Was semantische Suche bedeutet (ohne Fachchinesisch)
Semantische Suche ist eine Art der Suche, die sich darauf konzentriert, was Sie meinen, und nicht nur auf die exakten Worte, die Sie eingeben.
Wenn Sie schon einmal etwas gesucht und gedacht haben: „Die Antwort steht ganz klar hier – warum findet die Suche sie nicht?“, dann haben Sie die Grenzen der Keyword‑Suche erlebt. Traditionelle Suche vergleicht Begriffe. Das funktioniert, wenn die Formulierung in Ihrer Anfrage und im Inhalt übereinstimmt.
Warum Keyword‑Suche oft danebenliegt
Keyword‑Suche hat Probleme mit:
- Synonymen und Formulierungen: „cancel“ vs. „close“ vs. „terminate“ eines Kontos.
- Intent: „how do I stop being billed?“ ist in Wahrheit das Thema „Abo kündigen“.
- Kontext: „apple charger“ (Marke) vs. „apple tree charger“ (Unsinn, aber Sie verstehen die Idee).
Sie kann auch wiederholte Wörter überbewerten und Ergebnisse zurückgeben, die oberflächlich relevant wirken, während die Seite mit der eigentlichen Antwort übersehen wird, weil sie andere Worte benutzt.
Ein einfaches Beispiel
Stellen Sie sich ein Help‑Center mit einem Artikel „Pause or cancel your subscription“ vor. Ein Nutzer sucht:
„stoppe meine Zahlungen nächsten Monat"
Ein Keyword‑System würde diesen Artikel vielleicht nicht weit oben platzieren, wenn er weder „stoppe“ noch „Zahlungen“ enthält. Semantische Suche soll verstehen, dass „stoppe meine Zahlungen“ eng mit „Abo kündigen“ verwandt ist und diesen Artikel nach oben bringen—weil die Bedeutung übereinstimmt.
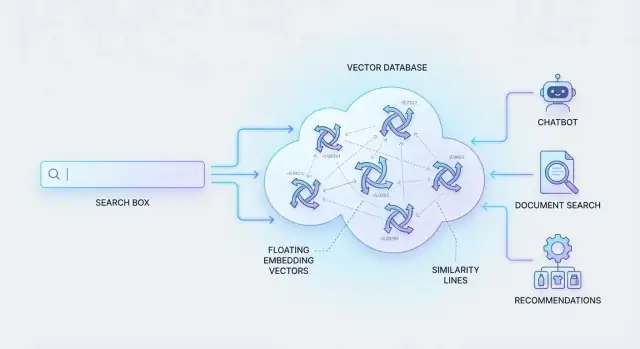
Wo Vektordatenbanken ins Spiel kommen
Damit das funktioniert, stellen Systeme Inhalte und Anfragen als „Bedeutungs‑Fingerabdrücke“ dar (Zahlen, die Ähnlichkeit erfassen). Danach müssen sie durch Millionen dieser Fingerabdrücke schnell suchen.
Dafür sind Vektordatenbanken gebaut: sie speichern diese numerischen Repräsentationen und rufen die ähnlichsten Treffer effizient ab, sodass semantische Suche auch in großem Maßstab nahezu instantan wirkt.
Embeddings: Inhalte in sinnvolle Vektoren verwandeln
Ein Embedding ist eine numerische Repräsentation von Bedeutung. Statt ein Dokument mit Schlagwörtern zu beschreiben, repräsentiert man es als Liste von Zahlen (einen „Vektor“), die erfassen, worum es inhaltlich geht. Zwei Inhalte mit ähnlicher Bedeutung haben Vektoren, die im numerischen Raum nahe beieinanderliegen.
Wie ein Embedding tatsächlich aussieht
Denken Sie an ein Embedding als Koordinate auf einer sehr hochdimensionalen Landkarte. Die Zahlen liest man normalerweise nicht direkt—sie sind nicht für Menschen gedacht. Ihr Wert liegt in ihrem Verhalten: Wenn „Abo kündigen“ und „wie stoppe ich meinen Tarif?“ nahe beieinanderliegende Vektoren erzeugen, kann das System diese als verwandt behandeln, auch wenn sie kaum oder gar keine gleichen Wörter teilen.
Text, Bilder und Audio können alle zu Vektoren werden
Embeddings sind nicht auf Text beschränkt.
- Text‑Embeddings repräsentieren Sätze, Absätze, Support‑Tickets, Produktbeschreibungen und mehr.
- Bild‑Embeddings repräsentieren visuelle Ähnlichkeit und Konzepte (z. B. „rote Laufschuhe“).
- Audio‑Embeddings können Sprecher, Tonfall oder die Bedeutung gesprochener Worte (in Kombination mit Speech‑Modellen) erfassen.
So kann eine einzige Vektordatenbank „Suche mit einem Bild“, „ähnliche Songs finden“ oder „ähnliche Produkte empfehlen“ unterstützen.
Generiert von Modellen — nicht manuell erstellt
Vektoren stammen nicht aus manueller Kennzeichnung. Sie werden von Machine‑Learning‑Modellen erzeugt, die darauf trainiert sind, Bedeutung in Zahlen zu komprimieren. Sie schicken Inhalte an ein Embedding‑Modell (self‑hosted oder über einen Anbieter) und erhalten einen Vektor zurück. Ihre Anwendung speichert diesen Vektor zusammen mit dem Originalinhalt und den Metadaten.
Warum die Wahl des Embeddings Qualität und Kosten beeinflusst
Das Embedding‑Modell, das Sie wählen, beeinflusst die Ergebnisse stark. Größere oder spezialisierte Modelle liefern oft bessere Relevanz, kosten aber mehr (und können langsamer sein). Kleinere Modelle sind günstiger und schneller, übersehen aber Nuancen—besonders bei domänenspezifischer Sprache, Mehrsprachigkeit oder sehr kurzen Anfragen. Viele Teams testen mehrere Modelle früh, um den besten Kompromiss zu finden, bevor sie hochskalieren.
Wie Vektordatenbanken Daten speichern
Eine Vektordatenbank baut auf einer einfachen Idee auf: speichere „Bedeutung“ (einen Vektor) zusammen mit den Informationen, die du brauchst, um Ergebnisse zu identifizieren, zu filtern und darzustellen.
Das grundlegende Datenmodell
Die meisten Datensätze sehen so aus:
- ID: ein eindeutiger Identifier, den Sie kontrollieren (z. B.
doc_18492 oder eine UUID)
- Vektor (Embedding): ein Array von Zahlen, das die Bedeutung des Inhalts repräsentiert
- Metadaten: Schlüssel‑Wert‑Felder wie title, URL, tags, author, language, created_at oder tenant_id
Zum Beispiel könnte ein Help‑Center‑Artikel speichern:
- ID:
kb_123
- Vektor: 768 Fließkommazahlen (für ein gängiges Embedding‑Modell)
- Metadaten:
{ "title": "Reset your password", "url": "/help/reset-password", "tags": ["account", "security"] }
Der Vektor treibt die semantische Ähnlichkeit an. ID und Metadaten machen die Ergebnisse nutzbar.
Metadaten erfüllen zwei Aufgaben:
- Filterung vor/nach der Vektorsuche: „Nur Ergebnisse zu Produkt X“, „Nur Englisch“, „Nur Dokumente, auf die der Nutzer Zugriff hat“ oder „Nur Items jünger als 90 Tage“. Das ist entscheidend für Relevanz und Zugriffskontrolle.
- Anzeige und Aktionen: Beim Präsentieren eines Ergebnisses wollen Nutzer keinen Vektor sehen—sie wollen einen Titel, einen Ausschnitt und einen Link (URL). Metadaten liefern die Details, die Ihre UI braucht.
Ohne gute Metadaten rufen Sie vielleicht die richtige Bedeutung ab, zeigen aber den falschen Kontext.
Gängige Vektorgrößen und Speicherimplikationen
Die Embedding‑Größe hängt vom Modell ab: 384, 768, 1024 und 1536 Dimensionen sind häufig. Mehr Dimensionen können Nuancen erfassen, erhöhen aber auch:
- Speicherplatz (jeder Datensatz speichert mehr Zahlen)
- Speicherbedarf für schnelle Suche
- Index‑Erstellungszeit (insbesondere bei ANN‑Indexen)
Als grobe Intuition: Eine Verdoppelung der Dimensionen treibt Kosten und Latenz nach oben, sofern Sie nicht durch Indexwahl oder Kompression ausgleichen.
Update‑Muster: Einfügen, Ändern und Löschen
Echte Datensätze ändern sich, daher unterstützen Vektordatenbanken typischerweise:
- Insert: neue Inhalte mit Embedding und Metadaten hinzufügen
- Update: Metadaten ändern (z. B. Tags) oder den Vektor ersetzen, wenn sich der Inhalt geändert hat
- Delete: veraltete oder widerrufene Inhalte entfernen
- Re‑embed: Vektoren neu berechnen, wenn Sie das Embedding‑Modell wechseln, das Chunking anpassen oder Text signifikant bearbeiten
Frühzeitige Planung für Updates verhindert ein „stales knowledge“-Problem, bei dem die Suche Inhalte zurückliefert, die nicht mehr mit dem übereinstimmen, was Benutzer sehen.
Ähnlichkeitssuche: „Nächste Bedeutung“ schnell finden
Sobald Ihr Text, Ihre Bilder oder Produkte in Embeddings (Vektoren) umgewandelt sind, wird Suche zu einem Geometrie‑Problem: „Welche Vektoren liegen am nächsten zu diesem Query‑Vektor?“ Das ist Nearest‑Neighbor‑Search. Statt Schlüsselwörter abzugleichen, vergleicht das System Bedeutung, indem es misst, wie nah zwei Vektoren beieinanderliegen.
Nearest Neighbors in einfachen Worten
Stellen Sie sich jeden Inhalt als Punkt in einem riesigen multidimensionalen Raum vor. Wenn ein Nutzer sucht, wird seine Anfrage in einen weiteren Punkt verwandelt. Die Ähnlichkeitssuche liefert die Items, deren Punkte am nächsten liegen—die „nächsten Nachbarn“. Diese Nachbarn teilen wahrscheinlich Intention, Thema oder Kontext, selbst wenn sie keine identischen Wörter verwenden.
Gängige Ähnlichkeitsmetriken
Vektordatenbanken unterstützen typischerweise einige Standardweisen, „Nähe“ zu bewerten:
- Kosinus‑Ähnlichkeit: vergleicht den Winkel zwischen Vektoren (gut, wenn Richtung/Bedeutung wichtiger ist als Magnitude).
- Dot‑Product: verwandt mit Kosinus, beeinflusst aber auch die Länge des Vektors; oft mit normalisierten Embeddings verwendet.
- Euklidische Distanz: die geradlinige Distanz zwischen Punkten (in manchen Modellen nützlich).
Verschiedene Embedding‑Modelle werden meist mit einer bestimmten Metrik trainiert, daher ist es wichtig, die vom Modellgeber empfohlene Metrik zu verwenden.
Exakte Suche vs. Annähernde (ANN)
Eine exakte Suche prüft jeden Vektor, um die tatsächlichen nächstliegenden Nachbarn zu finden. Das ist genau, wird aber bei Millionen von Elementen langsam und teuer.
Die meisten Systeme nutzen Approximate Nearest Neighbor (ANN)‑Suche. ANN verwendet intelligente Indexstrukturen, um die Suche auf vielversprechende Kandidaten zu beschränken. Meistens erhält man Ergebnisse, die „gut genug“ sind—dafür aber deutlich schneller.
Latenz vs. Recall‑Trade‑off
ANN ist populär, weil es erlaubt, für die eigenen Bedürfnisse zu feinjustieren:
- Niedrigere Latenz (schnellere Antworten) durch Suche in weniger Kandidaten
- Höherer Recall (mehr echte Top‑Treffer finden) durch Suche in mehr Kandidaten
Dieses Tuning ist der Grund, warum Vektor‑Suche in echten Apps gut funktioniert: Sie bleibt reaktionsschnell und liefert trotzdem sehr relevante Ergebnisse.
Der End‑to‑End‑Workflow der semantischen Suche
Semantische Suche lässt sich am besten als einfache Pipeline verstehen: Sie wandeln Text in Bedeutung um, suchen ähnliche Bedeutung und präsentieren dann die nützlichsten Treffer.
1) Anfrage einbetten
Ein Nutzer tippt eine Frage ein (z. B.: „Wie kündige ich meinen Tarif, ohne Daten zu verlieren?“). Das System leitet diesen Text durch ein Embedding‑Modell und erzeugt einen Vektor—ein Array von Zahlen, das die Bedeutung der Anfrage repräsentiert statt ihrer exakten Worte.
2) In der Vektordatenbank suchen
Dieser Query‑Vektor wird an die Vektordatenbank gesendet, die eine Ähnlichkeitssuche durchführt, um die „nächsten“ Vektoren in Ihrem Bestand zu finden.
Die meisten Systeme liefern Top‑K Treffer: die K ähnlichsten Chunks/Dokumente.
- Warum K konfigurierbar ist: ein kleineres K ist schneller und oft ausreichend (z. B. K=5).
- Ein größeres K erhöht den Recall (die Wahrscheinlichkeit, die richtige Antwort nicht zu verpassen), kann aber mehr „fast relevante“ Ergebnisse enthalten (z. B. K=50).
3) (Optional) Für Präzision neu ranken
Ähnlichkeitssuche ist auf Geschwindigkeit optimiert, daher kann die anfängliche Top‑K‑Liste Fehlgriffe enthalten. Ein Reranker ist ein zweites Modell, das die Anfrage und jeden Kandidaten zusammen betrachtet und sie nach Relevanz neu sortiert.
Denken Sie daran: Vektor‑Suche liefert eine starke Shortlist; Reranking wählt die beste Reihenfolge aus.
4) Ergebnisse zurückgeben (oder weiterverarbeiten)
Schließlich geben Sie die besten Treffer an den Nutzer zurück (als Suchergebnisse) oder übergeben sie an einen AI‑Assistenten (z. B. ein RAG‑System) als „Grounding“‑Kontext.
Wenn Sie diese Art von Workflow in einer App aufbauen, können Plattformen wie Koder.ai helfen, schnell Prototypen zu erstellen: Sie beschreiben die semantische Suche oder RAG‑Erfahrung in einer Chat‑Schnittstelle und iterieren dann am React‑Frontend und Go/PostgreSQL‑Backend, während die Retrieval‑Pipeline (Embedding → Vektor‑Suche → optionales Rerank → Antwort) als First‑Class‑Teil des Produkts erhalten bleibt.
Ein schnelles Beispiel „Keywords vs. Semantic"
Wenn Ihr Help‑Center‑Artikel „terminate subscription“ sagt und der Nutzer „cancel my plan“ sucht, kann Keyword‑Suche ihn übersehen, weil „cancel“ und „terminate“ nicht übereinstimmen.
Semantische Suche würde ihn typischerweise abrufen, weil das Embedding erfasst, dass beide Phrasen dieselbe Intention ausdrücken. Mit Reranking werden die obersten Ergebnisse meist nicht nur „ähnlich“, sondern direkt handlungsfähig für die Frage des Nutzers.
Zuerst die Pipeline planen
Plane Ingestion, Chunking und Updates, bevor du eine einzige Codezeile schreibst.
Reine Vektor‑Suche ist großartig für „Bedeutung“, aber Nutzer suchen nicht immer nur nach Bedeutungen. Manchmal brauchen sie ein exaktes Match: ein vollständiger Name, eine SKU, eine Rechnungsnummer oder ein Fehlercode aus einem Log. Hybride Suche kombiniert semantische Signale (Vektoren) mit lexikalischen Signalen (traditionelle Keyword‑Suche wie BM25).
Was hybride Suche tatsächlich macht
Eine hybride Anfrage führt typischerweise zwei Abrufpfade parallel aus:
- Vektor‑Suche: findet Inhalte, die inhaltlich ähnlich sind, auch wenn die Formulierungen abweichen.
- Keyword/BM25‑Suche: findet Inhalte, die dieselben Tokens teilen und exakte Begriffe, besonders seltene Wörter, belohnt.
Das System führt diese Kandidaten dann in einer Rangliste zusammen.
Wann Hybrid die bessere Standardeinstellung ist
Hybrid‑Suche überzeugt, wenn Ihre Daten „must‑match“ Strings enthalten:
- Produktnamen mit spezifischen Modifikatoren (z. B. „Pro Max“, „Gen 2")
- IDs (Bestellnummern, Ticket‑IDs, Ersatzteilnummern)
- Fehlercodes („E0421“, „ORA‑00933“) und Kommando‑Flags
- Seltene Domänentermini, bei denen Synonyme riskant wären
Semantische Suche allein liefert möglicherweise breit verwandte Seiten; Keyword‑Suche allein verpasst relevante Antworten mit anderer Formulierung. Hybrid deckt beide Fehlerfälle ab.
Metadatenfilter beschränken die Retrieval‑Menge vor der Rangordnung (oder parallel dazu) und verbessern Relevanz und Geschwindigkeit. Gängige Filter sind:
- Sprache (nur englische Dokumente zurückgeben)
- Datumsbereich (aktuellste Richtlinie, neueste Release‑Notes)
- Kategorie oder Quelle (Docs vs. Tickets; „billing“ vs. „security")
- Zugriffssteuerungs‑Tags (nur das zeigen, worauf dieser Nutzer Zugriff hat)
Wie Scoring grob funktioniert
Die meisten Systeme nutzen eine praktische Mischung: beide Suchen ausführen, Scores normalisieren, damit sie vergleichbar sind, und dann Gewichte anwenden (z. B. „mehr Gewicht auf Keywords für IDs“). Manche Produkte reranken die gemischte Shortlist mit einem leichten Modell oder Regeln, während Filter sicherstellen, dass Sie die richtige Teilmenge überhaupt erst ordnen.
RAG: Vektordatenbanken zur Fundierung von LLM‑Antworten
Retrieval‑Augmented Generation (RAG) ist ein praktisches Muster, um verlässlichere Antworten aus einem LLM zu bekommen: zuerst relevante Informationen abrufen, dann eine Antwort generieren, die an diesen Kontext gebunden ist.
Die RAG‑Idee in einem Satz
Anstatt das Modell Ihre Unternehmensdokumente „merken“ zu lassen, speichern Sie diese Dokumente (als Embeddings) in einer Vektordatenbank, rufen die relevantesten Chunks zur Abfragezeit ab und geben sie dem LLM als unterstützenden Kontext.
Warum eine Vektordatenbank Halluzinationen reduziert
LLMs schreiben hervorragend, neigen aber dazu, Lücken selbstbewusst zu füllen, wenn Fakten fehlen. Eine Vektordatenbank erleichtert es, die am besten passenden Passagen aus Ihrer Wissensbasis zu holen und dem Prompt zu übergeben.
Diese Fundierung verschiebt das Modell vom „Erfinde eine Antwort“ zu „Fasse diese Quellen zusammen und erkläre sie“. Außerdem macht es Antworten leichter prüfbar, weil Sie nachverfolgen können, welche Chunks abgerufen wurden und optional Zitate anzeigen.
Chunking‑Basics (damit Retrieval funktioniert)
Die RAG‑Qualität hängt oft mehr vom Chunking als vom Modell ab.
- Chunk‑Größe: Zielen Sie auf Chunks, die einen vollständigen Gedanken enthalten (oft ein kurzer Abschnitt). Zu klein verliert Bedeutung; zu groß zieht Rauschen hinein.
- Overlap: Fügen Sie eine kleine Überlappung hinzu, damit wichtige Details an Grenzen nicht abgeschnitten werden.
- Kontext behalten: Bewahren Sie Titel, Überschriften und Identifikatoren (Dokumentenname, Abschnitt, Datum) als Metadaten, damit die Ergebnisse verständlich und filterbar bleiben.
Einfacher RAG‑Pipeline‑Ablauf (Beschreibung)
Stellen Sie sich diesen Flow vor:
Nutzerfrage → Frage einbetten → Vektor‑DB ruft Top‑K Chunks ab (+ optionale Metadatenfilter) → Prompt mit abgerufenen Chunks bauen → LLM generiert Antwort → Antwort (und Quellen) zurückgeben.
Die Vektordatenbank sitzt in der Mitte als „schnelles Gedächtnis“, das zu jeder Anfrage die relevantesten Belege liefert.
Häufige KI‑Anwendungsfälle, die Vektordatenbanken antreiben
Quellcode erhalten
Behalte die volle Kontrolle: Exportiere den Quellcode, wenn du über Prototypen hinausgehen willst.
Vektordatenbanken machen Suche nicht nur „smarter“—sie ermöglichen Produkt‑Erlebnisse, in denen Nutzer natürlichsprachlich beschreiben, was sie wollen, und trotzdem relevante Ergebnisse bekommen. Hier einige praktische Anwendungsfälle, die immer wieder auftauchen.
Kundensupport: Antworten über Keywords hinaus finden
Support‑Teams haben häufig eine Wissensdatenbank, alte Tickets, Chat‑Transkripte und Release‑Notes—Keyword‑Suche kämpft mit Synonymen, Paraphrasen und vagen Problembeschreibungen.
Mit semantischer Suche kann ein Agent (oder ein Chatbot) vergangene Tickets abrufen, die dasselbe meinen, selbst wenn die Formulierungen anders sind. Das beschleunigt die Problemlösung, reduziert doppelte Arbeit und hilft neuen Agenten beim Einarbeiten. Die Kombination aus Vektor‑Suche und Metadatenfiltern (Produktlinie, Sprache, Problemtyp, Zeitraum) hält die Ergebnisse fokussiert.
Produktsuche: Kataloge so durchsuchen, wie Menschen sprechen
Käufer kennen selten genaue Produktnamen. Sie suchen nach Intentionen wie „kleiner Rucksack, der einen Laptop fasst und professionell aussieht“. Embeddings fangen solche Präferenzen—Stil, Funktion, Einschränkungen—ein, sodass die Ergebnisse eher wie von einem menschlichen Verkaufsberater wirken.
Diese Herangehensweise passt für Retail‑Kataloge, Reisen, Immobilien, Jobbörsen und Marktplätze. Sie können semantische Relevanz auch mit strukturierten Einschränkungen wie Preis, Größe, Verfügbarkeit oder Standort mischen.
Empfehlungen: „ähnliche Items“ und Content‑Discovery
Ein klassisches Feature ist „Finde ähnliche Items“. Wenn ein Nutzer ein Produkt ansieht, einen Artikel liest oder ein Video schaut, können Sie andere Inhalte mit ähnlicher Bedeutung oder Attributen zurückgeben—even wenn Kategorien nicht exakt übereinstimmen.
Nützliche Fälle:
- „Mehr davon“ Module
- Verwandte Artikel und Knowledge‑Base‑Vorschläge
- Duplikat‑ oder Near‑Duplicate‑Erkennung (für Moderation oder Content‑Cleanup)
Interne Suche mit Berechtigungen: Richtlinien, Docs, Meeting‑Notizen
Innerhalb von Unternehmen ist Information über Docs, Wikis, PDFs und Meeting‑Notizen verteilt. Semantische Suche hilft Mitarbeitenden, Fragen natürlich zu stellen („Wie ist unsere Erstattungsregelung für Konferenzen?“) und die richtige Quelle zu finden.
Unabdingbar ist Zugriffskontrolle. Ergebnisse müssen Berechtigungen respektieren—häufig durch Filter auf Team, Dokument‑Owner, Vertraulichkeitsniveau oder ACL‑Listen—damit Nutzer nur das sehen, worauf sie Zugriff haben.
Dasselbe Retrieval‑Layer treibt auch fundierte Q&A‑Systeme (siehe RAG) an.
Daten‑Pipelines: Ingestion, Chunking und Updates
Ein semantisches Suchsystem ist nur so gut wie die Pipeline, die es versorgt. Wenn Dokumente inkonsistent ankommen, schlecht gechunkt werden oder nach Änderungen niemals neu eingebettet werden, driftet die Suche von den Erwartungen der Nutzer ab.
Ein einfacher Ingest‑Flow (der funktioniert)
Die meisten Teams folgen einer wiederholbaren Sequenz:
- Daten sammeln (Docs, PDFs, Tickets, Chat‑Logs, Wiki‑Seiten, Produktdaten)
- Bereinigen (Boilerplate entfernen, Encoding reparieren, Whitespace normalisieren, Haupttext extrahieren)
- Chunking (in häppchengroße Passagen teilen, die Nutzer tatsächlich abrufen würden)
- Einbetten (Vektoren mit dem gewählten Embedding‑Modell erzeugen)
- Upsert (Vektoren + Metadaten in die Vektordatenbank schreiben, bei Bedarf ersetzen)
Der „Chunk“‑Schritt entscheidet oft über Erfolg oder Misserfolg. Chunks, die zu groß sind, verwässern Bedeutung; zu klein verlieren Kontext. Eine praktische Methode ist Chunking nach natürlicher Struktur (Überschriften, Absätze, Q&A‑Paare) und eine kleine Überlappung zur Kontinuität.
Embeddings aktuell halten
Inhalte ändern sich ständig—Richtlinien werden aktualisiert, Preise ändern sich, Artikel werden überarbeitet. Behandeln Sie Embeddings als abgeleitete Daten, die neu erzeugt werden müssen.
Gängige Taktiken:
- Speichern Sie eine Source‑Document‑ID, Chunk‑ID und einen Content‑Hash. Ändert sich der Hash, re‑embedden Sie den Chunk.
- Nutzen Sie Soft‑Deletes (alte Chunks inaktiv markieren), um Ghost‑Ergebnisse zu vermeiden.
- Wählen Sie selektives Rebuilden statt komplettes Neu‑Embeddieren.
Batch vs. Streaming‑Updates
- Batch eignet sich für große Backfills, nächtliche Synchronisationen und vorhersehbare Inhalte (Dokumentation, Wissensbasen).
- Streaming passt zu schnell ändernden Quellen (Support‑Tickets, UGC, Inventar). Es reduziert Staleness, benötigt aber mehr Monitoring und Kostenkontrolle.
Mehrere Sprachen und mehrere Modelle
Wenn Sie mehrere Sprachen bedienen, können Sie ein multilinguales Embedding‑Modell verwenden (einfacher) oder pro Sprache Modelle (manchmal höhere Qualität). Wenn Sie Modelle testen, versionieren Sie Ihre Embeddings (z. B. embedding_model=v3), um A/B‑Tests durchzuführen und Rollbacks ohne Bruch der Suche zu ermöglichen.
Semantische Suche wirkt im Demo‑Setup oft gut und kann in Produktion trotzdem scheitern. Der Unterschied ist Messung: Sie brauchen klare Relevanz‑Metriken und Latenz‑Ziele, ausgewertet auf Anfragen, die echtem Nutzerverhalten entsprechen.
Relevanzmetriken, die Nutzerzufriedenheit widerspiegeln
Beginnen Sie mit einer kleinen Metrik‑Auswahl und bleiben Sie konsistent:
- Precision / Recall: Precision zeigt, wie viele zurückgelieferte Ergebnisse tatsächlich relevant sind; Recall zeigt, wie viele relevante Items Sie überhaupt gefunden haben. Nutzt sich, wenn „relevant“ klar definiert ist.
- MRR (Mean Reciprocal Rank): Gut, wenn Nutzer eine einzige „beste“ Antwort erwarten. Belohnt, das richtige Dokument weit oben zu platzieren.
- nDCG: Nützlich, wenn mehrere Ergebnisse unterschiedliche Relevanzgrade haben (sehr relevant vs. etwas relevant).
- Latenz (p50/p95): Verfolgen Sie sowohl Durchschnitt als auch Tail‑Latenzen. Ein schnelles p50 mit langsamem p95 fühlt sich für Nutzer trotzdem träge an.
Ein Testset aufbauen, dem Sie vertrauen können
Erstellen Sie einen Evaluationssatz aus:
- Echten Anfragen aus Suchlogs oder Support‑Tickets (anonymisiert)
- Erwarteten Dokumenten (Gold‑Labels), die Domain‑Experten vereinbaren
- Edge‑Cases: kurze Anfragen („refund“), lange Fragen, mehrdeutige Begriffe, seltene Produktnamen und „No‑Result“‑Fälle, bei denen korrektes Verhalten „nichts gefunden“ ist
Halten Sie das Testset versioniert, damit Sie Releases vergleichen können.
A/B‑Tests und Feedback‑Schleifen
Offline‑Metriken erfassen nicht alles. Führen Sie A/B‑Tests durch und sammeln Sie leichte Signale:
- Thumbs up/down auf Ergebnisse
- Click‑Through und Dwell‑Time
- „Suche verfeinern“ Events
Nutzen Sie dieses Feedback, um Relevanzurteile zu aktualisieren und Fehlerbilder zu erkennen.
Drift über die Zeit überwachen
Performance kann sich ändern, wenn:
- Sie das Embedding‑Modell wechseln oder das Chunking anpassen
- Ihr Korpus sich verschiebt (neue Produkte, Policy‑Änderungen, saisonale Begriffe)
Führen Sie Ihre Test‑Suite nach jeder Änderung erneut aus, überwachen Sie Metrik‑Trends wöchentlich und setzen Sie Alerts für plötzliche Einbrüche in MRR/nDCG oder Spitzen im p95‑Latency.
Sicherheit, Datenschutz und Zugriffskontrolle
Wähle den richtigen Plan
Wechsle von Free zu Pro oder Business, wenn Nutzung und Team wachsen.
Vektor‑Suche ändert wie Daten abgerufen werden, aber nicht wer sie sehen darf. Wenn Ihr semantisches Such‑ oder RAG‑System den richtigen Chunk finden kann, kann es auch versehentlich einen Chunk zurückgeben, auf den der Nutzer nicht zugriffsberechtigt ist—es sei denn, Sie entwerfen Berechtigungen und Datenschutz bereits in den Retrieval‑Schritt hinein.
Zugriffskontrolle: zur Abfragezeit durchsetzen
Die sicherste Regel ist einfach: Ein Nutzer darf nur Inhalte abrufen, die er auch lesen darf. Verlassen Sie sich nicht darauf, dass die App Ergebnisse nachträglich „versteckt“—denn bis dahin haben die Inhalte Ihre Speichergrenze bereits verlassen.
Praktische Ansätze:
- Pro‑Dokument/Chunk ACLs: Berechtigungsfelder zusammen mit jedem Vektor speichern, sodass jede Abfrage sie prüfen kann.
- Tenant‑Isolation: Bei Multi‑Tenant‑Apps Daten pro Tenant trennen (logische Partitionen, Namespaces oder separate Indizes), um Cross‑Tenant‑Leaks zu vermeiden.
Viele Vektordatenbanken unterstützen metadatenbasierte Filter (z. B. tenant_id, department, project_id, visibility), die parallel zur Ähnlichkeitssuche laufen. Richtig verwendet ist das eine saubere Möglichkeit, Berechtigungen zur Abfragezeit anzuwenden.
Wichtig: Der Filter muss verpflichtend und serverseitig sein, nicht optionale Client‑Logik. Seien Sie vorsichtig bei „Role Explosion“ (zu viele Kombinationen). Bei komplexen Modellen kann es sinnvoll sein, „effective access groups“ vorzuberechnen oder einen dedizierten Autorisierungsdienst zu nutzen, der zur Abfragezeit ein Filter‑Token ausstellt.
PII und sensible Daten: entscheiden, was niemals eingebettet wird
Embeddings können Bedeutung aus dem Originaltext kodieren. Das offenbart nicht automatisch rohe PII, kann aber Risiken erhöhen (z. B. dass sensitive Fakten leichter abrufbar werden).
Bewährte Richtlinien:
- Vermeiden Sie, hochsensible Felder einzubetten (SSNs, Zahlungsdaten, medizinische Identifikatoren), wenn möglich.
- Redacten Sie vor dem Einbetten, wenn der Text durchsuchbar bleiben muss (ersetzen Sie exakte Werte durch Platzhalter).
- Speichern Sie Originale getrennt und rufen Sie sie erst nach Berechtigungsprüfungen ab.
Operationelle Bedürfnisse: Backups, Aufbewahrung und Audit
Behandeln Sie Ihren Vektor‑Index wie Produktionsdaten:
- Backups und Recovery: Indizes können teuer sein, neu zu erstellen; planen Sie Snapshots oder einen Rebuild‑Pfad aus den Quelldaten.
- Aufbewahrungsrichtlinien: Löschen Sie Vektoren, wenn Quell‑Dokumente ablaufen oder Nutzer Löschanfragen stellen.
- Auditierbarkeit: Protokollieren Sie, wer was abgefragt hat (mindestens Kontext der Anfrage und zurückgegebene Dokument‑IDs), um Untersuchungen und Compliance zu unterstützen.
Wird das gut gemacht, wirkt semantische Suche für Nutzer magisch—ohne später zur Sicherheitsüberraschung zu werden.
Fallstricke, Kosten und eine praktische Auswahl‑Checkliste
Vektordatenbanken wirken oft „Plug‑and‑Play“, aber die meisten Enttäuschungen kommen von den Entscheidungen rundherum: wie Sie chunking durchführen, welches Embedding‑Modell Sie wählen und wie zuverlässig Sie alles aktuell halten.
Häufige Fehlerquellen (und wie man sie erkennt)
Schlechtes Chunking ist die Nr.1 Ursache für irrelevante Ergebnisse. Chunks, die zu groß sind, verwässern Bedeutung; zu kleine verlieren Kontext. Wenn Nutzer oft sagen „es hat das richtige Dokument gefunden, aber die falsche Passage“, muss Ihr Chunking überarbeitet werden.
Das falsche Embedding‑Modell zeigt sich als konsistente semantische Fehlzuordnung—Ergebnisse sind flüssig, aber thematisch daneben. Das passiert, wenn das Modell nicht zu Ihrer Domäne (rechtlich, medizinisch, Support‑Tickets) oder Ihrem Inhaltstyp (Tabellen, Code, mehrsprachiger Text) passt.
Veraltete Daten schaffen schnell Vertrauensprobleme: Nutzer suchen nach der neuesten Richtlinie und bekommen die Version vom letzten Quartal. Ändert sich Ihre Quelle, müssen Embeddings und Metadaten mitziehen (und Löschungen müssen tatsächlich löschen).
Cold‑Start und Umgang mit Leerergebnissen
Anfangs haben Sie vielleicht zu wenig Inhalte, zu wenige Queries oder zu wenig Feedback, um Retrieval zu optimieren. Planen Sie für:
- Fallbacks: Keyword‑Suche oder kuratierte „Top Answers“, wenn semantische Ergebnisse schwach sind.
- UX bei leeren Ergebnissen: Zeigen Sie verwandte Kategorien, stellen Sie eine klärende Frage oder weiten Sie Filter.
- Warm‑up‑Queries: Testen Sie mit einer kleinen Menge repräsentativer Fragen vor dem Launch.
Kostentreiber, die Sie budgetieren sollten
Kosten entstehen meist aus vier Quellen:
- Embedding‑Compute (Initialer Backfill + laufende Updates)
- Speicher (Vektoren, Metadaten und Indizes)
- Query‑Volumen (Reads, Network‑Egress und Konkurenz)
- Reranking (optional, aber mächtig; kann pro Anfrage Modellkosten hinzufügen)
Vergleichen Sie Anbieter mit einer einfachen monatlichen Schätzung auf Basis Ihrer erwarteten Dokumentanzahl, durchschnittlichen Chunk‑Größe und Peak‑QPS. Viele Überraschungen treten nach dem Indexieren und bei Traffic‑Spitzen auf.
Auswahl‑Checkliste (praktisch)
Nutzen Sie diese kurze Checkliste, um eine Vektordatenbank zu wählen, die zu Ihren Anforderungen passt:
- Suchqualität: Unterstützt sie hybride Suche (Keywords + Vektoren) und Metadatenfilter? Können Sie Reranking hinzufügen?
- Performance: ANN‑Indexierungsoptionen, vorhersagbare Latenz bei Peak‑Traffic und einfache Skalierung?
- Daten‑Operationen: Upserts, Deletes, Re‑Indexing, Versionierung und Backfills ohne Downtime?
- Observability: Query‑Logs, Recall/Latenz‑Metriken und Tools, um zu debuggen „Warum dieses Ergebnis?“
- Sicherheit: Verschlüsselung, Tenant‑Isolation, rollenbasierte Zugriffe und Filter‑by‑Permission‑Mustern?
- Integration: SDKs, unterstützte Sprachen und Konnektoren zu Ihrem Storage (S3, DBs, Docs)?
- Gesamtkosten: Transparente Preisgestaltung für Storage, Writes, Reads und eventuelle Managed‑Compute‑Kosten.
Die richtige Wahl hängt weniger vom neuesten Indextyp ab als von Zuverlässigkeit: Können Sie Daten frisch halten, Zugriff kontrollieren und Qualität bewahren, während Inhalte und Traffic wachsen?