallelität
Nebenläufigkeit verändert das Bedrohungsbild: Speicher, der in einem Thread „in Ordnung“ ist, kann gefährlich werden, wenn ein anderer Thread ihn freigibt oder verändert. Modelle, die Regeln ums Teilen durchsetzen (oder explizite Synchronisation verlangen), reduzieren das Risiko von Race Conditions, die zu Zustandskorruption, Datenlecks und intermittierenden Abstürzen führen.
Defense in depth bleibt nötig
Kein Speicher-Modell entfernt alle Risiken — Logikfehler (Authentifizierungsfehler, unsichere Defaults, fehlerhafte Validierung) treten weiter auf. Starke Teams bündeln Schutzmaßnahmen: Sanitizer im Testing, sichere Standardbibliotheken, sorgfältige Code-Reviews, Fuzzing und strikte Grenzen rund um unsicheren/FFI-Code. Speichersicherheit reduziert die Angriffsfläche erheblich, ist aber keine Garantie.