29. Nov. 2025·8 Min
Wie man eine Web‑App zum Verwalten von Kunden‑Feedback‑Schleifen baut
Lernen Sie, wie Sie eine Web‑App entwerfen und bauen, die Kundenfeedback sammelt, weiterleitet, nachverfolgt und Feedback‑Schleifen mit klaren Workflows, Rollen und Metriken schließt.
Ziel klären: Was eine Feedback‑Schleife liefern sollte
Eine Feedback‑Management‑App ist nicht nur „ein Ort, um Nachrichten zu speichern“. Sie ist ein System, das Ihrem Team zuverlässig hilft, von Eingabe zu Aktion zu kundensichtbarer Nachverfolgung zu gelangen — und dann aus dem Ergebnis zu lernen.
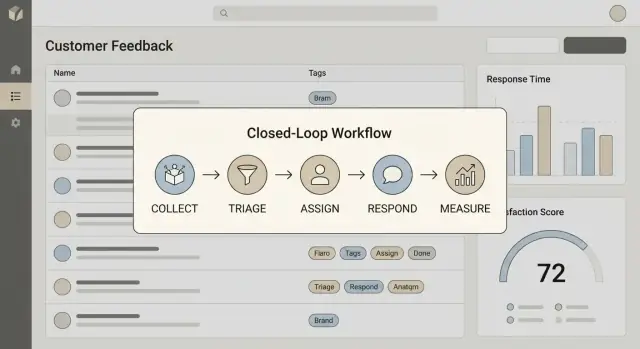
Definieren Sie, was „Schließen der Schleife“ bedeutet
Formulieren Sie einen Ein‑Satz, den Ihr Team wiederholen kann. Für die meisten Teams umfasst das Schließen der Schleife vier Schritte:
- Sammeln: Feedback mit genug Kontext erfassen (wer, was, woher)
- Handeln: Daraus Arbeit oder eine Entscheidung machen (fixen, ausliefern, erklären oder ablehnen)
- Antworten: Dem Kunden eine klare Rückmeldung mit Zeitrahmen geben (auch wenn es „noch nicht“ heißt)
- Lernen: Ergebnisse in Priorisierung, Produktentdeckung und Support‑Playbooks zurückspeisen
Wenn einer dieser Schritte fehlt, wird Ihre App zur Grabstätte für Backlogs.
Identifizieren Sie die Hauptnutzer und deren Bedürfnisse
Ihre erste Version sollte reale Alltagsrollen bedienen:
- Support: schnelle Triage, Statusklarheit, Vorlagen für Antworten
- Produkt: Trends, Impact, Links zur Roadmap‑Arbeit
- Customer Success: Sichtbarkeit für Accounts, proaktive Updates
- Admins: Konfiguration, Datenhygiene, Zugriffskontrolle
- Endkunden (optional): Bestätigung, Updates, Self‑Service‑Status
Listen Sie die Entscheidungen auf, die Ihre App unterstützen muss
Seien Sie konkret bei den „Entscheidungen pro Klick“:
- Worum geht es bei diesem Feedback (Tag/Kategorie)?
- Wer verantwortet es und was ist der nächste Schritt?
- Was ist der aktuelle Status und was hat sich seit letzter Woche geändert?
- Welche Antwort senden wir und wann?
Legen Sie messbare Ergebnisse fest (damit Sie wissen, ob es funktioniert)
Wählen Sie eine kleine Menge Metriken, die Geschwindigkeit und Qualität widerspiegeln, z. B. Zeit bis zur ersten Antwort, Abschlussrate und CSAT‑Änderung nach Nachverfolgung. Diese werden Ihr Nordstern für spätere Designentscheidungen.
Mappen Sie die Feedback‑Journey und das Datenmodell
Bevor Sie Bildschirme entwerfen oder eine Datenbank wählen, kartieren Sie, was mit Feedback passiert vom Moment der Erstellung bis zur Antwort. Eine einfache Journey‑Map hält Teams auf einen Nenner, was „fertig“ bedeutet, und verhindert, dass Sie Features bauen, die zur realen Arbeit nicht passen.
Beginnen Sie mit den Quellen, dann normalisieren
Listen Sie Ihre Feedback‑Quellen auf und notieren Sie, welche Daten jede zuverlässig liefert:
- In‑App‑Widget (enthält oft Nutzer-/Session‑Kontext)
- E‑Mail (threaded Nachrichten, Anhänge)
- Chat (Timestamps, Agent‑Info)
- Webformular (strukturierte Felder)
- App‑Store‑Reviews (öffentlicher Text, Bewertung)
- Umfragen (Scores plus Freitext)
Auch wenn Eingaben unterschiedlich sind, sollte Ihre App sie in eine konsistente „Feedback‑Item“‑Form normalisieren, damit Teams alles an einem Ort triagieren können.
Definieren Sie Kern‑Entitäten (und halten Sie sie langweilig)
Ein praktisches erstes Modell beinhaltet meistens:
- Customer: die Person, die Feedback gibt
- Account: das Unternehmen/Organisation (optional bei B2C)
- Feedback‑Item: der Hauptdatensatz (Nachricht, Quelle, Metadaten)
- Tag: Kategorisierung (z. B. „Abrechnung“, „Bug“, „Feature‑Request")
- Status: wo es im Workflow steht
- Zuweisung: wer den nächsten Schritt übernimmt (Person/Team)
- Reply: ausgehende Nachrichten, die mit dem Feedback‑Item verknüpft sind (optional Thread)
Empfohlene Start‑Status: Neu → Triagiert → Geplant → In Bearbeitung → Freigegeben → Geschlossen. Halten Sie die Bedeutungen schriftlich, damit „Geplant" nicht für ein Team „Vielleicht" und für ein anderes „Fest eingeplant" heißt.
Entscheiden Sie, was „Duplikat“ bedeutet
Duplikate sind unvermeidlich. Definieren Sie Regeln frühzeitig:
- Wann sind zwei Items Duplikate: gleiche Grundursache, gleiche Feature‑Anfrage oder gleiche Schlüsselwörter?
- Was macht das Zusammenführen: Tags kombinieren, beide Kunden behalten, Antworten verschieben?
Ein gängiger Ansatz ist, ein kanonisches Feedback‑Item zu behalten und andere als Duplikate zu verlinken, dabei die Attribution (wer gefragt hat) zu erhalten, ohne die Arbeit zu fragmentieren.
Entwerfen Sie die Kern‑User‑Flows (Inbox → Triage → Aktion → Antwort)
Eine Feedback‑Loop‑App steht oder fällt am ersten Tag damit, ob Leute Feedback schnell verarbeiten können. Ziel ist ein Flow, der sich anfühlt wie: „überfliegen → entscheiden → weitermachen“, und dabei Kontext für spätere Entscheidungen bewahrt.
1) Inbox: schnelles Überfliegen mit den richtigen Filtern
Ihre Inbox ist die gemeinsame Queue des Teams. Sie sollte schnelle Triage durch eine kleine Anzahl leistungsfähiger Filter unterstützen:
- Quelle (In‑App, E‑Mail, Chat, App‑Store, Verkaufsnotizen)
- Tag (Abrechnung, Bug, Feature‑Request, Onboarding)
- Status (neu, triagiert, in Bearbeitung, freigegeben, beantwortet)
- Priorität (niedrig → dringend)
- Kundentyp (free, pro, enterprise)
Fügen Sie früh „Gespeicherte Ansichten“ hinzu (auch wenn sie einfach sind), weil verschiedene Teams unterschiedlich scannen: Support will „dringend + zahlender Kunde“, Produkt will „Feature‑Requests + hoher ARR".
2) Detailansicht: alles, was nötig ist, um zu entscheiden
Wenn ein Nutzer ein Item öffnet, sollte er sehen:
- Volle Historie des Feedbacks (Originaltext plus Änderungen, Merges und Status‑Änderungen)
- Kundenkontext (Tarif, Account‑Wert, Firma, zuletzt gesehen, NPS/CSAT falls vorhanden)
- Einen Konversationsthread, der Antworten und interne Notizen trennt
Ziel ist, Tab‑Wechsel zu vermeiden, nur um zu beantworten: „Wer ist das, was meinte er, und haben wir schon geantwortet?"
3) Triage‑Aktionen: leichtgewichtig, aber vollständig
Aus der Detailansicht sollte Triage eine Entscheidung pro Klick ermöglichen:
- Taggen und Priorität setzen
- Zuweisen eines Owners (oder Team‑Queue)
- Duplikate mergen (mit einem kanonischen Item)
- Verknüpfen mit einem Feature/Issue, damit Arbeit mit Kundenrealität verbunden bleibt
4) Antwort: extern vs. intern entscheiden
Wahrscheinlich benötigen Sie zwei Modi:
- Nur intern (bei den meisten B2B‑Teams): Status und Notizen sind privat; Kunden erhalten direkte Antworten bei Updates.
- Kundenöffentliche Statusseite: Nützlich, wenn Sie Transparenz in großem Maßstab wollen (öffentliches Changelog‑Stil). Machen Sie es optional und streng kuratiert.
Egal, was Sie wählen: Machen Sie „Antwort mit Kontext" zum letzten Schritt — so ist das Schließen der Schleife Teil des Workflows, nicht eine Nachgedanke.
Planen Sie Rollen, Berechtigungen und Sicherheitsgrundlagen
Eine Feedback‑App wird schnell zum gemeinsamen System of Record: Produkt will Themen, Support schnelle Antworten, Führung Exporte. Wenn Sie nicht definieren, wer was darf (und beweisen kann, was passiert ist), bricht Vertrauen zusammen.
Beginnen Sie mit Multi‑Tenant‑Grenzen
Wenn Sie mehrere Firmen bedienen, behandeln Sie jeden Workspace/Org als harte Grenze von Anfang an. Jeder Kerndatensatz (Feedback‑Item, Kunde, Konversation, Tags, Reports) sollte ein workspace_id enthalten, und jede Abfrage sollte darauf begrenzt werden.
Das ist nicht nur eine Datenbank‑Entscheidung — es beeinflusst URLs, Einladungen und Analytics. Eine sichere Vorgabe: Benutzer gehören zu einem oder mehreren Workspaces, und ihre Berechtigungen werden pro Workspace ausgewertet.
Definieren Sie Rollen, die zur realen Arbeit passen
Halten Sie die erste Version einfach:
- Admin: verwaltet Workspace‑Einstellungen, Abrechnung, Integrationen und Rollen
- Manager: konfiguriert Kategorien/Routing, Bulk‑Aktionen, sieht Reports, exportiert
- Agent: triagiert Items, weist zu, kommentiert und antwortet an Kunden
Mappen Sie Berechtigungen auf Aktionen, nicht auf Bildschirme: view vs. edit feedback, merge duplicates, status ändern, Daten exportieren und Antworten senden. So lassen sich später Rollen wie „Read‑only“ einfacher hinzufügen.
Fügen Sie früh ein Audit‑Log hinzu
Ein Audit‑Log verhindert „Wer hat das geändert?“-Debatten. Loggen Sie wichtige Ereignisse mit Actor, Timestamp und Before/After, wo hilfreich:
- Zuweisungsänderungen
- Status‑Updates und Merges
- Tag/Kategorie‑Bearbeitungen
- Gesendete Kundenantworten
Basis‑Sicherheit, die nicht ausbremst
Erzwingen Sie eine vernünftige Passwort‑Policy, schützen Sie Endpoints mit Rate‑Limiting (besonders Login und Ingestion) und sichern Sie Session‑Handling.
Planen Sie SSO (SAML/OIDC) ein, auch wenn Sie es später ausliefern: speichern Sie eine Identity‑Provider‑ID und planen Sie Account‑Linking. Das verhindert, dass Enterprise‑Anfragen später eine schmerzhafte Refaktorierung erzwingen.
Wählen Sie eine Architektur, die zur ersten Version passt
Früh ist das größte Architektur‑Risiko nicht „skaliert es?“, sondern „können wir es schnell ändern, ohne alles kaputt zu machen?" Eine Feedback‑App entwickelt sich schnell, während Sie lernen, wie Teams triagieren, routen und antworten.
Starten Sie simpel: ein Monolith mit klaren Grenzen
Ein modularer Monolith ist oft die beste Erstwahl. Sie haben einen deploybaren Service, ein Log‑Set und einfacheres Debugging — und können trotzdem den Code organisiert halten.
Eine praktische Modulaufteilung sieht so aus:
- Auth & Orgs: Users, Teams, SSO später
- Feedback: Quellen, Submissions, Anhänge, Tags
- Workflow: Triage‑Status, Routing‑Regeln, Zuweisungen
- Messaging: ausgehende Antworten, Vorlagen, Audit‑Trail
- Analytics: Reports, Exporte, Dashboards
Denken Sie „separate Ordner & Interfaces“ bevor Sie „separate Services“ machen. Wenn eine Grenze später schmerzhaft wird (z. B. bei hoher Ingestions‑Last), können Sie sie leichter extrahieren.
Wählen Sie einen Stack, den Ihr Team pflegen kann
Nehmen Sie Frameworks und Bibliotheken, mit denen Ihr Team sicher ausliefern kann. Ein „langweiliger“, bekannter Stack gewinnt meist, weil:
- Recruiting und Onboarding leichter sind
- Upgrades vorhersagbarer sind
- Debugging in Production schneller geht
Neues Tooling kann warten, bis echte Einschränkungen auftreten (hohe Ingestionsrate, strikte Latenzanforderungen, komplexe Berechtigungen). Bis dahin optimieren Sie für Klarheit und stetiges Liefern.
Datenspeicherung: relational zuerst, Suche später
Die meisten Kern‑Entitäten — Feedback‑Items, Kunden, Accounts, Tags, Zuweisungen — passen natürlich in eine relationale Datenbank. Sie benötigen gute Abfragen, Constraints und Transaktionen für Workflow‑Änderungen.
Wenn Volltextsuche wichtig wird, fügen Sie später einen Suchindex hinzu (oder nutzen zunächst eingebaute DB‑Funktionen). Vermeiden Sie, zu früh zwei Wahrheiten (two sources of truth) zu schaffen.
Verwenden Sie Background‑Jobs, wo Nutzer nicht warten sollten
Ein Feedback‑System sammelt schnell „mach das später“‑Arbeit: E‑Mails senden, Integrationen syncen, Anhänge verarbeiten, Digests generieren, Webhooks feuern. Packen Sie das von Anfang in eine Queue/Background‑Worker‑Infrastruktur.
Das hält die UI reaktiv, reduziert Timeouts und macht Fehler retrybar — ohne Sie am ersten Tag in Microservices zu treiben.
Schneller Weg zu einem MVP (wenn Sie schneller bewegen wollen)
Wenn Ihr Ziel ist, Workflow und UI schnell zu validieren (Inbox → Triage → Antworten), überlegen Sie, eine Vibe‑Coding‑Plattform wie Koder.ai zu nutzen, um die erste Version aus einer strukturierten Chat‑Spezifikation zu generieren. Sie kann helfen, ein React‑Frontend mit einem Go + PostgreSQL‑Backend aufzusetzen, im „Planungsmodus" zu iterieren und den Quellcode zu exportieren, wenn Sie zu einem klassischen Engineering‑Workflow übergehen wollen.
Implementieren Sie Storage: Schema, Indexe und Aufbewahrungsregeln
Mehrmandantenfähig von Anfang an
Erstelle schnell Workspace-Grenzen und Rollenprüfungen mit von Koder.ai generierten Mustern.
Ihre Storage‑Schicht entscheidet, ob die Feedback‑Schleife sich schnell und vertrauenswürdig oder langsam und verwirrend anfühlt. Zielen Sie auf ein Schema, das leicht für die tägliche Arbeit (Triage, Zuweisung, Status) abfragbar ist und dennoch genug Rohdetails für Audits bewahrt.
Ein praktisches Start‑Datenmodell
Für ein MVP decken Sie die meisten Bedürfnisse mit einer kleinen Menge Tabellen/Collections ab:
- workspaces: account‑level Container (Tarif, Einstellungen, Retention‑Policy)
- users: Teammitglieder (Rolle, workspace_id)
- customers: Endnutzer/Organisationen (E‑Mail, external_id, workspace_id)
- feedback: Hauptdatensatz (Titel, Text/Summary, Status, Priorität, Quelle, customer_id, assigned_to, created_at)
- tags: normalisierte Tag‑Definitionen (Name, Farbe, workspace_id)
- feedback_tags (Join): feedback_id ↔ tag_id
- events: append‑only Timeline (Status‑Änderungen, Zuweisungen, Merges, Notizen)
- replies: ausgehende Antworten (Kanal, Nachricht, sent_at, feedback_id, customer_id)
Eine nützliche Regel: Halten Sie feedback schlank (das, was Sie ständig abfragen) und schieben Sie „alles andere“ in events und kanal‑spezifische Metadaten.
Speichern Sie rohe Payloads zur Nachvollziehbarkeit
Wenn ein Ticket per E‑Mail, Chat oder Webhook eintrifft, speichern Sie die rohe eingehende Payload genau so, wie sie empfangen wurde (z. B. originale E‑Mail‑Header + Body oder Webhook‑JSON). Das hilft Ihnen:
- Parsing‑Probleme zu debuggen („Warum wurde das Subject abgeschnitten?")
- zu beweisen, was empfangen wurde, wenn es Streit gibt
- alte Daten nachzuverarbeiten, nachdem Sie Ihren Parser verbessert haben
Gängiges Muster: eine ingestions‑Tabelle mit source, received_at, raw_payload (JSON/Text/Blob) und einem Link zur erstellten/aktualisierten feedback_id.
Indexieren Sie für die Abfragen, die Leute tatsächlich ausführen
Die meisten Screens reduzieren sich auf wenige vorhersehbare Filter. Fügen Sie früh Indexe hinzu für:
(workspace_id, status)für Inbox/Kanban‑Views(workspace_id, assigned_to)für „meine Items“(workspace_id, created_at)für Sortierung und Datumsfilter- Tags: entweder
(tag_id, feedback_id)auf der Join‑Tabelle oder ein dedizierter Tag‑Lookup‑Index
Wenn Sie Volltextsuche unterstützen, denken Sie an einen separaten Suchindex (oder die eingebaute Text‑Suche Ihrer DB), statt komplexe LIKE‑Queries in Produktion zu stapeln.
Aufbewahrung, Löschung und „Right to be forgotten"
Feedback enthält oft personenbezogene Daten. Entscheiden Sie im Vorhinein:
- Wie lange die rohen Payloads aufbewahrt werden (häufig kürzer als normalisierte Feedback‑Daten)
- Wie mit GDPR‑Löschanfragen umgegangen wird (löschen oder anonymisieren von Kunden‑IDs und Redaktion roher Payloads)
- Was passiert, wenn ein Kunde offboardet (Export + zeitgesteuerte Löschung)
Implementieren Sie Retention als Policy pro Workspace (z. B. 90/180/365 Tage) und erzwingen Sie sie mit einem geplanten Job, der zuerst rohe Ingestions löscht und dann ältere Events/Replies, falls nötig.
Bauen Sie Ingestion: Feedback aus mehreren Kanälen erfassen
Ingestion ist der Punkt, an dem Ihre Feedback‑Schleife entweder sauber und nützlich bleibt — oder zu einem chaotischen Haufen wird. Zielen Sie auf „einfach zu senden, konsistent zu verarbeiten“. Starten Sie mit einigen Kanälen, die Ihre Kunden bereits nutzen, und erweitern Sie dann.
Erfassungsoptionen, die Sie früh liefern sollten
Eine praktische erste Auswahl umfasst:
- In‑App‑Widget: Ein kleines Formular für Ideen und Probleme (optional Screenshot anhängen). Minimal halten: Nachricht, Kategorie, E‑Mail.
- API‑Endpoint: Interne Tools oder Partner können Feedback programmgesteuert senden. Bevorzugen Sie ein einfaches JSON‑Schema und einen API‑Key pro Workspace.
- E‑Mail‑Ingestion: Eine eindeutige Adresse pro Workspace (z. B. feedback+acme@…). Parsen Sie Subject/Body und behalten Sie die rohe E‑Mail zur Auditierung.
- CSV‑Import: Nützlich für Migrationen und Research‑Batches. Validieren Sie Spalten und bieten Sie eine Vorschau vor dem Import.
Spam‑ und Qualitätskontrollen
Am ersten Tag benötigen Sie kein schwergewichtiges Filtering, aber grundlegenden Schutz:
- CAPTCHA für öffentliche Widget‑Einsendungen
- Textlimits (z. B. 5–5.000 Zeichen) und Größenlimits für Anhänge
- Duplikat‑Erkennungs‑Hinweise: Hash der normalisierten Nachricht + Produktbereich oder „near duplicate“‑Erkennung durch ähnliche Subjects. Nicht automatisch löschen; als „möglicherweise Duplikat“ markieren.
Normalisieren Sie Eingaben, damit die Downstream‑Arbeit konsistent ist
Normalisieren Sie jedes Event in ein internes Format mit konsistenten Feldern:
- Quelle (widget, API, email, CSV)
- Kunden‑IDs (workspace, account_id, contact_email, plan)
- Produktbereich (Abrechnung, Onboarding, Mobile etc.)
Behalten Sie sowohl die rohe Payload als auch den normalisierten Datensatz, damit Sie das Parsen später verbessern können, ohne Daten zu verlieren.
Auto‑Bestätigung, die Erwartungen setzt
Senden Sie eine sofortige Bestätigung (bei E‑Mail/API/Widget wenn möglich): bedanken Sie sich, erklären Sie, was als Nächstes passiert, und vermeiden Sie Versprechungen. Beispiel: „Wir prüfen jede Nachricht. Falls wir mehr Details brauchen, melden wir uns. Wir können nicht jede Anfrage individuell beantworten, aber Ihr Feedback wird nachverfolgt."
Erstellen Sie ein Triage‑ und Routing‑System, das skaliert
Audit-Logs schnell hinzufügen
Modelliere Ereignisse und Zeitachsen in Koder.ai, damit jede Statusänderung nachvollziehbar ist.
Eine Feedback‑Inbox bleibt nur dann nützlich, wenn Teams schnell drei Fragen beantworten können: Was ist das? Wer besitzt es? Wie dringend ist es? Triage verwandelt rohe Nachrichten in organisierte Arbeit.
Beginnen Sie mit einem kontrollierten Tagging‑System
Freie Tags wirken zunächst flexibel, fragmentieren aber schnell („login", „log‑in", „signin"). Beginnen Sie mit einer kleinen, kontrollierten Taxonomie, die widerspiegelt, wie Ihre Produktteams bereits denken:
- Produktbereich (Abrechnung, Mobile, Admin)
- Thema (Bug, Feature‑Request, UX‑Problem)
- Impact (Blocker, Hoch, Normal)
Erlauben Sie Nutzern, neue Tags vorzuschlagen, aber verlangen Sie einen Owner (z. B. PM/Support‑Lead) zur Freigabe. So bleibt Reporting später aussagekräftig.
Nutzen Sie Auto‑Triage‑Regeln, um manuelle Sortierung zu reduzieren
Bauen Sie eine einfache Regel‑Engine, die Feedback basierend auf vorhersehbaren Signalen automatisch routet:
- Keyword/Intent: „refund“, „cancel“, „invoice" → Billing‑Queue
- Plan/Account‑Tier: Enterprise → Prioritäts‑Queue
- Produktbereich: aus URL‑Pfad, App‑Modul oder gewählter Kategorie abgeleitet
Machen Sie Regeln transparent: zeigen Sie „Weitergeleitet weil: Enterprise‑Plan + Keyword 'SSO'". Teams vertrauen Automation, wenn sie sie auditieren können.
SLA‑Sichtbarkeit, nicht Versteckspiel
Fügen Sie SLA‑Timer zu jedem Item und jeder Queue hinzu:
- Zeit bis zur ersten Antwort (wie schnell Sie bestätigen)
- Zeit bis zum Abschluss (wie schnell Sie lösen oder abschließen)
Zeigen Sie SLA‑Status in der Listenansicht („2h verbleibend") und auf der Detailseite, damit Dringlichkeit im Team geteilt wird — nicht in einer einzelnen Person sitzt.
Eskalationen und Erinnerungen in den Workflow bauen
Erstellen Sie einen klaren Pfad, wenn Items stocken: eine Überfällig‑Queue, tägliche Digests an Owner und eine leichte Eskalationsleiter (Support → Teamlead → On‑Call/Manager). Ziel ist nicht Druck, sondern zu verhindern, dass wichtiges Kundenfeedback stillschweigend verfällt.
Die Schleife schließen: Arbeit mit Kunden‑Antworten verbinden
Das Schließen der Schleife macht ein Feedback‑Management‑System aus einer „Sammelbox" zu einem vertrauensbildenden Werkzeug. Ziel ist einfach: Jedes Feedback kann mit realer Arbeit verbunden werden, und Kunden können informiert werden — ohne manuelle Tabellen.
Feedback mit interner Arbeit verknüpfen
Ermöglichen Sie zunächst, dass ein Feedback‑Item auf ein oder mehrere interne Arbeitselemente zeigt (Bug, Task, Feature). Versuchen Sie nicht, Ihren ganzen Issue‑Tracker zu spiegeln — speichern Sie leichte Referenzen:
work_type(z. B. issue/task/feature)external_system(z. B. jira, linear, github)external_idund optionalexternal_url
So bleibt Ihr Datenmodell stabil, auch wenn Sie später Tools wechseln. Es ermöglicht zudem Ansichten wie „zeige mir sämtliches Kundenfeedback zu diesem Release", ohne ein anderes System zu scrapen.
Definieren Sie einen „Freigegeben"‑Workflow, der alle informiert
Wenn verknüpfte Arbeit Freigegeben (oder Done/Released) wird, sollte Ihre App alle Kunden benachrichtigen können, die mit den zugehörigen Feedback‑Items verknüpft sind.
Nutzen Sie eine vorgefertigte Vorlage mit sicheren Platzhaltern (Name, Produktbereich, Zusammenfassung, Link zu Release‑Notes). Lassen Sie die Nachricht vor dem Versand editierbar, um peinliche Formulierungen zu vermeiden. Wenn Sie öffentliche Notizen haben, verlinken Sie relativ wie /releases.
Antwortkanäle und Tracking
Unterstützen Sie Antworten über Kanäle, die Sie zuverlässig senden können:
- E‑Mail
- In‑App‑Benachrichtigung
- Webhook an Ihr Messaging‑System
Verfolgen Sie Antworten pro Feedback‑Item mit einer auditfreundlichen Timeline: sent_at, channel, author, template_id und Zustellstatus. Wenn ein Kunde zurückantwortet, speichern Sie eingehende Nachrichten mit Timestamps, damit Ihr Team beweisen kann, dass die Schleife tatsächlich geschlossen wurde — und nicht nur als „freigegeben" markiert wurde.
Reporting hinzufügen, das Teams hilft, Entscheidungen zu treffen
Reporting ist nur nützlich, wenn es das Verhalten der Teams ändert. Zielen Sie auf wenige Views, die Leute täglich prüfen können, und erweitern Sie, wenn die zugrunde liegenden Workflow‑Daten (Status, Tags, Owner, Timestamps) konsistent sind.
Dashboards, die „was braucht Aufmerksamkeit?“ beantworten
Beginnen Sie mit operativen Dashboards, die Routing und Nachverfolgung unterstützen:
- Volumen nach Quelle (E‑Mail, In‑App, Social, Calls): Kanalverschiebungen und Personalbedarf erkennen
- Top‑Tags / Kategorien: welche Themen diese Woche steigen
- Backlog nach Status (neu, triagiert, in Bearbeitung, wartet auf Kunde, geschlossen): wo Arbeit steckt
- SLA‑Einhaltung: Zeit bis zur ersten Antwort und Zeit‑bis‑Schluss im Vergleich zu Targets
Halten Sie Charts einfach und klickbar, damit ein Manager in die genauen Items hinter einem Spike drillen kann.
Kunden‑Level‑Ansicht für bessere Gespräche
Fügen Sie eine „Customer 360“ Seite hinzu, die Support und Success hilft, mit Kontext zu antworten:
- sämtliches Feedback dieses Kunden über Kanäle hinweg
- Letzter Kontakt und wer geantwortet hat
- Offene Items und aktueller Status/Owner
- Platz für leichte Sentiment‑Notizen (z. B. „frustriert wegen Abrechnung; bevorzugt E‑Mail") — kein Black‑Box‑Score
Diese Ansicht reduziert doppelte Fragen und macht Nachverfolgungen bewusst.
Exportieren, ohne Vertrauen zu zerstören
Teams werden früh Exporte verlangen. Bieten Sie an:
- CSV‑Export, der dieselben Filter wie die UI respektiert
- Read‑only API‑Endpoints für Reporting/BI
Machen Sie Filter überall konsistent (gleiche Tag‑Namen, Datumsbereiche, Status‑Definitionen). Diese Konsistenz verhindert „zwei Wahrheiten".
Vermeiden Sie Vanity‑Metriken
Überspringen Sie Dashboards, die nur Aktivität messen (Tickets erstellt, Tags hinzugefügt). Bevorzugen Sie Outcome‑Metriken, die mit Aktion und Antwort verknüpft sind: Zeit bis zur ersten Antwort, % der Items, die eine Entscheidung erreichten, und wiederkehrende Probleme, die tatsächlich behoben wurden.
Integrieren Sie mit den Tools, die Ihr Team bereits nutzt
Für echte Nutzer bereitstellen
Stelle deine App bei Koder.ai bereit, wenn du bereit bist, ein Pilotteam einzusetzen.
Eine Feedback‑Schleife funktioniert nur, wenn sie dort lebt, wo Leute bereits Zeit verbringen. Integrationen reduzieren Copy‑Pasten, halten Kontext nahe an der Arbeit und machen das „Schließen der Schleife" zur Gewohnheit statt zu einem Sonderprojekt.
Starten Sie mit Integrationen, die den Alltag freimachen
Priorisieren Sie Systeme, die Ihr Team für Kommunikation, Build und Kunden‑Tracking nutzt:
- Slack / Microsoft Teams: Benachrichtigen Sie den richtigen Kanal, wenn hoch‑impact‑Feedback eingeht, ein Owner zugewiesen wird oder ein Kunde geantwortet wurde
- Jira / Linear: Verknüpfen Sie Feedback mit einem Issue (oder erstellen Sie eines), damit Engineering‑Arbeit zurückverfolgbar bleibt
- CRM‑Sync (Salesforce/HubSpot): Hängen Sie Feedback an Accounts/Contacts, damit Support/Success vollen Kontext haben
Halten Sie die erste Version simpel: One‑Way‑Notifications + Deep‑Links zurück zur App, dann fügen Sie Write‑Back‑Aktionen (z. B. „Assign owner" aus Slack) später hinzu.
Bauen Sie ein Webhook‑System für Erweiterbarkeit
Auch wenn Sie nur wenige native Integrationen liefern, erlauben Webhooks Kunden und internen Teams, alles andere zu verbinden.
Bieten Sie eine kleine, stabile Menge Events an:
feedback.createdfeedback.updatedfeedback.closed
Inkludieren Sie einen Idempotency‑Key, Timestamps, Tenant/Workspace‑ID und eine minimale Payload plus eine URL, um vollständige Details abzurufen. Das vermeidet, dass Konsumenten brechen, wenn Sie Ihr Datenmodell weiterentwickeln.
Machen Sie Fehler sichtbar und wiederherstellbar
Integrationen fallen aus normalen Gründen aus: zurückgezogene Tokens, Rate‑Limits, Netzwerkschwierigkeiten, Schema‑Mismatch.
Planen Sie das von Anfang an:
- Retries mit Backoff für transient Errors
- Eine Dead‑Letter‑Queue für wiederholte Fehler
- Eine einfache Integrations‑Health‑Seite (letzter Erfolg, letzter Fehler, nächster Retry)
- Handlungsfähige Fehlerzustände in der UI (z. B. „Reconnect Slack" oder „Berechtigung in Jira fehlt")
Wenn Sie das als Produkt verpacken, sind Integrationen auch ein Kauftrigger. Fügen Sie klare nächste Schritte in Ihrer App (und auf der Marketing‑Site) zu /pricing und /contact für Teams hinzu, die eine Demo oder Hilfe beim Anschluss ihres Stacks wollen.
Liefern Sie ein MVP, und verbessern Sie es mit echten Nutzungsdaten
Eine effektive Feedback‑App ist nach dem Launch nicht „fertig" — sie wird davon geformt, wie Teams tatsächlich triagieren, handeln und antworten. Ziel der ersten Version: den Workflow beweisen, manuelle Arbeit reduzieren und saubere, vertrauenswürdige Daten erfassen.
Definieren Sie ein kleines, aber vollständiges MVP
Halten Sie den Umfang eng, damit Sie schnell liefern und lernen können. Ein praktisches MVP enthält meist:
- Ein Workspace (noch keine Multi‑Org‑Komplexität)
- Eine Kern‑Inbox mit Suche und Basis‑Filtern
- Tagging/Kategorisierung und einfache Zuweisung
- Einen einfachen Antwortfluss (auch wenn es zunächst nur Plain‑Email‑Vorlagen sind)
Wenn ein Feature keinem Team hilft, Feedback Ende‑zu‑Ende zu verarbeiten, kann es warten.
Testen Sie, was Vertrauen zerstört
Frühe Nutzer verzeihen fehlende Features, aber nicht verlorenes Feedback oder falsche Routen. Testen Sie dort, wo Fehler teuer sind:
- Unit‑Tests für Routing‑Regeln, Tagging‑Logik und Permission‑Checks
- Integrationstests für Ingestions‑Quellen und Webhooks (inkl. Retries und Duplikate)
Zielen Sie auf Vertrauen in den Workflow, nicht auf perfekte Coverage.
Planen Sie für den operativen Alltag
Auch ein MVP braucht ein paar „langweilige" Essentials:
- Monitoring für Ingestions‑Fehler und Queue‑Backlogs
- Backups und einen Restore‑Prozess, den Sie wirklich ausprobiert haben
- Error‑Tracking mit genug Kontext, um Probleme zu reproduzieren
- Leichte Admin‑Tools (Event neu abspielen, Items umzuweisen, fehlerhafte Tags korrigieren)
Rollen Sie aus wie ein Produkt‑Experiment
Starten Sie mit einem Pilot: ein Team, eine begrenzte Kanalauswahl und eine klare Erfolgsmetrik (z. B. „90 % der hochprioritären Feedbacks innerhalb von 2 Tagen beantworten"). Sammeln Sie wöchentlich Reibungspunkte und iterieren Sie den Workflow, bevor Sie weitere Teams einladen.
Behandeln Sie Nutzungsdaten als Roadmap: wo Leute klicken, wo sie abbrechen, welche Tags ungenutzt bleiben und welche Workarounds echte Anforderungen offenlegen.
FAQ
Was bedeutet „Schließen der Schleife“ in einer Feedback‑Management‑App genau?
"Schließen der Schleife" bedeutet, dass Sie zuverlässig von Sammeln → Handeln → Antworten → Lernen kommen. In der Praxis sollte jedes Feedback‑Element in einem sichtbaren Ergebnis enden (freigegeben, abgelehnt, erklärt oder geplant) und — wenn angebracht — eine kundenorientierte Antwort mit einem Zeitrahmen erhalten.
Welche Metriken zeigen am besten, ob unsere Feedback‑Schleife funktioniert?
Beginnen Sie mit Metriken, die Geschwindigkeit und Qualität abbilden:
- Zeit bis zur ersten Antwort (Geschwindigkeit der Bestätigung)
- Zeit bis zum Abschluss (Entscheidung oder Lösung)
- Abschluss-/Entscheidungsrate (wie viele Elemente ein Ergebnis erreichen)
- CSAT/NPS‑Veränderung nach Nachverfolgung (hat das Schließen der Schleife geholfen?)
Wählen Sie eine kleine Menge, damit Teams nicht für oberflächliche Aktivitätsmetriken optimieren.
Wie sollten wir mehrere Feedback‑Quellen wie E‑Mail, Chat und In‑App‑Widgets handhaben?
Normalisieren Sie alles in eine einheitliche interne „Feedback‑Item“‑Form, behalten Sie aber die Originaldaten.
Ein praktischer Ansatz:
- Speichern Sie die rohen Payloads (E‑Mail‑Header, Webhook‑JSON, Chat‑Transkript)
- Parsen Sie in einen normalisierten Datensatz (Quelle, Kunden‑IDs, Nachricht, Metadaten)
So bleibt die Triage konsistent und Sie können alte Nachrichten neu verarbeiten, wenn der Parser verbessert wird.
Welches Datenmodell sollte eine MVP‑Feedback‑App verwenden?
Halten Sie das Kernmodell einfach und abfragefreundlich:
Mit welchen Workflow‑Status sollten wir starten und wie halten wir sie konsistent?
Schreiben Sie kurze, gemeinsame Statusdefinitionen und starten Sie mit einer linearen Folge:
- Neu → Triagiert → Geplant → In Bearbeitung → Freigegeben → Geschlossen
Stellen Sie sicher, dass jeder Status beantwortet: „Was passiert als Nächstes?“ und „Wer besitzt den nächsten Schritt?“. Wenn „Geplant" manchmal „vielleicht" bedeutet, trennen oder benennen Sie ihn um, damit Berichte vertrauenswürdig bleiben.
Wie erkennen und verwalten wir doppelte Feedbacks, ohne Kontext zu verlieren?
Definieren Sie Duplikate als „gleiches zugrunde liegendes Problem/Anliegen“, nicht nur ähnliche Texte.
Ein verbreiteter Workflow:
- Wählen Sie ein kanonisches Feedback‑Element
- Verknüpfen Sie andere als Duplikate (nicht löschen)
- Bewahren Sie die Attribution (alle Kunden, die gefragt haben)
- Legen Sie Merge‑Regeln im Voraus fest (Tags, Status, verknüpfte Arbeit, Antworten)
Das verhindert fragmentierte Arbeit und hält trotzdem die vollständige Nachfrage‑Historie intakt.
Wie implementieren wir Triage‑ und Routing‑Regeln in der Anfangsphase am besten?
Halten Sie Automatisierung einfach und auditierbar:
- Routen nach Keywords/Intent (z. B. „refund“ → Billing)
- Routen nach Plan/Tier (Enterprise → Prioritäts‑Queue)
- Routen nach ausgewähltem Produktbereich (aus Widget/Formular)
Zeigen Sie immer an: „Weitergeleitet wegen…“, damit Menschen die Automatisierung prüfen und korrigieren können. Beginnen Sie mit Vorschlägen/Default‑Werten, bevor Sie hartes Auto‑Routing durchsetzen.
Wie sollten wir Multi‑Tenancy und Berechtigungen in einem Feedback‑Loop‑Produkt angehen?
Behandeln Sie jeden Workspace als harte Grenze:
- Fügen Sie
workspace_idzu jedem Kern‑Datensatz hinzu - Scope jede Abfrage auf
workspace_id - Bewerten Sie Berechtigungen pro Workspace
Definieren Sie Rollen durch Aktionen (view/edit/merge/export/send replies), nicht durch Bildschirme. Fügen Sie früh ein Audit‑Log für Statusänderungen, Merges, Zuweisungen und Antworten hinzu.
Welche Architektur‑Entscheidungen sind für die erste Version sinnvoll (Monolith vs. Microservices)?
Starten Sie mit einem modularen Monolithen und klaren Grenzen (auth/orgs, feedback, workflow, messaging, analytics). Verwenden Sie eine relationale Datenbank für transaktionale Workflow‑Daten.
Fügen Sie Hintergrundjobs früh für:
- das Versenden von Antworten
- das Synchronisieren von Integrationen
- das Verarbeiten von Anhängen
- die Zustellung von Webhooks und Retries
Das hält die UI reaktiv und macht Fehler wiederholbar, ohne sich zu früh auf Microservices festzulegen.
Wie verbinden wir Feedback mit Jira/Linear/GitHub und benachrichtigen Kunden, wenn etwas geliefert wurde?
Speichern Sie leichte Referenzen, statt Ihren gesamten Issue‑Tracker zu spiegeln:
external_system(jira/linear/github)work_type(bug/task/feature)external_id(und optionalexternal_url)
Wenn verknüpfte Arbeit wird, starten Sie einen Workflow, der alle angehängten Kunden benachrichtigt — mit Vorlagen und nachverfolgter Zustellung. Wenn Sie öffentliche Hinweise haben, verlinken Sie relativ (z. B. ).