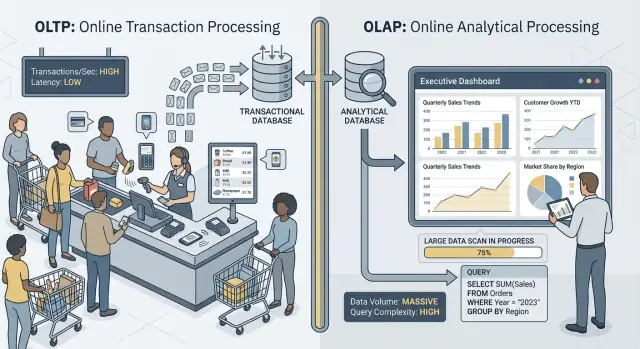
OLTP vs OLAP: Was das ist (ohne Fachchinesisch)
Wenn Leute von OLTP und OLAP sprechen, meinen sie zwei sehr unterschiedliche Nutzungsarten einer Datenbank.
OLTP: die Datenbank, die das Geschäft antreibt
OLTP (Online Transaction Processing) ist die Arbeitslast hinter den täglichen Aktionen, die schnell und korrekt sein müssen. Denken Sie: Daten jetzt speichern.
Typische OLTP-Aufgaben sind das Anlegen einer Bestellung, Aktualisieren des Inventars, Erfassen einer Zahlung oder Ändern einer Kundenadresse. Diese Operationen sind meist klein (ein paar Zeilen), häufig und müssen in Millisekunden antworten, weil ein Mensch oder ein anderes System wartet.
OLAP: die Datenbank, die das Geschäft erklärt
OLAP (Online Analytical Processing) ist die Arbeitslast, mit der man verstehen will, was passiert ist und warum. Denken Sie: viele Daten scannen und zusammenfassen.
Typische OLAP-Aufgaben sind Dashboards, Trendberichte, Kohortenanalysen, Forecasting und „Slice-and-Dice“-Fragen wie: „Wie hat sich der Umsatz nach Region und Produktkategorie in den letzten 18 Monaten verändert?“ Diese Abfragen lesen oft sehr viele Zeilen, führen schwere Aggregationen durch und können Sekunden (oder Minuten) laufen, ohne „falsch“ zu sein.
Dieselben Daten, unterschiedliche Ziele — und unterschiedliche Anforderungen
Die Hauptidee ist einfach: OLTP optimiert für schnelle, konsistente Writes und kleine Reads, während OLAP für große Reads und komplexe Berechnungen optimiert. Weil die Ziele auseinandergehen, unterscheiden sich auch die besten Datenbank-Einstellungen, Indizes, Speicherlayouts und Skalierungsansätze.
Beachten Sie auch die Formulierung: selten, nicht nie. Einige kleine Teams können eine Datenbank eine Zeitlang teilen, besonders bei moderatem Datenvolumen und disziplinärem Query-Verhalten. Spätere Abschnitte behandeln, was zuerst bricht, gängige Trennungspatterns und wie man Reporting sicher von der Produktion verlagert.
Kurze Beispiele
- Checkout (OLTP): Ein Kunde klickt auf „Bezahlen“, und Ihre App schreibt eine Bestellung, den Zahlungsstatus und Inventar-Updates.
- Reporting-Dashboard (OLAP): Ein Manager öffnet ein Dashboard, das Tausende (oder Millionen) Bestellungen aggregiert, um Conversion-Rate, durchschnittlichen Bestellwert und Wochen-Trends zu zeigen.
Unterschiedliche Ziele, unterschiedliche Erfolgsmetriken
OLTP und OLAP "nutzen beide SQL", sind aber für unterschiedliche Aufgaben optimiert — das zeigt sich darin, was für sie Erfolg bedeutet.
OLTP: Geschwindigkeit, Parallelität und Korrektheit
Transaktionale Systeme treiben den Tagesbetrieb: Checkout-Flows, Kontoänderungen, Reservierungen, Support-Tools. Prioritäten sind:
- Schnelle Antwortzeiten für kleine Reads/Writes (Denken Sie Millisekunden)
- Viele gleichzeitige Nutzer ohne Einbrüche
- Korrektheit und Konsistenz, weil ein falscher Kontostand oder eine doppelte Bestellung echtes Geschäftsschaden bedeutet
Der Erfolg wird oft mit Latenzmetriken wie p95/p99 Request-Zeit, Fehlerquote und Verhalten unter Spitzenparallelität gemessen.
OLAP: Scans, Aggregation und Flexibilität
Analytics-Systeme beantworten Fragen wie „Was hat sich dieses Quartal verändert?“ oder „Welches Segment churnte nach der neuen Preisgestaltung?“ Solche Abfragen:
- Scannen große Datenmengen über viele Zeilen
- Führen Aggregationen (SUM, COUNT, Percentiles) und Joins durch
- Ändern sich häufig, während Analysten explorieren und verfeinern
Erfolg misst man hier eher an Query-Durchsatz, Time-to-Insight und der Fähigkeit, komplexe Abfragen ohne manuelles Tuning auszuführen.
Warum „ein System für alles“ Kompromisse erzwingt
Wenn Sie beide Workloads in eine Datenbank zwingen, erwarten Sie, dass sie gleichzeitig großartige kleine Transaktionen und große explorative Scans handhabt. Das Ergebnis ist meist ein Kompromiss: OLTP bekommt unvorhersehbare Latenzen, OLAP wird gedrosselt, um die Produktion zu schützen, und Teams streiten darüber, welche Abfragen „erlaubt“ sind. Getrennte Ziele verdienen getrennte Erfolgsmetriken — und meist getrennte Systeme.
Ressourcenwettstreit: Wenn Analytics von Transaktionen stiehlt
Wenn OLTP (die täglichen Transaktionen Ihrer App) und OLAP (Reporting und Analyse) auf derselben Datenbank laufen, konkurrieren sie um dieselben endlichen Ressourcen. Das Resultat ist nicht nur "langsameres Reporting" — oft sind Checkouts langsamer, Logins stocken und die App zeigt unvorhersehbare Störungen.
CPU und Speicher: lange Queries vs. kurze Queries
Analytische Abfragen sind oft lang und schwer: Joins großer Tabellen, Aggregationen, Sortieren und Gruppieren. Sie können CPU-Kerne und besonders Speicher für Hash-Joins und Sort-Buffer monopolieren.
Transaktionale Queries sind klein, aber Latenz-sensitiv. Wenn die CPU ausgelastet ist oder Speicherdruck zu häufigen Evictions führt, warten diese kleinen Queries hinter den großen — selbst wenn jede Transaktion nur wenige Millisekunden Arbeit bräuchte.
Festplatten-I/O: große Scans vs. viele kleine Reads/Writes
Analytics löst oft umfassende Table-Scans aus und liest viele Seiten sequentiell. OLTP macht viele kleine, zufällige Reads plus konstante Writes in Indizes und Logs.
Kombiniert führt das dazu, dass das Storage-Subsystem widersprüchliche Zugriffsprofile jonglieren muss. Caches, die OLTP halfen, werden durch Analytics-Scans „weggespült“, und Write-Latenz kann ansteigen, wenn die Festplatte Daten für Reports streamt.
Connection-Pool-Druck und Queueing
Ein paar Analysten, die breite Abfragen fahren, können Verbindungen für Minuten belegen. Wenn Ihre Anwendung einen festen Pool nutzt, stauen sich Requests und warten auf freie Verbindungen. Dieser Queueing-Effekt lässt ein ansonsten gesundes System kaputt erscheinen: Durchschnittslatenz mag akzeptabel aussehen, aber Tail-Latenzen (p95/p99) werden schmerzhaft.
Was Nutzer tatsächlich bemerken
Nach außen zeigt sich das als Timeouts, langsame Checkout-Flows, verzögerte Suchergebnisse und generell flackerndes Verhalten — oft „nur während Reporting“ oder „nur am Monatsende“. Das App-Team sieht Fehler; das Analytics-Team sieht langsame Abfragen; das eigentliche Problem ist die gemeinsame Ressourcennutzung darunter.
Datenlayout und Indexbedarf ziehen in entgegengesetzte Richtungen
OLTP und OLAP belohnen oft gegensätzliche physische Designs. Versuchen Sie, beide in einem System zu befriedigen, endet das meist in einem teuren Kompromiss, der dennoch unterperformt.
OLTP: optimiert für schnelle, selektive Lookups
Transaktionale Workloads dominieren kurze Queries, die nur eine kleine Datenmenge berühren: eine Bestellung abrufen, eine Inventarzeile aktualisieren, die letzten 20 Events eines Nutzers listen.
Das zieht OLTP-Schemata zu zeilenorientierter Speicherung und Indizes, die Point-Lookups und kleine Bereichsscans unterstützen (Primär-/Fremdschlüssel und einige wenige sekundäre Indizes). Ziel ist vorhersehbare, niedrige Latenz — besonders bei Writes.
OLAP: optimiert für Scans, Gruppieren und Zusammenfassen
Analytics muss oft viele Zeilen, aber nur wenige Spalten lesen: „Umsatz pro Woche und Region“, „Conversion nach Kampagne“, „Top-Produkte nach Marge“.
OLAP-Systeme profitieren von spaltenorientierter Speicherung (nur benötigte Spalten lesen), Partitionierung (um alte/irrelevante Daten schnell auszuschließen) und Voraggregationen (materialisierte Views, Rollups, Summary-Tabellen), damit Reports nicht wiederholt dieselben Totals neu berechnen.
Warum "für alles indizieren" nach hinten losgeht
Ein häufiger Reflex ist, Indizes hinzuzufügen, bis jedes Dashboard schnell ist. Aber jeder Index erhöht die Schreibkosten, vergrößert den Speicherbedarf und verlangsamt Wartungsaufgaben wie Vacuuming, Reindexing und Backups.
Query-Planner und Statistikdrift (einfach erklärt)
Datenbanken wählen Query-Pläne auf Basis von Statistiken — Schätzungen, wie viele Zeilen einen Filter matchen und wie Daten verteilt sind. OLTP ändert Daten ständig. Wenn sich Verteilungen verschieben, driften Statistiken, und der Planner kann heute einen Plan wählen, der gestern gut war, heute aber langsam ist.
Schwere OLAP-Abfragen, die große Tabellen scannen und joinen, erhöhen diese Variabilität: Der „beste Plan“ wird schwieriger vorherzusagen, und Tuning für eine Arbeitslast verschlechtert oft die andere.
Locking, MVCC und Nebenwirkungen bei Wartung
Selbst wenn Ihre Datenbank „Concurrency unterstützt“, erzeugt das Mischen von Reporting und Live-Transaktionen subtile Verzögerungen, die schwer vorherzusagen und noch schwerer zu erklären sind — besonders gegenüber einem Kunden, der an der Checkout-Seite einen Spinner sieht.
Lange Abfragen erzeugen trotzdem Lock-Probleme
OLAP-Queries scannen oft viele Zeilen, joinen mehrere Tabellen und laufen Sekunden oder Minuten. Währenddessen können sie Locks halten (z. B. auf Schema-Objekte oder beim Schreiben in temporäre Strukturen) und erhöhen indirekt Lock-Contention, weil sie viele Zeilen „in Spiel“ halten.
Selbst mit MVCC muss die Datenbank mehrere Versionen derselben Zeile nachverfolgen, damit Leser und Schreiber sich nicht blockieren. Das hilft, eliminiert Contention aber nicht — vor allem bei heißen Tabellen, die Transaktionen ständig verändern.
MVCC hat versteckte Kosten: Aufräumen wird schwieriger
MVCC bedeutet, dass alte Row-Versionen so lange bleiben, bis die DB sie gefahrlos entfernen kann. Ein lang laufender Report kann einen alten Snapshot offenhalten und so das Aufräumen verhindern.
Das wirkt sich aus auf:
- Vacuum/Garbage-Collection: Aufräumen kann tote Tupel/Versionen nicht so schnell entfernen.
- Bloat/Fragmentierung: Speicher wächst, Indizes werden ineffizienter und Caches weniger nützlich.
- Kompaktionsdruck: Einige Engines reagieren mit intensiverer Hintergrundarbeit, die I/O und CPU von Transaktionen abzieht.
Das Ergebnis ist ein doppelter Schlag: Reporting erhöht die Last und macht das System über die Zeit langsamer.
Isolation Levels verstärken Latenz-Variabilität
Reporting-Tools verlangen oft starke Isolation (oder laufen versehentlich in einer langen Transaktion). Höhere Isolation kann Wartezeiten auf Locks erhöhen und die Menge der Versionierung, die die Engine verwalten muss, vergrößern. Aus OLTP-Sicht sieht man das als unvorhersehbare Spikes: die meisten Orders schreiben schnell, dann stocken plötzlich einige.
Praktisches Beispiel: Monatsabschluss bremst Bestellungen
Am Monatsende führt Finance eine „Umsatz nach Produkt“-Abfrage aus, die Bestellungen und Line-Items des gesamten Monats scannt. Während sie läuft, werden neue Bestellungen akzeptiert, aber Vacuum kann alte Versionen nicht freigeben und Indizes churnen. Die Order-API sieht gelegentliche Timeouts — nicht weil sie „down“ ist, sondern weil Contention und Aufräum-Overhead die Latenz über Ihre Grenzwerte drücken.
Spitzenlasten und unvorhersehbare Latenz
Kollegen werben und Credits verdienen
Gewinne Teamkollegen per Empfehlung und erhalte Credits, sobald neue Nutzer beitreten.
OLTP-Systeme leben und sterben von Vorhersehbarkeit. Ein Checkout, Support-Ticket oder Saldo-Update ist nicht „meistens okay“, wenn es 95% der Zeit schnell ist — Nutzer merken die langsamen Momente. OLAP ist oft bursty: ein paar schwere Queries können Stunden ruhig sein und dann plötzlich viel CPU, Speicher und I/O verbrauchen.
Spitzen treten aus normalen Geschäftsgründen auf
Analytics-Traffic bündelt sich häufig um Routinen:
- Morgen-Standup-Dashboards, bei denen viele Leute die gleichen Charts neu laden
- Geplante Reports, die zur vollen Stunde starten
- Monats- und Quartalsabschlüsse, die lange Scans und Joins auslösen
OLTP-Traffic ist meist gleichmäßiger. Wenn beide Workloads eine DB teilen, führen diese Analytics-Spitzen zu unvorhersehbarer Latenz für Transaktionen — Timeouts, langsamere Seitenladezeiten und Retries, die noch mehr Last erzeugen.
Warum Limits und Scheduling helfen — aber das Grundproblem nicht lösen
Sie können Schäden reduzieren durch Reportläufe in Nebenzeiten, Begrenzung der Parallelität, Statement-Timeouts oder Query-Kosten-Limits. Das sind nützliche Schutzmechanismen, besonders beim "Reporting on production".
Aber sie nehmen nicht die fundamentale Spannung weg: OLAP-Abfragen sind darauf ausgelegt, viele Ressourcen zu nutzen, um große Fragen zu beantworten, während OLTP kleine, schnelle Ressourcenscheiben den ganzen Tag braucht. Sobald ein unerwarteter Dashboard-Refresh, eine Ad-hoc-Abfrage oder ein Backfill durchrutscht, ist die gemeinsame Datenbank wieder exponiert.
Das "noisy neighbor"-Problem
Auf gemeinsamer Infrastruktur kann ein "lauter" Analytics-Job Cache monopolieren, Disk saturieren oder CPU-Planung belasten — ganz ohne Fehler. OLTP wird Kollateralschaden, und das Schlimmste ist, dass die Ausfälle zufällig aussehen: Latenzspikes statt klarer, reproduzierbarer Fehler.
Operative Komplexität: Backup, Sicherheit und Kapazitätsplanung
Das Mischen von OLTP und OLAP erzeugt nicht nur Performance-Kopfschmerzen — es macht den täglichen Betrieb komplizierter. Die Datenbank wird zur "Alles-in-einem-Box" und jede Betriebsaufgabe erbt die kombinierten Risiken beider Workloads.
Backups, Restores und Disaster Recovery werden langsamer
Analytics-Tabellen wachsen oft breit und schnell (mehr Historie, mehr Spalten, mehr Aggregate). Dieses Volumen verändert Ihre Recovery-Story.
Ein Full-Backup dauert länger, verbraucht mehr Storage und erhöht die Chance, dass Sie Ihr Backup-Fenster verpassen. Restores sind schlimmer: Bei einer Wiederherstellung spielen Sie nicht nur transaktionale Daten zurück, die die App zum Laufen braucht, sondern auch große analytische Datensätze, die für den Geschäftsbetrieb nicht zwingend nötig sind. DR-Tests dauern länger und finden seltener statt — genau das Gegenteil von dem, was Sie wollen.
Kapazitätsplanung wird zum Ratespiel
Transaktionelles Wachstum ist meist vorhersehbar: mehr Kunden, mehr Bestellungen, mehr Zeilen. Analytics-Wachstum ist oft stückig: ein neues Dashboard, eine geänderte Aufbewahrungsrichtlinie oder ein Team, das "noch ein Jahr" Rohdaten behalten will.
Bei gemeinsamer Haltung können Sie schwer beantworten:
- Wachsen wir, weil das Produkt erfolgreich ist, oder weil Reports mehr Historie speichern?
- Brauchen wir schnelleren Storage für Transaktionen oder billigen Storage für Analytics?
Diese Unsicherheit führt zu Überprovisionierung (Sie zahlen für unnötigen Spielraum) oder Unterprovisionierung (Überraschungs-Ausfälle).
Schutzmechanismen sind schwer fair durchzusetzen
In einer geteilten DB kann eine "harmlose" Abfrage zum Incident werden. Sie werden Guardrails wie Timeouts, Workload-Quoten, geplante Reporting-Fenster oder Regeln zum Workload-Management einführen. Das hilft, ist aber fragil: App und Analysten konkurrieren um dieselben Limits, und Policy-Änderungen für die eine Gruppe können die andere brechen.
Sicherheit und Zugriffssteuerung werden unordentlich
Apps brauchen enge, zweckgebundene Berechtigungen. Analysten benötigen oft breite Lesezugriffe über viele Tabellen, um zu explorieren und zu validieren. Beides in einer DB erhöht den Druck, weiterreichende Rechte zu gewähren, "damit der Report funktioniert", vergrößert die Blast-Radius von Fehlern und erweitert die Anzahl an Personen, die sensible operative Daten sehen können.
Skalierung und Kosten: Am Ende zahlen Sie oft doppelt (oder mehr)
Passenden Tarif wählen
Probiere Koder.ai kostenlos, wechsle dann zu Pro, Business oder Enterprise, wenn du mehr brauchst.
OLTP und OLAP in derselben Datenbank zu betreiben wirkt zunächst günstiger — bis Sie skalieren. Das Problem ist nicht nur Performance. Die "richtige" Art, jede Arbeitslast zu skalieren, führt zu unterschiedlicher Infrastruktur, und das Zusammenführen zwingt teure Kompromisse auf.
OLTP-Skalierung ist schreibgetrieben (und oft schmerzhaft)
Transaktionale Systeme sind durch Writes begrenzt: viele kleine Updates, strikte Latenz und Bursts, die sofort absorbiert werden müssen. OLTP skaliert man häufig vertikal (größere CPU, schnellere Disks, mehr RAM), weil write-lastige Workloads sich schwer horizontal verteilen lassen.
Wenn die vertikalen Grenzen erreicht sind, stehen Sharding oder andere Write-Scaling-Pattern an, was Engineering-Aufwand und oft Änderungen an der Anwendung erfordert.
OLAP-Skalierung ist compute-getrieben (und oft elastisch)
Analytics skaliert anders: lange Scans, schwere Aggregationen und großer Read-Durchsatz. OLAP-Systeme fügt man typischerweise verteilte Rechenkapazität hinzu, und moderne Setups trennen oft Compute von Storage, sodass man Query-Horsepower skalieren kann, ohne Daten zu duplizieren.
Teilt OLAP die OLTP-Datenbank, können Sie Analytics nicht unabhängig skalieren — Sie skalieren die ganze DB, auch wenn Transaktionen bereits in Ordnung sind.
Die versteckte Rechnung: OLTP-Ressourcen für Analytics bezahlen
Um Transaktionen schnell zu halten, während Reports laufen, überprovisionieren Teams die Produktionsdatenbank: zusätzliche CPU-Reserven, High-End-Storage und größere Instanzen "für alle Fälle". So zahlen Sie OLTP-Preise, um OLAP-Verhalten zu unterstützen.
Trennung erlaubt, jedes System passend zu dimensionieren: OLTP für vorhersehbare, latenzarme Writes; OLAP für burstige, schwere Reads. Ergebnis ist oft günstiger insgesamt — auch wenn es "zwei Systeme" statt einem sind — weil Sie aufhören, Premium-Transaktionskapazität für Reporting zu bezahlen.
Gängige Architekturen, die OLTP und OLAP trennen
Die meisten Teams trennen transaktionale Last (OLTP) von analytischer Last (OLAP), indem sie ein zweites, leseorientiertes System hinzufügen, anstatt eine Datenbank für beides zu missbrauchen.
Pattern 1: Read-Replica fürs Reporting
Ein üblicher erster Schritt ist eine Read-Replica (Follower) der OLTP-Datenbank, auf der BI-Tools laufen.
Vorteile: minimale App-Änderungen, vertrautes SQL, schnell einzurichten.
Nachteile: dieselbe Engine und Schema bleiben, schwere Reports können Replica-CPU/I/O sättigen; manche Reports brauchen Features, die auf Replikaten nicht verfügbar sind; Replikationsverzögerung kann Zahlen Minuten (oder länger) hinterherhinken. Verzögerung sorgt für verwirrende "Warum stimmt es nicht mit Produktion überein?"-Gespräche.
Beste Passung: kleine Teams, moderates Datenvolumen, "near-real-time" ist nett, aber nicht kritisch, und Reporting-Queries sind kontrolliert.
Pattern 2: Dediziertes Data Warehouse / Analytics-DB
OLTP bleibt für Writes und Point-Reads optimiert; Analytics wandert in ein Data Warehouse (oder spaltenorientierte Analytics-DB), das für Scans, Kompression und große Aggregationen gebaut ist.
Vorteile: vorhersehbare OLTP-Performance, schnellere Dashboards, bessere Konkurrenzfähigkeit für Analysten und klarere Kosten-/Performance-Optimierung.
Nachteile: ein weiteres System zu betreiben und ein Analytics-freundliches Datenmodell (oft Star-Schema) zu erstellen.
Beste Passung: wachsendes Datenvolumen, viele Stakeholder, komplexes Reporting oder strikte OLTP-Latenz-Anforderungen.
Pattern 3: CDC-basierte Pipeline in Analytics
Statt periodischem ETL streamen Sie Änderungen via CDC (Change Data Capture) aus dem OLTP-Log in das Warehouse (oft mit ELT).
Vorteile: frischere Daten bei geringerem OLTP-Load, einfachere inkrementelle Verarbeitung und bessere Auditierbarkeit.
Nachteile: mehr bewegliche Teile und vorsichtiger Umgang mit Schemaänderungen.
Beste Passung: größere Volumen, hohe Freshness-Anforderungen und Teams, die bereit für Datenpipelines sind.
Daten sicher von OLTP nach OLAP bekommen
Daten vom transaktionalen System in ein Analytics-System zu bewegen, ist weniger "Tabellen kopieren" und mehr "einen zuverlässigen, risikoarmen Pipeline-Prozess bauen". Ziel: Analytics bekommt, was es braucht, ohne die Produktion zu gefährden.
ETL vs ELT (kurz und praktisch)
ETL (Extract, Transform, Load): Daten werden bereinigt und geformt, bevor sie im Warehouse landen. Nützlich, wenn Warehouse-Compute teuer ist oder Sie genau kontrollieren wollen, was gespeichert wird.
ELT (Extract, Load, Transform): Rohere Daten werden zuerst geladen, dann im Warehouse transformiert. Schnell aufzusetzen und leichter evolvierbar: Sie behalten History und können Transformationen anpassen, wenn sich Anforderungen ändern.
Praktische Regel: ändert sich Geschäftslogik häufig, reduziert ELT Nacharbeit; verlangt Governance kuratierte Daten, kann ETL passender sein.
CDC-Grundlagen: Änderungen ohne schwere Queries erfassen
Change Data Capture (CDC) streamt Inserts/Updates/Deletes aus OLTP (oft über das DB-Log) in Ihr Analytics-System. Statt große Tabellen immer wieder zu scannen, bewegt CDC nur das, was sich geändert hat.
Was das ermöglicht:
- Near-real-time Reporting ohne große Reads auf Produktion
- Replays und Backfills, wenn Analytics-Tabellen neu aufgebaut werden müssen
- Historienverfolgung (wer hat was wann geändert), falls Sie Change-Events speichern
Datenfrische: Echtzeit vs Near-Real-Time vs Täglich
Freshness ist eine Geschäftsentscheidung mit technischem Preis.
- Echtzeit (Sekunden): gut für operative Dashboards, aber schwer stabil zu halten; kleine Pipeline-Hicks zeigen sich sofort.
- Near-real-time (Minuten): häufig der Sweetspot — gute Entscheidungsgrundlage ohne extreme Komplexität.
- Tägliche Batches: am simpelsten und günstigsten, ideal für Finanz-Reporting, bei dem "gestern" ausreicht.
Definieren Sie eine klare SLA (z. B. "Daten sind maximal 15 Minuten verzögert"), damit Stakeholder wissen, was "frisch" bedeutet.
Data-Quality-Checks, die stille Ausfälle verhindern
Pipelines brechen oft stillschweigend — bis jemand abweichende Zahlen bemerkt. Fügen Sie leichte Checks hinzu für:
- Schema-Änderungen: neue Spalten, umbenannte Felder oder Typänderungen, die Daten nullen können
- Spät eintreffende Events: Bestellungen oder Zahlungen, die Stunden später kommen; behandeln mit einem "Lookback-Window"
- Deduplizierung: Retries und Replays können doppelt zählen; nutzen Sie stabile IDs und idempotente Loads
Diese Schutzmaßnahmen halten OLAP vertrauenswürdig und die Produktion geschützt.
Wann das Teilen einer Datenbank akzeptabel sein kann
Verdiene Credits für deinen Beitrag
Veröffentliche deinen Build und verdiene Koder.ai‑Credits, um weiter zu bauen.
OLTP und OLAP zusammenzuhalten ist nicht per se falsch. Es kann eine sinnvolle Übergangsentscheidung sein, wenn die Anwendung klein ist, Reporting eng gefasst ist und harte Grenzen dafür sorgen, dass Analytics nicht plötzlich Checkouts, Zahlungen oder Timeouts verlangsamt.
Situationen, in denen es funktionieren kann
Kleine Apps mit leichter Analytics-Last und strikten Query-Limits kommen oft gut mit einer einzigen DB zurecht — besonders am Anfang. Entscheidend ist Ehrlichkeit darüber, was "leicht" heißt: einige Dashboards, moderates Zeilenvolumen und klare Laufzeit- und Parallelitätsobergrenzen.
Für einige wiederkehrende Reports können materialisierte Views oder Summary-Tabellen die Kosten reduzieren. Statt Rohtransaktionen zu scannen, preberechnen Sie tägliche Totals, Top-Kategorien oder Kunden-Rollups. Das hält die meisten Abfragen kurz und vorhersehbar.
Wenn Business-User verzögerte Zahlen tolerieren, helfen Off-Peak-Reporting-Fenster. Planen Sie schwere Jobs nachts oder in Traffic-Tiefphasen und erwägen Sie eine dedizierte Reporting-Rolle mit engeren Rechten und Ressourcenlimits.
Guardrails, die Sie setzen sollten
- Statement-Timeouts setzen und ausufernde Queries abbrechen.
- Reporting-Concurrency begrenzen.
- p95/p99-Latenz für Kerntransaktionen separat vom Reporting überwachen.
Klare Warnsignale für den Split
Wenn Sie steigende Transaktionslatenz, wiederkehrende Incidents während Reportläufen, Connection-Pool-Erschöpfung oder Geschichten wie "eine Abfrage hat die Produktion lahmgelegt" sehen, sind Sie aus der sicheren Zone raus. Dann ist Trennung (oder zumindest Read-Replicas) keine Optimierung mehr, sondern grundlegende Betriebshygiene.
Praktische Migrations-Checkliste: Von geteilt zu getrennt
Die Verlagerung von Analytics aus der Produktionsdatenbank ist weniger ein Big-Bang-Refactor als ein sichtbarer, zielorientierter und schrittweiser Prozess.
1) Inventarisieren Sie, was heute wirklich passiert
Starten Sie mit Evidenz, nicht Annahmen. Erstellen Sie Listen von:
- Top-OLTP-Endpunkten/Queries nach Häufigkeit und p95/p99-Latenz (Checkout, Login, Order-Anlage etc.)
- Top-OLAP-Reports/Dashboards nach Laufzeit, Scan-Volumen und Geschäftsbedeutung
Beziehen Sie "versteckte" Analytics mit ein: Ad-hoc-SQL aus BI-Tools, geplante Exporte und CSV-Downloads.
2) Definieren Sie Ziele: OLTP-SLOs und Analytics-Freshness
Schreiben Sie Ziele auf:
- OLTP-SLOs: p95/p99-Latenz, Fehlerquote und Spitzen-Durchsatz, die Sie halten müssen
- Analytics-Freshness: wie veraltet dürfen Daten sein (5 Minuten, 1 Stunde, nächster Tag) plus Time-to-Rebuild bei Pipeline-Fehlern
Das verhindert Debatten wie "es ist langsam" vs. "es ist okay" und hilft bei der Architekturwahl.
3) Wählen Sie einen Trennungsweg
Wählen Sie die einfachste Option, die die Ziele erfüllt:
- Read-Replica: schnell für leseintensives Reporting, aber anfällig für schwere Queries und Replikationslag
- Warehouse: richtig für große Scans, viele Joins und lange Historie; meist das Ziel für BI
- CDC-Pipeline (ETL/ELT): am besten für Near-Real-Time ohne Produktionslast
4) Rollout sicher (zuerst parallel)
- Validieren Sie Definitions-Übereinstimmung (Zeitzonen, Returns, "aktive Nutzer" etc.), damit Zahlen matchen.
- Lassen Sie alte und neue Dashboards einen vollständigen Geschäftszyklus parallel laufen.
- Cutover Report für Report, beginnend mit den schmerzhaftesten Queries.
- Sperren Sie direkten "Reporting on production" Zugriff, sobald Stakeholder der neuen Quelle vertrauen.
5) Guardrails, damit Sie nicht rückfällig werden
Überwachen Sie Replica-Lag/Pipeline-Delays, Dashboard-Laufzeiten und Warehouse-Kosten. Setzen Sie Query-Budgets (Timeouts, Concurrency-Limits) und behalten Sie ein Incident-Playbook: Was tun, wenn Freshness fällt, Lastspitzen auftreten oder Kennzahlen sich unterscheiden?
Praktische Anmerkung, wenn Sie die App bauen
Wenn Sie noch früh im Produkt sind, ist das größte Risiko, Analytics unbewusst in denselben Pfad wie Kerntransaktionen einzubauen (z. B. Dashboard-Queries, die stillschweigend "produktionskritisch" werden). Eine Möglichkeit das zu vermeiden: planen Sie die Trennung von Anfang an — selbst mit einer einfachen Read-Replica — und nehmen Sie sie in Ihre Architektur-Checkliste auf.
Plattformen wie Koder.ai können hier helfen, weil Sie die OLTP-Seite (React-App + Go-Services + PostgreSQL) prototypisch bauen und die Reporting-/Warehouse-Grenze im Planungsschritt skizzieren können, bevor Sie live gehen. Mit wachsendem Produkt können Sie Quellcode exportieren, das Schema weiterentwickeln und CDC/ELT-Komponenten hinzufügen, ohne "Reporting on production" zur Dauerlösung zu machen.