04. Nov. 2025·8 Min
Vint Cerf, TCP/IP und die Entscheidungen, die das Internet bauten
Erfahre, wie Vint Cerfs Entscheidungen zu TCP/IP interoperable Netze und später globale Softwareplattformen ermöglichten — von E‑Mail und Web bis zu Cloud‑Apps.
Erfahre, wie Vint Cerfs Entscheidungen zu TCP/IP interoperable Netze und später globale Softwareplattformen ermöglichten — von E‑Mail und Web bis zu Cloud‑Apps.
Die meisten Menschen erleben das Internet über Produkte: eine Website, die sofort lädt, einen Videoanruf, der (meistens) funktioniert, eine Zahlung, die in Sekunden abgewickelt wird. Unter diesen Erlebnissen liegen Protokolle — gemeinsame Regeln, die verschiedenen Systemen erlauben, Nachrichten zuverlässig genug auszutauschen, um nützlich zu sein.
Ein Protokoll ist wie die Vereinbarung über eine gemeinsame Sprache und Etikette fürs Kommunizieren: wie eine Nachricht aussieht, wie man ein Gespräch beginnt und beendet, was man tut, wenn etwas fehlt, und wie man weiß, für wen eine Nachricht bestimmt ist. Ohne gemeinsame Regeln würde jede Verbindung zu einer Einzellösung werden, und Netze skalierten nicht über kleine Kreise hinaus.
Vint Cerf wird oft als „Vater des Internets“ bezeichnet, aber treffender (und nützlicher) ist, seine Rolle als Teil eines Teams zu sehen, das pragmatische Designentscheidungen traf — insbesondere rund um TCP/IP — und so „Netzwerke“ in ein Internetwork verwandelte. Diese Entscheidungen waren nicht zwangsläufig. Sie spiegelten Kompromisse wider: Einfachheit vs. Features, Flexibilität vs. Kontrolle und Geschwindigkeit der Einführung vs. perfekte Garantien.
Moderne globale Plattformen — Web-Apps, mobile Dienste, Cloud‑Infrastruktur und APIs zwischen Unternehmen — leben oder sterben noch immer nach derselben Idee: Wenn du die richtigen Schnittstellen standardisierst, können Millionen unabhängiger Akteure darauf bauen, ohne um Erlaubnis fragen zu müssen. Dein Telefon kann mit Servern auf anderen Kontinenten sprechen, nicht nur weil Hardware schneller wurde, sondern weil die Verkehrsregeln stabil genug blieben, damit Innovation darauf aufbauen konnte.
Diese Denkweise zählt auch, wenn du „nur Software baust“. Beispielsweise gelingen Vibe‑Coding‑Plattformen wie Koder.ai, wenn sie eine kleine Menge stabiler Primitive (Projekte, Deployments, Umgebungen, Integrationen) bereitstellen und Teams gleichzeitig erlauben, an den Rändern schnell zu iterieren — ob sie nun ein React‑Frontend, ein Go + PostgreSQL‑Backend oder eine Flutter‑Mobile‑App erzeugen.
Wir werden die Geschichte kurz streifen, aber der Fokus liegt auf Designentscheidungen und ihren Folgen: wie Layering Wachstum ermöglichte, wo „gut genug“ neue Anwendungen freisetzte und welche frühen Annahmen zu Staus und Sicherheit falsch lagen. Das Ziel ist praktisch: Übertrage Protokolldenken — klare Schnittstellen, Interoperabilität und explizite Trade‑offs — auf modernes Plattformdesign.
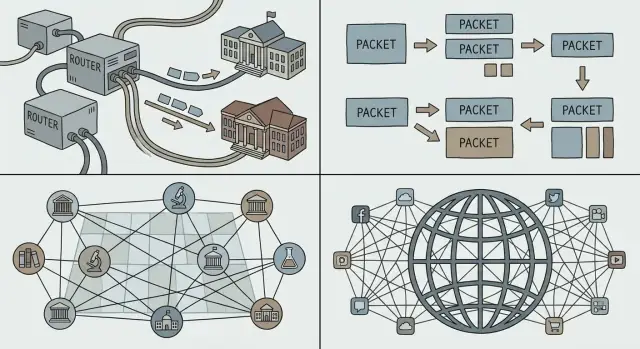
Bevor „das Internet“ entstand, gab es viele Netze — aber nicht ein Netz, das alle teilen konnten. Universitäten, Forschungslabore und Firmen bauten eigene Systeme, um lokale Bedürfnisse zu lösen. Jedes Netz funktionierte, aber sie arbeiteten selten zusammen.
Mehrere Netze existierten aus pragmatischen Gründen, nicht weil man Fragmentierung liebte. Betreiber hatten unterschiedliche Ziele (Forschung, militärische Zuverlässigkeit, kommerzielle Dienste), unterschiedliche Budgets und technische Randbedingungen. Hardware‑Anbieter verkauften inkompatible Systeme. Einige Netze waren für Langstrecken optimiert, andere für Campus‑Umgebungen oder spezialisierte Dienste.
Das Ergebnis waren viele „Inseln“ der Konnektivität.
Wenn zwei Netze kommunizieren sollten, war die grobe Lösung, eine Seite so umzubauen, dass sie zur anderen passt. Das passiert in der Praxis selten: teuer, langsam und politisch heikel.
Benötigt wurde ein gemeinsamer Klebstoff — ein Weg für unabhängige Netze, sich zu verbinden und gleichzeitig ihre internen Entscheidungen zu behalten. Das bedeutete:
Diese Herausforderung schuf den Rahmen für die Internetworking‑Ideen, die Cerf und andere vertraten: Netze auf einer gemeinsamen Schicht verbinden, damit Innovationen darüber stattfinden können und Diversität darunter erhalten bleibt.
Wenn du jemals telefoniert hast, kennst du das Prinzip hinter der Leitungsvermittlung: eine dedizierte „Leitung“ wird für die Dauer des Gesprächs reserviert. Das funktioniert gut für stetige, echtzeitige Sprache, ist aber verschwenderisch, wenn das Gespräch größtenteils Stille enthält.
Die Paketvermittlung kehrt das Modell um. Eine Alltagserklärung ist der Postdienst: Statt eine private Autobahn von deinem Haus zum Freund zu reservieren, steckst du deine Nachricht in Umschläge. Jeder Umschlag (Paket) ist beschriftet, wird über gemeinsame Straßen geleitet und am Ziel wieder zusammengesetzt.
Die meisten Computer‑Workloads sind burstartig. Eine E‑Mail, ein Dateidownload oder eine Webseite ist kein kontinuierlicher Strom — es sind kurze Datenstöße, dann nichts, dann wieder ein Stoß. Paketvermittlung erlaubt vielen Personen, dieselben Verbindungen effizient zu teilen, weil das Netz Pakete für diejenigen transportiert, die gerade etwas zu senden haben.
Das ist ein zentraler Grund, warum das Internet neue Anwendungen unterstützen konnte, ohne die Arbeitsweise des zugrundeliegenden Netzes neu verhandeln zu müssen: Man kann eine winzige Nachricht oder ein großes Video auf dieselbe Weise verschicken — zerlegen, verpacken und senden.
Pakete skalieren auch sozial, nicht nur technisch. Verschiedene Netze (von Universitäten, Unternehmen oder Regierungen betrieben) können sich verbinden, solange sie sich darauf einigen, wie Pakete weitergeleitet werden. Kein einzelner Betreiber muss den gesamten Pfad besitzen; jede Domain kann den Verkehr zur nächsten tragen.
Weil Pakete Links teilen, entstehen Wartezeiten in Warteschlangen, Jitter oder sogar Verluste, wenn Netze stark ausgelastet sind. Diese Nachteile führten zu Kontrollmechanismen — Neusendungen, Reihenfolge‑Wiederherstellung und Staukontrolle — damit Paketvermittlung auch unter hoher Last schnell und fair bleibt.
Das Ziel, das Cerf und Kollegen verfolgten, war nicht „ein Netz bauen“. Es war, viele Netze zu verbinden — Universitäts-, Regierungs‑, Geschäftsnetze — und jedem zu erlauben, seine Technologie, Betreiber und Regeln beizubehalten.
TCP/IP wird oft als „Suite“ beschrieben, aber die entscheidende Designentscheidung war die Trennung der Verantwortlichkeiten:
Diese Aufteilung ließ das „Internet“ als gemeinsame Lieferfabrik erscheinen, während Zuverlässigkeit ein optionaler Dienst darüber wurde.
Layering macht Systeme leichter weiterentwickelbar, weil man eine Schicht upgraden kann, ohne alles darüber neu zu verhandeln. Neue physische Verbindungen (Glasfaser, Wi‑Fi, Mobilfunk), Routing‑Strategien und Sicherheitsmechanismen können nachträglich kommen — Anwendungen sprechen weiterhin TCP/IP und funktionieren weiter.
Dasselbe Muster nutzen Plattform‑Teams: stabile Schnittstellen, austauschbare Interna.
IP verspricht keine Perfektion; es liefert einfache, universelle Primitive: „hier ist ein Paket“ und „hier ist eine Adresse“. Diese Zurückhaltung ermöglichte unerwartete Anwendungen — E‑Mail, das Web, Streaming, Echtzeit‑Chat — weil Innovatoren an den Rändern bauen konnten, ohne das Netz um Erlaubnis zu fragen.
Wenn du eine Plattform entwirfst, ist dies ein nützlicher Test: Bietest du ein paar verlässliche Bausteine an oder überfittest du das System auf den heutigen Lieblings‑Use‑Case?
„Best‑Effort“ Zustellung ist eine einfache Idee: IP versucht, deine Pakete Richtung Ziel zu bewegen, verspricht aber nicht, dass sie ankommen, in Reihenfolge sind oder rechtzeitig eintreffen. Pakete können verworfen werden, wenn Links ausgelastet sind, durch Staus verzögert oder über unterschiedliche Routen geleitet werden.
Diese Einfachheit war ein Feature, kein Bug. Unterschiedliche Organisationen konnten sehr unterschiedliche Netze verbinden — hochwertige, teure Leitungen an einigen Orten; rauschige, schmale Verbindungen an anderen — ohne alle dazu zu zwingen, dieselbe Premium‑Infrastruktur zu nutzen.
Best‑Effort‑IP senkte die „Eintrittspreise“. Universitäten, Regierungen, Startups und schließlich Haushalte konnten mit der Konnektivität teilnehmen, die sie sich leisten konnten. Hätte das Kernprotokoll strikte Garantien von jedem Netz entlang des Pfads verlangt, wäre die Adoption ins Stocken geraten: das schwächste Glied hätte die Kette blockiert.
Anstatt einen perfekt zuverlässigen Kern zu bauen, verlegte das Internet Zuverlässigkeit zu den Hosts (den Geräten an den Enden). Wenn eine Anwendung Korrektheit braucht — Dateiübertragungen, Zahlungen oder das Laden einer Webseite — kann sie Protokolle und Logik an den Rändern nutzen, um Verluste zu erkennen und zu beheben:
TCP ist das klassische Beispiel: Es macht aus einem unzuverlässigen Paketdienst einen zuverlässigen Stream, indem es die harte Arbeit an den Endpunkten erledigt.
Für Plattform‑Teams schuf Best‑Effort‑IP ein vorhersagbares Fundament: Überall auf der Welt kann man davon ausgehen, denselben grundlegenden Dienst zu haben — sende Pakete an eine Adresse, und sie kommen meist an. Diese Konsistenz machte es möglich, globale Softwareplattformen zu bauen, die sich über Länder, Carrier und Hardware hinweg ähnlich verhalten.
Das End‑to‑End‑Prinzip ist eine vorgaukende einfache Idee: Halte den Netzwerkkern minimal und bringe Intelligenz an die Ränder — auf Geräte und in Anwendungen.
Für Software‑Entwickler war diese Trennung ein Geschenk. Wenn das Netz die Anwendung nicht verstehen musste, konnte man neue Ideen ausliefern, ohne mit jedem Netzbetreiber Änderungen zu verhandeln.
Diese Flexibilität ist ein wesentlicher Grund, warum globale Plattformen schnell iterieren konnten: E‑Mail, das Web, Sprach/Video und später Mobile‑Apps liefen alle auf derselben Infrastruktur.
Ein einfacher Kern bedeutet auch, dass der Kern dich nicht automatisch schützt. Wenn das Netz hauptsächlich Pakete weiterleitet, können Angreifer und Missbraucher dieselbe Offenheit für Spam, Scans, Denial‑of‑Service‑Angriffe und Betrug nutzen.
Qualitätsanforderungen sind ein weiterer Spannungsfall. Nutzer erwarten flüssige Videoanrufe und sofortige Reaktionen, aber Best‑Effort‑Zustellung kann Jitter, Stau und inkonsistente Performance erzeugen. Das End‑to‑End‑Ansatz schiebt viele Lösungen nach oben: Retry‑Logik, Pufferung, Qualitätsanpassung und Anwendung‑Level‑Priorisierung.
Vieles, was heute als „das Internet“ verstanden wird, ist zusätzliche Struktur über dem minimalen Kern: CDNs, die Inhalte näher an Nutzer bringen; Verschlüsselung (TLS) für Privatsphäre und Integrität; Streaming‑Protokolle, die Qualität an aktuelle Bedingungen anpassen. Selbst netzwerknahe Fähigkeiten — Bot‑Schutz, DDoS‑Abwehr und Performance‑Beschleunigung — werden oft als Plattform‑Dienste am Rand bereitgestellt, statt in IP einzubauen.
Ein Netz kann nur global werden, wenn jedes Gerät ausreichend zuverlässig erreichbar ist, ohne dass jeder Teilnehmer über jeden anderen informiert sein muss. Das ist die Aufgabe von Adressierung, Routing und DNS: drei Ideen, die einen Haufen verbundener Netze in etwas verwandeln, das Menschen (und Software) tatsächlich nutzen können.
Eine Adresse ist ein Bezeichner, der dem Netz sagt, wo etwas ist. Bei IP wird dieses „Wo“ in strukturierter numerischer Form ausgedrückt.
Routing ist der Prozess, zu entscheiden, wie Pakete in Richtung dieser Adresse bewegt werden. Router brauchen keine vollständige Karte jeder Maschine auf der Welt; sie benötigen nur genug Informationen, um Verkehr Schritt für Schritt in die richtige Richtung zu leiten.
Das Entscheidende ist, dass Weiterleitungsentscheidungen lokal und schnell sein können, während das Gesamtergebnis trotzdem globale Erreichbarkeit liefert.
Wenn jede einzelne Geräteadresse überall gelistet werden müsste, würde das Internet unter der eigenen Buchhaltung zusammenbrechen. Hierarchische Adressierung erlaubt es, Adressen zu gruppieren (z. B. nach Netz oder Anbieter), sodass Router aggregierte Routen halten können — ein Eintrag, der viele Ziele repräsentiert.
Das ist das unspektakuläre Geheimnis des Wachstums: kleinere Routing‑Tabellen, weniger Updates und einfachere Koordination zwischen Organisationen. Aggregation ist auch der Grund, warum IP‑Adresspolitik und Zuteilung für Betreiber wichtig sind: sie beeinflussen direkt, wie aufwendig es ist, das globale System kohärent zu halten.
Menschen wollen keine Zahlen tippen, und Dienste wollen nicht dauerhaft an eine einzelne Maschine gebunden sein. DNS (Domain Name System) ist die Benennungsschicht, die lesbare Namen (wie api.example.com) auf IP‑Adressen abbildet.
Für Plattform‑Teams ist DNS mehr als Komfort:
Mit anderen Worten: Adressierung und Routing machen das Internet erreichbar; DNS macht es auf Plattform‑Skalierung nutzbar und betrieblich anpassbar.
Ein Protokoll wird erst dann „das Internet“, wenn viele unabhängige Netze und Produkte es ohne Erlaubnis nutzen können. Eine der klügsten Entscheidungen rund um TCP/IP war nicht nur technischer Natur — sie war sozial: Spezifikationen veröffentlichen, Kritik einladen und jede*n implementieren lassen.
Die Request for Comments (RFC)‑Reihe verwandelte Netzwerkideen in gemeinsame, zitierbare Dokumente. Anstelle eines Black‑Box‑Standards, der von einem Anbieter kontrolliert wird, machten RFCs die Regeln sichtbar: was jedes Feld bedeutet, wie man in Randfällen verhält und wie man kompatibel bleibt.
Diese Offenheit tat zweierlei: Erstens reduzierte sie das Risiko für Übernehmer — Universitäten, Regierungen und Firmen konnten das Design bewerten und dagegen bauen. Zweitens schuf sie einen gemeinsamen Bezugspunkt, sodass Streitigkeiten durch Textänderungen statt private Verhandlungen gelöst werden konnten.
Interoperabilität macht „Multi‑Vendor“ real. Wenn verschiedene Router, Betriebssysteme und Anwendungen vorhersehbar Verkehr austauschen können, sind Käufer nicht gefangen. Wettbewerb verlagert sich von „mit wessen Netz kannst du dich verbinden?“ zu „wessen Produkt ist besser?“ — das beschleunigt Verbesserungen und senkt Kosten.
Kompatibilität erzeugt Netzwerkeffekte: jede neue TCP/IP‑Implementierung macht das gesamte Netz wertvoller, weil sie mit allem anderen sprechen kann. Mehr Nutzer ziehen mehr Dienste an; mehr Dienste ziehen mehr Nutzer an.
Offene Standards beseitigen Reibung nicht — sie verteilen sie neu. RFCs beinhalten Debatten, Koordination und manchmal langsame Änderungen, besonders wenn Milliarden Geräte bereits auf dem heutigen Verhalten beruhen. Der Vorteil ist, dass Änderungen, wenn sie kommen, nachvollziehbar und breit implementierbar sind — und den Kernnutzen bewahren: alle können weiterhin verbinden.
Wenn man „Plattform“ sagt, meint man oft ein Produkt, auf dem andere Leute aufbauen können: Drittanbieter‑Apps, Integrationen und Dienste, die auf gemeinsamen Schienen laufen. Im Internet sind diese Schienen nicht das private Netz einer Firma — es sind gemeinsame Protokolle, die jede*r implementieren kann.
TCP/IP hat nicht alleine das Web, die Cloud oder App‑Stores geschaffen. Es machte ein stabiles, universelles Fundament, auf dem diese Dinge sich zuverlässig verbreiten konnten.
Sobald Netze über IP interconnecten konnten und Anwendungen sich auf TCP für Zustellung verlassen konnten, wurde es praktikabel, höherwertige Bausteine zu standardisieren:
Das Geschenk von TCP/IP für Plattformökonomie war Vorhersehbarkeit: Man konnte einmal bauen und viele Netze, Länder und Gerätetypen erreichen, ohne bei jeder Verbindung maßgeschneiderte Konnektivität zu verhandeln.
Eine Plattform wächst schneller, wenn Nutzer und Entwickler das Gefühl haben, sie könnten wechseln — oder zumindest nicht gefangen sind. Offene, weit verbreitete Protokolle senken Wechselkosten, weil:
Diese „permissionless“ Interoperabilität ist der Grund, warum globale Softwaremärkte um gemeinsame Standards statt um einen einzigen Netzwerkeigentümer entstehen konnten.
Diese Protokolle sitzen über TCP/IP, sind aber dem selben Prinzip verpflichtet: Sind die Regeln stabil und öffentlich, können Plattformen produktseitig konkurrieren, ohne die Verbindungsmöglichkeit zu zerstören.
Die Magie des Internets ist, dass es über Ozeane, Mobilnetze, Wi‑Fi‑Hotspots und ausgelastete Bürorouter funktioniert. Die weniger magische Wahrheit: Es arbeitet immer unter Einschränkungen. Bandbreite ist begrenzt, Latenz schwankt, Pakete gehen verloren oder werden umgeordnet, und Stau kann plötzlich auftreten, wenn viele Nutzer denselben Pfad teilen.
Selbst wenn dein Dienst „in der Cloud“ läuft, erlebt dein Nutzer ihn durch den schmalsten Teil der Route zu ihm. Ein Videoanruf über Glasfaser und derselbe Anruf in einem vollen Zug sind unterschiedliche Produkte, weil Latenz, Jitter und Verlust das Nutzererlebnis formen.
Wenn zu viel Verkehr dieselben Links trifft, bauen sich Warteschlangen auf und Pakete fallen weg. Wenn jede Quelle darauf mit mehr Senden (oder zu aggressivem Retry) reagiert, kann das Netz in einen Stau‑Kollaps geraten — viel Verkehr, wenig nutzbare Zustellung.
Staukontrolle sind die Verhaltensweisen, die fairen und stabilen Teilen ermöglichen: Suche nach verfügbarer Kapazität, reduziere bei Signalen für Überlast (Verlust/Latenz) und erhöhe dann vorsichtig wieder. TCP popularisierte dieses „langsamer werden, dann wieder vorsichtig schneller“‑Rhythmus, sodass das Netz einfach bleiben kann, während Endpunkte sich anpassen.
Weil Netze unvollkommen sind, leisten erfolgreiche Anwendungen stillschweigend zusätzliche Arbeit:
Entwirf so, als würde das Netz kurzzeitig und häufig ausfallen:
Resilienz ist kein Zusatzfeature — sie ist der Preis dafür, in Internet‑Maßstab zu operieren.
TCP/IP gelang, weil es jeden leicht machte, sich mit jederm zu verbinden. Der versteckte Preis dieser Offenheit ist, dass jeder* dir auch Traffic schicken kann — guten wie schlechten.
Frühe Internet‑Designs setzten auf eine relativ kleine, forschungsorientierte Gemeinschaft. Als das Netz öffentlich wurde, erlaubte dieselbe „einfach weiterleiten“‑Philosophie Spam, Betrug, Malware‑Verbreitung, DoS‑Angriffe und Identitätsbetrug. IP prüft nicht, wer du bist. E‑Mail (SMTP) erforderte nicht den Nachweis, dass du die „From“‑Adresse besitzt. Router waren nie dazu gedacht, Intentionen zu beurteilen.
Als das Internet zur kritischen Infrastruktur wurde, war Sicherheit nicht länger ein Feature, das man später draufsetzt — sie wurde zur Anforderung beim Systemaufbau: Identität, Vertraulichkeit, Integrität und Verfügbarkeit brauchten explizite Mechanismen. Das Netz blieb größtenteils best‑effort und neutral, aber Anwendungen und Plattformen mussten davon ausgehen, dass das Übertragungsmedium nicht vertrauenswürdig ist.
Wir „reparierten“ IP nicht, indem wir jedes Paket kontrollierten. Moderne Sicherheit ist gestapelt über IP:
Behandle das Netz standardmäßig als hostile. Nutze Least Privilege überall: enge Berechtigungen, kurzlebige Anmeldeinformationen und sichere Standardkonfigurationen. Verifiziere Identitäten und Eingaben an jeder Grenze, verschlüssele in Transit und entwerfe für Missbrauchsfälle — nicht nur für den Happy Path.
Das Internet „gewann“ nicht, weil jedes Netz dieselbe Hardware, denselben Anbieter oder perfekte Features wählte. Es hielt sich, weil zentrale Protokollentscheidungen es leicht machten, dass unabhängige Systeme sich verbinden, verbessern und weiterarbeiten, selbst wenn Teile ausfallen.
Layering mit klaren Nähten. TCP/IP trennte „Pakete bewegen“ von „Anwendungen zuverlässig machen.“ Diese Grenze ließ das Netz allgemein bleiben, während Apps schnell evolvierten.
Einfachheit im Kern. Best‑Effort‑Zustellung bedeutete, das Netz musste nicht jede Anwendungsanforderung verstehen. Innovation geschah an den Rändern, wo neue Produkte ohne zentrale Aushandlung ausgeliefert werden konnten.
Interoperabilität zuerst. Offene Spezifikationen und vorhersehbares Verhalten machten es möglichen, dass unterschiedliche Organisationen kompatible Implementierungen bauen — und erzeugten eine sich selbst verstärkende Verbreitung.
Wenn du eine Plattform baust, betrachte Interkonnektion als Feature, nicht als Nebeneffekt. Bevorzuge eine kleine Menge von Primitiven, die viele Teams zusammensetzen können, statt einer Vielzahl „smarter“ Features, die Nutzer in einen Weg einsperren.
Entwirf für Evolution: geh davon aus, dass Clients alt sein werden, Server neu, und einige Abhängigkeiten teilweise down sein werden. Deine Plattform sollte graceful degradieren und trotzdem nützlich bleiben.
Wenn du eine Rapid‑Build‑Umgebung wie Koder.ai nutzt, zeigen sich dieselben Prinzipien in Produktfähigkeiten: ein klarer Planungs‑Schritt (damit Schnittstellen explizit sind), sichere Iteration via Snapshots/Rollback und vorhersehbares Deployment/Hosting, das mehreren Teams erlaubt, schnell zu arbeiten, ohne Konsumenten zu brechen.
Ein Protokoll ist eine gemeinsame Menge von Regeln dafür, wie Systeme Nachrichten formatieren, Austausch beginnen/beenden, mit fehlenden Daten umgehen und Ziele identifizieren. Plattformen sind auf Protokolle angewiesen, weil sie Interoperabilität vorhersagbar machen — so können unabhängige Teams und Anbieter integrieren, ohne individuelle Sondervereinbarungen zu treffen.
Internetworking bedeutet, mehrere unabhängige Netze so zu verbinden, dass Pakete sie als eine durchgehende Reise durchqueren können. Das zentrale Problem war, dies zu erreichen, ohne irgendein Netz zu zwingen, seine internen Systeme umzuschreiben — deshalb wurde eine gemeinsame Schicht (IP) so wichtig.
Bei der Paketvermittlung werden Daten in Pakete zerlegt, die sich Netzressourcen mit anderem Verkehr teilen — das ist effizient für das burstartige Kommunikationsverhalten von Computern. Die Leitungsvermittlung reserviert hingegen eine dedizierte Route von Ende zu Ende, was bei intermittierendem Verkehr (wie bei den meisten Web/App-Workloads) verschwenderisch sein kann.
IP übernimmt Adressierung und Routing (Pakete hop-by-hop bewegen). TCP sitzt über IP und stellt Zuverlässigkeit bereit, wenn sie benötigt wird (Reihenfolge, Neusendungen, Fluss-/Verbindungskontrolle). Diese Trennung erlaubt es dem Netz, allgemein zu bleiben, während Anwendungen die gewünschten Liefergarantien wählen.
„Best‑Effort“ bedeutet, dass IP versucht, Pakete zu liefern, aber nicht garantiert, dass sie ankommen, in Reihenfolge sind oder pünktlich eintreffen. Diese Einfachheit senkte die Eintrittshürde für Netzwerke (nicht überall waren strikte Garantien nötig), was die Verbreitung beschleunigte und globale Konnektivität auch über unvollkommene Verbindungen ermöglicht hat.
Das End‑to‑End‑Prinzip besagt, dass der Kern des Netzes so wenig wie möglich tun sollte und die Intelligenz an den Endpunkten/bei den Anwendungen liegen sollte (Zuverlässigkeit, Sicherheit, Wiederherstellung). Der Nutzen ist schnellere Innovation an den Rändern; die Kosten sind, dass Anwendungen explizit mit Ausfällen, Missbrauch und Variabilität umgehen müssen.
Adressen identifizieren Ziele; Routing entscheidet den nächsten Hop in Richtung dieser Ziele. Hierarchische Adressierung erlaubt Aggregation von Routen, wodurch Routingtabellen auf globaler Ebene handhabbar bleiben. Schlechte Aggregation erhöht den Betriebsaufwand und belastet das Routing-System.
DNS bildet menschenlesbare Namen (wie api.example.com) auf IP-Adressen ab und kann diese Zuordnungen verändern, ohne dass Clients angepasst werden müssen. Plattformen nutzen DNS für Traffic-Steuerung, Multi‑Region‑Deployments und Failover — der Name bleibt stabil, auch wenn sich die Infrastruktur darunter ändert.
RFCs veröffentlichen das Protokollverhalten offen, sodass jede*r es implementieren und auf Kompatibilität prüfen kann. Diese Offenheit reduziert Vendor-Lock‑in, erhöht Multi‑Vendor‑Interoperabilität und erzeugt Netzwerkeffekte: jede zusätzliche kompatible Implementierung erhöht den Wert des gesamten Ökosystems.
Bau die Software so, als ob das Netz unzuverlässig ist:
Für weiterführende Hinweise siehe /blog/versioning-and-backward-compatibility und /blog/graceful-degradation-patterns.