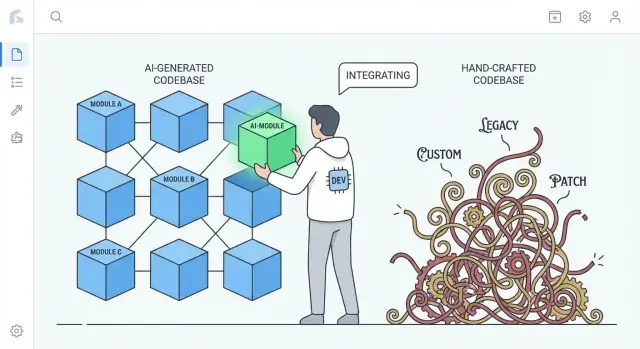
Was „einfacher zu ersetzen“ in echten Projekten bedeutet
„Einfacher zu ersetzen“ heißt selten, eine ganze Anwendung zu löschen und neu zu schreiben. In echten Teams passiert Ersatz auf verschiedenen Ebenen, und was „Rewrite“ bedeutet, hängt davon ab, was du austauschst.
Ersetzen vs. neu schreiben: Was tatsächlich auf dem Tisch liegt
Ein Ersatz kann sein:
- Ein Modul (Abrechnungsregeln, PDF-Generierung, E‑Mail‑Templates)
- Ein Service (Recommendation‑API, Background‑Worker)
- Eine Frontend‑Oberfläche (eine Seite, ein Feature‑Bereich oder die gesamte UI)
- Ein kompletter App‑Rewrite (selten, teuer, manchmal nötig)
Wenn Leute sagen, eine Codebase sei „einfacher neu zu schreiben“, meinen sie meist, dass du ein Slice neu starten kannst, ohne alles andere zu entwirren, das Geschäft weiterläuft und die Migration schrittweise erfolgen kann.
Der reale Vergleich: KI‑generiert vs. stark maßgeschneidert
Die Argumentation lautet nicht „KI‑Code ist besser“. Es geht um typische Tendenzen.
- Stark maßgeschneiderter, handgefertigter Code sammelt oft einzigartige Patterns, clevere Abstraktionen und einmalige „Frameworks im App‑Inneren“. Das kann exzellente Ingenieurskunst sein, aber auch ein privates Ökosystem erschaffen, das nur wenige verstehen.
- KI‑generierter Code neigt dazu, gängige Defaults zu verwenden: Mainstream‑Libraries, konventionelle Layering‑Ansätze und Muster, wie man sie in vielen Referenzprojekten findet.
Dieser Unterschied zählt beim Rewrite: Code, der weit verbreitete Konventionen folgt, kann oft durch eine andere konventionelle Implementierung ersetzt werden — mit weniger Verhandlung und weniger Überraschungen.
Erwartungen setzen: KI‑Code kann unordentlich sein
KI‑generierter Code kann inkonsistent, repetitiv oder untergetestet sein. „Einfacher zu ersetzen“ heißt nicht, dass er sauberer ist — es heißt oft, dass er weniger „besonders“ ist. Wenn ein Subsystem aus üblichen Bestandteilen besteht, ist das Ersetzen eher wie der Tausch eines Standardteils als das Reverse‑Engineering einer Spezialmaschine.
Vorschau: Warum Standardisierung Wechselkosten senkt
Die Kernidee ist einfach: Standardisierung senkt Wechselkosten. Wenn Code aus erkennbaren Patterns und klaren Nähten besteht, kannst du Teile neu generieren, refactoren oder neu schreiben, ohne versteckte Abhängigkeiten zu fürchten. Die folgenden Abschnitte zeigen, wie sich das in Struktur, Ownership, Tests und täglicher Engineering‑Geschwindigkeit auswirkt.
Standardmuster senken die Kosten eines Neuanfangs
Ein praktischer Vorteil von KI‑generiertem Code ist, dass er oft zu gängigen, wiedererkennbaren Mustern tendiert: vertraute Ordnerstrukturen, vorhersehbare Benennungen, konventionelle Framework‑Konventionen und „textbook“ Ansätze zu Routing, Validierung, Fehlerbehandlung und Datenzugriff. Selbst wenn der Code nicht perfekt ist, ist er meist so lesbar wie viele Tutorials und Starterprojekte.
Vertrautheit schlägt Originalität beim Rewrite
Rewrites sind teuer, weil Leute zuerst verstehen müssen, was existiert. Code, der bekannte Konventionen folgt, reduziert diese „Decodierungszeit“. Neue Entwickler:innen können das Gesehene auf mentale Modelle abbilden: wo Konfiguration liegt, wie Requests fließen, wie Dependencies verdrahtet sind und wo Tests hingehören.
Das macht es schneller, um:
- Nähte für den Austausch zu identifizieren (Module, Services, Endpunkte)
- Verhalten in einer neuen Implementierung nachzubilden
- Alt und Neu nebeneinander zu vergleichen, ohne zwischen Stilen zu übersetzen
Im Gegensatz dazu spiegeln stark handgefertigte Codebasen oft eine sehr persönliche Stilwelt wider: einzigartige Abstraktionen, Custom‑Mini‑Frameworks, cleveres „Glue“ oder domänenspezifische Patterns, die nur mit historischem Kontext Sinn ergeben. Diese Entscheidungen können elegant sein — aber sie erhöhen die Kosten eines Neuanfangs, weil ein Rewrite erst die Weltanschauung des Autors neu lernen muss.
Konventionen kannst du auch ohne KI durchsetzen
Das ist kein Zauber, der nur KI vorbehalten ist. Teams können (und sollten) Struktur und Stil durch Templates, Linter, Formatter und Scaffolding‑Tools erzwingen. Der Unterschied ist, dass KI dazu neigt, „generic by default“ zu sein, während menschlich geschriebene Systeme ohne aktive Pflege zu maßgeschneiderten Lösungen driftet.
Weniger maßgeschneidertes „Glue“ heißt oft weniger versteckte Abhängigkeiten
Viel Rewrite‑Schmerz entsteht nicht durch die „Haupt“-Business‑Logik, sondern durch maßgeschneidertes Glue — custom Helfer, hausgemachte Mikro‑Frameworks, Metaprogramming‑Tricks und einmalige Konventionen, die heimlich alles verbinden.
Was zählt als „bespoke glue"
Bespoke Glue ist das Zeug, das nicht Teil deines Produkts ist, aber ohne das dein Produkt nicht funktioniert. Beispiele: ein eigener Dependency‑Injection‑Container, eine DIY‑Routing‑Schicht, eine magische Basisklasse, die Modelle auto‑registriert, oder Helfer, die globalen Zustand „aus Bequemlichkeit“ mutieren. Es beginnt oft als Zeitgewinn und endet als erforderliches Wissen für jede Änderung.
Warum einzigartiges Glue Kopplung und Rewrite‑Risiko erhöht
Das Problem ist nicht das Glue an sich — es wird zur unsichtbaren Kopplung. Wenn Glue einzigartig für dein Team ist, dann:
- Entstehen implizite Abhängigkeiten (Dinge funktionieren nur, weil Helfer in einer bestimmten Reihenfolge laufen)
- Verteilen sich Annahmen über Dateien hinweg (Benennungsregeln werden zum Verhalten)
- Werden „einfache“ Refactors riskant (ändere das Glue, und alles geht kaputt)
Während eines Rewrites ist dieses Glue schwer korrekt zu replizieren, weil die Regeln selten niedergeschrieben sind. Man entdeckt sie erst, wenn man Produktion bricht.
Warum KI‑Code dazu neigt, extreme Cleverness zu vermeiden
KI‑Outputs neigen dazu, auf Standardbibliotheken, gebräuchliche Patterns und explizite Verdrahtung zu setzen. Erfindet die KI selten ein Mikro‑Framework, wenn ein einfaches Modul oder ein Service‑Objekt ausreicht. Diese Zurückhaltung kann ein Vorteil sein: weniger magische Hooks bedeuten weniger versteckte Abhängigkeiten, was das Herausreißen und Ersetzen eines Subsystems erleichtert.
Der Trade‑off: Redundanz statt Cleverness
Der Nachteil ist, dass „plain“ Code oft ausführlicher ist — mehr Parameter, mehr offensichtliche Verkabelung, weniger Abkürzungen. Aber Redundanz ist meist günstiger als Rätselhaftigkeit. Beim Entscheiden für einen Rewrite willst du Code, der leicht zu verstehen, leicht zu löschen und schwer fehlzuinterpretieren ist.
Vorhersehbare Struktur unterstützt inkrementelle Rewrites
„Vorhersehbare Struktur“ heißt weniger Schönheit als Konsistenz: dieselben Ordner, Benennungsregeln und Request‑Flows tauchen überall auf. KI‑generierte Projekte tendieren zu vertrauten Defaults — controllers/, services/, repositories/, models/ — mit repetitiven CRUD‑Endpunkten und ähnlichen Validierungsmustern.
Diese Uniformität macht aus einem Rewrite eher eine Treppe als einen Sprung.
Wie Vorhersehbarkeit aussieht
Du siehst Muster, die sich über Features wiederholen:
- Klare Ordnergrenzen (API → Service → Data Access)
- Konsistente Benennungen (
UserService, UserRepository, UserController)
- Ähnlicher CRUD‑Flow (list → get → create → update → delete)
- Standard‑Form für Fehler, Logging und Request/Response‑Objekte
Wenn jedes Feature gleich aufgebaut ist, kannst du ein Teil ersetzen, ohne jedes Mal neu lernen zu müssen.
Stückweises Austauschen
Inkrementelle Rewrites funktionieren am besten, wenn du eine Grenze isolieren und dahinter neu aufbauen kannst. Vorhersehbare Strukturen schaffen diese Nähte natürlich: jede Schicht hat eine schlanke Verantwortung, und die meisten Aufrufe laufen über eine kleine Menge von Schnittstellen.
Ein praktischer Ansatz ist der „Strangler“-Stil: halte die öffentliche API stabil und ersetze intern schrittweise.
Beispiel: Datenzugriff austauschen ohne API‑Änderung
Angenommen, Controller → Service → Repository:
OrdersController → OrdersService → OrdersRepository
Du willst von direkten SQL‑Queries zu einem ORM wechseln oder die DB tauschen. In einer vorhersehbaren Codebase lässt sich die Änderung begrenzen:
- Erstelle
OrdersRepositoryV2 (neue Implementierung)
- Behalte dieselben Methodensignaturen (
getOrder(id), listOrders(filters))
- Wechsel die Verdrahtung an einer Stelle (DI / Fabrik)
- Lauf Tests und rolle Feature für Feature aus
Controller und Service bleiben größtenteils unangetastet.
Gegensatz: handgefertigte Architekturen
Hochgradig handgeschmiedete Systeme können exzellent sein — aber sie kodieren oft einzigartige Ideen: custom Abstraktionen, clevere Metaprogrammierung oder querverbindendes Verhalten in Basisklassen. Das macht jede Änderung kontextabhängig. Mit vorhersehbarer Struktur ist die Frage „Wo ändere ich das?“ in der Regel einfach zu beantworten, weshalb kleine Rewrites Woche für Woche praktikabel werden.
Geringere „Author Attachment“ macht Löschen akzeptabler
Ein stiller Blocker bei vielen Rewrites ist nicht technisch, sondern sozial. Teams tragen oft ein Ownership‑Risiko, bei dem nur eine Person wirklich versteht, wie das System funktioniert. Wenn diese Person große Teile per Hand geschrieben hat, fühlt sich der Code schnell wie ein persönliches Artefakt an: „mein Design“, „meine clevere Lösung“, „mein Workaround, der den Release gerettet hat“. Diese Bindung macht Löschen emotional teuer, auch wenn es ökonomisch sinnvoll wäre.
KI‑generierter Code kann diesen Effekt abschwächen. Weil die Erstversion von einem Tool kommt (und oft vertrauten Patterns folgt), fühlt sich der Code weniger wie eine Signatur an und mehr wie eine austauschbare Implementierung. Teams sind eher bereit zu sagen: „Ersetzen wir dieses Modul“, wenn es sich nicht anfühlt, als würde man jemandes Handwerk ausradieren oder seinen Status infrage stellen.
Warum sich das Rewrite‑Verhalten ändert
Wenn Author Attachment geringer ist, neigen Teams dazu:
- Bestehenden Code offener zu hinterfragen („Ist das noch der beste Ansatz?“)
- Große Bereiche ohne Prestige‑Verhandlungen zu löschen
- Früher Regeneration oder Replacement zu wählen statt monatelangem Patchen
- Wissen schneller zu verbreiten, weil Interna nicht als „Besitz“ behandelt werden
Praktische Anmerkung
Rewrite‑Entscheidungen sollten weiterhin von Kosten und Ergebnissen geleitet sein: Liefertermine, Risiken, Wartbarkeit und Nutzerwirkung. „Leicht zu löschen“ ist ein nützliches Merkmal — keine Strategie für sich.
Prompts und Generations‑Traces können als Dokumentation dienen
Schnittstellenverhalten absichern
Definiere Verträge an Schnittstellen und regeneriere das Innenleben, ohne Clients zu brechen.
Ein unterschätzter Vorteil von KI‑generiertem Code ist, dass die Inputs zur Generierung wie eine lebende Spezifikation fungieren können. Ein Prompt, ein Template und eine Generator‑Konfiguration beschreiben die Absicht in Klartext: was das Feature tun soll, welche Einschränkungen gelten (Sicherheit, Performance, Stil) und was „fertig“ bedeutet.
Prompts als lebende Spezifikationen
Wenn Teams wiederverwendbare Prompts (oder Prompt‑Bibliotheken) und stabile Templates nutzen, entsteht eine Audit‑Spur von Entscheidungen, die sonst implizit blieben. Ein guter Prompt könnte Dinge explizit machen, die ein späterer Maintainer raten müsste:
- Erwarteter User‑Flow und Edge‑Cases
- Benennungsregeln und Ordnerstruktur
- Wie Fehler behandelt und geloggt werden sollen
- Was getestet werden muss (und was gemockt werden darf)
Das unterscheidet sich deutlich von vielen handgefertigten Codebasen, in denen Schlüsselentscheidungen in Commit‑Messages, Tribal Knowledge oder kleinen, ungschriebenen Konventionen verstreut sind.
Generations‑Traces helfen, Verhalten zu reproduzieren
Wenn du Generations‑Traces (Prompt + Modell/Version + Eingaben + Postprocessing‑Schritte) aufbewahrst, beginnt ein Rewrite nicht bei null. Du kannst dieselbe Checkliste wiederverwenden, um Verhalten unter einer saubereren Struktur neu zu erzeugen und dann die Ausgaben zu vergleichen.
In der Praxis kann das einen Rewrite in etwas verwandeln wie: „Feature X unter neuen Konventionen regenerieren und Parität prüfen“ statt „re‑engineering, was Feature X eigentlich tun sollte“.
Wichtige Warnung: Behandle Prompts wie Code
Das funktioniert nur, wenn Prompts und Konfigurationen mit derselben Disziplin wie Quellcode verwaltet werden:
- versioniere sie im Repo (nicht in den Notizen einer Person)
- erfordere Review für Änderungen
- dokumentiere, welches Prompt/Config welches Modul erzeugt hat
Ohne das werden Prompts zu einer weiteren undokumentierten Abhängigkeit. Mit Disziplin können sie die Dokumentation liefern, die handgefertigte Systeme oft vermissen.
Starke Tests verwandeln Rewrites in Routine‑Engineering
„Einfacher zu ersetzen“ hängt nicht daran, ob Code von einer Person oder einem Assistenten geschrieben wurde. Es geht darum, ob du ihn mit Vertrauen ändern kannst. Ein Rewrite wird zur Routine, wenn Tests dir schnell und zuverlässig sagen, dass das Verhalten gleich geblieben ist.
KI‑generierter Code kann dabei helfen — wenn du danach fragst. Viele Teams fordern Boilerplate‑Tests zusammen mit Features an (Unit‑Tests, einfache Integrationstests, Mocking). Diese Tests sind vielleicht nicht perfekt, aber sie schaffen ein initiales Sicherheitsnetz, das in handgebauten Systemen oft fehlt.
Setze Contract‑Tests an Grenzen ein
Wenn du Austauschbarkeit willst, konzentriere Tests auf die Nähte zwischen Teilen:
- Externe APIs: Requests, Responses, Fehlercodes, Retries, Pagination
- Adapter: Payment‑Provider, E‑Mail‑Services, Dateispeicher, Queues
- Datenmodelle: Migrationen, Serialisierung, Validierungsregeln
Contract‑Tests legen fest, was auch nach dem Austausch gleich bleiben muss. So kannst du ein Modul hinter einer API neu schreiben oder einen Adapter ersetzen, ohne das Business‑Verhalten neu zu verhandeln.
Nutze Coverage als Kompass, nicht als Trophäe
Coverage‑Zahlen zeigen Risiken, aber 100% zu jagen produziert oft fragile Tests, die Refactors blockieren. Stattdessen:
- Füge Tests dort hinzu, wo Fehler teuer sind (Geld, Datenverlust, Nutzervertrauen)
- Bevorzuge wenige, aussagekräftige Tests statt vieler oberflächlicher
- Vergleiche bei einem Rewrite alte und neue Implementierung über dieselben Contract‑Tests
Mit starken Tests werden Rewrites weniger Heldengeschichten und mehr eine Reihe sicherer, umkehrbarer Schritte.
Übliche Schwächen von KI‑Code sind oft leicht erkennbar und isolierbar
Pilot für austauschbare Module starten
Erstelle eine austauschbare Funktion in Koder.ai und entdecke, wie schnell du sie sicher ersetzen kannst.
KI‑generierter Code schlägt oft auf vorhersehbare Weise fehl. Du siehst häufig duplizierte Logik, „fast gleiche“ Branches mit unterschiedlichem Edge‑Case‑Handling oder Funktionen, die durch sukzessive Appends wachsen. Das ist nicht ideal — hat aber einen Vorteil: die Probleme sind oft sichtbar.
Offensichtliche Fehler statt subtiler, cleverer Bugs
Handgefertigte Systeme können Komplexität hinter cleveren Abstraktionen, Mikro‑Optimierungen oder eng gekoppeltem Verhalten verbergen. Diese Bugs sind schmerzhaft, weil sie korrekt aussehen und oberflächlichen Reviews standhalten.
KI‑Code ist eher offenkundig inkonsistent: ein Parameter wird in einem Pfad ignoriert, eine Validierung gibt es in einer Datei, aber nicht in einer anderen, oder die Fehlerbehandlung ändert den Stil alle paar Funktionen. Diese Unstimmigkeiten fallen in Reviews und bei statischer Analyse auf und sind leichter zu isolieren, weil sie selten auf tiefen, absichtlichen Invarianten beruhen.
Rewrite‑Kandidaten durch Wiederholung erkennen
Wiederholung ist der Tell. Wenn du denselben Ablauf wiederkehrend siehst — parse input → normalize → validate → map → return — dann hast du eine natürliche Naht zum Ersetzen gefunden. KI „löst“ oft neue Requests, indem es frühere Lösungen mit Anpassungen reproduziert, was Cluster von Near‑Duplicates erzeugt.
Ein praktischer Ansatz: markiere jeden wiederholten Chunk als Extraktions‑ oder Ersatzkandidat, besonders wenn:
- Er an 3+ Stellen mit kleinen Unterschieden auftaucht
- Die Unterschiede hauptsächlich Edge‑Case‑Handling oder Fehlermeldungen sind
- Der Code keinen klaren Eigentümer hat und ständig gepatcht wird
Faustregel: Konsolidiere Wiederholungen in ein getestetes Modul
Wenn du das wiederkehrende Verhalten in einem Satz benennen kannst, sollte es wahrscheinlich ein einzelnes Modul sein.
Ersetze die Duplikate durch eine gut getestete Komponente (Utility, Shared Service, Bibliotheksfunktion), schreibe Tests, die die erwarteten Edge‑Cases fixieren, und lösche dann die Kopien. Du hast viele fragile Kopien in einen Ort zum Verbessern verwandelt — und einen Ort, den du später neu schreiben kannst, falls nötig.
Lesbarkeit und Konsistenz wiegen oft mehr als handgefertigte Optimierung
KI‑generierter Code glänzt oft, wenn du ihn auf Klarheit statt Cleverness optimierst. Mit den richtigen Prompts und Linting‑Regeln wählt er meist vertrauten Kontrollfluss, konventionelle Benennungen und „langweilige“ Module gegenüber Neuem. Das kann auf lange Sicht mehr Wert bringen als ein paar Prozent Performance‑Gewinn durch handgetunte Tricks.
Warum lesbarer Code leichter neu zu schreiben ist
Rewrites gelingen, wenn neue Leute schnell ein korrektes mentales Modell des Systems aufbauen können. Lesbarer, konsistenter Code verkürzt die Zeit, um Fragen zu beantworten wie „Wo kommt die Anfrage herein?“ oder „Welche Form hat die Daten hier?“. Wenn jeder Service ähnliche Patterns folgt (Layout, Fehlerbehandlung, Logging, Konfiguration), kann ein neues Team einen Slice nach dem anderen ersetzen, ohne ständig lokale Konventionen neu zu lernen.
Konsistenz reduziert auch Angst. Vorhersehbarer Code lässt Ingenieur:innen Teile löschen und neu bauen, weil die Oberfläche leichter zu verstehen ist und die „Blast Radius“ geringer erscheint.
Hoch optimierter, handgeschriebener Code kann schwer zu rewrite sein, weil Performance‑Techniken oft überall durchsickern: custom Caching, Mikro‑Optimierungen, hausgemachte Concurrency‑Patterns oder enge Kopplung an spezifische Datenstrukturen. Diese Entscheidungen sind valide, schaffen aber oft subtile Constraints, die erst offensichtlich werden, wenn etwas bricht.
Lesbarkeit ist kein Freibrief für Langsamkeit. Verdiene Performance mit Beweisen. Vor einem Rewrite: erfasse Baseline‑Metriken (Latenz‑Perzentile, CPU, Speicher, Kosten). Nach dem Austausch: wieder messen. Wenn die Performance zurückgeht, optimiere gezielt den Hot Path — ohne die gesamte Codebase in ein Rätsel zu verwandeln.
Regenerieren vs. refactoren vs. neu schreiben: Die richtige Rücksetz‑Option wählen
Wenn eine KI‑unterstützte Codebase „merkwürdig“ wirkt, brauchst du nicht automatisch einen Full Rewrite. Die beste Option hängt davon ab, wie viel vom System falsch ist vs. nur unordentlich.
Drei Reset‑Optionen
Regenerieren heißt, einen Teil aus einer Spezifikation oder einem Prompt neu zu erzeugen — oft aus einem Template oder bekannten Pattern — und Integrationpunkte wieder anzubinden. Es ist nicht „alles löschen“, sondern „diesen Slice sauberer neu bauen".
Refactor behält Verhalten, ändert aber interne Struktur: umbenennen, Module splitten, Bedingung vereinfachen, Duplikation entfernen, Tests verbessern.
Rewrite ersetzt ein System oder Komponente durch eine neue Implementierung, meist weil das aktuelle Design nicht gesund zu machen ist, ohne Verhalten, Grenzen oder Datenflüsse zu ändern.
Wann Regeneration gut passt
Regeneration eignet sich, wenn der Code größtenteils Boilerplate ist und der Wert in Interfaces liegt statt in cleveren Interna:
- CRUD‑UIs und Admin‑Panels
- API‑Adapter und dünne Integrationsschichten
- Scaffolding: Routing, Serializer, DTOs, einfache Validierung, Standard‑Fehlerbehandlung
Ist die Spezifikation klar und die Modulgrenze sauber, ist Regenerieren oft schneller als das Entwirren inkrementeller Änderungen.
Wann Regeneration riskant ist (oder scheitert)
Vorsicht bei Code, der hart erarbeitetes Domänenwissen oder subtile Korrektheitsvoraussetzungen kodiert:
- Domänenintensive Business‑Rules mit vielen Edge‑Cases
- Komplexe Concurrency (Queues, Locks, Retries, Idempotenz)
- Compliance‑Logik (Audit‑Trails, Aufbewahrung, Datenschutzregeln)
In diesen Bereichen kann „nah genug“ teuer falsch sein — Regeneration hilft nur, wenn du Äquivalenz mit starken Tests belegen kannst.
Review‑Gates und kleine Rollouts
Behandle regenerierten Code wie eine neue Dependency: erfordere menschliche Review, laufe die komplette Test‑Suite und ergänze gezielte Tests für bekannte Fehlerfälle. Rolle schrittweise aus — einen Endpunkt, eine Seite, einen Adapter — hinter einem Feature‑Flag oder via Gradual Release.
Eine nützliche Default‑Regel: regeneriere die Hülle, refactore die Nähte, schreibe nur das neu, was Annahmen ständig bricht.
Risiken und Leitplanken für „by design ersetzbaren“ Code
Prototyp für eine saubere V2 erstellen
Starte einen kleinen CRUD-Service und iteriere, bis er klar, getestet und austauschbar ist.
„Leicht ersetzbar“ bleibt nur dann ein Vorteil, wenn Teams Ersatz als engineering‑gestützte Aktivität behandeln, nicht als beiläufigen Reset‑Button. KI‑geschriebene Module lassen sich schneller tauschen — sie können aber auch schneller scheitern, wenn man ihnen mehr vertraut, als man verifiziert.
Wichtige Risiken
KI‑generierter Code wirkt oft vollständig, auch wenn er es nicht ist. Das erzeugt falsches Vertrauen, besonders wenn Happy‑Path‑Demos funktionieren.
Ein zweites Risiko sind fehlende Edge‑Cases: ungewöhnliche Inputs, Timeouts, Concurrency‑Eigenheiten und Fehlerbehandlung, die im Prompt oder den Beispieldaten nicht abgedeckt waren.
Schließlich gibt es Lizenz-/IP‑Unsicherheit. Teams sollten Richtlinien haben, welche Quellen/Tools akzeptabel sind und wie Herkunft nachverfolgt wird.
Leitplanken, die Rewrites sicher halten
Setze Ersatz hinter dieselben Gates wie jede andere Änderung:
- Code Review mit explizitem „generated code“ Fokus: Lesbarkeit, Failure‑Modes, Input‑Validation und Logging
- Security Checks (SAST, Dependency‑Scanning, Secrets‑Detection); generierter Code darf sie nicht umgehen
- Dependency‑Policies: wenige, etablierte Bibliotheken bevorzugen; Versionen pinnen; nicht einfach ein neues Framework wegen eines Prompts einführen
- Audit‑Trails: Prompts, Modell/Tool‑Versionen und Generations‑Notizen im Repo ablegen, sodass Änderungen später erklärbar sind
Dokumentiere Grenzen, bevor du Module tauschst
Bevor du eine Komponente ersetzt, notiere ihre Grenze und Invarianten: welche Inputs akzeptiert werden, welche Zusicherungen gelten, was sie niemals tun darf (z. B. „keine Kundendaten löschen“), sowie Performance‑/Latenz‑Erwartungen. Dieser „Contract“ ist das, worauf du testest — unabhängig davon, wer (oder was) den Code schreibt.
Ein leichtes Checklisten‑Kürzel
- Definiere Modul‑Contract (Inputs/Outputs, Invarianten).
- Füge/prüfe Tests für Edge‑Cases.
- Führe Security‑ und Dependency‑Scans aus.
- Review auf Lesbarkeit und Fehlerbehandlung.
- Speichere Prompt/Tool‑Metadaten.
- Shippe hinter einem Flag und monitoren.
Praktische Erkenntnisse und ein einfacher nächster Schritt
KI‑generierter Code ist oft einfacher neu zu schreiben, weil er zu vertrauten Patterns tendiert, tiefe „Handwerks‑Personalisierung“ vermeidet und sich leichter regenerieren lässt, wenn sich Anforderungen ändern. Diese Vorhersehbarkeit reduziert soziale und technische Kosten, Teile des Systems zu löschen und zu ersetzen.
Das Ziel ist nicht „Code wegschmeißen“, sondern Ersetzen als normale, wenig friction‑behaftete Option zu etablieren — abgesichert durch Contracts und Tests.
Maßnahmen, die du diese Woche umsetzen kannst
Beginne damit, Konventionen zu standardisieren, damit jeder regenerierte oder neu geschriebene Code in denselben Rahmen passt:
- Konventionen festschreiben: Formatierung, Ordnerstruktur, Benennung, Fehlerbehandlung und API‑Shape. Schreibe eine kurze CONTRIBUTING.md.
- Contract‑Tests an Grenzen hinzufügen: Fokus auf Inputs/Outputs von Modulen und Services (HTTP‑Endpoints, Queue‑Messages, DB‑Zugriffsschichten). Diese Tests sollen bestehen bleiben, auch wenn Implementierungen getauscht werden.
- Prompts und Specs nachverfolgen: Speichere Prompts, Anforderungsnotizen und Generations‑Traces neben dem Code, damit zukünftige Rewrites Intent reproduzieren können, nicht nur Text.
Wenn du einen vibe‑coding Workflow nutzt, such nach Tools, die diese Praktiken erleichtern: Speichern von „Planning Mode“ Specs im Repo, Erfassen von Generations‑Traces und Unterstützung für sicheres Rollback. Beispiele: Koder.ai ist um Chat‑getriebene Generierung mit Snapshots und Rollback gebaut — passt gut zu einem „replaceable by design“ Ansatz: Slice regenerieren, Contract stabil halten und bei Paritätsfehlern schnell zurückrollen.
Führe ein kleines „replaceable module“ Pilotprojekt aus
Wähle ein Modul, das wichtig, aber isoliert ist — Report‑Generierung, Notification‑Sending oder ein einzelner CRUD‑Bereich. Definiere die öffentliche Schnittstelle, füge Contract‑Tests hinzu und erlaube dir, Interna zu regenerieren/refactoren/rewriten, bis alles langweilig ist. Messe Zykluszeit, Fehler‑Rate und Review‑Aufwand; nutze die Ergebnisse, um teamweite Regeln zu definieren.
Um das zu operationalisieren, behalte eine Checkliste im internen Playbook (oder teile sie via /blog) und mache das Trio „contracts + conventions + traces“ zur Anforderung für neue Arbeit. Wenn du Tooling evaluierst, dokumentiere außerdem, welche Features du von einer Lösung erwartest, bevor du zu /pricing gehst.