Vom Prototyp zum SaaS: wo die Verwirrung beginnt
Ein Prototyp beweist eine Idee. Ein SaaS muss echte Nutzung überstehen: Spitzenlast, unordentliche Daten, Neustarts und Kunden, die jeden Aussetzer bemerken. Genau hier wird es kompliziert, weil sich die Frage von „funktioniert es?“ zu „funktioniert es dauerhaft?“ verschiebt.
Bei echten Nutzern reicht „es hat gestern funktioniert“ aus langweiligen Gründen nicht mehr. Ein Hintergrundjob läuft später als sonst. Ein Kunde lädt eine Datei hoch, die zehnmal größer ist als Ihre Testdaten. Ein Zahlungsanbieter hängt 30 Sekunden. Nichts davon ist exotisch, aber die Folgeeffekte werden laut, sobald Teile Ihres Systems voneinander abhängen.
Die meiste Komplexität zeigt sich an vier Stellen: Daten (dasselbe Faktum existiert an mehreren Orten und driftet), Latenz (50 ms-Aufrufe dauern manchmal 5 Sekunden), Fehler (Timeouts, partielle Updates, Retries) und Teams (verschiedene Leute liefern verschiedene Services zu unterschiedlichen Zeiten aus).
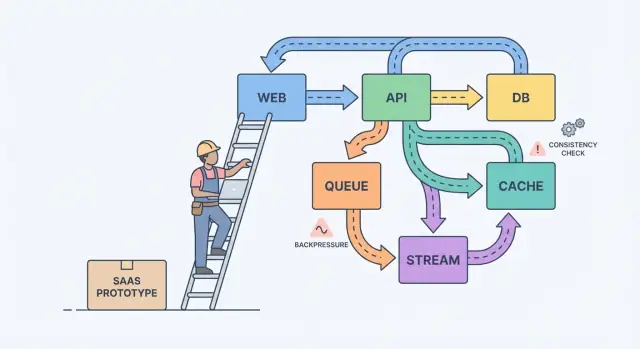
Ein einfaches mentales Modell hilft: Komponenten, Nachrichten und Zustand.
Komponenten erledigen Arbeit (Web-App, API, Worker, Datenbank). Nachrichten bewegen Arbeit zwischen Komponenten (Requests, Events, Jobs). Zustand ist, was Sie sich merken (Bestellungen, Benutzereinstellungen, Abrechnungsstatus). Skalierungsschmerz entsteht meist durch ein Missverhältnis: Sie schicken Nachrichten schneller, als eine Komponente verarbeiten kann, oder Sie aktualisieren Zustand an zwei Stellen ohne klare Single-Source-of-Truth.
Ein klassisches Beispiel ist Abrechnung. Ein Prototyp könnte innerhalb einer Anfrage eine Rechnung erstellen, eine E-Mail senden und den Plan eines Nutzers aktualisieren. Unter Last verlangsamt sich E-Mail, die Anfrage läuft aus, der Client wiederholt die Anfrage und plötzlich haben Sie zwei Rechnungen und nur eine Planänderung. Verlässlichkeitsarbeit dreht sich meist darum, diese alltäglichen Fehler davon abzuhalten, zu kunden-sichtbaren Bugs zu werden.
Konzepte in schriftliche Entscheidungen verwandeln
Die meisten Systeme werden schwieriger, weil sie wachsen, ohne Klarheit darüber, was korrekt sein muss, was schnell sein darf und was bei Fehlern passieren soll.
Beginnen Sie damit, eine Grenze zu ziehen für das, was Sie den Nutzern zusichern. Nennen Sie innerhalb dieser Grenze die Aktionen, die immer korrekt sein müssen (Geldbewegungen, Zugriffskontrolle, Account-Eigentum). Dann benennen Sie Bereiche, in denen „letztlich korrekt“ ausreicht (Analytics-Zähler, Suchindizes, Empfehlungen). Diese einfache Aufteilung macht unscharfe Theorie zu Prioritäten.
Schreiben Sie als Nächstes Ihre Quelle der Wahrheit auf. Das ist der Ort, an dem Fakten einmal dauerhaft mit klaren Regeln aufgezeichnet werden. Alles andere sind abgeleitete Daten, gebaut für Geschwindigkeit oder Komfort. Wenn eine abgeleitete Ansicht korrupt ist, sollten Sie sie aus der Quelle der Wahrheit wiederherstellen können.
Wenn Teams feststecken, bringen diese Fragen meist zutage, worauf es ankommt:
- Welche Daten dürfen niemals verloren gehen, selbst wenn es langsamer wird?
- Was kann aus anderen Daten rekonstruiert werden, selbst wenn es Stunden dauert?
- Was darf veraltet sein, und wie lange, aus Sicht des Nutzers?
- Welcher Fehler ist schlimmer für Sie: Duplikate, fehlende Events oder Verzögerungen?
Wenn ein Nutzer seinen Tarif ändert, kann ein Dashboard verzögert sein. Aber Sie können keinen Widerspruch zwischen Zahlungsstatus und tatsächlichem Zugriff tolerieren.
Wenn ein Nutzer sofort das Ergebnis sehen muss (Profil speichern, Dashboard laden, Berechtigungen prüfen), genügt meist ein normales Request-Response-API. Halten Sie es direkt.
Sobald Arbeit später erledigt werden kann, verschieben Sie sie auf Async. Denken Sie an E-Mails, Karten belasten, Berichte generieren, Uploads verkleinern oder Daten zu Search syncen. Der Nutzer sollte nicht auf diese Dinge warten, und Ihre API sollte nicht blockiert sein, während sie laufen.
Eine Queue ist eine To-do-Liste: jede Aufgabe sollte genau einmal von einem Worker bearbeitet werden. Ein Stream (oder Log) ist ein Protokoll: Events werden in Reihenfolge gehalten, sodass mehrere Leser sie reproduzieren, aufholen oder später neue Features bauen können, ohne den Produzenten zu ändern.
Eine praktische Auswahlhilfe:
- Verwenden Sie Request-Response, wenn der Nutzer sofort eine Antwort braucht und die Arbeit klein ist.
- Verwenden Sie eine Queue für Hintergrundarbeit mit Retries, bei der nur ein Worker jeden Job ausführen sollte.
- Verwenden Sie einen Stream/Log, wenn Sie Replay, ein Audit-Trail oder mehrere Konsumenten brauchen, die nicht an einen Service gekoppelt sein sollen.
Beispiel: Ihr SaaS hat einen „Create invoice“-Button. Die API validiert die Eingabe und speichert die Rechnung in Postgres. Dann kümmert sich eine Queue um „send invoice email“ und „charge card“. Wenn Sie später Analytics, Notifications und Fraud-Checks hinzufügen, erlaubt ein Stream mit InvoiceCreated-Events jedem Feature zu abonnieren, ohne Ihren Kernservice in ein Labyrinth zu verwandeln.
Event-Design: was Sie veröffentlichen und was Sie aufbewahren
Mit wachsendem Produkt werden Events vom „Nettigkeit“-Feature zur Rettungsleine. Gutes Event-Design reduziert sich auf zwei Fragen: Welche Fakten zeichnen Sie auf, und wie können andere Teile des Produkts reagieren, ohne zu raten?
Beginnen Sie mit einer kleinen Menge Business-Events. Wählen Sie Momente, die für Nutzer und Geld wichtig sind: UserSignedUp, EmailVerified, SubscriptionStarted, PaymentSucceeded, PasswordResetRequested.
Namen überdauern Code. Verwenden Sie die Vergangenheitsform für abgeschlossene Fakten, bleiben Sie spezifisch und vermeiden Sie UI-Formulierungen. PaymentSucceeded bleibt sinnvoll, auch wenn Sie später Coupons, Retries oder mehrere Zahlungsanbieter hinzufügen.
Behandeln Sie Events als Verträge. Vermeiden Sie ein Sammelsurium wie „UserUpdated“ mit wechselnden Feldern. Bevorzugen Sie das kleinste Faktum, hinter dem Sie jahrelang stehen können.
Um sicher zu evolvieren, bevorzugen Sie additive Änderungen (neue optionale Felder). Bei einer breaking change veröffentlichen Sie einen neuen Event-Namen (oder eine explizite Version) und betreiben beides, bis alte Konsumenten weg sind.
Was sollten Sie speichern? Wenn Sie nur die neuesten Zeilen in einer Datenbank behalten, verlieren Sie die Geschichte, wie Sie dorthin kamen.
Roh-Events sind großartig für Audit, Replay und Debugging. Snapshots sind großartig für schnelle Lesezugriffe und zügige Wiederherstellung. Viele SaaS-Produkte nutzen beides: Roh-Events für Schlüssel-Workflows (Abrechnung, Berechtigungen) und Snapshots für nutzernahe Ansichten.
Konsistenz-Abwägungen, die Nutzer tatsächlich spüren
Test under real conditions
Deploy and host your app early so you can observe latency, retries, and queue lag.
Konsistenz zeigt sich in Momenten wie: „Ich habe meinen Plan geändert, warum steht dort noch Free?“ oder „Ich habe eine Einladung geschickt, warum kann mein Kollege sich noch nicht einloggen?“
Starke Konsistenz bedeutet: Sobald Sie eine Erfolgsmeldung erhalten, sollte jeder Bildschirm den neuen Zustand sofort zeigen. Eventuelle Konsistenz bedeutet, die Änderung breitet sich über Zeit aus, und für ein kurzes Fenster können unterschiedliche Teile der App abweichen. Keines ist per se „besser“. Sie wählen je nach Schaden, den ein Missverhältnis anrichten kann.
Starke Konsistenz passt meist zu Geld, Zugriff und Sicherheit: eine Karte belasten, Passwort ändern, API-Keys sperren, Seat-Limits durchsetzen. Eventuelle Konsistenz passt oft zu Aktivitäts-Feeds, Suche, Analytics-Dashboards, „zuletzt gesehen“ und Notifications.
Wenn Sie Staleness akzeptieren, gestalten Sie dafür statt es zu verstecken. Halten Sie die UI ehrlich: zeigen Sie einen „Aktualisiert…“-Zustand nach einem Schreibvorgang, bis die Bestätigung eintrifft, bieten Sie manuelles Aktualisieren für Listen an und verwenden Sie optimistische UI nur, wenn Sie sauber zurückrollen können.
Retries sind der Ort, an dem Konsistenz heimtückisch wird. Netzwerke fallen aus, Clients klicken doppelt und Worker starten neu. Für wichtige Operationen machen Sie Requests idempotent, damit das Wiederholen derselben Aktion nicht zwei Rechnungen, zwei Einladungen oder zwei Rückerstattungen erzeugt. Ein gängiger Ansatz ist ein Idempotency-Key pro Aktion plus eine serverseitige Regel, das ursprüngliche Ergebnis bei Wiederholungen zurückzugeben.
Backpressure: das System vor dem Kollaps schützen
Backpressure brauchen Sie, wenn Requests oder Events schneller ankommen, als Ihr System verarbeiten kann. Ohne sie türmt sich Arbeit im Speicher auf, Queues wachsen und die langsamste Abhängigkeit (oft die Datenbank) bestimmt, wann alles ausfällt.
Einfach ausgedrückt: Ihr Producer redet weiter, während Ihr Consumer ertrinkt. Wenn Sie weiter Arbeit akzeptieren, werden Sie nicht nur langsamer. Sie lösen eine Kettenreaktion aus von Timeouts und Retries, die die Last multiplizieren.
Warnsignale sind meistens sichtbar, bevor ein Ausfall passiert: Backlog wächst stetig, Latenz steigt nach Spitzen oder Deploys, Retries nehmen wegen Timeouts zu, nicht verwandte Endpunkte fallen aus, wenn eine Abhängigkeit langsam ist, und DB-Verbindungen sitzen am Limit.
Wenn Sie diesen Punkt erreichen, legen Sie eine klare Regel fest, was passiert, wenn Sie voll sind. Das Ziel ist nicht, alles um jeden Preis zu verarbeiten. Es ist, am Leben zu bleiben und schnell wiederherzustellen. Teams beginnen typischerweise mit ein oder zwei Kontrollen: Rate Limits (pro Nutzer oder API-Schlüssel), begrenzte Queues mit definiertem Drop/Delay-Policy, Circuit Breaker für ausfallende Abhängigkeiten und Prioritäten, damit interaktive Anfragen Hintergrundjobs schlagen.
Schützen Sie die Datenbank zuerst. Halten Sie Connection-Pools klein und vorhersehbar, setzen Sie Query-Timeouts und harte Limits für teure Endpunkte wie Ad-hoc-Reports.
Ein Schritt-für-Schritt-Pfad zur Zuverlässigkeit (ohne alles neu zu schreiben)
Zuverlässigkeit erfordert selten einen großen Rewrite. Meistens helfen wenige Entscheidungen, die Fehler sichtbar, eingegrenzt und wiederherstellbar machen.
Beginnen Sie mit den Flows, die Vertrauen gewinnen oder verlieren, und fügen Sie Sicherheitsgeländer hinzu, bevor Sie Features hinzufügen:
-
Map critical paths. Schreiben Sie die genauen Schritte für Signup, Login, Passwort-Reset und jeden Zahlungs-Flow auf. Listen Sie für jeden Schritt seine Abhängigkeiten (DB, E-Mail-Provider, Background Worker). Das schafft Klarheit darüber, was sofort sein muss und was „eventuell“ repariert werden kann.
-
Add observability basics. Geben Sie jeder Anfrage eine ID, die in Logs auftaucht. Verfolgen Sie eine kleine Menge Metriken, die zum Nutzerleid passen: Fehlerrate, Latenz, Queue-Tiefe und langsame Queries. Fügen Sie Traces nur dort hinzu, wo Anfragen Services überschreiten.
-
Isolate slow or flaky work. Alles, was mit externen Services spricht oder regelmäßig länger als eine Sekunde braucht, sollte in Jobs und Worker verschoben werden.
-
Design for retries and partial failures. Gehen Sie von Timeouts aus. Machen Sie Operationen idempotent, verwenden Sie Backoff, setzen Sie Zeitlimits und halten Sie nutzernahe Aktionen kurz.
-
Practice recovery. Backups nützen nur, wenn Sie sie wiederherstellen können. Verwenden Sie kleine Releases und einen schnellen Rollback-Pfad.
Wenn Ihr Tooling Snapshots und Rollback unterstützt (Koder.ai tut das), bauen Sie das in normale Deployment-Gewohnheiten ein, statt es als Notfalltrick zu behandeln.
Beispiel: wie man ein kleines SaaS verlässlich macht
Build the SaaS, not slides
Turn your scaling decisions into a working React + Go + Postgres app in one place.
Stellen Sie sich ein kleines SaaS vor, das Teams beim Onboarding neuer Kunden hilft. Der Flow ist einfach: ein Nutzer meldet sich an, wählt einen Plan, bezahlt und erhält eine Willkommens-E-Mail plus ein paar „Getting started“-Schritte.
Im Prototyp passiert alles in einer Anfrage: Account anlegen, Karte belasten, „paid“ auf dem Nutzer setzen, E-Mail senden. Das funktioniert, bis Traffic wächst, Retries passieren und externe Services langsamer werden.
Um es verlässlich zu machen, wandelt das Team Schlüsselaktionen in Events um und behält eine Append-only-Historie. Sie führen einige Events ein: UserSignedUp, PaymentSucceeded, EntitlementGranted, WelcomeEmailRequested. Das gibt ihnen einen Audit-Trail, vereinfacht Analytics und erlaubt langsamer Arbeit, im Hintergrund zu laufen, ohne das Signup zu blockieren.
Ein paar Entscheidungen erledigen den Großteil der Arbeit:
- Behandeln Sie Zahlungen als Source of Truth für Zugriff, nicht als einzelnes „paid“-Flag.
- Gewähren Sie Entitlements aus
PaymentSucceeded mit einem klaren Idempotency-Key, damit Retries nicht doppelt gewähren.
- Senden Sie E-Mails aus einer Queue/Worker, nicht aus der Checkout-Anfrage.
- Zeichnen Sie Events auf, selbst wenn ein Handler fehlschlägt, damit Sie replayen und wiederherstellen können.
- Fügen Sie Timeouts und einen Circuit Breaker um externe Provider hinzu.
Wenn die Zahlung erfolgreich ist, der Zugriff aber noch nicht gewährt wurde, fühlen sich Nutzer betrogen. Die Lösung ist nicht „perfekte Konsistenz überall“. Es ist zu entscheiden, was jetzt konsistent sein muss, und diese Entscheidung in der UI widerzuspiegeln, etwa mit einem Zustand „Aktiviere Ihren Plan“, bis EntitlementGranted eintrifft.
An einem schlechten Tag macht Backpressure den Unterschied. Wenn die Email-API während einer Marketingkampagne hängt, timet das alte Design Checkouts aus und Nutzer wiederholen, was doppelte Abbuchungen und doppelte E-Mails erzeugt. Im besseren Design gelingt der Checkout, E-Mail-Anfragen werden angestellt und ein Replay-Job leert das Backlog, sobald der Provider sich erholt.
Häufige Fallen beim Skalieren
Die meisten Ausfälle werden nicht durch einen heroischen Bug verursacht. Sie ergeben sich aus kleinen Entscheidungen, die im Prototyp sinnvoll waren und dann zur Gewohnheit wurden.
Eine Falle ist, zu früh in Microservices zu splitten. Man endet mit Services, die sich hauptsächlich gegenseitig aufrufen, unklarer Ownership und Änderungen, die fünf Deploys statt einem erfordern.
Eine andere Falle ist, „eventual consistency“ als Freifahrtschein zu nutzen. Nutzer interessieren sich nicht für den Begriff. Sie wollen, dass sie auf Speichern klicken und später die Seite nicht alte Daten zeigt oder ein Rechnungsstatus hin und her springt. Wenn Sie Verzögerung akzeptieren, brauchen Sie trotzdem Nutzer-Feedback, Timeouts und eine Definition von „gut genug“ auf jedem Screen.
Weitere wiederkehrende Fehler: Events ohne Reprocessing-Plan veröffentlichen, unbeschränkte Retries, die Last während Vorfällen multiplizieren, und jeder Service erlaubt direkten Zugriff auf dasselbe DB-Schema, sodass eine Änderung viele Teams bricht.
Kurze Checks, bevor Sie „production ready“ sagen
Release with confidence
Ship small changes with snapshots and rollback ready when real traffic surprises you.
„Production ready“ ist eine Menge von Entscheidungen, auf die Sie um 2 Uhr morgens zeigen können. Klarheit schlägt Cleverness.
Beginnen Sie damit, Ihre Sources of Truth zu benennen. Für jeden wichtigen Datentyp (Kunden, Subscriptions, Rechnungen, Berechtigungen) entscheiden Sie, wo der finale Datensatz lebt. Wenn Ihre App „Wahrheit“ aus zwei Orten liest, werden Sie irgendwann unterschiedlichen Nutzern unterschiedliche Antworten zeigen.
Schauen Sie sich dann Retries an. Gehen Sie davon aus, dass jede wichtige Aktion irgendwann doppelt ausgeführt wird. Wenn dieselbe Anfrage zweimal Ihr System erreicht, können Sie doppelte Abbuchungen, doppelte Sendungen oder doppelte Erstellungen vermeiden?
Eine kleine Checkliste, die die meisten schmerzhaften Fehler fängt:
- Für jeden Datentyp können Sie eine Source of Truth benennen und sagen, was abgeleitet ist.
- Jeder wichtige Schreibvorgang ist retry-sicher (Idempotency-Key oder Unique Constraint).
- Ihre Async-Arbeit kann nicht unbegrenzt wachsen (Sie überwachen Lag, ältestes Nachrichtalter und alarmieren, bevor Nutzer es bemerken).
- Sie haben einen Plan für Änderungen (reversibler Migrationspfad, Event-Versionierung).
- Sie können schnell rollbacken und wiederherstellen, weil Sie es geübt haben.
Nächste Schritte: eine Entscheidung nach der anderen treffen
Skalierung wird einfacher, wenn Sie Systemdesign als kurze Liste von Entscheidungen behandeln, nicht als Theoriestapel.
Schreiben Sie 3 bis 5 Entscheidungen auf, denen Sie im nächsten Monat gegenüberstehen, in einfacher Sprache: „Verschieben wir das Senden von E-Mails in einen Hintergrundjob?“ „Akzeptieren wir leicht veraltete Analytics?“ „Welche Aktionen müssen sofort konsistent sein?“ Verwenden Sie diese Liste, um Produkt und Engineering abzustimmen.
Wählen Sie dann einen Workflow, der derzeit synchron ist, und konvertieren Sie genau diesen in Async. Belege, Notifications, Reports und Datei-Verarbeitung sind häufige erste Schritte. Messen Sie zwei Dinge vor und nach der Änderung: nutzerwahrgenommene Latenz (fühlte sich die Seite schneller an?) und Fehlerverhalten (haben Retries Duplikate oder Verwirrung erzeugt?).
Wenn Sie diese Änderungen schnell prototypen wollen, kann Koder.ai (koder.ai) hilfreich sein, um an einem React + Go + PostgreSQL SaaS zu iterieren, während Snapshots und Rollback griffbereit bleiben. Die Messlatte bleibt einfach: shippe eine Verbesserung, lerne aus echtem Traffic und entscheide dann die nächste.