26. Nov. 2025·8 Min
Wie man eine Web-App baut, um betriebliche Engpässe zu verfolgen
Schritt-für-Schritt-Anleitung zum Planen, Entwerfen und Bereitstellen einer Web-App, die Workflow-Daten erfasst, Engpässe aufdeckt und Teams hilft, Verzögerungen zu beheben.
Mit dem Problem und den Entscheidungen anfangen
Eine Prozess-Tracking-Web-App hilft nur, wenn sie eine konkrete Frage beantwortet: „Wo bleiben wir hängen und was sollen wir dagegen tun?“ Bevor Sie Bildschirme entwerfen oder eine Web-Architektur wählen, definieren Sie, was in Ihrer Organisation unter „Engpass“ fällt.
Definieren, was als Engpass zählt
Ein Engpass kann ein Schritt sein (z. B. „QA-Review“), ein Team (z. B. „Fulfillment“), ein System (z. B. „Zahlungs-Gateway“) oder sogar ein Lieferant (z. B. „Spediteur-Abholung“). Wählen Sie die Definitionen, die Sie tatsächlich steuern werden. Zum Beispiel:
- Ein Schritt ist ein Engpass, wenn seine durchschnittliche Wartezeit 24 Stunden überschreitet.
- Ein Team ist ein Engpass, wenn die Work-in-Progress (WIP) länger als 3 Tage über einem festgelegten Schwellenwert bleibt.
- Ein System ist ein Engpass, wenn Vorfälle die Durchlaufzeit außerhalb eines vereinbarten Bereichs ansteigen lassen.
Listen Sie die Entscheidungen auf, die die App ermöglichen muss
Ihr Operations-Dashboard sollte zu Maßnahmen führen, nicht nur Berichte liefern. Schreiben Sie die Entscheidungen auf, die Sie schneller und mit mehr Sicherheit treffen möchten, z. B.:
- Personalplanung: „Verschieben wir diese Woche eine Person von Team A zu Team B?“
- Priorisierung: „Welche Bestellungen/Tickets sollen die Warteschlange überspringen, um SLAs zu schützen?“
- Automatisierung: „Welcher Schritt ist stabil genug (und teuer genug), um ihn zuerst zu automatisieren?“
Primäre Nutzer und deren Bedarf identifizieren
Verschiedene Nutzer brauchen unterschiedliche Ansichten:
- Ops-Manager benötigen eine klare Ansicht „wo heute eingreifen“.
- Teamleiter brauchen Drilldowns zu einzelnen Warteschlangen, Blockern und Übergaben.
- Analysten benötigen konsistente Definitionen und Exporte für Workflow-Analysen.
Erfolgsmetriken für die App selbst festlegen
Definieren Sie, wie Sie wissen, dass die App funktioniert. Gute Messgrößen sind Adoption (wöchentliche aktive Nutzer), eingesparte Zeit beim Reporting und schnellere Problemlösung (reduzierte Time-to-detect und Time-to-fix von Engpässen). Diese Metriken halten Sie bei Ergebnissen statt Features.
Wählen Sie den Workflow und erstellen Sie eine einfache Prozesskarte
Bevor Sie Tabellen, Dashboards oder Alerts entwerfen, wählen Sie einen Workflow, den Sie in einem Satz beschreiben können. Ziel ist es, zu verfolgen, wo Arbeit wartet — also starten Sie klein und wählen Sie ein oder zwei Prozesse, die wichtig sind und ein stetiges Volumen erzeugen, wie Auftragsabwicklung, Support-Tickets oder Mitarbeiter-Onboarding.
Ein eng gefasster Umfang macht die Definition von Done klar und verhindert, dass das Projekt stehen bleibt, weil verschiedene Teams darüber streiten, wie der Prozess sein sollte.
Mit 1–2 Prozessen mit hohem Signal beginnen
Wählen Sie Workflows, die:
- Häufig vorkommen (genug Daten, um Muster zu erkennen)
- Mindestens eine Übergabe enthalten (wo sich Warteschlangen bilden)
- Einen klaren Kundeneinfluss haben (Zeit, Kosten, Zufriedenheit)
Zum Beispiel ist „Support-Tickets“ oft besser als „Customer Success“, weil es eine offensichtliche Arbeitseinheit und zeitgestempelte Aktionen gibt.
Schritte und Übergaben in einfacher Sprache kartieren
Schreiben Sie den Workflow als einfache Liste von Schritten in der Sprache, die das Team bereits verwendet. Sie dokumentieren keine Richtlinie — Sie identifizieren Zustände, durch die das Arbeitselement läuft.
Eine schlanke Prozesskarte könnte so aussehen:
- Ticket erstellt → triagiert → zugewiesen → Agent arbeitet → wartet auf Kunde → gelöst
Markieren Sie Übergaben explizit (triage → assigned, agent → specialist, etc.). Übergaben sind Orte, an denen Wartezeit oft versteckt ist und die Sie später messen möchten.
Start-/End-Ereignisse und „Done“ für jeden Schritt definieren
Für jeden Schritt notieren Sie zwei Dinge:
- Start-Ereignis (was beweist, dass der Schritt begonnen hat?)
- End-Ereignis (was beweist, dass der Schritt beendet ist?)
Halten Sie es beobachtbar. „Agent beginnt zu untersuchen“ ist subjektiv; „Status auf In Progress gesetzt“ oder „erste interne Notiz hinzugefügt“ ist nachvollziehbar.
Definieren Sie auch, was „done“ bedeutet, damit die App Teilabschlüsse nicht mit vollständiger Fertigstellung verwechselt. Beispiel: „gelöst“ kann bedeuten „Lösungsnachricht gesendet und Ticket als Resolved markiert“, nicht nur „intern abgeschlossene Arbeit“.
Übliche Ausnahmen notieren, die Sie später verfolgen
Echte Abläufe sind unordentlich: Nacharbeit, Eskalationen, fehlende Informationen und wieder geöffnete Elemente. Modellieren Sie nicht alles am ersten Tag — notieren Sie die Ausnahmen, damit Sie sie später bewusst hinzufügen können.
Eine einfache Notiz wie „10–15% der Tickets werden an Tier 2 eskaliert“ reicht. Diese Hinweise helfen zu entscheiden, ob Ausnahmen eigene Schritte, Tags oder separate Flows werden, wenn das System erweitert wird.
Metriken definieren, die tatsächlich Engpässe aufdecken
Ein Engpass ist kein Gefühl — er ist eine messbare Verlangsamung an einem bestimmten Schritt. Bevor Sie Diagramme bauen, entscheiden Sie, welche Zahlen beweisen, wo Arbeit sich staut und warum.
Ein kleines Set Kernmetriken wählen
Starten Sie mit vier Metriken, die in den meisten Workflows funktionieren:
- Durchlaufzeit (Cycle time): wie lange ein Element von Start bis Done braucht.
- Warte-/Queue-Zeit: wie lange ein Element zwischen Schritten untätig sitzt.
- Durchsatz (Throughput): wie viele Elemente pro Zeitfenster abgeschlossen werden.
- WIP (Work in Progress): wie viele Elemente gerade „im System“ sind.
Diese decken Geschwindigkeit (Durchlauf), Leerlauf (Queue), Output (Durchsatz) und Last (WIP) ab. Die meisten „mysteriösen Verzögerungen“ zeigen sich als wachsende Wartezeit und WIP an einem bestimmten Schritt.
Berechnungen (inkl. Randfälle) definieren
Schreiben Sie Definitionen, denen das ganze Team zustimmen kann, und implementieren Sie genau diese.
- Cycle time =
done_timestamp − start_timestamp.- Randfälle: wieder geöffnete Elemente (als neuer Zyklus behandeln vs. ursprünglichen Zyklus verlängern), nie gestartete Elemente (aus der Durchlaufzeit ausschließen, aber in WIP zählen), fehlende Zeitstempel (als Datenqualitätsproblem markieren).
- Queue time = Summe der Lücken zwischen Schritten, in denen der Status „wartet“ ist.
- Randfälle: Nächte/Wochenenden (Kalenderzeit vs. Geschäftszeit), blockierte Zustände (separat zählen, wenn Sie klare Ursachen wollen).
- Throughput = Anzahl der Elemente mit
done_timestampim Fenster.- Randfälle: Stornierungen (ausschließen oder separat verfolgen), Teilabschlüsse.
- WIP = Anzahl der Elemente, die sich zu einem Zeitpunkt nicht in einem terminalen Zustand befinden.
- Randfälle: On-hold-Elemente (weiterhin WIP, aber ggf. als „blocked WIP“ separat ausweisen).
Die Aufschlüsselungen wählen, die Entscheidungen treiben
Wählen Sie Slices, die Manager wirklich nutzen: Team, Kanal, Produktlinie, Region und Priorität. Ziel ist es zu beantworten: „Wo ist es langsam, für wen und unter welchen Bedingungen?“
Zeitfenster und Ziele festlegen
Entscheiden Sie Ihre Reporting-Routine (täglich und wöchentlich sind üblich) und definieren Sie Ziele wie SLA/SLO-Schwellen (z. B. „80% der hochprioritären Elemente innerhalb von 2 Tagen abgeschlossen“). Ziele machen das Dashboard handlungsfähig statt dekorativ.
Datenquellen und Erfassungsmethode planen
Der schnellste Weg, ein Engpass-Tracking-Projekt zu blockieren, ist anzunehmen, die Daten seien „einfach da“. Bevor Sie Tabellen oder Diagramme entwerfen, notieren Sie, wo jedes Ereignis und Zeitstempel herkommt — und wie Sie die Konsistenz über die Zeit sicherstellen.
Inventar der vorhandenen Quellen
Die meisten Teams tracken Arbeit bereits an einigen Stellen. Übliche Ausgangspunkte sind:
- Tabellenkalkulationen, die für Übergaben, Tageslogs oder Produktionszählungen genutzt werden
- ERP-/CRM-Systeme (Bestellungen, Kunden, Fulfillment-Schritte)
- Ticketing-Tools (Support-Queues, Änderungsanfragen, Wartungsaufgaben)
- Interne Datenbanken (Warehouse-Scans, Job-Scheduling-Tabellen, Manufacturing Execution Data)
Notieren Sie für jede Quelle, was sie liefern kann: eine stabile Record-ID, eine Statushistorie (nicht nur den aktuellen Status) und mindestens zwei Zeitstempel (Eintritt in Schritt, Austritt aus Schritt). Ohne diese ist Queue-Time-Monitoring und Cycle-Time-Tracking geratenes Schätzen.
Eine Erfassungsmethode wählen, die zur Quelle passt
In der Praxis haben Sie meist drei Optionen und viele Apps nutzen eine Mischung:
- API-Pull: geplante Synchronisation aus ERP/CRM/Ticketing-Tools. Einfach zu verstehen, aber Sie müssen Pagination, Rate Limits und inkrementelle Updates handhaben.
- Webhooks: Push-Updates, sobald Arbeit sich ändert. Gut für near-real-time Alerts, aber Sie müssen Retries und aus der Reihenfolge kommende Events designen.
- Manuelle Eingabe / CSV-Upload: nützlich für Teams, die von Spreadsheets starten oder Edge-Cases. Machen Sie es sicher mit Vorlagen, Validierung und klaren Fehlermeldungen.
Für Datenqualität planen (weil sie kommen wird)
Erwarten Sie fehlende Zeitstempel, Duplikate und inkonsistente Status („In Progress“ vs. „Working“). Bauen Sie Regeln früh ein:
- Bevorzugen Sie ein unveränderliches Event-Log statt Überschreiben von Records
- Deduplizieren nach Source-ID + Event-Time + Status
- Normalisieren Sie Status in die kanonischen Schritte Ihrer App
- Markieren Sie Datensätze, die keine verlässliche Durchlaufzeit liefern können
Aktualisierungsfrequenz entscheiden
Nicht jeder Prozess braucht Echtzeit. Wählen Sie nach Entscheidungen:
- Echtzeit: Disposition, Support-Triage, SLA-Risiko
- Stündlich: Lagerdurchsatz, Queue-Time-Monitoring
- Täglich: Wochenreporting, Continuous-Improvement-Reviews
Schreiben Sie das jetzt auf; es bestimmt Ihre Sync-Strategie, Kosten und Erwartungen an das Operations-Dashboard.
Datenmodell für zeitbasierte Analyse entwerfen
Eine Engpass-Tracking-App lebt oder stirbt daran, wie gut sie Zeitfragen beantworten kann: „Wie lange hat das gedauert?“, „Wo hat es gewartet?“ und „Was hat sich kurz vor der Verlangsamung verändert?“ Der einfachste Weg, diese Fragen später zu unterstützen, ist, die Daten von Anfang an um Events und Zeitstempel herum zu modellieren.
Mit den Kerntypen starten
Halten Sie das Modell klein und offensichtlich:
- Process: der Gesamtworkflow (z. B. „Order Fulfillment“).
- Step: eine Stufe innerhalb des Prozesses (z. B. „Pick“, „Pack“, „Ship").
- Work item: die Einheit, die durch die Schritte wandert (Ticket, Bestellung, Claim).
- Event: eine aufgezeichnete Zustandsänderung (Step betreten, zugewiesen, blockiert, abgeschlossen).
- User/Team und Assignment: wer die Arbeit zu einem Zeitpunkt besaß.
Diese Struktur ermöglicht, Durchlaufzeit pro Schritt, Wartezeit zwischen Schritten und Durchsatz über den ganzen Prozess zu messen, ohne Spezialfälle zu erfinden.
Ein Event-Log einem „aktuellen Status“-Feld vorziehen
Behandeln Sie jede Statusänderung als immutables Event-Record. Statt current_step zu überschreiben und Historie zu verlieren, hängen Sie ein Event an wie:
- work_item_id
- from_step → to_step (oder „entered_step“)
- event_type (assigned, started, blocked, completed)
- event_time
Sie können weiterhin einen „Current State“-Snapshot für Performance speichern, aber Ihre Analysen sollten auf dem Event-Log basieren.
Zeit und Nachvollziehbarkeit zur Pflicht machen
Speichern Sie Zeitstempel konsequent in UTC. Bewahren Sie außerdem Original-Source-IDs (z. B. Jira-Issue-Key, ERP-Order-ID) auf Work Items und Events, sodass jedes Diagramm auf einen realen Datensatz zurückverfolgt werden kann.
Ausnahmen erfassen, ohne Aufwand zu erzeugen
Planen Sie leichte Felder für Momente, die Verzögerungen erklären:
- reason_code (Standardoptionen wie „Waiting on customer")
- comment (optional)
- blocked_flag oder severity
Halten Sie sie optional und einfach ausfüllbar, damit Sie aus Ausnahmen lernen, ohne die App in ein Formularmonster zu verwandeln.
Architektur wählen, die zu Ihrem Team passt
Berechtigungen früh festlegen
Beziehe Viewer‑, Manager‑ und Admin‑Zugriffe ein sowie revisionssichere Änderungsverfolgung.
Die „beste“ Architektur ist die, die Ihr Team bauen, verstehen und jahrelang betreiben kann. Wählen Sie einen Stack, der zu Ihrem Talentpool und vorhandenen Fähigkeiten passt — übliche, gut unterstützte Optionen sind React + Node.js, Django oder Rails. Konsistenz schlägt Neuheit, wenn Sie ein Operations-Dashboard betreiben, auf das täglich Verlass ist.
Verantwortung trennen, damit das System editierbar bleibt
Eine Engpass-Tracking-App funktioniert meist besser, wenn Sie sie in klare Schichten aufteilen:
- Ingestion: Empfang von Events (Statusänderungen, Zeitstempel, Übergaben) aus Formularen, Integrationen oder Imports.
- Storage: transaktionale Datenbank für zuverlässige Writes und Audit-Historie.
- Analytics-Queries: leseoptimierte Queries oder Views zur Berechnung von Durchlaufzeit, Wartezeit und Durchsatz.
- UI/API: Endpunkte und Screens, die Dashboards schnell und vorhersehbar halten.
Diese Trennung erlaubt, einen Teil (z. B. neue Datenquelle) zu ändern, ohne alles neu zu schreiben.
Entscheiden, wo Berechnungen stattfinden sollen
Einige Metriken sind einfach in DB-Queries zu berechnen (z. B. „durchschnittliche Wartezeit pro Schritt letzte 7 Tage"). Andere sind teuer oder benötigen Vorverarbeitung (z. B. Perzentile, Anomalieerkennung, Wochen-Kohorten). Eine praktische Regel:
- Machen Sie Echtzeitfilter und Aufschlüsselungen in der Datenbank.
- Verwenden Sie Background-Jobs, um schwere Aggregates vorzukalkulieren und für schnelle Dashboard-Ladezeiten zu speichern.
- Fügen Sie eine Analytics-Schicht nur hinzu, wenn Ihr Team sie auch zuverlässig betreiben kann.
Für Performance früh planen
Operational Dashboards scheitern, wenn sie träge wirken. Indexieren Sie Zeitstempel, Workflow-Step-IDs und tenant/team-IDs. Fügen Sie Paginierung für Event-Logs hinzu. Cachen Sie häufige Dashboard-Views (z. B. „today“ und „last 7 days") und invalide Caches, wenn neue Events ankommen.
Wenn Sie tiefer in Trade-offs einsteigen möchten, führen Sie eine kurze Entscheidungsdokumentation im Repo, damit zukünftige Änderungen nicht aus der Spur geraten.
Ein schnellerer Pfad für Teams, die schnell ausliefern wollen
Wenn Ihr Ziel ist, Workflow-Analysen und Alerting zu validieren, bevor Sie sich auf einen vollständigen Build festlegen, kann eine Low-Code-/Vibe-Coding-Plattform wie Koder.ai helfen, eine erste Version schneller aufzusetzen: Sie beschreiben Workflow, Entitäten und Dashboards im Chat und iterieren dann an der generierten React-UI und Go + PostgreSQL-Backend, während Sie KPI-Instrumentierung verfeinern.
Der praktische Vorteil für eine Engpass-Tracking-App ist Tempo bis zum Feedback: Sie können Ingestion (API-Pulls, Webhooks oder CSV-Import) pilotieren, Drilldown-Screens hinzufügen und Metrikdefinitionen anpassen, ohne Wochen an Infrastruktur. Wenn Sie bereit sind, unterstützt Koder.ai auch Source-Code-Export sowie Deployment/Hosting, was den Übergang von Prototyp zu gepflegtem internen Tool erleichtert.
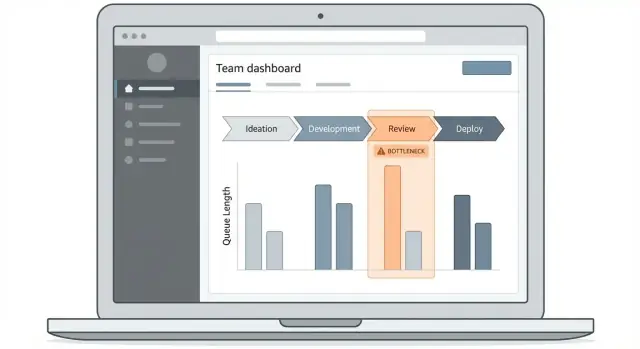
Dashboard- und Drilldown-Erlebnis entwerfen
Eine Engpass-Tracking-App steht oder fällt damit, ob Menschen schnell eine Frage beantworten können: „Wo bleibt Arbeit gerade hängen und welche Elemente verursachen das?“ Ihr Dashboard sollte diesen Pfad offensichtlich machen, auch für jemanden, der nur einmal pro Woche vorbeischaut.
Mit 2–3 Kern-Screens starten
Halten Sie den ersten Release eng:
- Übersichts-Dashboard: die „Status-Tafel“ für Durchlaufzeit, Wartezeit und Top-Blocked-Schritte.
- Work-Item-Liste: durchsuchbare, filterbare Tabelle mit von Verzögerungen betroffenen Items.
- Workflow-Detail: Schritt-für-Schritt-Ansicht, die Zeit in jeder Stufe und Übergabepunkte zeigt.
Diese Screens schaffen einen natürlichen Drilldown-Flow, ohne Nutzer mit einer komplexen UI zu überfordern.
Visualisierungen wählen, die Zeit und Fluss erklären
Wählen Sie Diagrammtypen, die zu operativen Fragen passen:
- Stufen-Funnel: zeigt, wo Volumen sich ansammelt (gut zum Finden von Warteschlangen).
- Time-in-Stage-Bars: vergleicht Schritte nach Median- und Perzentilzeiten, nicht nur Mittelwerten.
- Trendlinien: beantworten „wird es besser oder schlechter?“ über Wochen.
- Heatmaps: decken Muster auf wie „Montags in Review“ oder „Übergaben der Nachtschicht".
Beschriftungen schlicht halten: „Time waiting“ vs. „Queue latency" → besser „Wartezeit" oder „Queue-Latenz".
Filter konsistent und gut sichtbar machen
Nutzen Sie eine gemeinsame Filterleiste über alle Screens (gleiche Platzierung, gleiche Defaults): Datum, Team, Priorität und Schritt. Zeigen Sie aktive Filter als Chips an, damit Nutzer die Zahlen nicht falsch interpretieren.
Klare Drilldown-Pfade gestalten
Jede KPI-Kachel sollte klickbar sein und sinnvoll weiterführen:
KPI → Schritt → betroffene Elementliste
Beispiel: Ein Klick auf „Längste Wartezeit" öffnet die Schritt-Detailseite, und ein weiterer Klick zeigt die genauen Elemente, die dort aktuell warten — sortiert nach Alter, Priorität und Besitzer. So wird Neugier in eine konkrete To-Do-Liste verwandelt, und das macht das Dashboard nützlich statt ignoriert.
Alerts und Frühwarnsignale hinzufügen
Pilot schnell bereitstellen
Nutze Koder.ai‑Hosting, um dein internes Tool zu pilotieren und mit echten Nutzern iterativ zu verbessern.
Dashboards sind gut für Reviews, aber Engpässe schaden meist zwischen Meetings. Alerts verwandeln Ihre App in ein Frühwarnsystem: Sie finden Probleme, während sie entstehen, nicht nachdem die Woche verloren ist.
Mit klaren, langweiligen Regeln starten
Beginnen Sie mit wenigen Alert-Typen, die Ihr Team bereits als „schlecht" einstuft:
- Schwellenüberschreitungen: Durchlaufzeit oder Wartezeit über bekannter Grenze (z. B. „Review-Schritt > 24 Stunden").
- Ungewöhnliche Anstiege: heutige Median-Durchlaufzeit ist 30% höher als letzte Woche.
- Blockierte Items: keine Statusänderung für N Stunden/Tage oder Elemente, die ein Maximalalter überschreiten.
Halten Sie die erste Version einfach. Einige deterministische Regeln fangen die meisten Probleme und sind vertrauenswürdiger als komplexe Modelle.
Leichte Anomalie-Checks hinzufügen
Sobald Schwellen stabil sind, fügen Sie Basis-Signale für „ist das ungewöhnlich?“ hinzu:
- Prozentuale Veränderung vs. letzter Woche (gleicher Wochentag reduziert False Alarms).
- Gleitender Durchschnittsdrift (z. B. 7-Tage-Durchschnitt steigt stetig).
- Volumen-Mismatch (Input steigt schneller als Output an einem Schritt).
Machen Sie Anomalien zu Hinweisen, nicht zu Alarmen: Kennzeichnen Sie sie als „Hinweis“ oder „Heads up", bis Nutzer bestätigen, dass sie nützlich sind.
Alerts dorthin liefern, wo Leute arbeiten
Unterstützen Sie mehrere Kanäle, damit Teams wählen können:
- E-Mail für Manager und Tageszusammenfassungen
- Slack/Microsoft Teams für Echtzeit-Triage
- In-App-Benachrichtigungen für Owner in der Anwendung
Jeden Alert handlungsfähig machen
Ein Alert sollte beantworten: „was, wo und was als Nächstes“:
- Welcher Schritt ist betroffen und das Zeitfenster
- Die Haupttreiber (z. B. Team, Kategorie, Priorität)
- Ein direkter Link zur Untersuchung, z. B.:
/dashboard?step=review&range=7d&filter=stuck
Wenn Alerts nicht zu konkreten nächsten Schritten führen, werden Leute sie stummschalten — behandeln Sie die Qualität von Alerts als Produktfunktion, nicht als Add-on.
Berechtigungen, Sicherheit und Auditierbarkeit behandeln
Eine Engpass-Tracking-App wird schnell zur „Quelle der Wahrheit“. Das ist gut — bis die falsche Person eine Definition ändert, sensible Daten exportiert oder ein Dashboard außerhalb ihres Teams teilt. Berechtigungen und Audit-Trails sind kein Bürokratiekram; sie schützen das Vertrauen in die Zahlen.
Rollen und Zugriffsregeln definieren
Starten Sie mit einem kleinen, klaren Rollenmodell und erweitern Sie nur bei Bedarf:
- Viewer: Lesezugriff auf Dashboards und Berichte.
- Manager: kann nach Team filtern, gespeicherte Views erstellen, Alerts bestätigen und Notizen hinzufügen (aber keine globalen Einstellungen ändern).
- Admin: verwaltet Prozessdefinitionen, KPI-Formeln, Integrationen und Nutzerzugänge.
Seien Sie explizit, was jede Rolle darf: rohe Events ansehen vs. aggregierte Metriken, Daten exportieren, Schwellen bearbeiten, Integrationen verwalten.
Daten nach Team oder Geschäftseinheit trennen
Wenn mehrere Teams die App nutzen, erzwingen Sie Trennung in der Datenebene — nicht nur in der UI. Übliche Optionen:
- Multi-Tenant: jeder Datensatz hat ein
tenant_id, und jede Query ist darauf eingeschränkt. - Partitions/Projects: separate Workspaces pro Geschäftseinheit mit eigenen Einstellungen und Dashboards.
Entscheiden Sie früh, ob Manager andere Teams sehen dürfen. Machen Sie Cross-Team-Visibility zu einer bewussten Berechtigung, nicht zur Standardeinstellung.
Sichere Authentifizierung (SSO oder MFA-ready)
Wenn Ihre Organisation SSO (SAML/OIDC) hat, nutzen Sie es, damit Offboarding und Access Control zentral verwaltet werden. Wenn nicht, implementieren Sie ein Login, das MFA-ready ist (TOTP oder Passkeys), sichere Passwort-Resets unterstützt und Session-Timeouts erzwingt.
Änderungen auditierbar machen
Protokollieren Sie Aktionen, die Ergebnisse verändern oder Daten exponieren: Exporte, Schwellenänderungen, Workflow-Edits, Berechtigungsupdates und Integrationseinstellungen. Erfassen Sie wer es tat, wann, was sich änderte (vorher/nachher) und wo (Workspace/Tenant). Bieten Sie eine „Audit Log“-Ansicht an, damit Vorfälle schnell untersucht werden können.
Erkenntnisse in Maßnahmen und Prozessverbesserungen überführen
Ein Bottleneck-Dashboard zählt nur, wenn es verändert, was Menschen als Nächstes tun. Ziel dieses Abschnitts ist, „interessante Charts" in einen wiederholbaren Betriebsrhythmus zu überführen: entscheiden, handeln, messen und behalten, was funktioniert.
Leichtgewichtiges Bottleneck-Review einführen
Setzen Sie eine einfache wöchentliche Cadence (30–45 Minuten) mit klaren Verantwortlichen. Beginnen Sie mit den Top 1–3 Engpässen nach Impact (z. B. höchste Wartezeit oder größter Durchsatzabfall) und einigen Sie sich auf eine Aktion pro Engpass.
Halten Sie den Workflow klein:
- Owner: eine verantwortliche Person pro Aktion
- Fälligkeitsdatum: standardmäßig bis zum nächsten Review
- Definition of done: eine messbare Änderung (nicht „weiter untersuchen")
Erfassen Sie Entscheidungen direkt in der App, damit Dashboard und Aktionslog verbunden bleiben.
Verbesserungen als Experimente verfolgen
Behandeln Sie Änderungen wie Experimente, damit Sie schnell lernen und „zufällige Optimierungsaktionen" vermeiden. Für jede Änderung notieren Sie:
- Hypothese (was verlangsamt und warum)
- Änderung (was Sie tun werden)
- Erwarteter Effekt (welche Metrik sich wie verändert)
- Ergebnis (was tatsächlich passierte)
So entsteht über die Zeit ein Playbook: was Durchlaufzeit reduziert, was Nacharbeit verringert und was nicht.
Kontext mit Annotationen ergänzen
Diagramme können ohne Kontext irreführen. Fügen Sie einfache Annotationen auf Zeitlinien hinzu (z. B. Neueinstellung, Systemausfall, Policy-Update), damit Betrachter Verschiebungen in Wartezeit oder Durchsatz richtig interpretieren.
Teilen einfach machen
Bieten Sie Exportoptionen für Analysen und Reporting — CSV-Downloads und geplante Reports — damit Teams Ergebnisse in Ops-Updates und Leadership-Reviews einbinden können. Wenn Sie bereits eine Reporting-Seite haben, verlinken Sie sie vom Dashboard (z. B. /reports).
Deployment, Monitoring und Datenaktualität sicherstellen
Dein Build‑Budget strecken
Erhalte Credits, indem du teilst, was du gebaut hast, oder Teammitglieder zu Koder.ai einlädst.
Eine Engpass-Tracking-App ist nur nützlich, wenn sie zuverlässig verfügbar ist und die Zahlen vertrauenswürdig bleiben. Behandeln Sie Deployment und Datenfrische als Produktverantwortung, nicht als Nachgedanken.
Separate Umgebungen und reproduzierbare Deploys nutzen
Richten Sie dev / staging / prod früh ein. Staging sollte Produktion spiegeln (gleicher DB-Engine, ähnliches Datenvolumen, gleiche Background-Jobs), damit Sie langsame Queries und fehlerhafte Migrationsschritte vor Nutzern entdecken.
Automatisieren Sie Deployments mit einer Pipeline: Tests ausführen, Migrationen anwenden, deployen und einen Smoke-Check laufen lassen (einloggen, Dashboard laden, Ingestion prüfen). Halten Sie Deploys klein und häufig; das reduziert Risiko und macht Rollbacks machbar.
App und Pipeline überwachen
Sie sollten auf zwei Ebenen Monitoring haben:
- App-Gesundheit: Error-Rates, Latenz, langsame Endpunkte und langsame Queries.
- Daten-Gesundheit: Ingestion-Failures, Backlog-Größe und „Zeit seit letztem Event empfangen".
Alerten Sie auf Symptome, die Nutzer spüren (Dashboards timeouts) und auf frühe Signale (eine Warteschlange wächst seit 30 Minuten). Tracken Sie auch Metrik-Fehler — fehlende Durchlaufzeiten können wie „Verbesserung" aussehen.
Daten frisch halten: späte Events, Korrekturen und Backfills
Operative Daten kommen spät, außer der Reihenfolge oder werden korrigiert. Planen Sie für:
- Idempotente Ingestion (erneutes Verarbeiten des gleichen Events führt nicht zu Doppelzählung)
- Backfills für Zeiträume, in denen eine Quelle down war
- Recomputes, wenn Referenzdaten sich ändern (z. B. Schichtkalender aktualisiert)
Definieren Sie, was „frisch" bedeutet (z. B. 95% der Events innerhalb von 5 Minuten) und zeigen Sie die Frische in der UI an.
Runbooks schreiben, damit Fixes kein Ratespiel sind
Dokumentieren Sie Schritt-für-Schritt-Runbooks: wie man einen kaputten Sync neu startet, KPIs von gestern validiert und bestätigt, dass ein Backfill historische Zahlen nicht unerwartet verändert hat. Legen Sie sie im Projekt ab und verlinken Sie sie von /docs, damit das Team schnell reagieren kann.
Mit Nutzern iterieren und Abdeckung ausweiten
Eine Engpass-Tracking-App funktioniert, wenn Menschen ihr vertrauen und sie tatsächlich nutzen. Das geschieht erst, wenn Sie echte Nutzer beobachten, die echte Fragen stellen („Warum sind Genehmigungen diese Woche langsam?") und das Produkt auf diese Workflows zuschneiden.
Mit einem Pilot starten und lernen, was bricht
Beginnen Sie mit einem Pilotteam und einer kleinen Zahl von Workflows. Halten Sie den Umfang eng genug, um Nutzung zu beobachten und schnell zu reagieren.
In den ersten Wochen konzentrieren Sie sich auf Dinge, die verwirren oder fehlen:
- Welche Charts werden falsch gelesen?
- Wo bleiben Nutzer beim Drilldown hängen?
- Welche Daten erwarten sie, die nicht verfügbar sind?
- Welche operativen Engpässe erscheinen offensichtlich für sie, sind aber nicht in der App abgebildet?
Sammeln Sie Feedback in der App selbst (ein einfaches „War das nützlich?“-Prompt auf Schlüsselbildschirmen funktioniert gut), sodass Sie sich nicht auf Meeting-Erinnerungen verlassen.
Metriken validieren, um „Dashboard-Argumente" zu vermeiden
Bevor Sie auf weitere Teams ausrollen, sperren Sie Definitionen mit den Verantwortlichen. Viele Rollouts scheitern, weil Teams über die Bedeutung einer Metrik uneinig sind.
Für jede KPI (Durchlaufzeit, Wartezeit, Nacharbeitsrate, SLA-Verstöße) dokumentieren Sie:
- Exakte Start- und End-Ereignisse
- Umgang mit Pausen, Wochenenden und fehlenden Zeitstempeln
- Wie Ausnahmen gezählt werden (Stornierungen, Eskalationen, Reopens)
Überprüfen Sie diese Definitionen mit Nutzern und fügen Sie kurze Tooltips in der UI hinzu. Wenn Sie eine Definition anpassen, zeigen Sie ein Changelog, damit Nutzer verstehen, warum Zahlen sich verschoben haben.
Abdeckung ausweiten, ohne die App zu verschlechtern
Fügen Sie Funktionen vorsichtig hinzu und nur, wenn die Pilot-Workflows stabil sind. Häufige Erweiterungen sind: benutzerdefinierte Schritte (Teams bezeichnen Stufen unterschiedlich), zusätzliche Quellen (Tickets + CRM + Spreadsheets) und erweiterte Segmentierung (nach Produktlinie, Region, Priorität, Kundentyp).
Eine nützliche Regel: Fügen Sie jeweils nur eine neue Dimension hinzu und vergewissern Sie sich, dass sie Entscheidungen verbessert, nicht nur Reporting erweitert.
Onboarding einfach und wiederholbar machen
Beim Rollout für mehr Teams brauchen Sie Konsistenz. Erstellen Sie eine kurze Onboarding-Anleitung: wie Daten verbunden werden, wie das Operations-Dashboard zu interpretieren ist und wie man auf Alerts zu Engpässen reagiert.
Verlinken Sie Nutzer zu relevanten Seiten im Produkt und Inhalten, z. B. /pricing und /blog, damit neue Nutzer Antworten selbst finden können, statt auf Trainings zu warten.