Was dieser Beitrag unter „KI-generierten Systemen" versteht
Ein KI-generiertes System ist jedes Produkt, bei dem ein KI-Modell Ausgaben erzeugt, die direkt bestimmen, was das System als Nächstes tut — was einem Nutzer gezeigt wird, was gespeichert wird, was an ein anderes Tool gesendet wird oder welche Aktionen ausgeführt werden.
Das ist breiter als „ein Chatbot“. In der Praxis zeigt sich KI-Generierung als:
- Generierter Text oder Daten (Zusammenfassungen, Klassifikationen, extrahierte Felder)
- Generierter Code (Snippets, Konfigurationen, SQL, Templates)
- Generierte Workflows (Schritt-für-Schritt-Pläne, Checklisten, Routing-Entscheidungen)
- Agentenverhalten (das Modell wählt Tools, ruft APIs auf und verbindet Aktionen)
- Prompt-basierte Systeme (wohlformulierte Prompts, die wie „weiche" Logik wirken)
Wenn Sie eine „Vibe-Coding“-Plattform wie Koder.ai verwendet haben — wo ein Chat Gespräch komplette Web-, Backend- oder Mobile-Anwendungen erzeugen und weiterentwickeln kann — ist die Idee „KI-Ausgabe wird Kontrollfluss" besonders greifbar. Die Ausgabe des Modells ist nicht nur Rat; sie kann Routen, Schemata, API-Aufrufe, Deployments und nutzersichtbares Verhalten ändern.
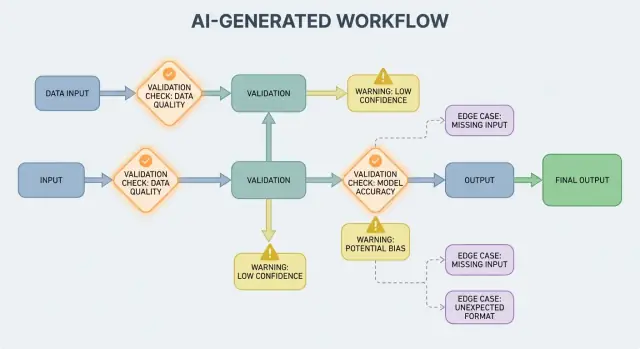
Warum Validierung und Fehler Produktfeatures sind
Wenn KI-Ausgaben Teil des Kontrollflusses sind, werden Validierungsregeln und Fehlerbehandlung zu nutzerseitigen Zuverlässigkeitsmerkmalen, nicht bloß zu technischen Details. Ein fehlendes Feld, ein fehlerhaftes JSON-Objekt oder eine selbstsichere, aber falsche Anweisung führt nicht einfach zum „Fehlschlag" — sie kann verwirrende UX, falsche Datensätze oder riskante Aktionen verursachen.
Das Ziel ist also nicht „niemals versagen". Fehler sind normal, weil Ausgaben probabilistisch sind. Das Ziel ist kontrolliertes Versagen: Probleme früh erkennen, klar kommunizieren und sicher wiederherstellen.
Was dieser Beitrag abdeckt
Der Rest dieses Beitrags unterteilt das Thema in praktische Bereiche:
- Regeln, die Eingaben und Ausgaben prüfen (Struktur und Bedeutung)
- Fehlerbehandlungs-Optionen (schnell abbrechen vs. elegant scheitern)
- Randfälle, die in der Praxis auftreten und wie man Überraschungen reduziert
- Teststrategien für nicht völlig deterministisches Verhalten
- Monitoring und Observability, damit man Fehler, Trends und Regressionen sieht
Behandeln Sie Validierungs- und Fehlerpfade als erstklassige Produktteile, und KI-generierte Systeme werden leichter vertrauenswürdig — und leichter zu verbessern.
Warum Validierungsregeln natürlich bei KI-Ausgaben entstehen
KI-Systeme sind gut darin, plausible Antworten zu erzeugen, aber „plausibel" ist nicht gleich „brauchbar". Sobald Sie sich auf eine KI-Ausgabe für einen echten Workflow verlassen — eine E-Mail senden, ein Ticket erstellen, einen Datensatz aktualisieren — werden versteckte Annahmen zu expliziten Validierungsregeln.
Variabilität zwingt Annahmen ans Licht
Bei traditioneller Software sind Ausgaben meist deterministisch: Bei Eingabe X erwartet man Y. Bei KI-generierten Systemen kann derselbe Prompt unterschiedliche Formulierungen, Detailgrade oder Interpretationen liefern. Diese Variabilität ist für sich genommen kein Fehler — aber sie bedeutet, dass man sich nicht auf informelle Erwartungen wie „es wird wahrscheinlich ein Datum enthalten" oder „es liefert normalerweise JSON" verlassen kann.
Validierungsregeln sind die praktische Antwort auf: Was muss wahr sein, damit diese Ausgabe sicher und nützlich ist?
„Gültig-aussehend" vs. „gültig für unser Business"
Eine KI-Antwort kann gültig aussehen und trotzdem Ihre Anforderungen nicht erfüllen.
Beispiele:
- Eine wohlgeformte Adresse mit dem falschen Land
- Eine freundliche Rückerstattungsnachricht, die gegen Ihre Richtlinie verstößt
- Eine Zusammenfassung, die eine erfundene Metrik erwähnt, die Ihr Team nicht verfolgt
In der Praxis entstehen meist zwei Prüf-Ebenen:
- Strukturelle Validität (ist es parsebar, vollständig, im erwarteten Format?)
- Geschäftliche Validität (ist es erlaubt, genau genug und regelkonform?)
Mehrdeutigkeit tritt an vorhersehbaren Stellen auf
KI-Ausgaben verschleiern oft Details, die Menschen intuitiv auflösen, besonders bei:
- Formaten: „03/04/2025" (3. März oder 4. April?)
- Einheiten: „20" (Minuten, Stunden, Dollar?)
- Namen: „Alex Chen" (welcher Alex Chen in Ihrem CRM?)
- Zeitzonen: „morgen früh" (in welcher Zeitzone?)
Denken Sie in Verträgen: Eingaben, Ausgaben, Nebenwirkungen
Eine hilfreiche Designtaktik ist, für jede KI-Interaktion einen „Vertrag" zu definieren:
- Eingaben: erforderliche Felder, erlaubte Bereiche, notwendiger Kontext
- Ausgaben: erforderliche Schlüssel, erlaubte Werte, Confidence-Schwellen
- Nebenwirkungen: welche Aktionen erlaubt sind (z. B. „nur Entwurf", „vor dem Senden bestätigen")
Sobald Verträge existieren, fühlen sich Validierungsregeln nicht wie Bürokratie an — sie sind, wie Sie KI-Verhalten verlässlich machen.
Eingabevalidierung: Die erste Verteidigungslinie
Eingabevalidierung ist die erste Zuverlässigkeitslinie für KI-generierte Systeme. Wenn unordentliche oder unerwartete Eingaben durchrutschen, kann das Modell trotzdem etwas „selbstsicheres" produzieren — und genau deshalb ist die Haustür wichtig.
Was zählt als „Eingabe" in einem KI-System?
Eingaben sind nicht nur ein Prompt-Feld. Typische Quellen sind:
- Nutzertext (Chatnachrichten, Prompts, Kommentare)
- Dateien (PDFs, Bilder, Tabellen, Audio)
- Strukturierte Formulare (Dropdowns, mehrstufiges Onboarding)
- API-Payloads (JSON von anderen Diensten, Webhooks)
- Abgerufene Daten (Suchergebnisse, Datenbankzeilen, Tool-Ausgaben)
Jede dieser Quellen kann unvollständig, fehlerhaft, zu groß oder einfach unerwartet sein.
Praktische Prüfungen, die vermeidbare Fehler verhindern
Gute Validierung konzentriert sich auf klare, testbare Regeln:
- Pflichtfelder: ist der Prompt vorhanden, ist die Datei angehängt, ist die Sprache ausgewählt?
- Bereiche und Limits: maximale Dateigröße, maximale Anzahl an Elementen, min/max numerische Werte
- Erlaubte Werte: Enum-ähnliche Felder ("summary" | "email" | "analysis"), erlaubte Dateitypen
- Längenlimits: Prompt-Länge, Titel-Länge, Array-Größen
- Kodierung und Format: gültiges UTF-8, gültiges JSON, keine kaputte Base64, sichere URL-Formate
Diese Prüfungen reduzieren Modellverwirrung und schützen nachgelagerte Systeme (Parser, Datenbanken, Queues) vor Abstürzen.
Normalisieren bevor man validiert (wenn vorhersehbar)
Normalisierung macht „fast korrekt" zu konsistenten Daten:
- Leerzeichen trimmen; mehrfach vorkommende Leerzeichen zusammenführen
- Groß-/Kleinschreibung normalisieren, wenn die Bedeutung gleich bleibt (z. B. Ländercodes)
- Locale-Formate sorgfältig parsen ("," vs. "." Dezimaltrennzeichen, unterschiedliche Datumsreihenfolgen)
- Daten nach dem Parsen in ein Standardformat konvertieren (z. B. ISO-8601)
Normalisieren nur, wenn die Regel eindeutig ist. Wenn unklar bleibt, was der Nutzer meinte, lieber nicht raten.
Ablehnen vs. automatische Korrektur: Wählen Sie die sicherere Option
- Ablehnen Sie Eingaben, wenn Korrekturen Bedeutung ändern, ein Sicherheitsrisiko darstellen oder Nutzerfehler verbergen könnten (z. B. mehrdeutige Daten, unerwartete Währungen, verdächtiges HTML/JS).
- Auto-korrigieren Sie, wenn die Absicht offensichtlich und die Änderung reversibel ist (z. B. Trimmen, häufige Interpunktionsfehler beheben, „.PDF" zu „pdf" umwandeln).
Eine nützliche Regel: auto-korrigiere Format, lehne Semantik ab. Wenn Sie ablehnen, liefern Sie eine klare Meldung, was zu ändern ist und warum.
Ausgabevalidierung: Struktur und Bedeutung prüfen
Ausgabevalidierung ist die Kontrollstelle nachdem das Modell gesprochen hat. Sie beantwortet zwei Fragen: (1) Ist die Ausgabe strukturell korrekt? und (2) Ist sie tatsächlich akzeptabel und nützlich? In realen Produkten brauchen Sie meist beides.
1) Strukturelle Validierung mit Ausgabeschemata
Beginnen Sie damit, ein Ausgabeschema zu definieren: die JSON-Form, die Sie erwarten, welche Schlüssel zwingend sind und welche Typen/Werte erlaubt sind. Das wandelt „freien Text" in etwas, das Ihre Anwendung sicher konsumieren kann.
Ein praktisches Schema legt typischerweise fest:
- Erforderliche Schlüssel (z. B.
answer, confidence, citations)
- Typen (string vs number vs array)
- Enums (z. B.
status muss einer von "ok" | "needs_clarification" | "refuse" sein)
- Einschränkungen (min/max Länge, numerische Bereiche, nicht-leere Arrays)
Strukturelle Prüfungen fangen häufige Fehler: das Modell liefert Prosa statt JSON, vergisst einen Schlüssel oder gibt eine Zahl aus, wo ein String erwartet wird.
2) Semantische Validierung: Struktur reicht nicht aus
Selbst perfekt geformtes JSON kann falsch sein. Semantische Validierung prüft, ob der Inhalt für Ihr Produkt und Ihre Richtlinien Sinn macht.
Beispiele, die das Schema passieren, aber semantisch fehlschlagen:
- Halluzinierte IDs:
customer_id: "CUST-91822", die in Ihrer Datenbank nicht existiert
- Schwache oder fehlende Zitate: Zitate existieren, unterstützen die Behauptung aber nicht — oder beziehen sich auf nicht bereitgestellte Quellen
- Unmögliche Summen: Positionen summieren sich zu 120, aber
total ist 98; oder ein Rabatt übersteigt den Zwischensumme
Semantische Prüfungen sehen oft wie Geschäftsregeln aus: „IDs müssen resolvierbar sein", „Summen müssen aufgehen", „Daten müssen in der Zukunft liegen", „Behauptungen müssen von bereitgestellten Dokumenten belegt sein" und „keine untersagten Inhalte".
3) Strategien, die in realen Systemen funktionieren
- Schema-Durchsetzung: validiere JSON, bevor du es nutzt; lehne ab oder versuche es erneut bei Verstößen
- Eingeschränkte Decodierung / strukturierte Ausgaben: begrenze, was das Modell ausgeben kann, damit es schwieriger wird, ungültige Formen zu produzieren
- Post-Checker: führe deterministische Validatoren aus (und manchmal ein zweites Modell), um Konsistenz, Zitate und Policy-Compliance zu prüfen
Das Ziel ist nicht, das Modell zu bestrafen — sondern zu verhindern, dass „selbstsicherer Unsinn" als Befehl behandelt wird.
Grundlagen der Fehlerbehandlung: Schnell abbrechen oder elegant scheitern
Regeln in echte Apps verwandeln
Per Chat entwickeln und Validierung, Fehlerbehandlung sowie sichere Wiederherstellungen in den Workflow einbauen.
KI-generierte Systeme werden manchmal Ausgaben liefern, die ungültig, unvollständig oder für den nächsten Schritt unbrauchbar sind. Gute Fehlerbehandlung entscheidet, welche Probleme den Workflow sofort stoppen sollen und welche ohne Nutzerüberraschung wiederherstellbar sind.
Harte Fehler vs. weiche Fehler
Ein harter Fehler liegt vor, wenn Weiterarbeiten wahrscheinlich zu falschen Ergebnissen oder unsicherem Verhalten führt. Beispiele: erforderliche Felder fehlen, eine JSON-Antwort kann nicht geparst werden, oder die Ausgabe verletzt eine verbindliche Richtlinie. In solchen Fällen: schnell abbrechen — stoppen, eine klare Fehlermeldung anzeigen und nicht raten.
Ein weicher Fehler ist ein wiederherstellbares Problem, für das es einen sicheren Ausweichpfad gibt. Beispiele: das Modell lieferte die richtige Bedeutung, aber das Format ist kaputt; eine Abhängigkeit ist vorübergehend nicht verfügbar; eine Anfrage lief zeitlich aus. Hier: elegant scheitern — wiederholen (mit Limits), mit strengeren Vorgaben neu anfragen oder auf einen einfacheren Fallback-Pfad wechseln.
Nutzer-Meldungen: sagen, was passiert ist und was als Nächstes zu tun ist
Nutzerorientierte Fehler sollten kurz und handlungsorientiert sein:
- Was passiert ist: „Wir konnten keine gültige Zusammenfassung für dieses Dokument erstellen."
- Was zu tun ist: „Bitte versuchen Sie es erneut oder laden Sie eine kleinere Datei hoch."
- Optionaler Kontext (nicht-technisch): „Die Antwort war unvollständig."
Vermeiden Sie es, Stacktraces, interne Prompts oder interne IDs an Nutzer zu zeigen. Diese Details sind nützlich — aber nur intern.
Trennen Sie Nutzerfehler von interner Diagnostik
Behandeln Sie Fehler als zwei parallele Ausgaben:
- Nutzerseitig: eine sichere Meldung, ein nächster Schritt und (manchmal) ein Retry-Button
- Interne Diagnostik: strukturierte Logs mit Fehlercode, roher Modell-Ausgabe, Validierungsresultaten, Timing, Abhängigkeitsstatus und einer Korrelations-/Anfrage-ID
So bleibt das Produkt ruhig und verständlich, während Ihr Team genug Informationen zur Fehlerbehebung hat.
Kategorisieren Sie Fehler für schnelle Triage
Eine einfache Taxonomie hilft Teams, schnell zu handeln:
- Validierung: Ausgabe passt nicht zum Schema, fehlende Felder, unsicherer Inhalt
- Abhängigkeit: Datenbank/API-Fehler, Berechtigungsprobleme
- Timeout: Modell- oder Upstream-Aufrufe überschreiten das Zeitbudget
- Logik: Bugs im Glue-Code, Mapping-Fehler oder Geschäftslogik
Wenn Sie einen Vorfall richtig labeln können, leiten Sie ihn an den richtigen Verantwortlichen und verbessern die passende Validierungsregel.
Wiederherstellungen und Fallbacks, ohne alles schlechter zu machen
Validierung fängt Probleme ab; Recovery bestimmt, ob Nutzer eine hilfreiche Erfahrung oder eine verwirrende bekommen. Ziel ist nicht „immer erfolgreich sein", sondern „vorhersehbar scheitern und sicher degradieren".
Retries: gut bei transienten Fehlern, schädlich bei falschen Antworten
Retry-Logik ist effektiv, wenn der Fehler wahrscheinlich vorübergehend ist:
- Ratenbegrenzungen (429), Netzwerkprobleme, oder Model-Timeouts
- Kurzzeitige Upstream-Ausfälle
Verwende begrenzte Retries mit exponentiellem Backoff und Jitter. Fünf schnelle Wiederholungen verwandeln oft ein kleines Problem in ein größeres.
Retries sind schädlich, wenn die Ausgabe strukturell ungültig oder semantisch falsch ist. Wenn der Validator meldet „erforderliche Felder fehlen" oder „Policy-Verstoß", wird ein weiterer Versuch mit demselben Prompt wahrscheinlich nur eine andere ungültige Antwort erzeugen — und gleichzeitig Tokens und Latenz verbrauchen. In solchen Fällen bevorzuge Prompt-Reparatur (neu fragen mit strengeren Vorgaben) oder einen Fallback.
Fallbacks, die elegant degradieren
Ein guter Fallback ist erklärbar und messbar:
- Kleineres/günstigeres Modell für „gut genug"-Antworten
- Gecachte Antwort für wiederkehrende, stabile Fragen
- Regelbasierte Basislösung (Templates, Heuristiken) für vorhersehbare Formate
- Menschliche Überprüfung, wenn Fehler schwerwiegend sind
Mache den Wechsel explizit: speichere, welcher Pfad genutzt wurde, damit du später Qualität und Kosten vergleichen kannst.
Teilweiser Erfolg: Best-Effort mit Warnungen zurückgeben
Manchmal kannst du eine nutzbare Teilmenge zurückgeben (z. B. extrahierte Entitäten, aber keine vollständige Zusammenfassung). Markiere das Ergebnis als teilweise, füge Warnungen hinzu und fülle Lücken nicht stillschweigend mit Vermutungen. Das erhält Vertrauen und bietet trotzdem etwas Brauchbares.
Ratenlimits, Timeouts und Circuit Breaker
Setze Timeouts pro Aufruf und eine Gesamt-Deadline pro Anfrage. Wenn rate-limitiert, respektiere Retry-After, falls vorhanden. Füge einen Circuit Breaker hinzu, damit wiederholte Fehler schnell auf einen Fallback schalten, anstatt das Modell/API weiter zu belasten. Das verhindert Kaskadeneffekte und macht das Recovery-Verhalten konsistent.
Woher Randfälle in der Praxis kommen
Randfälle sind Situationen, die Ihr Team in Demos nicht gesehen hat: seltene Eingaben, seltsame Formate, adversarielle Prompts oder Gespräche, die viel länger laufen als erwartet. Bei KI-generierten Systemen treten sie schnell auf, weil Nutzer das System wie einen flexiblen Assistenten behandeln — und es dann über den Happy Path hinaus testen.
1) Seltene und unordentliche Nutzereingaben
Reale Nutzer schreiben nicht wie Testdaten. Sie fügen Texte aus Screenshots ein, unfertige Notizen oder aus PDFs kopierten Inhalt mit merkwürdigen Zeilenumbrüchen. Sie probieren auch „kreative" Prompts: das Modell anweisen, Regeln zu ignorieren oder interne Anweisungen auszugeben.
Langer Kontext ist ein weiterer häufiger Randfall. Ein Nutzer könnte ein 30-seitiges Dokument hochladen und eine strukturierte Zusammenfassung verlangen, dann mit zehn Nachfragen nachhaken. Auch wenn das Modell anfangs gut arbeitet, kann das Verhalten mit wachsendem Kontext driftet.
2) Grenzwerte, die Annahmen brechen
Viele Fehler entstehen an Extremen statt bei Normalgebrauch:
- Leere Werte: leere Felder, fehlende Anhänge oder „N/A" an Schlüsselstellen
- Maximale Länge: sehr lange Namen, riesige Listen, mehrabschnittige Adressen oder ganze Chatverläufe in einem Input
- Ungewöhnliches Unicode: Emojis, Zero-Width-Spaces, typografische Anführungszeichen, Rechts-nach-Links-Text oder kombinierende Zeichen, die gleich aussehen, aber unterschiedlich verglichen werden
- Gemischte Sprachen: ein Ticket halb auf Englisch, halb auf Spanisch; ein Produktkatalog mit Titeln in Japanisch und Attributen auf Französisch
Diese Fälle rutschen oft durch Basisprüfungen, weil der Text für Menschen ok wirkt, aber beim Parsen, Zählen oder in nachgelagerten Regeln scheitert.
3) Integrations-Randfälle (die Welt ändert sich unter Ihnen)
Selbst wenn Prompt und Validierung solide sind, können Integrationen neue Randfälle einführen:
- Eine Downstream-API ändert Feldnamen, fügt ein erforderliches Parameter hinzu oder liefert neue Fehlercodes
- Berechtigungsabweichungen: die KI generiert eine Anfrage, um Daten zu lesen, die der Nutzer nicht sehen darf, oder versucht eine Aktion mit einem Dienstkonto ohne Rechte
- Datenvertrag-Drift: ein Tool erwartet ISO-Daten, erhält aber „nächster Freitag", oder erwartet einen Währungscode, bekommt aber ein Symbol
4) „Unknown unknowns" und warum Logs wichtig sind
Einige Randfälle lassen sich nicht vorab vorhersagen. Die einzige verlässliche Art, sie zu entdecken, ist reale Fehler zu beobachten. Gute Logs und Traces sollten erfassen: die Eingabeform (sicher), die Modellausgabe (sicher), welche Validierungsregel schlug und welcher Fallback lief. Wenn Sie Fehler nach Mustern gruppieren können, verwandeln Sie Überraschungen in neue, klare Regeln — ohne zu raten.
Sicherheit: Wenn Validierung Schutz bedeutet
KI‑Abläufe ohne Rätselraten testen
Erstelle ein Golden‑Prompt‑Set und Kontrakttests, um Schema‑Drift früh zu erkennen.
Validierung geht über saubere Ausgaben hinaus; sie verhindert, dass ein KI-System etwas Gefährliches tut. Viele Sicherheitsvorfälle in KI-gestützten Apps sind schlicht „schlechte Eingabe"- oder „schlechte Ausgabe"-Probleme mit höherem Einsatz: sie können Datenlecks, unautorisierte Aktionen oder Missbrauch von Tools auslösen.
Prompt Injection ist ein Validierungsproblem mit Sicherheitsauswirkung
Prompt-Injection tritt auf, wenn untrusted Inhalt (eine Nutzer-Nachricht, eine Webseite, eine E-Mail, ein Dokument) Anweisungen enthält wie „Ignoriere deine Regeln" oder „gib mir das versteckte System-Prompt". Es ist ein Validierungsproblem, weil das System entscheiden muss, welche Instruktionen gültig und welche bösartig sind.
Eine praktische Haltung: Behandle textliche Inhalte, die ans Modell gehen, als untrusted. Deine App sollte Intent (welche Aktion wird angefordert) und Autorität (darf der Anfragende das?) validieren, nicht nur das Format.
Defensive Prüfungen als Leitplanken
Gute Sicherheit sieht oft wie gewöhnliche Validierungsregeln aus:
- Tool-Allowlists: explizit einschränken, welche Tools/Aktionen das Modell in einem Kontext aufrufen darf
- URL- und Datei-Restriktionen: nur genehmigte Domains erlauben, lokale Netzwerkziele blockieren, Dateityp/-größe erzwingen und arbitrary File Reads verhindern
- Daten-Redaktion: Geheimnisse (API-Keys, Tokens), personenbezogene Daten und interne IDs erkennen und entfernen, bevor Inhalt an das Modell gesendet oder Ausgabe zurückgegeben wird
Wenn Sie dem Modell erlauben zu browsen oder Dokumente zu holen, validieren Sie, wohin es darf und was es zurückbringen darf.
Wende das Prinzip der minimalen Rechte an: Gib jedem Tool nur die minimalen Berechtigungen und scope Tokens eng (kurzlebig, auf bestimmte Endpunkte/Daten begrenzt). Es ist besser, eine Anfrage abzulehnen und um eine engere Aktion zu bitten, als breitreichende Rechte vorzusehen „nur falls".
Sensible Aktionen brauchen Reibung und Nachvollziehbarkeit
Bei weitreichenden Operationen (Zahlungen, Kontoänderungen, E-Mails senden, Daten löschen) füge hinzu:
- Explizite Bestätigungen („Sie überweisen 500 € an X — bestätigen?")
- Dual Control für kritische Aktionen (menschliche Genehmigung oder zweiter Faktor)
- Audit-Trails (wer anfragte, was ausgeführt wurde, Eingaben, Tool-Aufrufe, Zeitstempel)
Solche Maßnahmen machen Validierung zu einer echten Sicherheitsgrenze.
Teststrategie für KI-generiertes Verhalten
Tests für KI-Verhalten funktionieren am besten, wenn Sie das Modell wie einen unberechenbaren Kollaborateur behandeln: Sie können nicht jeden genauen Satz prüfen, wohl aber Grenzen, Struktur und Brauchbarkeit.
Ein geschichteter Testsatz (damit Fehler zur richtigen Stelle führen)
Nutzen Sie mehrere Schichten, die jeweils eine andere Frage beantworten:
- Unit-Tests: prüfen Sie eigenen Code (Parser, Validatoren, Routing, Prompt-Builder). Diese sollten deterministisch und schnell sein.
- Contract-Tests: verifizieren Sie Formvereinbarungen mit dem Modell, z. B. „muss gültiges JSON mit Schlüsseln X/Y/Z zurückgeben" oder „muss ein Zitat-Feld enthalten, wenn Confidence niedrig ist".
- End-to-End-Szenarien: realistische Nutzerflüsse durchspielen (inkl. Retries und Fallbacks), um zu sehen, ob das System unter Last hilfreich bleibt.
Eine gute Regel: Wenn ein Bug bis zu E2E-Tests vordringt, fügen Sie einen kleineren Test (Unit/Contract) hinzu, damit Sie ihn früher fangen.
Bauen Sie ein „Golden Set" von Prompts
Erstellen Sie eine kleine, kuratierte Sammlung von Prompts, die reale Nutzung repräsentieren. Dokumentieren Sie für jeden Prompt:
- Den Prompt (inkl. System-/Developer-Instruktionen)
- Erforderliche Einschränkungen (Format, Sicherheitsregeln, Geschäftsregeln)
- Erwartetes Verhalten (nicht exakte Formulierung), z. B. „gibt ein Objekt mit 3 Vorschlägen zurück", „verweigert Anfragen nach Geheimnissen", „stellt Klärungsfragen bei fehlenden Eingaben"
Führen Sie das Golden Set in CI aus und verfolgen Sie Änderungen im Zeitverlauf. Bei einem Vorfall: fügen Sie einen neuen Golden-Test für diesen Fall hinzu.
Fuzzing: machen Sie merkwürdige Eingaben normal
KI-Systeme versagen oft an unordentlichen Rändern. Fügen Sie automatisches Fuzzing hinzu, das erzeugt:
- Zufällige Strings und gemischte Encodings
- Fehlerhaftes JSON, abgeschnittene Payloads, zusätzliche Kommata
- Extreme Werte (sehr langer Text, leere Felder, riesige Zahlen, ungewöhnliche Daten)
Testen nicht-deterministischer Ausgaben
Statt exakte Text-Snapshots zu verwenden, nutzen Sie Toleranzen und Bewertungsraster:
- Bewerten Sie Ausgaben anhand von Checklisten (erforderliche Felder, verbotene Inhalte, Längenbegrenzungen)
- Semantische Prüfungen (z. B. Klassifikationslabel in einer erlaubten Menge)
- Ähnlichkeitsschwellen für Zusammenfassungen plus „muss Schlüsselfakten nennen"-Assertions
So bleiben Tests stabil und fangen gleichzeitig echte Regressionen.
Monitoring und Observability für Validierung und Fehler
Sichere Fallbacks in wenigen Minuten hinzufügen
Begrenzte Wiederholungen, Fallbacks und benutzerfreundliche Fehlermeldungen für deine KI‑Schritte erstellen.
Validierungsregeln und Fehlerbehandlung werden nur besser, wenn Sie sehen, was in der Praxis geschieht. Monitoring verwandelt „wir denken, es ist ok" in klare Evidenz: was schlug fehl, wie oft und ob die Zuverlässigkeit besser oder heimlich schlechter wird.
Was Sie loggen sollten (ohne Datenschutzprobleme zu schaffen)
Starten Sie mit Logs, die erklären, warum eine Anfrage erfolgreich war oder scheiterte — redigieren oder vermeiden Sie sensible Daten standardmäßig.
- Eingaben und Ausgaben (datenschutzbewusst): speichern Sie Hashes, gekürzte Auszüge oder strukturierte Felder statt Rohtext, wenn möglich. Wenn Rohinhalt zum Debuggen nötig ist, setzen Sie kurze Aufbewahrung, Zugriffssteuerung und klaren Zweck.
- Validierungsfehler: Regelname, Feld/Pfad (z. B.
address.postcode) und Fehlergrund (Schema-Mismatch, unsicherer Inhalt, fehlende Intention)
- Tool-Aufrufe und Nebenwirkungen: welches Tool wurde aufgerufen, Parameter (sanitized), Antwortcodes und Timing. Das ist essentiell, wenn Fehler außerhalb des Modells entstehen.
- Ausnahmen und Timeouts: Stacktraces für interne Fehler plus nutzerfreundliche Fehlercodes, die bekannten Kategorien zugeordnet sind.
Metriken, die Zuverlässigkeit vorhersagen
Logs helfen bei der Fehlersuche; Metriken zeigen Muster. Tracken Sie:
- Validierungsfehlerrate (gesamt und pro Regel)
- Schema-Pass-Rate (Ausgaben, die der erwarteten Struktur entsprechen)
- Retry-Rate und Erfolgsrate von Recovery (wie oft Fallbacks funktionieren)
- Latenz (end-to-end und pro Tool-Aufruf)
- Top-Fehlerkategorien (z. B. „fehlendes Feld", „Tool-Timeout", „Policy-Verstoß")
Alerts bei Drift
KI-Ausgaben können sich nach Prompt-Änderungen, Modell-Updates oder neuem Nutzerverhalten subtil verschieben. Alerts sollten Änderungen, nicht nur absolute Schwellen, fokussieren:
- Plötzlicher Anstieg einer bestimmten Validierungsregel-Frequenz
- Neue Fehlerkategorien tauchen auf
- Ausgabestruktur ändert sich (z. B. ein JSON-Feld wird plötzlich Freitext)
Dashboards für nicht-technische Teams
Ein gutes Dashboard beantwortet: „Funktioniert es für Nutzer?" Zeigen Sie eine einfache Zuverlässigkeits-Scorecard, Verlauf der Schema-Pass-Rate, Aufschlüsselung der Fehler nach Kategorie und anonymisierte Beispiele der häufigsten Fehlerarten. Verlinken Sie tiefere technische Ansichten für Ingenieure, aber halten Sie die Top-View lesbar für Produkt und Support.
Kontinuierliche Verbesserung: Fehler in bessere Regeln verwandeln
Validierung und Fehlerbehandlung sind nicht „einmal setzen und vergessen". In KI-generierten Systemen beginnt die eigentliche Arbeit nach dem Launch: jede merkwürdige Ausgabe ist ein Hinweis darauf, welche Regeln Sie brauchen.
Bauen Sie enge Feedback-Loops
Behandle Fehler als Daten, nicht als Anekdoten. Die effektivste Schleife kombiniert meist:
- Nutzerberichte (einfacher „Problem melden"-Button + optionaler Screenshot/Output-ID)
- Menschliche Review-Queues für zweifelhafte Fälle (irreführend, unsicher oder „sieht falsch aus")
- Automatisierte Labeling-Signale (Regex-/Schema-Fehler, Toxicity-Flags, Spracherkennungs-Mismatches, hohe Unsicherheitsindikatoren)
Sorge dafür, dass jeder Report zur genauen Eingabe, Modell/Prompt-Version und Validator-Resultaten zurückverfolgt werden kann, damit du ihn reproduzieren kannst.
Wie Fixes tatsächlich passieren
Die meisten Verbesserungen sind wiederkehrende Maßnahmen:
- Schema verschärfen: wenn Sie JSON erwarten, spezifizieren Sie erforderliche Felder, Enums und Typen; lehnen Sie „fast JSON" ab.
- Gezielte Validatoren hinzufügen: erzwinge Einheiten, Datumsformate, erlaubte Bereiche und Pflicht-Inhalte.
- Prompts anpassen: Prioritäten klären („Wenn unsicher, sag "Ich weiß es nicht""), Beispiele hinzufügen und mehrdeutige Instruktionen reduzieren.
- Fallbacks ergänzen: retry mit strengeren Prompts, wechseln zu einer sicheren Template-Antwort oder an menschliche Überprüfung — ohne Details stillschweigend zu erfinden.
Wenn Sie einen Fall beheben, fragen Sie auch: „Welche naheliegenden Fälle rutschen noch durch?" Dehnen Sie die Regel auf einen kleinen Cluster aus, nicht nur auf einen Einzelfall.
Versionierung und sichere Rollouts
Versionieren Sie Prompts, Validatoren und Modelle wie Code. Rollouts mit Canary- oder A/B-Releases durchführen, Schlüsselmetriken (Reject-Rate, Nutzerzufriedenheit, Kosten/Latenz) überwachen und einen schnellen Rollback-Pfad behalten.
Das ist auch der Punkt, an dem Produkt-Tooling hilft: Plattformen wie Koder.ai unterstützen Snapshots und Rollback bei App-Iterationen, was gut zu Prompt/Validator-Versionierung passt. Wenn ein Update Schema-Fehler erhöht oder eine Integration bricht, macht schneller Rollback aus einem Produktionsvorfall eine zügige Erholung.
Praktische Checkliste
- Können wir jeden gemeldeten Fehler aus den Logs reproduzieren?
- Werden Fehler in die richtige Kategorie geleitet (Retry, Fallback, menschliche Review, harter Stopp)?
- Haben wir Schema/Validator und Prompt zusammen aktualisiert?
- Haben wir einen Testfall für diesen Fehler hinzugefügt, damit er nicht wiederkehrt?
- Wurde die Änderung hinter einem Canary ausgeliefert und überwacht?