14. Okt. 2025·7 Min
Was ist GraphQL? Eine verständliche Anleitung für APIs und Datenabfragen
Erfahre, was GraphQL ist, wie Abfragen, Mutations und Schemata funktionieren und wann man es statt REST einsetzen sollte — plus praktische Vor‑ und Nachteile und Beispiele.
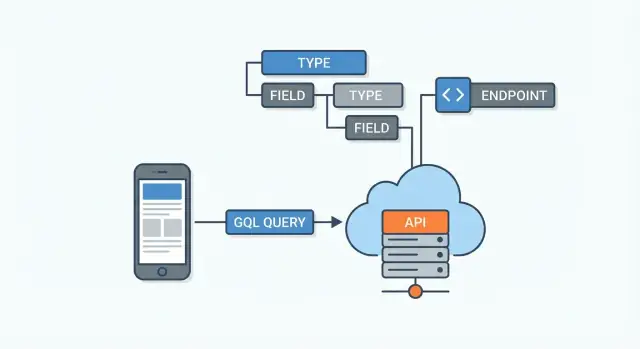
Was GraphQL ist (und was nicht)
GraphQL ist eine Abfragesprache und Laufzeitumgebung für APIs. Einfach gesagt: Es ist eine Möglichkeit für eine App (Web, Mobile oder ein anderer Service), eine API mit einer klaren, strukturierten Anfrage um Daten zu bitten — und der Server liefert eine Antwort, die dieser Anfrage entspricht.
Das Problem, das es löst
Viele APIs zwingen Clients dazu, das zu akzeptieren, was ein fester Endpoint zurückgibt. Das führt oft zu zwei Problemen:
- Over‑fetching: du lädst Felder herunter, die du nicht brauchst.
- Under‑fetching: du musst mehrere Anfragen stellen, um eine einzige Ansicht zusammenzustellen.
Mit GraphQL kann der Client genau die Felder anfordern, die er benötigt, nicht mehr und nicht weniger. Das ist besonders hilfreich, wenn verschiedene Bildschirme (oder verschiedene Apps) unterschiedliche „Ausschnitte“ derselben zugrundeliegenden Daten brauchen.
Wo GraphQL „sitzt"
GraphQL sitzt typischerweise zwischen Client‑Apps und deinen Datenquellen. Diese Datenquellen können sein:
- Datenbanken
- vorhandene REST‑Services
- Drittanbieter‑APIs
- Microservices
Der GraphQL‑Server empfängt eine Abfrage, entscheidet, wie jedes angeforderte Feld aus der richtigen Quelle geholt wird, und stellt dann die finale JSON‑Antwort zusammen.
Ein einfaches Denkmodell
Stell dir GraphQL vor wie das Bestellen einer maßgeschneiderten Antwort:
- Der Client beschreibt die Form der Daten, die er will.
- Der Server liefert die Daten genau in dieser Form (soweit möglich).
Was GraphQL nicht ist
GraphQL wird oft missverstanden, daher ein paar Klarstellungen:
- Es ist keine Datenbank (es speichert deine Daten nicht).
- Es ist nicht automatisch schneller (es kann unnötige Datenübertragung reduzieren, aber Serverarbeit bleibt wichtig).
- Es ist kein „REST 2.0“ (es ist ein alternativer API‑Ansatz mit eigenen Stärken und Kompromissen).
Wenn du die Kerndefinition – Abfragesprache + Laufzeitumgebung für APIs – im Kopf behältst, hast du das richtige Fundament für alles Weitere.
Warum GraphQL geschaffen wurde
GraphQL wurde entwickelt, um ein praktisches Produktproblem zu lösen: Teams verbrannten zu viel Zeit damit, APIs an reale UI‑Bildschirme anzupassen.
Traditionelle endpoint‑basierte APIs zwingen oft die Wahl zwischen dem Ausliefern unnötiger Daten oder zusätzlichen Aufrufen, um die benötigten Daten zu bekommen. Mit wachsendem Produkt zeigt sich diese Reibung als langsamere Seiten, komplizierterer Client‑Code und schmerzhafte Abstimmung zwischen Frontend‑ und Backend‑Teams.
Die Schmerzpunkte, auf die GraphQL abzielt
Over‑fetching tritt auf, wenn ein Endpoint ein „vollständiges“ Objekt zurückgibt, obwohl eine Ansicht nur wenige Felder braucht. Eine mobile Profilansicht braucht vielleicht nur Name und Avatar, aber die API liefert Adressen, Einstellungen, Audit‑Felder und mehr. Das verschwendet Bandbreite und kann die User‑Experience verschlechtern.
Under‑fetching ist das Gegenteil: Kein einzelner Endpoint hat alles, was eine Ansicht braucht, also muss der Client mehrere Anfragen stellen und Ergebnisse zusammensetzen. Das erhöht Latenz und die Wahrscheinlichkeit teilweiser Fehler.
APIs weiterentwickeln ohne ständige Versionssprünge
Viele REST‑APIs reagieren auf Änderungen, indem sie neue Endpoints hinzufügen oder versionieren (v1, v2, v3). Versionierung kann nötig sein, erzeugt aber langfristigen Wartungsaufwand: Alte Clients nutzen weiterhin alte Versionen, während neue Features woanders entstehen.
GraphQLs Ansatz ist, das Schema durch Hinzufügen von Feldern und Typen zu erweitern, während bestehende Felder stabil bleiben. Das verringert oft den Druck, neue „Versionen“ nur zur Unterstützung neuer UI‑Bedürfnisse zu erstellen.
Eine API, viele Clients
Moderne Produkte haben selten nur einen Konsumenten. Web, iOS, Android und Partnerintegrationen brauchen alle unterschiedliche Datenformen.
GraphQL wurde so entworfen, dass jeder Client genau die Felder anfordern kann, die er braucht — ohne dass das Backend für jeden Bildschirm oder jedes Gerät einen separaten Endpoint anlegt.
Das GraphQL‑Schema: Der API‑Vertrag
Eine GraphQL‑API wird durch ihr Schema definiert. Denk daran als die Vereinbarung zwischen Server und allen Clients: Es listet, welche Daten existieren, wie sie verbunden sind und was angefragt oder geändert werden kann. Clients raten nicht nach Endpoints — sie lesen das Schema und fragen spezifische Felder an.
Schema‑Grundlagen: Typen, Felder, Beziehungen
Das Schema besteht aus Typen (wie User oder Post) und Feldern (wie name oder title). Felder können auf andere Typen verweisen; so modelliert GraphQL Beziehungen.
Hier ein einfaches Beispiel in Schema Definition Language (SDL):
type User {
id: ID!
name: String!
posts: [Post!]!
}
type Post {
id: ID!
title: String!
body: String
author: User!
comments: [Comment!]!
}
type Comment {
id: ID!
text: String!
author: User!
post: Post!
}
Starke Typisierung = Validierung vor der Ausführung
Weil das Schema stark typisiert ist, kann GraphQL eine Anfrage vor ihrer Ausführung validieren. Wenn ein Client ein Feld anfragt, das nicht existiert (z. B. Post.publishDate, wenn das Schema ein solches Feld nicht hat), kann der Server die Anfrage ablehnen oder teil‑erfüllen und klare Fehler zurückgeben — ohne mehrdeutiges „vielleicht funktioniert es“ Verhalten.
Sicheres Weiterentwickeln über die Zeit
Schemata sind so gestaltet, dass sie wachsen können. Du kannst in der Regel neue Felder hinzufügen (z. B. User.bio), ohne bestehende Clients zu brechen, weil Clients nur das bekommen, was sie anfordern. Das Entfernen oder Ändern von Feldern ist sensibler; Teams markieren Felder daher oft zuerst als veraltet (deprecate) und migrieren Clients schrittweise.
Queries: Genau das anfragen, was du brauchst
Eine GraphQL‑API wird typischerweise über einen einzigen Endpunkt (z. B. /graphql) exponiert. Statt vieler URLs für unterschiedliche Ressourcen (wie /users, /users/123, /users/123/posts) sendest du eine Query an einen Ort und beschreibst genau die Daten, die du zurückhaben willst.
Felder auswählen (inkl. verschachtelter Daten)
Eine Query ist im Grunde eine „Einkaufsliste“ von Feldern. Du kannst einfache Felder anfragen (z. B. id und name) und gleichzeitig verschachtelte Daten (z. B. die letzten Posts eines Users) in derselben Anfrage — ohne unnötige Felder herunterzuladen.
Hier ein kleines Beispiel:
query GetUserWithPosts {
user(id: "123") {
id
name
posts(limit: 2) {
id
title
}
}
}
Eine vorhersehbare Antwortstruktur
GraphQL‑Antworten sind vorhersehbar: das JSON, das du zurückbekommst, spiegelt die Struktur deiner Query wider. Das macht die Frontend‑Arbeit einfacher, weil du nicht raten musst, wo Daten erscheinen oder verschiedene Antwortformate parsen musst.
Eine vereinfachte Antwort könnte so aussehen:
{
"data": {
"user": {
"id": "123",
"name": "Sam",
"posts": [
{ "id": "p1", "title": "Hello GraphQL" },
{ "id": "p2", "title": "Queries in Practice" }
]
}
}
}
Wenn du ein Feld nicht abfragst, ist es nicht enthalten. Fragst du es an, kannst du es an der entsprechenden Stelle erwarten — das macht GraphQL‑Queries zu einem sauberen Weg, genau das zu holen, was jeder Bildschirm oder jede Funktion braucht.
Mutations: Daten sicher schreiben
Queries dienen dem Lesen; Mutations sind der Weg, wie du in einer GraphQL‑API Daten änderst — also erstellst, aktualisierst oder löschst.
Typischer Ablauf einer Mutation
Die meisten Mutations folgen demselben Muster:
- Inputs: Der Client sendet ein strukturiertes Input (oft ein
input‑Objekt), z. B. die zu ändernden Felder. - Validierung & Autorisierung: Der Server prüft Pflichtfelder, Formate, Einzigartigkeit und ob der Nutzer die Aktion ausführen darf.
- Schreiben: Der Server führt die Datenbankänderung durch (oder ruft einen anderen Service auf).
- Payload/Rückgabetyp: Der Server gibt eine vorhersehbare Ergebnisstruktur zurück, damit die UI aktualisiert werden kann.
Warum Mutations Daten zurückgeben
GraphQL‑Mutations geben in der Regel absichtlich Daten zurück, statt nur „success: true“. Das Zurückgeben des aktualisierten Objekts (oder mindestens seiner id und wichtiger Felder) hilft der UI:
- den Bildschirm sofort zu aktualisieren, ohne einen zusätzlichen Round‑Trip
- zwischengespeicherte Daten sicher zu aktualisieren (z. B. mit Apollo Client)
- feldspezifische Fehler im Kontext anzuzeigen
Ein gängiges Design ist ein „Payload“‑Typ, der sowohl das aktualisierte Entity als auch mögliche Fehler enthält.
Ein einfaches Mutation‑Beispiel
mutation UpdateEmail($input: UpdateUserEmailInput!) {
updateUserEmail(input: $input) {
user {
id
email
}
errors {
field
message
}
}
}
Für UI‑getriebene APIs gilt eine gute Regel: Gib zurück, was du brauchst, um den nächsten Zustand zu rendern (z. B. den aktualisierten user plus eventuelle errors). Das hält den Client einfach, vermeidet Rätselraten über Änderungen und macht Fehlerbehandlung benutzerfreundlicher.
Resolver: Wie GraphQL das Ergebnis erzeugt
Stelle noch heute die erste Query bereit
Verwandle die Datenanforderungen eines Bildschirms in wenigen Minuten in eine funktionierende GraphQL-Operation.
Ein GraphQL‑Schema beschreibt, was angefragt werden kann. Resolver beschreiben, wie es tatsächlich geholt wird. Ein Resolver ist eine Funktion, die an ein bestimmtes Feld im Schema gebunden ist. Wenn ein Client dieses Feld anfragt, ruft GraphQL den Resolver auf, um den Wert zu liefern oder zu berechnen.
Resolver sind feld‑level Funktionen
GraphQL führt eine Abfrage aus, indem es die angeforderte Struktur durchläuft. Für jedes Feld findet es den passenden Resolver und führt ihn aus. Manche Resolver geben einfach eine Eigenschaft eines bereits im Speicher vorhandenen Objekts zurück; andere rufen eine Datenbank, einen anderen Service auf oder kombinieren mehrere Quellen.
Beispiel: Hat dein Schema User.posts, könnte der posts‑Resolver die posts‑Tabelle nach userId abfragen oder einen separaten Posts‑Service kontaktieren.
Schema‑Felder mit Datenquellen verbinden
Resolver sind die Verbindung zwischen Schema und echten Systemen:
- Datenbanken: SQL/NoSQL‑Abfragen, Stored Procedures, ORM‑Aufrufe
- Services: REST/gRPC‑Aufrufe, interne Microservices, Drittanbieter‑APIs
- Berechnete Felder: Summen, Formatierungen, abgeleitete Werte
Diese Abbildung ist flexibel: Du kannst deine Backend‑Implementierung ändern, ohne die Client‑Query‑Form zu verändern — solange das Schema konsistent bleibt.
Performance: langsame Resolver‑Ketten (N+1) vermeiden
Da Resolver pro Feld und pro Listeneintrag ausgeführt werden können, ist es leicht, viele kleine Aufrufe auszulösen (z. B. Posts für 100 Nutzer mit 100 separaten Datenbankabfragen). Das N+1‑Muster kann Antworten verlangsamen.
Gängige Lösungen sind Batching und Caching (z. B. IDs sammeln und in einer Abfrage holen) und bewusstes Fördern bzw. Beschränken verschachtelter Felder, die Clients anfragen dürfen.
Wo Autorisierung und Validierung stattfinden
Autorisierung wird oft in Resolvern (oder gemeinsamer Middleware) durchgesetzt, weil Resolver wissen, wer anfragt (über den Kontext) und auf welche Daten zugegriffen werden soll. Validierung passiert typischerweise auf zwei Ebenen: GraphQL übernimmt Typ‑/Form‑Validierung automatisch, während Resolver Geschäftsregeln (z. B. „nur Admins dürfen dieses Feld setzen“) durchsetzen.
Fehler und partielle Ergebnisse
Eine Überraschung für viele GraphQL‑Neulinge ist, dass eine Anfrage „erfolgreich“ sein kann und trotzdem Fehler enthält. Das liegt daran, dass GraphQL feldorientiert ist: Wenn einige Felder aufgelöst werden können und andere nicht, kannst du partielle Daten erhalten.
Wie Fehler aussehen
Eine typische GraphQL‑Antwort kann sowohl data als auch ein errors‑Array enthalten:
{
"data": {
"user": {
"id": "123",
"email": null
}
},
"errors": [
{
"message": "Not authorized to read email",
"path": ["user", "email"],
"extensions": { "code": "FORBIDDEN" }
}
]
}
Das ist nützlich: Der Client kann weiterhin rendern, was vorhanden ist (z. B. das Benutzerprofil), während er mit dem fehlenden Feld umgeht.
Feld‑level Fehler vs. Anfrage‑level Fehler
- Feld‑level Fehler treten während der Ausführung auf (ein Resolver wirft, Berechtigungscheck schlägt fehl, ein downstream Service time‑out). Andere Felder können trotzdem aufgelöst werden.
- Anfrage‑level Fehler verhindern die Ausführung (ungültiges JSON, fehlerhafte Query, Validierungsfehler gegen das Schema). In diesen Fällen ist
datahäufignull.
Benutzerfreundliche Meldungen ohne Details zu leaken
Formuliere Fehlermeldungen für Endnutzer, nicht fürs Debugging. Vermeide das Offenlegen von Stacktraces, Datenbanknamen oder internen IDs. Ein gutes Muster ist:
- Eine kurze, sichere
message - Ein stabiler, machine‑readable
extensions.code - Optionale, sichere Metadaten (z. B.
retryable: true)
Logge detaillierte Fehler serverseitig mit einer Request‑ID, damit du untersuchen kannst, ohne Interna offenzulegen.
Tipps für konsistente Behandlung in allen Clients
Definiere einen kleinen Fehler‑„Vertrag“, den Web‑ und Mobile‑Apps teilen: gemeinsame extensions.code‑Werte (z. B. UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), Regeln, wann ein Toast gezeigt wird vs. inline Feldfehler, und wie mit partiellen Daten umgegangen wird. Konsistenz verhindert, dass jeder Client eigene Fehlerkonventionen erfindet.
Subscriptions für Echtzeit‑Updates
GraphQL an einer Funktion testen
Vergleiche GraphQL und REST für ein Feature, indem du ein kleines MVP End-to-End baust.
Subscriptions sind GraphQLs Möglichkeit, Clients Daten zu pushen, sobald sie sich ändern, anstatt dass der Client wiederholt nachfragt. Sie werden typischerweise über eine persistente Verbindung geliefert (meist WebSockets), sodass der Server Ereignisse sofort an verbundene Clients senden kann.
Was Subscriptions sind (und wie sie funktionieren)
Eine Subscription sieht einer Query ähnlich, aber das Ergebnis ist kein einmaliges Response. Es ist ein Strom von Ergebnissen — jedes repräsentiert ein Ereignis.
Unter der Haube „abonniert“ ein Client ein Thema (z. B. messageAdded in einem Chat). Wenn der Server ein Ereignis veröffentlicht, erhalten alle verbundenen Abonnenten eine Nutzlast, die zur Selection Set der Subscription passt.
Gängige Anwendungsfälle
Subscriptions eignen sich, wenn Änderungen sofort erwartet werden:
- Chat‑Nachrichten, die in einem Raum ohne Refresh erscheinen
- Benachrichtigungen (Mentions, Bestellstatus‑Änderungen, Alerts)
- Live‑Dashboards (Systemzustand, Logistik, Trading, Sportstände)
Subscriptions vs. Polling
Beim Polling fragt der Client alle N Sekunden „Gibt es Neues?“. Das ist einfach, kann aber viele Anfragen verschwenden (vor allem wenn sich nichts ändert) und wirkt verzögert.
Bei Subscriptions sagt der Server „Hier ist das Update“ sofort. Das reduziert unnötigen Traffic und verbessert die gefühlte Geschwindigkeit — auf Kosten offener Verbindungen und real‑time Infrastrukturmanagement.
Wann Subscriptions unnötige Komplexität sind
Subscriptions sind nicht immer die richtige Wahl. Wenn Updates selten, nicht zeitkritisch oder leicht zu bündeln sind, reicht Polling oder ein nach Benutzeraktion ausgelöster Refetch oft aus.
Sie erhöhen auch den operativen Aufwand: Skalierung der Verbindungen, Auth für lang laufende Sessions, Retries und Monitoring. Gute Regel: Nutze Subscriptions nur, wenn Echtzeit ein Produkt‑Requirement ist, nicht nur ein Nice‑to‑Have.
Vor‑ und Nachteile sowie praktische Abwägungen
GraphQL wird oft als „Power für den Client“ beschrieben, aber diese Macht hat Kosten. Die Kenntnis der Tradeoffs hilft zu entscheiden, wann GraphQL passt — und wann es Overhead bringt.
Wo GraphQL glänzt
Der größte Gewinn ist flexibles Daten‑Fetching: Clients können genau die Felder anfordern, die sie brauchen, was Over‑fetching reduzieren und UI‑Änderungen beschleunigen kann.
Ein weiterer Vorteil ist der starke Vertrag durch ein GraphQL‑Schema. Das Schema wird zur Single Source of Truth für Typen und verfügbare Operationen, was Zusammenarbeit und Tooling verbessert.
Teams sehen oft bessere Produktivität auf Client‑Seite, weil Frontend‑Entwickler iterieren können, ohne auf neue Endpoint‑Varianten warten zu müssen; Tools wie Apollo Client können Typen generieren und das Daten‑Fetching vereinfachen.
Häufige Nachteile, auf die man sich einstellen sollte
GraphQL kann Caching komplizierter machen. Bei REST ist Caching oft „pro URL“. Bei GraphQL teilen viele Queries denselben Endpoint, daher basieren Caching‑Strategien auf Query‑Shapes, normalisierten Caches und sorgfältiger Server/Client‑Konfiguration.
Serverseitig gibt es Performance‑Fallstricke. Eine scheinbar kleine Query kann viele Backend‑Aufrufe auslösen, wenn Resolver nicht bedacht implementiert sind (Batching, N+1 vermeiden, teure Felder kontrollieren).
Es gibt außerdem eine Lernkurve: Schemata, Resolver und Client‑Pattern sind für Teams, die an endpointbasierte APIs gewöhnt sind, neu.
Sicherheit und Betrieb
Weil Clients viel anfragen können, sollten GraphQL‑APIs Tiefe‑ und Komplexitätslimits durchsetzen, um missbräuchliche oder versehentlich „zu große“ Anfragen zu verhindern.
Authentifizierung und Autorisierung sollten pro Feld durchgesetzt werden, nicht nur auf Routen‑Level, da unterschiedliche Felder unterschiedliche Zugriffsregeln haben können.
Operativ solltest du in Logging, Tracing und Monitoring investieren, das GraphQL versteht: Operation‑Namen, Variablen (vorsichtig), Resolver‑Laufzeiten und Fehlerquoten tracken, damit du langsame Queries und Regressionen früh erkennst.
GraphQL vs REST: Worin sie sich unterscheiden
GraphQL und REST helfen beide Apps bei der Kommunikation mit Servern, aber sie strukturieren dieses Gespräch unterschiedlich.
Wie REST typischerweise funktioniert
REST ist ressourcenbasiert. Daten holst du über mehrere Endpoints (URLs), die „Dinge“ repräsentieren wie /users/123 oder /orders?userId=123. Jeder Endpoint liefert eine vom Server festgelegte Struktur.
REST nutzt außerdem HTTP‑Semantik: Methoden wie GET/POST/PUT/DELETE, Statuscodes und Caching‑Regeln. Das macht REST natürlich, wenn du einfache CRUD‑Operationen machst oder stark auf Browser/Proxy‑Caches angewiesen bist.
Wie GraphQL funktioniert
GraphQL ist schema‑basiert. Anstelle vieler Endpoints hast du meist einen Endpunkt, und der Client sendet eine Query, die die gewünschten Felder beschreibt. Der Server validiert gegen das GraphQL‑Schema und liefert eine Antwort, die zur Abfrage passt.
Diese „client‑gesteuerte Auswahl“ ist der Grund, warum GraphQL Over‑ und Under‑fetching reduzieren kann — besonders für UI‑Bildschirme, die Daten aus mehreren miteinander verbundenen Modellen benötigen.
Wann REST einfacher ist
REST passt häufig besser, wenn:
- Du Datei‑Downloads/-Uploads machst (Streaming, Content‑Types, Range‑Requests).
- Deine API hauptsächlich einfaches CRUD mit vorhersehbaren Payloads ist.
- Du stark auf HTTP‑Caching am Edge setzt und maximale Kompatibilität mit vorhandenen Tools brauchst.
Hybride Ansätze sind üblich
Viele Teams mischen beides:
- Nutze GraphQL für UI‑fokussiertes Daten‑Fetching (Web/Mobile Screens).
- Behalte REST für spezielle Dienste wie Auth‑Callbacks, Webhooks, Datei‑Handling oder interne Microservice‑Endpoints.
Die praktische Frage ist nicht „Was ist besser?“, sondern „Was passt für diesen Anwendungsfall mit dem geringsten Aufwand?".
Wie man eine GraphQL‑API entwirft (Einsteiger‑Checkliste)
Entwirf zuerst dein Schema
Nutze den Planungsmodus, um Typen, Abfragen und Mutationen zu skizzieren, bevor du Code schreibst.
Eine GraphQL‑API zu entwerfen ist am einfachsten, wenn du sie als Produkt für die Bildschirmbauer behandelst, nicht als Abbild deiner Datenbank. Fang klein an, validiere mit echten Use Cases und erweitere bei Bedarf.
1) Von UI‑Screens ausgehen (nicht von Tabellen)
Liste deine wichtigen Screens (z. B. „Produktliste“, „Produktdetails“, „Checkout“). Schreib für jeden Screen die exakten Felder auf, die er braucht, und welche Interaktionen unterstützt werden.
Das hilft, „God‑Queries“ zu vermeiden, Over‑fetching zu reduzieren und klarzustellen, wo Filter, Sortierung und Pagination nötig sind.
2) Domain‑Typen modellieren, dann Operationen schrittweise hinzufügen
Definiere zuerst deine Kerntypen (z. B. User, Product, Order) und deren Beziehungen. Dann füge hinzu:
- eine kleine Auswahl an Queries, die reale Screens abbilden
- eine kleine Auswahl an Mutations, die reale Nutzeraktionen abbilden (z. B.
addToCart,placeOrder)
Bevorzuge sprechende, business‑nahe Namen statt datenbanknaher Namen. „placeOrder“ kommuniziert die Absicht besser als „createOrderRecord".
3) Namensgebung und Pagination‑Basics
Halte die Namensgebung konsistent: Singular für Einzelobjekte (product), Plural für Collections (products). Bei Pagination wählst du meist eine der beiden Varianten:
- Cursor‑basiert: besser für sich verändernde Listen und „infinite scroll“ (stabiler)
- Offset‑basiert: einfacher, kann aber bei Datenänderungen überspringen/duplizieren
Entscheide dich früh, weil das die Struktur deiner API‑Responses prägt.
4) Dokumentiere beim Bauen
GraphQL unterstützt Beschreibungen direkt im Schema — nutze sie für Felder, Argumente und Randfälle. Ergänze ein paar Copy‑Paste‑Beispiele in deinen Docs (inkl. Pagination und häufigen Fehlerfällen). Ein gut beschriebenes Schema macht Introspection und API‑Explorer deutlich nützlicher.
Erste Schritte: Tools, Tests und nächste Schritte
Mit GraphQL anzufangen heißt meist, ein paar gut unterstützte Tools auszuwählen und einen verlässlichen Workflow einzurichten. Du musst nicht alles auf einmal übernehmen — bring eine Query end‑to‑end zum Laufen und baue darauf auf.
Wähle ein Server‑Framework
Wähle einen Server basierend auf deinem Stack und wie viel „Batterien inklusive“ du willst:
- Apollo Server: beliebte Wahl mit großem Ökosystem und guter Dokumentation.
- GraphQL Yoga: leichtgewichtig, moderne Defaults, angenehme Developer‑Experience.
- NestJS: ideal, wenn du bereits Nest nutzt und GraphQL in Module, DI und Patterns integrieren willst.
Ein praktischer erster Schritt: Definiere ein kleines Schema (ein paar Typen + eine Query), implementiere Resolver und verbinde eine echte Datenquelle (auch wenn es zunächst eine stub‑in‑memory Liste ist).
Wenn du schneller von Idee zu funktionsfähiger API kommen willst, können Plattformen zum Vibe‑Coding wie Koder.ai helfen, ein kleines Full‑Stack‑App‑Gerüst zu erzeugen (React Frontend, Go + PostgreSQL Backend) und GraphQL Schema/Resolver interaktiv zu iterieren — danach kannst du den Quellcode exportieren und selbst weiter pflegen.
Wähle einen Client‑Ansatz
Auf dem Frontend hängt die Wahl oft davon ab, ob du stark strukturierte Konventionen oder Flexibilität willst:
- Apollo Client: weit verbreitet, starkes Caching und Devtools.
- Relay: strengere Patterns, oft in großen Apps für Konsistenz genutzt.
- urql: kleiner, komponierbar, gut für Teams, die Kontrolle wollen.
Wenn du von REST migrierst, starte damit, GraphQL für einen Bildschirm oder ein Feature zu nutzen und lass REST für den Rest, bis sich der Ansatz bewährt hat.
Tests: Schema + Resolver + Integration
Behandle dein Schema wie einen API‑Vertrag. Nützliche Testschichten sind:
- Schema‑Validierung (Schema in CI bauen; bei ungültigen Typen fehlschlagen)
- Resolver‑Unit‑Tests (Datenquellen mocken und Randfälle + Auth prüfen)
- Integrationstests (echte GraphQL‑Operationen gegen Testserver und DB laufen lassen)
Nächste Schritte
Zur Vertiefung fahre mit folgendem Artikel fort:
- /blog/graphql-vs-rest
FAQ
Was ist GraphQL in einfachen Worten?
GraphQL ist eine Abfragesprache und Laufzeitumgebung für APIs. Clients senden eine Abfrage, die genau die Felder beschreibt, die sie benötigen, und der Server liefert eine JSON-Antwort, die dieser Struktur entspricht.
Man kann es am besten als Schicht zwischen Clients und einer oder mehreren Datenquellen begreifen (Datenbanken, REST-Services, Drittanbieter‑APIs, Microservices).
Welches Problem löst GraphQL im Vergleich zu festen REST‑Endpoints?
GraphQL hilft vor allem bei:
- Over‑fetching: wenn zu viele Felder geliefert werden, die eine Ansicht nicht braucht.
- Under‑fetching: wenn mehrere Anfragen nötig sind, um eine Ansicht zusammenzustellen.
Indem der Client nur bestimmte Felder (auch verschachtelte) anfordert, kann GraphQL überflüssige Datenübertragung reduzieren und den Client-Code vereinfachen.
Was ist GraphQL nicht?
GraphQL ist kein:
- Datenbanksystem (es speichert deine Daten nicht).
- Automatisch schnelleres System (es kann übertragenen Overhead reduzieren, aber Serverarbeit bleibt relevant).
- „REST 2.0“ (es ist ein anderer API‑Stil mit eigenen Vor‑ und Nachteilen).
Behandle es als API‑Vertrag + Ausführungsengine, nicht als Speicher- oder Performance‑Wunder.
Warum verwenden GraphQL‑APIs oft nur einen Endpunkt?
Die meisten GraphQL‑APIs bieten einen einzigen Endpunkt (häufig /graphql). Statt vieler URLs sendest du unterschiedliche Operationen (Queries/Mutations) an diesen einen Endpunkt.
Praktische Konsequenz: Caching und Observability orientieren sich oft an Operationsname + Variablen, nicht an der URL.
Was ist ein GraphQL‑Schema und warum ist es wichtig?
Das Schema ist der API‑Vertrag. Es definiert:
- Typen (z. B.
User,Post) - Felder auf diesen Typen (z. B.
User.name) - Beziehungen (z. B.
User.posts)
Da es ist, kann der Server Abfragen vor der Ausführung validieren und klare Fehler zurückgeben, wenn Felder fehlen oder falsch sind.
Wie funktionieren GraphQL‑Queries?
Queries sind Leseoperationen. Du gibst an, welche Felder du brauchst, und die Antwort‑JSON spiegelt die Struktur der Abfrage wider.
Tipps:
- Vergib Operationsnamen (z. B.
query GetUserWithPosts) für Debugging und Monitoring. - Nutze Argumente, um Ergebnisse zu formen (z. B.
posts(limit: 2)).
Wie funktionieren GraphQL‑Mutations und warum geben sie Daten zurück?
Mutations sind Schreiboperationen (create/update/delete). Üblicher Ablauf:
- Ein
input‑Objekt wird gesendet - Server validiert und authorisiert
- Die Änderung wird durchgeführt
- Ein Payload mit aktualisierten Daten und möglichen Fehlern wird zurückgegeben
Daten zurückzugeben (nicht nur success: true) hilft der UI, sofort zu aktualisieren und Caches konsistent zu halten.
Was sind Resolver und wo liegen Auth‑ und Geschäftsregeln?
Resolver sind feld‑spezifische Funktionen, die bestimmen, wie GraphQL ein Feld tatsächlich erhält oder berechnet.
In der Praxis können Resolver:
- Eine Datenbank abfragen
- Einen internen Service aufrufen
- Eine Drittanbieter‑API nutzen
- Einen abgeleiteten Wert berechnen
Autorisierung wird oft in Resolvern (oder gemeinsamem Middleware) durchgesetzt, weil sie wissen, wer was anfragt.
Wie vermeidet man häufige Performance‑Probleme wie N+1‑Abfragen?
Leicht entsteht ein N+1‑Problem (z. B. Posts für 100 Nutzer jeweils separat laden).
Gängige Gegenmaßnahmen:
- Batching (IDs sammeln und in einer Abfrage holen)
- Caching (pro Request oder geteilter Cache)
- Bewusster Umgang mit teuren verschachtelten Feldern
Miss die Resolver‑Dauer und achte auf wiederholte Downstream‑Aufrufe innerhalb einer Anfrage.
Warum kann eine GraphQL‑Antwort sowohl Daten als auch Fehler enthalten?
GraphQL kann teilweise Daten zusammen mit einem errors‑Array zurückgeben. Das passiert, wenn einige Felder erfolgreich aufgelöst werden und andere fehlschlagen (z. B. fehlende Berechtigung oder Timeout).
Gute Praxis: