08. Juli 2025·8 Min
Wie man eine Web‑App für teamübergreifendes Abhängigkeits‑Tracking erstellt
Lernen Sie, wie Sie eine Web-App für teamübergreifendes Abhängigkeits-Tracking planen und bauen: Datenmodell, UX, Workflows, Alerts, Integrationen und Rollout-Schritte.
Klären Sie das Abhängigkeitsproblem, das Sie lösen wollen
Bevor Sie Bildschirme entwerfen oder einen Tech-Stack wählen: Präzisieren Sie, was „Abhängigkeit“ in Ihrer Organisation bedeutet. Wenn das Wort alles beschreibt, wird Ihre App am Ende nichts gut nachverfolgen.
Definieren Sie „Abhängigkeit“ in einfachen Worten
Formulieren Sie einen Ein-Satz, den alle wiederholen können, und listen Sie auf, was dazugehört. Häufige Kategorien sind:
- Arbeitsauftrag: ein anderes Team muss ein Feature bauen, einen Bug beheben oder ein Ticket liefern.
- Liefergegenstand: ein Dokument, Datensatz, Design oder Asset, das benötigt wird, um weiterzumachen.
- Entscheidung: eine Vereinbarung oder Freigabe, die die Implementierung freischaltet.
- Umgebung/Zugriff: Credentials, Infrastruktur, Testumgebungen oder Genehmigungen.
Definieren Sie außerdem, was keine Abhängigkeit ist (z. B. „Nice-to-have“-Verbesserungen, generelle Risiken oder interne Aufgaben, die kein anderes Team blockieren). Das hält das System sauber.
Wählen Sie aus, für wen die App gedacht ist
Dependency-Tracking scheitert, wenn es nur für PMs oder nur für Entwickler gebaut wird. Benennen Sie Ihre Hauptnutzer und was jeder in 30 Sekunden braucht:
- Team Leads / Engineering Manager: was die Lieferung blockiert und wer den nächsten Schritt verantwortet.
- PMs / Programmmanager: Übergabetermine, Zusagen und Eskalationspfade.
- Entwickler: die genaue Anfrage, der Kontext und die Abnahmekriterien.
- Führung / Operations: planbare Lieferung, weniger Überraschungen und Trend-Reports.
Wählen Sie messbare Erfolgskennzahlen
Wählen Sie eine kleine Anzahl von Ergebnissen, z. B.:
- Weniger „Überraschungs-Blocker“, die spät in einem Sprint oder Release entdeckt werden
- Kürzere Zeit von Abhängigkeitsanlage → zugewiesene Ownership
- Höhere termingerechte Übergaben im Vergleich zu vereinbarten Daten
- Klare Ownership (weniger Items mit „TBD“ als Zuständigen)
Listen Sie die Pain Points auf, die Sie eliminieren werden
Erfassen Sie die Probleme, die Ihre App am ersten Tag lösen muss: veraltete Tabellen, unklare Owner, verpasste Termine, verborgene Risiken und Status-Updates, die über Chatstränge verstreut sind.
Modellieren Sie Abhängigkeiten, Zustände und Definitionen
Sobald Sie sich darauf geeinigt haben, was Sie nachverfolgen und für wen, legen Sie das Vokabular und den Lebenszyklus fest. Gemeinsame Definitionen verwandeln eine „Liste von Tickets“ in ein System, das Blocker reduziert.
Beginnen Sie mit den Abhängigkeitstypen, die Sie unterstützen
Wählen Sie eine kleine Menge von Typen, die die meisten realen Situationen abdecken, und machen Sie jeden Typ leicht erkennbar:
- Blocked-by: Team A kann erst liefern, wenn Team B etwas erledigt hat.
- Provides-to: Team B liefert ein Artefakt/Service, das Team A konsumiert.
- Waiting-on: Ähnlich wie blocked-by, oft aber zeitlich begrenzt (Genehmigung, Zugriff, Entscheidung).
- Geteilter Ressourcenpool: Teams konkurrieren um dieselben Personen, Umgebungen, Budget oder Vendor.
- Sequenzielle Einschränkung: Arbeit muss in einer bestimmten Reihenfolge stattfinden, auch wenn kein Team strikt „blockiert“ ist.
Das Ziel ist Konsistenz: Zwei Personen sollten dieselbe Abhängigkeit gleich klassifizieren.
Definieren Sie die minimalen Attribute (und erzwingen Sie sie)
Ein Abhängigkeitsdatensatz sollte klein, aber vollständig genug sein, um ihn zu managen:
- Owner-Team (verantwortlich für die Lieferung)
- Requesting-Team (benötigt das Ergebnis)
- Fälligkeitsdatum (wann der Requester es braucht)
- Status (siehe Lebenszyklus weiter unten)
- Risikostufe (z. B. Niedrig/Mittel/Hoch)
- Notizen (Kontext, Annahmen)
- Links zur Ursprungsarbeit (Jira-Issue, Doc, PR, Incident, etc.)
Wenn Sie das Erstellen einer Abhängigkeit ohne Owner-Team oder Fälligkeitsdatum erlauben, bauen Sie einen „Concern Tracker“ statt ein Koordinationstool.
Einigen Sie sich auf Lifecycle-Zustände und Auslöser für Änderungen
Verwenden Sie ein einfaches Zustandsmodell, das dem tatsächlichen Arbeitsablauf entspricht:
Proposed → Accepted → In progress → Ready → Delivered/Closed, plus Rejected.
Schreiben Sie Regeln für Zustandsänderungen. Beispiel: „Accepted erfordert ein Owner-Team und ein initiales Ziel-Datum“ oder „Ready erfordert Nachweise.“
Machen Sie „erledigt“ unmissverständlich
Für das Schließen verlangen Sie alles Folgende:
- Abnahmekriterien: was als vollständig gilt
- Sign-off: wer bestätigt (Name/Team)
- Nachweis/Link: PR, Release-Note, Screenshot, Doc oder Ticket
- Zeitstempel: wann es akzeptiert/geschlossen wurde
Diese Definitionen werden später das Rückgrat Ihrer Filter, Erinnerungen und Status-Reviews.
Entwerfen Sie ein einfaches Datenmodell, das skaliert
Ein Dependency-Tracker steht oder fällt damit, ob Menschen die Realität beschreiben können, ohne gegen das Tool zu kämpfen. Starten Sie mit wenigen Objekten, die Teams bereits verwenden, und fügen Sie Struktur dort hinzu, wo sie Verwirrung verhindert.
Kernobjekte (halten Sie sie unspektakulär)
Verwenden Sie eine Handvoll primärer Datensätze:
- Team: die Gruppe, die Arbeit besitzt oder eine Abhängigkeit liefert.
- Projekt/Initiative: ein Container für Arbeit mit klarem Outcome.
- Work Item: die Einheit, die ausgeführt wird (Feature, Task, Epic, Ticket-Link).
- Dependency: ein Versprechen zwischen Requester und Provider.
- Milestone/Release: ein datumsgetriebener Checkpoint, den Abhängigkeiten blockieren können.
Vermeiden Sie separate Typen für jede Randbedingung. Besser ein paar Felder (z. B. „type: data/API/approval“) hinzufügen als das Modell zu früh aufzuteilen.
Beziehungen, die echte Koordination widerspiegeln
Abhängigkeiten betreffen oft mehrere Gruppen und mehrere Aufgaben. Modellieren Sie das explizit:
- Teams ↔ Dependencies: viele-zu-viele (eine Abhängigkeit kann mehrere Provider-Teams haben; ein Team kann in vielen Abhängigkeiten involviert sein).
- Dependencies ↔ Work Items: viele-zu-viele (eine Abhängigkeit kann mehrere Work Items blockieren; ein Work Item kann mehrere Abhängigkeiten haben).
Das verhindert brüchiges „eine Abhängigkeit = ein Ticket“-Denken und ermöglicht Roll-up-Reports.
Auditierbarkeit: machen Sie Änderungen vertrauenswürdig
Jedes Primärobjekt sollte Audit-Felder enthalten:
- Created by / created at, updated by / updated at
- Change history (was sich wann geändert hat)
- Kommentare (Entscheidungen und Kontext)
- Anhänge/Links (Specs, Docs, Jira-Issues, Meeting-Notizen)
Leichte Unterstützung für externe Abhängigkeiten
Nicht jede Abhängigkeit hat ein Team in Ihrem Organigramm. Fügen Sie einen Owner/Contact-Datensatz hinzu (Name, Organisation, E‑Mail/Slack, Notizen) und erlauben Sie, dass Dependencies darauf verweisen. Das macht Vendor- oder „anderes Department“-Blocker sichtbar, ohne sie in Ihre interne Teamliste zu zwingen.
Definieren Sie Rollen, Ownership und Berechtigungen
Wenn Rollen nicht explizit sind, wird Dependency-Tracking zur Kommentarspalte: alle gehen davon aus, jemand anderes sei verantwortlich, und Termine werden ohne Kontext „angepasst“. Ein klares Rollenmodell macht die App vertrauenswürdig und Eskalationen vorhersehbar.
Kernrollen (einfach halten)
Starten Sie mit vier alltäglichen Rollen und einer administrativen Rolle:
- Requester: erstellt eine Dependency-Anfrage und liefert das „Warum“, das benötigte Datum und die Abnahmekriterien.
- Owner: die einzige verantwortliche Person, die für Lieferung (oder formale Ablehnung) zuständig ist.
- Approver: bestätigt Zusagen, wenn eine Abhängigkeit Kapazität, Scope oder Release-Planung beeinflusst.
- Viewer: kann verfolgen und kommentieren, aber keine Zusagen ändern.
- Admin: verwaltet Konfiguration (Teams, Berechtigungen, Templates), nicht die tägliche Entscheidungsfindung.
Ownership-Regeln, die Unklarheit verhindern
Machen Sie den Owner erforderlich und singulär: eine Abhängigkeit, ein verantwortlicher Owner. Unterstützen Sie weiterhin Collaborators (Mitarbeitende aus anderen Teams), aber Collaborators sollten nie die Accountability ersetzen.
Fügen Sie einen Eskalationspfad hinzu, wenn ein Owner nicht reagiert: zuerst eine Erinnerung an den Owner, dann an dessen Manager (oder Team Lead), dann an einen Programm-/Release-Verantwortlichen — je nach Struktur Ihrer Organisation.
Berechtigungen: schützen Sie Zusagen, nicht Sichtbarkeit
Trennen Sie „Details bearbeiten“ von „Zusagen ändern“. Ein sinnvolles Default:
- Requester kann erstellen, Kontext hinzufügen und Termine vorschlagen; kann „Committed“ nicht ohne Genehmigung setzen.
- Owner kann Status aktualisieren, Liefernotizen hinzufügen und neue Termine vorschlagen; schließen nur, wenn Abnahmekriterien erfüllt sind.
- Approver kann Commitment-States (Committed/Rejected) setzen und Datumsänderungen genehmigen.
- Viewer kann sehen und kommentieren; keine Bearbeitungen.
Wenn Sie private Initiativen unterstützen, definieren Sie, wer sie sehen darf (z. B. nur beteiligte Teams + Admin). Vermeiden Sie „geheime Abhängigkeiten“, die Lieferteams überraschen.
RACI-Hinweise in der UI
Verstecken Sie Verantwortung nicht in einer Policy. Zeigen Sie sie auf jeder Abhängigkeit:
- Accountable (A): Owner
- Responsible (R): Collaborators (optional)
- Consulted (C): Approver und betroffene Teams
- Informed (I): Viewer/Watcher
Die Kennzeichnung „Accountable vs Consulted“ direkt im Formular reduziert Fehlleitung und beschleunigt Status-Reviews.
Planen Sie die UX: Ansichten, die Teams wirklich nutzen
Ein Dependency-Tracker funktioniert nur, wenn Personen ihre Items in Sekunden finden und ohne Nachdenken aktualisieren können. Entwerfen Sie um die häufigsten Fragen: „Wen blockiere ich?“, „Wer blockiert mich?“ und „Rutscht etwas gleich?“
Kern-Screens, die Sie early shippen sollten
Starten Sie mit wenigen Ansichten, die der alltäglichen Sprache entsprechen:
- Dependency-Liste: filterbare Tabelle für „alle offenen Dependencies“ mit Schnellaktionen.
- Dependency-Detail: ein Ort, um Anfrage, Status, Owner, Termine und Historie zu verstehen.
- Team-Ansicht: alles, was ein Team schuldet und worauf es wartet, mit klaren Prioritäten.
- Initiative-Ansicht: Dependencies gruppiert unter einem Projekt/Release, sodass Leads Risiken erkennen.
- Timeline: leichte Datumsansicht für Fälligkeiten und erwartete Übergaben (kein vollwertiges Gantt-Tool).
Machen Sie Erstellung und Updates reibungslos
Die meisten Tools scheitern bei „täglichen Updates“. Optimieren Sie für Geschwindigkeit:
- Templates und Standardfelder (häufige Abhängigkeitstypen, vorausgefüllte SLA/Fälligkeitsregeln).
- Inline-Bearbeitung auf Listen- und Detailseiten (keine modalen Formulare für einfache Änderungen).
- Tastaturfreundliche Steuerelemente für Power-User (Tab-Reihenfolge, Quick-Save, vorhersehbare Shortcuts).
Machen Sie Status missverständlich unmöglich
Verwenden Sie Farbe plus Textlabels (niemals nur Farbe) und halten Sie die Terminologie konsistent. Fügen Sie auf jeder Abhängigkeit ein prominentes „Zuletzt aktualisiert“-Zeitstempel hinzu und eine Stale-Warnung, wenn sie über einen definierten Zeitraum nicht angefasst wurde (z. B. 7–14 Tage). Das sorgt für sanfte Nudges ohne Meetings zu erzwingen.
Reduzieren Sie Meetings, indem Sie Kontext erfassen
Jede Abhängigkeit sollte einen einzigen Thread enthalten mit:
- Kommentaren und Fortschritts-Updates
- Entscheidungen (mit Datum und wer zugestimmt hat)
- Links zu unterstützender Arbeit (Tickets, Docs)
Wenn die Detailseite die ganze Geschichte erzählt, werden Status-Reviews schneller — und viele „schnellen Syncs“ entfallen, weil die Antwort bereits dokumentiert ist.
Bauen Sie Workflows für Anfragen, Updates und Abschluss
Übernimm deine Codebasis
Exportiere den vollständigen Quellcode, wenn du die Entwicklung vollständig intern übernehmen willst.
Ein Dependency-Tracker lebt von den täglichen Aktionen, die er unterstützt. Können Teams nicht schnell anfragen, klar zusagen und mit Nachweis schließen, wird die App zu einem „FYI-Board“ statt zu einem Ausführungswerkzeug.
Kernworkflow: request → decision → commitment
Beginnen Sie mit einem einzigen „Create request“-Flow, der erfasst, was das liefernde Team liefern muss, warum es wichtig ist und wann es benötigt wird. Halten Sie es strukturiert: gewünschtes Fälligkeitsdatum, Abnahmekriterien und Link zum relevanten Epic/Spec.
Erzwingen Sie anschließend einen expliziten Antwortstatus:
- Accept (Zusage zu einem Datum)
- Decline (mit Pflichtangabe eines Grundes)
- Propose new date (Gegenangebot mit Erklärung)
Das vermeidet die häufigste Fehlerquelle: stille „Vielleicht“-Abhängigkeiten, die bis zur Eskalation harmlos aussehen.
SLA-artige Erwartungen, die Stagnation verhindern
Definieren Sie leichte Erwartungen im Workflow selbst. Beispiele:
- Antwort innerhalb X Arbeitstagen nachdem eine Anfrage gestellt wurde
- Update-Rhythmus (z. B. wöchentlich oder bei Statusänderung)
- Als stale markieren, wenn keine Aktualisierung für Y Tage erfolgte und das Fälligkeitsdatum innerhalb von Z Tagen liegt
Ziel ist nicht Kontrolle, sondern aktuelle Zusagen, damit Planung ehrlich bleibt.
Updates mit Change Control (ohne Bürokratie)
Ermöglichen Sie Teams, eine Abhängigkeit als At risk zu markieren mit einer kurzen Notiz und nächsten Schritten. Wenn jemand ein Fälligkeitsdatum oder Status ändert, verlangen Sie einen Grund (Dropdown + Freitext). Diese einzige Regel schafft eine Audit-Spur, die Retrospektiven und Eskalationen sachlich statt emotional macht.
Abschluss, der beweist, dass Arbeit tatsächlich erledigt wurde
„Close“ sollte bedeuten, dass die Abhängigkeit erfüllt ist. Fordern Sie Nachweis: Link zu einem gemergten PR, released Ticket, Dokument oder einer Genehmigungsnotiz. Wenn der Abschluss unscharf ist, werden Teams Items zu früh „grün“ setzen, um Lärm zu reduzieren.
Bulk-Aktionen für wöchentliche Planung
Unterstützen Sie Massenupdates während Status-Reviews: mehrere Dependencies auswählen und denselben Status setzen, eine gemeinsame Notiz hinzufügen (z. B. „nach Q1-Reset neu geplant“) oder Updates anfordern. So bleibt die App schnell genug für Meetings, nicht nur für Nacharbeit.
Fügen Sie Alerts und Benachrichtigungen hinzu — ohne Spam
Benachrichtigungen sollen die Lieferung schützen, nicht ablenken. Der einfachste Weg, Lärm zu erzeugen, ist, alle über alles zu informieren. Designen Sie Alerts stattdessen um Entscheidungspunkte (jemand muss handeln) und Risikosignale (etwas driftet).
Beginnen Sie mit einer kleinen Menge hochrelevanter Trigger
Beschränken Sie die erste Version auf Ereignisse, die den Plan ändern oder eine explizite Antwort brauchen:
- Neue Anfrage erstellt (Owner-Team wird benachrichtigt)
- Bestätigung erforderlich (eine Abhängigkeit ist zugewiesen und wartet auf Bestätigung)
- Datum geändert (eine Seite passt zugesagte/benötigte Daten an)
- Status: at risk / blocked (Risikoflag gesetzt, Blocker hinzugefügt)
- Stale-Updates (keine Aktualisierung in X Tagen für eine aktive Abhängigkeit)
Jeder Trigger sollte zu einem klaren nächsten Schritt führen: akzeptieren/ablehnen, Gegenangebot machen, Kontext ergänzen oder eskalieren.
Liefern Sie Benachrichtigungen über die Kanäle, die Teams bereits nutzen
Setzen Sie standardmäßig auf In-App-Notifications (damit Alerts an den Datensatz gebunden sind) plus E-Mail für Dinge, die nicht warten können.
Bieten Sie optionale Chat-Integrationen — Slack oder Microsoft Teams — an, behandeln Sie sie aber als Zustellmechanismus, nicht als System of Record. Chat-Nachrichten sollten deep-linken zum Item (z. B. /dependencies/123) und das Minimum an Kontext enthalten: wer handeln muss, was sich geändert hat und bis wann.
Reduzieren Sie Lärm mit Präferenzen und Digests
Stellen Sie Team- und Benutzer-Einstellungen bereit:
- Sofortige Alerts für Acceptance, Blocked, Overdue
- Digest-Modus (täglich/wöchentlich) für Low-Urgency-Updates wie kleine Datumsverschiebungen oder Kommentare
- Gruppierung und Deduplizierung (eine Zusammenfassung pro Abhängigkeit pro Zeitfenster)
Hier sind auch „Watcher“ wichtig: benachrichtigen Sie Requester, das zuständige Team und explizit hinzugefügte Stakeholder — vermeiden Sie breite Broadcasts.
Eskalieren Sie nur bei musterbasiertem Risiko
Eskalation sollte automatisiert, aber konservativ sein: alarmieren, wenn eine Abhängigkeit überfällig ist, das Fälligkeitsdatum wiederholt verschoben wurde oder ein blockierter Status längere Zeit ohne Update besteht.
Richten Sie Eskalationen an die richtige Ebene (Team Lead, Program Manager) und fügen Sie die Historie bei, damit der Empfänger schnell handeln kann, ohne Kontext zu jagen.
Wählen Sie Integrationen, die Doppelarbeit entfernen
Kernansichten bereitstellen
Erstelle Listen-, Detail-, Team- und Initiativenansichten schnell genug für einen echten Pilot.
Integrationen sollen Nachpflege eliminieren, nicht zusätzlichen Setup-Overhead schaffen. Der sicherste Weg ist, mit Systemen zu starten, denen Teams bereits vertrauen (Issue-Tracker, Kalender, Identity), die erste Version read-only oder einseitig zu halten und erst zu erweitern, wenn das Tool genutzt wird.
Beginnen Sie mit einem Issue-Tracker
Wählen Sie einen primären Tracker (Jira, Linear oder Azure DevOps) und unterstützen Sie zunächst einen einfachen Link-first-Flow:
- Ein Dependency-Datensatz speichert eine Tracker-URL und einen Key (z. B.
PROJ-123). - Ihre App zieht Status (Open/In Progress/Done), Assignee und Fälligkeitsdatum in regelmäßigen Intervallen.
- Updates bleiben zunächst im Tracker; Ihre App spiegelt sie wider.
So vermeiden Sie „zwei Wahrheitsquellen“, geben aber trotzdem Dependency-Sichtbarkeit. Später können Sie optional Zwei-Wege-Sync für eine kleine Menge Felder (Status, Fälligkeitsdatum) hinzufügen – mit klaren Konfliktregeln.
Kalender-Milestones hinzufügen (zuerst nur lesend)
Meilensteine und Deadlines werden oft in Google Calendar oder Microsoft Outlook gepflegt. Beginnen Sie damit, Events in Ihre Dependency-Timeline einzulesen (z. B. „Release Cutoff“, „UAT-Window“), ohne zurückzuschreiben.
Read-only Calendar-Sync lässt Teams dort planen, wo sie es bereits tun, während Ihre App Auswirkungen und anstehende Termine an einem Ort zeigt.
Machen Sie den Zugang unkompliziert mit SSO
Single-Sign-On reduziert Onboarding-Hürden und Berechtigungsdrift. Wählen Sie basierend auf Ihrer Kundensituation:
- Google Workspace (häufig bei kleineren Organisationen)
- Microsoft Entra ID (häufig bei Enterprises)
- Okta (häufig bei gemischten Umgebungen)
Wenn Sie früh sind, liefern Sie einen Anbieter zuerst und dokumentieren, wie weitere angefragt werden können.
Bieten Sie eine kleine, gut dokumentierte API + Webhooks
Auch nicht-technische Teams profitieren, wenn Ops interne Handoffs automatisieren können. Stellen Sie ein paar Endpunkte und Event-Hooks mit Copy‑Paste-Beispielen bereit.
# Create a dependency from a release checklist
curl -X POST /api/dependencies \\
-H "Authorization: Bearer $TOKEN" \\
-d '{"title":"API contract from Payments","trackerUrl":"https://jira/.../PAY-77"}'
Webhooks wie dependency.created und dependency.status_changed erlauben es Teams, sich mit internen Tools zu integrieren, ohne auf Ihre Roadmap zu warten. Für mehr, verlinken Sie auf /docs/integrations.
Erstellen Sie Dashboards und Berichte für Status-Reviews
Dashboards sind der Punkt, an dem ein Dependency-Tool seinen Wert beweist: Sie verwandeln „Ich glaube, wir sind blockiert“ in ein klares, gemeinsames Bild dessen, was vor dem nächsten Check-in Aufmerksamkeit braucht.
Dashboards für verschiedene Audiences
Ein „One size fits all“-Dashboard scheitert meist. Entwerfen Sie stattdessen ein paar Views, die zu Meeting-Formaten passen:
- Team Lead View: zeigt Dependencies, die Ihr Team schuldet und worauf es wartet, mit Fokus auf Fälligkeiten, aktuellen Status und nächstem Schritt.
- Program View: gruppiert Dependencies nach Initiative/Release und hebt teamübergreifende Engpässe hervor (z. B. viele Items warten auf dasselbe Team oder denselben Milestone).
- Exec Summary: kompakte Roll-up-Kennzahlen: offene Abhängigkeiten gesamt, wie viele sind at risk, was ist neu überfällig und die Top‑3-Blocker. Kurz und skimmbar.
Berichte, die Entscheidungen antreiben (nicht Busywork)
Bauen Sie eine kleine Menge Reports, die in Reviews tatsächlich genutzt werden:
- Overdue Dependencies: sortiert nach Tagen überfällig und Schwere/Risiko.
- Top blocking teams: wer hat die meisten wartenden Dependencies (mit Zeitreihen-Trend).
- Upcoming milestones at risk: Meilensteine in den nächsten 2–4 Wochen mit noch offenen oder als „at risk“ markierten Dependencies.
Jeder Report sollte beantworten: „Wer muss als Nächstes was tun?“ Inkludieren Sie Owner, erwartetes Datum und letzte Aktualisierung.
Filter, die zählen
Machen Sie Filter schnell und offensichtlich – die meisten Meetings starten mit „zeige mir nur …“
Unterstützen Sie Filter wie Team, Initiative, Status, Fälligkeitsbereich, Risikostufe und Tags (z. B. „Security Review“, „Data Contract“, „Release Train“). Speichern Sie häufig genutzte Filtersets als benannte Views (z. B. „Release A — nächste 14 Tage").
Export und Teilen
Nicht alle leben täglich in Ihrer App. Bieten Sie:
- CSV-Export für leichte Analysen und einmaliges Teilen.
- Shareable Links zu gefilterten Dashboards oder Reports (z. B. eine Programm-Ansicht für das wöchentliche Sync). Halten Sie Links intern und stabil, z. B. /reports/overdue?team=payments.
Wenn Sie ein kostenpflichtiges Tier anbieten, behalten Sie Admin-freundliche Sharing-Kontrollen und verweisen Sie auf /pricing für Details.
Wählen Sie einen praktischen Tech-Stack und eine Architektur
Sie brauchen keine komplexe Plattform, um einen Dependency-Tracker zu releasen. Ein MVP kann ein einfaches Dreiteiler-System sein: eine Web-UI für Menschen, eine API für Regeln und Integrationen und eine Datenbank als Source of Truth. Optimieren Sie für „leicht änderbar“ statt „perfekt“. Sie lernen mehr aus realer Nutzung als aus monatelanger Architekturplanung.
Ein einfaches MVP-Stack
Ein pragmatischer Start sieht so aus:
- Web UI: React, Vue oder server-gerenderte Seiten (Rails/Django) wenn Sie schneller CRUD-Seiten wollen.
- API: Node (Express/Nest), Python (FastAPI/Django) oder Rails — wählen Sie, was Ihr Team bereits unterstützt.
- Datenbank: Postgres ist meist die beste Default für relationale Daten wie Dependencies, Owner, Status und Timestamps.
Wenn Sie Slack/Jira-Integrationen bald erwarten, halten Sie Integrationen als separate Module/Jobs, die mit derselben API sprechen, statt externen Tools direkt in die DB zu schreiben.
Wenn Sie schnell zu einem nutzbaren Produkt kommen wollen, ohne alles von Grund auf aufzubauen, kann ein Vibe-Coding-Workflow helfen: z. B. Koder.ai kann eine React-UI und ein Go + PostgreSQL-Backend aus einer Chat-basierten Spezifikation generieren und Ihnen erlauben, mit Planning Mode, Snapshots und Rollback zu iterieren. Sie behalten die Architekturhoheit, verkürzen aber den Weg von „Requirements“ zu „benutzbarem Pilot“ und exportieren den Source-Code, wenn Sie es vollständig inhouse übernehmen möchten.
Technische Basics, die Sie schätzen werden
- Authentifizierung: SSO (SAML/OIDC) falls verfügbar; sonst sichere E‑Mail-Logins.
- Logging: strukturierte Request-Logs plus Error-Tracking, damit Sie Debugging zu „Warum hat sich das geändert?“ betreiben können.
- Rate Limits: schützen die API vor lauten Integrationen und versehentlichen Loops.
- Backups: automatisierte tägliche Backups und getestete Restores (testen Sie die Wiederherstellung).
Performance und Datenhygiene
Die meisten Screens sind Listenansichten: offene Dependencies, Blocker nach Team, Änderungen dieser Woche. Entwerfen Sie dafür:
- Fügen Sie Indexes für gängige Filter hinzu (Status, Owner-Team, Fälligkeitsdatum, updated_at).
- Nutzen Sie Pagination überall.
- Bieten Sie Suche (einfaches Postgres Full‑Text reicht oft).
Datenschutz und Vertrauen
Dependency-Daten können sensible Lieferdetails enthalten. Nutzen Sie Least-Privilege Access (Team-Level-Sichtbarkeit wo sinnvoll) und behalten Sie Audit-Logs für Änderungen — wer hat was wann geändert. Diese Audit-Spur reduziert Diskussionen in Reviews und macht das Tool vertrauenswürdig.
Rollout-Plan: Pilot, Migrieren und Adoption fördern
Auf deiner Domain starten
Wechsle von einer Test-URL zu deiner eigenen Domain, wenn das Team bereit ist.
Die Einführung einer Dependency-Tracking-App ist weniger Feature- als Gewohnheitsänderung. Behandeln Sie den Rollout wie ein Produkt-Launch: klein anfangen, Wert beweisen und dann mit klarem Betriebsrhythmus skalieren.
1) Starten Sie mit einem fokussierten Pilot
Wählen Sie 2–4 Teams in einer gemeinsamen Initiative (z. B. ein Release-Train oder ein Kundenprojekt). Definieren Sie messbare Erfolgskriterien, die Sie in ein paar Wochen bewerten können:
- Weniger „unbekannte“ Blocker in Status-Reviews
- Kürzere Zeit von „Abhängigkeit angelegt“ bis „Owner zugewiesen“
- Höhere termingerechte Übergaben für die Pilot-Initiative
Halten Sie die Pilotkonfiguration minimal: nur Felder und Views, die nötig sind, um die Frage zu beantworten: „Was ist blockiert, von wem und bis wann?"
2) Migrieren Sie Tabellenkalkulationen ohne Chaos
Viele Teams tracken Dependencies bereits in Tabellen. Importieren Sie sie, aber mit Bedacht:
- Mappen Sie Spalten auf Felder (Beschreibung, Requesting Team, Owning Team, Due Date, Status, Blocker-Reason)
- Bereinigen Sie Duplikate und normalisieren Sie Teamnamen vor dem Import
- Entscheiden Sie, was mit historischen Zeilen passiert (oft besser archiviert als migriert)
Führen Sie mit Pilot-Usern eine kurze Data-QA durch, um Definitionen zu bestätigen und zweideutige Einträge zu bereinigen.
3) Fördern Sie Adoption mit einem leichten Playbook
Adoption bleibt, wenn die App eine bestehende Routine unterstützt. Bieten Sie:
- Ein 15–20-minütiges Training mit 2–3 realistischen Beispiel-Dependencies
- Eine wöchentliche Update-Routine (z. B. dienstags vor dem Cross-Team-Sync)
- Eine klare Regel: Abhängigkeiten ohne Owner oder Fälligkeitsdatum sind nicht „geloggt“, sie sind unvollständig
Wenn Sie schnell bauen (z. B. iterativ im Koder.ai-Workflow), nutzen Sie Umgebungen/Snapshots, um Änderungen an Pflichtfeldern, Zuständen und Dashboards mit den Pilot-Teams zu testen — und rollforward/rollback ohne Störung aller.
4) Bauen Sie eine Feedback-Schleife und iterieren Sie
Tracken Sie, wo Nutzer hängen bleiben: verwirrende Felder, fehlende Zustände oder Views, die Review-Fragen nicht beantworten. Überprüfen Sie Feedback wöchentlich während des Pilots und passen Sie Felder und Default-Views an, bevor Sie mehr Teams einladen. Ein einfacher „Report an /support“-Link hilft, die Schleife kurz zu halten.
Vermeiden Sie Fallen und planen Sie die nächste Iteration
Ist Ihre App live, sind die größten Risiken nicht technischer Natur, sondern verhaltensbedingt. Teams geben Tools selten auf, weil sie „nicht funktionieren“, sondern weil das Aktualisieren optional, verwirrend oder zu laut erscheint.
Häufige Fehler (und wie man sie vermeidet)
Zu viele Felder. Wenn das Anlegen einer Dependency wie ein Formularausfüllen wirkt, verschieben oder überspringen Menschen es. Starten Sie mit einem minimalen Pflichtset: Titel, Requesting Team, Owning Team, „Next action“, Fälligkeitsdatum und Status.
Unklare Ownership. Wenn nicht klar ist, wer als Nächstes handeln muss, werden Dependencies zu Status-Threads. Machen Sie „Owner“ und „Next action owner“ explizit und zeigen Sie sie prominent an.
Keine Update-Gewohnheiten. Selbst eine großartige UI versagt, wenn Items veralten. Nutzen Sie sanfte Nudges: markierte veraltete Items in Listen, Erinnerungen nur wenn ein Datum naht oder das letzte Update alt ist, und einfache Updates (One‑Click-Statuswechsel plus kurzer Notiz).
Benachrichtigungs-Überlastung. Wenn jeder Kommentar alle pingt, werden Nutzer das System stummschalten. Standardmäßig Watcher nutzen, und Zusammenfassungen (täglich/wöchentlich) senden.
Guardrails, die das System gesund halten
Behandeln Sie „Next action“ als erstklassiges Feld: jede offene Abhängigkeit sollte immer einen klaren nächsten Schritt und eine einzelne verantwortliche Person haben. Fehlt das, darf das Item in wichtigen Views nicht als „vollständig“ erscheinen.
Definieren Sie außerdem, was „done“ bedeutet (z. B. resolved, nicht mehr benötigt oder in einen anderen Tracker verschoben) und verlangen Sie einen kurzen Abschlussgrund, um Zombie-Items zu vermeiden.
Governance: verhindern Sie Taxonomie-Drift
Bestimmen Sie, wer Tags, Teamliste und Kategorien pflegt — meist ein Programmmanager oder Ops mit leichtem Change-Control. Setzen Sie eine einfache Retirement-Policy: archive alte Initiativen automatisch X Tage nach Schließung und prüfen Sie ungenutzte Tags quartalsweise.
Roadmap-Ideen für die nächste Iteration
Nach stabiler Adoption denken Sie über sinnvolle Erweiterungen nach, die keinen zusätzlichen Friktion erzeugen:
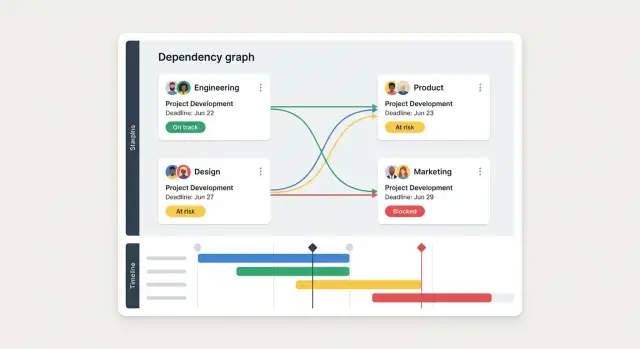
- Dependency-Graph-View für komplexe Releases und multi‑team Arbeit
- Risk Scoring (z. B. Alter, verpasste Fälligkeitsdaten, hochimpactige Tags)
- SLA-Analytics zur Erkennung chronischer Engpässe
- Department-Templates damit häufige Dependency‑Typen mit einem Klick erstellt werden können
Um Prioritäten strukturiert zu setzen: Verknüpfen Sie Ideen mit Review-Ritualen (wöchentliche Status-Meeting, Release-Planung, Incident-Retros), damit Verbesserungen durch reale Nutzung getrieben werden — nicht durch Vermutungen.
FAQ
Was zählt als „Abhängigkeit“ in einer teamübergreifenden Tracking-App?
Beginnen Sie mit einer einprägsamen Ein-Satz-Definition, die alle wiederholen können, und listen Sie dann auf, was darunter fällt (Arbeitsauftrag, Liefergegenstand, Entscheidung, Umgebung/Zugriff).
Schreiben Sie außerdem auf, was nicht dazugehört (Nice-to-haves, allgemeine Risiken, interne Aufgaben, die kein anderes Team blockieren). So vermeiden Sie, dass das Tool zu einem vagen „Concern Tracker“ wird.
Für wen sollte eine Dependency-Tracking-Web-App gebaut werden?
Mindestens sollten Sie gestalten für:
- Team Leads / Engineering Manager: was die Auslieferung blockiert und wer der nächste Schritt-Verantwortliche ist
- PMs / Programmmanager: Übergabetermine, Zusagen und Eskalationswege
- Entwickler: die genaue Anforderung, Kontext und Abnahmekriterien
- Führung / Ops: weniger Überraschungen und Trend-Reporting
Wenn Sie nur für eine Gruppe bauen, werden die anderen es nicht pflegen – und das System veraltet.
Welche Status sollte eine Abhängigkeit durchlaufen?
Nutzen Sie einen kleinen, konsistenten Lebenszyklus wie:
- Proposed → Accepted → In progress → Ready → Delivered/Closed
- Rejected (für abgelehnte Anfragen)
Definieren Sie dann Regeln für Zustandswechsel (z. B. „Accepted erfordert ein Owner-Team und ein Ziel-Datum“, „Ready erfordert Nachweise“). Konsistenz ist wichtiger als Komplexität.
Welche Mindestfelder sollte jede Abhängigkeit haben?
Fordern Sie nur das an, was zur Koordination nötig ist:
- Owner-Team (Provider)
- Requester-Team
- Fälligkeitsdatum (needed-by)
- Status
- Risikostufe (Niedrig/Mittel/Hoch)
- Notizen/Kontext
- Links zur Ursprungsarbeit (Ticket/Dokument/PR)
Erlauben Sie kein Fehlen von Owner oder Fälligkeitsdatum – sonst sammeln Sie Items, die nicht bearbeitet werden können.
Wie macht man „done“ eindeutig, damit Abhängigkeiten nicht zu früh geschlossen werden?
Machen Sie „done“ nachweisbar. Fordern Sie:
- Abnahmekriterien
- Sign-off (wer bestätigt)
- Nachweis/Link (PR, Release-Note, Dokument, Genehmigung)
- Zeitstempel der Schließung
So verhindern Sie zu frühes „Grünsetzen“, nur um Lärm zu reduzieren.
Welche Rollen und Ownership-Regeln verhindern Unklarheiten?
Definieren Sie vier alltägliche Rollen plus Admin:
- Requester: erstellt die Anfrage und liefert Why/When/Criteria
- Owner: einzelne verantwortliche Person, die liefert oder ablehnt
- Approver: bestätigt Zusagen, die Kapazität/Scope betreffen
- Viewer: kann folgen und kommentieren, aber keine Zusagen ändern
- Admin: verwaltet Konfiguration
Halten Sie „eine Abhängigkeit, ein Owner“ – Collaborators helfen, aber ersetzen keine Verantwortung.
Welche Screens und Views sollte ein MVP enthalten?
Starten Sie mit Ansichten, die tägliche Fragen beantworten:
- Dependency-Liste (filterbare Tabelle mit Schnellaktionen)
- Dependency-Detail (Kontext, Owner, Termine, Historie)
- Team-View (was wir schulden vs. was uns blockiert)
- Initiative/Release-View (gruppiertes Risiko)
- Einfache Timeline für Fälligkeiten/Übergaben
Optimieren Sie für schnelle Updates: Templates, Inline-Bearbeitung, Tastatur-Shortcuts und eine prominente „Zuletzt aktualisiert“-Anzeige.
Wie richtet man Benachrichtigungen ein, ohne Spam zu erzeugen?
Alarmieren Sie nur bei Entscheidungs- und Risikoereignissen:
- Neue Anfrage erstellt (Owner-Team benachrichtigen)
- Acceptance erforderlich
- Datum geändert
- Status: At risk / Blocked
- Stale Item (keine Aktualisierung in X Tagen mit nahendem Fälligkeitsdatum)
Verwenden Sie Watcher statt Broadcasts, bieten Sie Digest-Modi und deduplizieren Benachrichtigungen (eine Zusammenfassung pro Abhängigkeit pro Zeitfenster).
Welche Integrationen sind frühzeitig am wertvollsten?
Integrieren Sie so, dass Doppelbearbeitung entfällt, nicht entsteht:
- Starten Sie mit einem Issue-Tracker (Jira/Linear/Azure DevOps) und ziehen Sie Schlüsselfelder (Status, Assignee, Due Date)
- Zuerst read-only oder einseitig; Zwei-Wege-Sync nur für wenige Felder mit Konfliktregeln
- SSO früh einführen, um Onboarding-Hürden zu senken
- Bieten Sie eine kleine API + Webhooks (z. B.
dependency.created,dependency.status_changed)
Behandeln Sie Chat (Slack/Teams) als Zustellkanal, nicht als Source of Truth; deep-linken Sie zurück zum Eintrag.
Wie rollt man die App aus und migriert von Tabellenkalkulationen?
Führen Sie einen fokussierten Pilot durch, bevor Sie skalieren:
- Wählen Sie 2–4 Teams in einer geteilten Initiative
- Definieren Sie messbaren Erfolg (weniger Überraschungs-Blocker, schnellere Owner-Zuweisung, bessere On-Time-Handoffs)
- Migrieren Sie Tabellen sorgfältig (Teamnamen normalisieren, Duplikate entfernen, alte Reihen archivieren)
- Etablieren Sie eine leichte Betriebsroutine (wöchentliche Updates vor dem Cross-Team-Sync)
Behandeln Sie Items ohne Owner oder Fälligkeitsdatum als unvollständig und iterieren Sie basierend auf Nutzer-Feedback.