Kafka in einfachen Worten
Apache Kafka ist eine verteilte Event-Streaming-Plattform. Kurz gesagt: Es ist eine geteilte, dauerhafte „Leitung“, die vielen Systemen erlaubt, Fakten darüber zu veröffentlichen, was passiert ist, und anderen Systemen erlaubt, diese Fakten zu lesen — schnell, in großem Maßstab und in Reihenfolge.
Teams nutzen Kafka, wenn Daten zuverlässig zwischen Systemen fließen müssen, ohne enge Kopplung. Statt einer Anwendung, die direkt eine andere aufruft (und scheitert, wenn sie down oder langsam ist), schreiben Producer Ereignisse in Kafka. Consumer lesen sie, wenn sie bereit sind. Kafka speichert Ereignisse für einen konfigurierbaren Zeitraum, sodass Systeme von Ausfällen wiederherstellen und sogar die Historie erneut verarbeiten können.
Einige Begriffe, die du sehen wirst
- Event / Nachricht: Ein Datensatz über etwas, das passiert ist (zum Beispiel „OrderPlaced“ oder „PaymentFailed“). Nutzer sagen oft „Nachricht“, aber „Event“ betont, dass es eine reale Zustandsänderung darstellt.
- Stream: Ein kontinuierlicher Fluss von Ereignissen über die Zeit.
- Log: Kafka organisiert Ereignisse als append-only Log — neue Ereignisse werden ans Ende angehängt, und Leser bewegen sich in ihrem eigenen Tempo vorwärts.
Für wen dieser Leitfaden ist (und was du lernst)
Dieser Leitfaden richtet sich an produktorientierte Entwickler, Data-Teams und technische Führungskräfte, die ein praktisches mentales Modell von Kafka möchten.
Du lernst die Kernbausteine (Producer, Consumer, Topics, Broker), wie Kafka mit Partitionen skaliert, wie es Ereignisse speichert und erneut abspielt und wo es in einer ereignisgesteuerten Architektur passt. Wir behandeln außerdem gängige Anwendungsfälle, Liefergarantien, Sicherheitsgrundlagen, Betriebsplanung und wann Kafka (nicht) das richtige Werkzeug ist.
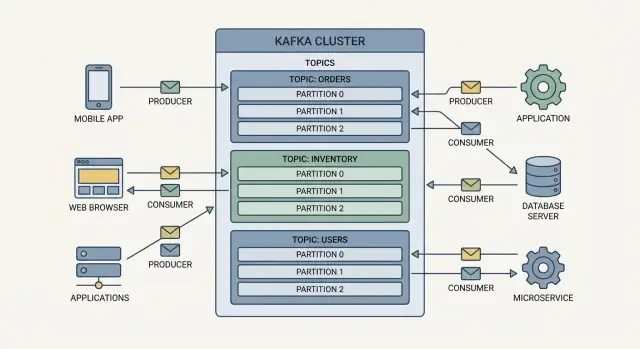
Kernkonzepte: Producer, Consumer, Topics, Broker
Kafka ist am leichtesten als ein geteiltes Ereignislog zu verstehen: Anwendungen schreiben Ereignisse hinein, und andere Anwendungen lesen diese Ereignisse später — oft in Echtzeit, manchmal Stunden oder Tage danach.
Producer und Consumer
Producer sind die Schreiber. Ein Producer könnte ein Ereignis wie „order placed“, „payment confirmed“ oder „temperature reading“ veröffentlichen. Producer schicken Ereignisse nicht direkt an bestimmte Apps — sie schicken sie an Kafka.
Consumer sind die Leser. Ein Consumer könnte ein Dashboard treiben, einen Versandworkflow auslösen oder Daten in Analysesysteme laden. Consumer entscheiden, was sie mit Ereignissen tun, und sie können in ihrem eigenen Tempo lesen.
Topics: Ereignisse organisieren
Ereignisse in Kafka werden in Topics gruppiert, das sind im Grunde benannte Kategorien. Zum Beispiel:
orders für bestellbezogene Ereignissepayments für Zahlungsereignisseinventory für Lagerbestandsänderungen
Ein Topic wird zur „Quelle der Wahrheit“ für diese Art von Ereignis, was es mehreren Teams erleichtert, dieselben Daten wiederzuverwenden, ohne Einzellösungen zu bauen.
Broker und Cluster
Ein Broker ist ein Kafka-Server, der Ereignisse speichert und sie Consumer bereitstellt. In der Praxis läuft Kafka als Cluster (mehrere Broker zusammen), damit es mehr Traffic verarbeiten kann und weiterläuft, selbst wenn eine Maschine ausfällt.
Consumer-Gruppen: Leser skalieren, ohne Arbeit zu duplizieren
Consumer laufen oft in einer Consumer-Gruppe. Kafka verteilt die Lesearbeit über die Gruppe, sodass du mehr Consumer-Instanzen hinzufügen kannst, um die Verarbeitung horizontal zu skalieren — ohne dass jede Instanz dieselbe Arbeit macht.
Wie Topics und Partitionen Kafka skalieren lassen
Kafka skaliert, indem es Arbeit in Topics (zusammengehörige Ereignisströme) und dann in Partitionen (kleinere, unabhängige Scheiben dieses Stroms) aufteilt.
Partitionen = Parallelität und Durchsatz
Ein Topic mit einer Partition kann innerhalb einer Consumer-Gruppe nur von einem Consumer gleichzeitig gelesen werden. Füge mehr Partitionen hinzu, und du kannst mehr Consumer hinzufügen, um Ereignisse parallel zu verarbeiten. So unterstützt Kafka hohe Event-Streaming- und Echtzeit-Datenpipelines, ohne jedes System zum Engpass zu machen.
Partitionen helfen auch, die Last auf mehrere Broker zu verteilen. Statt einer Maschine, die alle Schreib- und Lesezugriffe für ein Topic abwickelt, können mehrere Broker verschiedene Partitionen hosten und den Traffic teilen.
Reihenfolge: was Kafka garantiert (und was nicht)
Kafka garantiert Reihenfolge innerhalb einer einzelnen Partition. Wenn Ereignisse A, B und C in dieser Reihenfolge in dieselbe Partition geschrieben werden, lesen Consumer sie A → B → C.
Die Reihenfolge über Partitionen hinweg ist nicht garantiert. Wenn du strikte Reihenfolge für eine bestimmte Entität (z. B. Kunde oder Bestellung) benötigst, sorgst du typischerweise dafür, dass alle Ereignisse für diese Entität in dieselbe Partition gehen.
Keys entscheiden, wohin Ereignisse gehen
Producer können beim Senden eines Ereignisses einen Key (z. B. order_id) mitsenden. Kafka nutzt den Key, um zusammenhängende Ereignisse konsistent in dieselbe Partition zu routen. Das gibt vorhersehbare Reihenfolgen für diesen Key, während das Topic insgesamt über viele Partitionen skaliert.
Replikate halten Daten verfügbar
Jede Partition kann auf andere Broker repliziert werden. Fällt ein Broker aus, kann ein anderer Broker mit einer Replik die Führung übernehmen. Replikation ist ein Hauptgrund, warum Kafka für geschäftskritische Pub-Sub-Nachrichten und ereignisgesteuerte Systeme vertraut wird: Sie erhöht die Verfügbarkeit und ermöglicht Fehlertoleranz, ohne dass jede Anwendung eigene Failover-Logik bauen muss.
Speicherung, Retention und erneutes Abspielen von Ereignissen
Eine zentrale Idee in Apache Kafka ist, dass Ereignisse nicht nur weitergereicht werden und dann vergessen sind. Sie werden geordnet auf die Festplatte geschrieben, sodass Consumer sie jetzt oder später lesen können. Das macht Kafka nicht nur für die Datenübertragung nützlich, sondern auch als dauerhafte Historie dessen, was passiert ist.
Ereignisse werden persistiert, nicht nur "unterwegs"
Wenn ein Producer ein Ereignis an ein Topic sendet, hängt Kafka es an den Speicher des Brokers an. Consumer lesen dann aus diesem gespeicherten Log in ihrem eigenen Tempo. Wenn ein Consumer eine Stunde lang ausgefallen ist, existieren die Ereignisse weiterhin und können beim Wiederanlaufen nachgeholt werden.
Retention: wie lange Kafka Daten aufbewahrt
Kafka behält Ereignisse gemäß Retention-Policies:
- Zeitbasierte Retention: Ereignisse für einen festgelegten Zeitraum aufbewahren (z. B. 7 Tage).
- Größenbasierte Retention: Ereignisse behalten, bis das Log eine konfigurierte Größe erreicht, dann die ältesten Daten löschen.
Retention wird pro Topic konfiguriert, sodass du "Audit-Trail"-Topics anders behandeln kannst als stark frequentierte Telemetrie-Topics.
Kompaktion: den neuesten Wert pro Key behalten
Manche Topics sind eher ein Changelog als ein historisches Archiv — beispielsweise „aktuelle Kundeneinstellungen“. Log-Compaction behält mindestens den aktuellsten Eintrag pro Key, während ältere, überschriebenen Datensätze entfernt werden können. So erhältst du eine dauerhafte Quelle der Wahrheit für den neuesten Zustand, ohne unendliches Wachstum.
Ereignisse erneut abspielen: Zustand wiederaufbauen und von Bugs erholen
Da Ereignisse gespeichert bleiben, kannst du sie erneut abspielen, um Zustand wiederherzustellen:
- Eine Suchindextabelle oder materialisierte Sicht von Grund auf neu aufbauen
- Einen Service nach einem fehlerhaften Deployment durch Reprocessing wiederherstellen
- Einen neuen Consumer onboarden und historische Daten lesen lassen
In der Praxis wird das Replay durch den Punkt gesteuert, an dem ein Consumer „zu lesen beginnt“ (sein Offset), was Teams ein mächtiges Sicherheitsnetz beim Weiterentwickeln der Systeme gibt.
Zuverlässigkeit und Fehlertoleranz – Grundlagen
Kafka ist darauf gebaut, Datenfluss aufrechtzuerhalten, selbst wenn Teile des Systems ausfallen. Es erreicht das durch Replikation, klare Regeln darüber, wer für eine Partition „zuständig“ ist, und konfigurierbare Write-Acknowledgments.
Replikation: Leader und Follower (high level)
Jede Topic-Partition hat einen Leader-Broker und einen oder mehrere Follower-Replicas auf anderen Brokern. Producer und Consumer sprechen mit dem Leader für diese Partition.
Follower kopieren kontinuierlich die Daten des Leaders. Fällt der Leader aus, kann Kafka einen aktuellen Follower zum neuen Leader wählen, sodass die Partition verfügbar bleibt.
Was bei einem Broker-Ausfall passiert (kurz)
Wenn ein Broker ausfällt, werden die Partitionen, für die er als Leader diente, kurzzeitig nicht verfügbar. Der Kafka-Controller (Interne Koordination) erkennt den Ausfall und startet eine Leader-Wahl für diese Partitionen.
Wenn mindestens ein Follower-Replica aktuell genug ist, kann es die Führung übernehmen und Clients produzieren/consumieren wieder. Ist kein in-sync Replica verfügbar, kann Kafka (je nach Einstellung) Schreibzugriffe anhalten, um zu vermeiden, dass bestätigte Daten verloren gehen.
Dauerhaftigkeit: Acks und Replikationsfaktor
Zwei Hauptstellschrauben bestimmen die Dauerhaftigkeit:
- Replikationsfaktor: wie viele Kopien jeder Partition existieren (z. B. 3 Kopien über 3 Broker).
- Acknowledgments (acks): wann ein Producer einen Write als erfolgreich betrachtet.
Konzeptionell:
- acks=0: Producer wartet nicht — schnell, aber Nachrichten können verloren gehen.
- acks=1: Leader bestätigt den Write — besser, aber wenn der Leader ausfällt bevor Follower die Daten kopiert haben, können jüngste Nachrichten verloren gehen.
- acks=all (oder -1): Leader wartet auf Bestätigung der in-sync Replicas — sicherer, meist etwas langsamer.
Um Duplikate bei Retries zu reduzieren, kombinieren Teams oft sichere acks mit idempotenten Producern und robuster Consumer-Logik (weiter unten behandelt).
Latenz vs. Sicherheit
Höhere Sicherheit bedeutet typischerweise, auf mehr Bestätigungen zu warten und mehr Replikate synchron zu halten, was Latenz erhöhen und Spitzen-Durchsatz reduzieren kann.
Niedrigere Latenz-Einstellungen sind für Telemetrie oder Clickstream-Daten akzeptabel, wo gelegentlicher Verlust tolerierbar ist; Zahlungen, Inventar und Audit-Logs rechtfertigen meistens die zusätzliche Sicherheit.
Kafkas Rolle in ereignisgesteuerter Architektur
Übernimm die Codebasis
Behalte die volle Kontrolle, indem du den Quellcode exportierst, wenn du über den Prototyp hinausgehen willst.
Ereignisgesteuerte Architektur (EDA) baut Systeme so auf, dass geschäftliche Ereignisse — eine Bestellung, eine bestätigte Zahlung, ein versandtes Paket — als Ereignisse dargestellt werden, auf die andere Teile des Systems reagieren können.
Ereignisse publizieren, mit Consumern reagieren
Kafka sitzt oft im Zentrum der EDA als geteilter "Ereignisstrom". Statt Dienst A Dienst B direkt aufzurufen, publiziert Dienst A ein Event (z. B. OrderCreated) in ein Kafka-Topic. Beliebig viele andere Dienste können dieses Event konsumieren und Aktionen auslösen — E-Mails senden, Inventar reservieren, Betrugsprüfungen starten — ohne dass Dienst A wissen muss, wer alles existiert.
Lose Kopplung (weniger direkte Abhängigkeiten)
Weil Dienste über Ereignisse kommunizieren, müssen sie nicht für jede Interaktion Request/Response-APIs koordinieren. Das reduziert enge Abhängigkeiten zwischen Teams und erleichtert das Hinzufügen neuer Features: Du kannst einen neuen Consumer für ein bestehendes Event einführen, ohne den Producer zu ändern.
Asynchrone Workflows und Widerstand gegen Lastspitzen
EDA ist natürlich asynchron: Producer schreiben Ereignisse schnell, und Consumer verarbeiten sie in ihrem eigenen Tempo. Bei Verkehrsspitzen puffert Kafka die Welle, sodass Downstream-Systeme nicht sofort zusammenbrechen. Consumer können horizontal skaliert werden, um aufzuholen, und wenn ein Consumer vorübergehend ausfällt, kann er dort weitermachen, wo er aufgehört hat.
Praktisches mentales Modell
Denke an Kafka als das "Aktivitäts-Feed" des Systems. Producer veröffentlichen Fakten; Consumer abonnieren die Fakten, die sie interessieren. Dieses Muster ermöglicht Echtzeit-Datenpipelines und ereignisgesteuerte Workflows und hält Dienste einfacher und unabhängiger.
Gängige Kafka-Anwendungsfälle in modernen Systemen
Kafka taucht dort auf, wo Teams viele kleine "Fakten, die passiert sind" (Ereignisse) zwischen Systemen bewegen müssen — schnell, zuverlässig und so, dass mehrere Consumer dieselben Daten wiederverwenden können.
Aktivitäts-Tracking und Audit-Logs
Anwendungen benötigen oft eine append-only Historie: Benutzeranmeldungen, Berechtigungsänderungen, Datensatzänderungen oder Admin-Aktionen. Kafka eignet sich gut als zentraler Ereignisstrom, sodass Sicherheitstools, Reporting und Compliance-Exporte dieselbe Quelle lesen, ohne die Produktionsdatenbank zu belasten. Da Ereignisse für eine Zeit aufbewahrt werden, kannst du sie auch erneut abspielen, um nach einem Fehler oder Schemawechsel eine Audit-Ansicht neu aufzubauen.
Kommunikation zwischen Microservices über Events
Statt Dienste direkt aufzurufen, können sie Events wie "order created" oder "payment received" veröffentlichen. Andere Dienste abonnieren und reagieren in ihrem eigenen Tempo. Das reduziert enge Kopplung, hilft Systemen bei Teil-Ausfällen weiterzuarbeiten und macht es einfacher, neue Fähigkeiten (z. B. Betrugsprüfungen) hinzuzufügen, indem man einfach den bestehenden Event-Stream konsumiert.
Datenpipelines zu Analytics und Warehouses
Kafka ist ein gängiges Rückgrat, um Daten aus operativen Systemen in Analytics-Plattformen zu bewegen. Teams können Änderungen aus Anwendungsdatenbanken streamen und mit geringer Verzögerung in ein Warehouse oder einen Data Lake liefern, während die Produktionsanwendung von schweren analytischen Abfragen getrennt bleibt.
IoT und Telemetrie mit burstigem Traffic
Sensoren, Geräte und App-Telemetrie kommen oft in Spitzen an. Kafka kann Bursts aufnehmen, sicher puffern und Downstream-Verarbeitung aufholen lassen — nützlich für Monitoring, Alerts und Langzeitanalyse.
Kafka ist mehr als Broker und Topics. Die meisten Teams nutzen Begleit-Tools, die Kafka im Alltag praktikabel machen — für Datenbewegung, Stream-Processing und Betrieb.
Kafka Connect: Daten bewegen ohne eigenen Code
Kafka Connect ist Kafkas Integrationsframework, um Daten in Kafka (Sources) und aus Kafka (Sinks) zu bewegen. Statt Einzellösungen zu bauen, betreibst du Connect und konfigurierst Connectoren.
Typische Beispiele: Änderungen aus Datenbanken ziehen, SaaS-Ereignisse ingestieren oder Kafka-Daten in ein Data Warehouse oder Objektspeicher liefern. Connect standardisiert zudem Betriebskonzepte wie Retries, Offsets und Parallelismus.
Kafka Streams: Echtzeitverarbeitung in deiner Anwendung
Wenn Connect für Integration steht, ist Kafka Streams für Berechnung. Es ist eine Bibliothek, die du deiner Anwendung hinzufügst, um Streams in Echtzeit zu transformieren — filtern, anreichern, Streams joinen und Aggregate bauen (z. B. „Orders pro Minute“).
Da Streams-Apps aus Topics lesen und wieder in Topics schreiben, fügen sie sich natürlich in ereignisgesteuerte Systeme ein und skalieren durch zusätzliche Instanzen.
Schema-Management: Ereignisse konsistent halten
Wenn mehrere Teams Ereignisse veröffentlichen, ist Konsistenz wichtig. Schema-Management (oft über ein Schema-Registry) definiert, welche Felder ein Ereignis haben soll und wie es sich über die Zeit entwickelt. Das verhindert Brüche, etwa wenn ein Producer ein Feld umbenennt, von dem ein Consumer abhängt.
Kafka ist betriebssensitiv, daher ist grundlegendes Monitoring unerlässlich:
- Consumer-Lag: Liegen Consumer zurück?
- Durchsatz: Wie viele Ereignisse pro Sekunde fließen?
- Fehler: Fehlgeschlagene Fetches, Produce-Errors, Connector-Task-Fehler
Die meisten Teams nutzen außerdem Management-UIs und Automatisierung für Deployments, Topic-Konfigurationen und Zugriffskontrollrichtlinien (siehe /blog/kafka-security-governance).
Liefergarantien und Verarbeitungsmuster
Einen DLQ-Workflow hinzufügen
Erstelle eine kleine App, um Poison-Nachrichten zu verarbeiten und Fehler zu prüfen, ohne Consumer zu blockieren.
Kafka wird oft als „dauerhaftes Log + Consumer“ beschrieben, aber was die meisten Teams wirklich interessiert, ist: Verarbeite ich jedes Event genau einmal und was passiert bei Fehlern? Kafka liefert Bausteine, und du wählst die Kompromisse.
Liefergarantien (grober Überblick)
At-most-once heißt, du kannst Ereignisse verlieren, aber du verarbeitest keine Duplikate. Das passiert, wenn ein Consumer seine Position zuerst committet und dann vor Abschluss der Arbeit abstürzt.
At-least-once heißt, du verlierst keine Ereignisse, aber Duplikate sind möglich (z. B. wenn ein Consumer ein Ereignis verarbeitet, abstürzt und nach Neustart erneut verarbeitet). Das ist der häufigste Standard.
Exactly-once zielt darauf ab, sowohl Verlust als auch Duplikate zu vermeiden. In Kafka involviert das typischerweise transaktionale Producer und kompatible Verarbeitung (oft via Kafka Streams). Es ist mächtig, aber restriktiver und erfordert sorgfältige Einrichtung.
Idempotenz und Deduplication
In der Praxis akzeptieren viele Systeme at-least-once und fügen Schutzmechanismen hinzu:
- Idempotente Writes: Mache den "Event anwenden"-Schritt wiederholbar (z. B. Upserts, bedingte Updates, eindeutige Schlüssel).
- Deduplication: Speichere eine Event-ID (oder Geschäfts-Key) und ignoriere Wiederholungen innerhalb eines Fensters.
Consumer-Offsets: dein "Lesezeichen"
Ein Consumer-Offset ist die Position des zuletzt verarbeiteten Datensatzes in einer Partition. Wenn du Offsets committest, sagst du: „Bis hierhin bin ich fertig.“ Zu früh committen riskiert Verlust; zu spät committen erhöht Duplikate bei Fehlern.
Retries und Poison Messages
Retries sollten begrenzt und sichtbar sein. Ein gängiges Muster ist:
- Wiederholen mit Backoff bei transienten Fehlern,
- dann den fehlerhaften Datensatz in ein Dead-Letter-Topic schicken zur Inspektion und zum späteren Replay.
So blockiert eine "poison message" nicht die gesamte Consumer-Gruppe, während die Daten für spätere Korrekturen erhalten bleiben.
Sicherheits- und Governance-Überlegungen
Kafka transportiert oft geschäftskritische Ereignisse (Bestellungen, Zahlungen, Benutzeraktivitäten). Deshalb sind Sicherheit und Governance Teil des Designs, nicht nachträglich.
Authentifizierung und Autorisierung
Authentifizierung beantwortet „Wer bist du?“. Autorisierung beantwortet „Was darfst du tun?“. In Kafka erfolgt Authentifizierung häufig mit SASL (z. B. SCRAM oder Kerberos), und Autorisierung wird mit ACLs (Access Control Lists) auf Topic-, Consumer-Group- und Cluster-Ebene durchgesetzt.
Eine praktische Regel ist das Prinzip der geringsten Rechte: Producer dürfen nur in die Topics schreiben, die sie besitzen; Consumer dürfen nur die Topics lesen, die sie benötigen. Das reduziert versehentliche Datenaussetzung und begrenzt den Schaden, falls Anmeldeinformationen kompromittiert werden.
Verschlüsselung in Transit (TLS)
TLS verschlüsselt Daten zwischen Apps, Brokern und Tools. Ohne TLS können Ereignisse im internen Netzwerk abgefangen werden, nicht nur im öffentlichen Internet. TLS hilft zudem, Man-in-the-Middle-Angriffe zu verhindern, indem Broker-Identitäten validiert werden.
Multi-Tenant-Kafka und Namenskonventionen
Wenn mehrere Teams einen Cluster teilen, sind Leitplanken wichtig. Klare Topic-Namenskonventionen (z. B. <team>.<domain>.<event>.<version>) machen Ownership deutlich und helfen Tools, Richtlinien konsistent anzuwenden.
Paarung von Namenskonventionen mit Quotas und ACL-Templates sorgt dafür, dass eine laute Arbeitslast andere nicht ausbremst und neue Services mit sicheren Voreinstellungen starten.
Daten-Governance: PII, Retention und Alignment
Behandle Kafka nur dann als System of Record für Ereignishistorie, wenn du das beabsichtigst. Wenn Ereignisse PII enthalten, verwende Datenminimierung (IDs statt kompletter Profile), erwäge feldspezifische Verschlüsselung und dokumentiere, welche Topics sensibel sind.
Retention-Einstellungen sollten rechtlichen und geschäftlichen Anforderungen entsprechen. Wenn Richtlinie "lösche nach 30 Tagen" sagt, dann behalte nicht 6 Monate an Daten "nur für den Fall". Regelmäßige Überprüfungen und Audits halten die Konfigurationen im Lauf der Zeit konform.
Kafka betreiben: Wofür Teams planen sollten
Einen EDA-Service prototypen
Prototyp eines ereignisgesteuerten Dienstes mit React-UI, Go-Backend und PostgreSQL in Koder.ai.
Kafka zu betreiben ist nicht einfach „installieren und vergessen“. Es verhält sich eher wie ein gemeinsam genutztes Versorgungswerk: Viele Teams sind davon abhängig, und kleine Fehler können sich auf viele Downstream-Apps auswirken.
Grundlagen der Kapazitätsplanung
Kapazität ist größtenteils Rechenwerk, das du regelmäßig neu betrachtest. Die größten Stellschrauben sind Partitionen (Parallelität), Durchsatz (MB/s in und out) und Speicherwachstum (wie lange du Daten aufbewahrst).
Wenn der Traffic sich verdoppelt, brauchst du möglicherweise mehr Partitionen, um die Last zu verteilen, mehr Plattenspeicher für Retention und mehr Netzwerk-Kapazität für Replikation. Eine praktische Gewohnheit ist, die Spitzen-Schreibrate zu prognostizieren und mit Retention zu multiplizieren, um das Speicherwachstum zu schätzen, dann Puffer für Replikation und "unerwarteten Erfolg" einzurechnen.
Tägliche Betriebsaufgaben
Erwarte Routinearbeit über das bloße Bereitstellen von Servern hinaus:
- Upgrades: Rolling Upgrades planen, Client-Kompatibilität testen und Änderungen zu verkehrsarmen Zeiten durchführen.
- Rebalancing: Consumer-Group-Rebalances können kurze Pausen verursachen; sichere Deployment-Pattern und klare Verantwortlichkeiten sind wichtig.
- Incident Response: Playbooks für Broker-Ausfälle, volllaufende Festplatten und falsch konfigurierte Producer, die ein Topic fluten.
Kostentreiber und Bereitstellungsoptionen
Kosten werden bestimmt von Platten, Netzwerk-Ausgang und der Anzahl/Größe der Broker. Managed Kafka kann den Personalaufwand verringern und Upgrades vereinfachen, während Self-Hosting bei großem Maßstab günstiger sein kann, falls du erfahrene Betreiber hast. Der Kompromiss liegt in Wiederherstellungszeit und On-Call-Aufwand.
Was gemessen werden sollte
Teams überwachen typischerweise:
- End-to-End-Latenz (vom Produce bis zum Consume)
- Consumer-Lag (wie weit Consumer zurückliegen)
- Broker-Gesundheit (Plattennutzung, under-replicated partitions, Fehlerraten bei Requests)
Gute Dashboards und Alerts verwandeln Kafka von einer "Black Box" in einen verständlichen Service.
Wann man Kafka nutzen sollte (und wann nicht)
Kafka passt gut, wenn du viele Ereignisse zuverlässig bewegen musst, sie eine Zeit lang aufbewahrt werden sollen und mehrere Systeme denselben Datenstrom in ihrem eigenen Tempo verarbeiten sollen. Besonders nützlich, wenn Events erneut abgespielt werden müssen (Backfills, Audits, neuer Service) und wenn du erwartest, dass mit der Zeit mehr Producer/Consumer hinzukommen.
Gute Einsatzfälle für Kafka
Kafka eignet sich besonders, wenn du:
- Hochdurchsatz-Ereignisströme hast (Clicks, Orders, Sensordaten)
- Viele Consumer dieselben Ereignisse benötigen (Analytics, Monitoring, Fraud, Notifications)
- Replay und langlebige Historie ein Feature sind, nicht nur "einmal liefern und vergessen"
- Integrationsarbeit entfällt und Teams/Services entkoppelt werden sollen
Wann Kafka zu schwer sein kann
Kafka ist überdimensioniert, wenn dein Bedarf einfach ist:
- Eine einzelne, niedrigvolumige Queue zwischen zwei Diensten
- Kurzlebige Tasks (Background Jobs), bei denen Replay keinen Mehrwert hat
- Teams ohne Kapazität, ein verteiltes System zu betreiben und zu überwachen
In diesen Fällen kann der Betriebsaufwand (Cluster-Größe, Upgrades, Monitoring, On-Call) den Nutzen übersteigen.
Alternativen und Ergänzungen
- RabbitMQ: gut für klassische Work-Queues und Routing-Muster.
- NATS: leichtgewichtiges Messaging mit niedriger Latenz.
- Cloud Pub/Sub: geeignet, wenn du verwaltete Infrastruktur und einfacheren Betrieb möchtest.
Kafka ergänzt — ersetzt nicht — Datenbanken (System of Record), Caches (schnelle Lesezugriffe) und Batch-ETL-Tools (große periodische Transformationen).
Kurze Entscheidungs-Checkliste
Frage dich:
- Brauchen wir mehrere Consumer und Replay?
- Wird der Durchsatz erheblich wachsen?
- Brauchen wir Ereignishistorie/Retention als Feature?
- Können wir Betriebsverantwortung tragen (oder Managed Kafka nutzen)?
- Streamen wir Ereignisse und senden nicht nur Befehle/Tasks?
Wenn du auf die meisten Fragen "Ja" antwortest, ist Kafka meistens eine sinnvolle Wahl.
Einstieg: Ein einfacher Adoption-Pfad
Kafka passt am besten, wenn du eine gemeinsame "Quelle der Wahrheit" für Echtzeit-Ereignisströme brauchst: viele Systeme, die Fakten produzieren (Bestellungen erstellt, Zahlungen autorisiert, Lager geändert) und viele Systeme, die diese Fakten konsumieren, um Pipelines, Analytics und reaktive Features zu betreiben.
Schritt 1: Wähle einen konkreten Anwendungsfall
Starte mit einem engen, wertvollen Flow — z. B. das Veröffentlichen von "OrderPlaced"-Ereignissen für Downstream-Services (E-Mail, Betrugserkennung, Fulfillment). Vermeide, Kafka von Anfang an zur Catch-All-Queue zu machen.
Schritt 2: Definiere deine Events und Topics
Halte fest:
- Events: was passiert ist, in klaren Geschäftsbegriffen
- Topics: wo diese Events leben (oft ein Topic pro Event-Typ oder Domäne)
- Consumer: welche Teams/Services die Events brauchen und warum
Halte frühe Schemas einfach und konsistent (Timestamps, IDs, klarer Event-Name). Entscheide, ob du Schemas von Anfang an durchsetzen willst oder sie vorsichtig weiterentwickelst.
Schritt 3: Etabliere Ownership und Betriebsgrundlagen
Kafka gelingt, wenn jemand zuständig ist für:
- Topic-Erstellung und Namenskonventionen
- Retention- und Zugriffspolicies
- On-Call-Verantwortlichkeiten und Runbooks
Füge Monitoring sofort hinzu (Consumer-Lag, Broker-Health, Durchsatz, Fehlerraten). Wenn du noch kein Plattformteam hast, starte mit einem Managed-Angebot und klaren Limits.
Schritt 4: Baue eine "dünne" erste Pipeline
Produziere Events aus einem System, konsumiere sie an einem Ort und beweise den End-to-End-Loop. Erst dann erweitere zu mehr Consumern, Partitionen und Integrationen.
Wenn du schnell von einer Idee zu einem funktionierenden ereignisgetriebenen Service kommen willst, können Tools wie Koder.ai helfen, die umgebende Anwendung (React Web UI, Go-Backend, PostgreSQL) zu prototypisieren und iterativ Kafka Producer/Consumer per Chat-gestütztem Workflow hinzuzufügen. Nützlich für interne Dashboards und leichte Services, mit Funktionen wie Planungsmodus, Quellcode-Export, Deployment/Hosting und Snapshots mit Rollback.
Wenn du das in einen event-getriebenen Ansatz einordnen möchtest, siehe /blog/event-driven-architecture. Zur Planung von Kosten und Umgebungen, prüfe /pricing.