Was eine Garantie‑ und Service‑Web‑App können sollte
Eine Garantie‑ und Service‑Web‑App ersetzt verstreute E‑Mails, PDFs und Telefonate durch einen einzigen Ort, um Hilfe anzufordern, Berechtigung zu prüfen und den Fortschritt zu verfolgen.
Bevor du über Features nachdenkst, definiere das genaue Problem, das du lösen willst, und die Ergebnisse, die du verbessern musst.
Umfang festlegen: Ansprüche, Serviceanfragen oder beides
Beginne damit, eine klare Trennung zwischen zwei ähnlichen (aber unterschiedlichen) Abläufen zu zeichnen:
- Garantieansprüche: „Ist das abgedeckt?“ plus Kaufnachweis, Garantiebedingungen und eine Entscheidung (Genehmigung/Ablehnung).\n- Serviceanfragen (außerhalb der Garantie oder allgemeiner Support): „Könnt ihr das reparieren?“ plus Fehlerbehebung, Terminplanung und Zahlung, wenn nötig.
Viele Teams unterstützen beides in einem Portal, aber die App sollte die Nutzer dennoch auf den richtigen Weg führen, damit sie nicht die falsche Anfrage stellen.
Kenne die Nutzer, für die du baust
Ein funktionales System bedient typischerweise vier Gruppen:
- Kunden, die Anfragen einreichen, Dokumente hochladen und den Status prüfen.\n- Support‑Agenten, die triagieren, Folgefragen stellen und nächste Schritte genehmigen.\n- Techniker/Service‑Partner, die diagnostizieren, reparieren und Teile/Arbeitszeit dokumentieren.\n- Manager, die Leistung, Ausnahmen und Kostentreiber überwachen.
Jede Gruppe braucht eine maßgeschneiderte Ansicht: Kunden brauchen Klarheit; interne Teams brauchen Queues, Zuordnungen und Historie.
„Erfolg“ messbar definieren
Gute Ziele sind praktisch und messbar: weniger Hin‑und‑her‑E‑Mails, schnellere Erstreaktion, weniger unvollständige Einsendungen, kürzere Lösungszeiten und höhere Kundenzufriedenheit.
Diese Ergebnisse sollten deine Must‑Have‑Features formen (Statusverfolgung, Benachrichtigungen und konsistente Datenerfassung).
Ein einfaches Self‑Service‑Portal reicht oft nicht. Wenn dein Team Arbeit noch in Tabellen verwaltet, sollte die App auch interne Tools enthalten: Queues, Ownership, Eskalationspfade und Entscheidungsprotokolle.
Andernfalls verlagert sich nur die Intake‑Stufe ins Netz, während das Chaos hinter den Kulissen bleibt.
Definiere den Workflow, bevor du baust
Eine Garantie‑Claims‑Web‑App scheitert oder gelingt basierend auf dem darunterliegenden Workflow. Bevor du Bildschirme entwirfst oder ein Ticketing‑System auswählst, schreibe den End‑to‑End‑Pfad auf, den eine Anfrage nimmt — vom Moment der Einreichung bis zum Abschluss und zur Dokumentation des Ergebnisses.
End‑to‑End‑Flow abbilden (und lesbar halten)
Starte mit einem einfachen Ablauf wie: Anfrage → Prüfung → Genehmigung → Service → Abschluss. Dann füge die realen Details hinzu, die Projekte oft entgleisen lassen:
- Welche Informationen sind an jedem Schritt erforderlich (Seriennummer, Kaufnachweis, Fotos, Fehlercodes)?\n- Welche Entscheidungen werden getroffen (berechtigt vs. nicht berechtigt, Reparatur vs. Ersatz, Einsendung vs. Vor‑Ort)?\n- Was wird im Hintergrund erstellt (Fall, RMA‑Nummer, Reparaturauftrag, Versandetikett)?
Eine gute Übung ist, den Flow auf einer Seite zu skizzieren. Wenn das nicht passt, ist das ein Zeichen dafür, dass dein Prozess vereinfacht werden muss, bevor dein Service‑Portal einfach sein kann.
Garantieansprüche vs. kostenpflichtige Serviceanfragen trennen
Versuche nicht, zwei unterschiedliche Journeys zu einer zu zwingen.
Garantieansprüche und kostenpflichtige Serviceanfragen haben oft unterschiedliche Regeln, Tonalität und Erwartungen:
- Garantie: Validierung, Berechtigungsregeln, möglicherweise kostenfreie Leistung, klare Policy‑Mitteilungen.\n- Kostenpflichtiger Service: Kostenvoranschläge, Zahlungs‑/Zustimmungs‑Schritte und andere Kundenfragen.
Sie getrennt zu halten reduziert Verwirrung und verhindert „Überraschungen“ (z. B. dass ein Kunde denkt, eine kostenpflichtige Reparatur sei gedeckt).
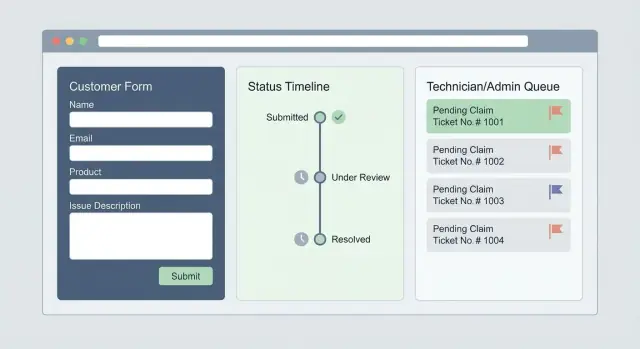
Kunden‑sichtbare Status definieren
Kunden sollten immer wissen, wo sie stehen. Wähle eine kleine Menge an Status, die du verlässlich pflegen kannst — z. B. Eingereicht, In Prüfung, Genehmigt, Versand, Abgeschlossen — und definiere, was jeder intern bedeutet.
Wenn du einen Status nicht in einem Satz erklären kannst, ist er zu vage.
Handoffs und Verantwortliche identifizieren
Jeder Handoff ist ein Risikopunkt. Mache Ownership explizit: Wer prüft, wer genehmigt Ausnahmen, wer plant Termine, wer handelt Versand, wer schließt ab.
Wenn ein Schritt keinen klaren Besitzer hat, türmen sich Queues und Kunden fühlen sich ignoriert — egal wie poliert die App aussieht.
Dein Formular ist die „Eingangstür“ der App. Wenn es verwirrend ist oder zu viel verlangt, brechen Kunden ab — oder sie senden minderwertige Anfragen, die später manuelle Arbeit erzeugen.
Ziele: Klarheit, Schnelligkeit und genau genug Struktur, um Fälle korrekt zu routen.
Die richtigen Essentials erfassen (und nichts Überflüssiges)
Beginne mit einem engen Feldset, das Garantieprüfung und RMA‑Prozess unterstützt:
- Kundendaten (Name, E‑Mail, Telefon, Adresse, falls Versand nötig)\n- Produktmodell, Seriennummer und Kaufdatum\n- Fehlerbeschreibung (ein kurzer Prompt hilft: „Was ist passiert? Wann begann es? Gibt es Fehlercodes?“)
Wenn du über Reseller verkaufst, füge ein Dropdown „Wo gekauft?“ hinzu und zeige ein „Beleg hochladen“‑Feld nur bei Bedarf.
Anhänge, die Technikern helfen zu handeln
Anhänge reduzieren Rückfragen, aber nur, wenn du Erwartungen setzt:
- Erlaube Fotos, kurze Videos und Uploads von Rechnungen/Belegen\n- Setze klare Dateityp‑ und Größenlimits (z. B. JPG/PNG/PDF, sowie ein Video‑Max)\n- Zeige Hinweise neben der Upload‑Schaltfläche („Foto vom Serienetikett“, „Video, das das Problem zeigt“)
Verwende einfache, spezifische Einverständnis‑Checkboxen (keine juristische Wüste). Zum Beispiel: Einwilligung zur Verarbeitung personenbezogener Daten zur Bearbeitung des Anspruchs und Einwilligung, Versanddaten mit Logistikpartnern zu teilen, falls Rücksendung nötig ist.
Verlinke auf /privacy-policy für die vollständigen Details.
Validierungsregeln, die schlechte Einsendungen verhindern
Gute Validierung lässt das Portal „smart“ erscheinen, nicht streng:
- Pflichtfelder nur dort, wo wirklich nötig\n- Formatprüfungen (E‑Mail, Telefon, Kaufdatum)\n- Seriennummern‑Patternprüfung, wo möglich
Wenn etwas falsch ist, erkläre es in einem Satz und behalte die vom Kunden eingegebenen Daten bei.
Garantieprüfung und Entscheidungsregeln
Validierungsregeln sind der Punkt, an dem deine App mehr ist als „ein Formular“ und zum Entscheidungswerkzeug wird. Gute Regeln reduzieren Rückfragen, beschleunigen Genehmigungen und sorgen für konsistente Ergebnisse über Agenten und Regionen hinweg.
Regeln zur Garantieberechtigung
Beginne mit klaren Prüfungen, die laufen, sobald eine Anfrage eingereicht wurde:
- Zeitraum: Berechne die Abdeckung vom Kaufdatum (oder Versanddatum) aus. Berücksichtige Sonderfälle wie „90 Tage ab Registrierung“ oder verlängerte Pläne.\n- Kaufnachweis: Akzeptiere Beleg‑Upload, Rechnungsnummer oder Händler‑Bestell‑ID. Wenn Nachweis fehlt, leite die Anfrage in eine „Benötigt Info“‑Queue, statt sie abzulehnen.\n- Seriennummernformat: Validere Länge/Präfix/Prüfziffer und blockiere unmögliche Werte. Wenn du mehrere Produktlinien hast, erkenne das Modell aus der Seriennummer und fülle Felder voraus.
Abdeckungslogik (was tatsächlich abgedeckt ist)
Trenne „berechtigt“ von „abgedeckt“. Ein Kunde kann im Zeitfenster liegen, aber das Problem kann ausgeschlossen sein.
Definiere Regeln für:
- Teile vs. Arbeit: Manche Garantien decken nur Teile; Arbeit wird kostenpflichtig.\n- Ausschlüsse: Verbrauchsteile, kosmetische Schäden, unsachgemäße Nutzung, unautorisierte Reparaturen.\n- Unfallschäden: Oft über einen separaten Plan oder kostenpflichtige Reparatur abgedeckt.\n- Regionale Unterschiede: Garantiebedingungen, Rücksendeadressen und rechtliche Formulierungen können je nach Land/Region variieren.
Halte diese Regeln konfigurierbar (nach Produkt, Region und Plan), damit Policy‑Änderungen kein Code‑Release benötigen.
Duplikaterkennung
Verhindere doppelte Tickets, bevor sie zu doppelten Sendungen werden:
- Markiere wiederholte Seriennummern innerhalb eines Zeitraums.\n- Erkenne wiederholte Kundenanfragen anhand von E‑Mail/Telefon + ähnlicher Fehlerkategorie.\n- Führe Fälle automatisch zusammen oder verlinke sie, und erhalte trotzdem die Audit‑Spur.
Eskalationsregeln
Automatisiere Eskalationen bei hohem Risiko:
- Sicherheitsrelevante Fälle (Rauch, Überhitzung, Stromschlag) sollten in eine Prioritäts‑Queue mit vordefinierten Schritten springen.\n- Wiederholte Ausfälle (z. B. dritter Anspruch für dieselbe Seriennummer/Modell) sollten eine Engineering‑Prüfung oder höherstufige Genehmigung auslösen.
Diese Entscheidungen sollten erklärbar sein: Jede Genehmigung, Ablehnung oder Eskalation braucht ein sichtbares „Warum“ für Agenten und Kunden.
Benutzerrollen, Berechtigungen und interne Queues
Eine Garantie‑Claims‑App steht und fällt damit, „wer darf was tun“ und wie Arbeit innerhalb deines Teams fließt. Klare Rollen verhindern versehentliche Änderungen, schützen Kundendaten und verhindern, dass Anfragen ins Stocken geraten.
Rollen und Berechtigungen definieren
Beginne mit einer Mindestmenge an Rollen, die dein Portal braucht:
- Kunde: Ansprüche erstellen, Belege/Fotos hochladen, Status sehen, Kostenvoranschläge genehmigen, Versand/Termindetails einsehen.\n- Agent: Einsendungen prüfen, fehlende Infos anfordern, Garantieergebnisse anwenden, Entscheidungen kommunizieren.\n- Techniker: Zugewiesene Reparaturaufträge einsehen, Diagnosen, verwendete Teile und Abschlussupdates (ohne sensible Zahlungsdaten, falls nicht nötig).\n- Admin: Regeln, Nutzerzugriffe, Templates, SLAs und Audit‑Logs verwalten.\n- Partner‑Service‑Center: Begrenzter Zugriff nur auf RMAs/Reparaturen, die diesem Partner zugewiesen sind, mit eingeschränkten Kundendaten.
Nutze Berechtigungsgruppen statt Einzelausnahmen und arbeite nach dem Least‑Privilege‑Prinzip.
Agent‑Queue planen (Filter, Zuordnung, Prioritäten, SLAs)
Dein Ticketing‑System braucht eine interne Queue, die sich wie ein Control‑Panel anfühlt: Filter nach Produktlinie, Anspruchstyp, Region, „Wartet auf Kunde“ und „Breach‑Risk“.
Füge Prioritätsregeln hinzu (z. B. Sicherheit zuerst), Auto‑Assignment (Round‑Robin oder skill‑basiert) und SLA‑Timer, die pausieren, wenn auf den Kunden gewartet wird.
Interne Notizen vs. kundensichtbare Kommentare
Trenne interne Notizen (Triage, Betrugssignale, Teilekompatibilität, Eskalationskontext) von kundensichtbaren Updates.
Mach die Sichtbarkeit vor dem Posten explizit und logge Änderungen.
Antwortvorlagen für Konsistenz
Erstelle Vorlagen für häufige Antworten: fehlende Seriennummer, außer‑Garantie‑Ablehnung, Genehmigung zur Reparatur, Versandanweisungen und Terminbestätigungen.
Erlaube Agents, Texte zu personalisieren, aber halte die Sprache konsistent und rechtskonform.
Kunden‑Statusverfolgung und Benachrichtigungen
Garantie vs. Service trennen
Generiere separate Abläufe für Garantieansprüche und bezahlten Service, damit Kunden richtig wählen.
Ein Garantie‑ oder Service‑Portal wirkt „einfach“, wenn Kunden nie raten müssen, was passiert. Statusverfolgung ist mehr als ein Label wie Offen oder Geschlossen — es ist die klare Erzählung, was als Nächstes passiert, wer handeln muss und wann.
Baue eine Statusseite, der man vertrauen kann
Erstelle eine dedizierte Statusseite für jeden Anspruch/Serviceantrag mit einer einfachen Timeline.
Jeder Schritt sollte in klarer Sprache erklären, was er bedeutet (und was der Kunde tun muss, falls überhaupt). Typische Meilensteine: Anfrage eingereicht, Artikel erhalten, Verifikation läuft, genehmigt/abgelehnt, Termin geplant, Reparatur abgeschlossen, verschickt/abholbereit, geschlossen.
Füge unter jedem Schritt „Was passiert als Nächstes“ hinzu. Wenn die nächste Aktion beim Kunden liegt (z. B. Kaufnachweis hochladen), mache diese Aktion zu einer prominenten Schaltfläche — nicht zu einer versteckten Notiz.
Updates zu den Momenten senden, die zählen
Automatische E‑Mail/SMS‑Updates reduzieren „Gibt’s Neuigkeiten?“-Anrufe und stimmen Erwartungen ab.
Trigger‑Nachrichten für Ereignisse wie:
- Wir haben Ihre Anfrage erhalten\n- Wir haben Ihren Artikel erhalten\n- Anspruch genehmigt/abgelehnt (mit Begründung und nächsten Schritten)\n- Service geplant/verschoben\n- Reparatur abgeschlossen / Ersatz genehmigt\n- Ticket geschlossen (mit Zusammenfassung)
Lass Kunden Kanäle und Frequenz wählen (z. B. SMS nur für Terminplanung). Halte Templates konsistent, nenne die Ticket‑Nummer und verlinke zurück zur Statusseite.
Ein Nachrichten‑Center mit Audit‑Trail
Integriere ein Nachrichten‑Center, damit Unterhaltungen am Fall hängen bleiben.
Unterstütze Anhänge (Fotos, Belege, Versandetiketten) und halte eine Audit‑Spur: wer was wann gesendet hat und welche Dateien hinzugefügt wurden. Das ist bei strittigen Entscheidungen sehr wertvoll.
Support‑Volumen mit kontextueller Hilfe reduzieren
Nutze kurze FAQs und kontextuelle Hilfen neben Formularfeldern, um schlechte Einsendungen zu verhindern: Beispiele für akzeptablen Kaufnachweis, wo die Seriennummer zu finden ist, Verpackungstipps und Erwartungszeiten.
Verlinke tiefergehende Anleitungen bei Bedarf (z. B. /help/warranty-requirements, /help/shipping).
Service‑Betrieb: Terminplanung, Versand und Reparaturen
Sobald ein Anspruch genehmigt (oder vorläufig angenommen) ist, muss die App „ein Ticket“ in echte Arbeit verwandeln: einen Termin, einen Versand, einen Reparaturauftrag und eine klare Abschlussdokumentation.
Hier scheitern viele Portale — Kunden bleiben stecken und Serviceteams landen wieder in Tabellen.
Terminplanung, die zur Realität passt
Unterstütze sowohl Vor‑Ort‑Einsätze als auch Depot/In‑Shop‑Reparaturen.
Das Scheduling‑UI sollte verfügbare Zeitfenster basierend auf Techniker‑Kalendern, Geschäftszeiten, Kapazitäten und Service‑Region anzeigen.
Ein praktikabler Ablauf: Kunde wählt Servicetyp → bestätigt Adresse/Ort → wählt Slot → erhält Bestätigung und Vorbereitungshinweise (z. B. „Kaufnachweis bereithalten“, „Daten sichern“, „Zubehör entfernen“).
Wenn du Dispatching nutzt, erlaube internen Benutzern, Techniker neu zuzuweisen, ohne den Kundentermin zu zerschießen.
Versand und Rücksendungen: RMA‑Abläufe ohne E‑Mail‑Hin‑und‑Her
Bei Depot‑Reparaturen mache Versand zur Kernfunktion:
- Generiere automatisch eine RMA‑Nummer und zeige sie prominent an.\n- Stelle druckbare Versandetiketten (oder Abholanfragen) und klare Verpackungshinweise bereit.\n- Zeige Inbound/Outbound‑Tracking‑Links, damit Kunden den Artikel verfolgen können, ohne anzurufen.
Intern sollte die App Schlüssel‑Scan‑Ereignisse verfolgen (Etikett erstellt, in Transit, erhalten, zurückgeschickt), damit dein Team in Sekunden beantworten kann „Wo ist es?“.
Teile‑ und Lager‑Touchpoints (optional, aber wertvoll)
Auch ohne volles Inventory‑System sind leichte Teilefunktionen nützlich:
- "Teile anfordern" pro Auftrag (mit Genehmigung, falls nötig)\n- Verfolgung der pro Reparatur verwendeten Teile für Kosten‑ und Garantieabrechnung\n- Rückstände und erwartete Lieferdaten vermerken
Wenn du ein ERP hast, kann das eine einfache Synchronisation statt eines neuen Moduls sein.
Abschlussdokumentation und sauberer Closeout
Eine Reparatur ist erst „fertig“, wenn sie dokumentiert ist.
Erfasse:
- Techniker‑Notizen (Befund, ausgetauschte Teile)\n- Fotos (Vorher/Nachher) als Anhänge\n- Kundenbestätigung: Unterschrift vor Ort oder eine In‑Portal‑Bestätigung „Service abgeschlossen"
Schließe mit einer klaren Zusammenfassung und nächsten Schritten (z. B. verbleibende Garantie, Rechnung bei außer‑Garantie) und einem Link zum Wieder‑Öffnen, falls das Problem wiedertritt.
Integrationen: CRM, ERP, Zahlungen und Logistik
Arbeitsablauf zuerst planen
Nutze den Planungsmodus, um Schritte, Verantwortliche und Ausnahmefälle zu skizzieren, bevor du Bildschirme generierst.
Integrationen machen aus einem weiteren Portal ein System, das dein Team tatsächlich betreiben kann. Ziel: doppelte Eingaben eliminieren, Fehler reduzieren und Kunden schneller durch den RMA‑Prozess bringen.
CRM / Helpdesk: ein Kunde, eine Konversation
Die meisten Firmen tracken Kundeninteraktionen bereits in einem CRM oder Helpdesk. Dein Portal sollte die wichtigen Daten synchronisieren, damit Agenten nicht in zwei Systemen arbeiten müssen:
- Erstelle oder aktualisiere ein Ticket, wenn ein Anspruch eingereicht wird (inkl. Anhänge, Seriennummer, gewünschtes Ergebnis).\n- Synchronisiere Statusänderungen in beide Richtungen (z. B. "Wartet auf Fotos", "Genehmigt", "Versandt", "Repariert", "Geschlossen").\n- Verknüpfe den Anspruch mit dem Kundenprofil, damit Supporthistorie bei Nachfragen sichtbar ist.
Wenn du bereits Workflows/Makros im Helpdesk nutzt, mappe interne Queues auf diese Zustände anstatt einen parallelen Prozess zu erfinden.
ERP / Bestelldaten: Kaufverifikation und Produktkataloge
Garantieprüfung hängt von verlässlichen Kauf‑ und Produktdaten ab. Eine leichte ERP‑Integration kann:
- Kaufnachweise anhand Bestellnummer, Kunden‑E‑Mail oder Rechnungs‑ID verifizieren\n- Produkt‑SKUs, Garantiebedingungen und zulässige Serviceoptionen liefern\n- Fehlzuordnungen verhindern (falsches Modell ausgewählt, ungültiges Serienformat, doppelte Ansprüche)
Auch wenn dein ERP unordentlich ist, beginne mit einer Read‑Only‑Verifikation und erweitere später auf Write‑Back (RMA‑Nummern, Servicekosten), sobald der Flow stabil ist.
Zahlungen für außer‑Garantie‑Arbeiten
Verbinde einen Zahlungsanbieter, um Kostenvoranschläge, Rechnungen und Zahlungslinks zu unterstützen.
Wichtige Details:
- Verknüpfe Zahlungen mit einer Claim‑ID und speichere die Transaktionsreferenz.\n- Unterstütze „zuerst zahlen, dann Termin“ oder „Angebot genehmigen, dann zahlen“ je nach Policy.\n- Mache Rückerstattungen/Anpassungen im Zeitstrahl explizit.
Logistik: Versandetiketten, Tracking und Ausnahmen
Logistik‑Integrationen reduzieren manuelle Etikettenerstellung und liefern automatische Tracking‑Updates.
Erfasse Tracking‑Events (zugestellt, Zustellversuch fehlgeschlagen, Retour an Absender) und leite Ausnahmen an eine interne Queue.
API‑Plan und Daten, die du offenlegst
Auch wenn du nur ein paar Integrationen startest, definiere früh ein Webhook/API‑Konzept:
- Webhooks für Events wie claim.created, claim.approved, shipment.created, payment.received.\n- Eine API zum Lesen von Claim‑Status und Schreiben von Notizen/Status‑Updates.\n- Klare Felddefinitionen (IDs, Timestamps, Status‑Enums), damit künftige Systeme ohne Rätselraten integrieren können.
Eine kleine Integrationsspezifikation jetzt verhindert teure Umbauten später.
Sicherheit, Datenschutz und Auditierbarkeit
Sicherheit ist kein "Später"‑Feature — sie formt, wie du Daten sammelst, speicherst und wer sie sehen darf.
Ziel: Kunden und dein Team schützen, ohne das Portal unbenutzbar zu machen.
Nur das sammeln, was nötig ist
Jedes zusätzliche Feld erhöht Risiko und Reibung. Frage nur die Mindestinfos ab, die zur Garantieprüfung und Weiterleitung nötig sind (z. B. Modell, Seriennummer, Kaufdatum, Kaufnachweis).\n
Wenn du sensible oder zusätzliche Daten verlangst, erkläre kurz und klar den Zweck („Wir nutzen Ihre Seriennummer, um die Garantieabdeckung zu prüfen“). Das reduziert Abbruchraten und Rückfragen.
Zugriffskontrolle und sichere Speicherung
Nutze rollenbasierten Zugriff, damit Personen nur das sehen, was sie brauchen:
- Kunden: nur eigene Tickets und Anhänge\n- Support‑Agenten: zugewiesene Queues; limitierter Zugriff auf Zahlungsdaten\n- Techniker: Reparaturdetails und Fotos, nicht Zahlungsdaten\n- Admins: Konfiguration und Reporting mit protokollierten erhöhten Aktionen
Verschlüssele Daten in Transit (HTTPS) und im Ruhezustand (Datenbank & Backups).
Speichere Uploads in sicherem Object‑Storage mit privaten Zugriffen und zeitlich begrenzten Download‑Links — nicht als öffentliche URLs.
Verlässliche Audit‑Logs
Garantieentscheidungen brauchen Nachvollziehbarkeit. Führe ein Audit‑Log, wer was wann und von wo geändert hat:
- Statusänderungen (Eingereicht → In Prüfung → Genehmigt/Abgelehnt)\n- Ergebnisse der Garantieprüfung und Regelversionen\n- Reparaturfreigaben (RMA erstellt, Etiketten ausgestellt)\n- Notiz‑Bearbeitungen und Anhangsaktionen
Mache Audit‑Logs append‑only und durchsuchbar, damit Streitfälle schnell geklärt werden können.
Aufbewahrungs‑ und Löschregeln
Definiere, wie lange du Kundendaten und Anhänge behältst und wie Löschungen (inkl. Backups) funktionieren.
Beispiel: Belege X Jahre aus Compliance‑Gründen, Fotos Y Monate nach Abschluss löschen. Stelle einen klaren Weg bereit, Kundenlöschanfragen zu erfüllen, soweit anwendbar.
Architektur‑ und Technologieauswahl (ohne Overengineering)
Eine Garantie‑Claims‑Web‑App braucht kein komplexes Microservices‑Setup, um gut zu funktionieren.
Beginne mit der einfachsten Architektur, die deinen Workflow unterstützt, Daten konsistent hält und sich leicht an Policy‑ oder Produktänderungen anpassen lässt.
Wähle einen Build‑Ansatz, der zu deiner Realität passt
Du hast typischerweise drei Wege:
- Bestehendes Helpdesk/Ticketing erweitern: Schnell, wenn du hauptsächlich ein Intake‑Portal, interne Queues und E‑Mail‑Updates brauchst. Kann jedoch unhandlich werden, wenn du Garantievalidierung, RMA‑Schritte oder Reparaturlogik hinzufügst.\n- Low‑Code: Gut, wenn dein Team Formulare, Status und Automationen schnell konfigurieren kann — ideal für frühe Versionen, aber achte auf Limits bei Integrationen und Reporting.\n- Custom Build: Sinnvoll, wenn Entscheidungsregeln, Integrationen (CRM/ERP/Logistik) und Datenhoheit wichtig sind. Ein einfacher Monolith mit sauberer Datenbank ist meist ein guter Start.
Wenn du schnell ein lauffähiges Prototyp (Form → Workflow → Statusseite) ausliefern und mit Stakeholdern iterieren willst, kann eine Plattform wie Koder.ai helfen, ein React‑Portal und ein Go/PostgreSQL‑Backend aus einem chatgetriebenen Spec zu generieren — und später den Quellcode zu exportieren.
Fang mit einem klaren, einfachen Datenmodell an
Die meisten Projekte gelingen, wenn die Kern‑Entitäten offensichtlich sind:
- Kunden (und Kontakte)\n- Produkte (mit Seriennummern, Kaufdaten, Beleg‑Dateien)\n- Ansprüche (die Anfrage selbst: Grund, Fotos, Notizen, Status)\n- Service‑Jobs (Reparaturereignisse, verwendete Teile, Techniker‑Notizen)\n- Nachrichten (threaded Kommunikation und Anhänge)
Design so, dass du einfache Fragen beantworten kannst: „Was ist passiert?“, „Was wurde entschieden?“ und „Welche Arbeit wurde ausgeführt?"
Mobile‑first UI und leichtes Admin‑Panel
Gehe davon aus, dass viele Nutzer vom Handy einreichen. Priorisiere schnelle Seiten, große Formularelemente und müheloses Foto‑Hochladen.
Halte Konfiguration aus dem Code heraus: baue ein kleines Admin‑Panel für Status, Grundcodes, Templates und SLAs.
Wenn das Ändern eines Statuslabels einen Entwickler erfordert, verlangsamt das den Prozess schnell.
Testen, Schulung und Launch‑Checklist
Prototyp in einer Sitzung
Erstelle zuerst einen Prototyp des Anfrageformulars und der Statusseite, dann iteriere mit echten Nutzern.
Eine Garantie‑Claims‑App live zu stellen heißt nicht nur „funktioniert“. Es bedeutet, dass echte Kunden in zwei Minuten eine Anfrage abschicken können, dein Team sie ohne Rätsel bearbeiten kann und bei Lastspitzen nichts zusammenbricht.
Eine kurze, praktische Checkliste spart dir Wochen Nacharbeit.
Bevor du alle Integrationen baust, prototypisiere die zwei wichtigsten Bildschirme:
- das Anspruchs-/Service‑Formular\n- die Anspruchs‑Statusseite (was der Kunde nach Einreichung sieht)
Teste den Prototyp mit realen Nutzern (Kunden und intern) in 30‑min Sessions.
Beobachte, wo sie zögern: Seriennummer? Upload‑Schritt? „Kaufdatum“‑Feld? Genau dort entscheidet sich, ob Formulare funktionieren oder abbrechen.
Edge‑Cases testen, die Support‑Tickets erzeugen
Die meisten Fehler passieren in der "unordentlichen Realität", nicht im Happy‑Path.
Teste explizit:
- Fehlender Kaufnachweis (welche Optionen hat der Kunde?)\n- Falsche Seriennummernformate (validiert ihr und zeigt hilfreiche Fehlermeldungen?)\n- Große Anhänge und langsame Verbindungen\n- Spam und wiederholte Einsendungen (Rate‑Limiting, CAPTCHA, E‑Mail‑Verifikation)
Teste auch Entscheidungsfälle: Garantieprüfung, Reparaturfreigabe (RMA‑Prozess) und was bei Ablehnung passiert — bekommt der Kunde eine klare Begründung und nächste Schritte?
Staging‑Umgebung und Release‑Checklist
Nutze eine Staging‑Umgebung, die Produktionseinstellungen spiegelt (E‑Mail‑Versand, Dateispeicher, Berechtigungen), ohne echte Kundendaten zu verwenden.
Führe bei jedem Release eine kurze Checkliste durch:
- Formulareinreichung, Bestätigungs‑E‑Mail und Ticketerstellung\n- Statusupdates und Kundenbenachrichtigungen\n- Interne Queues und rollenbasierter Zugriff (Support vs. Techniker)\n- Dateibehandlung und Virenscan (falls aktiviert)\n- Audit‑Log‑Einträge für Schlüsselaktionen (Genehmigen/Ablehnen, RMA ausgestellt, Rückerstattung verarbeitet)
So wird jeder Deploy planbar statt ein Glücksspiel.
Support und Techniker schulen (und es einfach machen)
Schulung sollte sich auf den Workflow konzentrieren, nicht auf UI‑Knöpfe.
Stelle bereit:
- Eine einseitige Schnellhilfe pro Rolle (Support, Lager, Reparaturtechniker)\n- Eine Bibliothek von Standardantworten für übliche Szenarien (fehlender Beleg, außer‑Garantie, Versandanweisungen)\n- Klare "Definition of Done" für jeden Queue‑Status
Wenn dein Team Statuslabels nicht einem Kunden erklären kann, sind die Labels das Problem. Behebe das vor dem Launch.
Analytics, Reporting und kontinuierliche Verbesserung
Analytics ist kein „Nice‑to‑have“ — es ist, wie du das Portal für Kunden schnell und für dein Team vorhersehbar hältst.
Baue Reporting um den realen Flow: was Kunden versuchen, wo sie stecken bleiben und was nach Einreichung passiert.
Funnel‑Metriken: abgebrochene Anfragen reduzieren
Beginne mit Funnel‑Tracking, das beantwortet: „Kommen Leute durch das Formular?“
Miss:
- Gestartet vs. abgeschickte Anfragen (gesamt und nach Gerätetyp)\n- Drop‑off‑Schritt (z. B. Seriennummer, Kaufnachweis, Fotos)\n- Abbruchsgründe per kurzer Nachfrage wie „Was hat Sie gestoppt?“ (fehlende Info, unklare Richtlinie, zu viele Felder)
Wenn du hohe Abbrüche auf Mobilgeräten siehst, brauchst du weniger Pflichtfelder, besseren Foto‑Upload UX oder klarere Beispiele.
Operative Kennzahlen: Serviceleistung verbessern
Operative Reports helfen, das Ticketing zu steuern:
- Time to first response (nach Queue, Produktlinie, Priorität)\n- Time to resolution (inkl. Reparaturfreigabe/RMA‑Schritte)\n- Reopen‑Rate (starker Hinweis, dass Ergebnisse oder Anweisungen nicht klar waren)
Mache diese Metriken wöchentlich Team‑Leads sichtbar, nicht nur quartalsweise.
Füge strukturierte Tags/Grundcodes zu jedem Anspruch hinzu (z. B. "Akkuschwellung", "Displaydefekt", "Versandschaden").
Mit der Zeit zeigen sich Muster: bestimmte Chargen, Regionen oder Ausfallarten. Diese Erkenntnisse können künftige Ansprüche reduzieren durch Verpackungsänderungen, Firmware‑Fixes oder bessere Anleitung.
Kontinuierliche Verbesserungs‑Schleife (und teile sie)
Behandle das Portal wie ein Produkt. Führe kleine Experimente (Feldreihenfolge, Formulierungen, Attachment‑Anforderungen), miss den Effekt und führe ein Changelog.
Erwäge eine öffentliche Roadmap oder Update‑Seite (z. B. /blog), um Verbesserungen zu teilen — Kunden schätzen Transparenz und das reduziert wiederholte Fragen.