07. Aug. 2025·8 Min
Verteilte Datenbanken: Konsistenz gegen Verfügbarkeit tauschen
Erfahre, warum verteilte Datenbanken oft Konsistenz zugunsten von Verfügbarkeit lockern, wie CAP und Quorums funktionieren und wann welche Strategie sinnvoll ist.
Erfahre, warum verteilte Datenbanken oft Konsistenz zugunsten von Verfügbarkeit lockern, wie CAP und Quorums funktionieren und wann welche Strategie sinnvoll ist.
Wenn eine Datenbank über mehrere Maschinen (Replikate) verteilt ist, gewinnt man Geschwindigkeit und Ausfallsicherheit—aber man führt auch Zeiträume ein, in denen diese Maschinen nicht perfekt übereinstimmen oder nicht zuverlässig miteinander sprechen können.
Konsistenz bedeutet: nach einem erfolgreichen Schreibvorgang lesen alle dasselbe. Wenn du deine Profil-E-Mail aktualisierst, sollte der nächste Lesezugriff—egal welches Replikat antwortet—die neue E-Mail zurückliefern.
In der Praxis können Systeme, die Konsistenz priorisieren, Anfragen verzögern oder ablehnen, wenn Fehler auftreten, um widersprüchliche Antworten zu vermeiden.
Verfügbarkeit bedeutet: das System antwortet auf jede Anfrage, selbst wenn einige Server ausgefallen oder getrennt sind. Du erhältst vielleicht nicht die aktuellsten Daten, aber eine Antwort.
In der Praxis akzeptieren verfügbarkeitsorientierte Systeme oft Writes und serven Reads auch wenn Replikate uneinig sind und gleichen die Unterschiede später ab.
Ein Trade-off heißt: du kannst nicht in jedem Fehlerfall beide Ziele maximieren. Wenn Replikate nicht koordinieren können, muss die Datenbank entweder:
Die richtige Balance hängt davon ab, welche Fehler du tolerieren kannst: eine kurze Ausfallzeit oder eine kurze Periode falscher/alter Daten. Die meisten Systeme wählen einen Mittelweg und machen den Trade-off bewusst.
Eine Datenbank ist „verteilt", wenn sie Daten auf mehreren Maschinen (Knoten) speichert und über ein Netzwerk koordiniert. Für die Anwendung kann sie wie eine einzige Datenbank aussehen—unter der Haube können Anfragen jedoch von verschiedenen Knoten an unterschiedlichen Orten beantwortet werden.
Die meisten verteilten Datenbanken replizieren Daten: derselbe Datensatz liegt auf mehreren Knoten. Gründe dafür:
Replikation ist mächtig, wirft aber sofort die Frage auf: wenn zwei Knoten beide eine Kopie derselben Daten haben, wie stellt man sicher, dass sie immer übereinstimmen?
Auf einem einzelnen Server ist „down" meist offensichtlich: die Maschine ist da oder nicht. In verteilten Systemen sind Ausfälle oft partiell. Ein Knoten kann leben, aber langsam sein. Eine Netzwerkverbindung kann Pakete verlieren. Ein ganzes Rack kann die Verbindung verlieren, während der Rest des Clusters weiterläuft.
Das ist wichtig, weil Knoten nicht sofort wissen können, ob ein anderer Knoten wirklich down, vorübergehend unerreichbar oder nur verzögert ist. Während sie das herausfinden, müssen sie entscheiden, wie sie mit eingehenden Reads und Writes umgehen.
Bei einem Server gibt es eine einzige Quelle der Wahrheit: jedes Lesen sieht den neuesten erfolgreichen Schreibvorgang.
Bei mehreren Knoten hängt "neueste" vom Koordinieren ab. Wenn ein Write auf Knoten A erfolgreich ist, Knoten B aber nicht erreicht werden kann, sollte die Datenbank dann:
Diese Spannung—verursacht durch unvollkommene Netzwerke—ist der Grund, warum Verteilung die Regeln ändert.
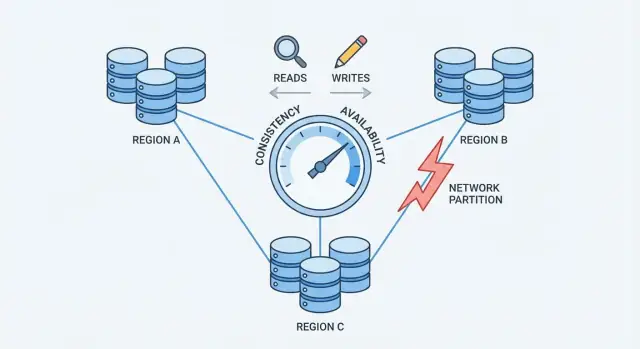
Eine Netzwerkpartition ist eine Unterbrechung der Kommunikation zwischen Knoten, die eigentlich als eine Datenbank arbeiten sollten. Die Knoten können weiterlaufen und gesund erscheinen, aber sie können Nachrichten nicht zuverlässig austauschen—wegen eines ausgefallenen Switches, einer überlasteten Leitung, einer fehlerhaften Routing-Änderung, einer falsch konfigurierten Firewall oder sogar störenden Nachbarn in einer Cloud-Umgebung.
Sobald ein System über mehrere Maschinen verteilt ist (oft über Racks, Zonen oder Regionen), kontrollierst du nicht mehr jeden einzelnen Hop dazwischen. Netzwerke verlieren Pakete, verursachen Verzögerungen und können sich in „Inseln" aufteilen. In kleinem Maßstab sind solche Ereignisse selten; in großem Maßstab sind sie Routine. Schon eine kurze Unterbrechung reicht, weil Datenbanken ständige Koordination brauchen, um zu wissen, was passiert ist.
Während einer Partition erhalten beide Seiten weiterhin Anfragen. Wenn Nutzer auf beiden Seiten schreiben können, akzeptiert jede Seite Updates, die die andere Seite nicht sieht.
Beispiel: Knoten A aktualisiert die Adresse eines Nutzers auf „Neue Straße“. Gleichzeitig aktualisiert Knoten B sie auf „Alte Straße, Whg. 2“. Jede Seite glaubt, ihr Schreibvorgang sei der aktuellste—weil sie sich nicht in Echtzeit austauschen kann.
Partitionen treten nicht als saubere Fehlermeldungen auf; sie zeigen sich durch verwirrendes Verhalten:
Das ist der Druckpunkt, der eine Entscheidung erzwingt: wenn das Netzwerk Kommunikation nicht garantiert, muss eine verteilte Datenbank entscheiden, ob sie Konsistenz oder Verfügbarkeit priorisiert.
CAP ist eine kompakte Beschreibung dessen, was passiert, wenn eine Datenbank über mehrere Maschinen verteilt ist.
Wenn es keine Partition gibt, können viele Systeme sowohl konsistent als auch verfügbar wirken.
Wenn eine Partition auftritt, musst du priorisieren:
balance = 100 auf Server A.balance = 80.CAP bedeutet nicht „dauerhaft zwei wählen“. Es heißt: während einer Partition kannst du nicht gleichzeitig Konsistenz und Verfügbarkeit garantieren. Außerhalb von Partitionen kannst du oft sehr nahe an beidem sein—bis das Netzwerk doch ausfällt.
Konsistenz zu wählen bedeutet, die "gleiche Wahrheit für alle" der ständigen Antwortbereitschaft vorzuziehen. Praktisch spricht man hier oft von starker Konsistenz, etwa linearizierbarem Verhalten: nachdem ein Schreibvorgang bestätigt wurde, liefert jede spätere Leseoperation (von überall) genau diesen Wert, als gäbe es eine einzige aktuelle Kopie.
Wenn das Netzwerk splittert und Replikate nicht zuverlässig sprechen können, kann ein stark konsistentes System keine unabhängigen Updates auf beiden Seiten akzeptieren. Um Korrektheit zu schützen, wird es typischerweise:
Aus Nutzerperspektive kann das wie ein Ausfall wirken, obwohl einige Maschinen weiterhin laufen.
Der Hauptvorteil ist einfacheres Denken. Anwendungscode kann so gestaltet werden, als spreche er mit einer einzigen Datenbank, nicht mit mehreren Replikaten, die möglicherweise widersprechen. Das reduziert überraschende Zustände wie:
Außerdem erhältst du klarere Modelle für Audits, Abrechnung und alles, was beim ersten Versuch korrekt sein muss.
Konsistenz hat reale Kosten:
Wenn dein Produkt fehlende Antworten während partieller Ausfälle nicht toleriert, kann starke Konsistenz teuer wirken—auch wenn sie korrektheitsseitig die richtige Wahl ist.
Verfügbarkeit zu wählen heißt, für das einfache Versprechen zu optimieren: das System antwortet, selbst wenn Teile der Infrastruktur gestört sind. „Hohe Verfügbarkeit" heißt nicht „keine Fehler jemals"—sondern, dass die meisten Anfragen weiterhin beantwortet werden, wenn Knoten ausfallen, Replikate überlastet sind oder Verbindungen gestört sind.
Bei einer Partition können Replikate nicht zuverlässig miteinander sprechen. Ein verfügbarkeitsorientiertes System bedient weiterhin den erreichbaren Teil:
Das hält Anwendungen am Laufen, bedeutet aber, dass verschiedene Replikate temporär unterschiedliche Wahrheiten akzeptieren können.
Du erreichst bessere Verfügbarkeit: Nutzer können weiterhin browsen, Artikel in den Warenkorb legen, Kommentare posten oder Events aufzeichnen, selbst wenn eine Region isoliert ist.
Das sorgt für ein flüssigeres Nutzererlebnis unter Stress. Statt Timeouts kann deine App weiter arbeiten („Dein Update wurde gespeichert") und später synchronisieren. Für viele Consumer- und Analytics-Workloads ist dieser Trade-off akzeptabel.
Der Preis ist, dass die Datenbanken veraltete Reads zurückgeben können. Ein Nutzer aktualisiert ein Profil auf einem Replikat und liest kurz danach von einem anderen—dort steht noch der alte Wert.
Es können Schreibkonflikte auftreten. Zwei Nutzer (oder derselbe Nutzer an zwei Orten) ändern während einer Partition dasselbe Objekt. Wenn die Partition heilt, muss das System divergente Historien reconciliieren. Je nach Regeln gewinnt der eine Write, Felder werden gemerged oder es braucht Anwendungslogik.
Verfügbarkeitsorientiertes Design akzeptiert temporäre Uneinigkeit, damit das Produkt antwortet—und investiert dann in Erkennung und Reparatur der Diskrepanzen.
Quorums sind eine praktische "Abstimmungs"-Technik, die viele replizierte Datenbanken nutzen, um Konsistenz und Verfügbarkeit ausbalancieren zu können. Statt einem einzelnen Replikat zu vertrauen, fragt das System genug Replikate an, um eine Entscheidung zu treffen.
Oft beschreibt man Quorums mit drei Zahlen:
Eine Faustregel: wenn R + W > N, dann überlappt jede Leseoperation mit mindestens einem Replikat, das den neuesten erfolgreichen Schreibvorgang gesehen hat—was die Chance auf veraltete Reads reduziert.
Bei N=3 Replikaten:
Manche Systeme wählen W=3 (alle Replikate) für stärkere Konsistenz, was aber mehr Schreibfehler verursacht, wenn auch nur ein Replikat langsam oder down ist.
Quorums beseitigen Partitionen nicht—sie legen fest, wer Fortschritt machen darf. Spaltet sich das Netzwerk 2–1, kann die Seite mit 2 Replikaten weiterhin R=2 und W=2 erfüllen, während das isolierte einzelne Replikat das nicht kann. Das reduziert konkurrierende Updates, bedeutet aber, dass manche Clients Fehler oder Timeouts sehen.
Quorums bedeuten in der Regel höhere Latenz (mehr Knoten kontaktieren), höhere Kosten (mehr Cross-Node-Traffic) und komplexeres Fehlverhalten (Timeouts erscheinen als Unverfügbarkeit). Der Vorteil ist ein einstellbarer Mittelweg: du kannst R und W in Richtung frischere Reads oder höhere Schreibverfügbarkeit drehen, je nachdem, was wichtiger ist.
Eventuelle Konsistenz erlaubt, dass Replikate vorübergehend nicht synchron sind, solange sie später konvergieren.
Stell dir eine Kette von Cafés vor, die ein gemeinsames "ausverkauft"-Schild für ein Gebäckstück teilen. Ein Laden markiert es als ausverkauft, aber das Update erreicht die anderen Läden erst Minuten später. In dieser Zeit zeigt ein anderer Laden noch "verfügbar" und verkauft das letzte Stück. Das System ist nicht „kaputt"—die Updates holen einfach auf.
Wenn sich Daten noch verbreiten, können Clients überraschende Zustände sehen:
Eventual-Consistency-Systeme nutzen oft Hintergrundmechanismen, um das Fenster der Inkonsistenz zu verkürzen:
Sie eignet sich, wenn Verfügbarkeit wichtiger ist als absolute Aktualität: Activity-Feeds, Zähler, Empfehlungen, gecachte Profile, Logs/Telemetry und andere nicht-kritische Daten, bei denen „später korrekt" akzeptabel ist.
Wenn eine Datenbank Writes auf mehreren Replikaten akzeptiert, kann sie am Ende Konflikte haben: zwei oder mehr Updates desselben Eintrags, die unabhängig während der Trennung erfolgten.
Ein klassisches Beispiel ist, dass ein Nutzer auf einem Gerät die Lieferadresse ändert und auf einem anderen Gerät gleichzeitig die Telefonnummer. Landen die Updates auf verschiedenen Replikaten während einer temporären Trennung, muss das System entscheiden, welcher Zustand nach dem Abgleich der „wahre" ist.
Viele Systeme beginnen mit Last-Write-Wins: das Update mit dem neuesten Zeitstempel überschreibt die anderen.
Das ist attraktiv, weil es einfach zu implementieren und schnell zu berechnen ist. Der Nachteil: es kann stillschweigend Daten verlieren. Wenn immer das „neueste" gewinnt, wird ein älteres, aber wichtiges Update überschrieben—auch wenn die beiden Updates unterschiedliche Felder betreffen.
Außerdem setzt LWW vertrauenswürdige Zeitstempel voraus. Uhrabweichungen zwischen Maschinen (oder Clients) können dazu führen, dass das „falsche" Update gewinnt.
Sicherere Konflikthandhabung erfordert oft kausale Historien. Konzeptuell hängen Versionsvektoren (oder Varianten) jedem Datensatz Metadaten an, die zusammenfassen, "welches Replikat welche Updates gesehen hat". Wenn Replikate Versionen austauschen, kann die Datenbank erkennen, ob eine Version eine andere einschließt (kein Konflikt) oder ob sie divergiert haben (Konflikt, der aufgelöst werden muss).
Manche Systeme nutzen logische Zeitstempel (z. B. Lamport-Clocks) oder hybride logische Uhren, um weniger von der Wanduhrzeit abhängig zu sein und dennoch eine Ordnungs-Hilfe zu liefern.
Wenn ein Konflikt erkannt wird, gibt es mehrere Optionen:
Die beste Strategie hängt davon ab, was für deine Daten als „korrekt" gilt—manchmal ist das Verwerfen eines Writes akzeptabel, in anderen Fällen wäre es ein geschäftskritischer Fehler.
Die Entscheidung über Konsistenz/Verfügbarkeit ist kein philosophisches Thema, sondern eine Produktentscheidung. Frag zuerst: Was kostet es, für einen Moment falsch zu liegen, und was kostet es, den Nutzer zu bitten „später erneut zu versuchen"?
Einige Bereiche brauchen zur Schreibzeit eine einzige, autoritative Antwort, weil „fast richtig" immer noch falsch ist:
Wenn ein temporärer Widerspruch wenig ausmacht oder reversibel ist, kannst du eher auf Verfügbarkeit setzen.
Viele UXs kommen mit leicht veralteten Reads klar:
Formuliere explizit, wie alt die Daten maximal sein dürfen: Sekunden, Minuten oder Stunden. Dieses Zeitbudget bestimmt deine Replikations- und Quorum-Entscheidungen.
Wenn Replikate nicht übereinstimmen, endest du meist in einer von drei UX-Situationen:
Triff die Entscheidung pro Feature, nicht global.
Lehne dich an C (Konsistenz), wenn falsche Ergebnisse finanzielles/rechtliches Risiko, Sicherheitsprobleme oder irreversible Aktionen erzeugen.
Lehne dich an A (Verfügbarkeit), wenn Nutzer Reaktionsschnelligkeit schätzen, veraltete Daten tolerierbar sind und Konflikte später sicher aufgelöst werden können.
Wenn du unsicher bist: teile das System. Halte kritische Datensätze stark konsistent und erlaube abgeleiteten Sichten (Feeds, Caches, Analytics) höhere Verfügbarkeit.
Du musst selten eine einzige Konsistenz-Einstellung für das gesamte System wählen. Viele moderne verteilte Datenbanken erlauben Konsistenz pro Operation—und clevere Anwendungen nutzen das, um die UX glatt zu halten, ohne so zu tun, als existiere der Trade-off nicht.
Behandle Konsistenz wie einen Regler, den du je nach Nutzeraktion drehst:
So vermeidest du, für alles den höchsten Konsistenzpreis zu zahlen, schützt aber wichtige Operationen.
Ein übliches Muster ist stark für Writes, schwächer für Reads:
Manchmal ist die umgekehrte Reihenfolge sinnvoll: schnelle Writes (queued/eventual) plus starke Reads zur Bestätigung („Wurde meine Bestellung platziert?“).
Netzwerke wackeln, Clients retryen. Mach Retries sicher mit Idempotency Keys, damit „Bestellung abschicken" nicht zweimal zwei Bestellungen erzeugt. Speichere und reuse das erste Ergebnis, wenn derselbe Key erneut gesehen wird.
Für mehrstufige Aktionen über Services hinweg nutze eine Saga: jeder Schritt hat eine entsprechende Kompensationsaktion (Rückerstattung, Reservierung freigeben, Versand stornieren). So bleibt das System wiederherstellbar, selbst wenn Teile vorübergehend uneins sind.
Du kannst den Trade-off nicht managen, wenn du ihn nicht sichtbar machst. Produktionsprobleme wirken oft wie „zufällige Fehler", bis du die richtigen Messwerte und Tests hast.
Beginne mit einer kleinen Metrikauswahl, die sich direkt auf Nutzerauswirkung bezieht:
Wenn möglich, tagge Metriken nach Konsistenzmodus (Quorum vs. lokal) und Region/Zone, um Abweichungen zu erkennen.
Warte nicht auf den echten Ausfall. Führe in Staging Chaos-Experimente durch, die simulieren:
Prüfe nicht nur, ob „das System läuft", sondern welche Garantien gehalten werden: Bleiben Reads frisch? Blockieren Writes? Bekommen Clients klare Fehler?
Lege Alerts an für:
Dokumentiere schließlich explizit, was dein System verspricht—im Normalbetrieb und während Partitionen—und schule Produkt- und Support-Teams, was Nutzer sehen können und wie zu reagieren ist.
Wenn du diese Trade-offs in einem neuen Produkt erkundest, hilft es, Annahmen früh zu validieren—insbesondere zu Fehlerverhalten, Retry-Logik und wie “veraltet" in der UI wirkt.
Ein praktischer Ansatz ist, einen kleinen Prototypen des Workflows zu bauen (Schreibpfad, Lesepfad, Retry/Idempotenz und ein Rekonsilierungs-Job), bevor du dich auf eine vollständige Architektur festlegst. Mit Tools wie Koder.ai können Teams Web-Apps und Backends über einen chatgesteuerten Workflow schnell hochziehen, Datenmodelle und APIs iterieren und verschiedene Konsistenzmuster (z. B. strikte Writes + entspannte Reads) testen, ohne den Overhead einer traditionellen Build-Pipeline. Wenn der Prototyp das gewünschte Verhalten zeigt, lässt sich der Code exportieren und in Richtung Produktion weiterentwickeln.
In einer replizierten Datenbank lebt dieselbe Information auf mehreren Maschinen. Das erhöht Ausfallsicherheit und Performance, bringt aber Koordinationsprobleme: Knoten können langsam, unerreichbar oder durch das Netzwerk getrennt sein, sodass sie nicht immer sofort über den neuesten Schreibvorgang übereinstimmen.
Konsistenz bedeutet: nach einem erfolgreichen Schreibvorgang liefert jede spätere Leseoperation denselben Wert—egal, welcher Replikat antwortet. In der Praxis erzwingen Systeme das oft, indem sie Lese-/Schreibanfragen verzögern oder ablehnen, bis genügend Replikate (oder ein Leader) das Update bestätigt haben.
Verfügbarkeit bedeutet, dass das System auf jede Anfrage mit einer Nicht-Fehler-Antwort reagiert, selbst wenn einige Knoten ausgefallen sind oder nicht kommunizieren können. Die Antwort kann veraltet oder partiell sein und basiert auf lokalem Zustand, aber das System blockiert die Nutzer nicht während Ausfällen.
Eine Netzwerkpartition ist eine Unterbrechung der Kommunikation zwischen Knoten, die eigentlich als ein System zusammenarbeiten sollten. Die Knoten können noch laufen, aber Nachrichten passieren die Trennung nicht zuverlässig. Dadurch steht die Datenbank vor der Entscheidung, entweder:
Während einer Partition können beide Seiten weiterhin Updates annehmen, die die andere Seite nicht sofort sieht. Das führt zu:
Das sind die sichtbaren Folgen davon, dass Replikate vorübergehend nicht koordinieren können.
Es heißt nicht „dauerhaft nur zwei auswählen“. Es bedeutet: während einer Partition kannst du nicht gleichzeitig garantieren:
Außerhalb von Partitionen erscheinen viele Systeme oft gleichzeitig konsistent und verfügbar—bis das Netzwerk doch mal ausfällt.
Quorums nutzen Abstimmungen über Replikate:
Eine gängige Richtlinie ist R + W > N, damit sich Lese- und Schreibmengen überlappen und die Wahrscheinlichkeit veralteter Reads sinkt. Quorums lösen Partitionen nicht, sie definieren nur, welche Seite bei einer Teilung fortschreiten darf (beispielsweise die Mehrheit).
Eventuelle Konsistenz erlaubt, dass Replikate vorübergehend unterschiedlich sind, solange sie später zusammenlaufen. Übliche Anomalien sind:
Systeme mildern das mit , und regelmäßiger -Rekonsilierung.
Konflikte entstehen, wenn während einer Trennung verschiedene Replikate inkompatible Writes akzeptieren. Auflösungsstrategien sind unter anderem:
Wähle die Strategie danach, was für die Daten als „korrekt" gilt.
Treffe die Entscheidung nach dem geschäftlichen Risiko und dem Fehlerbild, das du tolerieren kannst:
Praktische Muster: pro Operation Konsistenzstufen, idempotente Retries und Sagas mit Kompensationen für mehrstufige Workflows.