Umfang und Benutzerbedürfnisse definieren
Bevor Sie Bildschirme entwerfen oder einen File‑Parser wählen, werden Sie konkret, wer Daten in Ihr Produkt rein- und rausbewegt und warum. Eine Datenimport‑Web‑App, die für interne Operatoren gebaut ist, sieht ganz anders aus als ein Self‑Service‑Excel‑Import‑Tool für Kunden.
Wer sind die Nutzer?
Beginnen Sie mit einer Auflistung der Rollen, die Imports/Exports anfassen werden:
- Admins, die Mappings, Regeln und Berechtigungen konfigurieren
- Operatoren, die Importe regelmäßig ausführen und Ausnahmen behandeln
- Kunden, die ihre eigenen CSV/Excel‑Dateien hochladen und klare Hilfestellung erwarten
Definieren Sie für jede Rolle das erwartete Skill‑Level und die Toleranz gegenüber Komplexität. Kunden benötigen in der Regel weniger Optionen und deutlich bessere In‑Product‑Erklärungen.
Kern‑Use‑Cases (und was „fertig“ bedeutet)
Schreiben Sie Ihre Top‑Szenarien auf und priorisieren Sie sie. Häufige Fälle sind:
- Initialer Bulk‑Load beim Onboarding (hohes Volumen, unordentliche Daten)
- Periodischer Sync (wöchentlich/monatlich, Konsistenz ist wichtig)
- Einmalige Exporte für Reporting, Migration oder Backup
Definieren Sie dann messbare Erfolgskennzahlen: weniger fehlgeschlagene Importe, kürzere Time‑to‑Resolution bei Fehlern und weniger Support‑Tickets vom Typ „meine Datei lädt nicht hoch“. Diese Metriken helfen später bei Trade‑Offs (z. B. in bessere Fehlerberichterstattung vs. Unterstützung zusätzlicher Formate investieren).
Seien Sie explizit, was Sie am ersten Tag unterstützen wollen:
- Dateiformate: CSV, Excel (XLSX), JSON
- Maximale Dateigröße und Zeilenlimits (und was passiert, wenn sie überschritten werden)
- Encoding‑Erwartungen (z. B. UTF‑8) und Zeitzonenregeln für Datumsangaben
Identifizieren Sie früh Compliance‑Bedürfnisse: enthalten Dateien PII, welche Aufbewahrungsregeln gelten und welche Audit‑Anforderungen bestehen (wer hat was wann importiert und was hat sich geändert). Diese Entscheidungen beeinflussen Speicher, Logging und Berechtigungen im gesamten System.
Architektur und Tech‑Stack wählen
Bevor Sie an eine schicke Spalten‑Mapping‑UI oder CSV‑Validierungsregeln denken: wählen Sie eine Architektur, die Ihr Team zuverlässig liefern und betreiben kann. Imports/Exports sind oft „langweilige“ Infrastruktur — Iterationsgeschwindigkeit und Debuggfähigkeit schlagen Neuheitswert.
Starten Sie mit einem Stack, den Ihr Team bereits kennt
Jeder gängige Web‑Stack kann eine Datenimport‑Web‑App antreiben. Wählen Sie basierend auf vorhandenen Skills und Einstellbarkeit:
- React + Node (TypeScript), wenn Sie eine Single‑Language Full‑Stack und ein starkes Ökosystem für Hintergrundjobs wollen.
- Django, wenn Sie ein batteries‑included Admin, ein ausgereiftes ORM und schnelle Lieferung bevorzugen.
- Rails, wenn Sie Konventionen, schnelles CRUD und bewährte Hintergrundjob‑Muster schätzen.
Der Schlüssel ist Konsistenz: der Stack sollte es einfach machen, neue Import‑Typen, Validierungsregeln und Exportformate hinzuzufügen, ohne alles neu schreiben zu müssen.
Wenn Sie das Scaffolding beschleunigen wollen, ohne sich auf einen einmaligen Prototypen festzulegen, kann eine Low‑Code/„vibe‑coding“ Plattform wie Koder.ai hilfreich sein: Sie beschreiben Ihren Import‑Flow (Upload → Vorschau → Mapping → Validierung → Hintergrundverarbeitung → Historie) im Chat, generieren eine React‑UI mit Go + PostgreSQL Backend und iterieren schnell mit Planungs‑ und Snapshot/Rollback‑Funktionen.
Speicherung: „Rohdatei“ von „normalisierten Records“ trennen
Verwenden Sie eine relationale Datenbank (Postgres/MySQL) für strukturierte Records, Upserts und Audit‑Logs für Datenänderungen.
Speichern Sie Original‑Uploads (CSV/Excel) in Object Storage (S3/GCS/Azure Blob). Rohdateien zu behalten ist für den Support unbezahlbar: Sie können Parsing‑Probleme reproduzieren, Jobs neu laufen lassen und Entscheidungen zur Fehlerbehandlung erklären.
Entscheiden, wie Importe laufen
Kleine Dateien können synchron verarbeitet werden (Upload → Validieren → Anwenden) für ein reaktionsschnelles UX. Bei größeren Dateien verlagern Sie die Arbeit in Hintergrundjobs:
- upload → enqueue job → Fortschritt/Historie anzeigen → Benachrichtigen bei Fertigstellung
Das ermöglicht auch Retries und rate‑limitiertes Schreiben.
Multi‑Tenant vs Single‑Tenant
Wenn Sie SaaS bauen, entscheiden Sie früh, wie Sie Tenant‑Daten trennen (Row‑Level Scoping, separate Schemas oder separate Datenbanken). Diese Wahl beeinflusst Ihre Export‑API, Berechtigungen und Performance.
Nicht‑funktionale Anforderungen jetzt dokumentieren
Schreiben Sie Ziele für Uptime, Max‑Dateigröße, erwartete Zeilen pro Import, Time‑to‑Complete und Kostenlimits nieder. Diese Zahlen treiben die Wahl des Job‑Queues, Batching‑Strategie und Indizierung—lange bevor Sie die UI polieren.
Den Import‑Intake‑Flow bauen
Der Intake‑Flow bestimmt den Ton für jeden Import. Wenn er vorhersehbar und nachsichtig wirkt, versuchen Nutzer es erneut, wenn etwas schiefgeht—und Support‑Tickets gehen zurück.
Einstiegspunkte: UI‑Upload und API
Bieten Sie eine Drag‑and‑Drop‑Zone plus klassischen Dateiauswahldialog für die Web‑UI. Drag‑and‑Drop ist schneller für Power‑User, die Dateiauswahl ist zugänglicher und vertrauter.
Wenn Kunden aus anderen Systemen importieren, fügen Sie einen API‑Endpunkt hinzu. Er kann Multipart‑Uploads (Datei + Metadaten) akzeptieren oder einen pre‑signed URL‑Flow für größere Dateien unterstützen.
Beim Upload führen Sie ein leichtes Parsing durch, um eine „Vorschau“ zu erstellen, ohne Daten zu committen:
- Header erkennen und eine Stichprobe der Zeilen anzeigen (z. B. erste 20–100)
- Gängige Encodings (UTF‑8, UTF‑16) und Trennzeichen (Komma, Tab, Semikolon) handhaben
- Neue Zeilen normalisieren und offensichtliche Formatierungsprobleme trimmen
Diese Vorschau treibt spätere Schritte wie Spalten‑Mapping und Validierung.
Originaldatei für Replay speichern
Speichern Sie immer die Originaldatei sicher (Object Storage ist typisch). Halten Sie sie unveränderlich, damit Sie:
- den Import neu starten können, wenn sich Validierungsregeln ändern
- Bugs mit exakt dem gleichen Input untersuchen können
- eine „Original herunterladen“‑Option in der Import‑Historie anbieten können
Behandeln Sie jeden Upload als erstklassigen Datensatz. Speichern Sie Metadaten wie Uploader, Timestamp, Quellsystem, Dateiname und Checksumme (zur Duplikat‑Erkennung und Integritätsprüfung). Das ist für Auditability und Debugging extrem wertvoll.
Pre‑Checks, bevor Nutzer Zeit investieren
Führen Sie schnelle Vorprüfungen sofort aus und schlagen Sie früh fehl, wenn nötig:
- Dateityp‑ und Größenlimits
- Grundlegende Lesbarkeit (kann es geparst werden?)
- Erforderliche Spalten vorhanden (je nach Importtyp)
Wenn ein Pre‑Check fehlschlägt, geben Sie eine klare Meldung zurück und zeigen, was zu beheben ist. Ziel ist es, wirklich schlechte Dateien schnell zu blockieren—ohne valide, aber unperfekte Daten abzulehnen, die später gemappt und bereinigt werden können.
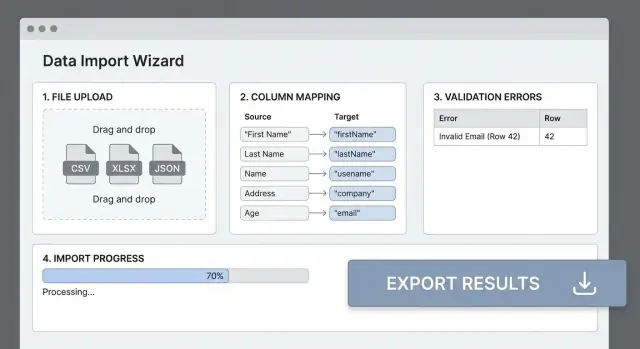
Die meisten Importfehler entstehen dadurch, dass Header der Datei nicht zu den Feldern Ihrer App passen. Ein klarer Spalten‑Mapping‑Schritt macht „messy CSV“ in vorhersehbaren Input und spart Nutzern Trial‑and‑Error.
Eine Mapping‑UI, die Menschen verstehen
Zeigen Sie eine einfache Tabelle: Quellspalte → Zielfeld. Erkennen Sie wahrscheinliche Treffer automatisch (case‑insensitive Header‑Matching, Synonyme wie „E‑mail“ → email), lassen Sie Nutzer aber immer überschreiben.
Fügen Sie ein paar QoL‑Funktionen hinzu:
- Pflicht‑Zielfelder kennzeichnen und anzeigen, ob sie gemappt sind
- „Diese Spalte ignorieren“ für irrelevante Daten erlauben
- Unmapped‑Spalten hervorheben, damit Nutzer nichts übersehen
Gespeicherte Mapping‑Templates (pro Kunde oder Datensatz)
Wenn Kunden dasselbe Format jede Woche importieren, machen Sie es mit einem Klick möglich. Lassen Sie sie Vorlagen speichern, die scoped sind für:
- ein Kundenkonto
- einen Datensatztyp (z. B. Kontakte vs. Rechnungen)
- optional ein bestimmtes Integration/Quellsystem
Wenn eine neue Datei hochgeladen wird, schlagen Sie eine Vorlage basierend auf Spaltenüberlappung vor. Unterstützen Sie auch Versionierung, damit Nutzer eine Vorlage aktualisieren können, ohne ältere Runs zu brechen.
Fügen Sie leichte Transformationen pro gemapptem Feld hinzu:
- Leerzeichen trimmen; leere Strings → null
- Datumsparsing (MM/DD/YYYY vs. DD.MM.YYYY) mit Zeitzonenoptionen
- Währungsnormalisierung (z. B. “$1,200.00” → 1200.00 + Währung)
- Enums (z. B. “Active”, “enabled”, “1” → ACTIVE)
- Spalten teilen/zusammenführen (Full Name → Vorname/Nachname oder umgekehrt)
Halten Sie Transformationen im UI explizit („Angewendet: Trim → Parse Date“), damit das Ergebnis erklärbar bleibt.
Vorschau bevor Sie committen
Bevor Sie die gesamte Datei verarbeiten, zeigen Sie eine Vorschau der gemappten Ergebnisse (z. B. 20 Zeilen). Zeigen Sie den Originalwert, den transformierten Wert und Warnungen (z. B. „Datum konnte nicht geparst werden“). Hier fangen Nutzer Probleme früh ab.
Duplikate und Schlüssel erkennen
Bitten Sie Nutzer, ein Schlüsselfeld zu wählen (Email, external_id, SKU) und erklären Sie, was bei Duplikaten passiert. Selbst wenn Sie später Upserts machen, setzt dieser Schritt Erwartungen: Sie können auf Duplikatschlüssel in der Datei hinweisen und vorschlagen, welcher Datensatz „gewinnt“ (erste, letzte oder Fehler).
Das Validierungssystem entwerfen
Validierung macht den Unterschied zwischen einem „Datei‑Uploader“ und einem Import‑Feature, dem Leute vertrauen. Ziel ist nicht Strenge um der Strenge willen—sondern zu verhindern, dass schlechte Daten sich verbreiten, und den Nutzern klare, umsetzbare Rückmeldungen zu geben.
Validierung in Schichten trennen
Behandeln Sie Validierung als drei unterschiedliche Prüfungen mit verschiedenen Zwecken:
- Schema‑Validierung (Typen & Pflichtfelder): „Ist
email ein String?“, „Ist amount eine Zahl?“, „Ist customer_id vorhanden?“ Schnell und kann sofort nach dem Parsen laufen.
- Business‑Regeln: „Betrag muss positiv sein“, „Status muss eine von Active/Paused sein“, „Startdatum darf nicht in der Vergangenheit liegen.“ Diese Regeln spiegeln Produktlogik wider.
- Cross‑Field und relationale Regeln: „Wenn
country=US, ist state Pflicht“, „end_date muss nach start_date liegen“, „Plan‑Name muss in diesem Workspace existieren.“ Diese benötigen oft Kontext (andere Spalten oder DB‑Lookups).
Diese Trennung macht das System erweiterbar und leichter im UI zu erklären.
Strenger vs. nachsichtiger Modus (und warum das zählt)
Entscheiden Sie früh, ob ein Import:
- Die ganze Datei fehlschlägt (strict): gut für Finanzdaten, Berechtigungen oder alles, wo partielle Updates riskant sind.
- Teilweise gültige Zeilen akzeptiert (lenient): gut für große Listen, bei denen Nutzer nur problematische Datensätze beheben wollen.
Sie können beides unterstützen: strict als Default und eine Option „Teilweisen Import erlauben“ für Admins.
Menschenfreundliche Fehler (mit Zeilen/Spalten‑Bezug)
Jeder Fehler sollte beantworten: was ist passiert, wo und wie behebe ich es?
Beispiel: „Zeile 42, Spalte ‚Start Date‘: muss ein gültiges Datum im Format YYYY‑MM‑DD sein."
Unterscheiden Sie:
- Errors: blockieren die Verarbeitung für diese Zeile (oder die ganze Datei im strict‑Modus)
- Warnings: zulässig, aber hervorgehoben (z. B. „Unbekannte Abteilung; bleibt leer“)
„Fix and re‑upload“‑Loops ermöglichen
Nutzer beheben selten alles in einem Durchgang. Machen Sie Nachuploads schmerzfrei, indem Sie Validierungsergebnisse an einen Importversuch binden und es Nutzern erlauben, eine korrigierte Datei erneut hochzuladen. Kombinieren Sie das mit herunterladbaren Fehlerberichten (siehe unten), damit Probleme in Bulk gelöst werden können.
Rules‑Engine: konfigurierbar, wo nötig; code‑only, wo sicherer
Ein praktischer Ansatz ist hybrid:
- Konfigurierbare Regeln für tenant‑spezifische Anforderungen (z. B. „Mitarbeiter‑ID muss innerhalb dieses Workspaces eindeutig sein“).
- Code‑definierte Regeln für Kern‑Produktinvarianten (z. B. Berechtigungsgrenzen, erforderliche Beziehungen), um Fehlkonfigurationen zu vermeiden.
So bleibt Validierung flexibel, ohne in ein schwer zu debuggendes Einstellungs‑Labyrinth zu verwandeln.
Zuverlässige Verarbeitung und Retries implementieren
Prototyp Ihres Import-Assistenten
Beschreiben Sie Ihren Importablauf im Chat und erhalten Sie schnell ein funktionierendes React- und Go-Gerüst.
Importe scheitern oft an banalen Gründen: langsame DB, spikes bei Datei‑Uploads oder eine einzelne „schlechte“ Zeile, die den ganzen Batch blockiert. Zuverlässigkeit bedeutet meist, schwere Arbeit aus dem Request/Response‑Pfad zu verschieben und jeden Schritt sicher wiederholbar zu machen.
Hintergrundjobs für große Dateien verwenden
Führen Sie Parsing, Validierung und Schreibvorgänge in Hintergrundjobs (Queues/Worker) aus, damit Uploads nicht in Web‑Timeouts laufen. Das erlaubt zudem, Worker unabhängig zu skalieren, wenn Kunden größere Tabellen importieren.
Ein praktisches Muster ist, Arbeit in Chunks zu teilen (z. B. 1.000 Zeilen pro Job). Ein „Parent“‑Import‑Job schedult Chunk‑Jobs, aggregiert Ergebnisse und aktualisiert den Fortschritt.
Klare States und Übergänge nachverfolgen
Modellieren Sie den Import als Zustandsmaschine, damit UI und Ops-Team immer wissen, was passiert:
- queued → running → completed
- queued/running → failed (mit Grund)
- queued/running → canceled (durch Nutzer oder System)
Speichern Sie Timestamps und Attempt‑Counts pro Übergang, damit Sie Fragen wie „wann hat es begonnen?“ und „wie viele Versuche gab es?“ ohne Log‑Graben beantworten können.
Fortschritt, dem Nutzer vertrauen kann
Zeigen Sie messbaren Fortschritt: verarbeitete Zeilen, verbleibende Zeilen und bisher gefundene Fehler. Wenn Sie Durchsatz schätzen können, fügen Sie eine grobe ETA hinzu—aber bevorzugen Sie „~3 Min“ statt präziser Countdown‑Angaben.
Verarbeitung idempotent machen (retry‑sicher)
Retries dürfen niemals Duplikate erzeugen oder Updates doppelt anwenden. Übliche Techniken:
- Verwenden Sie ein import_id plus row_number (oder Row‑Hash) als stabilen Idempotency‑Key.
- Upsert anhand eines natürlichen Schlüssels (z. B. external_id) statt „immer insert“.
- Schreiben Sie in Transaktionen pro Chunk, damit partielle Fehler den Zustand nicht korrupt machen.
Drosselung zum Schutz aller
Rate‑limiten Sie gleichzeitige Importe pro Workspace und drosseln Sie write‑schwere Schritte (z. B. max N rows/sec), um die Datenbank nicht zu überlasten und die Erfahrung anderer Nutzer nicht zu degradieren.
Fehlerberichte und Import‑Historie
Wenn Leute nicht verstehen, was schiefgelaufen ist, versuchen sie dieselbe Datei immer wieder, bis sie aufgeben. Behandeln Sie jeden Import als erstklassigen „Run“ mit klarer Audit‑Spur und umsetzbaren Fehlern.
Einen Import‑Run‑Datensatz erstellen
Erzeugen Sie eine Import‑Run Entität in dem Moment, in dem eine Datei eingereicht wird. Dieser Datensatz sollte das Wesentliche erfassen:
- Wer ihn initiiert hat (Benutzer + Organisation)
- Was importiert wurde (Dateiname, Größe, Checksumme, Entitätstyp)
- Wann es geschah (Start/End‑Timestamps)
- Wie es interpretiert wurde (verwendete Mapping‑Konfiguration, Transformations‑Version)
- Ergebnis (erfolgreich/fehlgeschlagen/teilweise, verarbeitete Zeilen, abgelehnte Zeilen)
Das wird Ihre Import‑Historie: eine einfache Liste von Runs mit Status, Zählern und einer „Details ansehen“‑Seite.
Row‑Level‑Fehler speichern (nicht nur Logs)
Application Logs sind gut für Entwickler, aber Nutzer brauchen abfragbare Fehler. Speichern Sie Fehler als strukturierte Records, idealerweise auf beiden Ebenen:
- Row‑Level: Zeilennummer, Primary Identifier (falls erkannt), Snapshot der Rohwerte
- Field‑Level: Spaltenname, Fehlercode (z. B. REQUIRED, INVALID_DATE), menschliche Meldung, Schweregrad
Mit dieser Struktur können Sie schnelles Filtern und Aggregat‑Insights wie „Top 3 Fehlerarten diese Woche“ anbieten.
Fehler nutzbar machen: UI + Download‑Report
Auf der Run‑Details‑Seite bieten Sie Filter nach Typ, Spalte und Schweregrad sowie eine Suche (z. B. „email“). Dann stellen Sie einen downloadbaren CSV‑Fehlerbericht bereit, der die Originalzeile plus zusätzliche Spalten wie error_columns und error_message enthält, mit klaren Anweisungen wie „Datumformat auf YYYY‑MM‑DD korrigieren."
Dry‑Run‑Modus hinzufügen
Ein Dry‑Run validiert alles mit demselben Mapping und denselben Regeln, schreibt aber nicht in die Datenbank. Ideal für Erstimporte und gibt Nutzern die Möglichkeit, sicher zu iterieren, bevor sie Änderungen bestätigen.
Datenmodell, Upserts und Auditability
Sorgenfrei iterieren
Führen Sie riskante Änderungen sicher durch mit Snapshots und Rollback, während Sie Validierungsregeln anpassen.
Importe sind „fertig“, sobald Zeilen in der DB landen—aber die langfristigen Kosten entstehen oft durch chaotische Updates, Duplikate und unklare Änderungsverläufe. Dieser Abschnitt behandelt das Design so, dass Importe vorhersehbar, reversibel und erklärbar sind.
Entscheiden: Erstellen, Aktualisieren oder beides
Definieren Sie für jede Entität, wie eine importierte Zeile auf Ihr Domänenmodell abgebildet wird. Entscheiden Sie, ob der Import:
- nur neue Datensätze erstellen darf
- nur vorhandene Datensätze aktualisieren darf
- beides erlaubt (häufig bei SaaS)
Diese Entscheidung sollte explizit in der Import‑Setup‑UI stehen und mit dem Import‑Job gespeichert werden, damit das Verhalten reproduzierbar ist.
Upsert‑Keys und Kollisionen festlegen
Wenn Sie „create or update“ unterstützen, brauchen Sie stabile Upsert‑Keys—Felder, die dasselbe Record jedes Mal identifizieren. Häufige Optionen:
external_id (ideal bei Daten aus anderen Systemen)- Email (funktioniert für Nutzer/Kontakte, kann sich aber ändern)
- Composite‑Keys (z. B.
account_id + sku)
Definieren Sie Kollisionsregeln: was passiert, wenn zwei Zeilen denselben Key teilen oder ein Key zu mehreren Records passt? Gute Defaults sind „Zeile fehlschlagen mit klarer Fehlermeldung“ oder „letzte Zeile gewinnt“, aber wählen Sie bewusst.
Transaktionen ohne die Welt zu sperren
Verwenden Sie Transaktionen dort, wo sie Konsistenz schützen (z. B. Parent und Children anlegen). Vermeiden Sie eine riesige Transaktion für eine 200k‑Zeilen Datei; das kann Tabellen sperren und Retries schwierig machen. Bevorzugen Sie chunked Writes (z. B. 500–2.000 Zeilen pro Batch) mit idempotenten Upserts.
Referential Integrity schützen
Importe sollten Beziehungen respektieren: wenn eine Zeile auf ein Parent‑Record verweist (z. B. Company), fordern Sie entweder dessen Existenz oder erstellen Sie es kontrolliert. Frühzeitiges Fehlschlagen mit „fehlendem Parent“‑Fehler verhindert halbverknüpfte Daten.
Alles auditieren, was Importe ändern
Fügen Sie Audit‑Logs für importgetriebene Änderungen hinzu: wer den Import ausgelöst hat, wann, Quell‑Datei und eine pro‑Record‑Zusammenfassung der Änderungen (alt vs. neu). Das erleichtert Support, schafft Vertrauen bei Nutzern und vereinfacht Rollbacks.
Exporte bauen, die skalieren
Exporte wirken simpel, bis Kunden versuchen, „alles“ kurz vor einer Deadline herunterzuladen. Ein skalierbares Export‑System sollte große Datensätze verarbeiten, ohne Ihre App zu verlangsamen oder inkonsistente Dateien zu produzieren.
Richtige Export‑Typen anbieten
Starten Sie mit drei Optionen:
- Full export: alles, worauf der Nutzer Zugriff hat.
- Gefilterter Export: respektiert die gleichen Filter/Suche aus der UI (Status, Datumsbereich, Owner usw.).
- Inkrementeller Export: „Änderungen seit X“ für Sync‑Jobs und Reporting‑Pipelines.
Inkrementelle Exporte sind besonders nützlich für Integrationen und reduzieren Last im Vergleich zu wiederholten Voll‑Dumps.
- CSV ist Default für Tabellenkalkulationen und Bulk‑Analysen.
- JSON ist ideal für eine Data Export API und Automatisierung.
- Excel nur wenn nötig (mehrere Sheets, reichhaltige Formatierung oder nicht‑technische Workflows).
Behalten Sie konsistente Header und stabile Spaltenreihenfolge bei, damit Downstream‑Prozesse nicht brechen.
Streamen und paginieren, um Memory‑Spikes zu vermeiden
Große Exporte sollten nicht alle Zeilen in den Speicher laden. Nutzen Sie Pagination/Streaming, um Zeilen zu schreiben, während Sie sie abrufen. Das verhindert Timeouts und hält Ihre Web‑App reaktiv.
Große Exporte asynchron erzeugen
Für große Datensätze generieren Sie Exporte in einem Hintergrundjob und benachrichtigen den Nutzer, wenn sie bereit sind. Ein übliches Muster:
- Nutzer fordert Export an.
- App queued einen Job.
- Job schreibt die Datei in Object Storage.
- UI zeigt einen Download‑Link und speichert ihn in der Export‑Historie.
Das passt gut zu Ihren Hintergrundjobs für Importe und zum gleichen „Run‑Historie + Download‑Artefakt“‑Muster, das Sie für Fehlerberichte nutzen.
Exporte werden oft auditiert. Fügen Sie immer hinzu:
- Eine klare Zeitzonenpolitik (z. B. in UTC speichern, im Export in der Zeitzone des Nutzers ausgeben).
- Konsistente Datumsformate (ISO‑8601 für JSON; explizite Formate für CSV/Excel).
- Einen „generated at“ Timestamp und bei inkrementellen Exporten den verwendeten Cutoff.
Diese Details reduzieren Verwirrung und unterstützen zuverlässige Reconciliation.
Sicherheit, Berechtigungen und Datenschutz
Importe und Exporte sind mächtige Features, weil sie schnell große Datenmengen bewegen können. Das macht sie auch zu einer häufigen Quelle für Sicherheitsbugs: eine zu großzügige Rolle, ein geleakter File‑URL oder eine Log‑Zeile mit personenbezogenen Daten.
Authentifizierung: wählen Sie, was zur Nutzung passt
Nutzen Sie die gleiche Authentifizierung wie im Rest der App—erschaffen Sie keinen speziellen Auth‑Pfad nur für Importe.
Wenn Nutzer im Browser arbeiten, passt session‑basierte Auth (plus optional SSO/SAML). Wenn Importe/Exporte automatisiert sind (nächtliche Jobs, Integrationspartner), erwägen Sie API‑Keys oder OAuth‑Tokens mit klarer Scope und Rotation.
Praktische Regel: UI und Import‑API sollten dieselben Berechtigungen durchsetzen, auch wenn verschiedene Audiencen sie nutzen.
Rollenbasierte Zugriffe: wer darf was?
Behandeln Sie Import/Export‑Fähigkeiten als explizite Privilegien. Gängige Rollen:
- Kann importieren (Dateien hochladen, Importe ausführen)
- Kann exportieren (Exporte erzeugen und herunterladen)
- Kann Historie sehen (Import‑Runs, Fehler, Zählungen ansehen)
- Kann Dateien herunterladen (Originaluploads, Fehlerberichte)
Machen Sie „Dateien herunterladen“ zu einer separaten Berechtigung. Viele Leaks passieren, weil jemand Runs sehen kann und das System annimmt, er dürfe auch die Original‑Tabelle herunterladen.
Berücksichtigen Sie auch Row‑Level oder Tenant‑Level Grenzen: ein Nutzer sollte nur Daten für das Konto/Workspace importieren/exportieren können, dem er angehört.
Sensible Daten Ende‑zu‑Ende schützen
Für gespeicherte Dateien (Uploads, generierte Fehler‑CSVs, Export‑Archive) nutzen Sie privaten Object Storage und kurzlebige Download‑Links. Verschlüsseln Sie at rest, wenn es Ihre Compliance erfordert, und seien Sie konsistent: Originalupload, verarbeitete Staging‑Datei und generierte Reports sollten alle denselben Regeln folgen.
Seien Sie vorsichtig mit Logs. Redigieren Sie sensible Felder (Emails, Telefonnummern, IDs, Adressen) und loggen Sie Rohzeilen nicht standardmäßig. Wenn Debugging nötig ist, sperren Sie „verbose row logging“ hinter admin‑only Einstellungen und stellen Sie sicher, dass solche Logs ablaufen.
Uploads vor der Verarbeitung validieren und scannen
Behandeln Sie jeden Upload als untrusted Input:
- Erzwingen Sie Dateityp‑Checks (nicht nur anhand des Dateinamens)
- Setzen Sie Größenlimits, um DoS und versehentlich riesige Uploads zu verhindern
- Erwägen Sie Malware‑Scans, wenn Ihr Risikoprofil oder Ihre Branche es erfordert
Validieren Sie Struktur früh: lehnen Sie offenkundig malformed Dateien ab, bevor sie Hintergrundjobs erreichen, und geben Sie dem Nutzer klare Hinweise, was falsch ist.
Audit‑Trails für sicherheitsrelevante Ereignisse
Protokollieren Sie Ereignisse, die Sie in einer Untersuchung brauchen würden: wer eine Datei hochgeladen hat, wer einen Import gestartet hat, wer einen Export heruntergeladen hat, Berechtigungsänderungen und fehlgeschlagene Zugriffsversuche.
Audit‑Einträge sollten Actor, Timestamp, Workspace/Tenant und das betroffene Objekt (Import‑Run‑ID, Export‑ID) enthalten, ohne sensible Zeilendaten zu speichern. Das ergänzt Ihre Import‑Historie‑UI und hilft schnell zu beantworten: „wer hat was wann geändert?"
Tests, Monitoring und Operability
Skalierbare Exporte erstellen
Erzeugen Sie CSV‑ und JSON‑Exportendpunkte sowie große Exportjobs im selben Projekt.
Wenn Importe/Exporte Kundendaten berühren, bekommen Sie früher oder später Edge‑Cases: seltsame Encodings, zusammengeführte Zellen, halbgefüllte Zeilen, Duplikate und „es funktionierte gestern noch“‑Rätsel. Operability verhindert, dass daraus Support‑Albträume werden.
Tests, die reale Dateien spiegeln
Starten Sie mit fokussierten Tests rund um die ausfallanfälligsten Teile: Parsing, Mapping und Validierung.
- Parsing‑Tests: Nutzen Sie eine kleine Menge repräsentativer CSV/XLSX‑Fixtures (verschiedene Trennzeichen, Datumsformate, leere Spalten, große Zahlen, UTF‑8 vs. Windows‑1252). Prüfen Sie Zeilenzahlen und dass Schlüsselfelder konsistent geparst werden.
- Mapping + Transformation‑Tests: Gegeben ein Input‑Spaltenset, prüfen Sie, ob die App richtig auf interne Felder mapped und Transformationen anwendet (Trim, Case‑Normalisierung, Währungs/Prozent‑Konversion).
- Validierungsregel‑Tests: Für jede Regel (required, unique, range, foreign‑key existence) fügen Sie „good“ und „bad“ Zeilen hinzu und asserten genaue Fehlercodes/Messages.
Fügen Sie dann mindestens einen End‑to‑End‑Test für den kompletten Flow hinzu: Upload → Hintergrundverarbeitung → Report‑Generierung. Diese Tests fangen Contract‑Mismatch zwischen UI, API und Workers (z. B. fehlende Mapping‑Konfiguration im Job‑Payload).
Monitoring, das beantwortet „was ist kaputt?“
Tracken Sie Signale, die Nutzererfahrung widerspiegeln:
- Job‑Fehler (Anzahl und Rate)
- Verarbeitungszeit (p50/p95)
- Validierungsfehlerrate (plötzliche Sprünge deuten oft auf Template‑Änderungen hin)
- Queue‑Tiefe und Worker‑Throughput
Verdrahten Sie Alerts auf Symptome (steigende Fehler, wachsende Queue‑Tiefe) statt auf jede Exception.
Geben Sie internen Teams ein kleines Admin‑Surface, um Jobs neu zu starten, hängende Importe abzubrechen und Fehler zu inspizieren (Input‑File‑Metadaten, verwendetes Mapping, Fehlerzusammenfassung und Link zu Logs/Traces).
Für Nutzer reduzieren Sie vermeidbare Fehler mit Inline‑Hinweisen, herunterladbaren Sample‑Templates und klaren nächsten Schritten in Fehlerbildschirmen. Halten Sie eine zentrale Hilfeseite bereit und verlinken Sie sie aus der Import‑UI (z. B. /docs).
Deployment, Rollout und zukünftige Verbesserungen
Ein Import/Export‑System zu liefern ist mehr als „push to production“. Behandeln Sie es wie ein Produktfeature mit sicheren Defaults, klaren Recovery‑Pfaden und Raum zur Weiterentwicklung.
Umgebungen: dev, staging, prod
Richten Sie getrennte dev/staging/prod Umgebungen mit isolierten Datenbanken und separaten Object Storage Buckets (oder Prefixes) für Uploads und Exporte ein. Nutzen Sie unterschiedliche Verschlüsselungs‑Keys und Credentials pro Umgebung und sorgen Sie dafür, dass Background‑Worker auf die richtigen Queues zeigen.
Staging sollte Produktion spiegeln: gleiche Job‑Concurrency, Timeouts und Dateigrößenlimits. Dort validieren Sie Performance und Berechtigungen ohne Risiko für echte Kundendaten.
Migrationen und versionierte Templates
Importe leben oft „für immer“, weil Kunden alte Tabellen aufbewahren. Nutzen Sie DB‑Migrationen wie üblich, aber versionieren Sie auch Ihre Import‑Templates (und Mapping‑Presets), damit ein Schema‑Change nicht die CSV vom letzten Quartal bricht.
Eine praktische Vorgehensweise ist, template_version mit jedem Import‑Run zu speichern und Abwärtskompatibilitätscode für ältere Versionen so lange zu behalten, bis Sie sie deprecatieren können.
Rollout‑Strategie mit Feature‑Flags
Nutzen Sie Feature‑Flags, um Änderungen sicher auszurollen:
- Neue Validierungsregeln (zuerst nur als Warnung, dann als Fehler)
- Neue Exportformate (z. B. JSON zusätzlich zu CSV)
- Neue Mapping‑Optionen (z. B. „Full name“ splitten)
Flags erlauben es, mit internen Nutzern oder einer kleinen Kundengruppe zu testen, bevor Sie Features breit aktivieren.
Support‑Workflows und Diagnose
Dokumentieren Sie, wie der Support Fehler untersucht, mithilfe Ihrer Import‑Historie, Job‑IDs und Logs. Eine einfache Checkliste hilft: Template‑Version bestätigen, erste fehlerhafte Zeile prüfen, Storage‑Zugriff prüfen, dann Worker‑Logs durchsehen. Verlinken Sie das in Ihrem internen Runbook und, wo sinnvoll, in Ihrer Admin‑UI (z. B. /admin/imports).
Nächste Schritte: Integrationen
Sobald der Kernworkflow stabil ist, erweitern Sie ihn über reinen Upload hinaus:
- API‑basierte Importe für automatisierte Pipelines
- Webhooks für „Import fertig“ oder „Export bereit“ Events
- Connectoren für gängige Tools (Google Sheets, S3, Snowflake)
Diese Erweiterungen reduzieren manuelle Arbeit und machen Ihre Datenimport‑Web‑App in den bestehenden Prozessen der Kunden natürlicher.
Wenn Sie das als Produktfeature bauen und die Zeit bis zur „ersten nutzbaren Version“ verkürzen möchten, erwägen Sie Koder.ai, um den Import‑Wizard, Job‑Status‑Seiten und Run‑Historie End‑to‑End zu prototypen und dann den Source‑Code für einen konventionellen Engineering‑Workflow zu exportieren. Dieser Ansatz ist besonders praktisch, wenn Zuverlässigkeit und Iterationsgeschwindigkeit wichtiger sind als pixelgenaue UI‑Perfektion am ersten Tag.