SQL vs NoSQL-Datenbanken: Wichtige Unterschiede und Anwendungsfälle
Erfahren Sie die wesentlichen Unterschiede zwischen SQL- und NoSQL-Datenbanken: Datenmodelle, Skalierbarkeit, Konsistenz und wann welcher Typ für Ihre Anwendungen am besten geeignet ist.
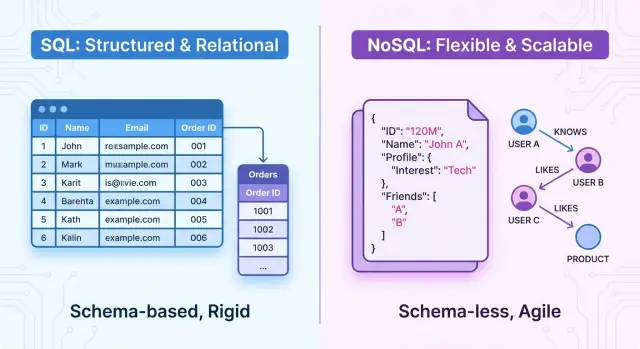
Überblick: SQL und NoSQL im Schnellcheck
Die Wahl zwischen SQL‑ und NoSQL‑Datenbanken prägt, wie Sie Ihre Anwendung entwerfen, bauen und skalieren. Das Datenbankschema beeinflusst alles, von Datenstrukturen und Abfrage‑Mustern bis hin zu Performance, Zuverlässigkeit und der Geschwindigkeit, mit der Ihr Team das Produkt weiterentwickeln kann.
Auf hoher Ebene sind SQL‑Datenbanken relationale Systeme. Daten werden in Tabellen mit festen Schemata, Zeilen und Spalten organisiert. Beziehungen zwischen Entitäten sind explizit (z. B. über Fremdschlüssel) und Sie fragen Daten mit SQL ab — einer mächtigen deklarativen Sprache. Diese Systeme legen Wert auf ACID‑Transaktionen, starke Konsistenz und eine klar definierte Struktur.
NoSQL‑Datenbanken sind nicht‑relationale Systeme. Anstelle eines starren Tabellenmodells bieten sie verschiedene Datenmodelle für unterschiedliche Anforderungen, zum Beispiel:
- Key‑Value‑Stores
- Dokumenten‑Datenbanken
- Wide‑Column‑Stores
- Graph‑Datenbanken
Das bedeutet: „NoSQL“ ist keine einzelne Technologie, sondern ein Sammelbegriff für mehrere Ansätze, jeweils mit eigenen Kompromissen in Flexibilität, Performance und Datenmodellierung. Viele NoSQL‑Systeme lockern strikte Konsistenzgarantien zugunsten hoher Skalierbarkeit, Verfügbarkeit oder geringer Latenz.
Dieser Beitrag konzentriert sich auf die Unterschiede zwischen SQL und NoSQL — Datenmodelle, Abfragesprachen, Performance, Skalierbarkeit und Konsistenz (ACID vs. eventual consistency). Ziel ist es, Ihnen bei der Entscheidung zwischen SQL und NoSQL für konkrete Projekte zu helfen und zu zeigen, wann welcher Typ am besten passt.
Sie müssen nicht nur eine Technologie wählen: Viele moderne Architekturen nutzen polyglotte Persistenz, wobei SQL‑ und NoSQL‑Datenbanken nebeneinander bestehen und jeweils die Workloads übernehmen, für die sie am besten geeignet sind.
Was ist eine SQL (relationale) Datenbank?
Eine SQL (relationale) Datenbank speichert Daten strukturiert in Tabellenform und verwendet Structured Query Language (SQL), um Daten zu definieren, abzufragen und zu manipulieren. Sie basiert auf dem mathematischen Konzept der Relationen, die man sich als gut organisierte Tabellen vorstellen kann.
Kernstruktur: Tabellen, Zeilen, Spalten und Schemata
Daten sind in Tabellen organisiert. Jede Tabelle repräsentiert eine Entität, z. B. customers, orders oder products.
- Eine Zeile (Datensatz) ist eine einzelne Instanz dieser Entität, etwa ein Kunde.
- Eine Spalte (Feld) ist ein Attribut wie
emailoderorder_date.
Jede Tabelle folgt einem festen Schema: sie legt fest,
- welche Spalten existieren,
- deren Datentypen (z. B.
INTEGER,VARCHAR,DATE) und - Einschränkungen (
NOT NULL,UNIQUEusw.).
Das Schema wird von der Datenbank durchgesetzt, was hilft, Daten konsistent und vorhersehbar zu halten.
Schlüssel und Beziehungen
Relationale Datenbanken sind hervorragend darin, Beziehungen zwischen Entitäten abzubilden.
- Ein Primärschlüssel identifiziert jede Zeile eindeutig (z. B.
customer_id). - Ein Fremdschlüssel verweist auf einen Primärschlüssel in einer anderen Tabelle und verknüpft so verwandte Zeilen.
Damit lassen sich Beziehungen wie
- Eins‑zu‑viele (ein Kunde, viele Bestellungen)
- Viele‑zu‑viele (Produkte in vielen Bestellungen, Bestellungen mit vielen Produkten)
modellieren.
Transaktionen und ACID‑Eigenschaften
Relationale Datenbanken unterstützen Transaktionen — Gruppen von Operationen, die als eine Einheit betrachtet werden. Transaktionen folgen den ACID‑Eigenschaften:
- Atomicity: alle Operationen gelingen komplett oder gar nicht.
- Consistency: Transaktionen bringen die Datenbank von einem gültigen Zustand in einen anderen.
- Isolation: gleichzeitige Transaktionen stören sich nicht gegenseitig.
- Durability: einmal committete Daten sind dauerhaft gespeichert.
Diese Garantien sind entscheidend für Finanzsysteme, Inventarverwaltung und alle Anwendungen, bei denen Korrektheit zählt.
Gängige SQL‑Datenbanken
Populäre relationale Systeme sind:
- MySQL und MariaDB
- PostgreSQL
- Microsoft SQL Server
- Oracle Database
Alle implementieren SQL und bieten zusätzlich eigene Erweiterungen sowie Werkzeuge für Administration, Performance‑Tuning und Sicherheit.
Was ist eine NoSQL (nicht‑relationale) Datenbank?
NoSQL‑Datenbanken sind nicht‑relationale Datenspeicher, die nicht das traditionelle Tabellen‑/Zeilen‑/Spalten‑Modell verwenden. Stattdessen setzen sie auf flexible Datenmodelle, horizontale Skalierung und hohe Verfügbarkeit — oft auf Kosten strikter Transaktionsgarantien.
Flexible Datenmodelle
Viele NoSQL‑Datenbanken gelten als schema‑los oder schema‑flexibel. Anstatt ein starres Schema vorab zu definieren, können Datensätze mit unterschiedlichen Feldern in derselben Collection oder in demselben Bucket gespeichert werden.
Das ist besonders nützlich für:
- sich schnell ändernde Anforderungen
- semi‑strukturierte Daten (Logs, Events, Benutzerprofile)
- verschachtelte Daten wie JSON‑Dokumente
Da Felder pro Datensatz hinzugefügt oder weggelassen werden können, können Entwickler schneller iterieren, ohne für jede Strukturänderung Migrationsschritte durchzuführen.
Haupttypen von NoSQL
NoSQL ist ein Sammelbegriff für mehrere Modelle:
- Dokumenten‑Datenbanken: Speichern Daten als JSON‑ähnliche Dokumente mit verschachtelten Feldern. Beispiele: MongoDB, Couchbase.
- Key‑Value‑Stores: Einfache assoziative Arrays, geeignet für Caching und Session‑Daten. Beispiele: Redis, Amazon DynamoDB (Key‑Value‑Modus).
- Column‑Family‑Stores: Organisieren Daten nach Column‑Families für hohen Schreibdurchsatz und breite Tabellen. Beispiele: Apache Cassandra, HBase.
- Graph‑Datenbanken: Fokus auf Nodes und Beziehungen, ideal für stark vernetzte Daten. Beispiele: Neo4j, Amazon Neptune.
Konsistenzmodelle
Viele NoSQL‑Systeme priorisieren Verfügbarkeit und Partitionstoleranz und bieten eventual consistency statt strikter ACID‑Transaktionen über das gesamte Dataset. Einige erlauben jedoch einstellbare Konsistenzniveaus oder begrenzte Transaktionen (pro Dokument, Partition oder Schlüsselbereich), sodass Sie zwischen stärkeren Garantien und höherer Performance wählen können.
Datenmodelle: Struktur, Schemata und Beziehungen
Beim Datenmodellieren zeigen sich die größten Unterschiede zwischen SQL und NoSQL. Das Modell beeinflusst, wie Sie Features designen, Daten abfragen und die Anwendung weiterentwickeln.
Struktur und Schemata
SQL‑Datenbanken verwenden strukturierte, vordefinierte Schemata. Sie entwerfen Tabellen und Spalten im Vorfeld mit strikten Typen und Constraints:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL
);
CREATE TABLE orders (
id INT PRIMARY KEY,
user_id INT NOT NULL,
total DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
);
Jede Zeile muss dem Schema entsprechen. Änderungen erfordern meist Migrationen (ALTER TABLE, Backfills usw.).
NoSQL‑Datenbanken unterstützen typischerweise flexible Schemata. Ein Dokumentenspeicher kann erlauben, dass jedes Dokument unterschiedliche Felder hat:
{
"_id": 1,
"name": "Alice",
"orders": [
{ "id": 101, "total": 49.99 },
{ "id": 102, "total": 15.50 }
]
}
Felder können pro Dokument hinzugefügt werden, ohne zentrale Schema‑Migrationen. Einige NoSQL‑Systeme bieten dennoch optionale oder durchsetzbare Schemata, sind aber im Allgemeinen lockerer.
Normalisierung vs. Denormalisierung
Relationale Modelle fördern Normalisierung: Aufteilung in verwandte Tabellen, um Duplikate zu vermeiden und Integrität zu wahren. Das führt zu schnellen, konsistenten Schreiboperationen und geringerem Speicherbedarf, kann aber komplexe Lesevorgänge erfordern, die viele Joins benötigen.
NoSQL‑Modelle bevorzugen häufig Denormalisierung: Eingebettete oder redundante Daten für die Lesezugriffe, die am wichtigsten sind. Das verbessert Leseperformance und vereinfacht Abfragen, kann aber Schreiboperationen verlangsamen oder komplexer machen, weil dieselben Informationen an mehreren Stellen vorliegen.
Beziehungen modellieren
In SQL sind Beziehungen explizit und werden durch die Datenbank durchgesetzt:
- Eins‑zu‑viele: Fremdschlüssel (users → orders)
- Viele‑zu‑viele: Join‑Tabellen (users_roles)
In NoSQL werden Beziehungen typischerweise durch:
- Embedding (das Benutzerdokument enthält ein orders‑Array) für stark gekoppelte Daten
- Referencing (user_id im Bestelldokument) für lose gekoppelte oder große Sammlungen
Die Wahl richtet sich nach Ihren Zugriffsgewohnheiten:
- Wenn Sie immer einen Nutzer und dessen 10 neueste Bestellungen zusammen abrufen, ist Embedding ideal.
- Sind Bestellungen sehr groß, werden häufig aktualisiert oder unabhängig abgerufen, sind Referenzen und separate Abfragen besser.
Auswirkungen auf sich ändernde Anforderungen
Bei SQL erfordern Schemaänderungen mehr Planung, geben Ihnen aber starke Garantien und Konsistenz über das gesamte Dataset. Refactorings sind explizit: Migrationen, Backfills, Anpassung von Constraints.
Bei NoSQL sind Änderungen meist kurzfristig leichter zu unterstützen: Sie können sofort neue Felder speichern und alte Dokumente nach und nach aktualisieren. Der Nachteil ist, dass die Anwendung mehrere Dokument‑Formen und Randfälle handhaben muss.
Die Entscheidung zwischen normalisierten SQL‑Modellen und denormalisierten NoSQL‑Modellen ist weniger eine Frage von „besser oder schlechter“ als eine Frage der Ausrichtung des Datenmodells auf Ihre Abfrage‑Patterns, Schreiblast und der Häufigkeit von Domain‑Änderungen.
Abfragesprachen und Zugriffs‑Patterns
SQL: deklarativ und standardisiert
SQL‑Datenbanken werden mit einer deklarativen Sprache abgefragt: Sie beschreiben was Sie wollen, nicht wie es zu holen ist. Kernkonstrukte wie SELECT, WHERE, JOIN, GROUP BY und ORDER BY erlauben komplexe Abfragen über mehrere Tabellen in einer einzigen Anweisung.
Da SQL standardisiert ist (ANSI/ISO), teilen die meisten relationalen Systeme einen gemeinsamen Kernsyntax. Anbieter erweitern diese um eigene Features, aber Kenntnisse und Abfragen lassen sich oft zwischen PostgreSQL, MySQL, SQL Server usw. transferieren.
Diese Standardisierung bringt ein reiches Ökosystem: ORMs, Query‑Builder, Reporting‑Tools, BI‑Dashboards, Migrations‑Frameworks und Query‑Optimizer. Viele dieser Tools lassen sich mit geringem Aufwand an verschiedene SQL‑Datenbanken anbinden, was Vendor‑Lock‑in reduziert und Entwicklung beschleunigt.
NoSQL: Abfrage‑APIs und Muster
NoSQL‑Systeme bieten vielfältigere Abfrageformen:
- Dokumentenstores (MongoDB, Couchbase) verwenden JSON‑ähnliche Query‑Objekte und eigene Sprachen.
- Key‑Value‑Stores (Redis, DynamoDB‑APIs) konzentrieren sich auf Primärschlüssel‑Lookups und wenige sekundäre Index‑Abfragen.
- Wide‑Column‑Stores (Cassandra, HBase) optimieren Abfragen, die einem vordefinierten Primär- und Clustering‑Key folgen.
- Suchmaschinen (Elasticsearch, Solr) nutzen DSLs für Volltext und Relevanz‑Abfragen.
Manche NoSQL‑Datenbanken bieten Aggregations‑Pipelines oder MapReduce‑Mechanismen für Analysen, aber Cross‑Collection‑ oder Cross‑Partition‑Joins sind begrenzt oder nicht vorhanden. Stattdessen werden verwandte Daten oft im selben Dokument eingebettet oder über Datensätze denormalisiert.
Zugriffs‑Patterns und Produktivität
Relationale Abfragen nutzen häufig JOIN‑schwere Muster: Daten normalisieren und zur Laufzeit durch Joins rekonstruieren. Das ist mächtig für Ad‑hoc‑Reporting, aber komplexe Joins können schwer zu optimieren und zu verstehen sein.
NoSQL‑Zugriffe sind eher dokument‑ oder schlüsselzentriert: Daten werden um die häufigsten Abfragen herum gestaltet. Lesezugriffe sind schnell und einfach — oft nur ein Key‑Lookup — doch veränderte Zugriffsanforderungen können ein Umgestalten der Daten erfordern.
Zur Produktivität:
- SQLs deklaratives Modell und die Fülle an Lernressourcen machen es zugänglich und beständig als Skill.
- NoSQL‑Abfragen sind für einfache, bekannte Patterns oft leichter, aber jedes System hat eigene Syntaxen und Beschränkungen; Skills sind weniger portabel.
Teams, die reichhaltige, Ad‑hoc‑Abfragen über Beziehungen benötigen, bevorzugen meist SQL. Teams mit stabilen, vorhersehbaren Patterns bei extremem Maßstab finden NoSQL‑Modelle oft geeigneter.
Konsistenz, Transaktionen und das CAP‑Dilemma
ACID: strikte Garantien in SQL‑Systemen
Die meisten SQL‑Datenbanken sind um ACID‑Transaktionen herumgebaut:
- Atomicity: eine Transaktion gelingt vollständig oder gar nicht.
- Consistency: jede commitete Transaktion bringt die Daten in einen gültigen Zustand und erzwingt Constraints.
- Isolation: parallele Transaktionen beeinflussen sich nicht sichtbar (Isolationsebenen wie READ COMMITTED, REPEATABLE READ, SERIALIZABLE).
- Durability: commitete Daten überdauern Abstürze (z. B. via Write‑Ahead‑Logs, Replikation).
Das macht SQL‑Datenbanken zur starken Wahl, wenn Korrektheit wichtiger ist als reiner Schreibdurchsatz.
BASE und eventual consistency in vielen NoSQL‑Systemen
Viele NoSQL‑Datenbanken tendieren zu BASE:
- Basically Available: das System versucht, stets verfügbar zu sein.
- Soft state: Daten können temporär zwischen Replikaten differieren.
- Eventual consistency: ohne weitere Updates konvergieren Replikate irgendwann.
Schreibvorgänge können sehr schnell und verteilt erfolgen, aber ein Lesezugriff kann kurzzeitig veraltete Daten zurückliefern.
CAP‑Theorem in der Praxis
CAP besagt, dass ein verteiltes System bei Netzwerkpartitionen zwischen:
- Consistency (C): alle Clients sehen dieselben Daten zur gleichen Zeit
- Availability (A): jede Anfrage erhält eine Antwort
wählen muss — beides gleichzeitig ist während einer Partition nicht garantiert.
Typische Muster:
- Viele SQL‑Deployments favorisieren starke Konsistenz: passend für Zahlungen, Inventar, Kontostände, Reservierungen, wo veraltete Reads Geld kosten oder rechtliche Regeln verletzen können.
- Viele NoSQL‑Setups favorisieren Verfügbarkeit und eventual consistency: geeignet für Analytics, Social Feeds, Produktkataloge, Logs, Caching, wo kleine, temporäre Inkonsistenzen akzeptabel sind und Geschwindigkeit/Uptime wichtiger sind.
Moderne Systeme mischen oft Modi (z. B. einstellbare Konsistenz pro Operation), sodass verschiedene Teile einer Anwendung die benötigten Garantien wählen können.
Skalierbarkeit und Performance‑Unterschiede
Wie SQL‑Datenbanken üblicherweise skalieren
Traditionelle SQL‑Datenbanken sind für einen einzelnen, leistungsfähigen Knoten ausgelegt.
Man skaliert oft zunächst vertikal: mehr CPU, RAM und schnellere Platten auf einem Server. Viele Engines unterstützen auch Read‑Replicas: zusätzliche Knoten, die nur Leseanfragen übernehmen, während alle Schreibvorgänge zum Primary gehen. Dieses Muster eignet sich für:
- moderate Schreiblast
- analytische bzw. Reporting‑Abfragen
- Workloads, bei denen starke Konsistenz wichtig ist
Vertikales Skalieren stößt jedoch an Hardware‑ und Kostenlimits; Read‑Replicas können Replikationsverzögerungen für Lesenden einführen.
NoSQL und horizontale Skalierung
NoSQL‑Systeme sind meist für horizontale Skalierung konzipiert: Daten werden per Sharding oder Partitionierung auf viele Knoten verteilt. Jeder Shard hält einen Teil der Daten, sodass sowohl Lese‑ als auch Schreiblast verteilt werden können und Durchsatz steigt.
Das passt zu:
- massiven, schreibintensiven Workloads
- sehr großen Datensätzen, die den Speicher eines einzelnen Servers übersteigen
- globalen Anwendungen, die Daten nahe bei den Nutzern halten müssen
Der Preis ist erhöhte operative Komplexität: Auswahl von Shard‑Keys, Rebalancing und Cross‑Shard‑Abfragen.
Performance‑Muster und Indexierung
Für leselastige Workloads mit komplexen Joins und Aggregationen kann eine SQL‑Datenbank mit gutem Indexdesign sehr performant sein — der Optimizer nutzt Statistiken und Query‑Pläne.
Viele NoSQL‑Systeme bevorzugen einfache, schlüsselbasierte Zugriffe. Sie glänzen bei niedriger Latenz und hohem Durchsatz, wenn Abfragen vorhersehbar sind und das Datenmodell darauf abgestimmt ist.
Die Latenz in NoSQL‑Clustern kann sehr gering sein, aber Cross‑Partition‑Abfragen, sekundäre Indizes und Multi‑Document‑Operationen können langsamer oder eingeschränkt sein. Operativ bedeutet Skalierung bei NoSQL oft mehr Cluster‑Management, während bei SQL meist bessere Hardware und sorgfältige Indexierung auf weniger Knoten ausreichen.
Wann SQL meist die bessere Wahl ist
Transaktionsstarke, geschäftskritische Workloads
Relationale Datenbanken sind prädestiniert für zuverlässiges OLTP (Online Transaction Processing):
- Finanzsysteme (Zahlungen, Buchhaltung, Handel)
- Bestell‑ und Inventarverwaltung
- ERP, CRM und Abrechnungssysteme
Diese Systeme benötigen ACID‑Transaktionen, strikte Konsistenz und klare Rollback‑Verhalten. Wenn eine Überweisung niemals doppelt belastet oder Gelder verloren gehen dürfen, ist eine SQL‑Datenbank meist sicherer als die meisten NoSQL‑Alternativen.
Strukturierte Daten und komplexe Beziehungen
Wenn Ihr Datenmodell gut verstanden und stabil ist und Entitäten stark miteinander verknüpft sind, ist eine relationale Datenbank oft die natürliche Wahl. Beispiele:
- Kunden, Bestellungen, Rechnungen und Lieferungen
- Gesundheitsdaten mit Patienten, Besuchen, Rezepten und Laborwerten
SQLs normalisierte Schemata, Fremdschlüssel und Joins erleichtern es, Datenintegrität durchzusetzen und komplexe Beziehungen abzufragen, ohne Daten zu duplizieren.
Analysen über wohldefinierte Schemata
Für Reporting und BI über klar strukturierte Daten (Star/Snowflake‑Schemas, Data Marts) sind relationale Datenbanken und SQL‑kompatible Data‑Warehouses meist die bevorzugte Wahl. Analysten kennen SQL und bestehende Tools (Dashboards, ETL, Governance) integrieren sich direkt.
Reife, Skills und Compliance
Debatten über relationale vs. nicht‑relationale Systeme übersehen oft die betriebliche Reife. SQL‑Datenbanken bieten:
- Lang bewährte Zuverlässigkeit und Tooling
- Eine große Anzahl von Ingenieuren, DBAs und Analysten mit SQL‑Kenntnissen
- Funktionen für Auditing, Zugriffskontrolle, Verschlüsselung und Backups, die regulatorische Anforderungen (Finanzen, Regierung, Gesundheitswesen) erfüllen
Wenn Audits, Zertifizierungen oder rechtliche Risiken relevant sind, ist SQL oft die naheliegendere und leichter zu argumentierende Wahl.
Wann NoSQL meist die bessere Wahl ist
NoSQL‑Datenbanken sind vorteilhaft, wenn Skalierbarkeit, Flexibilität und immer‑verfügbare Zugriffe wichtiger sind als komplexe Joins und strikte Transaktionen.
Hohe Last und groß angelegte Systeme
Bei massiven Schreibvolumen, unvorhersehbaren Traffic‑Spitzen oder Datensätzen in Terabyte‑Größen sind NoSQL‑Systeme (Key‑Value, Wide‑Column) oft leichter horizontal skalierbar. Sharding und Replikation sind meist integriert, sodass Sie Kapazität durch Knoten‑Hinzufügung erweitern können.
Typische Anwendungsfälle:
- Hochfrequentierte Web‑ und Mobile‑Apps
- Gaming‑Backends und Echtzeit‑Leaderboards
- Ad‑Tech, Recommendation Engines und Personalisierung
Flexible Daten bei schnellem Produkt‑Iterieren
Wenn sich Ihr Datenmodell oft ändert, ist ein flexibles, schema‑loses Design hilfreich. Dokumentendatenbanken erlauben es, Felder ohne Migration sofort zu speichern.
Geeignet für:
- Content‑Management und Produktkataloge
- Benutzerprofile und Präferenzen
- Activity‑Feeds und Events mit regelmäßig neuen Event‑Typen
IoT, Caching und Time‑Series
NoSQL‑Stores sind stark bei append‑intensiven und zeitlich geordneten Workloads:
- IoT‑Telemetrie und Sensordaten
- Metriken, Logging und Monitoring
- Caching‑Layer für häufig gelesene Daten (Sessions, Tokens, Feature Flags)
Key‑Value‑ und Time‑Series‑Datenbanken sind für sehr schnelle Writes und einfache Reads optimiert.
Globale Verteilung und Always‑On‑Erlebnisse
Viele NoSQL‑Plattformen legen Wert auf Geo‑Replikation und Multi‑Region‑Writes, damit Nutzer weltweit lokal schnell lesen und schreiben können. Das ist nützlich, wenn:
- Die App bei regionalen Ausfällen verfügbar bleiben muss
- Nutzer auf verschiedenen Kontinenten niedrige Latenzen benötigen
Der Kompromiss ist häufig eventual consistency statt strikter ACID‑Semantik über Regionen hinweg.
Kompromisse und Einschränkungen
NoSQL‑Wahl bedeutet oft, auf einige SQL‑Features zu verzichten:
- Schwächere oder konfigurierbare Konsistenz; nicht jede Leseoperation sieht den neuesten Write
- Begrenzte Ad‑hoc‑Abfragen und Joins; Daten werden auf die Abfrage‑Patterns hin modelliert
- Mehr Verantwortung in der Anwendung für bestimmte Datenintegritätsregeln
Wenn diese Kompromisse akzeptabel sind, liefert NoSQL bessere Skalierbarkeit, Flexibilität und globale Reichweite als traditionelle relationale Lösungen.
Hybride Muster und polyglotte Persistenz
Polyglot Persistence bedeutet, bewusst mehrere Datenbanktechnologien innerhalb desselben Systems zu nutzen und das beste Werkzeug für jede Aufgabe zu wählen, statt alles in einen Store zu pressen.
Typisches hybrides Setup
Ein häufiges Muster ist:
- SQL für Kerndaten: Bestellungen, Zahlungen, Benutzerprofile, Konfiguration — hier brauchen Sie starke Konsistenz und Transaktionen.
- NoSQL für Sessions und Caching: Key‑Value‑Stores (z. B. Redis‑ähnlich) für Sessions, Rate‑Limits, Feature‑Flags oder Hot‑Aggregates; manchmal Dokumentenspeicher für Benutzerpräferenzen oder Activity‑Feeds.
So bleibt das „System of Record“ relational, während volatile oder leseintensive Workloads ausgelagert werden.
Kombination verschiedener NoSQL‑Typen
Sie können NoSQL‑Systeme intern kombinieren:
- Key‑Value für Caching und Sessions
- Dokumente für Content oder nutzergenerierte Daten mit flexiblen Schemata
- Wide‑Column / Time‑Series für Metriken und Event‑Logs
- Such‑Engines (z. B. Lucene‑basiert) für Volltext und Analytics
Ziel ist, jeden Datenspeicher an ein spezifisches Zugriffs‑Pattern anzupassen: Lookups, Aggregationen, Suche oder zeitbasierte Abfragen.
Integrations‑ und Betriebskosten
Hybrid‑Architekturen benötigen Integrationspunkte:
- ETL oder Streaming zum Synchronisieren zwischen Stores oder zum Erstellen lesefertiger Modelle
- Event‑Streaming, um Änderungen zu propagieren (z. B. von SQL zu Cache/Analytics)
- APIs, die die zugrundeliegenden Datenbanken verbergen, sodass Services nicht wissen müssen, wo Daten liegen
Der Nachteil ist betrieblicher Overhead: mehr Technologien lernen, überwachen, sichern, sichern und debuggen. Polyglot Persistence lohnt sich, wenn jeder zusätzliche Datenspeicher ein klar messbares Problem löst — nicht nur, weil es modern klingt.
Wie Sie zwischen SQL und NoSQL für ein Projekt wählen
Die Wahl richtet sich danach, Ihr Daten‑ und Zugriffsverhalten mit dem richtigen Werkzeug abzugleichen — nicht danach, was gerade im Trend liegt.
1. Beginnen Sie mit Ihren Daten und Beziehungen
Fragen Sie:
- Sind meine Daten natürlich tabellarisch mit klaren Entitäten (Benutzer, Bestellungen, Rechnungen)?
- Habe ich viele Joins und reichhaltige Beziehungen (1‑zu‑viele, viele‑zu‑viele)?
Wenn ja, ist eine relationale SQL‑Datenbank meist die Default‑Wahl. Wenn Ihre Daten dokumentenartig, verschachtelt oder stark variabel sind, könnte ein Dokumenten‑ oder anderes NoSQL‑Modell besser passen.
2. Klären Sie Konsistenz‑ und Transaktionsanforderungen
- Brauche ich Multi‑Row- oder Multi‑Table‑ACID‑Transaktionen (z. B. Zahlungen, Inventar)?
- Ist es akzeptabel, dass manche Reads leicht veraltet sind?
Strikte Konsistenz und komplexe Transaktionen sprechen für SQL. Hohe Schreibrate mit lockerer Konsistenz spricht für NoSQL.
3. Verstehen Sie Skalierung und Performance
- Erwartetes Lese-/Schreibvolumen jetzt und in 2–3 Jahren?
- Brauche ich niedrige Latenz über mehrere Regionen?
Viele Projekte skalieren weit mit SQL durch gutes Indexing und passende Hardware. Wenn Sie sehr großen Maßstab mit einfachen Zugriffen (Key‑Value, Time‑Series) erwarten, sind NoSQL‑Systeme oft wirtschaftlicher.
4. Abfragemuster und Reporting
- Benötige ich Ad‑hoc‑Analysen, Joins und flexibles Reporting?
- Wer wird die Daten abfragen (nur Entwickler oder auch Analysten/Business‑User)?
SQL ist stark für komplexe Abfragen und BI‑Tools. Viele NoSQL‑Datenbanken sind auf vordefinierte Zugriffswege optimiert, und neue Abfragearten sind schwieriger oder teurer.
5. Team‑Skills, Tooling und Hosting
- Was kann Ihr Team bereits: SQL‑Schema‑Design oder spezielle NoSQL‑Systeme?
- Welche Managed‑Services stehen zur Verfügung (managed PostgreSQL/MySQL, managed MongoDB, DynamoDB etc.)?
- Welches Ökosystem bietet bessere Libraries, Treiber und Monitoring für Ihren Stack?
Bevorzugen Sie Technologien, die Ihr Team sicher betreiben kann — besonders für Produktion, Troubleshooting und Migrationen.
6. Kosten und Betriebskomplexität
- Können Sie verteilte NoSQL‑Cluster betreiben, oder reicht ein Managed‑SQL‑Instance?
- Wie vergleichen sich Speicher‑ und Lese/Schreibkosten für Ihre Workload?
Eine einzelne Managed‑SQL‑Datenbank ist oft günstiger und einfacher, bis Sie sie deutlich überlasten.
7. Testen Sie mit realistischen Workloads
Bevor Sie sich festlegen:
- Modellieren Sie einen repräsentativen Datenschnitt sowohl als SQL‑Schema als auch als Kandidat‑NoSQL‑Modell.
- Implementieren Sie kritische Abfragen und Schreibpfade.
- Führen Sie Lasttests mit realistischen Datenmengen und Traffic‑Mustern durch.
- Messen Sie Latenz, Durchsatz, Fehlerraten und den betrieblichen Aufwand.
Treffen Sie Entscheidungen auf Basis dieser Messungen — nicht nur Annahmen. Für viele Projekte ist es sicher, mit SQL zu starten und NoSQL‑Komponenten später gezielt einzuführen.
Gängige Mythen über SQL und NoSQL
Mythos 1: NoSQL wird SQL ersetzen
NoSQL ist nicht gekommen, um relationale Datenbanken zu ersetzen, sondern um sie zu ergänzen.
Relationale Datenbanken dominieren weiterhin Systeme of Record: Finanzen, HR, ERP, Inventar und alle Workflows, bei denen strikte Konsistenz und reichhaltige Transaktionen wichtig sind. NoSQL ist stark dort, wo flexible Schemata, riesiger Schreibdurchsatz oder global verteilte Lesezugriffe wichtiger sind.
Die meisten Organisationen nutzen beides und wählen das richtige Tool pro Workload.
Mythos 2: SQL‑Datenbanken können nicht horizontal skalieren
Relationale Systeme skalieren traditionell vertikal, aber moderne Engines unterstützen:
- Read‑Replicas
- Sharding/Partitionierung
- Distributed SQL / NewSQL
Horizontale Skalierung ist möglich, aber oft mit mehr Design‑Aufwand als bei einigen NoSQL‑Clustern.
Mythos 3: NoSQL hat keine Schemata oder Regeln
„Schema‑los“ bedeutet meistens „Schema wird von der Anwendung durchgesetzt, nicht von der Datenbank“.
Dokumenten‑, Key‑Value‑ und Wide‑Column‑Stores haben Struktur — sie erlaubt nur flexiblere Veränderungen. Ohne klare Datenverträge, Governance und Validierung führt das jedoch schnell zu inkonsistenten Daten.
Mythos 4: Ein Typ ist immer schneller
Performance hängt stärker von Datenmodellierung, Indexierung und Zugriffsmustern ab als von der Kategorie „SQL vs NoSQL“. Eine schlecht indexierte NoSQL‑Collection ist oft langsamer als eine gut optimierte relationale Tabelle. Umgekehrt kann ein relationales Schema, das Abfrage‑Patterns ignoriert, deutlich schlechter abschneiden als ein auf die Queries zugeschnittenes NoSQL‑Design.
Mythos 5: SQL ist immer sicherer und zuverlässiger als NoSQL
Viele NoSQL‑Datenbanken bieten starke Durability, Verschlüsselung, Auditing und Zugriffskontrollen. Gleichzeitig kann eine falsch konfigurierte relationale Datenbank unsicher und fragil sein. Sicherheit und Zuverlässigkeit sind Eigenschaften des konkreten Produkts, der Bereitstellung, Konfiguration und des Betriebs — nicht allein der Kategorie.
Migration und Koexistenz‑Strategien
Teams wechseln zwischen SQL und NoSQL meist aus zwei Gründen: Skalierung und Flexibilität. Häufig bleibt eine relationale DB das verlässliche System of Record, während NoSQL ergänzend gelesen wird oder neue Features mit flexibleren Schemata unterstützt.
Migrationsmuster
Eine Big‑Bang‑Migration ist riskant. Sicherere Ansätze sind:
- Inkrementelle Migration: schneiden Sie einen bounded context aus (z. B. Produktkatalog) und migrieren nur diesen Teil zu NoSQL, während der Rest in SQL bleibt.
- Dual Writes: schreiben Sie vorübergehend in beide Stores. Sobald das neue System im Betrieb stabil ist, schalten Sie den alten Pfad ab.
- Sync‑Pipelines: halten Sie eine DB als primär und streamen Änderungen via CDC, Messaging oder ETL in den zweiten Store.
Schema‑ und Modell‑Fallstricke
Beim Wechsel von SQL zu NoSQL neigen Teams dazu, Tabellen 1:1 als Dokumente oder Key‑Value‑Paare abzubilden. Das führt oft zu:
- Über‑normalisierten NoSQL‑Daten mit zu vielen Anwendungs‑Joins
- Dokumenten, die unbegrenzt wachsen
Planen Sie zuerst Zugriffs‑Patterns, dann das NoSQL‑Schema um die tatsächlichen Abfragen herum.
Koexistenz und Sicherheitsnetze
Ein gängiges Muster ist SQL für autoritative Daten (Billing, Accounts) und NoSQL für leseintensive Views (Feeds, Suche, Caching). Investieren Sie in:
- wiederholbare Backfills und Rollbacks
- Datenvalidierung zwischen Stores
- Lasttests, die reale Abfragemuster abbilden
So bleiben Migrationen kontrolliert statt zu schmerzhaften Einbahnstraßen zu werden.
Zusammenfassung und praktische Empfehlungen
SQL und NoSQL unterscheiden sich vor allem in vier Bereichen:
- Datenmodell – SQL: Tabellen und feste Schemata; NoSQL: Dokumente, Key‑Value, Wide‑Column oder Graphen mit flexiblerer Struktur.
- Abfragen – SQL: eine expressive, einheitliche Sprache; NoSQL: meist datenbankspezifische APIs oder Syntaxen.
- Konsistenz & Transaktionen – SQL: ACID und starke Konsistenz; viele NoSQL‑Systeme tauschen Garantien für Verfügbarkeit, Skalierung oder Latenz.
- Skalierung – SQL: traditionell vertikal (und zunehmend horizontal via Clustering); NoSQL: typischerweise für Sharding und Replikation über viele Knoten entworfen.
Keine Kategorie ist universell besser. Die richtige Wahl hängt von Ihren konkreten Anforderungen ab — nicht von Schlagworten.
Praktische Vorgehensweise
-
Schreiben Sie Ihre Anforderungen auf:
- Datenstruktur und Beziehungen
- Abfrage‑ und Reporting‑Bedürfnisse
- Erwartungen zu Konsistenz vs. Verfügbarkeit
- Peak‑Traffic, Datengröße und Latenzziele
- Operative Skills und verfügbares Tooling
-
Default sinnvoll:
- Bevorzugen Sie SQL für transaktionale Systeme, Analysen und wohlstrukturierte Geschäftsdaten.
- Ziehen Sie NoSQL bei sehr hohen Schreiblasten, großem Maßstab oder sehr variablen/semi‑strukturierten Daten in Betracht.
-
Klein anfangen und messen:
- Bauen Sie einen dünnen Vertical Slice oder Proof‑of‑Concept.
- Sammeln Sie Metriken: Latenz, Durchsatz, Fehlerraten und betrieblichen Aufwand.
- Iterieren Sie Schema, Indexe und Partitionierung anhand realer Nutzung.
-
Hybridlösungen offenhalten:
- Nutzen Sie mehrere Datenbanken, wenn verschiedene Teile des Systems unterschiedliche Bedürfnisse haben.
- Dokumentieren Sie Entscheidungen, Kompromisse und Muster in Ihrem internen Wissensspeicher (z. B. unter
/docs/architecture/datastores).
Für tiefergehende Informationen erweitern Sie diese Übersicht mit internen Standards, Migrations‑Checklisten und weiterführender Literatur in Ihrem Engineering‑Handbuch oder auf /blog.
FAQ
Was ist der Kernunterschied zwischen SQL- und NoSQL-Datenbanken?
SQL (relational) Datenbanken:
- Verwenden Tabellen mit Zeilen und Spalten.
- Erzwingen ein festes Schema (definierte Spalten, Typen, Constraints).
- Nutzen SQL als standardisierte Abfragesprache.
- Legen Wert auf ACID‑Transaktionen und starke Konsistenz.
NoSQL (nicht‑relational) Datenbanken:
- Verwenden flexible Modelle (Dokumente, Key‑Value, Wide‑Column, Graph).
- Ermöglichen oft schema‑flexible oder schema‑lose Daten.
- Nutzen datenbankspezifische Abfrage‑APIs oder DSLs.
- Tauschen häufig etwas Konsistenz für bessere Skalierbarkeit und Verfügbarkeit ein.
Wann ist eine SQL-Datenbank üblicherweise die bessere Wahl?
Verwenden Sie eine SQL‑Datenbank, wenn:
- Ihre Daten gut strukturiert und relational sind (Benutzer, Bestellungen, Rechnungen).
- Sie Multi‑Row- oder Multi‑Table‑ACID‑Transaktionen benötigen.
- Korrektheit und Konsistenz wichtiger sind als rohe Durchsatzleistung.
- Sie viele Ad‑hoc‑Abfragen, Joins und Reporting‑Anforderungen erwarten.
- Compliance, Auditing und langfristige Wartbarkeit kritisch sind.
Für die meisten neuen Business‑Systeme of‑Record ist SQL eine sinnvolle Standardwahl.
Wann ist eine NoSQL-Datenbank üblicherweise die bessere Wahl?
NoSQL eignet sich besonders, wenn:
- Sie Schreib‑ und Speicherlast horizontal über viele Knoten skalieren müssen.
- Ihre Daten semi‑strukturiert, verschachtelt sind oder häufig ihre Form ändern.
- Zugriffs‑Patterns bekannt sind und sich um Schlüssel‑ oder Dokument‑Lookups modellieren lassen.
- Vorübergehende Inkonsistenzen akzeptabel sind (z. B. Feeds, Logs, Analyse‑Sichten).
- Sie IoT‑Telemetry, Time‑Series, Caching oder große Mengen nutzergenerierter Inhalte verarbeiten.
Wie unterscheiden sich Schemas und Datenmodellierung zwischen SQL und NoSQL?
SQL‑Datenbanken:
- Verwenden vordefinierte Schemata; jede Zeile muss zur Tabellenstruktur passen.
- Fördern Normalisierung, um Duplikate zu vermeiden und Integrität zu wahren.
- Nutzen Fremdschlüssel und Constraints zur Verwaltung von Beziehungen.
NoSQL‑Datenbanken:
- Erlauben, dass Dokumente/Datensätze innerhalb derselben Collection unterschiedliche Felder haben.
- Fördern oft Denormalisierung und das Einbetten verwandter Daten.
- Verlegen die Durchsetzung vieler Datenregeln stärker in die Anwendung.
Das bedeutet, die Schema‑Kontrolle verschiebt sich bei NoSQL tendenziell von der Datenbank in die Anwendung.
Wie unterscheiden sich SQL und NoSQL in Bezug auf Konsistenz und Transaktionen?
SQL‑Datenbanken:
- Konzentrieren sich auf ACID‑Transaktionen mit starker Konsistenz.
- Sind ideal, wenn jede Leseoperation einen gültigen, aktuellen Zustand sehen muss.
Viele NoSQL‑Systeme:
- Setzen auf Verfügbarkeit und Partitionstoleranz.
- Folgen BASE‑Prinzipien und eventual consistency: Replikate konvergieren über die Zeit.
- Bieten manchmal einstellbare Konsistenzlevel pro Operation oder Partition.
Wählen Sie SQL, wenn veraltete Leseergebnisse gefährlich sind; wählen Sie NoSQL, wenn kurze Staleness zugunsten von Skalierbarkeit und Verfügbarkeit akzeptabel ist.
Wie skalieren SQL- und NoSQL-Datenbanken üblicherweise?
SQL‑Datenbanken typischerweise:
- Beginnen mit vertikalem Skalieren (stärkere Einzelserver).
- Nutzen Read‑Replicas, um Lesezugriffe zu skalieren.
- Setzen teilweise Sharding oder verteilte SQL‑Produkte ein, um nach außen zu skalieren.
NoSQL‑Datenbanken typischerweise:
- Sind von Anfang an für horizontale Skalierung ausgelegt.
- Sharden oder partitionieren Daten über viele Knoten.
- Erleichtern Kapazitätserweiterung durch Hinzufügen weiterer Commodity‑Server.
Der Kompromiss: NoSQL‑Cluster sind betrieblich oft komplexer, während SQL‑Instanzen schneller an die Grenzen eines einzelnen Knotens stoßen können.
Kann ich SQL und NoSQL zusammen im selben System nutzen?
Ja. Polyglot Persistence ist verbreitet:
- Verwenden Sie SQL als System of Record (Zahlungen, Konten, zentrale Entitäten).
- Ergänzen Sie NoSQL für Sessions, Caches, Feeds, Logs oder Suche.
Integrationsmuster umfassen:
- Change Data Capture oder Event‑Streams von SQL nach NoSQL.
- Periodische ETL‑Jobs zur Erstellung lesefertiger Sichten.
- Services, die zugrundeliegende Speicher hinter stabilen APIs verbergen.
Wichtig ist, jeden zusätzlichen Datenspeicher nur dann einzuführen, wenn er ein konkretes Problem löst.
Wie sollte ich eine Migration zwischen SQL und NoSQL angehen?
Um schrittweise und sicher vorzugehen:
- Identifizieren Sie einen begrenzten Kontext (z. B. Produktkatalog) zum Migrieren.
- Modellieren Sie die Daten nach neuen Zugriffs‑Patterns, nicht Tabelle‑für‑Tabelle.
- Nutzen Sie Dual Writes oder CDC, um alte und neue Stores vorübergehend synchron zu halten.
- Validieren Sie Daten zwischen den Stores und planen Sie wiederholbare Backfills.
- Lenken Sie den Traffic schrittweise um und halten Sie Rollbacks bereit.
Vermeiden Sie Big‑Bang‑Migrationen; bevorzugen Sie inkrementelle, gut überwachte Schritte.
Welche Faktoren sollte ich bewerten, wenn ich zwischen SQL und NoSQL wähle?
Berücksichtigen Sie:
- Datenstruktur: tabellarisch mit klaren Beziehungen vs. flexible Dokumente/Ereignisse.
- Konsistenzbedarf: strikte ACID‑Garantien vs. akzeptable Staleness.
- Skalierung & Latenz: erwartete Schreiblast, Datengröße, globale Nutzer.
- Abfragemuster: Ad‑hoc‑Joins und Analysen vs. vorhersehbare Schlüssel/Dokument‑Lookups.
- Team‑Skills & Tooling: Was Ihr Team sicher betreiben kann.
- Kosten & Betrieb: Managed‑Optionen vs. eigener Betrieb verteilter Cluster.
Prototypen Sie kritische Flows und messen Sie Latenz, Durchsatz und Komplexität, bevor Sie entscheiden.
Was sind einige verbreitete Mythen über SQL vs NoSQL?
Häufige Missverständnisse:
- "NoSQL wird SQL ersetzen" – in der Praxis ergänzen sie sich.
- "SQL kann nicht horizontal skalieren" – moderne relationale Systeme unterstützen Replikate, Sharding und verteiltes SQL.
- "NoSQL hat kein Schema" – Schemata existieren meist, werden aber durch Anwendung oder Validatoren durchgesetzt.
- "Ein Typ ist immer schneller" – Leistung hängt vor allem von Modellierung, Indexierung und Workload ab.
Bewerten Sie konkrete Produkte und Architekturen statt auf Kategorien basierende Mythen zu vertrauen.