02. Juni 2025·8 Min
Web‑App zur Verwaltung teamübergreifender Kommunikationsanfragen
Lerne, wie du eine Web‑App planst, gestaltest und entwickelst, die teamübergreifende Kommunikationsanfragen erfasst, weiterleitet und nachverfolgt – mit klarer Zuständigkeit, Status und SLAs.
Problem und Umfang definieren
Bevor du etwas baust, sei konkret über das, was du lösen willst. „Teamübergreifende Kommunikation“ kann alles bedeuten – von einer schnellen Slack‑Nachricht bis zur kompletten Produktlaunch‑Ankündigung. Wenn der Umfang unklar ist, wird die App entweder zum Ablageort für alles Mögliche – oder niemand nutzt sie.
Was ist hier eine „Kommunikationsanfrage"?
Schreibe eine einfache Definition, die sich leicht merken lässt, sowie ein paar Beispiele und Nicht‑Beispiele. Typische Anfragetypen sind:
- Kundenorientierte Ankündigungen (Wartung, Richtlinienänderungen)
- Freigaben für Support‑Antworten in sensiblen Fällen
- Release‑Notes und Changelogs
- Sales‑Enablement‑Updates (neue Preise, Positionierung)
- Stellungnahmen mit Executive‑ oder Rechtsprüfung
Dokumentiere außerdem, was nicht dazugehört (z. B. Ad‑hoc‑Brainstorming, allgemeine FYI‑Updates oder „kannst du kurz anrufen?“). Eine klare Abgrenzung verhindert, dass das System zur allgemeinen Inbox wird.
Wer ist beteiligt und welche Rolle haben sie?
Liste die Teams auf, die mit Anfragen zu tun haben, und die jeweilige Verantwortung:
- Anfragende Person (reicht den Bedarf ein, liefert Kontext und Assets)
- Freigeber / Approver (bestätigt Priorität, Risiko, Compliance und Messaging)
- Ausführende Person (erstellt/produziert den Inhalt, veröffentlicht oder sendet ihn)
- Reviewer (abschließende Prüfung auf Genauigkeit, Ton und Marke)
Wenn eine Rolle je nach Anfragetyp variiert (z. B. nur bei bestimmten Themen Legal), halte das jetzt fest — das steuert später die Routing‑Regeln.
Woran erkennst du, dass es funktioniert?
Wähle ein paar messbare Ergebnisse, z. B.:
- Weniger „any update?“‑Nachfragen im Chat
- Schnellere Durchlaufzeit von Einreichung bis Veröffentlichung
- Weniger verpasste oder doppelte Anfragen
Schreibe abschließend die aktuellen Schmerzpunkte klar auf: unklare Zuständigkeit, fehlende Infos, Last‑Minute‑Anfragen und Anfragen in DMs. Das ist dein Ausgangswert und deine Begründung für die Änderung.
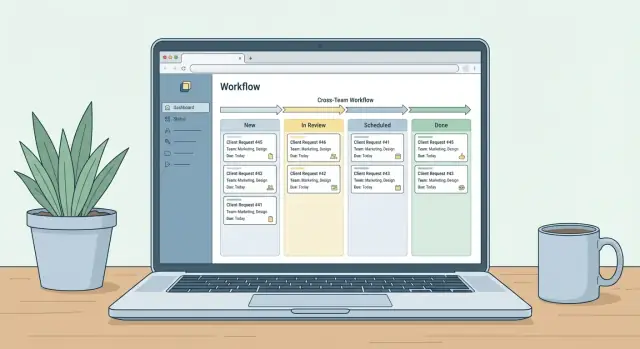
Workflow und User Stories abbilden
Bevor du baust, stimme dich mit den Stakeholdern darüber ab, wie eine Anfrage von „jemand braucht Hilfe“ zu „Arbeit geliefert“ gelangt. Eine einfache Workflow‑Karte verhindert unnötige Komplexität und zeigt, wo Übergaben oft scheitern.
User Stories (konkret halten)
Hier sind fünf Starter‑Stories, die du anpassen kannst:
- Als Anfragende Person möchte ich eine kurze Zusammenfassung einreichen und sofort sehen, wer zuständig ist und wann ich ein Datum erwarten kann.
- Als Triage‑Verantwortliche:r möchte ich schnell die Anfrage validieren, eine Follow‑up‑Frage stellen oder sie mit klarer Begründung ablehnen können.
- Als Approver möchte ich die Anfrage prüfen, genehmigen/ablehnen und einen Kommentar hinterlassen können, der Teil des Protokolls wird.
- Als Planer/Publisher möchte ich genehmigte Arbeiten in einen Kalender eintragen, Konflikte erkennen und das Veröffentlichungsdatum bestätigen können.
- Als Stakeholder möchte ich Status und Updates verfolgen, ohne Leute im Chat hinterherlaufen zu müssen.
Lebenszyklus der Anfrage abbilden
Ein verbreiteter Lebenszyklus für eine Management‑Web‑App für teamübergreifende Kommunikationsanfragen sieht so aus:
einreichen → Triage → Prüfung → Genehmigung → Planung → Veröffentlichung → Abschluss
Für jeden Schritt notiere:
- Eintrittskriterien (was wahr sein muss, um zu starten)
- Owner (Person oder Rolle)
- Erwartetes Ergebnis (was „fertig“ bedeutet)
- Erlaubte Ausgänge (voran, zur Überarbeitung zurück, ablehnen)
Konfigurierbare vs. feste Entscheidungen
Mach diese konfigurierbar: Teams, Kategorien, Prioritäten und Intake‑Fragen pro Kategorie. Behalte zunächst fest: die Kernstatus und die Definition von „geschlossen“. Zu viel Konfigurierbarkeit am Anfang erschwert Reporting und Schulung.
Risikoreiche Schritte besonders durchdenken
Achte auf Schwachstellen: blockierte Genehmigungen, Planungskonflikte zwischen Kanälen und Compliance/Legal‑Prüfungen, die Prüfpfade und strikte Zuständigkeiten brauchen. Diese Risiken sollten direkt dein Workflow‑Design und die Status‑Übergänge beeinflussen.
Das Intake‑Formular gestalten (die richtigen Infos gleich erfassen)
Eine Anfragen‑App funktioniert nur, wenn das Intake‑Formular konsequent ein brauchbares Briefing liefert. Ziel ist nicht, alles zu erfragen – sondern die richtigen Dinge, damit dein Team nicht Tage mit Rückfragen verbringt.
Beginne mit dem minimal brauchbaren Briefing
Halte den ersten Bildschirm schlank. Sammle mindestens:
- Anfragetitel (Ein‑Satz‑Zusammenfassung)
- Beschreibung (was gebraucht wird und warum)
- Zielgruppe (wer das erhalten soll)
- Kanal (E‑Mail, In‑App, Social, Presse etc.)
- Gewünschtes Datum (wann es raus muss)
- Anhänge (Entwurfstext, kreatives Material, Screenshots, Rechtsnotizen)
Füge unter jedem Feld kurze Hilfetexte hinzu, z. B.: „Zielgruppe Beispiel: ‚Alle US‑Kunden im Pro‑Plan‘.“ Diese Mikro‑Beispiele reduzieren Rückfragen mehr als lange Guidelines.
Nützliche Felder, die Nacharbeit verhindern
Wenn die Basis stabil ist, ergänze Felder, die Priorisierung und Koordination erleichtern:
- Priorität (z. B. Niedrig/Mittel/Hoch)
- Business‑Impact (was sich ändert, wenn es nicht rausgeht)
- Links (PRD, Jira‑Ticket, Analytics, Brand‑Dokument)
- Stakeholder (Freigeber und zu Informierende)
- Sprache/Region (falls Lokalisierung oder regionale Regeln gelten)
Bedingte Fragen nutzen, um kurz und gründlich zu bleiben
Bedingte Logik hält das Formular leichtgewichtig. Beispiele:
- Wenn Kanal = Presse, frage nach Sprecher, Embargo‑Datum und Medienliste.
- Wenn Zielgruppe Kunden enthält, frage nach Segmentierungskriterien und Support‑Bereitschaft.
Auf Vollständigkeit prüfen (ohne zu nerven)
Verwende klare Validierungsregeln: Pflichtfelder, Datum darf nicht in der Vergangenheit liegen, Anhänge erforderlich bei „Hoch“‑Priorität und Mindestzeichenanzahl für die Beschreibung.
Wenn du eine Einreichung zurückweist, gib konkrete Anweisungen zurück (z. B. „Füge Zielgruppe und Link zum Quell‑Ticket hinzu“), damit Anfragende mit der Zeit den erwarteten Standard lernen.
Status, Zuständigkeit und klare Regeln festlegen
Eine Anfragen‑Management‑Web‑App funktioniert nur, wenn alle dem Status vertrauen. Die App muss die einzige Wahrheit sein – nicht ein „echter Status“, der in Nebengesprächen, DMs oder E‑Mails lebt.
Einfache, gemeinsam genutzte Status definieren
Halte Status wenige, eindeutig und an Aktionen gebunden. Ein praktisches Default‑Set für teamübergreifende Kommunikationsanfragen ist:
- Neu — eingereicht und wartet auf Triage
- Mehr Infos benötigt — blockiert, bis die anfragende Person fehlende Details liefert
- In Prüfung — wird auf Machbarkeit, Priorität oder Policy geprüft
- Genehmigt — akzeptiert und bereit zur Planung
- Geplant — einem Zeitpunkt oder Sprint zugewiesen
- Erledigt — geliefert und geschlossen
- Abgelehnt — mit Begründung abgelehnt
Der Schlüssel ist, dass jeder Status beantwortet: Was passiert als Nächstes und wer wartet auf wen?
Zuständigkeiten pro Schritt zuweisen (damit nichts schwebt)
Jeder Status sollte eine klare „Owner“‑Rolle haben:
- Triage‑Verantwortliche:r (häufig rotierender Bereitschaftsdienst) sorgt dafür, dass jede Neu eingegangene Anfrage schnell bearbeitet wird.
- Approver trifft die Go/No‑Go‑Entscheidung während In Prüfung.
- Zuständige Person/Assignee ist verantwortlich für die Umsetzung nach Genehmigt/Geplant.
Zuständigkeit verhindert den häufigen Fehler, dass „alle beteiligt sind“, aber niemand verantwortlich ist.
Regeln schreiben, die Statuschaos verhindern
Füge leichte Regeln direkt in die App ein:
- Wer kann eine Anfrage verschieben (z. B. nur Triage kann aus Neu herausbewegen; nur Approver können Genehmigt/Abgelehnt setzen).
- Wann sie wieder geöffnet werden kann (z. B. Wiederöffnung aus Erledigt nur innerhalb von 14 Tagen und mit Begründung).
- Was für den Übergang erforderlich ist (z. B. für Geplant ist ein Datum erforderlich; für Abgelehnt eine Begründung verpflichtend).
Diese Regeln halten das Reporting akkurat, verringern Rückfragen und machen Übergaben berechenbar.
Datenmodell und wichtige Felder planen
Ein klares Datenmodell hält dein Anfragensystem flexibel, wenn neue Teams, Anfragetypen und Genehmigungsstufen hinzukommen. Strebe eine kleine Menge Kern‑Tabellen an, die viele Workflows unterstützen, statt für jedes Team ein neues Schema zu schaffen.
Kern‑Tabellen (einfach starten)
Mindestens planen:
- Users: Name, E‑Mail, Rolle, Active‑Flag
- Teams: Teamname, standardmäßige SLA‑Policy, Routing‑Regeln
- Requests: das eigentliche „Ticket“ (Details weiter unten)
- Comments: Threaded‑Diskussionen zur Anfrage
- Attachments: Dateien oder Links mit Uploader und Zeitstempel
- StatusHistory: jede Statusänderung (idealerweise auch Owner‑Wechsel)
Diese Struktur unterstützt Übergaben zwischen Teams und erleichtert Reporting deutlich mehr, als nur den aktuellen Zustand zu speichern.
Wichtige Felder im Request‑Datensatz
Deine Requests‑Tabelle sollte Routing und Verantwortlichkeit abbilden:
- requesting_team und/oder requester_user
- category (Kampagne, Ankündigung, Presse, Rechtsprüfung etc.)
- priority (oder Impact/Urgency)
- due_date (was die anfragende Person benötigt)
- sla_target_at (berechnete Deadline basierend auf SLA‑Policy)
- current_status
- current_owner_user (oder Owner‑Team + Zuständige Person)
Ziehe außerdem in Betracht: Zusammenfassung/Titel, Beschreibung, gewünschte Kanäle (E‑Mail, Slack, Intranet) und erforderliche Assets.
Tags + Suche für echtes Filtern
Füge Tags (Many‑to‑Many) und ein searchable_text‑Feld (oder indexierte Spalten) hinzu, damit Teams Queues schnell filtern und Trends berichten können (z. B. „product‑launch“ oder „executive‑urgent").
Auditierbarkeit ist kein Luxus
Plane Auditbedarf von Anfang an:
- Speichere created_at / updated_at / closed_at‑Zeitstempel
- Halte StatusHistory mit wer was wann geändert hat
- Bewahre vorherige Werte für kritische Felder (Status, Owner, Termine)
Wenn Stakeholder fragen „Warum war das verspätet?“, hast du eine klare Antwort ohne Durchforsten von Chat‑Logs.
Hauptbildschirme und Navigation gestalten
Plane, bevor du generierst
Lege Status, Zuständigkeitsregeln und SLAs fest, bevor du die ersten Bildschirme erzeugst.
Gute Navigation ist kein Schmuckstück — sie verhindert, dass „Wo schaue ich das nach?“ die eigentliche Arbeit wird. Gestalte Ansichten um die Rollen, die Menschen natürlich in Anfragenarbeit einnehmen, und halte jede Ansicht auf die nächste Aktion fokussiert.
Ansicht für Anfragende (einreichen und nachverfolgen)
Die Erfahrung für Anfragende sollte sich anfühlen wie Paketverfolgung: klar, ruhig und immer aktuell. Nach der Einreichung zeige eine Einzelseiten‑Ansicht mit Status, Owner, Zielterminen und dem nächsten erwarteten Schritt.
Mach es einfach, zu:
- Eine Anfrage einzureichen und Anhänge hochzuladen
- Fortschritt über die Zeit zu sehen (eine einfache Timeline reicht)
- Schnell auf Mehr Infos benötigt zu antworten mit Kommentaren/Dateien
- Updates zu erhalten, ohne sie suchen zu müssen (E‑Mail + In‑App)
Triage‑Ansicht (Warteschlange und Entscheidungen)
Das ist der Kontrollraum. Standardmäßig eine Queue‑Ansicht mit Filtern (Team, Kategorie, Status, Priorität) und Massenaktionen.
Enthalten sein sollten:
- Eine priorisierte Warteschlange mit Sichtbarkeit „Zeit im Status"
- Schnell‑Assign und Reassign
- Duplikaterkennung (Match auf Titel + Anfragende Person + Links)
- Prioritäts‑ und Fälligkeitskontrollen ohne Öffnen jeder Anfrage
Ausführenden‑Ansicht (Arbeit erledigen)
Ausführende brauchen einen persönlichen Arbeitsbildschirm: „Was ist meins, was ist als Nächstes, was ist gefährdet?“ Zeige anstehende Deadlines, Abhängigkeiten und eine Asset‑Checkliste, um Rückfragen zu vermeiden.
Admin‑Ansicht (konfigurieren ohne den Fluss zu brechen)
Admins sollten Teams, Kategorien, Berechtigungen und SLAs an einem Einstellungsort verwalten können. Halte erweiterte Optionen einen Klick entfernt und biete sichere Defaults.
Konsistente Navigation
Nutze eine linke Navigation (oder Top‑Tabs), die rollenbasierte Bereiche abbildet: Anfragen, Queue, Meine Arbeit, Reports, Einstellungen. Wenn ein Nutzer mehrere Rollen hat, zeige alle relevanten Bereiche, aber mache den Startbildschirm rollenadäquat (z. B. landen Triage‑Verantwortliche auf der Queue).
Berechtigungen, Sicherheit und Auditierbarkeit
Berechtigungen sind nicht nur IT‑Pflichten — sie verhindern unbeabsichtigtes Oversharing und halten Anfragen in Bewegung. Beginne einfach und engagiere dich später, sobald du verstehst, was Teams wirklich brauchen.
Rollenbasierter Zugriff (vorhersehbar halten)
Definiere eine kleine Menge Rollen und mache jede in der UI offensichtlich:
- Anfragende Person: kann einreichen, ihre eigenen Anfragen sehen, auf Fragen antworten und Status verfolgen.
- Teammitglied (Erfüller): kann die Queue seines Teams sehen, kommentieren, Änderungen anfragen und Status aktualisieren.
- Approver: kann bestimmte Schritte genehmigen/ablehnen (z. B. Comms‑Sign‑Off oder Legal‑Review).
- Admin: verwaltet Templates, Felder, Teams und Berechtigungsregeln.
Vermeide zu Beginn „Spezialfälle“. Wenn jemand extra Zugang braucht, behandle das als Rollenänderung – nicht als Einzelfall.
Sensible Anfragen schützen, ohne alles zu verlangsamen
Standardmäßig teambasierte Sichtbarkeit: eine Anfrage ist für die anfragende Person plus die zugewiesenen Teams sichtbar. Ergänze zwei Optionen:
- Private Felder (z. B. Budget, Mitarbeiterdetails) nur für bestimmte Rollen sichtbar.
- Eingeschränkte Anfragen, bei denen nur eine benannte Gruppe den vollständigen Datensatz sehen kann.
So bleibt die Arbeit größtenteils kollaborativ, während Randfälle geschützt werden.
Gäste regeln (falls notwendig)
Wenn externe Reviewer oder gelegentliche Stakeholder nötig sind, wähle ein Modell:
- View‑only‑Links mit Ablauf (gut zum Teilen des finalen Entwurfs).
- Verpflichtende Accounts (besser für Freigaben, Kommentare und Nachvollziehbarkeit).
Beide Modelle können kombiniert funktionieren, aber dokumentiere, wann welches erlaubt ist.
Auditierbarkeit: Verantwortlichkeit automatisch machen
Logge zentrale Aktionen mit Zeitstempel und Akteur: Statusänderungen, Änderungen an kritischen Feldern, Genehmigungen/Ablehnungen und finale Veröffentlichungsbestätigung. Mach die Audit‑Spur exportierbar für Compliance und sichtbar genug, dass Teams die Historie vertrauen, ohne „herumfragen“ zu müssen.
Benachrichtigungen und Erinnerungen, die nicht nerven
Lass deinen Build sich auszahlen
Teile, was du gebaut hast, mit Koder.ai und verdiene Credits für Inhalte oder Empfehlungen.
Benachrichtigungen sollen eine Anfrage voranbringen – nicht einen zweiten Posteingang erzeugen, den Leute ignorieren. Ziel: die richtige Person zur richtigen Zeit über das Richtige informieren, mit einem klaren nächsten Schritt.
Nur bei wichtigen Workflow‑Ereignissen benachrichtigen
Starte mit einer kurzen Menge an Ereignissen, die direkt eine Handlung auslösen:
- Eingereicht (Bestätigung an Anfragende Person + „Was als Nächstes passiert“)
- Zugewiesen (Owner bekommt Kontext + Link zur Anfrage)
- Mehr Infos benötigt (Anfragende Person bekommt konkrete Fragen und eine Frist)
- Genehmigt/abgelehnt (Anfragende Person + nachgelagertes Team falls relevant)
- Bald fällig und überfällig (Owner + optionale Eskalation an Manager)
Wenn ein Ereignis keine Aktion auslöst, behalte es im Aktivitätsprotokoll statt als Push‑Benachrichtigung.
1–2 Kanäle wählen und gut machen
Vermeide, Updates überall zu streuen. Die meisten Teams starten erfolgreich mit einem primären Kanal (oft E‑Mail) plus einem Echtzeit‑Kanal (Slack/Teams) für Owner.
Praktische Regel: Echtzeit‑Nachrichten für Arbeit, die du besitzt, E‑Mail für Sichtbarkeit und Aufzeichnungen. In‑App‑Benachrichtigungen sind nützlich, sobald Leute täglich im Tool arbeiten.
Erinnerungsregeln, die Lärm reduzieren
Erinnerungen sollten vorhersehbar und konfigurierbar sein:
- Tägliche oder zweimal wöchentliche Digests für „Mehr Infos benötigt“ und „Warten auf dich“‑Elemente
- Ruhezeiten (keine Pings nach Feierabend; am nächsten Morgen zustellen)
- Eskalation erst nach klarer Schwelle (z. B. 48 Stunden überfällig)
Vorlagen nutzen, damit Updates handlungsfähig sind
Vorlagen machen Nachrichten konsistent und leicht zu scannen. Jede Benachrichtigung sollte enthalten:
- Anfragetitel + ID
- Aktueller Status und Owner
- Was sich geändert hat
- Einen klaren CTA‑Link (z. B. „Info hinzufügen“, „Prüfen“, „Als erledigt markieren")
So wird jede Nachricht zu einem Fortschrittssignal statt zu Lärm.
SLAs, Fälligkeit und Planung
Wenn Anfragen nicht rechtzeitig ausgeliefert werden, liegt es meist an unklaren Erwartungen: „Wie lange sollte das dauern?“ und „Bis wann?“ Baue Zeitangaben in den Workflow, damit sie sichtbar, konsistent und fair sind.
SLAs nach Anfragetyp definieren
Setze Service‑Level‑Erwartungen, die zur Arbeit passen. Beispiele:
- Ankündigungen: 5 Werktage
- Newsletter‑Beiträge: 3 Werktage
- Executive‑Kommunikation: 10 Werktage
Mache SLA feldgetrieben: Sobald eine anfragende Person einen Typ auswählt, kann die App die erwartete Vorlaufzeit und das frühestmögliche Publikationsdatum anzeigen.
Zieltermine automatisch berechnen
Vermeide manuelle Rechnerei. Speichere zwei Daten:
- Gewünschtes Veröffentlichungsdatum (was die anfragende Person möchte)
- Ziel‑Abschlussdatum (was das Team zusagt)
Berechne das Ziel‑Datum aus der Vorlaufzeit des Anfragetypen (Werktage) und erforderlichen Schritten (z. B. Genehmigungen). Wenn jemand das Veröffentlichungsdatum ändert, sollte die App das Ziel‑Datum sofort anpassen und „enges Zeitfenster“ flaggen, wenn das gewünschte Datum vor dem frühestmöglichen Termin liegt.
Planung zur Vermeidung von Kollisionen
Eine Queue allein zeigt keine Konflikte. Ergänze eine einfache Kalender‑/Planungsansicht, die Elemente nach Veröffentlichungsdatum und Kanal (E‑Mail, Intranet, Social etc.) gruppiert. So entdecken Teams Überlast (z. B. zu viele Sends am Dienstag) und verhandeln Alternativen, bevor Arbeit beginnt.
Gründe für Verzögerungen erfassen
Wenn eine Anfrage sich verzögert, erfasse einen einzelnen „Verzögerungsgrund“, damit das Reporting handlungsfähig ist: Warten auf Anfragende Person, Warten auf Genehmigungen, Kapazität oder Scope‑Änderung. Mit der Zeit werden verpasste Deadlines dadurch zu lösbaren Mustern statt wiederkehrenden Überraschungen.
MVP bauen und technischen Ansatz praktisch wählen
Der schnellste Weg zu Wert ist, ein kleines, nutzbares MVP zu liefern, das Ad‑hoc‑Chats und Tabellen ersetzt – ohne alle Randfälle lösen zu wollen.
Mit einem real nutzbaren MVP starten
Ziele für das kleinste Funktionsset, das einen vollständigen Anfrage‑Lebenszyklus unterstützt:
- Ein Intake‑Formular, das das Wesentliche erfasst (Anfragetyp, Zielgruppe, Deadline, Priorität, Anhänge)
- Eine gemeinsame Request‑Queue (ein Ort, um „was wartet“ zu sehen)
- Einfache Status, die zu deinem Workflow passen (z. B. Neu → In Prüfung → Genehmigt → Geplant → Erledigt, mit Mehr Infos benötigt und Abgelehnt als Seitenschleifen)
- Kommentare und @Erwähnungen für Klarstellungen
- Basis‑Benachrichtigungen (Bestätigung an Anfragende Person, Zuweisung an Owner, Statusänderungen)
Wenn du diese Dinge gut machst, reduzierst du Rückfragen sofort und schaffst eine einzige Quelle der Wahrheit.
Einen Stack wählen, der zu deinem Team passt (nicht zu deiner Wunschliste)
Wähle den Ansatz, der zu Fähigkeiten, Geschwindigkeit und Governance passt:
- Low‑Code (schnellste Lieferung): gut für Formulare + Genehmigungen + einfache Dashboards.
- Plattformen für interne Tools: stark für authentifizierte Apps mit Tabellen, Filtern und Admin‑Panels.
- Full‑Stack‑Build: am besten, wenn du spezielle Integrationen, komplexe Berechtigungen oder starke Automatisierung brauchst.
Wenn du den Full‑Stack‑Weg beschleunigen willst, ohne zu brüchigen Tabellen zurückzukehren, können Plattformen wie Koder.ai hilfreich sein, um aus einem strukturierten Chat‑basierten Spec eine funktionierende interne App zu bekommen. Du kannst Intake‑Formular, Queue, Rollen/Berechtigungen und Dashboards schnell prototypen und später den Quellcode exportieren und unter deinen Policies deployen.
Suche und Filter früh implementieren
Schon bei 50–100 Anfragen müssen Leute die Queue nach Team, Status, Fälligkeitsdatum und Priorität schneiden können. Füge Filter von Anfang an hinzu, damit das Tool nicht zur Scroll‑Fest wird.
Analytics später hinzufügen (wenn die Daten sauber sind)
Sobald der Workflow stabil ist, füge Reporting hinzu: Durchsatz, Zykluszeit, Backlog‑Größe und SLA‑Erfüllungsrate. Du bekommst bessere Erkenntnisse, sobald Teams konsistent die gleichen Status und Fälligkeitsregeln nutzen.
Launch, Adoption und Iterationsplan
Staus bei Veröffentlichungsterminen vermeiden
Füge Planungsansichten hinzu, um Kanal-Kollisionen zu erkennen und Last‑Minute‑Konflikte zu vermeiden.
Eine Anfragen‑Management‑Web‑App funktioniert nur, wenn die Leute sie wirklich nutzen. Behandle den ersten Release als Lernphase, nicht als Großauftritt. Dein Ziel ist, die neue „Quelle der Wahrheit“ für teamübergreifende Kommunikationsanfragen zu etablieren und den Workflow anhand realer Nutzung zu verfeinern.
Mit einem kleinen Pilot starten
Pilote mit 1–2 Teams und 1–2 Anfragetypen. Wähle Teams mit häufigen Übergaben und einen Manager, der den Prozess verstärkt. Halte das Volumen überschaubar, damit du schnell auf Probleme reagieren und Vertrauen aufbauen kannst.
Während des Piloten das alte Verfahren nur parallel laufen lassen, wenn unbedingt nötig. Wenn Updates weiterhin im Chat oder per E‑Mail stattfinden, wird die App nie zur Default.
Leichtgewichtige Richtlinien veröffentlichen
Erstelle kurze Guidelines, die beantworten:
- Was eingereicht werden soll (und was nicht)
- Erforderliche Vorlaufzeit (z. B. „72 Stunden für Standardanfragen“)
- Wo Updates liegen (die App, nicht DMs)
Pinne die Guidelines im Team‑Hub und verlinke sie in der App (z. B. /help/requests). Mach sie so kurz, dass Leute sie tatsächlich lesen.
Einen umsetzbaren Feedback‑Loop einrichten
Sammle wöchentlich Feedback von Anfragenden und Ownern. Frage spezifisch nach fehlenden Feldern, verwirrenden Status und Benachrichtigungs‑Spam. Verbinde das mit einer schnellen Durchsicht realer Anfragen: Wo haben Leute gezögert, abgebrochen oder den Workflow umgangen?
Iterieren, ohne Gewohnheiten zu zerstören
Iteriere in kleinen, vorhersehbaren Änderungen: Passe Formularfelder, SLAs und Berechtigungen anhand realer Nutzung an. Kündige Änderungen an einem Ort an mit einem „Was hat sich geändert / Warum“‑Hinweis. Stabilität fördert Adoption; ständige Überarbeitungen schwächen sie.
Wenn du willst, dass es Bestand hat, messe Adoption (Anfragen über die App vs. außerhalb), Durchlaufzeit und Nacharbeit. Nutze diese Ergebnisse, um die nächste Iteration zu priorisieren.
Ergebnisse messen und langfristig verbessern
Den Request‑Management‑Web‑App‑Launch sollte man nicht als Endpunkt sehen – es ist der Start eines Feedback‑Loops. Ohne Messgrößen kann das System leise zur „Black Box“ werden, und Teams vertrauen Status nicht mehr und kehren zu Nebenkommunikation zurück.
Mit Dashboards starten, die Menschen wirklich nutzen
Erstelle wenige Ansichten, die die täglichen Fragen beantworten:
- Offene Anfragen (was gerade in der Queue ist)
- Überfällige (Datum oder SLA überschritten)
- Anstehende (bald fällig, damit Teams planen können)
- Workload nach Team/Owner (um Engpässe und ungleiche Verteilung zu erkennen)
Halte Dashboards sichtbar und konsistent. Wenn Teams sie in 10 Sekunden nicht verstehen, werden sie sie nicht prüfen.
Metriken monatlich prüfen – und Änderungen ableiten
Führe ein monatliches Meeting (30–45 Minuten) mit Vertretern der Hauptteams ein. Nutze es, um eine kurze, stabile Metrikauswahl zu prüfen, z. B.:
- Durchschnittszeit bis zur ersten Reaktion
- Durchschnittszeit bis zum Abschluss
- SLA‑Erfüllungsrate
- Wiederöffnungsrate (Anfragen, die zurückspringen)
- Volumen nach Anfragetyp
Beende das Meeting mit konkreten Entscheidungen: SLAs anpassen, Intake‑Fragen klären, Status verfeinern oder Zuständigkeiten verschieben. Dokumentiere Änderungen in einem einfachen Changelog, damit alle wissen, was anders ist.
Leichte Taxonomie pflegen
Eine Anfragetaxonomie ist nur hilfreich, solange sie klein bleibt. Ziel: eine Handvoll Kategorien plus optionale Tags. Vermeide hunderte Typen, die ständige Pflege erfordern.
Verbesserungen evidenzbasiert planen
Wenn die Basics stabil sind, priorisiere Verbesserungen, die manuelle Arbeit reduzieren:
- Vorlagen für wiederkehrende Anfragen
- Integrationen (Chat, E‑Mail, Kalender, Ticketing)
- Policy‑gesteuerte Genehmigungen (nur wenn nötig)
- Eine API für Reporting oder zum Erstellen von Anfragen aus anderen Tools
Lass Nutzung und Metriken – nicht Meinungen – entscheiden, was als Nächstes gebaut wird.