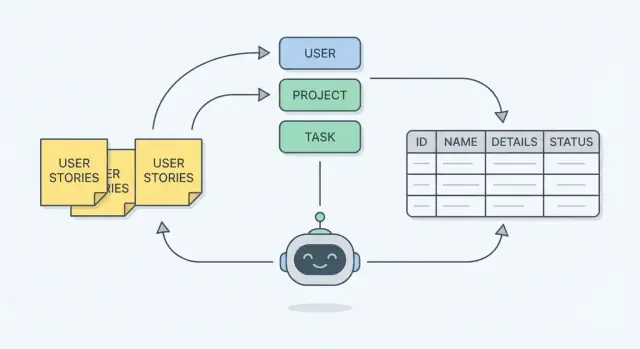
Was Sie bauen: Ein Schema, das echte Arbeit abbildet
Ein Datenbankschema ist der Plan dafür, wie Ihre App Dinge erinnert. Praktisch ist es:
- Tabellen: die „Behälter“ von Informationen (Customers, Orders, Tickets)
- Felder (Spalten): die Details, die Sie über jedes Ding speichern (customer_name, order_date)
- Beziehungen: wie Behälter verbunden sind (eine Bestellung gehört zu einem Kunden; ein Kunde kann viele Bestellungen haben)
Wenn das Schema die echte Arbeit abbildet, spiegelt es wider, was Menschen tatsächlich tun — erstellen, prüfen, genehmigen, planen, zuweisen, stornieren — und nicht nur das, was auf einem Whiteboard ordentlich aussieht.
Warum bei User Stories anfangen?
User Stories und Akzeptanzkriterien beschreiben reale Bedürfnisse in klarer Sprache: wer was tut und was „fertig“ bedeutet. Wenn Sie diese als Ausgangspunkt nutzen, übersieht das Schema seltener wichtige Details (z. B. „wir müssen verfolgen, wer die Rückerstattung genehmigt hat“ oder „eine Buchung kann mehrfach verschoben werden").
Vom Story‑Ausgangspunkt aus bleiben Sie auch ehrlich bezüglich Umfang: Wenn etwas nicht in den Stories (oder dem Workflow) steht, behandeln Sie es als optional statt stillschweigend ein kompliziertes Modell „für alle Fälle“ zu bauen.
Was KI hier kann und nicht kann
KI kann Ihnen helfen, schneller voranzukommen, indem sie:
- Kandidaten‑Entitäten aus den Stories extrahiert (wichtige „Dinge")
- Felder vorschlägt, die durch Akzeptanzkriterien impliziert werden (Zeitstempel, Status, Referenzen)
- wahrscheinliche Beziehungen und Lücken aufzeigt (z. B. „es werden Genehmigungen erwähnt, aber kein Genehmiger gespeichert“)
KI kann nicht zuverlässig:
- Ihre versteckten Geschäftsregeln oder Randfälle kennen, die Sie nicht aufgeschrieben haben
- ohne Trade‑Offs (einfach vs. flexibel) das „richtige“ Detaillierungsniveau wählen
- garantieren, dass das Schema Reporting-, Sicherheits‑ oder Compliance‑Anforderungen erfüllt
Behandeln Sie KI als starken Assistenten, nicht als Entscheidungsträger.
Wenn Sie diesen Assistenten in echte Geschwindigkeit verwandeln wollen, kann eine Vibe‑Coding‑Plattform wie Koder.ai Ihnen helfen, schneller von Schema‑Entscheidungen zu einer funktionierenden React + Go + PostgreSQL App zu kommen — und dabei bleiben Sie in Kontrolle über Modell, Constraints und Migrationen.
Erwartungen setzen: iterativ, nicht einmalig
Schema‑Design ist ein Loop: Entwurf → Test gegen Stories → fehlende Daten finden → verfeinern. Ziel ist nicht ein perfektes erstes Ergebnis; Ziel ist ein Modell, das Sie jeder User Story zuordnen können und zuversichtlich sagen: „Ja, wir können alles speichern, was dieser Workflow braucht — und wir können erklären, warum jede Tabelle existiert."
Bevor Sie Anforderungen in Tabellen verwandeln, klären Sie, was Sie modellieren. Ein gutes Schema beginnt selten bei null — es beginnt mit konkreter Arbeit und dem Beweis, den Sie später brauchen (Screens, Outputs und Randfälle).
User Stories sind die Überschrift, aber allein nicht genug. Sammeln Sie:
- User Stories + Rollen (wer tut was und warum)
- Akzeptanzkriterien (die „muss wahr sein“-Regeln)
- Formulare/Screens (Felder, die Nutzer eingeben, wählen oder sehen)
- Reports/Exports (was zusammengefasst, gruppiert oder gefiltert werden muss)
- Reale Beispiele (Beleg‑Bestellungen, Rechnungen, Tickets, Kalender — alles Repräsentative)
Wenn Sie KI nutzen, halten diese Inputs das Modell geerdet. KI kann Entitäten und Felder schnell vorschlagen, benötigt aber reale Artefakte, um nicht eine Struktur zu erfinden, die nicht zu Ihrem Produkt passt.
Akzeptanzkriterien: die versteckte Quelle von Constraints
Akzeptanzkriterien enthalten oft die wichtigsten Datenbankregeln, selbst wenn sie Daten nicht explizit erwähnen. Achten Sie auf Formulierungen wie:
- „E‑Mail muss eindeutig sein“ (Eindeutigkeit)
- „Status kann Draft, Submitted, Approved sein“ (erlaubte Werte)
- „Nur Manager können genehmigen“ (Berechtigungen, eventuell Audit‑Felder)
- „Eine Rechnung mit Zahlungen kann nicht gelöscht werden“ (Referentielle Regeln)
Häufige Fallstricke früh beheben
Vage Stories („Als Nutzer kann ich Projekte verwalten") verbergen oft mehrere Entitäten und Workflows. Eine weitere Lücke sind fehlende Randfälle wie Stornierungen, Wiederholungen, Teilrückerstattungen oder Neuzuweisungen.
Kurze Story‑Qualitäts‑Checkliste (vor dem Modellieren)
- Der Akteur/Rolle ist explizit.
- Das Objekt ist spezifisch (nicht „Daten“ oder „Dinge“).
- Mindestens ein reales Beispiel existiert.
- Akzeptanzkriterien enthalten Validierungen und Grenzen.
- Fehler‑ und „Was‑wenn“‑Fälle sind genannt (oder ausdrücklich vertagt).
Bevor Sie an Tabellen oder Diagramme denken, lesen Sie die User Stories und markieren Sie die Nomen. In der Anforderungsanalyse deuten Nomen meist auf die „Dinge“ hin, die Ihr System merken muss — diese werden oft zu Entitäten im Schema.
Ein schnelles Gedankenmodell: Nomen → Entitäten, während Verben → Aktionen/Workflows. Wenn eine Story sagt „Ein Manager weist einem Techniker einen Auftrag zu“, sind die wahrscheinlichen Entitäten manager, technician und job — und „weist zu“ deutet auf eine Beziehung hin, die Sie später modellieren.
Woran Sie erkennen, ob ein Nomen eine echte Entität ist
Nicht jedes Nomen braucht eine eigene Tabelle. Ein Nomen ist ein starker Entitätskandidat, wenn es:
- eine eigene Identität hat: Sie können auf eine einzelne Instanz verweisen (Job #1042, Kunde A)
- sich über die Zeit ändert: es hat einen Lifecycle (ein Auftrag geht von geplant → abgeschlossen)
- an mehreren Stellen verwendet wird: mehrere Stories referenzieren es oder mehrere Workflows greifen darauf zu
Wenn ein Nomen nur einmal auftaucht oder nur etwas anderes beschreibt („rote Taste“, „Freitag“), ist es vielleicht keine Entität.
Attribut vs. eigene Entität (Der „Adresse“ und „Tag“ Test)
Ein häufiger Fehler ist, jedes Detail in eine Tabelle zu verwandeln. Faustregel:
- Wenn es ein Wert ist, der ein Ding beschreibt, ist es meist ein Attribut (z. B. Customer.phone_number).
- Wenn es wiederholbar, geteilt oder strukturiert ist, ist es oft eine separate Entität.
Zwei klassische Beispiele:
- Adresse: Wenn Sie Versand‑ und Rechnungsadressen speichern, Historie halten oder Adressen zwischen Kunden/Standorten teilen, ist
Address wahrscheinlich eine eigene Entität. Wenn Sie nur eine einzelne Postadresse benötigen und nie wiederverwenden, kann sie ein Attribut bleiben.
- Tag: Tags sind fast immer eigene Entitäten, weil sie wiederholbar und viele‑zu‑viele sind (ein Job hat viele Tags; ein Tag gehört zu vielen Jobs).
KI nutzen, um Kandidaten‑Entitäten vorzuschlagen (mit Vorsicht)
KI kann die Entitätenfindung beschleunigen, indem sie Stories scannt und eine Entitätsliste nach Themen (Personen, Arbeitselemente, Dokumente, Orte) zurückgibt. Ein nützlicher Prompt ist: „Extrahiere Nomen, die Daten darstellen, die wir speichern müssen, und gruppiere Duplikate/Synonyme."
Behandeln Sie die Ausgabe als Startpunkt, nicht als fertige Antwort. Stellen Sie Folgefragen wie:
- „Welche davon haben einen Lifecycle oder brauchen eine eigene ID?"
- „Welche sind tatsächlich Status, Kategorien oder Attribute?"
- „Gibt es Synonyme (z. B. ‘client’ vs. ‘customer’)?"
Ziel von Schritt 1 ist eine kurze, saubere Liste von Entitäten, die Sie durch direkte Story‑Belege verteidigen können.
Schritt 2 — Details in Felder verwandeln (Die Erinnerungen, die Sie speichern müssen)
Haben Sie die Entitäten benannt (z. B. Order, Customer, Ticket), ist der nächste Schritt, die Details zu erfassen, die Sie später brauchen. In einer Datenbank sind diese Details Felder (auch Attribute genannt) — die Erinnerungen, die Ihr System nicht vergessen darf.
Wie Sie Felder auswählen (ohne zu raten)
Beginnen Sie mit der User Story und lesen Sie die Akzeptanzkriterien als Checkliste dessen, was gespeichert werden muss.
Wenn eine Anforderung sagt „Nutzer können Bestellungen nach Lieferdatum filtern“, dann ist delivery_date kein optionales Feld — es muss existieren (oder zuverlässig aus anderen gespeicherten Daten abgeleitet werden). Wenn es heißt „Zeige, wer die Anfrage genehmigt hat und wann“, brauchen Sie wahrscheinlich approved_by und approved_at.
Ein praktischer Test: Braucht jemand diesen Wert, um etwas anzuzeigen, zu suchen, zu sortieren, zu auditieren oder zu berechnen? Wenn ja, gehört er wahrscheinlich als Feld in die Datenbank.
Einfache Regeln für saubere Felder
- Werte atomar halten: speichern Sie Vorname und Nachname separat, wenn Sie danach suchen oder sortieren wollen. Packen Sie keine Mehrfachwerte in ein Feld (z. B. „rot, blau“).
- Konsequente Typen verwenden: Daten als Datum, Geld als Decimal, Booleans als true/false — vermeiden Sie gemischte Formate wie „$10“, „10 USD“ und „10".
- Keine Texte duplizieren: kopieren Sie nicht die Adresse des Kunden in jede Bestellposition. Speichern Sie sie einmal und referenzieren Sie diese.
Kontrollierte Vokabulare: Status, Typen und Kategorien
Viele Stories enthalten Wörter wie „Status“, „Typ“ oder „Priorität“. Behandeln Sie diese als kontrollierte Vokabulare — eine begrenzte Menge erlaubter Werte.
Wenn die Menge klein und stabil ist, reicht oft ein Enum‑Feld. Wenn sie wachsen kann, Labels benötigt oder Berechtigungen erfordert (z. B. adminverwaltete Kategorien), nutzen Sie eine separate Lookup‑Tabelle (z. B. status_codes) und speichern eine Referenz.
So werden aus Stories verlässliche Felder — durchsuchbar, reportbar und schwer falsch einzugeben.
Schritt 3 — Entitäten mit Beziehungen verbinden
Haben Sie die Entitäten (User, Order, Invoice, Comment usw.) und deren Felder entworfen, verbinden Sie sie. Beziehungen sind die Ebene „wie diese Dinge interagieren“, die Ihre Stories implizieren.
One‑to‑one (1:1) bedeutet „ein Ding hat genau ein anderes".
- Story‑Phrase: „Jeder Nutzer hat ein Profil."
- Modellidee:
User ↔ Profile (oft lassen sich diese zusammenführen, sofern kein Trennungsgrund besteht).
One‑to‑many (1:N) bedeutet „ein Ding kann viele eines anderen haben." Das ist am häufigsten.
- Story‑Phrase: „Ein Nutzer kann viele Bestellungen haben."
- Modellidee:
User → Order (speichern Sie user_id auf Order).
Many‑to‑many (M:N) bedeutet „viele Dinge können mit vielen Dingen verbunden sein." Das benötigt eine zusätzliche Tabelle.
- Story‑Phrase: „Eine Bestellung kann viele Produkte enthalten, und ein Produkt kann in vielen Bestellungen sein."
Many‑to‑many: Der Join‑Table‑Trick
Datenbanken können keine sauberen „Listen von Produkt‑IDs“ in einer Spalte von Order speichern, ohne später Probleme zu bekommen. Stattdessen erstellen Sie eine Join‑Tabelle, die die Beziehung selbst repräsentiert.
Beispiel:
OrderProductOrderItem (Join‑Tabelle)
OrderItem enthält typischerweise:
order_idproduct_id- details aus der Story wie
quantity, unit_price, discount
Beachten Sie, wie Details aus der Story („quantity“) oft auf der Beziehung gehören, nicht auf einer der beiden Entitäten.
Pflicht vs. optional (ohne Fachchinesisch)
Stories sagen oft, ob eine Verbindung obligatorisch oder manchmal fehlen kann.
- „Eine Bestellung muss zu einem Nutzer gehören“ → jede
Order braucht ein user_id (nicht leer zulassen).
- „Ein Nutzer kann eine Telefonnummer haben“ →
phone kann leer sein.
- „Eine Bestellung kann eine Versandadresse haben (bei physischen Waren)" →
shipping_address_id kann bei digitalen Bestellungen leer sein.
Ein schneller Check: Wenn die Story impliziert, dass der Datensatz nicht ohne den Link erstellt werden kann, behandeln Sie ihn als erforderlich. Bei Formulierungen wie „kann“ oder mit Ausnahmen behandeln Sie ihn als optional.
Story‑Sätze in Beziehungssätze umformulieren
Wenn Sie eine Story lesen, schreiben Sie sie als einfache Paarung um:
- „Ein Nutzer kann viele Kommentare hinterlassen" →
User 1:N Comment
- „Ein Kommentar gehört zu einem Nutzer" →
Comment N:1 User
Machen Sie das für jede Interaktion in Ihren Stories. Am Ende haben Sie ein verbundenes Modell, das zeigt, wie die Arbeit wirklich abläuft — bevor Sie ein ER‑Tool öffnen.
Schritt 4 — Workflows nutzen, um Zustände, Ereignisse und Lücken zu finden
Ihre Codebasis behalten
Behalten Sie die Kontrolle, indem Sie den Quellcode exportieren, wann immer Sie tiefere Anpassungen benötigen.
User Stories sagen, was Leute wollen. Workflows zeigen, wie Arbeit tatsächlich fließt, Schritt für Schritt. Einen Workflow in Daten zu übersetzen ist einer der schnellsten Wege, „wir haben vergessen zu speichern“‑Probleme zu entdecken — bevor Sie bauen.
Beginnen Sie mit einem einfachen Workflow
Schreiben Sie den Workflow als Abfolge von Aktionen und Zustandswechseln. Zum Beispiel:
- Create request → Draft
- Submit request → Submitted
- Manager reviews → Approved oder Rejected
- If approved, work is scheduled → In progress
- Completed → Done
Diese fettgedruckten Wörter werden oft ein status‑Feld (oder eine kleine „state“‑Tabelle) mit klaren erlaubten Werten.
Workflows zeigen fehlende Felder auf
Wenn Sie jeden Schritt durchgehen, fragen Sie: „Was müssten wir später wissen?“ Workflows decken oft Felder auf wie:
- Zeitstempel:
submitted_at, approved_at, completed_at
- Zuständigkeit:
created_by, assigned_to, approved_by
- Grund/Kontext:
rejection_reason, approval_note
- Reihenfolge:
sequence für mehrstufige Prozesse
Wenn Ihr Workflow Warten, Eskalation oder Übergaben enthält, brauchen Sie meist mindestens einen Zeitstempel und ein Feld „wer hat es jetzt".
Workflows zeigen fehlende Tabellen auf
Manche Workflow‑Schritte sind nicht nur Felder — sie sind eigene Datenstrukturen:
- Audit Log / History für „wer hat wann den Status geändert"
- Approvals für Multi‑Approver oder bedingte Genehmigungen
- Attachments wenn Nutzer während eines Schrittes Dateien hochladen
- Comments wenn Diskussion Teil des Prozesses ist
KI zur Lückenprüfung einsetzen
Geben Sie KI sowohl: (1) die User Stories und Akzeptanzkriterien als auch (2) die Workflow‑Schritte. Bitten Sie sie, jeden Schritt aufzulisten und die benötigten Daten für jeden Schritt zu identifizieren (State, Actor, Timestamps, Outputs) und dann jede Anforderung hervorzuheben, die durch die aktuellen Felder/Tabellen nicht abgedeckt ist.
In Plattformen wie Koder.ai wird diese „Gap Check“ praktisch, weil Sie schnell iterieren können: Schema‑Annahmen anpassen, Scaffolding neu erzeugen und ohne langen Umweg weiterarbeiten.
Schlüssel, Eindeutigkeit und Grundlegende Constraints (ohne Fachchinesisch)
Beim Überführen von Stories in Tabellen legen Sie nicht nur Felder fest — Sie entscheiden auch, wie Daten über die Zeit identifizierbar und konsistent bleiben.
Primärschlüssel: eine stabile "Ausweisnummer" für jede Zeile
Ein Primärschlüssel identifiziert eindeutig einen Datensatz — denken Sie an die permanente ID‑Karte der Zeile.
Warum jede Zeile eine braucht: Stories implizieren Updates, Referenzen und Historie. Wenn eine Story sagt „Support kann eine Bestellung ansehen und eine Rückerstattung ausstellen“, brauchen Sie eine stabile Möglichkeit, die Bestellung zu referenzieren — auch wenn der Kunde seine E‑Mail ändert, die Adresse editiert wird oder der Bestellstatus wechselt.
In der Praxis ist das meist ein internes id (Nummer oder UUID), das nie ändert.
Fremdschlüssel: Verweise zwischen Tabellen
Ein Fremdschlüssel ist, wie eine Tabelle sicher auf eine andere zeigt. Wenn orders.customer_id auf customers.id referenziert, kann die Datenbank erzwingen, dass jede Bestellung zu einem echten Kunden gehört.
Das passt zu Stories wie „Als Nutzer sehe ich meine Rechnungen.“ Die Rechnung hängt an einem Kunden (und oft an einer Bestellung oder Subscription).
Eindeutigkeitsregeln: „muss eindeutig sein" durchsetzen
User Stories enthalten oft versteckte Eindeutigkeitsanforderungen:
- „Nutzer melden sich mit E‑Mail an" → durchsetzen: eindeutige E‑Mail (oder eindeutig pro Mandant bei Multi‑Tenant)
- „Finanzen sucht nach Rechnungsnummer" → durchsetzen: eindeutige invoice_number
Diese Regeln verhindern verwirrende Duplikate, die später als „Datenfehler" auftauchen.
Indexierung (hochlevel): häufige Lookups schnell machen
Indizes beschleunigen Abfragen wie „Finde Kunde per E‑Mail" oder „liste Bestellungen nach Kunde". Beginnen Sie mit Indizes, die Ihren häufigsten Abfragen und Eindeutigkeitsregeln entsprechen.
Was Sie aufschieben sollten: schwere Indizierung für seltene Reports oder spekulative Filter. Notieren Sie solche Bedürfnisse in Stories, validieren Sie erst das Schema und optimieren Sie dann auf Basis realer Nutzung und langsamer Abfragen.
Daten konsistent halten: Eine praktische Normalisierungs‑Checkliste
Schema ohne Risiko ändern
Iterieren Sie sicher mit Snapshots und Rollback, während Sie Tabellen und Constraints anpassen.
Normalization hat ein einfaches Ziel: widersprüchliche Duplikate verhindern. Wenn dieselbe Tatsache an zwei Orten gespeichert werden kann, wird sie früher oder später auseinanderlaufen (zwei Schreibweisen, zwei Preise, zwei „aktuelle“ Adressen). Ein normalisiertes Schema speichert jede Tatsache einmal und referenziert sie.
Kurze Checkliste für jeden Entwurf
1) Auf wiederholte Gruppen achten
Wenn Sie Muster wie „Phone1, Phone2, Phone3" oder „ItemA, ItemB, ItemC" sehen, ist das ein Signal für eine separate Tabelle (z. B. CustomerPhones, OrderItems). Wiederholte Gruppen erschweren Suche, Validierung und Skalierung.
2) Keine Namens‑/Detailkopien in mehreren Tabellen
Wenn CustomerName in Orders, Invoices und Shipments auftaucht, haben Sie mehrere Wahrheitsquellen geschaffen. Halten Sie Kundendetails in Customers und speichern Sie nur customer_id andernorts.
3) Mehrere Spalten für dasselbe vermeiden
Spalten wie billing_address, shipping_address, home_address sind ok, wenn sie wirklich unterschiedliche Konzepte darstellen. Wenn Sie jedoch „viele Adressen mit Typ“ modellieren, nutzen Sie eine Addresses‑Tabelle mit einem type‑Feld.
4) Lookups von Freitext trennen
Wenn Nutzer aus einer bekannten Menge wählen (Status, Kategorie, Rolle), modellieren Sie es konsistent: entweder als restriktiertes Enum oder als Lookup‑Tabelle. Das verhindert „Pending" vs „pending" vs „PENDING".
5) Prüfen, dass jedes Nicht‑ID Feld von der richtigen Entität abhängt
Ein hilfreicher Bauchtest: Wenn eine Spalte etwas anderes als die Haupteinheit der Tabelle beschreibt, gehört sie wahrscheinlich woanders hin. Beispiel: Orders sollten nicht product_price speichern, es sei denn, es ist ein historischer Snapshot (Preis zum Zeitpunkt der Bestellung).
Wann Denormalisierung akzeptabel ist (später)
Manchmal speichern Sie Duplikate bewusst:
- Reporting/Performance: voraggregierte Summen oder Summary‑Tabellen
- Caching: ein berechneter Wert zur Vermeidung teurer Neuberechnungen
- Audit/History: Kopie „Name zum Zeitpunkt des Kaufs" zur Bewahrung der Vergangenheit
Wichtig ist, dass es bewusst geschieht: dokumentieren Sie, welches Feld die Quelle der Wahrheit ist und wie Kopien aktualisiert werden.
Wo KI hilft — und wo Menschen entscheiden
KI kann verdächtige Duplikationen (wiederholte Spalten, ähnliche Feldnamen, inkonsistente Statusfelder) markieren und Aufteilungen in Tabellen vorschlagen. Menschen entscheiden jedoch über Trade‑Offs — Einfachheit vs. Flexibilität vs. Performance — basierend darauf, wie das Produkt tatsächlich genutzt wird.
Gespeichert vs. Berechnet: Was gehört in die Datenbank
Eine nützliche Regel: Speichern Sie Fakten, die Sie später nicht zuverlässig rekonstruieren können; berechnen Sie alles andere.
Gespeichert vs. berechnet (abgeleitet)
Gespeicherte Daten sind die Quelle der Wahrheit: Einzelne Line‑Items, Zeitstempel, Statusänderungen, wer was getan hat. Berechnete (abgeleitete) Daten entstehen aus diesen Fakten: Summen, Zähler, Flags wie „ist überfällig“ und Rollups wie „aktueller Bestand".
Wenn sich zwei Werte aus denselben Fakten berechnen lassen, bevorzugen Sie, die Fakten zu speichern und den Rest zu berechnen. Sonst riskieren Sie Widersprüche.
Warum gespeicherte abgeleitete Werte zu Inkonsistenzen führen
Abgeleitete Werte ändern sich, wenn ihre Eingaben sich ändern. Wenn Sie sowohl Eingaben als auch das Ergebnis speichern, müssen beide über alle Workflows und Randfälle synchron gehalten werden (Edits, Rückerstattungen, Teillieferungen, rückdatierte Änderungen). Ein verpasstes Update und die DB erzählt unterschiedliche Geschichten.
Beispiel: order_total speichern und gleichzeitig order_items halten. Wenn jemand die Menge ändert oder einen Rabatt anwendet und das Total nicht korrekt aktualisiert wird, sieht Finance eine Zahl, der Warenkorb eine andere.
Workflows nutzen, um zu entscheiden, was gespeichert werden muss (Historie und Snapshots)
Workflows zeigen, wann Sie historische Wahrheit und nicht nur „aktuelle Wahrheit“ brauchen. Wenn Nutzer wissen müssen, wie ein Wert damals war, speichern Sie einen Snapshot.
Für eine Bestellung speichern Sie möglicherweise:
- Line‑Items und Preise (Fakten)
- ein erfasstes
order_total beim Checkout (Snapshot), weil Steuern, Rabatte und Preisregeln sich später ändern können
Für Inventar wird der „Bestand“ oft aus Bewegungen berechnet (Wareneingang, Verkauf, Korrekturen). Wenn Sie eine Auditspur brauchen, speichern Sie die Bewegungen und optional periodische Snapshots für Reporting‑Performance.
Für Login‑Tracking speichern Sie last_login_at als Fakt (Ereignis). „Ist aktiv in den letzten 30 Tagen?“ bleibt berechnet.
Beispiel: Von 5 User Stories zu einem ER‑Modell
Nutzen wir eine vertraute Support‑Ticket App. Wir gehen von fünf User Stories zu einem einfachen ER‑Modell (Entitäten + Felder + Beziehungen) und prüfen es gegen einen Workflow.
5 User Stories → Nomen → Entitäten
- Als Kunde kann ich ein Support‑Ticket mit Betreff, Beschreibung und Kategorie erstellen.
- Als Agent kann ich ein Ticket mir selbst oder einem anderen Agenten zuweisen.
- Als Agent kann ich interne Notizen und öffentliche Antworten zu einem Ticket hinzufügen.
- Als Kunde kann ich sehen, wann mein Ticket aktualisiert wurde und wann es geschlossen wurde.
- Als Manager kann ich verfolgen, wie lange Tickets offen bleiben und wer sie geschlossen hat.
Daraus ergeben sich Kernentitäten:
- User (Kunden, Agents, Manager)
- Ticket
- Message (öffentliche Antworten + interne Notizen)
- Category
- TicketEvent (Audit/History)
Felder und Beziehungen (kompaktes ER‑Modell)
- User: id, name, email, role
- Category: id, name
- Ticket: id, subject, description, status, created_at, updated_at, closed_at
- Beziehungen: Ticket.category_id → Category.id
- Beziehungen: Ticket.requester_id → User.id (Kunde)
- Beziehungen: Ticket.assignee_id → User.id (Agent, nullable)
- Message: id, ticket_id, author_id, body, is_internal, created_at
- Beziehungen: Message.ticket_id → Ticket.id
- Beziehungen: Message.author_id → User.id
- TicketEvent: id, ticket_id, actor_id, type, from_status, to_status, created_at
Workflow‑Mapping: erstellen → aktualisieren → schließen
- Erstellen: Insert Ticket (status = „open“, created_at), Insert TicketEvent(type = „created").
- Aktualisieren (zuweisen, antworten): Insert Message oder Update Ticket.assignee_id, und Insert TicketEvent(type = „assigned"/„replied", updated_at).
- Schließen: Update Ticket.status = „closed“, set closed_at, Insert TicketEvent(type = „closed", actor_id = closer).
„Vorher und Nachher": KI findet eine fehlende Regel
Vorher (häufiger Fehler): Ticket hat assignee_id, aber wir haben vergessen, sicherzustellen, dass nur Agents als Assignees möglich sind.
Nachher: KI markiert das und Sie fügen eine praktische Regel hinzu: assignee muss ein User mit role = "agent" sein (implementierbar per Applikationsvalidierung oder DB‑Constraint/Policy, je nach Stack). Das verhindert „zugewiesen an Kunde“-Daten, die Berichte später kaputtmachen.
Schema validieren: Jede Story zurückverfolgen
Bauen und Credits verdienen
Erhalten Sie Credits, indem Sie Inhalte über Koder.ai erstellen oder Teamkollegen mit einem Empfehlungslink einladen.
Ein Schema ist erst „fertig“, wenn jede User Story mit Daten beantwortet werden kann, die Sie zuverlässig speichern und abfragen können. Der einfachste Validierungsschritt ist: Nehmen Sie jede Story und fragen Sie: „Können wir diese Frage aus der Datenbank zuverlässig für jeden Fall beantworten?“ Wenn die Antwort „vielleicht" ist, hat Ihr Modell eine Lücke.
Jede Story in eine Datenbankfrage verwandeln
Formulieren Sie jede Story als eine oder mehrere Testfragen — Dinge, die ein Report, Screen oder API stellen würde. Beispiele:
- Reports: „Zeige alle offenen Bestellungen pro Kunde mit Summen der letzten 30 Tage.“
- Berechtigungen: „Welche Nutzer dürfen Rückerstattungen für diesen Shop genehmigen?“
- Randfälle: „Kann eine Bestellung ohne Versandadresse existieren? Wie ist es mit digitalen Artikeln?"
- Löschungen: „Wenn wir einen Kunden löschen, was passiert mit Bestellungen, Rechnungen und Notizen?"
Wenn Sie eine Story nicht als klare Frage ausdrücken können, ist die Story unklar. Wenn sie sich ausdrücken lässt — aber nicht mit Ihrem Schema beantwortet werden kann — fehlen Feld, Beziehung, Status/Ereignis oder Constraint.
Mit Beispieldaten schnell prüfen
Erstellen Sie einen kleinen Datensatz (5–20 Zeilen pro Schlüsseltabelle) mit normalen und schwierigen Fällen (Duplikate, fehlende Werte, Stornierungen). Spielen Sie dann die Stories mit diesen Daten durch. Sie sehen schnell Probleme wie „wir können nicht sagen, welche Adresse zum Zeitpunkt des Kaufs verwendet wurde“ oder „wir haben keinen Ort, um zu speichern, wer die Änderung genehmigt hat".
KI zur Suche nach unbehandelten Fällen nutzen
Bitten Sie KI, Validierungsfragen pro Story zu erzeugen (inkl. Randfälle und Löschszenarien) und aufzuzählen, welche Daten nötig wären, um sie zu beantworten. Vergleichen Sie diese Liste mit Ihrem Schema: jede Abweichung ist eine konkrete Maßnahme, kein vages Gefühl, dass „etwas nicht stimmt".
KI sicher nutzen und Schema wartbar halten
KI kann das Datenmodellieren beschleunigen, erhöht aber auch das Risiko, sensible Informationen zu leaken oder falsche Annahmen festzuschreiben. Behandeln Sie sie wie einen sehr schnellen Assistenten: nützlich, aber mit Leitplanken.
Was Sie mit KI teilen sollten (und was nicht)
Teilen Sie Inputs, die realistisch genug zum Modellieren sind, aber sanitisiert genug, um sicher zu sein:
- Sanitiserte User Stories (Kunden, Produkte, Orte umbenennen)
- Akzeptanzkriterien und Randfälle („Rückerstattung innerhalb 14 Tage", „ein aktives Abonnement pro Account")
- Beispielfelder mit Fake‑Daten (z. B.
invoice_total: 129.50, status: "paid")
- Aktuelle CSV‑Header / bestehende Tabellen (Struktur ist meist unkritisch; Inhalt oft nicht)
Vermeiden Sie alles, was Personen identifiziert oder vertrauliche Abläufe offenlegt:
- Echte Namen, E‑Mails, Telefonnummern, Adressen
- Echte Bestell‑/Support‑Historien, interne Notizen
- API‑Keys, DB‑Zugangsdaten, Screenshots mit privaten Daten
Wenn Sie Realismus brauchen, generieren Sie synthetische Beispiele, die Formate und Bereiche nachahmen — kopieren Sie nie Produktionsrows.
Annahmen neben dem Schema dokumentieren
Schemas scheitern meist, weil „alle angenommen" etwas unterschiedlich verstanden haben. Führen Sie neben Ihrem ER‑Modell (oder im selben Repo) ein kurzes Entscheidungsprotokoll:
- Definitionen („Was zählt als ‚aktiv’ Account?")
- Constraints („Ein Nutzer kann zu mehreren Organisationen gehören")
- Trade‑Offs („Wir speichern die Währung auf jeder Rechnung für Audits")
So wird KI‑Output zum Teamwissen statt zum Einzelstück.
Für Veränderungen planen: Versionierung und Migrationen
Ihr Schema wird mit neuen Stories wachsen. Schützen Sie es durch:
- Versionierung von Schema‑Änderungen (Migrationsdateien im Git)
- Reversible Migrationen wo möglich
- Seeds und Beispielabfragen aktualisieren, damit Änderungen testbar sind
- KI‑generierte Migrationen wie normalen Code prüfen
Wenn Sie Plattformen wie Koder.ai nutzen, nutzen Sie Guardrails wie Snapshots und Rollback beim Iterieren an Schema‑Änderungen und exportieren Sie den Source Code, wenn Sie tiefere Anpassungen oder traditionelle Reviews brauchen.
Ein einfacher wiederholbarer Workflow
- Stories sanitizen + 5–10 synthetische Beispiele erstellen.
- KI um Vorschlag für Entitäten, Felder, Beziehungen und Constraints bitten.
- Mit Team reviewen; Annahmen dokumentieren.
- Migrationen implementieren; einen kleinen „Story Trace" Test laufen lassen (jede Story ist durch das Modell abbildbar).
- Wiederholen, wenn Stories sich ändern; Schema und Notizen synchron halten.