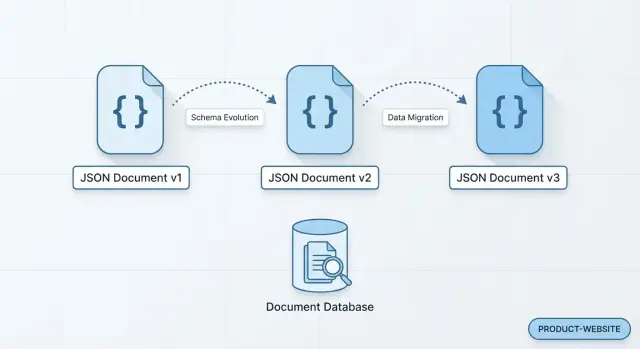
Was dieser Artikel mit „Dokumentdatenbank“ meint
Eine Dokumentdatenbank speichert Daten als in sich geschlossene „Dokumente“, üblicherweise in einem JSON‑ähnlichen Format. Anstatt ein Geschäftsobjekt über mehrere Tabellen zu verteilen, kann ein einzelnes Dokument alles darüber enthalten — Felder, Unterfelder und Arrays — ähnlich wie viele Apps Daten bereits im Code darstellen.
Dokumente und Collections (auf einfachen Worten)
- Dokument: Ein Datensatz, den man als Ganzes lesen und schreiben kann (zum Beispiel ein Kunde, eine Bestellung, ein Support‑Ticket).
- Collection: Eine Gruppe ähnlicher Dokumente (zum Beispiel eine
users-Collection oder eine orders-Collection).
Dokumente in derselben Collection müssen nicht identisch aussehen. Ein User‑Dokument kann 12 Felder haben, ein anderes 18 — und beide können nebeneinander existieren.
Wie ein „sich schnell änderndes Datenmodell“ aussieht
Stell dir ein Nutzerprofil vor. Du beginnst mit name und email. Nächsten Monat möchte das Marketing preferred_language. Dann fragt der Customer Success nach timezone und subscription_status. Später fügst du social_links (ein Array) und privacy_settings (ein verschachteltes Objekt) hinzu.
In einer Dokumentdatenbank kannst du normalerweise sofort beginnen, die neuen Felder zu schreiben. Ältere Dokumente bleiben solange unverändert, bis du dich entscheidest, sie nachzufüllen (oder nicht).
Flexibilität — mit Kompromissen
Diese Flexibilität kann die Produktarbeit beschleunigen, aber sie verlagert Verantwortung auf deine Anwendung und dein Team: Du brauchst klare Konventionen, optionale Validierungsregeln und durchdachtes Query‑Design, um unordentliche, inkonsistente Daten zu vermeiden.
Was du in diesem Artikel lernen wirst
Als Nächstes schauen wir, warum einige Modelle sich so häufig ändern, wie flexible Schemata Reibung reduzieren, wie Dokumente zu echten App‑Abfragen passen und welche Abwägungen du vor der Wahl von Dokument‑Speicher gegenüber relationalem Speicher beachten solltest — oder wie ein hybrider Ansatz aussehen kann.
Warum sich Datenmodelle so oft ändern
Datenmodelle bleiben selten statisch, weil das Produkt selten statisch ist. Was als „einfaches Nutzerprofil speichern“ beginnt, entwickelt sich schnell zu Präferenzen, Benachrichtigungsoptionen, Abrechnungsmetadata, Geräteinformationen, Einwilligungsflags und einem Dutzend weiterer Details, die in der ersten Version nicht existierten.
Produktwachstum erzeugt neue Attribute
Der größte Teil des Modell‑Wechsels ist schlicht Lernprozess. Teams fügen Felder hinzu, wenn sie:
- neue Features einführen (z. B. Loyalty‑Stufen, Abonnements, Rollen)
- Experimente laufen, die neue Tracking‑Eigenschaften benötigen
- mehr Kontext sammeln, um das Erlebnis zu personalisieren
Diese Änderungen sind oft inkrementell und häufig — kleine Ergänzungen, die schwer als formale „große Migrationen“ zu terminieren sind.
Mehrere Versionen derselben Entität müssen koexistieren
Echte Datenbanken enthalten Historie. Alte Datensätze behalten die Form, mit der sie geschrieben wurden, während neue Datensätze die aktuelle Form übernehmen. Du kannst Kunden haben, die erstellt wurden, bevor marketing_opt_in existierte, Bestellungen vor delivery_instructions oder Events, die protokolliert wurden, bevor ein neues Feld source definiert wurde.
Du veränderst also nicht „ein Modell“ — du unterstützt gleichzeitig mehrere Versionen, teils über Monate.
Parallele Teams und Microservices verstärken Veränderungen
Wenn mehrere Teams parallel ausliefern, wird das Datenmodell zur gemeinsamen Schnittstelle. Ein Payments‑Team kann Fraud‑Signale hinzufügen, während ein Growth‑Team Attributionsdaten ergänzt. In Microservices speichert jeder Service möglicherweise ein „Kunden“-Konzept mit unterschiedlichen Anforderungen, die sich unabhängig weiterentwickeln.
Ohne Koordination wird das „eine perfekte Schema“ schnell zum Engpass.
Integrationen und verschachtelte, semi-strukturierte Daten
Externe Systeme senden oft teilweise bekannte, verschachtelte oder inkonsistente Payloads: Webhooks, Partner‑Metadata, Formularübermittlungen, Geräte‑Telemetrie. Auch wenn du die wichtigen Teile normalisierst, willst du häufig die Originalstruktur für Audit, Debugging oder spätere Nutzung behalten.
All diese Kräfte treiben Teams in Richtung Speicher, der Änderungen gut toleriert — besonders wenn hohe Liefergeschwindigkeit zählt.
Flexible Schemata reduzieren Reibung, wenn Anforderungen sich verschieben
Wenn ein Produkt noch in der Findungsphase ist, ist das Datenmodell selten „fertig“. Neue Felder erscheinen, alte werden optional, und verschiedene Kunden benötigen leicht unterschiedliche Informationen. Dokumentdatenbanken sind in diesen Momenten beliebt, weil sie erlauben, Daten zu entwickeln, ohne jede Änderung in ein Datenbank‑Migrationsprojekt zu verwandeln.
Felder hinzufügen, wenn du sie brauchst (keine Tabellenmigrationen)
Mit JSON‑Dokumenten kann das Hinzufügen einer neuen Eigenschaft so einfach sein wie sie in neuen Datensätzen zu schreiben. Bestehende Dokumente können unangetastet bleiben, bis du entscheidest, dass ein Backfill nötig ist. Das bedeutet, ein kleines Experiment — z. B. das Sammeln einer neuen Präferenz — erfordert nicht unbedingt Koordination eines Schema‑Wechsels, eines Deploy‑Fensters und eines Backfill‑Jobs, nur um zu lernen.
Manchmal hast du tatsächlich Varianten: Ein „Free“-Account hat weniger Einstellungen als ein „Enterprise“-Account, oder ein Produkttyp braucht zusätzliche Attribute. In einer Dokumentdatenbank kann es akzeptabel sein, dass Dokumente in derselben Collection unterschiedliche Formen haben, solange deine Anwendung weiß, wie sie interpretiert werden.
Statt alles in eine starre Struktur zu zwängen, kannst du:
- gemeinsame Felder konsistent halten (wie
id, userId, createdAt)
- Variantenfelder nur dort vorhalten, wo sie relevant sind
Defaults + Anwendungslogik behandeln fehlendes
Flexible Schemata bedeuten nicht „keine Regeln“. Ein gängiges Muster ist, fehlende Felder als „Default verwenden“ zu behandeln. Deine Anwendung kann zur Lesezeit sinnvolle Defaults anwenden (oder sie beim Schreiben setzen), sodass ältere Dokumente weiterhin korrekt funktionieren.
Schnellere Experimente und Feature‑Flags
Feature‑Flags führen oft temporäre Felder und partielle Rollouts ein. Flexible Schemata erleichtern es, eine Änderung an eine kleine Kohorte zu liefern, zusätzlichen Zustand nur für geflaggte Nutzer zu speichern und schnell zu iterieren — ohne vorab auf Schema‑Arbeit warten zu müssen.
Dokumente entsprechen oft der Datenvorstellung vieler Apps
Viele Produktteams denken natürlich in „Dingen, die der Nutzer auf dem Bildschirm sieht“. Eine Profilseite, die Bestelldetailansicht, ein Projekt‑Dashboard — jede davon bildet meist ein einzelnes App‑Objekt mit vorhersehbarer Form ab. Dokumentdatenbanken unterstützen dieses Denkmodell, indem sie erlauben, dieses Objekt als ein JSON‑Dokument zu speichern, mit deutlich weniger Übersetzungen zwischen Anwendungscode und Speicher.
Von App‑Objekten zu JSON mit weniger Hand‑offs
Bei relationalen Tabellen wird dasselbe Feature oft über mehrere Tabellen, Foreign Keys und Join‑Logik verteilt. Diese Struktur ist mächtig, kann sich aber wie extra Zeremonie anfühlen, wenn die App die Daten bereits als verschachteltes Objekt hält.
In einer Dokumentdatenbank kannst du das Objekt oft nahezu unverändert persistieren:
- Ein
user-Dokument, das zu deiner User‑Klasse/Typ passt
- Ein
project-Dokument, das zu deinem Project‑State‑Modell passt
Weniger Übersetzung bedeutet in der Regel weniger Mapping‑Bugs und schnellere Iteration, wenn Felder sich ändern.
Verschachtelte Daten bleiben zusammen
Echte App‑Daten sind selten flach. Adressen, Präferenzen, Benachrichtigungseinstellungen, gespeicherte Filter, UI‑Flags — all das ist natürlich verschachtelt.
Verschachtelte Objekte im Eltern‑Dokument zu speichern hält zusammengehörige Werte nah, was für „ein Datensatz = eine Ansicht“-Abfragen hilfreich ist: ein Dokument holen, eine Ansicht rendern. Das reduziert die Notwendigkeit für Joins und die damit verbundenen Performance‑Überraschungen.
Klarere Ownership in Teams
Wenn jedes Feature‑Team die Form seiner Dokumente besitzt, werden Verantwortlichkeiten klarer: Das Team, das das Feature ausliefert, entwickelt auch dessen Datenmodell weiter. Das funktioniert gut in Microservices‑ oder modularen Architekturen, wo unabhängige Änderungen eher Regel als Ausnahme sind.
Schnellere Produktiteration und Deployment‑Muster
Dokumentdatenbanken passen oft zu Teams, die häufig ausliefern, weil kleine Datenänderungen selten ein koordiniertes „Stop the world“‑Datenbankupdate erfordern.
Schnelle Iterationen mit weniger blockierenden Änderungen
Wenn ein Product Manager „nur noch ein Attribut“ verlangt (z. B. preferredLanguage oder marketingConsentSource), erlaubt ein Dokumentmodell typischerweise, dieses Feld sofort zu schreiben. Du musst nicht immer eine Migration planen, Tabellen sperren oder ein Release‑Fenster über mehrere Services verhandeln.
Das reduziert die Anzahl an Tasks, die einen Sprint blockieren: Die Datenbank bleibt nutzbar, während die Anwendung sich weiterentwickelt.
Einfachere Deploys beim Hinzufügen von Feldern
Optionale Felder zu JSON‑ähnlichen Dokumenten hinzuzufügen ist meist rückwärtskompatibel:
- Alte Datensätze haben das neue Feld einfach nicht.
- Neue Datensätze enthalten es.
- Leser behandeln „fehlend“ als normalen Fall.
Dieses Muster macht Deploys gelassener: Du kannst zuerst den Schreibpfad ausrollen (beginne, das Feld zu speichern) und später Lesepfade und UI anpassen — ohne jedes bestehende Dokument sofort zu aktualisieren.
Unterstützung mehrerer App‑Versionen in freier Wildbahn
Echte Systeme updaten Clients selten alle auf einmal. Du kannst haben:
- Mobile Apps, die wochenlang auf älteren Versionen laufen
- A/B‑Tests und Canary Releases
- Mehrere Microservices, die unabhängig deployen
Bei Dokumentdatenbanken designen Teams oft für „gemischte Versionen“, indem Felder additiv und optional behandelt werden. Neuere Schreiber können Daten hinzufügen, ohne ältere Leser zu brechen.
Ein gängiges Vorgehen: neu schreiben, mit Fallbacks lesen
Ein praktisches Deployment‑Pattern sieht so aus:
- Schreiben: Das neue Feld in der neuesten App/Service‑Version schreiben.
- Lesen: Mit einer Fallback‑Regel lesen: „Wenn das Feld fehlt, verwende den alten Wert oder einen Default.“
- Optional später einen Hintergrund‑Backfill ausführen, falls das Feld auch in älteren Dokumenten wichtig wird.
Dieser Ansatz hält die Velocity hoch und reduziert Koordinationsaufwand zwischen Datenbankänderungen und Anwendungsreleases.
Read‑freundliches Datenmodellieren für reale Abfragen
Behalte die Kontrolle über deinen Code
Generiere die App und exportiere dann den Quellcode, damit dein Team sie frei erweitern kann.
Ein Grund, warum Teams Dokumentdatenbanken mögen, ist, dass man Daten so modellieren kann, wie die Anwendung sie am häufigsten liest. Anstatt ein Konzept über viele Tabellen zu verteilen und es später wieder zusammenzufügen, speicherst du ein „ganzes“ Objekt (oft als JSON‑Dokument) an einem Ort.
Denormalisierung: zusammengehörige Daten zusammenhalten
Denormalisierung bedeutet, verwandte Felder zu duplizieren oder einzubetten, damit häufige Abfragen aus einer einzigen Dokumentabfrage beantwortet werden können.
Beispielsweise könnte ein Order‑Dokument Kunden‑Snapshot‑Felder enthalten (Name, E‑Mail zum Kaufzeitpunkt) und ein eingebettetes Array von Line Items. Dieses Design macht „zeige meine letzten 10 Bestellungen“ schnell und einfach, weil das UI nicht mehrere Lookups braucht, um eine Seite zu rendern.
Wenn Daten für einen Screen oder eine API‑Antwort in einem Dokument leben, bekommst du oft:
- Weniger Netzwerk‑Roundtrips zwischen App und Datenbank
- Weniger serverseitige Joins (oder join‑ähnliche Operationen) zur Ergebniszusammenstellung
Das reduziert Latenz für read‑lastige Pfade — besonders bei Produkt‑Feeds, Profilen, Warenkörben und Dashboards.
Einbetten vs. Referenzieren: eine praktische Faustregel
Einbetten ist meist hilfreich, wenn:
- die eingebetteten Daten normalerweise zusammen mit dem Parent gelesen werden
- die eingebetteten Daten in der Größe begrenzt sind (z. B. „bis zu 20 Items“)
- du tolerieren kannst, dass sie als Teil des Parent‑Dokuments aktualisiert werden
Referenzieren ist besser, wenn:
- die zugehörige Entität groß oder unbegrenzt ist (z. B. „alle jemals abgegebenen Kommentare“)
- viele Eltern auf dasselbe Kind verweisen (geteilte Daten)
- das Kind sich häufig ändert und du nicht viele Dokumente updaten willst
Es gibt keine universell „beste“ Dokumentform. Ein Modell, das für eine Abfrage optimiert ist, kann eine andere langsamer machen (oder teurer beim Updaten). Die verlässlichste Herangehensweise ist, von deinen realen Abfragen auszugehen — was deine App tatsächlich braucht — und Dokumente um diese Read‑Pfade zu formen, dann das Modell bei veränderter Nutzung erneut zu prüfen.
Schema‑on‑Read und optionale Validierung
Schema‑on‑Read bedeutet, dass du nicht jedes Feld und jede Tabellenform definieren musst, bevor du Daten speichern kannst. Stattdessen interpretiert deine Anwendung (oder eine Analytics‑Abfrage) die Struktur jedes Dokuments beim Lesen. Praktisch erlaubt das, ein neues Feature zu liefern, das preferredPronouns oder shipping.instructions hinzufügt, ohne vorher eine Datenbankmigration zu koordinieren.
Wie Schema‑on‑Read im Alltag aussieht
Die meisten Teams haben weiterhin eine „erwartete Form“ im Kopf — sie wird nur später und selektiver durchgesetzt. Ein Kunden‑Dokument kann phone haben, ein anderes nicht. Eine ältere Bestellung speichert discountCode als String, während neuere Bestellungen ein reichhaltigeres discount‑Objekt speichern.
Schlimme Daten verhindern ohne schwere Migrationen
Flexibilität muss nicht Chaos bedeuten. Gängige Ansätze:
- Validierungsregeln in der Datenbank (wo unterstützt): erfordere Schlüssel wie
id, createdAt oder status und beschränke Typen für risikoreiche Felder.
- Anwendungsseitige Prüfungen: validiere Eingaben beim Schreiben (API‑Layer) und lehne unerwartete Werte ab oder normalisiere sie.
- Hintergrund‑„Data Hygiene“ Jobs: scanne regelmäßig nach Ausreißern und korrigiere oder markiere sie.
Leichtgewichtige Governance, die skaliert
Ein wenig Konsistenz wirkt oft Wunder:
- Namenskonventionen (z. B.
camelCase, Zeitstempel in ISO‑8601)
- Eine kleine Menge erforderlicher Felder über Dokumente hinweg
- Dokumentversionierung (z. B.
schemaVersion: 3), damit Leser alte und neue Formen sicher behandeln können
Wann die Validierung strenger werden sollte
Wenn sich ein Modell stabilisiert — meist nachdem du gelernt hast, welche Felder wirklich zentral sind — führe strengere Validierung für diese Felder und kritische Beziehungen ein. Halte optionale oder experimentelle Felder flexibel, damit die Datenbank weiterhin schnelle Iterationen unterstützt, ohne ständig Migrationen nötig zu machen.
Umgang mit Änderungsverlauf und sich entwickelnden Events
Leseoptimierte Ansichten erstellen
Starte eine React-App, die pro Bildschirm ein Dokument lädt, für einfacheres Lesen.
Wenn dein Produkt wöchentlich Änderungen sieht, ist nicht nur die „aktuelle“ Form der Daten wichtig. Du brauchst auch eine verlässliche Geschichte, wie es dazu kam. Dokumentdatenbanken sind dafür oft geeignet, weil sie in sich geschlossene Datensätze speichern, die sich entwickeln können, ohne alles Vergangene umschreiben zu müssen.
Append‑only Event‑Dokumente
Ein gängiger Ansatz ist, Änderungen als Event‑Stream zu speichern: Jedes Event ist ein neues Dokument, das du anhängst (anstatt alte Zeilen in‑place zu aktualisieren). Zum Beispiel: UserEmailChanged, PlanUpgraded oder AddressAdded.
Da jedes Event ein eigenes JSON‑Dokument ist, kannst du den vollständigen Kontext dieses Moments erfassen — wer es tat, was es auslöste und welche Metadaten später nützlich sind.
Neue Felder hinzufügen, ohne die Historie umzuschreiben
Event‑Definitionen bleiben selten stabil. Du könntest source="mobile", experimentVariant oder ein neues verschachteltes Objekt wie paymentRiskSignals hinzufügen. Mit Dokumentspeicher können alte Events diese Felder einfach weglassen, neue Events sie enthalten.
Deine Leser (Services, Jobs, Dashboards) können fehlende Felder sicher defaulten, anstatt Millionen historischer Datensätze backfillen und migrieren zu müssen, nur um ein zusätzliches Attribut einzuführen.
Versionierung für schrittweise Migrationen
Um Konsumenten vorhersehbar zu halten, fügen viele Teams ein schemaVersion (oder eventVersion) Feld in jedes Dokument ein. Das ermöglicht eine schrittweise Einführung:
- Producer beginnen, Version‑2‑Events zu schreiben
- Konsumenten lesen für eine Weile sowohl v1 als auch v2
- Alte Versionen migriert oder außer Betrieb genommen werden, wenn es passt
Bessere Analytics und Debugging über die Zeit
Eine dauerhafte Historie von „was passiert ist“ ist über Audits hinaus nützlich. Analytics‑Teams können Zustände zu jedem Zeitpunkt rekonstruieren, und Support‑Ingenieure können Regressionsursachen finden, indem sie Events wieder abspielen oder das genaue Payload inspizieren, das zu einem Bug führte. Über Monate beschleunigt das die Root‑Cause‑Analyse und macht Reporting vertrauenswürdiger.
Trade‑Offs, die du kennen solltest, bevor du dich für eine Dokumentdatenbank entscheidest
Dokumentdatenbanken machen Veränderung leichter, aber sie nehmen die Designarbeit nicht weg — sie verlagern sie. Bevor du dich verpflichtest, solltest du klar sein, was du für diese Flexibilität eintauschst.
Transaktionen über mehrere Entitäten können komplizierter sein
Viele Dokumentdatenbanken unterstützen Transaktionen, aber Multi‑Entity (Multi‑Dokument) Transaktionen können beschränkt, langsamer oder teurer sein als in einer relationalen Datenbank — besonders bei hohem Durchsatz. Wenn dein Kern‑Workflow „Alles oder Nichts“-Updates über mehrere Datensätze verlangt (z. B. Bestellung, Inventar und Ledger‑Eintrag gleichzeitig aktualisieren), prüfe, wie deine Datenbank das handhabt und welche Performance‑ oder Komplexitätskosten entstehen.
Weil Felder optional sind, können Teams versehentlich mehrere „Versionen“ desselben Konzepts in Produktion erzeugen (z. B. address.zip vs address.postalCode). Das kann Downstream‑Features brechen und Bugs schwerer auffindbar machen.
Eine praktische Gegenmaßnahme ist, einen gemeinsamen Vertrag für wichtige Dokumenttypen zu definieren (auch wenn er leichtgewichtig ist) und dort optionale Validierungsregeln zu ergänzen — etwa für Zahlungsstatus, Preise oder Berechtigungen.
Ad‑hoc‑Reporting kann ohne Standardisierung schwieriger werden
Wenn Dokumente sich frei entwickeln, werden Analytics‑Abfragen unordentlich: Analysten schreiben Logik für mehrere Feldnamen und fehlende Werte. Für Teams mit starkem Reporting‑Bedarf brauchst du vielleicht einen Plan wie:
- Standardisierung „reporting‑freundlicher“ Felder
- Export in ein Data Warehouse
- Pflege kuratierter Read‑Modelle für Analytics
Denormalisierung kann Duplikation und Update‑Komplexität verursachen
Eingebettete Daten (z. B. Kunden‑Snapshots in Bestellungen) beschleunigen Reads, duplizieren aber Informationen. Wenn ein gemeinsames Stück Daten sich ändert, musst du entscheiden: überall aktualisieren, Historie aufbewahren oder zeitweilige Inkonsistenzen tolerieren. Diese Entscheidung sollte bewusst getroffen werden — sonst droht subtile Datenabweichung.
Dokumentdatenbanken passen gut, wenn Änderungen häufig sind, aber sie belohnen Teams, die Modellierung, Benennung und Validierung als fortlaufende Produktarbeit behandeln — nicht als einmalige Einrichtung.
Typische Anwendungsfälle, in denen Dokumentdatenbanken glänzen
Dokumentdatenbanken speichern Daten als JSON‑Dokumente, was sie zur natürlichen Wahl macht, wenn Felder optional sind, sich häufig ändern oder je Kunde/Gerät/Produktlinie variieren. Statt jeden Datensatz in dieselbe starre Tabellenform zu pressen, kannst du das Datenmodell schrittweise entwickeln und weiterhin schnell liefern.
E‑Commerce‑Kataloge mit ständig wechselnden Attributen
Produktdaten bleiben selten gleich: neue Größen, Materialien, Compliance‑Flags, Bundles, regionale Beschreibungen und marketplace‑spezifische Felder tauchen ständig auf. Mit verschachtelten JSON‑Daten kann ein „Produkt“ Kernfelder (SKU, Preis) behalten und gleichzeitig kategoriespezifische Attribute erlauben, ohne Wochen für Schema‑Redesign zu benötigen.
Nutzerprofile und Präferenzen mit optionalen Feldern
Profile starten oft klein und wachsen: Benachrichtigungseinstellungen, Marketing‑Einwilligungen, Onboarding‑Antworten, Feature‑Flags und Personalisierungssignale. In einer Dokumentdatenbank können Nutzer unterschiedliche Feldsets haben, ohne bestehende Reads zu brechen. Diese Schema‑Flexibilität hilft auch der agilen Entwicklung, bei der Experimente Felder schnell hinzufügen und entfernen.
Content‑Management, das sich über die Zeit entwickelt
Moderne CMS‑Inhalte sind nicht nur „eine Seite“. Sie sind Mischungen aus Blöcken und Komponenten — Hero‑Sektionen, FAQs, Produktkarussells, Embeds — jede mit eigener Struktur. Seiten als JSON‑Dokumente zu speichern erlaubt es, neue Komponententypen einzuführen, ohne jede historische Seite sofort migrieren zu müssen.
IoT und Telemetrie mit gerätespezifischen Payloads
Telemetrie variiert oft nach Firmware‑Version, Sensor‑Pack oder Hersteller. Dokumentdatenbanken handhaben solche sich entwickelnden Datenmodelle gut: Jedes Event kann nur das enthalten, was das Gerät kennt, während Schema‑on‑Read Analytics‑Tools erlaubt, Felder bei Bedarf zu interpretieren.
Wenn du zwischen NoSQL vs SQL abwägst: Das sind Szenarien, in denen Dokumentdatenbanken tendenziell schnellere Iteration bei weniger Reibung liefern.
Praktische Modellier‑Tipps für schnell veränderliche Modelle
Einen kleinen Pilot starten
Stelle deine Pilot-App bereit und hoste sie, um das Modell mit echtem Traffic zu validieren.
Wenn dein Datenmodell noch in der Findungsphase ist, ist „gut genug und leicht änderbar“ besser als „auf dem Papier perfekt“. Diese praktischen Gewohnheiten helfen, Geschwindigkeit zu behalten, ohne die Datenbank in eine Schublade für Altlasten zu verwandeln.
1) Starte von Zugriffspfaden, nicht von Entitäten
Beginne jedes Feature, indem du die wichtigsten Reads und Writes aufschreibst: die Screens, die du renderst, die API‑Antworten, die du zurückgibst, und die Updates, die am häufigsten vorkommen.
Wenn eine User‑Aktion regelmäßig „Order + Items + Versandadresse“ braucht, modelliere ein Dokument, das diese Read mit minimalem zusätzlichen Abruf bedienen kann. Wenn eine andere Aktion „alle Bestellungen nach Status“ braucht, stelle sicher, dass du dafür abfragen oder indexieren kannst.
2) Entscheide Einbetten vs. Referenzieren früh
Einbetten ist großartig, wenn:
- die Kind‑Daten normalerweise mit dem Parent gelesen werden
- die Kindmenge begrenzt ist (z. B. 1–20 Items)
Referenzieren ist sicherer, wenn:
- die Kind‑Collection groß oder unbegrenzt wachsen kann
- das Kind über viele Eltern geteilt wird (z. B. ein Katalogprodukt)
Du kannst beide mischen: ein Snapshot für Lesegeschwindigkeit einbetten und eine Referenz zur Quelle der Wahrheit halten.
3) Füge minimale Leitplanken hinzu: Validierung + Versionierung
Auch mit Flexibilität solltest du leichte Regeln für abhängige Felder festlegen (Typen, erforderliche IDs, erlaubte Status). Füge ein schemaVersion (oder docVersion) Feld hinzu, damit deine Anwendung ältere Dokumente graceful behandeln und im Laufe der Zeit migrieren kann.
4) Plane Bereinigung und Migrationen als normale Routine
Behandle Migrationen als regelmäßige Wartung, nicht als einmaliges Ereignis. Während das Modell reift, plane kleine Backfills und Bereinigungen (nicht genutzte Felder, umbenannte Keys, denormalisierte Snapshots) und messe den Einfluss davor und danach. Eine einfache Checkliste und ein leichtgewichtiger Migrationsskript helfen enorm.
Wie entscheiden: Dokument vs Relational (und Hybride)
Die Wahl zwischen einer Dokumentdatenbank und einer relationalen Datenbank ist weniger eine Frage von „welches ist besser“ als davon, welche Art von Änderungen dein Produkt am häufigsten erfährt.
Wähle Dokumentdatenbanken, wenn Flexibilität und Geschwindigkeit am wichtigsten sind
Dokumentdatenbanken eignen sich gut, wenn sich die Datenform häufig ändert, verschiedene Datensätze unterschiedliche Felder haben können oder Teams Features liefern müssen, ohne jede Änderung als Schema‑Migration zu koordinieren.
Sie passen auch gut, wenn deine Anwendung natürlich mit „ganzen Objekten“ arbeitet, wie einer Bestellung (Kundeninfo + Items + Lieferhinweise) oder einem Nutzerprofil (Settings + Präferenzen + Geräteinfo), die zusammen als JSON‑Dokument gespeichert werden.
Wähle relationale Datenbanken, wenn starke Konsistenz und Joins dominieren
Relationale Datenbanken glänzen, wenn du brauchst:
- starke, durchgesetzte Struktur (jeder Datensatz muss dieselben Regeln befolgen)
- komplexes Reporting über viele Entitäten (viele Joins)
- Transaktionen, die mehrere Tabellen umfassen und perfekt konsistent bleiben müssen
Wenn die Arbeit deines Teams hauptsächlich darin besteht, Cross‑Table‑Queries und Analytics zu optimieren, ist SQL oft das langfristig einfachere Zuhause.
Ziehe einen hybriden Ansatz in Betracht, wenn die Realität gemischt ist
Viele Teams nutzen beides: relational für das „Core System of Record“ (Abrechnung, Inventar, Entitlements) und einen Dokumentstore für schnell evolvierende oder read‑optimierte Sichten (Profile, Content‑Metadata, Produktkataloge). In Microservices ordnet sich das oft natürlich: Jeder Service wählt das Speicher‑Modell, das zu seinen Grenzen passt.
Es ist auch erwähnenswert, dass „hybrid“ innerhalb einer relationalen Datenbank existieren kann. PostgreSQL kann z. B. semi‑strukturierte Felder mit JSON/JSONB neben stark typisierten Spalten speichern — nützlich, wenn du transaktionale Konsistenz und gleichzeitig einen flexiblen Platz für sich entwickelnde Attribute willst.
Wo Koder.ai passt, wenn du schnell iterierst
Wenn dein Schema wöchentlich ändert, ist der Flaschenhals oft die End‑to‑End‑Schleife: Modelle, APIs, UI, Migrationen (falls vorhanden) aktualisieren und Änderungen sicher ausrollen. Koder.ai ist für diese Art von Iteration gemacht. Du kannst das Feature und die Datenform im Chat beschreiben, eine lauffähige Web/Backend/Mobile‑Implementierung generieren und sie dann verfeinern, während sich Anforderungen entwickeln.
In der Praxis beginnen Teams oft mit einem relationalen Kern (Koder.ai’s Backend‑Stack ist Go mit PostgreSQL) und nutzen dokumentenartige Muster dort, wo sie sinnvoll sind (z. B. JSONB für flexible Attribute oder Event‑Payloads). Koder.ai’s Snapshots und Rollback helfen zudem, wenn eine experimentelle Datenform schnell zurückgesetzt werden muss.
Nächste Schritte: mit einem kleinen Pilot entscheiden
Führe eine kurze Evaluation durch, bevor du dich verpflichtest:
- Schreibe 5–10 reale Abfragen auf, die das Produkt braucht (keine hypothetischen).\n2. Modelle dieselbe Funktion in beiden Ansätzen.\n3. Messe die Iterationsgeschwindigkeit: Wie schmerzhaft ist die zweite Änderungsanforderung?\n4. Validere operative Bedürfnisse (Backups, Monitoring, Zugriffskontrolle).
Wenn du Optionen vergleichst, halte den Umfang eng und zeitlich begrenzt — und erweitere dann, sobald du siehst, welches Modell dir weniger Überraschungen beim Liefern bereitet. Für mehr zur Evaluierung von Speicher‑Tradeoffs, siehe /blog/document-vs-relational-checklist.