Kläre den Eskalations-Workflow und die Ziele
Bevor du Bildschirme baust oder Code schreibst, entscheide, wofür deine App ist und welches Verhalten sie durchsetzen soll. Eskalationen sind nicht nur „verärgerte Kunden“ — es sind Tickets, die schnellere Bearbeitung, höhere Sichtbarkeit und engere Koordination erfordern.
Was zählt als Eskalation?
Definiere Eskalationskriterien in klarer Sprache, damit Agenten und Kunden nicht raten müssen. Häufige Auslöser sind:
- Ein Ausfall oder starke Leistungsverschlechterung
- Ein VIP- oder vertraglich geregelter „Priority Support“-Kunde
- Eine drohende SLA-Verletzung (oder wiederholte Verstöße)
- Ein sicherheits-, abrechnungs- oder rechtlich relevanter Vorfall
Definiere auch, was keine Eskalation ist (z. B. How-to-Fragen, Feature-Requests, kleinere Bugs) und wie diese Anfragen stattdessen geroutet werden sollen.
Rollen und Verantwortlichkeiten
Liste die Rollen auf, die dein Ablauf benötigt, und was jede Rolle tun kann:
- Agent: triagiert und löst, aktualisiert das Ticket, folgt Playbooks
- Lead: überprüft Eskalationen, weist neu zu, genehmigt Prioritätsänderungen
- Manager: verantwortet Reporting, Kundenkommunikationsstandards und Eskalationsrichtlinien
- On-call: erhält dringende Alerts und übernimmt außerhalb der Geschäftszeiten sofort die Verantwortung
- Customer admin: reicht Tickets ein und verfolgt sie, fügt interne Stakeholder hinzu
Schreibe auf, wer das Ticket in jedem Schritt besitzt (einschließlich Übergaben) und was „Besitz“ bedeutet (Antwortanforderung, nächster Update-Zeitpunkt und Befugnis zu eskalieren).
Kanäle, die zuerst unterstützt werden sollten
Beginne mit einer kleinen Menge von Eingangsquellen, damit du schneller liefern kannst und die Triage konsistent bleibt. Viele Teams starten mit E-Mail + Webformular und fügen Chat hinzu, sobald SLAs und Routing stabil sind.
Ziele und Erfolgskriterien
Wähle messbare Ergebnisse, die die App verbessern soll:
- First response time (gesamt und für Eskalationen)
- Resolution time oder Time-to-mitigation für Vorfälle
- Reopen-Rate und Anzahl der „nachgefragten Updates"
- Missed SLA rate und Zeit, die Tickets unbesetzt waren
Diese Entscheidungen werden zu deinen Produktanforderungen für den weiteren Build.
Entwirf das Datenmodell für Tickets, SLAs und Eskalationen
Eine Prioritätssupport-App lebt oder stirbt mit ihrem Datenmodell. Wenn die Grundlagen stimmen, werden Routing, Reporting und SLA-Durchsetzung einfacher — weil das System die nötigen Fakten hat.
Beginne mit den Ticket-„Basics“ (was Agenten immer wissen müssen)
Mindestens sollte jedes Ticket erfassen: Requester (ein Kontakt), Company (Kundenkonto), Betreff, Beschreibung und Anhänge. Behandle die Beschreibung als ursprüngliche Problemstellung; spätere Updates gehören in Kommentare, damit du sehen kannst, wie sich die Geschichte entwickelt hat.
Füge eskalationsspezifische Felder hinzu (was das Ticket „prioritär“ macht)
Eskalationen brauchen mehr Struktur als allgemeiner Support. Übliche Felder sind Severity (wie schlimm), Impact (wie viele Nutzer/welcher Umsatz) und Priority (wie schnell geantwortet wird). Füge ein Affected service-Feld hinzu (z. B. Billing, API, Mobile App), damit die Triage schnell routen kann.
Für Deadlines speichere explizite Fälligkeitszeitpunkte (wie „first response due“ und „resolution/next update due“), nicht nur einen „SLA-Namen“. Das System kann diese Zeitstempel berechnen, aber Agenten sollten die genauen Zeiten sehen.
Modelliere Beziehungen für echte Arbeit
Ein praktisches Modell enthält üblicherweise:
- Customers → viele Contacts
- Customers → viele Tickets
- Tickets → viele Comments (intern + öffentlich)
- Tickets → viele Tasks (Checklistenpunkte, Follow-ups)
Das hält die Zusammenarbeit sauber: Gespräche in Comments, Aktionspunkte in Tasks und Ownership am Ticket.
Definiere Statuszustände (und halte sie konsistent)
Benutze eine kleine, stabile Statusauswahl wie: New, Triaged, In Progress, Waiting, Resolved, Closed. Vermeide „fast gleiche“ Status — jeder zusätzliche Zustand macht Reporting und Automatisierung weniger zuverlässig.
Entscheide, was für Audits unveränderlich sein muss
Für SLA-Tracking und Verantwortlichkeit sollten einige Daten append-only sein: created/updated Timestamps, Status-Change-Historie, SLA-Start/Stop-Ereignisse, Eskalationsänderungen und wer jede Änderung vorgenommen hat. Bevorzuge ein Audit-Log (oder Event-Tabelle), damit du rekonstruieren kannst, was passiert ist, ohne zu raten.
Lege Prioritätsstufen und SLA-Regeln fest
Priorität und SLA-Regeln sind der „Vertrag“, den deine App durchsetzt: was zuerst bearbeitet wird, wie schnell und wer verantwortlich ist. Halte das Schema einfach, dokumentiere es klar und mache es schwer, es ohne Grund zu überschreiben.
Ein einfaches Prioritätsschema (P1–P4)
Verwende vier Stufen, damit Agenten schnell klassifizieren und Manager konsistent reporten können:
- P1 — Kritischer Ausfall / schwerwiegender Impact: Das Produkt ist ausgefallen, es kommt zu Datenverlust oder ein Sicherheitsvorfall wird vermutet. Mehrere Nutzer oder ein ganzer Kundenaccount sind blockiert.
- P2 — Grobe Degradierung: Kernfunktionen sind teilweise gestört, Workarounds sind begrenzt und der Geschäftseinfluss ist hoch, aber nicht total.
- P3 — Standardproblem: Ein einzelner Nutzer oder eine nicht-kritische Funktion ist betroffen. Ein Workaround existiert. Viele Tickets sollten hier landen.
- P4 — Geringe Dringlichkeit / Anfragen: How-to-Fragen, kleinere Bugs, Feature-Requests, Abrechnungsfragen, die die Nutzung nicht blockieren.
Definiere im UI „Impact“ (wie viele Nutzer/Kunden) und „Urgency“ (wie zeitkritisch), um Fehlkennzeichnungen zu reduzieren.
Definiere SLAs nach Plan, Kundentier und Priorität
Dein Datenmodell sollte es erlauben, SLAs nach Kundenplan/Tier (z. B. Free/Pro/Enterprise) und Priority zu variieren. Typischerweise verfolgst du mindestens zwei Timer:
- First response SLA (Zeit bis zur Bestätigung und Übernahme)
- Resolution SLA oder Next-update SLA (Zeit bis zur Lösung oder einem sinnvollen Update)
Beispiel: Enterprise + P1 verlangt vielleicht eine erste Antwort in 15 Minuten, während Pro + P3 8 Geschäfts-Stunden haben könnte. Halte die Regeln für Agenten sichtbar und verlinke sie von der Ticket-Seite.
Support-SLAs hängen oft davon ab, ob ein Plan 24/7-Abdeckung beinhaltet.
- Für Business-hours SLAs speichere einen Arbeitsplan (Zeitzone, Wochentage, Start-/Endzeiten).
- Für 24/7 SLAs läuft die Uhr immer.
- Füge einen Feiertagskalender hinzu (falls nötig pro Region), damit Timer nicht an Tagen „verpassen“, an denen niemand arbeiten sollte.
Zeige dem Ticket sowohl „SLA verbleibend“ als auch den verwendeten Plan an (damit Agenten dem Timer vertrauen).
SLA-Pausen, „Waiting on customer“ und Umgang mit Verstößen
Echte Workflows brauchen Pausen. Eine gängige Regel: Pause der SLA, wenn das Ticket Waiting on customer (oder Waiting on third party) ist, und Fortsetzen, wenn der Kunde antwortet.
Sei explizit in Bezug auf:
- Welche Status welche SLA-Timer pausieren
- Ob Pausen für Response-SLA, Resolution-SLA oder beide gelten
- Was bei einem Breach passiert (z. B. Auto-Eskalation der Priorität, Paging der On-call, Benachrichtigung eines Managers, Tag „SLA Breached")
Vermeide stille Verstöße. Der Umgang mit Breaches sollte ein sichtbares Ereignis in der Ticket-Historie erzeugen.
Wer wird vor/nach einem Breach alarmiert
Lege mindestens zwei Alert-Schwellen fest:
- Pre-breach warning (z. B. 50% und 80% des SLA-Verbrauchs): informiere den Ticket-Owner und den Team-Kanal
- Breach alert: benachrichtige On-call (für P1/P2), Team-Lead und optional Customer Success für High-Tier-Konten
Route Alerts basierend auf Priority und Tier, damit Leute nicht wegen P4-Lärm gepaged werden. Wenn du mehr Details willst, verknüpfe diesen Abschnitt mit deinen On-Call-Regeln in /blog/notifications-and-on-call-alerting.
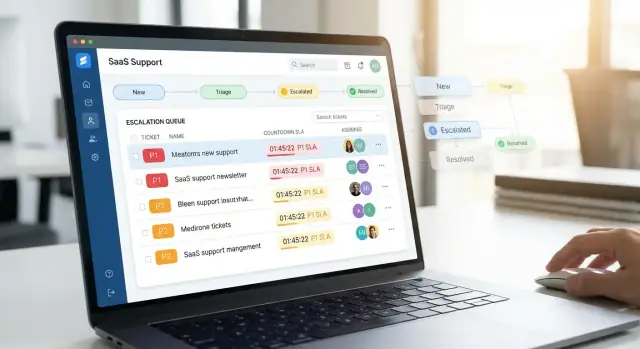
Baue Triage-, Routing- und Ownership-Logik
Triage und Routing sind der Punkt, an dem eine Prioritätssupport-App entweder Zeit spart oder Verwirrung stiftet. Ziel: Jede neue Anfrage sollte schnell am richtigen Ort landen, mit klarer Zuständigkeit und offensichtlichem nächsten Schritt.
Erstelle eine Triage-Inbox, der Agenten vertrauen können
Beginne mit einer dedizierten Triage-Inbox für unassigned oder needs-review Tickets. Halte sie schnell und voraussagbar:
- Standard-Sortierung nach Dringlichkeitssignalen (Priority, SLA-Fälligkeitszeit, Kundentier)
- Filter für Produktbereich, Region/Zeitzone, Kanal (E-Mail/Chat/Web) und „VIP“-Accounts
- Eine Ansicht „No owner / No category“, die Datenqualitätslücken hervorhebt
Eine gute Inbox minimiert Klicks: Agenten sollten Tickets aus der Liste heraus claimen, umleiten oder eskalieren können, ohne jedes Ticket zu öffnen.
Definiere Routing-Regeln (und halte sie erklärbar)
Routing sollte regelbasiert, aber für Nicht-Engineers lesbar sein. Übliche Eingaben:
- Product area (vom Benutzer ausgewählt, aus dem Formular erkannt oder aus Tags inferiert)
- Keywords im Betreff/Body (z. B. „outage“, „invoice“, „SSO")
- Customer tier (standard vs. priority)
- Region (zur Route an zeitzonennahe Teams)
Speichere das „Warum" jeder Routing-Entscheidung (z. B. „Matched keyword: SSO → Auth team"). Das macht Streitfälle leicht zu klären und verbessert Training.
Manueller Override und Eskalationspfade
Selbst die besten Regeln brauchen einen Ausweg. Erlaube autorisierten Nutzern, Routing zu überschreiben und Eskalationspfade wie auszulösen:
Agent → Team lead → On-call
Overrides sollten einen kurzen Grund erfordern und einen Audit-Eintrag erzeugen. Wenn du später On-Call-Alerting verknüpfst, verbinde Eskalationsaktionen damit (siehe /blog/notifications-and-on-call-alerting).
Dedupe und Verknüpfen verwandter Arbeit
Doppelte Tickets verschwenden SLA-Zeit. Füge leichte Werkzeuge hinzu:
- Vorschläge für mögliche Duplikate basierend auf Kunde + ähnlichem Betreff + Zeitfenster
- Ermögliche Agenten, Tickets zu verlinken zu einem Parent-Incident („related to INC-123")
Verknüpfte Tickets sollten Status-Updates und öffentliche Mitteilungen vom Parent erben.
Ownership-Regeln: ein Name, eine Queue
Definiere klare Ownership-Zustände:
- Single assignee (eine verantwortliche Person)
- Team queue (unassigniert innerhalb eines Teams; nutze, wenn Handoffs häufig sind)
- Handoff (explizite Übergabe mit Notizen und ggf. neuem SLA-Checkpoint)
Zeige Ownership überall: List-View, Ticket-Header und Activity-Log. Wenn jemand fragt „Wer hat das?", sollte die App sofort antworten.
Erstelle ein Support-Dashboard, das Agenten schnell nutzen können
Eine Prioritätssupport-App wird in den ersten 10 Sekunden benutzt — hier entscheidet sich Erfolg oder Misserfolg. Das Dashboard sollte drei Fragen sofort beantworten: was braucht jetzt Aufmerksamkeit, warum, und was kann ich als Nächstes tun.
Wichtige Ansichten, die Agenten wirklich nutzen
Beginne mit einer kleinen Menge hochnützlicher Ansichten statt einem Labyrinth an Tabs:
- Queue (Worklist): Standardansicht mit Filtern für Priority, SLA-Status, Kanal, Produktbereich und Assignee
- Ticket-Detail: mit einem Klick geöffnet, mit Kontext und Aktionen above the fold
- Customer-Profil: kompakte Ansicht von Account-Tier, jüngsten Eskalationen, aktiven Vorfällen und wichtigen Kontakten
- SLA-Board: zeitbasierte Ansicht, die hervorhebt, was bald bricht, nicht nur was bereits spät ist
Visuelle Hinweise, die kognitive Last reduzieren
Nutze klare, konsistente Signale, damit Agenten nicht jede Zeile lesen müssen:
- Priority-Chips (P1–P4) mit zugänglicher Farbe + Text (niemals nur Farbe)
- SLA-Countdown (z. B. „45m to first response") und ein „Breach risk“-Indikator
- Blocker-Badges (Waiting on customer, Waiting on engineering, Needs approval), damit blockierte Arbeit sichtbar ist
Halte die Typografie einfach: eine primäre Akzentfarbe und eine enge Hierarchie (Title → Customer → Status/SLA → letzte Aktualisierung).
Schnelle Aktionen und Triage-Geschwindigkeit
Jede Ticket-Zeile sollte schnelle Aktionen unterstützen, ohne die volle Seite zu öffnen:
- Assign / reassign, escalate, change priority, request info, set blocker, add internal note.
Füge Bulk-Aktionen (assign, close, apply tag, set blocker) hinzu, um Backlogs schnell zu bereinigen.
Tastatur, Zugänglichkeit und „keine Überraschungen"
Unterstütze Tastaturkürzel für Power-User: / zum Suchen, j/k zum Navigieren, e zum Eskalieren, a zum Zuweisen, g dann q zum Zurück zur Queue.
Für Barrierefreiheit: sorge für ausreichenden Kontrast, sichtbare Fokuszustände, beschriftete Controls und screen-reader-freundliche Statustexte (z. B. „SLA: 12 minutes remaining"). Mache die Tabelle responsiv, sodass derselbe Flow auf kleineren Bildschirmen funktioniert, ohne kritische Felder zu verbergen.
Benachrichtigungen und On-Call-Alerting
SLAs in Code umsetzen
Implementiere P1–P4-Prioritäten, Geschäftszeiten und Pausenzustände mit klarer, testbarer Logik.
Benachrichtigungen sind das „Nervensystem" einer Prioritätssupport-App: sie verwandeln Ticket-Änderungen in zeitgerechte Aktionen. Ziel ist nicht mehr zu benachrichtigen — sondern die richtigen Personen, im richtigen Kanal, mit genug Kontext.
Ordne die Notification-Typen
Beginne mit einer klaren Menge von Ereignissen, die Nachrichten auslösen. Häufige, hochwertige Typen sind:
- Assignment: Ticket wird einer Person oder einem Team zugewiesen/neu zugewiesen
- Mention: Jemand @erwähnt einen Agenten in einer internen Notiz
- SLA warning: ein Ticket nähert sich First-Response- oder Resolution-Zielen
- SLA breach: ein Ziel wurde verfehlt (mit Grund, falls bekannt)
- Escalation: Priorität erhöht sich, Executive/Kunde wird hinzugefügt oder ein Incident wird ausgerufen
Jede Nachricht sollte Ticket-ID, Kundenname, Priority, aktuellen Owner, SLA-Timer und einen Deep-Link zum Ticket enthalten.
Wähle Kanäle ohne die Kontrolle zu verlieren
Nutze In-App-Benachrichtigungen für den Alltag und E-Mail für dauerhafte Updates und Handoffs. Für echte On-Call-Szenarien füge SMS/Push als optionalen Kanal hinzu, reserviert für dringende Ereignisse (wie P1-Eskalation oder unmittelbarer Breach).
Vermeide Alert-Fatigue
Alert-Fatigue zerstört Reaktionszeiten. Baue Kontrollen wie Gruppierung, Ruhezeiten und Deduplizierung ein:
- Gruppiere wiederholte SLA-Warnungen in einen Thread
- Dedupe „assignment changed"-Flut in kurzen Fenstern
- Respektiere quiet hours mit einer Ausnahme für kritische Incidents
Templates + Zustellungs-Historie
Stelle Templates für kundenorientierte Updates und interne Notizen bereit, damit Ton und Vollständigkeit konsistent bleiben. Verfolge Zustellstatus (sent, delivered, failed) und halte eine Benachrichtigungs-Timeline pro Ticket für Audit und Nachverfolgung. Ein einfaches „Notifications“-Tab auf der Ticket-Detail-Seite macht das prüfen leicht.
Ticket-Detail-Seite: Zusammenarbeit und Kommunikation
Die Ticket-Detail-Seite ist der Ort, an dem Eskalationsarbeit tatsächlich passiert. Sie sollte Agenten in Sekunden Kontext liefern, Zusammenarbeit mit Teamkollegen ermöglichen und fehlerfreie Kommunikation mit dem Kunden sicherstellen.
Trenne, was Kunden sehen, und was intern bleibt
Mach dem Composer die Wahl Customer Reply oder Internal Note deutlich, mit unterschiedlicher Stilgebung und einer klaren Vorschau. Interne Notizen sollten schnelles Formatieren, Links zu Runbooks und private Tags (z. B. „needs engineering") unterstützen. Kundenantworten sollten auf freundliche Templates voreingestellt sein und exakt zeigen, was gesendet wird.
Threaded Conversation + sichere Anhänge
Unterstütze einen chronologischen Thread mit E-Mails, Chat-Transkripten und Systemereignissen. Bei Anhängen priorisiere Sicherheit:
- Virenscans und Allow-Listen für Dateitypen
- Größenlimits und Ablauf-Download-Links
- Warnungen zur Redaktion sensibler Daten (Tokens, Passwörter)
Wenn du kundenbereitgestellte Dateien anzeigst, mach sichtbar, wer sie wann hochgeladen hat.
Makros, Quick Replies und gespeicherte Schritte
Füge Makros ein, die freigegebene Antworten plus Troubleshooting-Checklisten einfügen (z. B. „collect logs“, „restart steps", „status page wording"). Erlaube Teams, eine gemeinsame Makro-Bibliothek mit Versionierung zu pflegen, damit Eskalationen konsistent und compliant bleiben.
Eine Timeline wichtiger Ereignisse
Zeige neben Nachrichten eine kompakte Ereignistimeline: Statusänderungen, Priority-Updates, SLA-Pausen/Resumes, Assignee-Transfers und Eskalationsstufen. Das verhindert „Was hat sich geändert?"-Nachfragen und hilft bei Post-Incident-Reviews.
Ermögliche @mentions, Followers und verknüpfte Tasks (Engineering-Ticket, Incident-Doku). Mentions sollten nur die richtigen Personen benachrichtigen, und Follower sollten Zusammenfassungen bei materiellen Änderungen erhalten — nicht bei jedem Tastendruck.
Sicherheit, Datenschutz und Berechtigungen
Plane SLAs und Zuständigkeiten
Nutze den Planungsmodus, um Rollen, Status und SLA-Regeln zuzuordnen, bevor du Code generierst.
Sicherheit ist kein Feature für später: Eskalationen enthalten häufig Kunden-E-Mails, Screenshots, Logs und interne Notizen. Baue Schutzmechanismen früh ein, damit Agenten schnell arbeiten können, ohne Daten zu überschreiben oder Vertrauen zu verlieren.
Rollenbasiertes Zugriffskontrollmodell (RBAC), das echte Support-Arbeit abbildet
Beginne mit wenigen, einfach erklärbaren Rollen (z. B. Agent, Team Lead, On-Call Engineer, Admin). Definiere dann, was jede Rolle ansehen, bearbeiten, kommentieren, umverteilen und exportieren darf.
Ein praktischer Ansatz ist „default deny“:
- Eskalationssichtbarkeit: einschränken nach Team, Queue und Kundenkonto (z. B. nur Enterprise-Queue-Agenten sehen Enterprise-Eskalationen)
- Bearbeitungsrechte: Agents dürfen Status ändern und Notizen hinzufügen, SLA-Änderungen, Priority-Overrides und Eskalationsstornos beschränke auf Leads/Admins
- Sensitive Felder: behandle Kunden-PII (E-Mail, Telefon), Sicherheitslogs und Anhänge als separate Berechtigungen
Privacy by design: least-privilege-Defaults
Sammle nur, was dein Workflow braucht. Wenn du keine vollständigen Nachrichteninhalte oder ganze IP-Adressen brauchst, speichere sie nicht. Wenn Kundendaten gespeichert werden, mache klar, welche Felder Pflicht vs. optional sind, und vermeide unnötige Datenkopien aus anderen Systemen.
Für Zugriffsmodelle: gehe davon aus, dass „Support-Agenten nur das Minimum sehen sollten, um das Ticket zu lösen." Nutze Account- und Queue-Scoping bevor du komplexe Regeln hinzufügst.
Basics schützen: Authentifizierung, Sessions, CSRF
Nutze bewährte Authentifizierung (SSO/OIDC wenn möglich), erfordere starke Passwörter, wenn sie verwendet werden, und unterstütze Multi-Factor für erhöhte Rollen.
Härte Sessions ab:
- Secure, HttpOnly Cookies; kurze Session-Laufzeiten für Admin-Aktionen
- Rotation bei Login und Privilege-Changes
- CSRF-Schutz für zustandsändernde Requests
Secrets, Audit-Logs und sensibler Zugriff
Speichere Secrets in einem verwalteten Secret-Store (nicht im Source-Control). Logge Zugriff auf sensible Daten (wer eine Eskalation angesehen, einen Anhang heruntergeladen oder ein Ticket exportiert hat) und mache Audit-Logs manipulationssicher und durchsuchbar.
Aufbewahrung und Exporte (ohne zu viel zu versprechen)
Definiere Retention-Regeln für Tickets, Anhänge und Audit-Logs (z. B. Anhänge nach N Tagen löschen, Audit-Logs länger behalten). Biete Exporte für Kunden oder internes Reporting an, aber vermeide das Versprechen spezifischer Compliance-Zertifikate, es sei denn, du kannst sie nachweisen. Ein einfacher „Data Export“-Flow plus ein Admin-only „Delete Request“-Workflow ist ein guter Anfang.
Wähle Tech-Stack und Architektur
Deine Eskalations-App ist nur dann effektiv, wenn sie sich leicht ändern lässt. Eskalationsregeln, SLAs und Integrationen entwickeln sich ständig weiter, also priorisiere einen Stack, den dein Team warten kann.
Wähle einen Stack, der zu deinem Team passt
Wähle vertraute Tools statt „perfekter" Lösungen. Einige bewährte Kombinationen:
- React + Node.js (Express/NestJS): gut für hoch interaktive Dashboards und viel Echtzeit-UI
- Django (Python): starke Admin-Tools, schnelles CRUD-Development, ideal für workflow-lastige Apps
- Rails (Ruby): exzellente Konventionen, um Ticketing-ähnliche Produkte schnell zu bauen
Wenn du bereits einen Monolith anderswo hast, reduziert das Matching der Ökosysteme Einarbeitungszeit und Betriebskomplexität.
Wenn du schneller prototypen willst, ohne initial großen Engineering-Aufwand, kannst du den Workflow auch in einer vibe-coding Plattform wie Koder.ai prototypen — insbesondere Standardteile wie ein React-basiertes Agent-Dashboard, ein Go/PostgreSQL-Backend und die job-getriebene SLA-/Notification-Logik.
Datenspeicher: relational zuerst, Suche wo sie hilft
Für Kernobjekte — Tickets, Kunden, SLAs, Eskalationsereignisse, Zuweisungen — nutze eine relationale Datenbank (Postgres ist ein häufiger Default). Sie bietet Transaktionen, Constraints und reportingfreundliche Abfragen.
Für schnelles Suchen über Betreffzeilen, Konversationstexte und Kundennamen ergänze später einen Search-Index (z. B. Elasticsearch/OpenSearch). Halte das optional: starte mit Postgres Full-Text-Search und skaliere bei Bedarf.
Hintergrundjobs sind unverzichtbar
Eskalations-Apps hängen von zeitbasierten und Integrationsaufgaben ab, die nicht in Web-Requests laufen sollten:
- SLA-Timer und Breach-Checks
- Benachrichtigungen (E-Mail/SMS/Push)
- On-call Paging
- Synchronisation von E-Mails/Chats/CRM
Nutze eine Job-Queue (z. B. Celery, Sidekiq, BullMQ) und mache Jobs idempotent, damit Retries keine Duplikate erzeugen.
Definiere APIs früh und halte sie konsistent
Ob REST oder GraphQL: definiere Ressourcen-Grenzen früh: tickets, comments, events, customers und users. Ein konsistenter API-Stil beschleunigt Integrationen und das UI. Plane auch Webhook-Endpunkte (Signing-Secrets, Retries, Rate-Limits) von Anfang an ein.
Hosting und Umgebungen
Betreibe mindestens dev/staging/prod. Staging sollte Prod-Einstellungen widerspiegeln (E-Mail-Provider, Queues, Webhooks) mit sicheren Test-Credentials. Dokumentiere Deployment- und Rollback-Schritte und halte Konfiguration in Environment-Variablen — nicht im Code.
Integrationen: E-Mail, Chat, CRM und Webhooks
Integrationen machen deine Eskalations-App aus „einem weiteren Ort zum Nachschauen" zum System, in dem Teams tatsächlich arbeiten. Starte mit den Kanälen, die Kunden bereits nutzen, und füge Automatisierungs-Hooks hinzu, damit andere Tools auf Eskalationsereignisse reagieren können.
E-Mail: Inbound-Parsen, Outbound, Threading
E-Mail ist meist die wirkungsvollste Integration. Unterstütze Inbound-Forwarding (z. B. support@) und parse:
- From/To/Cc, Subject, Body (bevorzuge Plain-Text-Fallback) und Anhänge
- Message-ID und In-Reply-To für Threading
- Kunden-Domain und Signatur-Hints für Contact-Discovery
Für Outbound: sende aus dem Ticket (Reply/Forward) und erhalte Threading-Header bei, damit Antworten zum selben Ticket zurücklaufen. Speichere eine saubere Konversationstimeline: zeige, was der Kunde gesehen hat, nicht interne Notizen.
Bei Chat (Slack/Teams/Intercom-Widgets) halte es einfach: konvertiere ein Gespräch in ein Ticket mit klarem Transkript und Teilnehmern. Vermeide das automatische Synchronisieren jeder Nachricht — biete stattdessen einen „Attach last 20 messages"-Button, damit Agenten Lärm kontrollieren.
CRM-/Kundendaten-Synchronisation: Tier und Kontakte identifizieren
CRM-Sync macht „Priority Support" automatisch. Hole Firma, Plan/Tier, Account-Owner und Key-Contacts. Mappe CRM-Accounts auf deine Tenants, damit neue Tickets sofort Prioritätsregeln erben.
Webhooks für zentrale Ereignisse
Biete Webhooks für Events wie ticket.escalated, ticket.resolved und sla.breached. Liefere ein stabiles Payload (Ticket-ID, Zeitstempel, Severity, Customer-ID) und signe Requests, damit Empfänger die Authentizität prüfen können.
Dokumentiere und vereinfache das Setup
Füge einen kleinen Admin-Flow mit Test-Buttons hinzu („Send test email", „Verify webhook"). Halte Docs an einem Ort (z. B. /docs/integrations) und zeige gängige Troubleshooting-Schritte wie SPF/DKIM-Probleme, fehlende Threading-Header und CRM-Feldmapping.
Testing, Monitoring und Zuverlässigkeit
Kompensiere deine Entwicklungszeit
Erhalte Guthaben, indem du Inhalte über das Erstellen von Apps mit Koder.ai erstellst.
Eine Prioritätssupport-App wird zur „Quelle der Wahrheit" in angespannten Momenten. Wenn SLA-Timer driftet, Routing fehlgeht oder Berechtigungen Daten leaken, schwindet Vertrauen schnell. Behandle Zuverlässigkeit als Feature: teste, was zählt, messe, was passiert, und plane für Ausfälle.
Teste die Regeln, die Dringlichkeit steuern
Fokussiere automatisierte Tests auf Logik, die Ergebnisse beeinflusst:
- SLA-Berechnungen: Start/Stop-Bedingungen, Geschäftszeiten, Pausen, Breach-Schwellen und „next due"-Timestamps
- Routing und Ownership: Triage-Regeln, Round-Robin/Skill-basierte Zuweisung und Eskalations-Trigger
- Berechtigungen: RBAC für Queues, Ticket-Details, interne Notizen und kunden-sichtbare Nachrichten
Füge eine kleine End-to-End-Suite hinzu, die einen Agenten-Workflow nachbildet (Ticket erstellen → triagieren → eskalieren → lösen), um Annahmen zwischen UI und Backend zu validieren.
Seed-Daten und realistische Szenarien
Erzeuge Seed-Daten, die über Demos hinaus nützlich sind: ein paar Kunden, mehrere Tiers (standard vs. priority), unterschiedliche Prioritäten und Tickets in verschiedenen Zuständen. Schließe knifflige Fälle ein wie wiedereröffnete Tickets, „waiting on customer" und mehrere Assignees. Das macht Triage-Übungen sinnvoll und hilft QA, Edge-Cases schnell zu reproduzieren.
Observability: wissen, bevor Kunden es sagen
Instrumentiere die App so, dass du beantworten kannst: „Was ist fehlgeschlagen, bei wem und warum?"
- Error-Tracking für Exceptions in SLA-/Routing-Jobs
- Strukturierte Logs mit Ticket-IDs, Rule-IDs und Korrelations-IDs
- Performance-Monitoring für kritische Seiten und Background-Worker
Load-Tests und sichere Wiederherstellung
Führe Load-Tests für hochfrequentierte Views durch wie Queues, Search und Dashboards — besonders zu Schichtwechseln.
Bereite schließlich ein Incident-Playbook vor: Feature-Flags für neue Regeln, Rollback-Schritte für DB-Migrationen und ein klares Verfahren, um Automationen zu deaktivieren, während Agents weiterarbeiten können.
Launch-Plan, Reporting und Iteration
Eine Prioritätssupport-Web-App ist erst „fertig", wenn Agents ihr unter Druck vertrauen. Der beste Weg dahin ist klein starten, messen, wie es wirklich läuft, und in kurzen Schleifen iterieren.
Starte mit einem MVP, das den Workflow beweist
Widerstehe dem Drang, jedes Feature auszuliefern. Deine erste Version sollte den kürzesten Weg von „neuer Eskalation" zu „gelöst mit Verantwortlichkeit" abdecken:
- Eine Triage-Queue mit klarer Sortierung (Priority, SLA-Fällig, Kundentier)
- Eine Ticket-Detail-Seite für schnelle Updates und interne Notizen
- Sichtbare SLA-Timer (First response und Resolution/Next update, falls relevant)
- Basis-Alerts für drohende Breaches und Statusänderungen
Wenn du Koder.ai nutzt, passt diese MVP-Form gut zu den Defaults (React UI, Go-Services, PostgreSQL), und die Möglichkeit, Snapshots zu machen und zurückzurollen, kann beim Feintuning von SLA-Mathematik, Routing-Regeln und Berechtigungsgrenzen nützlich sein.
Pilot mit einem kleinen Team und wöchentliche Reviews
Rolle für einen Pilot-Betrieb an ein kleines Team aus (eine Region, eine Produktlinie oder eine On-Call-Rotation) und führe wöchentliche Feedback-Reviews durch. Halte sie strukturiert: was hat Agents verlangsamt, welche Daten fehlten, welche Alerts waren zu laut und wo ist Eskalationsmanagement gescheitert (Übergaben, unklare Ownership, Fehlrouting).
Eine praktische Taktik: pflege ein leichtgewichtiges Changelog in der App, damit Agents Verbesserungen sehen und sich gehört fühlen.
Füge Reporting hinzu, das Handlungen antreibt, keine Eitelkeitsmetriken
Sobald die Nutzung konsistent ist, führe Reports ein, die operative Fragen beantworten:
- SLA-Compliance: Breach-Rate nach Priority, Kundentier und Kanal
- Eskalationsvolumen: Trends über die Zeit und Spitzen nach Releases
- Top-Treiber: Tags/Gründe, die mit Eskalationen korrelieren
- Agenten-Last: offene Tickets pro Agent und Time-to-first-touch
Die Reports sollten einfach zu exportieren und für nicht-technische Stakeholder leicht zu erklären sein.
Iteriere Rules und Makros anhand realer Ergebnisse
Routing- und Triage-Regeln sind anfangs fehlerhaft — das ist normal. Tune Regeln basierend auf Fehlrouten, Lösungszeiten und Feedback aus On-Call. Dasselbe gilt für Makros und Standardantworten: entferne solche, die Zeit nicht sparen, und verfeinere jene, die Kommunikation und Klarheit verbessern.
Veröffentliche eine einfache Roadmap und Hilfsmittel
Halte deine Roadmap knapp und im Produkt sichtbar („Next 30 days"). Verlinke Hilfetexte und FAQs, damit Training nicht zu Tribal Knowledge wird. Wenn du öffentliche Informationen pflegst, mache sie per internen Links wie /pricing oder /blog auffindbar, damit Teams sich selbst bedienen und Best Practices nachlesen können.