Was Sie bauen und für wen es gedacht ist
Sie bauen eine Web-App, die zwischen Ihrer API und den Konsumenten sitzt. Ihre Aufgabe ist es, API-Schlüssel auszustellen, zu kontrollieren, wie diese Schlüssel verwendet werden dürfen, und zu erklären, was passiert ist — so, dass es sowohl Entwickler als auch Nicht-Entwickler verstehen.
Mindestens beantwortet sie drei praktische Fragen:
- Wer ruft die API auf? (Welcher Kunde, welche App, welcher Schlüssel)
- Wie viel dürfen sie nutzen? (Quoten, Rate-Limits, Plan-Regeln)
- Wie viel haben sie tatsächlich genutzt? (Verlässliches Metering und Analytics)
Wenn Sie beim Portal und Admin-UI schnell vorankommen wollen, können Tools wie Koder.ai helfen, ein Produktions-fähiges Baseline-Produkt schnell zu prototypen und auszuliefern (React-Frontend + Go-Backend + PostgreSQL), während Sie trotzdem volle Kontrolle über den Code-Export, Snapshots/Rollbacks und Deployment/Hosting behalten.
Wer es nutzt
Eine Key-Management-App ist nicht nur für Ingenieure. Unterschiedliche Rollen kommen mit unterschiedlichen Zielen:
- Admins / Plattform-Besitzer wollen Policies erstellen (Limits, Zugangsebenen), Vorfälle schnell lösen und Kontrolle über viele Kunden behalten.
- Entwickler (Ihre Kunden oder interne Teams) wollen Self-Serve-Key-Erstellung, einfache Doku und schnelle Antworten, wenn etwas schiefgeht („Warum bekomme ich 429s?“).
- Finanz- und Support-Teams wollen Nutzungshistorie, Kunden-übersichten und Daten, die Rechnungen, Gutschriften oder Plan-Upgrades untermauern — ohne rohe Logs lesen zu müssen.
Kernmodule, die Sie wahrscheinlich brauchen
Die meisten erfolgreichen Implementierungen konvergieren auf ein paar Kernmodule:
- Keys: Schlüssel erstellen, benennen/taggen, Berechtigungen scopen, rotieren, widerrufen und „last used“ ansehen.
- Quoten & Rate-Limiting: Limits pro Schlüssel, pro Kunde, pro Endpoint definieren und konsistent durchsetzen.
- Usage-Metering: Request-Events (oder Zusammenfassungen) erfassen und in tägliche/monatliche Nutzung aggregieren.
- Analytics: Dashboards, die Nutzungstrends, Top-Endpoints, Fehler und Throttling erklären.
- Alerts: Benachrichtigen bei Nutzungsspitzen, fast erreichter Quote, Missbrauch von Schlüsseln oder Fehleranstiegen.
Umfang: einfach starten, dann erweitern
Ein starkes MVP fokussiert sich auf Key-Ausgabe + Basis-Limits + klare Nutzungsberichte. Erweiterte Features — wie automatisierte Plan-Upgrades, Abrechnungs-Workflows, Pro-Rata und komplexe Vertragsbedingungen — können später kommen, wenn Sie Metering und Enforcement vertrauen.
Ein praktischer „North Star“ für die erste Veröffentlichung: Es soll für jemanden einfach sein, einen Schlüssel zu erstellen, seine Limits zu verstehen und die Nutzung zu sehen, ohne ein Support-Ticket öffnen zu müssen.
Anforderungsliste (MVP vs Später)
Bevor Sie Code schreiben, entscheiden Sie, was „fertig“ für den ersten Release bedeutet. Dieses System wächst schnell: Abrechnung, Audits und Enterprise-Security tauchen früher auf, als Sie erwarten. Ein klares MVP hält Sie beim Ausliefern.
MVP: das Minimum, das echten Wert schafft
Mindestens sollten Nutzer Folgendes können:
- API-Schlüssel erstellen und widerrufen (mit Name/Label und optionaler Ablaufzeit)
- Quoten setzen (z. B. Anfragen/Tag oder Anfragen/Monat) pro Schlüssel oder Projekt
- Rate-Limiting durchsetzen (z. B. Anfragen/Minute) zum Schutz Ihrer API
- Nutzungsdiagramme sehen (einfache Tages-Totale, Top-Schlüssel und Fehlerquoten)
- Basis-Audit-Events verfolgen (Schlüssel erstellt/widerrufen, Quote geändert) für Support und Verantwortlichkeit
Wenn Sie keinen Schlüssel sicher ausgeben, limitieren und beweisen können, was er getan hat, ist es nicht bereit.
Nicht-funktionale Anforderungen, die Sie im Voraus entscheiden sollten
- Performance: Wie viele Requests/sec müssen Sie peak ohne Eventverlust meter können?
- Zuverlässigkeit: Brauchen Sie „nie Events verlieren“ oder ist „eventuelle Genauigkeit“ akzeptabel?
- Datenaufbewahrung: Wie lange bewahren Sie Roh-Events vs aggregierte Totale auf (z. B. 7 Tage roh, 13 Monate aggregiert)?
Tenant-Modell: Single Org vs Multi-Tenant
Wählen Sie früh:
- Single Org: schneller zu bauen, weniger Rollen-/Rechte-Kanten.
- Multi-Tenant SaaS: erfordert Tenant-Isolation, pro-Tenant-Quoten und Admin-Rollen von Anfang an.
„Später“-Features, für die sich Planung lohnt
Rotation-Flows, Webhook-Benachrichtigungen, Billing-Exports, SSO/SAML, Per-Endpoint-Quoten, Anomalie-Erkennung und reichhaltigere Audit-Logs.
Erfolgsmetriken (messbar machen)
- Zeit bis zur Schlüssel-Ausgabe: z. B. unter 2 Minuten vom Signup bis zum ersten Schlüssel
- Metering-Genauigkeit: z. B. <0.5% Abweichung zwischen Gateway-Zählungen und Aggregaten
- Support-Last: Weniger „Warum wurde ich geblockt?“-Tickets; klare Erklärungen zu Quoten/Rate-Limits
Architektur-Optionen auf hoher Ebene
Ihre Architekturwahl sollte mit einer Frage beginnen: Wo setzen Sie Zugriff und Limits durch? Diese Entscheidung beeinflusst Latenz, Zuverlässigkeit und wie schnell Sie liefern können.
Option 1: Durchsetzung am API-Gateway
Ein API-Gateway (managed oder self-hosted) kann API-Schlüssel validieren, Rate-Limits anwenden und Usage-Events aussenden, bevor Requests Ihre Services erreichen.
Das passt gut bei mehreren Backend-Services, wenn Sie konsistente Policies brauchen oder Enforcement aus der Anwendungslogik heraushalten möchten. Der Trade-off: Gateway-Konfiguration kann zu einem eigenen „Produkt“ werden und Debugging erfordert gutes Tracing.
Option 2: Durchsetzung am Reverse-Proxy
Ein Reverse-Proxy (z. B. NGINX/Envoy) kann Key-Checks und Rate-Limiting mit Plugins oder externen Auth-Hooks übernehmen.
Das funktioniert, wenn Sie eine leichte Edge-Schicht wollen, aber Geschäftsregeln (Pläne, per-Tenant-Quoten, Spezialfälle) lassen sich ohne zusätzliche Services schwer modellieren.
Option 3: Durchsetzung in der App-Middleware
Checks in Ihrer API-Anwendung (Middleware) zu platzieren ist in der Regel am schnellsten für ein MVP: eine Codebasis, ein Deploy, einfacheres lokales Testen.
Wenn Sie mehr Services hinzufügen, wird es kompliziert — Policy-Drift und Duplikation sind häufig — planen Sie also eine spätere Extraktion in eine gemeinsame Komponente oder Edge-Schicht.
Trennen Sie die Verantwortlichkeiten früh
Selbst wenn Sie klein starten, halten Sie Grenzen klar:
- Auth (Ist der Schlüssel gültig?), Quota/Rate-Limit (Ist es jetzt erlaubt?), Metering (Aufzeichnen, was passiert ist), Analytics-UI (Anzeigen davon).
Sync vs Async Tracking
Beim Metering entscheiden Sie, was im Request-Pfad passieren muss:
- Synchron: Zähler vor der Antwort inkrementieren (genaue Durchsetzung, höhere Latenz).
- Asynchron: Events in eine Warteschlange/Log schreiben (schnellere Requests, eventual consistency für Reports).
Planen Sie für Scale: Hot vs Cold Paths
Rate-Limit-Checks sind der Hot Path (optimieren Sie für geringe Latenz, In-Memory/Redis). Reports und Dashboards sind der Cold Path (optimieren Sie für flexible Abfragen und Batch-Aggregation).
Datenmodell für Keys, Quoten und Nutzung
Ein gutes Datenmodell trennt drei Belange: wer hat Zugriff, welche Limits gelten, und was ist tatsächlich passiert. Wenn Sie das richtig machen, werden Rotation, Dashboards und Abrechnung einfacher.
Kern-Entitäten (was Sie am ersten Tag brauchen)
Mindestens modellieren Sie diese Tabellen (oder Collections):
- Organization: die Tenant-Grenze (Billing-Owner, Mitglieder).
- Project/App: ein Container für Keys und Einstellungen (oft eine API-Client-Abbildung).
- API Key: Metadaten über ein Credential (Name, Status, created_at, last_used_at).
- Plan: ein Bündel aus Limits und Features (z. B. Free, Pro).
- Quota: die spezifischen Limit-Regeln (z. B. 10k requests/day, 60 req/min).
- Usage Event: das rohe Nutzungs-Record (timestamp, project_id, endpoint, status code, units).
Speichern Sie niemals rohe API-Token. Speichern Sie nur:
- Ein Key-Prefix (erste 6–8 Zeichen) zur Anzeige/Suche.
- Einen Verifier für das Token (typischerweise SHA-256 oder HMAC-SHA-256 mit einem serverseitigen Pepper über ein zufälliges 32–64 Byte Secret) zur Verifikation.
- Optional: Scopes, Environment (prod/sandbox) und expires_at.
So können Sie „Key: ab12cd…“ anzeigen und das tatsächliche Geheimnis unrecoverable halten.
Auditierbarkeit ist Pflicht
Fügen Sie früh Audit-Tabellen hinzu: KeyAudit und AdminAudit (oder ein einzelnes AuditLog) und erfassen Sie:
- actor_id (User/Service), action, target_type/id
- before/after (bei Quota-Änderungen)
- ip/user_agent, timestamp
Wenn ein Kunde fragt „Wer hat meinen Schlüssel widerrufen?“, haben Sie eine Antwort.
Zeitfenster und Zähler
Modellieren Sie Quoten mit expliziten Fenstern: per_minute, per_hour, per_day, per_month.
Speichern Sie Zähler in einer separaten Tabelle wie UsageCounter keyed by (project_id, window_start, window_type, metric). Das macht Resets vorhersehbar und hält Analytics-Abfragen schnell.
Für Portal-Ansichten können Sie Usage Events in tägliche Rollups aggregieren und auf /blog/usage-metering für tiefere Details verlinken.
Authentifizierung, Autorisierung und Rollen
Wenn Ihr Produkt API-Schlüssel und Nutzung verwaltet, muss der eigene Zugriffskontrollmechanismus strenger sein als bei einem typischen CRUD-Dashboard. Ein klares Rollenmodell hält Teams produktiv und verhindert, dass „jeder Admin ist“.
Rollen, die reale Teams abbilden
Starten Sie mit einer kleinen Menge Rollen pro Organisation (Tenant):
- Owner: volle Kontrolle, Billing-Verantwortung, kann Org-Einstellungen verwalten und die Org löschen.
- Admin: verwaltet Nutzer, Projekte, Keys, Quoten und Sicherheits-Einstellungen.
- Developer: kann Keys für zugewiesene Projekte erstellen/rotieren, Nutzung sehen, aber nicht Billing oder org-weite Security ändern.
- Read-only: kann Schlüssel (maskiert), Quoten und Analytics ansehen.
- Finance: kann Rechnungen/Nutzungs-Kostenberichte sehen und Daten exportieren, aber keine Keys verwalten.
Halten Sie Berechtigungen explizit (z. B. keys:rotate, quotas:update), damit Sie Features hinzufügen können, ohne Rollen neu zu erfinden.
Sicherer Login für Menschen
Nutzen Sie Username/Passwort nur wenn nötig; unterstützen Sie stattdessen OAuth/OIDC. SSO ist optional, aber MFA sollte für Owner/Admins Pflicht und für alle anderen dringend empfohlen werden.
Fügen Sie Sitzungs-Schutz hinzu: kurzlebige Access-Tokens, Refresh-Token-Rotation und Geräte-/Sitzungs-Management.
Authentifizierung für geschützte APIs
Bieten Sie einen Standard API-Key im Header an (z. B. Authorization: Bearer <key> oder X-API-Key). Für fortgeschrittene Kunden ergänzen Sie optional HMAC-Signierung (verhindert Replay/Tampering) oder JWT (gut für kurzlebigen, scope-beschränkten Zugriff). Dokumentieren Sie das klar im Entwicklerportal.
Tenant-Isolation: nicht verhandelbar
Durchsetzen Sie Isolation in jeder Abfrage: org_id überall. Verlassen Sie sich nicht allein auf UI-Filter — wenden Sie org_id in DB-Constraints, Row-Level-Policies (falls verfügbar) und Service-Layer-Checks an und schreiben Sie Tests, die Cross-Tenant-Zugriff versuchen.
API-Key-Lifecycle: Erstellen, Rotieren, Widerrufen
Entwirf zuerst das Datenmodell
Nutze den Planungsmodus, um Rollen, Limits und Datentabellen zu planen, bevor du Code generierst.
Ein guter Key-Lifecycle hält Kunden produktiv und gibt schnelle Möglichkeiten, Risiken zu reduzieren. Gestalten Sie UI und API so, dass der „Happy Path“ offensichtlich ist und sichere Optionen (Rotation, Ablauf) Standard werden.
Erstellen: Absicht erfassen, nicht nur eine Zeichenfolge
Im Erstellungsflow verlangen Sie einen Namen (z. B. „Prod server“, „Local dev“) sowie Scopes/Berechtigungen, damit der Schlüssel von Anfang an Least-Privilege hat.
Fügen Sie, wenn passend, optionale Einschränkungen wie allowed origins (für Browser-Nutzung) oder allowed IPs/CIDRs (für Server-zu-Server) hinzu. Halten Sie diese optional und warnen Sie klar vor Lockouts.
Nach der Erstellung zeigen Sie den Roh-Schlüssel nur einmal. Bieten Sie einen großen „Kopieren“-Button und leichte Hinweise: „In einem Secret-Manager speichern. Wir können ihn nicht erneut anzeigen.“ Verlinken Sie direkt zu Setup-Anleitungen wie /docs/auth.
Rotieren: zur Routine machen, nicht zum Zwischenfall
Rotation sollte einem vorhersehbaren Muster folgen:
- Erstellen Sie einen neuen Schlüssel mit denselben Scopes und Einschränkungen.
- Deployen/aktualisieren Sie die Integration, um den neuen Schlüssel zu nutzen.
- Verifizieren Sie, dass Traffic fließt.
- Widerrufen Sie den alten Schlüssel.
Bieten Sie in der UI eine „Rotate“-Aktion, die einen Ersatzschlüssel erstellt und den vorherigen als „Pending revoke“ markiert, um Cleanup zu fördern.
Widerrufen und Ablauf: sofortig und geplant
Widerruf sollte den Schlüssel sofort deaktivieren und protokollieren, wer es getan hat und warum.
Unterstützen Sie auch geplante Expires (z. B. 30/60/90 Tage) und manuelle „expires on“-Daten für temporäre Auftragnehmer oder Trials. Abgelaufene Schlüssel sollten mit einem klaren Auth-Fehler fehlschlagen, damit Entwickler wissen, was zu beheben ist.
Quoten und Rate-Limiting: Wie Nutzung durchgesetzt wird
Rate-Limits und Quoten lösen unterschiedliche Probleme; sie zu vermischen ist eine häufige Ursache für verwirrte Support-Anfragen „Warum wurde ich blockiert?".
Rate-Limits vs Quoten
Rate-Limits kontrollieren Bursts (z. B. „nicht mehr als 50 req/s“). Sie schützen Infrastruktur und verhindern, dass ein lauter Kunde alle anderen beeinträchtigt.
Quoten begrenzen die Gesamt-Nutzung über einen Zeitraum (z. B. „100.000 Anfragen pro Monat“). Sie dienen Fairness, Preisgestaltung und Abrechnung.
Viele Produkte nutzen beides: eine monatliche Quote für Fairness und Preis, plus ein per-Sekunde/Minute Rate-Limit für Stabilität.
Wählen Sie einen Durchsetzungsalgorithmus
Für Echtzeit-Rate-Limiting wählen Sie einen Algorithmus, den Sie erklären und zuverlässig implementieren können:
- Token Bucket: Tokens füllen sich über die Zeit auf; jede Anfrage verbraucht ein Token. Gut, um kleine Bursts zu erlauben und gleichzeitig eine durchschnittliche Rate einzuhalten.
- Leaky Bucket: Anfragen „tropfen“ mit konstanter Rate. Glättet Traffic, kann aber strenger wirken.
Token Bucket ist meist die bessere Default-Wahl für developer-facing APIs, da es vorhersehbar und nachsichtig ist.
Wo Zähler leben sollten
Sie brauchen typischerweise zwei Stores:
- Redis (oder ähnliches) für schnelle, atomare Echtzeit-Checks am Gateway/Edge.
- Ihre Datenbank für dauerhafte Reports und billing-grade History.
Redis beantwortet „Kann diese Anfrage jetzt laufen?" Die DB beantwortet „Wie viel haben sie diesen Monat genutzt?".
Definieren Sie, was als Nutzung zählt
Seien Sie pro Produkt und Endpoint explizit. Gängige Metriken sind Requests, Tokens, übertragene Bytes, endpoint-spezifische Gewichte oder Compute-Zeit.
Wenn Sie gewichtete Endpoints verwenden, veröffentlichen Sie die Gewichte in Ihrer Doku und im Portal.
Machen Sie Fehlerantworten handlungsfähig
Beim Blockieren einer Anfrage geben Sie klare, konsistente Fehler zurück:
- 429 Too Many Requests für Rate-Limits. Fügen Sie
Retry-After und optional Header wie X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset hinzu.
- 402 Payment Required (oder 403) für Über-Quota-Zugriff in bezahlten Plänen. Geben Sie den aktuellen Periodenverbrauch, das Quota-Limit und einen Link zu /billing oder /pricing mit.
Gute Meldungen reduzieren Churn: Entwickler können backoffen, Retries ergänzen oder upgraden, ohne zu raten.
Usage-Metering: Events sammeln und aggregieren
Usage-Metering ist die „Quelle der Wahrheit“ für Quoten, Rechnungen und Kundenvertrauen. Das Ziel ist einfach: Zählen, was passiert ist, konsistent, ohne Ihre API zu verlangsamen.
Was pro Request geloggt werden sollte (und was nicht)
Für jede Anfrage erfassen Sie eine kleine, vorhersagbare Event-Payload:
- timestamp (Serverzeit)
- key_id (oder Token-Identifier)
- endpoint (Routenname, nicht die komplette URL)
- status (z. B. 200, 401, 429)
- units (wie viel zu zählen ist: 1 Request, Tokens, Bytes, etc.)
Vermeiden Sie das Loggen von Request-/Response-Bodies. Reduzieren Sie sensible Header standardmäßig (Authorization, Cookies) und behandeln Sie PII als „opt-in mit begründetem Bedarf“. Wenn Sie etwas fürs Debugging loggen müssen, speichern Sie es separat mit kürzerer Aufbewahrung und strengen Zugriffsregeln.
Halten Sie die API schnell mit einer Event-Pipeline
Aggregieren Sie Metriken nicht inline während der Anfrage. Stattdessen:
- Die API schreibt ein Event in eine Queue/Stream (oder eine leichte append-only Tabelle).
- Ein Worker konsumiert Events und aktualisiert Tages-/Stunden-Aggregate.
Das hält die Latenz stabil, auch bei Traffic-Spitzen.
Idempotenz, Retries und Doppelzählungen
Queues können Nachrichten mehr als einmal zustellen. Fügen Sie eine eindeutige event_id hinzu und erzwingen Sie Deduplizierung (z. B. Unique-Constraint oder „seen“-Cache mit TTL). Worker sollten retry-sicher sein, sodass ein Absturz die Totale nicht kaputtmacht.
Aufbewahrung: roh kurzfristig, Aggregates langfristig
Bewahren Sie Roh-Events kurz (Tage/Wochen) für Audits und Untersuchungen. Bewahren Sie aggregierte Metriken deutlich länger (Monate/Jahre) für Trends, Quota-Durchsetzung und Abrechnungsreife.
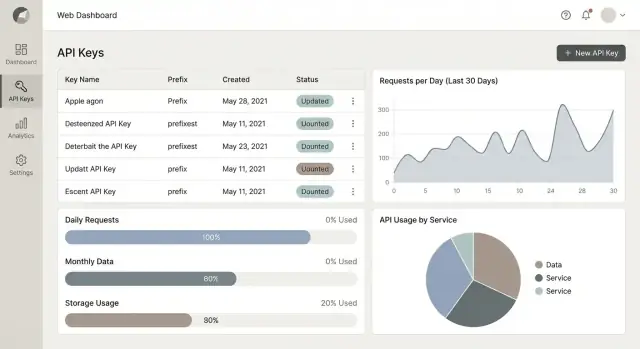
Analytics-Dashboards, die Menschen tatsächlich nutzen
Von der Checkliste zur App
Wandle deine Anforderungsliste in eine funktionierende Basis um, die du anpassen kannst.
Ein Nutzungs-Dashboard sollte keine „netten Diagramme“-Seite sein. Es sollte zwei Fragen schnell beantworten: Was hat sich geändert? und Was sollte ich als Nächstes tun? Entwerfen Sie für Entscheidungen — Debugging von Spitzen, Vermeidung von Übernutzung und Nachweis des Kundenwerts.
Kernansichten, die Sie zuerst ausliefern sollten
Starten Sie mit vier Panels, die alltägliche Bedürfnisse abdecken:
- Nutzung über Zeit (Requests/Tag oder Requests/Min), mit klarem Vergleich zur Vorperiode.
- Top-Endpoints (nach Volumen und nach Kosten/Gewicht, falls gewichtet).
- Fehlerquote (4xx vs 5xx), damit Teams Client-Fehler von Service-Problemen trennen können.
- Latenz (optional) p50/p95; nur aufnehmen, wenn Sie sie zuverlässig messen können.
Machen Sie es handlungsfähig, nicht dekorativ
Jedes Diagramm sollte mit einem nächsten Schritt verknüpft sein. Zeigen Sie:
- Verbleibende Quote für den aktuellen Zyklus (z. B. „18.200 von 50.000 übrig“)
- Prognostizierte Nutzung beim aktuellen Tempo, mit einfacher Kennzeichnung „wird überschritten / bleibt im Rahmen"
Wenn ein Überschreiten wahrscheinlich ist, verlinken Sie direkt zum Upgrade-Pfad: /plans (oder /pricing).
Filter, die zur Arbeitsweise passen
Fügen Sie Filter hinzu, die Untersuchungen ohne komplexe Query-Builder vereinfachen:
- Zeitbereich (letzte 24h, 7d, 30d, benutzerdefiniert)
- API-Schlüssel, Projekt, Environment (prod/staging)
- Endpoint und Status-Code-Familie
Export und API-Zugriff
Bieten Sie CSV-Downloads für Finance und Support an und stellen Sie eine leichte Metrics-API bereit (z. B. GET /api/metrics/usage?from=...&to=...&key_id=...), damit Kunden Nutzung in ihre eigenen BI-Tools ziehen können.
Alerts, Benachrichtigungen und Billing-Readiness
Alerts sind der Unterschied zwischen „wir haben ein Problem bemerkt“ und „Kunden haben es zuerst bemerkt“. Entwerfen Sie sie rund um die Fragen, die Nutzer unter Druck stellen: Was ist passiert? Wer ist betroffen? Was ist der nächste Schritt?
Worauf Sie alerten sollten (und wann)
Starten Sie mit vorhersehbaren Schwellen, die an Quoten gebunden sind. Ein einfaches Muster: 50% / 80% / 100% der Quota-Nutzung innerhalb eines Abrechnungszeitraums.
Fügen Sie ein paar High-Signal-Behavioral-Alerts hinzu:
- Ungewöhnliche Spitzen: Nutzung, die deutlich vom jüngsten Baseline des Tenants abweicht (z. B. 3× stündlicher Durchschnitt)
- Authentifizierungsfehler: plötzlicher Anstieg ungültiger API-Key-Versuche oder Signaturfehler
- Rate-Limit-Druck: anhaltende Throttling-Events, die auf einen falsch konfigurierten Client hindeuten
Halten Sie Alerts handlungsfähig: Tenant, API-Key/App, Endpoint-Gruppe (falls vorhanden), Zeitfenster und ein Link zur relevanten Ansicht im Portal (z. B. /dashboard/usage).
Benachrichtigungskanäle
E-Mail ist die Basis, weil jeder sie hat. Fügen Sie Webhooks für Teams hinzu, die Alerts in eigene Systeme leiten wollen. Wenn Sie Slack unterstützen, behandeln Sie es als optional und halten Sie das Setup leichtgewichtig.
Eine praktische Regel: Bieten Sie eine pro-Tenant Benachrichtigungs-Policy — wer welche Alerts bei welcher Schwere erhält.
Einfache Nutzungsberichte, die gelesen werden
Bieten Sie eine tägliche/wöchentliche Zusammenfassung an, die Gesamt-Requests, Top-Endpoints, Fehler, Throttles und „Veränderung vs Vorperiode“ hervorhebt. Stakeholder wollen Trends, keine rohen Logs.
Billing-Readiness ohne sofortige Abrechnung
Auch wenn Abrechnung „später“ kommt, speichern Sie:
- Plan-Historie (welcher Plan ein Tenant wann hatte)
- Preis-Effekt-Daten (Pricing-Effekt-Daten), damit Neuberechnungen konsistent sind
So können Sie Rechnungen oder Previews nachträglich erstellen, ohne Ihr Datenmodell umzubauen.
Klare Messaging-Vorlage
Jede Nachricht sollte sagen: Was ist passiert, Auswirkung und nächster Schritt (Schlüssel rotieren, Plan upgraden, Client untersuchen oder Support kontaktieren via /support).
Sicherheits- und Compliance-Basics
Build-Kosten reduzieren
Erhalte Credits, indem du Inhalte über Koder.ai erstellst oder Kollegen zur Nutzung empfiehlst.
Sicherheit bei einer API-Key-Management-App ist weniger Fancy-Features und mehr sorgsame Defaults. Behandeln Sie jeden Schlüssel als Credential und gehen Sie davon aus, dass er irgendwann an die falsche Stelle kopiert wird.
API-Schlüssel schützen
Speichern Sie niemals Schlüssel im Klartext. Speichern Sie einen Verifier aus dem Geheimnis (typischerweise SHA-256 oder HMAC-SHA-256 mit serverseitigem Pepper) und zeigen Sie dem Nutzer das vollständige Geheimnis nur einmal bei der Erstellung.
In UI und Logs zeigen Sie nur ein nicht-sensitives Präfix (z. B. ak_live_9F3K…), sodass Menschen einen Schlüssel identifizieren können, ohne ihn preiszugeben.
Bieten Sie praktische Hinweise zum „Secret Scanning“: Erinnern Sie Nutzer daran, Schlüssel nicht in Git zu committen, und verlinken Sie auf Tooling-Doku (z. B. GitHub secret scanning) im Portal unter /docs.
Admin-Schutzmaßnahmen (oft übersehen)
Angreifer lieben Admin-Endpunkte, weil sie Schlüssel erstellen, Quoten erhöhen oder Limits deaktivieren können. Wenden Sie Rate-Limits auch auf Admin-APIs an und erwägen Sie eine IP-Allowlist-Option für Admin-Zugriffe (nützlich für interne Teams).
Verwenden Sie Least Privilege: Rollen trennen (Viewer vs Admin) und beschränken Sie, wer Quoten ändern oder Schlüssel rotieren darf.
Audit-Logs und Aufbewahrung
Protokollieren Sie Audit-Events für Schlüssel-Erstellung, Rotation, Widerruf, Login-Versuche und Quota-Änderungen. Halten Sie Logs manipulationssicher (append-only Storage, eingeschränkter Schreibzugang und regelmäßige Backups).
Führen Sie Compliance-Basics früh ein: Datenminimierung (nur nötiges speichern), klare Retention-Controls (Auto-Delete alter Logs) und dokumentierte Zugriffsregeln.
Bedrohungsszenarien, für die Sie designen sollten
Key-Leakage, Replay-Abuse, Scraping Ihres Portals und „noisy neighbor“ Tenants, die gemeinsam genutzte Kapazität verbrauchen. Gestalten Sie Gegenmaßnahmen (Hashing/Verifiers, kurzlebige Tokens wo möglich, Rate-Limits und per-Tenant-Quoten) um diese Realitäten.
Admin- und Entwickler-Portal UX
Ein großartiges Portal macht den „sicheren Pfad“ zum einfachsten Pfad: Admins können schnell Risiko reduzieren, Entwickler bekommen einen funktionierenden Schlüssel und einen erfolgreichen Test-Call ohne jemanden anmailen zu müssen.
Admin-UX: Geschwindigkeit, Kontrolle und Vertrauen
Admins kommen oft mit dringenden Aufgaben („Widerrufe diesen Schlüssel jetzt“, „Wer hat das erstellt?“, „Warum ist die Nutzung gestiegen?“). Entwerfen Sie für schnelles Scannen und entschlossene Aktionen.
Nutzen Sie Quick Search, die über Key-ID-Präfixe, App-Namen, Nutzer und Workspace/Org-Namen hinweg funktioniert. Kombinieren Sie das mit klaren Status-Indikatoren (Active, Expired, Revoked, Compromised, Rotating) und Zeitstempeln wie „last used“ und „created by“. Diese Felder allein verhindern viele versehentliche Widerrufe.
Für Massen-Operationen bieten Sie Bulk Actions mit Sicherheitsmechanismen: Bulk-Revoke, Bulk-Rotate, Bulk-Quota-Änderung. Zeigen Sie stets einen Bestätigungsschritt mit einer Zusammenfassung („38 Keys werden widerrufen; 12 wurden in den letzten 24h genutzt").
Bieten Sie ein auditfreundliches Detailpanel pro Schlüssel: Scopes, zugehörige App, erlaubte IPs (falls vorhanden), Quota-Tier und jüngste Fehler.
Developer-UX: Erfolg sofort ermöglichen
Entwickler wollen kopieren, einfügen und weitermachen. Platzieren Sie klare Dokus neben dem Key-Erstellungsflow, nicht versteckt.
Bieten Sie kopierbare curl-Beispiele und einen Sprachschalter (curl, JS, Python), wenn möglich.
Zeigen Sie den Schlüssel einmal mit einem „Kopieren“-Button und einem kurzen Hinweis zur Speicherung. Führen Sie dann durch einen „Test-Call“-Schritt, der einen echten Request gegen ein Sandbox- oder Low-Risk-Endpoint ausführt. Falls er fehlschlägt, liefern Sie Fehlererklärungen in einfachem Deutsch mit üblichen Fixes:
- „Invalid key“ → Header-Name und Whitespace prüfen
- „Forbidden“ → fehlender Scope/Rolle
- „Rate limited“ → Quoten prüfen und
Retry-After beachten
Self-Serve Onboarding in Minuten
Ein einfacher Pfad funktioniert am besten: Erstelle ersten Schlüssel → mache einen Test-Call → sieh Nutzung. Selbst ein kleines Nutzungsdiagramm („Letzte 15 Minuten") schafft Vertrauen, dass Metering funktioniert.
Verlinken Sie direkt zu relevanten Seiten mit relativen Routen wie /docs, /keys und /usage.
Barrierefreiheit und Klarheit
Verwenden Sie klare Labels („Requests per minute“, „Monthly requests") und halten Sie Einheiten konsistent. Fügen Sie Tooltips für Begriffe wie „Scope“ und „Burst“ hinzu. Stellen Sie Tastatur-Navigation, sichtbare Fokuszustände und ausreichenden Kontrast sicher — besonders bei Status-Badges und Fehlerbannern.
Deployment, Monitoring und Testing
Das In-Produktion-Bringen dieses Systems ist vor allem Disziplin: vorhersehbare Deploys, klare Sichtbarkeit bei Fehlern und Tests, die sich auf die „Hot Paths“ (Auth, Rate-Checks, Metering) konzentrieren.
Deployment-Setup (Secrets, Env-Vars, Migrations)
Halten Sie Konfiguration explizit. Lagern Sie nicht-sensible Einstellungen in Environment-Variablen (z. B. Rate-Limit-Defaults, Queue-Namen, Retention-Windows) und verwahren Sie Secrets in einem Managed-Store (AWS Secrets Manager, GCP Secret Manager, Vault). Vermeiden Sie, Secrets in Images einzubrennen.
Führen Sie DB-Migrationen als festen Schritt in Ihrer Pipeline aus. Bevorzugen Sie eine „migrate then deploy“-Strategie für abwärtskompatible Änderungen und planen Sie sichere Rollbacks (Feature-Flags helfen). Wenn Sie multi-tenant sind, fügen Sie Sanity-Checks hinzu, um Migrationen zu verhindern, die versehentlich alle Tenant-Tabellen scannen.
Wenn Sie das System mit Koder.ai bauen, können Snapshots und Rollbacks ein praktisches Sicherheitsnetz für frühe Iterationen sein (besonders während Sie Enforcement-Logik und Schema-Grenzen verfeinern).
Observability, die echte Fragen beantwortet
Sie benötigen drei Signale: Logs, Metriken und Traces. Instrumentieren Sie Rate-Limiting und Quota-Enforcement mit Metriken wie:
- Erlaubte vs abgelehnte Requests (nach API-Key, Endpoint und Tenant)
- „Reason Codes" für Ablehnungen (rate limit, quota exceeded, invalid key)
- Metering-Pipeline-Lag (Event-Ingest → Aggregation-Delay)
Erstellen Sie ein Dashboard speziell für Rate-Limit-Rejects, damit Support ohne Raten beantworten kann „Warum fällt mein Traffic aus?". Tracing hilft, langsame Abhängigkeiten auf dem kritischen Pfad zu finden (DB-Lookups für Key-Status, Cache-Misses etc.).
Backups und Recovery-Prioritäten
Behandeln Sie Konfigurationsdaten (Keys, Quoten, Rollen) als hochprioritär und Usage-Events als hochvolumig. Sichern Sie Konfiguration häufig mit Point-in-Time-Recovery.
Für Nutzungsdaten fokussieren Sie auf Haltbarkeit und Replay: ein Write-Ahead-Log/Queue plus Re-Aggregation ist oft praktikabler als häufige Voll-Backups.
Test- und Rollout-Plan
Unit-testen Sie Limit-Logik (Edge-Cases: Fenstergrenzen, konkurrierende Requests, Schlüsselrotation). Load-Tests auf den heißesten Pfaden: Key-Validierung + Zähler-Updates.
Rollen Sie dann phasenweise aus: interne Nutzer → begrenzte Beta (ausgewählte Tenants) → GA, mit einem Kill-Switch, um Enforcement bei Bedarf zu deaktivieren.