Was ein Read-Replica ist (und was nicht)
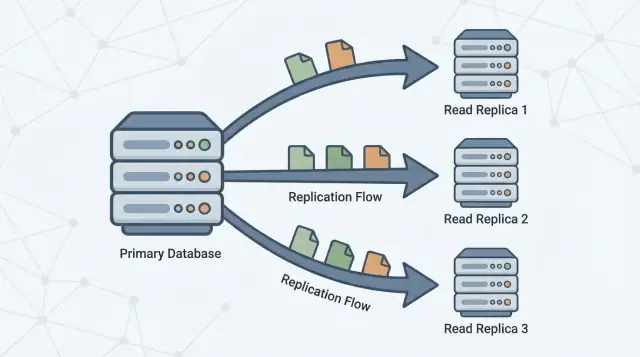
Ein Read-Replica ist eine Kopie deiner Hauptdatenbank (oft primary genannt), die durch kontinuierliches Übernehmen von Änderungen aktuell gehalten wird. Deine Anwendung kann nur Leseabfragen (wie SELECT) an das Replikat senden, während die Primärinstanz weiterhin alle Schreibvorgänge (wie INSERT, UPDATE und DELETE) übernimmt.
Das grundlegende Versprechen
Das Versprechen ist einfach: mehr Lese-Kapazität, ohne die Primärinstanz stärker zu belasten.
Wenn deine App viel „Fetch“-Traffic hat — Startseiten, Produktseiten, Nutzerprofile, Dashboards — kann das Verlegen einiger Leseabfragen auf ein oder mehrere Replikate die Primärinstanz entlasten, sodass sie sich auf Schreibarbeiten und kritische Lesevorgänge konzentrieren kann. In vielen Architekturen lässt sich das mit minimalen Änderungen an der Anwendung erreichen: eine Datenquelle bleibt die Quelle der Wahrheit, und Replikate werden als zusätzliche Abfrageziele hinzugefügt.
Was ein Read-Replica nicht ist
Read-Replikate sind nützlich, aber kein magischer Performance-Knopf. Sie tun nicht:
- Die Schreibleistung erhöhen. Alle Schreibvorgänge landen weiterhin auf der Primärinstanz.
- Langsame Abfragen reparieren. Ist eine Abfrage ineffizient (fehlende Indizes, große Scans, ungünstige Joins), wird sie wahrscheinlich auch auf Replikaten langsam sein — nur an einer anderen Stelle.
- Gutes Schema- und Datenmodell ersetzen. Replikate lösen keine Hot-Spots, übergroße Zeilen oder eine „alles in einer Tabelle“-Anti-Pattern.
- Die Notwendigkeit für Monitoring eliminieren. Replikate fügen weitere bewegliche Teile hinzu: Verzögerung, Verbindungsgrenzen und Failover-Verhalten.
Erwartungen für den Rest dieses Leitfadens
Betrachte Replikate als ein Werkzeug zur Lese-Skalierung mit Kompromissen. Der Rest dieses Artikels erklärt, wann sie wirklich helfen, wie sie oft schiefgehen und wie Konzepte wie Replikationsverzögerung und eventuelle Konsistenz beeinflussen, was Nutzer sehen, wenn Abfragen von einer Kopie statt von der Primärinstanz beantwortet werden.
Warum Read-Replikate existieren
Eine einzelne Primärdatenbank fühlt sich oft anfangs „groß genug“. Sie verarbeitet Schreibvorgänge (Inserts, Updates, Deletes) und beantwortet gleichzeitig jede Leseanfrage (SELECT) von deiner App, Dashboards und internen Tools.
Mit wachsender Nutzung vervielfachen sich Lesezugriffe meist schneller als Schreibvorgänge: jede Seitenansicht kann mehrere Abfragen auslösen, Suchseiten können viele Lookups verursachen und analytische Abfragen scannen viele Zeilen. Selbst bei moderater Schreibleistung kann die Primärinstanz zum Flaschenhals werden, weil sie zwei Aufgaben gleichzeitig erfüllen muss: Änderungen sicher und schnell annehmen und ein wachsendes Leseaufkommen mit niedriger Latenz bedienen.
Lesen und Schreiben trennen
Read-Replikate existieren, um diese Last zu teilen. Die Primärinstanz bleibt auf das Verarbeiten von Schreibvorgängen und das Pflegen der „Quelle der Wahrheit“ fokussiert, während ein oder mehrere Replikate Leseabfragen beantworten. Wenn deine Anwendung ausgewählte Abfragen an Replikate weiterleiten kann, reduzierst du CPU-, Speicher- und I/O-Druck auf der Primärinstanz. Das verbessert typischerweise die Gesamtreaktionszeit und schafft mehr Spielraum für Schreibspitzen.
Replikation in einem Satz
Replikation ist der Mechanismus, der Replikate aktuell hält, indem Änderungen von der Primärinstanz auf andere Server kopiert werden. Die Primärinstanz protokolliert Änderungen, und Replikate wenden diese Änderungen an, sodass sie Abfragen mit nahezu den gleichen Daten beantworten können.
Dieses Muster findet sich in vielen Datenbanksystemen und Managed-Services (z. B. PostgreSQL, MySQL und Cloud-Varianten). Die genaue Implementierung variiert, aber das Ziel ist gleich: Lese-Kapazität erhöhen, ohne die Primärinstanz unendlich vertikal skalieren zu müssen.
Wie Replikation funktioniert (ein einfaches Mentalmodell)
Stell dir die Primärdatenbank als „Quelle der Wahrheit“ vor. Sie akzeptiert jeden Schreibvorgang — Bestellungen anlegen, Profile aktualisieren, Zahlungen erfassen — und ordnet diesen Änderungen eine feste Reihenfolge zu.
Ein oder mehrere Read-Replikate folgen der Primärinstanz und kopieren diese Änderungen, damit sie Leseabfragen beantworten können (zum Beispiel „zeige meine Bestellhistorie“), ohne die Primärinstanz zusätzlich zu belasten.
Der Grundablauf
- Primärinstanz akzeptiert Schreibvorgänge und protokolliert sie in einem dauerhaften Log (der Name variiert je nach Datenbank).
- Replikate streamen oder holen diese Log-Einträge von der Primärinstanz.
- Replikate spielen die Änderungen in derselben Reihenfolge ab und holen so allmählich auf.
Lesen kann von Replikaten beantwortet werden, aber Schreiben geht weiterhin an die Primärinstanz.
Synchron vs. asynchron (grober Überblick)
Replikation kann in zwei Modi passieren:
- Synchron: Die Primärinstanz wartet, bis ein Replikat (oder ein Quorum) den Empfang bestätigt, bevor der Write als „committed“ gilt. Das reduziert veraltete Reads, kann aber die Schreiblatenz erhöhen und macht Writes sensibler gegenüber Replikat-/Netzwerkproblemen.
- Asynchron: Die Primärinstanz commitet den Write sofort, Replikate holen später auf. Das hält Writes schnell und robust, aber Replikate können vorübergehend zurückliegen.
Replikationsverzögerung und „eventuelle Konsistenz"
Die Verzögerung — Replikate, die hinter der Primärinstanz liegen — heißt Replikationsverzögerung. Das ist kein automatischer Fehler; es ist oft der normale Kompromiss, den man zur Skalierung von Lesezugriffen akzeptiert.
Für Endnutzer äußert sich Verzögerung als eventuelle Konsistenz: nachdem du etwas geändert hast, wird das System überall konsistent sein, aber nicht unbedingt sofort.
Beispiel: Du aktualisierst deine E-Mail-Adresse und lädst dein Profil neu. Wenn die Seite von einem Replikat bedient wird, das ein paar Sekunden zurückliegt, siehst du kurzzeitig die alte E-Mail — bis das Replikat die Änderung angewendet hat und aufgeholt hat.
Wann Read-Replikate tatsächlich helfen
Read-Replikate helfen, wenn deine Primärdatenbank für Writes gesund ist, aber unter der Leseauslastung leidet. Sie sind am effektivsten, wenn du einen nennenswerten Anteil der SELECT-Last auslagern kannst, ohne das Schreibverhalten zu verändern.
Hinweise, dass du lesegebunden bist (nicht schreibgebunden)
Achte auf Muster wie:
- Hohe CPU auf der Primärinstanz während Traffic-Spitzen, während die Schreibdurchsatzrate nicht ungewöhnlich hoch ist
- Sehr hohes Verhältnis von
SELECT-Abfragen zu INSERT/UPDATE/DELETE
- Leseabfragen werden während Spitzen langsamer, obwohl Writes stabil bleiben
- Verbindungspool-Sättigung durch leseintensive Endpunkte (Produktseiten, Feeds, Suchergebnisse)
Wie du bestätigst, dass Lesen das Problem ist (Metriken)
Bevor du Replikate hinzufügst, validiere mit konkreten Signalen:
- CPU vs I/O: Ist die Primär-CPU ausgelastet, wenn die Lese-Latenz zunimmt? Oder ist die Disk-Lese-I/O der Engpass?
- Abfragen-Mix: Prozentsatz der Zeit, die in
SELECT-Statements verbracht wird (Slow-Query-Log/APM).
- p95/p99 Lese-Latenz: Verfolge Leseendpunkte und DB-Abfrage-Latenz getrennt.
- Buffer-/Cache-Hitrate: Eine niedrige Hitrate kann bedeuten, dass Lesezugriffe Platte erzwingen.
- Top-Abfragen nach Gesamtzeit: Eine teure Abfrage kann die gesamte Lese-Last dominieren.
Überspringe nicht die günstigeren Fixes
Oft ist der beste erste Schritt Tuning: den richtigen Index setzen, eine Abfrage umschreiben, N+1-Aufrufe reduzieren oder heiße Reads cachen. Diese Änderungen sind meist schneller und günstiger als den Betrieb von Replikaten.
Kurze Checkliste: Replikate vs. Tuning
Wähle Replikate, wenn:
- Die meiste Last Lese-Traffic ist und die Leseabfragen bereits einigermaßen optimiert sind
- Du gelegentlich veraltete Reads für die ausgelagerten Abfragen tolerieren kannst
- Du schnell zusätzliche Kapazität brauchst, ohne riskante Schema-/Query-Änderungen
Wähle erst Tuning, wenn:
- Wenige Abfragen den Großteil der Lesezeit dominieren
- Offensichtliche fehlende Indizes oder ineffiziente Joins bestehen
- Reads schon bei geringem Traffic langsam sind (Hinweis auf Abfrage-Design-Probleme)
Best-Fit-Anwendungsfälle
Read-Replikate sind besonders wertvoll, wenn die Primärdatenbank Schreibarbeiten (Checkout, Registrierungen, Updates) bearbeitet, aber ein großer Anteil des Traffics leseintensiv ist. In einer Primary–Replica-Architektur verbessert das Verschieben der richtigen Abfragen auf Replikate die Datenbankperformance, ohne die Anwendung zu verändern.
1) Dashboards und Analytics, die Transaktionen nicht verlangsamen sollen
Dashboards führen oft lange Abfragen aus: Gruppierungen, Filter über große Zeiträume oder Joins mehrerer Tabellen. Diese Abfragen konkurrieren mit transaktionaler Arbeit um CPU, Speicher und Cache.
Ein Read-Replica ist ein guter Ort für:
- Interne Reporting-Workloads
- Admin-Dashboards
- „Tägliche/wöchentliche Metriken“
Du hältst die Primärinstanz für schnelle, vorhersehbare Transaktionen frei, während Analytics-Reads unabhängig skaliert werden.
2) Suche und Browse-Seiten mit hohem Lesevolumen
Katalog-Browsing, Nutzerprofile und Content-Feeds können ein hohes Volumen ähnlicher Leseabfragen erzeugen. Wenn dieser Lese-Druck der Engpass ist, können Replikate Traffic absorbieren und Latenzspitzen reduzieren.
Das ist besonders effektiv, wenn viele Abfragen Cache-Misses erzeugen (viele unterschiedliche Abfragen) oder wenn du nicht ausschließlich auf einen Anwendungscache vertrauen kannst.
3) Hintergrundjobs, die große Datenmengen scannen
Exporte, Backfills, Neuberechnungen von Zusammenfassungen und „Finde alle Datensätze, die X entsprechen“-Jobs können die Primärinstanz stark belasten. Diese Scans gegen ein Replikat laufen zu lassen ist oft sicherer.
Stelle nur sicher, dass der Job eventual consistency toleriert: wegen Replikationsverzögerung sieht er möglicherweise nicht die neuesten Updates.
4) Multi-Region-Lesen für geringere Latenz (mit Staleness-Vorbehalten)
Wenn du Nutzer global bedienst, kann es helfen, Read-Replikate näher an den Nutzern zu platzieren, um RTT zu reduzieren. Der Kompromiss ist eine stärkere Anfälligkeit für veraltete Reads bei Verzögerungen oder Netzwerkproblemen — also eignet sich das am besten für Seiten, bei denen „nahezu aktuell“ akzeptabel ist (Browse, Empfehlungen, öffentliche Inhalte).
Wo Replikate nach hinten losgehen können
Reporting von Transaktionen trennen
Erzeuge interne Reporting‑Ansichten, ohne schwere Lesevorgänge in kritische Schreibpfade zu mischen.
Read-Replikate sind klasse, wenn „nah genug“ ausreicht. Sie schlagen fehl, wenn dein Produkt stillschweigend davon ausgeht, dass jeder Lesezugriff den aktuellsten Stand zeigt.
Klassisches Symptom: „Ich habe es gerade aktualisiert, warum hat sich nichts geändert?“
Ein Nutzer bearbeitet sein Profil, sendet ein Formular oder ändert Einstellungen — und der nächste Seitenaufruf wird von einem Replikat bedient, das ein paar Sekunden zurückliegt. Die Änderung ist erfolgreich, aber der Nutzer sieht alte Daten, wiederholt Aktionen, sendet doppelt oder verliert Vertrauen.
Das ist besonders ärgerlich in Flows, in denen der Nutzer sofortige Bestätigung erwartet: E-Mail-Änderungen, Präferenzumschaltungen, Dateiuploads oder das Posten eines Kommentars und anschließendes Redirect.
Bildschirme, die aktuell sein müssen (hier kein Glücksspiel)
Einige Reads können keine Verzögerung tolerieren, auch nicht kurz:
- Warenkörbe und Checkout-Summen
- Wallet-Balances, Treuepunkte, Lagerbestände
- „Ist meine Zahlung durch?“-Statusseiten
Wenn ein Replikat zurückliegt, kannst du den falschen Warenkorbwert anzeigen, Überverkäufe riskieren oder ein veraltetes Guthaben zeigen. Selbst wenn das System später korrigiert, leidet die User Experience und das Support-Aufkommen steigt.
Interne Dashboards steuern oft echte Entscheidungen: Betrugsprüfung, Kundensupport, Auftragsabwicklung, Moderation und Incident Response. Liest ein Admin-Tool von Replikaten, riskierst du, auf unvollständigen Daten zu handeln — etwa eine Rückerstattung für eine Bestellung zu veranlassen, die bereits rückerstattet wurde, oder den neuesten Statuswechsel zu übersehen.
Praktischer Fix: „Read-your-writes“ an die Primärinstanz routen
Ein übliches Muster ist bedingtes Routing:
- Nach einem Nutzer-Write werden dessen anschließende Bestätigungs-Reads für ein kurzes Fenster (Sekunden bis Minuten) an die Primärinstanz geschickt.
- Hintergrund-, anonyme oder nicht-kritische Reads bleiben auf Replikaten.
So bewahrst du die Vorteile von Replikaten, ohne Konsistenz zu raten.
Verständnis von Replikationsverzögerung und veralteten Reads
Replikationsverzögerung ist die Verzögerung zwischen dem Commit eines Writes auf der Primärinstanz und dem Moment, in dem dieselbe Änderung auf einem Replikat sichtbar wird. Liest deine App von einem Replikat während dieser Verzögerung, können „stale“ Ergebnisse zurückgegeben werden — Daten, die vor kurzem gültig waren, aber nicht mehr.
Warum Verzögerung entsteht
Verzögerung ist normal und wächst meist unter Last. Häufige Ursachen:
- Load-Spitzen auf der Primärinstanz: viele Writes bedeuten mehr Änderungen zum Verschicken und Anwenden.
- Unterdimensioniertes oder ausgelastetes Replikat: das Replikat kann Änderungen nicht so schnell anwenden wie sie ankommen (CPU, Disk I/O).
- Netzwerk-Latenz oder Jitter: Verzögerungen beim Übertragen des Replikationsstreams.
- Große Transaktionen / Bulk-Updates: eine einzelne Änderung kann Zeit zum Serialisieren, Übertragen und Wiedergeben benötigen.
Wie sich veraltete Reads im Produktverhalten zeigen
Verzögerung beeinflusst nicht nur Frische — sie beeinflusst aus Nutzersicht die Korrektheit:
- Ein Nutzer aktualisiert sein Profil und sieht beim Neuladen den alten Wert.
- „Ungelesene Nachrichten“-Zähler oder Badge-Counts driften, weil Zählungen auf leicht veralteten Zeilen basieren.
- Admin-/Reporting-Screens verpassen die neuesten Bestellungen, Rückerstattungen oder Statusänderungen.
Praktische Handhabung
Lege zuerst fest, was dein Feature tolerieren kann:
- Toleranzfenster hinzufügen: „Daten können bis zu 30 Sekunden alt sein“ ist für viele Dashboards akzeptabel.
- Read-after-write an Primärinstanz routen: nach einer Nutzeränderung lese dieses Objekt für ein kurzes Intervall von der Primärinstanz.
- UI-Nachrichten: Erwartungen setzen („Wird aktualisiert…“, „Kann ein paar Sekunden dauern").
- Retry-Logik: Wenn ein kritischer Read einen gerade geschriebenen Datensatz vermisst, wiederhole gegen die Primärinstanz oder nach kurzer Verzögerung.
Was zu überwachen und zu alarmieren ist
Verfolge Replikationsverzögerung (Zeit/Bytes hinterher), Apply-Rate, Replikationsfehler sowie CPU/Disk-I/O der Replikate. Alarmiere, wenn Verzögerung deine Toleranz überschreitet (z. B. 5s, 30s, 2m) und wenn Verzögerung kontinuierlich steigt (Hinweis, dass das Replikat ohne Eingriff nie aufholt).
Lese-Skalierung vs. Schreib-Skalierung (wichtige Trade-Offs)
Entscheiden, was aktuell sein muss
Kartiere „muss aktuell sein“-Bildschirme vs. sichere Replica‑Lesungen mit dem Planning Mode von Koder.ai.
Read-Replikate sind ein Werkzeug zur Lese-Skalierung: mehr Orte, um SELECT-Abfragen zu bedienen. Sie sind kein Werkzeug zur Schreib-Skalierung: die Erhöhung der Anzahl von INSERT/UPDATE/DELETE-Operationen, die dein System akzeptieren kann.
Lesen skalieren: wofür Replikate gut sind
Mit mehr Replikaten erhöhst du die Lese-Kapazität. Wenn deine Anwendung bei leseintensiven Endpunkten (Produktseiten, Feeds, Lookups) limitiert ist, kannst du diese Abfragen auf mehrere Maschinen verteilen.
Das verbessert oft:
- Abfrage-Latenz unter Last (weniger Contention auf der Primärinstanz)
- Durchsatz für Reads (mehr CPU/Speicher/I/O für
SELECT-Anfragen)
- Isolation für schwere Reads, sodass Reporting-Workloads transaktionalen Traffic nicht stören
Schreiben skalieren: was Replikate nicht tun
Ein verbreitetes Missverständnis ist, dass „mehr Replikate = mehr Schreibdurchsatz“ bedeutet. In einem typischen Primary-Replikat-Setup gehen alle Writes weiterhin an die Primärinstanz. Tatsächlich können mehr Replikate die Primärinstanz leicht mehr belasten, weil sie Replikationsdaten an jedes Replikat erzeugen und verschicken muss.
Wenn dein Problem Schreibdurchsatz ist, helfen Replikate nicht weiter. Du brauchst andere Ansätze (Query-/Index-Tuning, Batching, Partitioning/Sharding oder Änderungen am Datenmodell).
Verbindungsgrenzen und Pooling: der versteckte Engpass
Selbst wenn Replikate mehr Lese-CPU bieten, kannst du zuerst auf Verbindungsgrenzen stoßen. Jeder DB-Knoten hat eine maximale Anzahl gleichzeitiger Verbindungen, und Replikate erhöhen die Anzahl der möglichen Verbindungsziele — ohne die Gesamtnachfrage zu reduzieren.
Praktische Regel: nutze Connection Pooling (oder einen Pooler) und halte die Verbindungsanzahl pro Service bewusst. Sonst werden Replikate einfach zu „mehr Datenbanken, die man überlasten kann“.
Kosten: Kapazität kostet
Replikate verursachen echte Kosten:
- Mehr Knoten (Compute-Kosten)
- Mehr Speicher (jedes Replikat speichert in der Regel eine vollständige Kopie)
- Mehr Betriebsaufwand (Monitoring von Verzögerung, Backup-/Restore-Strategie, Schemaänderungen, Incident-Response)
Der Tausch ist einfach: Replikate kaufen dir Lese-Kapazität und Isolation, aber sie erhöhen Komplexität und heben die Schreib-Obergrenze nicht an.
Hochverfügbarkeit und Failover: Was Replikate leisten können
Read-Replikate können die Leseverfügbarkeit verbessern: ist deine Primärinstanz überlastet oder kurz nicht erreichbar, kannst du weiterhin einigen Lese-Traffic aus Replikaten bedienen. Das hält kundennahe Seiten reaktionsfähig (für Inhalte, die leicht veraltet sein dürfen) und reduziert die Auswirkung eines Primärvorfalls.
Was Replikate nicht alleine liefern, ist ein vollständiger Hochverfügbarkeitsplan. Ein Replikat ist normalerweise nicht automatisch bereit, Writes zu akzeptieren, und eine „lesbare Kopie existiert“ unterscheidet sich von „das System kann sicher und schnell wieder Writes annehmen".
Failover bedeutet typischerweise: Primärausfall erkennen → ein Replikat auswählen → dieses zum neuen Primär promoten → Writes (und normalerweise Reads) auf den promoteten Knoten umleiten.
Manche Managed-Datenbanken automatisieren vieles davon, aber die Kerngedanken bleiben: du änderst, wer Writes akzeptiert.
Wichtige Risiken, die du planen musst
- Veraltete Replikatdaten: Das Replikat kann zurückliegen. Wenn du es promotest, könntest du die neuesten Writes verlieren, die nie repliziert wurden.
- Split-Brain vermeiden: Du musst verhindern, dass zwei Knoten gleichzeitig Writes akzeptieren. Deshalb sind Promotionen üblicherweise durch eine zentrale Autorität (Managed Control Plane, Quorum-System oder strikte Betriebsverfahren) abgesichert.
- Routing und Caches: Deine Anwendung braucht einen verlässlichen Weg zum Umschalten — Connection Strings, DNS, Proxies oder ein DB-Router. Stelle sicher, dass Write-Traffic nicht versehentlich an die alte Primärinstanz weiterläuft.
Teste es wie ein Feature
Behandle Failover als etwas, das du übst. Führe Game-Day-Tests in Staging durch (und vorsichtig in Produktion in wartungsarmen Fenstern): simuliere Primärausfall, messe Time-to-Recover, überprüfe Routing und vergewissere dich, dass deine App Read-Only-Phasen und Reconnects sauber handhabt.
Praktische Routing-Pattern (Read/Write Splitting)
Read-Replikate helfen nur, wenn dein Traffic sie auch erreicht. „Read/Write-Splitting" sind Regeln, die Writes an die Primärinstanz und geeignete Reads an Replikate senden — ohne die Korrektheit zu brechen.
Pattern 1: Split in der Anwendung
Der einfachste Ansatz ist explizites Routing in deiner Data-Access-Schicht:
- Alle Writes (
INSERT/UPDATE/DELETE, Schema-Änderungen) gehen an die Primärinstanz.
- Nur ausgewählte Reads dürfen ein Replikat nutzen.
Das ist einfach nachvollziehbar und leicht rückgängig zu machen. Hier lassen sich auch Geschäftsregeln kodieren wie „nach Checkout lese den Bestellstatus für eine Weile vom Primärsystem".
Pattern 2: Split über Proxy oder Treiber
Einige Teams nutzen einen Datenbank-Proxy oder einen smarten Treiber, der Primär- vs. Replikat-Endpunkte kennt und basierend auf Abfragetyp oder Connection-Settings routet. Das reduziert Änderungen im Anwendungscode, aber Vorsicht: Proxies können nicht zuverlässig wissen, welche Reads aus Produktsicht „sicher“ sind.
Welche Abfragen können sicher zu Replikaten gehen
Gute Kandidaten:
- Analytics-, Reporting-Workloads, Dashboards
- Such-/Browse-Seiten, bei denen leicht veraltete Daten akzeptabel sind
- Hintergrundjobs, die retryen und nicht den neuesten Wert benötigen
Vermeide das Routing von Reads, die unmittelbar auf einen Nutzer-Write folgen (z. B. „Profil aktualisieren → Profil neu laden"), sofern du keine Konsistenzstrategie hast.
Transaktionen und Session-Konsistenz
Innerhalb einer Transaktion sollten alle Reads auf der Primärinstanz bleiben.
Außerhalb von Transaktionen solltest du „read-your-writes“-Sessions in Erwägung ziehen: Nach einem Write pinne Nutzer/Session kurzzeitig an die Primärinstanz (TTL) oder leite spezifische Folgeabfragen an die Primärinstanz.
Klein anfangen und messen
Füge ein Replikat hinzu, route eine begrenzte Menge von Endpunkten/Abfragen und vergleiche vorher/nachher:
- Primär-CPU und Lese-IOPS
- Auslastung des Replikats
- Fehlerquote und Latenzpercentiles
- Vorfälle im Zusammenhang mit veralteten Reads
Erweitere das Routing nur, wenn der Effekt klar und sicher ist.
Monitoring und Betrieb: die Grundlagen
Schnell deployen und iterieren
Stelle deine App mit Hosting und Deployment bereit und iteriere, wenn der Traffic wächst.
Read-Replikate sind nicht „einmal einrichten und vergessen“. Sie sind zusätzliche DB-Server mit eigenen Leistungsgrenzen, Fehler-Modi und Betriebsaufgaben. Ein wenig Monitoring-Disziplin ist oft der Unterschied zwischen „Replikate haben geholfen“ und „Replikate haben Verwirrung gestiftet".
Was zu beobachten ist (die wenigen wichtigen Metriken)
Fokussiere dich auf Indikatoren, die nutzerseitige Symptome erklären:
- Replikationsverzögerung: wie weit ein Replikat hinter der Primärinstanz liegt (Sekunden, Bytes oder WAL/LSN-Position, je nach DB). Das ist die Frühwarnung für veraltete Reads.
- Replikationsfehler: kaputte Verbindungen, Auth-Fehler, volles Laufwerk, Slot-Probleme. Behandle diese als Incidents, nicht als Rauschen.
- Abfrage-Latenz (p50/p95) auf Replikat vs Primär: Replikate können langsam sein, auch wenn die Primärinstanz in Ordnung ist (unterschiedlicher Cache-Zustand, andere Hardware, lange Reports).
- Cache-Hitrate: ein Replikat, das ständig Cache-Misses hat, zeigt nach Neustarts oder Traffic-Verschiebungen höhere Latenzen.
Kapazitätsplanung: wie viele Replikate brauchst du?
Starte mit einem Replikat, wenn dein Ziel das Auslagern von Reads ist. Füge mehr hinzu, wenn du eine klare Grenze erreichst:
- Lese-Durchsatz: ein Replikat reicht nicht für Spitzen-QPS oder schwere analytische Queries.
- Isolation: weise ein Replikat dem Reporting zu, damit Dashboards die Nutzer-Traffic-Ressourcen nicht stehlen.
- Geographie: ein Replikat pro Region kann Lese-Latenz senken, erhöht aber den Betriebsaufwand.
Praktische Regel: skaliere Replikate erst, nachdem du bestätigt hast, dass Lesen der Engpass ist (nicht Indizes, langsame Abfragen oder App-Caching).
Übliche Betriebsaufgaben
- Backups: Entscheide, wo Backups laufen. Backups von einem Replikat zu nehmen kann die Primärinstanz entlasten, aber prüfe Konsistenzanforderungen und ob das Replikat gesund ist.
- Schema-Änderungen: teste Migrationen mit Replikation im Blick (lang laufende DDL kann Verzögerung erhöhen). Koordiniere Rollouts, damit App- und Schema-Änderungen während der Propagation kompatibel bleiben.
- Wartungsfenster: Patchen oder Neustarten von Replikaten reduziert vorübergehend die Lese-Kapazität. Plane Rotation, damit du nicht unter deine benötigte Lese-Kapazität fällst.
Troubleshooting-Checkliste: „Replikate sind langsam"
- Prüfe Replikationsverzögerung: ist sie hoch? Dann retryen Nutzer vielleicht oder sehen stale Daten.
- Vergleiche Slow-Query-Logs auf Replikat vs Primär: Reporting-Queries tauchen hier oft auf.
- Überprüfe CPU, Speicher, Disk I/O und Netzwerk auf dem Replikat-Host.
- Suche nach Lock-Contention oder lang laufenden Transaktionen auf der Primärinstanz, die Replikation verzögern.
- Bestätige, dass dein Read-Routing nicht ein einzelnes Replikat überlädt (ungleiche Lastverteilung).
- Validiere, dass Indizes auf Replikaten vorhanden sind (sie sollten die Primärstruktur spiegeln) und Statistiken aktuell sind.
Alternativen und ein einfaches Entscheidungs-Framework
Read-Replikate sind ein Werkzeug zur Lese-Skalierung, aber selten der erste Hebel. Bevor du operative Komplexität hinzufügst, prüfe, ob ein einfacherer Fix dasselbe Ergebnis liefert.
Alternativen, die du zuerst versuchen solltest
Caching kann ganze Klassen von Lesezugriffen aus der Datenbank entfernen. Für „read-mostly“-Seiten (Produktdetails, öffentliche Profile, Konfiguration) kann ein App-Cache oder CDN den Load dramatisch reduzieren — ohne Replikationsverzögerung einzuführen.
Indizes und Query-Optimierung übertreffen Replikate oft für den Normalfall: ein paar teure Abfragen, die CPU verbrauchen. Der richtige Index, weniger Spalten im SELECT, Vermeidung von N+1 und bessere Joins können aus „wir brauchen Replikate“ ein „wir brauchten nur besseren Plan“ machen.
Materialized Views / Voraggregation helfen, wenn die Last inhärent schwer ist (Analytics, Dashboards). Statt komplexe Abfragen immer wieder auszuführen, speicherst du berechnete Ergebnisse und aktualisierst sie zeitgesteuert.
Wann Sharding/Partitionierung in Betracht ziehen
Wenn deine Writes der Engpass sind (Hot Rows, Lock-Contention, Write-I/O-Limits), hilft ein Replikat nicht viel. Dann sind Partitionierung der Tabellen nach Zeit/Tenant oder Sharding nach Kunden-ID der richtige Schritt. Das ist ein größerer Architekturwechsel, aber er adressiert das wirkliche Problem.
Ein einfaches Entscheidungs-Framework
Stelle vier Fragen:
- Was ist das Ziel? Lese-Latenz reduzieren, Reporting-Workloads auslagern oder Verfügbarkeit verbessern?
- Wie frisch müssen Reads sein? Wenn du keine stale Reads tolerierst, können Replikate Nutzer-visible Probleme schaffen.
- Wie hoch ist dein Budget? Replikate erhöhen Infrastruktur- und Betriebs-Kosten.
- Wie viel Komplexität kannst du tragen? Read/Write-Splitting, Umgang mit eventueller Konsistenz und Failover-Tests sind nicht trivial.
Wenn du ein neues Produkt prototypst oder einen Service schnell hochziehst, hilft es, diese Einschränkungen früh in die Architektur einzubauen. Teams, die auf Koder.ai bauen (eine Plattform, die React-Apps mit Go + PostgreSQL Backends aus einer Chat-Oberfläche generiert), starten oft mit einer einzigen Primärinstanz zur Vereinfachung und führen Replikate ein, sobald Dashboards, Feeds oder internes Reporting mit transaktionalem Traffic in Konflikt geraten. Ein planungsorientierter Workflow macht es leichter, im Vorhinein zu entscheiden, welche Endpunkte eventual consistency tolerieren und welche unmittelbar „read-your-writes" von der Primärinstanz benötigen.
Wenn du Hilfe bei der Entscheidung möchtest, siehe /pricing für Optionen, oder durchstöbere verwandte Guides unter /blog.