01. Sept. 2025·8 Min
Von der Idee zur Live‑App in einem KI‑gestützten Workflow
Eine praktische, End‑to‑End‑Erzählung, wie man von einer App‑Idee zu einem bereitgestellten Produkt in einem KI‑gestützten Workflow kommt—Schritte, Prompts und Prüfungen.
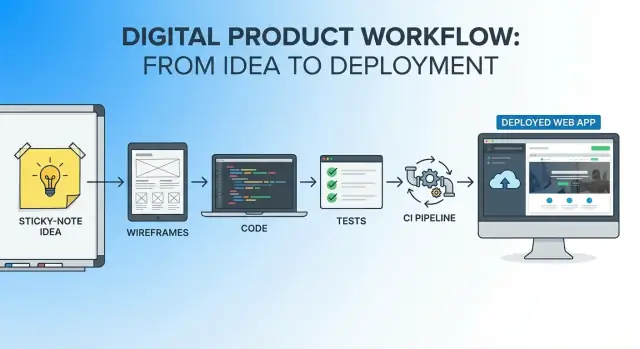
Eine praktische, End‑to‑End‑Erzählung, wie man von einer App‑Idee zu einem bereitgestellten Produkt in einem KI‑gestützten Workflow kommt—Schritte, Prompts und Prüfungen.
Stell dir eine kleine, nützliche App-Idee vor: ein „Queue Buddy“, mit dem ein Café-Mitarbeiter per Knopfdruck einen Kunden zur Warteliste hinzufügt und automatisch per SMS benachrichtigt wird, wenn der Tisch frei ist. Die Erfolgsmetrik ist einfach und messbar: reduziere verwirrende Anruf‑Nachfragen wegen Wartezeit um 50% in zwei Wochen, und die Einarbeitung des Personals soll unter 10 Minuten bleiben.
Das ist der Geist dieses Artikels: nimm eine klare, begrenzte Idee, definiere, wie „gut“ aussieht, und gehe dann vom Konzept zur Live‑Bereitstellung, ohne ständig Tools, Dokumente und Denkmodelle zu wechseln.
Ein einzelner Workflow ist ein durchgehender Faden vom ersten Satz der Idee bis zur ersten Produktionsfreigabe:
Du verwendest weiterhin mehrere Tools (Editor, Repo, CI, Hosting), aber du „startest“ das Projekt in keiner Phase neu. Die gleiche Erzählung und die gleichen Einschränkungen begleiten dich durch alle Schritte.
KI ist am wertvollsten, wenn sie:
Aber sie trifft nicht die Produktentscheidungen. Du tust das. Der Workflow ist so aufgebaut, dass du stets überprüfst: Bewegt diese Änderung die Metrik? Ist es sicher, sie auszuliefern?
In den nächsten Abschnitten gehst du Schritt für Schritt vor:
Am Ende solltest du einen wiederholbaren Weg haben, von „Idee“ zur „Live‑App“ zu kommen, während Scope, Qualität und Lernen eng verbunden bleiben.
Bevor du die KI bittest, Bildschirme, APIs oder Datenbanken zu entwerfen, brauchst du ein präzises Ziel. Ein wenig Klarheit hier spart Stunden mit „fast richtigen“ Outputs später.
Du baust eine App, weil eine bestimmte Personengruppe immer wieder auf die gleiche Reibung stößt: sie können eine wichtige Aufgabe nicht schnell, zuverlässig oder mit Vertrauen mit den vorhandenen Mitteln erledigen. Ziel von Version 1 ist, einen schmerzhaften Schritt in diesem Workflow zu entfernen—ohne zu versuchen, alles zu automatisieren—sodass Nutzer in Minuten von „Ich muss X tun“ zu „X ist erledigt“ gelangen, mit einer klaren Aufzeichnung dessen, was passiert ist.
Wähle einen primären Nutzer. Sekundäre Nutzer können warten.
Annahmen sind oft der Ort, an dem gute Ideen still scheitern—mach sie sichtbar.
Version 1 sollte ein kleiner Erfolg sein, den du ausliefern kannst:
Ein leichtgewichtiges Anforderungsdokument (denk: eine Seite) ist die Brücke von „coole Idee“ zu „baubarem Plan“. Es hält dich fokussiert, gibt deiner KI‑Assistenz den richtigen Kontext und verhindert, dass die erste Version in ein monatelanges Projekt aufbläht.
Halte es knapp und übersichtlich. Ein einfaches Template:
Schreibe maximal 5–10 Features, formuliert als Outcomes. Dann priorisiere sie:
Diese Priorisierung steuert auch, welche KI‑generierten Pläne und Codes du zulässt: „Implementiere zunächst nur Must‑haves.“
Für die Top‑3–5 Features füge 2–4 Akzeptanzkriterien hinzu. Verwende einfache Sprache und testbare Aussagen.
Beispiel:
Schließe mit einer kurzen Liste „Offene Fragen“—Dinge, die du per Chat, Nutzeranruf oder kurzer Recherche beantworten kannst.
Beispiele: „Brauchen Nutzer Google‑Login?“ „Welche Minimaldaten müssen gespeichert werden?“ „Benötigen wir Admin‑Freigabe?“
Dieses Dokument ist kein Papierkram; es ist die gemeinsame Quelle der Wahrheit, die du während des Builds weiter aktualisierst.
Bevor du die KI bittest, Screens zu generieren, bring die Produkt‑Geschichte in Ordnung. Eine schnelle Journey‑Skizze hält alle auf dem gleichen Stand: was der Nutzer erreichen will, wie „Erfolg“ aussieht und wo etwas schiefgehen kann.
Beginne mit dem Happy Path: der einfachste Ablauf, der den Hauptnutzen liefert.
Beispiel‑Flow (generisch):
Dann ergänze ein paar Edge‑Cases, die wahrscheinlich und kostenintensiv sind, wenn sie schlecht behandelt werden:
Du brauchst kein großes Diagramm. Eine nummerierte Liste plus Notizen reicht, um Prototyping und Code‑Generierung zu steuern.
Schreibe für jeden Screen eine kurze „Job to be done“. Bleib outcome‑orientiert statt UI‑orientiert.
Wenn du mit KI arbeitest, wird diese Liste zu hervorragendem Prompt‑Material: „Generiere ein Dashboard, das X, Y, Z unterstützt und Empty/Loading/Error‑States enthält.“
Halte es auf einem hohen Level—genug für Screens und Flows:
Notiere Beziehungen (User → Projects → Tasks) und alles, was Berechtigungen beeinflusst.
Markiere Punkte, an denen Fehler Vertrauen zerstören:
Es geht nicht um Over‑Engineering—sondern darum, die Überraschungen zu verhindern, die aus einer „funktionierenden Demo“ einen Support‑Albtraum machen.
Die Architektur für v1 sollte eine Sache gut können: dir erlauben, das kleinste nützliche Produkt auszuliefern, ohne dich einzuengen. Eine gute Regel ist „ein Repo, ein deploybares Backend, ein deploybares Frontend, eine Datenbank“—und erst zusätzliche Teile hinzufügen, wenn eine klare Anforderung sie fordert.
Für eine typische Web‑App ist ein sinnvoller Default:
Halte die Anzahl der Services gering. Für v1 ist ein „modularer Monolith“ (gut organisierter Code, aber ein Backend‑Service) meist einfacher als Microservices.
Wenn du eine KI‑first‑Umgebung bevorzugst, in der Architektur, Tasks und generierter Code eng verbunden bleiben, können Plattformen wie Koder.ai passen: du beschreibst den v1‑Scope im Chat, iterierst in „Planning Mode“ und generierst dann z. B. ein React‑Frontend mit Go + PostgreSQL‑Backend—bei gleichzeitiger Kontrolle und Review.
Bevor du Code generierst, schreibe eine winzige API‑Tabelle, damit du und die KI das gleiche Ziel haben. Beispiel‑Shape:
GET /api/projects → { items: Project[] }POST /api/projects → { project: Project }GET /api/projects/:id → { project: Project, tasks: Task[] }POST /api/projects/:id/tasks → { task: Task }Füge Hinweise zu Statuscodes, Fehlerformat (z. B. { error: { code, message } }) und Pagination hinzu.
Wenn v1 öffentlich oder Single‑User sein kann, überspringe Auth und liefere schneller. Wenn Konten nötig sind, nutze einen Managed‑Provider (Magic Link per E‑Mail oder OAuth) und halte Berechtigungen simpel: „User besitzt seine Datensätze.“ Vermeide komplexe Rollen, bis reale Nutzung es fordert.
Dokumentiere ein paar praktische Vorgaben:
Diese Notizen leiten die KI‑gestützte Code‑Generierung in Richtung Deploybarkeit, nicht nur Funktionalität.
Die schnellste Art, Momentum zu killen, ist eine Woche über Tools zu diskutieren und trotzdem keinen lauffähigen Code zu haben. Dein Ziel: ein „hello app“, das lokal startet, einen sichtbaren Screen hat und eine Anfrage annehmen kann—während alles klein genug bleibt, um leicht zu prüfen.
Gib der KI einen straffen Prompt: Framework‑Wahl, Grundseiten, ein Stub‑API und die erwarteten Dateien. Du suchst vorhersehbare Konventionen, nicht Cleverness.
Eine gute erste Struktur ist:
/README.md
/.env.example
/apps/web/
/apps/api/
/package.json
Wenn du ein Single‑Repo nutzt, fordere Basis‑Routen (z. B. / und /settings) und einen API‑Endpoint (z. B. GET /health oder GET /api/status). Das reicht, um die Verkabelung zu beweisen.
Wenn du Koder.ai nutzt, ist das auch ein natürlicher Startpunkt: bitte um ein minimales „web + api + database‑ready“ Skeleton, und exportiere den Source, wenn Struktur und Konventionen passen.
Halte das UI absichtlich langweilig: eine Seite, ein Button, ein Request.
Beispielverhalten:
Das gibt dir eine unmittelbare Feedback‑Schleife: lädt die UI, aber der Call schlägt fehl, weißt du genau, wo du suchen musst (CORS, Port, Routing, Netzwerkfehler). Vermeide Auth, Datenbanken oder komplexen State hier—das kommt, wenn das Skeleton stabil ist.
Lege .env.example am ersten Tag an. Es verhindert „läuft nur auf meinem Rechner“‑Probleme und macht Onboarding einfach.
Beispiel:
WEB_PORT=3000
API_PORT=4000
API_URL=http://localhost:4000
Mach das README so, dass es in unter einer Minute ausführbar ist:
.env.example nach .env kopierenBehandle diese Phase wie das Ziehen sauberer Fundamentlinien. Committe nach jedem kleinen Erfolg: „init repo“, „add web shell“, „add api health endpoint“, „wire web to api“. Kleine Commits machen KI‑gestützte Iteration sicherer: geht eine generierte Änderung schief, kannst du revertieren, ohne einen Tag zu verlieren.
Wenn das Skeleton End‑to‑End läuft, widerstehe dem Drang, „alles zu beenden“. Baue stattdessen eine schmale vertikale Scheibe, die DB, API und UI berührt, und wiederhole das. Dünne Slices halten Reviews schnell, Bugs klein und KI‑Assistenz leichter verifizierbar.
Wähle das eine Modell, ohne das deine App nicht funktioniert—oft das „Ding“, das Nutzer erstellen oder verwalten. Definiere es klar (Felder, Pflicht vs. optional, Defaults) und füge Migrationen hinzu, wenn du eine relationale DB nutzt. Halte die erste Version unspektakulär: vermeide clevere Normalisierung und vorschnelle Flexibilität.
Wenn du die KI das Modell entwerfen lässt, bitte sie, jedes Feld und jeden Default in einem Satz zu begründen. Alles, was sie nicht in einem Satz erklären kann, gehört wahrscheinlich nicht in v1.
Erstelle nur die Endpunkte, die für die erste User‑Journey nötig sind: meist Create, Read und ein minimales Update. Platziere Validierung nah an der Grenze (Request DTO/Schema) und mache Regeln explizit:
Validierung ist Teil des Features, nicht nur Politur—sie verhindert chaotische Daten, die dich später ausbremsen.
Behandle Fehlermeldungen als Debug‑/Support‑UX. Gib klare, handhabbare Meldungen zurück (was ist schiefgelaufen und wie behebe ich es), ohne sensible Details an den Client zu leaken. Logge technischen Kontext serverseitig mit einer Request‑ID, damit du Vorfälle ohne Rätselraten nachverfolgen kannst.
Bitte die KI um inkrementelle PR‑große Änderungen: eine Migration + ein Endpoint + ein Test pro Änderung. Reviewe Diffs wie bei einem Teamkollegen: prüfe Namensgebung, Edge‑Cases, Sicherheitsannahmen und ob die Änderung wirklich den Nutzer‑„kleinen Erfolg“ unterstützt. Fügt sie Features hinzu, kürze sie und mach weiter.
v1 braucht keine Enterprise‑Sicherheit—aber es muss die vorhersehbaren Fehler vermeiden, die eine vielversprechende App in Support‑Hölle verwandeln. Das Ziel ist „sicher genug": schlechte Eingaben verhindern, standardmäßig Zugriff verweigern und eine brauchbare Spur hinterlassen, wenn etwas schiefgeht.
Behandle jede Grenze als untrusted: Formularfelder, API‑Payloads, Query‑Parameter und sogar interne Webhooks. Validier Typ, Länge und erlaubte Werte, normalisiere Daten (Strings trimmen, Casing konvertieren), bevor du speicherst.
Einige praktische Defaults:
Wenn du KI nutzt, um Handler zu generieren, bitte sie, Validierungsregeln explizit zu nennen (z. B. „max 140 chars“ oder „muss eines von: … sein“) statt nur „validiere Input“.
Ein einfaches Berechtigungsmodell reicht meist für V1:
Mach Ownership‑Checks zentral und wiederverwendbar (Middleware/Policy‑Funktionen), sodass du nicht überall if userId == … verstreust.
Gute Logs beantworten: Was ist passiert, bei wem und wo? Inklusive:
update_project, project_id)Logge Events, keine Geheimnisse: niemals Passwörter, Tokens oder vollständige Zahlungsdaten schreiben.
Bevor du die App als „sicher genug“ deklarierst, prüfe:
Testen ist nicht Jagd nach perfekter Coverage—es geht darum, Fehler zu verhindern, die Nutzer schädigen, Vertrauen zerstören oder teure Feuerwehreinsätze auslösen. In einem KI‑gestützten Workflow dienen Tests auch als „Vertrag“, der generierten Code mit deiner Absicht in Einklang hält.
Identifiziere, wo Fehler teuer wären: Geld/ Credits, Berechtigungen, Datentransformationen und Randfallvalidierung. Schreibe zuerst Unit‑Tests für diese Bereiche. Halte sie klein und präzise: Für Input X erwartest du Output Y (oder einen Fehler). Wenn eine Funktion zu viele Verzweigungen hat, ist das ein Hinweis, sie zu vereinfachen.
Unit‑Tests finden Logikfehler; Integrationstests fangen „Verdrahtungsfehler“—Routen, DB‑Aufrufe, Auth‑Checks und das Zusammenspiel mit der UI—auf.
Wähle die Kern‑Journey und automatisiere sie End‑to‑End:
Ein paar solide Integrationstests verhindern oft mehr Vorfälle als Dutzende kleine Tests.
KI ist gut darin, Test‑Scaffolds und Edge‑Cases aufzulisten. Bitte sie um:
Überprüfe jede generierte Assertion: Tests sollten Verhalten prüfen, nicht Implementierungsdetails. Wenn ein Test nach einem Bug noch grün wäre, erfüllt er seinen Zweck nicht.
Setze ein moderates Ziel (z. B. 60–70% auf Kern‑Modulen) und nutze es als Leitplanke, nicht als Pokal. Fokus auf stabile, schnelle Tests in CI, die aus berechtigten Gründen fehlschlagen. Flaky Tests untergraben Vertrauen—und wenn niemand dem Testsuite vertraut, schützt sie dich nicht mehr.
Automation ist der Punkt, an dem ein KI‑gestützter Workflow aus „läuft auf meinem Rechner“ ein Prozess wird, den du mit Vertrauen ausrollen kannst. Ziel ist Wiederholbarkeit, nicht schicke Tools.
Wähle einen einzelnen Befehl, der lokal und in CI dasselbe Ergebnis liefert. Für Node könnte das npm run build sein; für Python ein make build; für Mobile ein definierter Gradle/Xcode‑Step.
Trenne früh Development‑ und Production‑Konfiguration. Eine einfache Regel: Dev‑Defaults sind bequem; Prod‑Defaults sind sicher.
{
"scripts": {
"lint": "eslint .",
"format": "prettier -w .",
"test": "vitest run",
"build": "vite build"
}
}
Ein Linter fängt riskante Muster (unused variables, unsichere async‑Aufrufe). Ein Formatter verhindert Stil‑Debatten als laute Diffs in Reviews. Halte Regeln moderat für v1, aber setze sie konsistent durch.
Praktische Gate‑Reihenfolge:
Der erste CI‑Workflow kann klein sein: Dependencies installieren, Gates ausführen, schnell failen. Das verhindert, dass kaputter Code unbemerkt landet.
name: ci
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npm run format -- --check
- run: npm run lint
- run: npm test
- run: npm run build
Lege fest, wo Secrets leben: CI‑Secret‑Store, Passwortmanager oder die Deploy‑Plattform. Niemals in Git committen—füge .env zu .gitignore hinzu und liefere .env.example mit sicheren Platzhaltern.
Wenn du weitergehen willst, connecte diese Gates an deinen Deployment‑Prozess, sodass „grüner CI“ der einzige Weg in Produktion ist.
Releasen ist kein einmaliger Klick—es ist eine wiederholbare Routine. Ziel für v1: wähle ein Deployment‑Ziel, das zu deinem Stack passt, deploye in kleinen Schritten und habe immer einen Weg zurück.
Wähle eine Plattform passend zur App:
Für v1 übertrifft „einfach wieder‑deploybar“ oft „maximale Kontrolle“. Plattformen, die Build + Hosting + Rollback bieten, machen Releases zu reversiblen Schritten. Beispielsweise unterstützt Koder.ai Deployments und Hosting samt Snapshots und Rollback‑Mechaniken.
Schreibe die Checkliste einmal und verwende sie bei jedem Release. Kurz genug, dass Leute sie tatsächlich anwenden:
Wenn du sie im Repo (z. B. /docs/deploy.md) ablegst, bleibt sie automatisch nahe am Code.
Erzeuge einen leichten Endpoint, der beantwortet: „Ist die App up und kann sie ihre Abhängigkeiten erreichen?“
Gängige Patterns:
GET /health für Load Balancer und Uptime‑MonitoreGET /status mit Basis App‑Version + Dependency‑ChecksAntworten sollten schnell, cache‑frei und sicher sein (keine Secrets).
Ein Rollback‑Plan sollte explizit sein:
Wenn Deployment reversibel ist, wird Releasen zur Routine—du kannst öfter und mit weniger Stress ausliefern.
Der Launch ist der Beginn der nützlichsten Phase: lernen, was echte Nutzer tun, wo die App bricht und welche kleinen Änderungen die Erfolgsmetrik bewegen. Ziel ist, den gleichen KI‑gestützten Workflow weiterzuverwenden—nun basierend auf Evidenz statt Annahmen.
Starte mit einem minimalen Monitoring‑Stack, der drei Fragen beantwortet: Ist sie up? Fällt sie aus? Ist sie langsam?
Uptime‑Checks können einfach sein (periodischer Hit auf Health‑Endpoint). Error‑Tracking sollte Stacktraces und Request‑Kontext erfassen (ohne sensible Daten). Performance‑Monitoring beginnt mit Antwortzeiten für Schlüssel‑Endpoints und Frontend‑Page‑Load‑Metriken.
Lass die KI helfen, indem sie erzeugt:
Tracke nicht alles—tracke, was beweist, dass die App funktioniert. Definiere eine primäre Erfolgsmetrik (z. B. „abgeschlossener Checkout“, „erstes Projekt erstellt“ oder „Teammitglied eingeladen"). Instrumentiere ein kleines Funnel: Entry → Key Action → Success.
Bitte die KI, Event‑Namen und Properties vorzuschlagen, und prüfe sie dann auf Datenschutz und Klarheit. Halte Events stabil; wöchentliche Namensänderungen machen Trends praktisch wertlos.
Erzeuge einen einfachen Intake: In‑App‑Feedback‑Button, eine kurze E‑Mail‑Alias und ein leichtgewichtiges Bug‑Template. Triage wöchentlich: Themen clustern, Analytics zuordnen und die nächsten 1–2 Verbesserungen festlegen.
Behandle Monitoring‑Alerts, Analytics‑Drops und Feedback‑Themen wie neue „Requirements“. Führe sie in denselben Prozess: Dokument aktualisieren, kleinen Change‑Vorschlag generieren, in dünnen Slices implementieren, gezielten Test hinzufügen und via demselben reversiblen Release‑Prozess deployen. Für Teams hält eine gemeinsame „Learning Log“‑Seite Entscheidungen sichtbar und reproduzierbar.
Ein „Single Workflow“ ist ein durchgehender Faden von der Idee bis zur Produktion, bei dem:
Du kannst weiterhin mehrere Tools verwenden, vermeide aber, das Projekt in jeder Phase „neu zu starten“.
Nutze KI, um Optionen und Entwürfe zu erzeugen — du triffst die Entscheidungen und prüfst sie:
Halte die Entscheidungsregel fest: „Bewegt das die Metrik, und ist es sicher auszuliefern?“
Definiere eine messbare Erfolgsmetrik und eine enge v1-„Definition of done“. Beispiel:
Wenn ein Feature diese Outcomes nicht unterstützt, ist es ein Non-Goal für v1.
Halte es auf eine gut lesbare, einseitige PRD-Form:
Füge dann 5–10 Kern-Features hinzu, maximal, und bewerte sie Must/Should/Nice. Nutze diese Priorisierung, um KI-generierte Pläne und Code zu begrenzen.
Für die Top-3–5 Features ergänze 2–4 testbare Aussagen pro Feature. Gute Akzeptanzkriterien sind:
Beispielmuster: Validierungsregeln, erwartete Redirects, Fehlermeldungen und Berechtigungsverhalten (z. B. „nicht autorisierte Nutzer sehen eine klare Fehlermeldung und keine Datenlecks“).
Beginne mit einem nummerierten Happy-Path und liste dann einige wahrscheinliche, kostenintensive Fehlerfälle:
Eine einfache Liste reicht; Ziel ist die Steuerung von UI-Zuständen, API-Antworten und Tests.
Für v1 empfiehlt sich meist ein „modularer Monolith“:
Füge erst dann Services hinzu, wenn eine Anforderung es zwingend macht. Das reduziert Koordinationsaufwand und macht KI-gestützte Iteration leichter prüfbar und revertierbar.
Schreibe vor der Code-Generierung eine kleine API‑Contract‑Tabelle:
{ error: { code, message } })Das verhindert Diskrepanzen zwischen UI und Backend und gibt Tests ein stabiles Ziel.
Ziele auf eine „Hello App“, die die Infrastruktur beweist:
/health) aufruft.env.example und ein README, das in unter einer Minute startbar istCommitte kleine Meilensteine früh, damit du sicher zurückrollen kannst, wenn eine generierte Änderung Probleme macht.
Priorisiere Tests, die teure Fehler verhindern:
In CI setze einfache Gates in konstanter Reihenfolge durch:
Halte Tests stabil und schnell; flackernde Suiten verlieren Vertrauen und hören auf zu schützen.