15. Mai 2025·8 Min
Wie man eine Web‑App zur Anreicherung von Kundendaten baut
Erfahren Sie, wie Sie eine Web‑App zur Anreicherung von Kundendaten bauen: Architektur, Integrationen, Matching, Validierung, Datenschutz, Monitoring und Rollout‑Tipps.
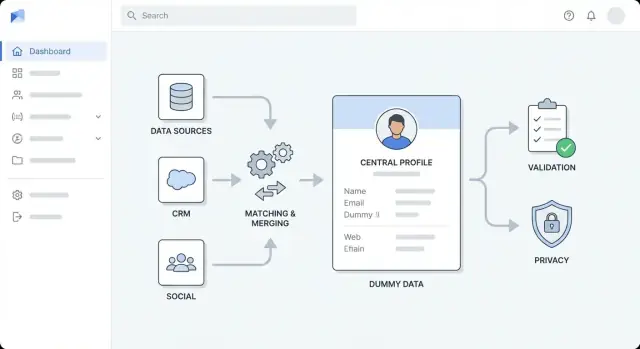
Ziele, Nutzer und Anreicherungsumfang definieren
Bevor Sie Tools wählen oder Architekturdiagramme zeichnen, klären Sie genau, was „Anreicherung“ für Ihre Organisation bedeutet. Teams mischen oft mehrere Anreicherungsarten und haben dann Probleme, Fortschritt zu messen — oder streiten darüber, wann etwas „fertig“ ist.
Was zählt als Anreicherung?
Nennen Sie zunächst die Feldkategorien, die Sie verbessern wollen, und warum:
- Firmografisch: Unternehmensgröße, Branche, Hauptsitz, Finanzierungsstufe
- Kontakt: Berufsbezeichnung, verifizierte E‑Mail/Telefon, Seniorität, Rolle
- Verhaltensdaten: Produktnutzungs‑Signale, Intent, Engagement‑Scores
- Benutzerdefinierte Felder: interne Vertriebsregion, Account‑Tier, ICP‑Fit‑Score
Schreiben Sie auf, welche Felder erforderlich, welche nice‑to‑have und welche niemals angereichert werden dürfen (z. B. sensible Attribute).
Wer nutzt die App — und wofür?
Identifizieren Sie Ihre Hauptnutzergruppen und ihre wichtigsten Aufgaben:
- Sales Ops: Dubletten reduzieren, Accounts standardisieren, Routing verbessern
- Marketing Ops: Leads für Segmentierung und zielgerichtete Kampagnen anreichern
- Support: Account‑Kontext in Tickets sichtbar machen
- Analysten: vertrauenswürdige Datensätze für Reports
Jede Gruppe braucht meist einen anderen Workflow (Massenverarbeitung vs. Einzelprüfung). Erfassen Sie diese Bedürfnisse früh.
Ergebnisse, Scope‑Grenzen und Erfolgsmetriken definieren
Listen Sie erwartete Ergebnisse in messbaren Begriffen: höhere Match‑Rate, weniger Duplikate, schnelleres Lead/Account‑Routing oder bessere Segmentierungsleistung.
Setzen Sie klare Grenzen: welche Systeme sind im Scope (CRM, Billing, Produkt‑Analytics, Supportdesk) und welche nicht — zumindest für den ersten Release.
Stimmen Sie abschließend Erfolgsmetriken und akzeptable Fehlerraten ab (z. B. Abdeckungsgrad der Anreicherung, Verifizierungsrate, Duplikatrate und „sichere Fehlerroutinen“, wenn Anreicherungen unsicher sind). Das wird Ihr Nordstern für den Rest des Builds.
Modellieren Sie Ihre Kundendaten und identifizieren Sie Lücken
Bevor Sie etwas anreichern, klären Sie, was in Ihrem System „ein Kunde“ ist — und was Sie bereits über ihn wissen. Das verhindert, dass Sie für Anreicherungen bezahlen, die Sie nicht speichern können, und vermeidet verwirrende Zusammenführungen später.
Bestandsaufnahme der Felder und Quellen
Beginnen Sie mit einem einfachen Katalog von Feldern (z. B. Name, E‑Mail, Firma, Domain, Telefon, Adresse, Berufsbezeichnung, Branche). Notieren Sie für jedes Feld, woher es stammt: Benutzerangabe, CRM‑Import, Billing‑System, Support‑Tool, Produkt‑Signup‑Formular oder ein Anreicherungsanbieter.
Erfassen Sie auch, wie es gesammelt wird (erforderlich vs. optional) und wie häufig es sich ändert. Beispielsweise ändern sich Jobtitel und Unternehmensgröße mit der Zeit, während eine interne Kunden‑ID niemals wechseln sollte.
Definieren Sie Ihr Identitätsmodell: Person, Unternehmen, Account
Die meisten Anreicherungsworkflows beinhalten mindestens zwei Entitäten:
- Person (Kontakt/Lead): eine Einzelperson mit E‑Mails, Telefonen, Rollen
- Firma (Organisation): ein Unternehmen mit Domain, Standort, Firmografiken
Entscheiden Sie, ob Sie zusätzlich ein Account-Konzept benötigen (kommerzielle Beziehung), das mehrere Personen mit einer Firma verknüpft und Attribute wie Plan, Vertragsdaten und Status hält.
Schreiben Sie die unterstützten Beziehungen auf (z. B. viele Personen → eine Firma; eine Person → im Laufe der Zeit mehrere Firmen).
Häufige Datenprobleme dokumentieren
Listen Sie wiederkehrende Probleme: fehlende Werte, inkonsistente Formate ("US" vs. "United States"), Duplikate durch Importe, veraltete Datensätze und widersprüchliche Quellen (Billing‑Adresse vs. CRM‑Adresse).
Schlüsselattribute und Vertrauensstufen wählen
Wählen Sie die Identifikatoren, die Sie für Matching und Updates verwenden — typischerweise E‑Mail, Domain, Telefon und eine interne Kunden‑ID.
Weisen Sie jedem eine Vertrauensstufe zu: welche Keys autoritativ sind, welche „Best‑Effort“ und welche niemals überschrieben werden sollten.
Zuständigkeiten und Bearbeitungsrechte klären
Einigen Sie sich, wer welche Felder besitzt (Sales Ops, Support, Marketing, Customer Success) und definieren Sie Bearbeitungsregeln: was Menschen ändern dürfen, was die Automatisierung ändern darf und was Genehmigung erfordert.
Diese Governance spart Zeit, wenn Anreicherungsergebnisse mit bestehenden Daten kollidieren.
Anreicherungsquellen und Datenverträge wählen
Bevor Sie Integrationscode schreiben, entscheiden Sie, woher Anreicherungsdaten kommen und was Sie damit tun dürfen. Das vermeidet einen häufigen Fehler: eine technisch funktionierende Funktion ausliefern, die aber Kosten, Zuverlässigkeit oder Compliance bricht.
Typische Anreicherungsquellen
Sie kombinieren meist mehrere Inputs:
- Interne Systeme: CRM, Billing, Support‑Tickets, Produkt‑Analytics, E‑Mail‑Plattform, Data Warehouse
- Drittanbieter‑APIs: Firmografien, Kontaktverifizierung, Branchen‑Codes, Technografien, Risiko‑Signale
- Hochgeladene Listen: CSVs von Sales, Events, Partnern oder Datenanbietern
- Webhooks: Echtzeit‑Updates von Tools, die Änderungen beobachten (z. B. E‑Mail‑Verifikation, Identitätsanbieter)
Quellen bewerten
Bewerten Sie jede Quelle nach Coverage (wie oft liefert sie etwas Nützliches), Freshness (wie schnell sie aktualisiert), Kosten (pro Call/pro Datensatz), Rate Limits und Nutzungsbedingungen (was Sie speichern dürfen, wie lange und zu welchem Zweck).
Prüfen Sie auch, ob der Anbieter Confidence‑Scores und klare Provenienz (woher ein Feld stammt) liefert.
Einen Datenvertrag definieren
Behandeln Sie jede Quelle als Vertrag, der Feldnamen und Formate, erforderliche vs. optionale Felder, Aktualisierungsfrequenz, erwartete Latenz, Fehlercodes und Confidence‑Semantik festlegt.
Fügen Sie eine explizite Zuordnung hinzu („Provider‑Feld → Ihr kanonisches Feld“) sowie Regeln für Nullwerte und widersprüchliche Werte.
Fallback‑ und Speicherentscheidungen
Planen Sie, was passiert, wenn eine Quelle nicht verfügbar ist oder Low‑Confidence‑Ergebnisse liefert: Retry mit Backoff, Zurückstellen zur späteren Verarbeitung oder Fallback auf eine sekundäre Quelle.
Entscheiden Sie, was Sie speichern (stabile Attribute, die für Suche/Reporting benötigt werden) versus was Sie on‑demand berechnen (teure oder zeitkritische Lookups).
Dokumentieren Sie Einschränkungen beim Speichern sensibler Attribute (z. B. persönliche Identifikatoren, inferierte Demografien) und legen Sie Aufbewahrungsregeln fest.
High‑Level‑Architektur entwerfen
Bevor Sie Tools wählen, entscheiden Sie, wie die App strukturiert ist. Eine klare High‑Level‑Architektur macht Anreicherungsarbeit vorhersehbar, verhindert, dass „quick fixes“ dauerhaften Ballast werden, und hilft dem Team, Aufwand abzuschätzen.
Architekturstil wählen, der zum Team passt
Für die meisten Teams empfiehlt sich ein modularer Monolith: eine deploybare App, intern in klar definierte Module (Ingestion, Matching, Enrichment, UI) aufgeteilt. Das ist einfacher zu bauen, zu testen und zu debuggen.
Wechseln Sie zu separaten Services, wenn es einen klaren Grund gibt — z. B. hohe Durchsatzanforderungen, unabhängige Skalierung oder unterschiedliche Teams, die Teile verantworten. Eine übliche Aufteilung ist:
- API‑Service (synchrone Anfragen, Auth, Record CRUD)
- Worker‑Service (asynchrone Anreicherung, Retries)
- UI (Review, Genehmigungen, Bulk‑Aktionen)
Verantwortlichkeiten in Schichten trennen
Halten Sie Grenzen explizit, damit Änderungen nicht überall durchschlagen:
- Ingestion‑Layer: Importe aus CRM/Dateien und Normalisierung der Eingaben
- Enrichment‑Layer: Ruft Anbieter/internen Quellen an und speichert Ergebnisse
- Validierungs‑Layer: Wendet Datenqualitätsregeln an und markiert Ausnahmen
- Storage‑Layer: Kundenprofile, rohe Quellen‑Payloads, Audit‑Historie
- Präsentations‑Layer: UI‑Views, Review‑Queues, Genehmigungen
Von Anfang an asynchrone Anreicherung planen
Anreicherung ist langsam und fehleranfällig (Rate Limits, Timeouts, partielle Daten). Behandeln Sie Anreicherung als Jobs:
- API erstellt einen Job und antwortet schnell
- Worker verarbeiten Jobs über eine Queue (mit Retries und Backoff)
- UI zeigt Job‑Status und erlaubt Neuversuche
Umgebungen und Konfiguration planen
Richten Sie dev/staging/prod früh ein. Halten Sie Vendor‑Keys, Schwellenwerte und Feature‑Flags in der Konfiguration (nicht im Code) und machen Sie Provider‑Austausch einfach pro Umgebung.
Einseitiges Diagramm abstimmen
Skizzieren Sie ein einfaches Diagramm: UI → API → Datenbank, plus Queue → Worker → Enrichment‑Provider. Nutzen Sie es in Reviews, damit alle vor der Implementierung die Verantwortlichkeiten verstehen.
Schnelles Prototyping (optional)
Wenn Sie Workflows und Review‑Screens validieren möchten, bevor Sie viel Engineering‑Aufwand investieren, kann eine Rapid‑Prototyping‑Plattform wie Koder.ai helfen: React‑basierte UI für Review/Genehmigungen, eine Go‑API‑Schicht und PostgreSQL‑gestützte Speicherung.
Das ist besonders nützlich, um das Job‑Modell (asynchrone Anreicherung mit Retries), Audit‑Historie und rollenbasierte Zugriffsmodelle zu verproben und anschließend den Quellcode für die Produktionsbereitstellung zu exportieren.
Storage, Queues und unterstützende Dienste einrichten
Bevor Sie Anreicherungsanbieter ankoppeln, richten Sie die „Plumbing“ richtig ein. Storage‑ und Background‑Processing‑Entscheidungen sind später schwer zu ändern und beeinflussen Zuverlässigkeit, Kosten und Auditierbarkeit.
Primäre Datenbank: Profile + Historie
Wählen Sie eine primäre Datenbank für Kundenprofile, die strukturierte Daten und flexible Attribute unterstützt. Postgres ist eine verbreitete Wahl, weil es Kernfelder (Name, Domain, Branche) neben semi‑strukturierten Anreicherungsfeldern (JSON) speichern kann.
Ebenso wichtig: speichern Sie Änderungsverläufe. Statt Werte stillschweigend zu überschreiben, erfassen Sie wer/was ein Feld wann und warum geändert hat (z. B. „vendor_refresh“, „manual_approval“). Das erleichtert Genehmigungen und schützt bei Rollbacks.
Queue: Anreicherung und Retries
Anreicherung ist inhärent asynchron: APIs haben Rate Limits, Netze fallen aus und einige Anbieter antworten langsam. Fügen Sie eine Job‑Queue für Hintergrundarbeit hinzu:
- Anreicherungsanfragen (Einzel‑ und Bulk‑Records)
- Retries mit Backoff
- Geplante Refreshes (z. B. alle 30/90 Tage)
- Dead‑Letter‑Handling für dauerhaft fehlernde Jobs
Das hält Ihre UI reaktiv und verhindert, dass Anbieterstörungen die App lahmlegen.
Cache: schnelle Lookups und Rate‑Limit‑Tracking
Ein kleiner Cache (z. B. Redis) hilft bei häufigen Lookups (z. B. „Firma nach Domain“) und beim Tracking von Vendor‑Rate‑Limits und Cooldown‑Fenstern. Außerdem nützlich für Idempotency‑Keys, damit wiederholte Importe keine doppelten Anreicherungen auslösen.
Dateispeicherung und Aufbewahrung
Planen Sie Object‑Storage für CSV‑Importe/‑Exporte, Fehlerberichte und „Diff“‑Dateien, die in Review‑Flows verwendet werden.
Definieren Sie Aufbewahrungsregeln früh: speichern Sie rohe Vendor‑Payloads nur so lange wie nötig zum Debugging und Audits und löschen Sie Logs gemäß Ihrer Compliance‑Policy.
Ingest‑ und Normalisierungspipelines bauen
Das asynchrone Job‑Modell validieren
Setze Job‑Queues, Retries und Statusanzeigen auf – ohne zuerst verschiedene Tools zusammenzufügen.
Ihre Anreicherungsapp ist nur so gut wie die Daten, die Sie einspeisen. Ingestion entscheidet, wie Informationen ins System kommen, Normalisierung sorgt dafür, dass diese konsistent genug sind zum Matchen, Anreichern und Reporten.
Wie Daten hereinkommen sollen
Die meisten Teams benötigen eine Mischung aus Entry‑Points:
- API‑Endpoints für Ihr Produkt oder interne Tools, um neue/aktualisierte Kunden zu pushen
- Webhooks von CRMs oder Billing‑Systemen für nahezu Echtzeit‑Änderungen
- Geplante Pulls (nächtliche Synchronisationen) für Systeme ohne Push‑Support
- CSV‑Importe für Backfills und One‑Off‑Uploads
Was immer Sie unterstützen, halten Sie den „raw ingest“ leichtgewichtig: akzeptieren Sie Daten, authentifizieren, loggen Metadaten und enqueue Arbeit zur Verarbeitung.
Früh normalisieren und standardisieren
Implementieren Sie eine Normalisierungsschicht, die unordentliche Eingaben in eine konsistente interne Form bringt:
- Namen: Trim Whitespaces, Vor‑/Nachnamen splitten wenn möglich, Groß-/Kleinschreibung behandeln
- Telefone: in E.164 konvertieren und Länderannahmen explizit speichern
- Adressen: Felder standardisieren (street, locality, region, postal code) und Originaltext behalten
- Domains/E‑Mails: lowercase, Tracking‑Parameter aus URLs entfernen, Syntax validieren
Validieren, quarantänisieren und idempotent bleiben
Definieren Sie erforderliche Felder pro Record‑Typ und rejecten oder quarantänisieren Datensätze, die Prüfungen nicht bestehen (z. B. fehlende E‑Mail/Domain für Firmen‑Matching). Quarantänisierte Items sollten in der UI sichtbar und korrigierbar sein.
Fügen Sie Idempotency‑Keys hinzu, um doppelte Verarbeitung bei Retries zu verhindern (häufig bei Webhooks und instabilen Netzen). Ein einfacher Ansatz ist ein Hash von (source_system, external_id, event_type, event_timestamp).
Lineage pro Feld nachverfolgen
Speichern Sie Provenienz für jeden Datensatz und idealerweise für jedes Feld: Quelle, Ingest‑Zeit und Transformations‑Version. So lassen sich später Fragen beantworten: „Warum änderte sich diese Telefonnummer?“ oder „Welcher Import erzeugte diesen Wert?"
Matching, Dublettenbereinigung und Merging implementieren
Erfolgreiche Anreicherung hängt davon ab, wer‑ist‑wer zuverlässig zu identifizieren. Ihre App braucht klare Matching‑Regeln, vorhersehbares Merge‑Verhalten und ein Sicherheitsnetz, wenn das System unsicher ist.
Matching‑Regeln (und Confidence‑Schwellen) definieren
Beginnen Sie mit deterministischen Identifikatoren:
- Exakte Keys: E‑Mail (normalisiert auf lowercase), Kunden‑ID, Steuer‑/USt‑ID oder verifizierte Domain
Dann ergänzen Sie probabilistisches Matching für Fälle ohne exakte Keys:
- Fuzzy Matches: Name + Firmen‑Domain, Name + Standort, Telefonähnlichkeit
Weisen Sie einen Match‑Score zu und setzen Sie Schwellenwerte, z. B.:
- Auto‑Merge nur oberhalb einer hohen Schwelle
- Manuelle Prüfung bei „vielleicht“‑Bereich
- Ablehnen unterhalb der unteren Schwelle
Dublettenbereinigung und Merge‑Logik planen
Wenn zwei Datensätze dieselbe Person/dasselbe Unternehmen repräsentieren, entscheiden Sie, wie Felder ausgewählt werden:
- Feld‑Präzedenz: „verifizierte E‑Mail schlägt unverifizierte“, „neuerer Zeitstempel gewinnt“, „CRM überschreibt Enrichment für Kontakt‑Owner"
- Source‑Trust‑Scores: Quellen (CRM, Billing, Enrichment‑Provider) ranken, um Konflikte aufzulösen
- Konfliktbehandlung: halten Sie beide Werte wenn möglich (z. B. mehrere Telefonnummern) oder speichern Sie den unterlegenen Wert in der Historie
Audit‑Trail und Review‑Workflow
Jeder Merge sollte ein Audit‑Event erzeugen: wer/was ihn ausgelöst hat, Vor‑/Nach‑Werte, Match‑Score und beteiligte Record‑IDs.
Bei unklaren Matches bieten Sie eine Prüfoberfläche mit Seiten‑an‑Seiten‑Vergleich und Optionen „merge / nicht mergen / weitere Daten anfordern“.
Schutz gegen versehentliche Massenmerges
Erfordern Sie zusätzliche Bestätigung für Bulk‑Merges, begrenzen Sie Merges pro Job und unterstützen Sie „Dry‑Run“‑Vorschauen.
Fügen Sie außerdem einen Undo‑Weg (oder Merge‑Reversal) mit Hilfe der Audit‑Historie hinzu, damit Fehler nicht dauerhaft sind.
Enrichment‑APIs integrieren und Zuverlässigkeit handhaben
Anreicherung ist der Punkt, an dem Ihre App auf die Außenwelt trifft — mehrere Provider, inkonsistente Antworten und unvorhersehbare Verfügbarkeit.
Behandeln Sie jeden Provider als einen austauschbaren „Connector“, sodass Sie Quellen hinzufügen, austauschen oder deaktivieren können, ohne den Rest der Pipeline anzufassen.
Provider‑Connectoren bauen (Auth, Retries, Fehler‑Mapping)
Erstellen Sie pro Anbieter einen Connector mit konsistenter Schnittstelle (z. B. enrichPerson(), enrichCompany()). Kapseln Sie anbieter‑spezifische Logik im Connector:
- Authentifizierung (API‑Keys, OAuth‑Tokens, Token‑Refresh)
- Standardisierte Retries für transienten Fehler
- Fehler‑Mapping (Provider‑Fehler in Ihre Kategorien wie
invalid_request,not_found,rate_limited,provider_downübersetzen)
Das macht Downstream‑Workflows einfacher: sie handeln Ihre Fehler‑Typen, nicht die Eigenarten jedes Anbieters.
Rate Limits mit Throttling und Backoff handhaben
Die meisten Anreicherungs‑APIs haben Quoten. Bauen Sie Throttling pro Provider (und ggf. pro Endpoint) ein, um unter Limits zu bleiben.
Wenn Sie ein Limit erreichen, nutzen Sie exponentielles Backoff mit Jitter und respektieren Sie Retry‑After‑Header.
Planen Sie auch für „langsame Fehler“: Timeouts und partielle Antworten sollten als retryable Events erfasst werden, nicht stillschweigend verworfen.
Confidence und Evidenz speichern (innerhalb der Policy)
Anreicherungsresultate sind selten absolut. Speichern Sie Provider‑Confidence‑Scores, wenn verfügbar, sowie einen eigenen Score basierend auf Match‑Qualität und Feldvollständigkeit.
Wo vertraglich und datenschutzrechtlich erlaubt, speichern Sie rohe Evidenz (Source‑URLs, Identifikatoren, Zeitstempel), um Audits und Benutzervertrauen zu unterstützen.
Multi‑Provider‑Strategie: „best available“
Unterstützen Sie mehrere Anbieter und definieren Sie Auswahlregeln: zuerst billigster Anbieter, höchster Confidence‑Score oder feldweise „best available“.
Protokollieren Sie, welcher Provider welches Attribut geliefert hat, damit Änderungen erklärt und bei Bedarf zurückgenommen werden können.
Geplante Refresh‑Regeln
Anreicherungen veralten. Implementieren Sie Refresh‑Routinen wie „alle 90 Tage neu anreichern“, „bei Änderung eines Schlüssel‑Feldes auffrischen“ oder „nur auffrischen, wenn Confidence sinkt“.
Machen Sie Zeitpläne konfigurierbar pro Kunde und Datentyp, um Kosten und Rauschen zu steuern.
Datenqualitätsregeln und Validierung hinzufügen
Reviews und Freigaben testen
Lege Merge‑Review‑Screens und Audit‑History frühzeitig an, bevor die vollständige Implementierung beginnt.
Anreicherung hilft nur, wenn neue Werte vertrauenswürdig sind. Behandeln Sie Validierung als Kernfunktion: sie schützt Nutzer vor fehlerhaften Importen, unzuverlässigen Drittanbietern und unbeabsichtigter Korruption beim Mergen.
Feld‑Level Validierungsregeln definieren
Beginnen Sie mit einem einfachen „Rules Catalog“ pro Feld, geteilt von UI‑Formularen, Ingest‑Pipelines und öffentlichen APIs.
Gängige Regeln sind Formatchecks (E‑Mail, Telefon, Postleitzahl), erlaubte Werte (Ländercodes, Branchenlisten), Bereiche (Mitarbeiteranzahl, Umsatzklassen) und Abhängigkeiten (wenn country = US, dann ist state erforderlich).
Versionieren Sie Regeln, damit Änderungen sicher erfolgen können.
Qualitätschecks, die den Business‑Use widerspiegeln
Über Basisvalidierung hinaus führen Sie Checks ein, die Geschäftsfragen beantworten:
- Vollständigkeit: Haben wir Mindestfelder, um den Datensatz zu nutzen?
- Einzigartigkeit: Sind vermeintlich eindeutige Identifier (Domain, Steuer‑ID) dupliziert?
- Konsistenz: Stimmen verbundene Felder überein (Land vs. Telefon‑Präfix)?
- Aktualität: Wie alt ist ein Wert und sollte er erneuert werden?
Records und Quellen bewerten
Übersetzen Sie Checks in Scorecards: pro Record (Gesundheit) und pro Quelle (wie oft liefert sie gültige, aktuelle Werte).
Nutzen Sie Scores, um Automatisierung zu steuern — z. B. nur Anreicherungen oberhalb einer Schwelle automatisch anwenden.
Fehler vorhersehbar routen
Wenn ein Datensatz Validierung nicht besteht, verwerfen Sie ihn nicht.
Senden Sie ihn an eine „data‑quality“ Queue zur Nachbearbeitung (transiente Probleme) oder zur manuellen Prüfung (schlechte Eingabe). Speichern Sie die fehlgeschlagene Payload, Regelverletzungen und vorgeschlagene Korrekturen.
Fehler verständlich machen
Geben Sie klare, umsetzbare Meldungen für Importe und API‑Clients zurück: welches Feld ist fehlgeschlagen, warum und ein Beispiel für einen gültigen Wert.
Das reduziert Supportaufwand und beschleunigt Cleanup‑Arbeit.
UI für Review, Genehmigungen und Bulk‑Arbeit erstellen
Ihre Anreicherungs‑Pipeline liefert nur dann Wert, wenn Menschen sehen können, was sich geändert hat, und Updates vertrauenswürdig in nachgelagerte Systeme schreiben.
Die UI sollte „was ist passiert, warum und was mache ich als Nächstes?“ offensichtlich machen.
Kernbildschirme
Das Kundenprofil ist die Zentrale. Zeigen Sie Schlüssel‑Identifiers (E‑Mail, Domain, Firmenname), aktuelle Feldwerte und ein Anreicherungs‑Status‑Badge (z. B. Not enriched, In progress, Needs review, Approved, Rejected).
Fügen Sie eine Änderungshistorie hinzu, die Updates in Klartext erklärt: „Unternehmensgröße von 11–50 auf 51–200 geändert.“ Jeder Eintrag sollte anklickbar sein, um Details zu sehen.
Bieten Sie Merge‑Vorschläge an, wenn Duplikate erkannt werden. Zeigen Sie zwei (oder mehrere) Kandidaten nebeneinander mit dem empfohlenen „Survivor“‑Datensatz und einer Vorschau des zusammengeführten Ergebnisses.
Bulk‑Arbeit, die echten Abläufen entspricht
Die meisten Teams arbeiten in Batches. Ermöglichen Sie Bulk‑Aktionen wie:
- Ausgewählte Datensätze anreichern (oder zur nächtlichen Verarbeitung einreihen)
- Vorschläge für Merges genehmigen/ablehnen
- Ergebnisse (CSV) exportieren für Audits oder Offline‑Review
Nutzen Sie eine klare Bestätigung für destruktive Aktionen (Merge, Überschreiben) mit einem möglichst verfügbaren „Undo“‑Fenster.
Schnelle Suche, Filter und Feld‑Provenienz
Fügen Sie globale Suche und Filter nach E‑Mail, Domain, Firma, Status und Quality‑Score hinzu.
Lassen Sie Nutzer Views speichern wie „Needs review“ oder „Low confidence updates“. Für jedes angereicherte Feld zeigen Sie Provenienz: Quelle, Zeitstempel und Confidence.
Ein einfaches „Warum dieser Wert?“‑Panel stärkt Vertrauen und reduziert Rückfragen.
Geführte Workflows für nicht‑technische Nutzer
Halten Sie Entscheidungen einfach und geführt: „Vorgeschlagenen Wert akzeptieren“, „Bestehenden behalten“ oder „Manuell bearbeiten“. Tiefergehende Kontrolle verstecken Sie hinter einem „Erweitert“‑Toggle.
Security, Privacy und Compliance Grundlagen
Ohne Angst iterieren
Nutze Snapshots und Rollbacks, um Matching‑Regeln und Merge‑Prioritäten sicher anzupassen, während du lernst.
Anreicherungs‑Apps berühren sensible Identifier (E‑Mails, Telefonnummern, Firmendaten) und ziehen oft Daten von Drittanbietern. Behandeln Sie Sicherheit und Datenschutz als Kernfeatures, nicht als spätere Aufgabe.
Rollenbasiertes Zugriffsmodell (RBAC)
Starten Sie mit klaren Rollen und Least‑Privilege‑Defaults:
- Admin: Benutzer, Rollen, Connectoren, Aufbewahrungsrichtlinien verwalten
- Ops: Anreicherungsjobs ausführen, Konflikte lösen, Merges genehmigen
- Viewer: Read‑Only für Reporting und Support
Halten Sie Berechtigungen granular (z. B. „Daten exportieren“, „PII sehen“, „Merges genehmigen") und trennen Sie Umgebungen, sodass Produktionsdaten nicht in Dev verfügbar sind.
Sensible Daten schützen
Nutzen Sie TLS für jeglichen Traffic und Verschlüsselung at rest für Datenbanken und Object‑Storage.
Speichern Sie API‑Keys in einem Secrets‑Manager (nicht in Env‑Dateien im Quellcode), rotieren Sie Schlüssel regelmäßig und scope Keys pro Umgebung.
Wenn PII in der UI angezeigt wird, setzen Sie sichere Defaults wie Maskierung (z. B. nur letzte 2–4 Ziffern) und verlangen Sie explizite Berechtigung zum Entblättern.
Einwilligung und Nutzungsbeschränkungen
Wenn Anreicherung von Einwilligung oder speziellen vertraglichen Bedingungen abhängt, kodifizieren Sie diese Beschränkungen im Workflow:
- Tracken Sie Datenquelle, Zweck und erlaubte Verwendungen pro Feld
- Dokumentieren Sie, was Sie speichern und warum (eine kurze interne Policy‑Seite wie /privacy oder /docs/data-handling hilft)
- Vermeiden Sie das Sammeln unnötiger Felder — weniger Daten reduzieren Risiken
Auditierung, Aufbewahrung und Löschung
Erzeugen Sie sowohl Zugriffs‑ als auch Änderungs‑Audit‑Logs:
- Loggen Sie wer Datensätze angesehen/exportiert hat
- Loggen Sie wer was wann geändert hat (Vorher/Nachher, Job‑ID, Enrichment‑Provider)
Unterstützen Sie Datenschutzanfragen mit praktischen Tools: Aufbewahrungspläne, Datensatzlöschung und „Forget“‑Workflows, die auch Kopien in Logs, Caches und Backups soweit möglich markieren oder für Ablauf kennzeichnen.
Monitoring, Analytics und operative Kontrollen
Monitoring ist nicht nur für Uptime — es hält Anreicherungen vertrauenswürdig, während Volumina, Provider und Regeln sich ändern.
Behandeln Sie jeden Anreicherungsrun als messbaren Job mit Signalen, die Sie über Zeit trendbar machen.
Nützliche Metriken
Beginnen Sie mit einer kleinen Menge operativer Metriken, die an Outcomes gekoppelt sind:
- Job‑Durchsatz (Records/min) und Time‑to‑Complete pro Run
- Success‑Rate vs. Failure‑Rate, aufgeschlüsselt nach Fehlerart (Validation, Matching, Provider)
- Provider‑Latenz (p50/p95) und Timeouts pro Quelle
- Match‑Rate (wie oft Anreicherung sicher zugeordnet wird)
- Verhinderte Duplikate (wie viele sonst falsch gemerged worden wären)
Diese Zahlen beantworten schnell: „Verbessern wir Daten, oder verschieben wir sie nur?"
Alerts und Guardrails
Fügen Sie Alerts hinzu, die auf Veränderungen reagieren, nicht auf Lärm:
- Anstiege bei Fehlern oder quarantänisierten Datensätzen
- Queue‑Backlogs oder langsame Verbraucher (Hinweis auf blockierte Pipeline)
- Provider‑Fehlerbursts (429/5xx), erhöhte Latenz oder mehr Timeouts
Verknüpfen Sie Alerts mit konkreten Aktionen: Provider pausieren, Concurrency reduzieren oder auf gecachte/veraltete Daten umschalten.
Admin‑Dashboard für Operatoren
Stellen Sie ein Admin‑Dashboard für aktuelle Runs bereit: Status, Counts, Retries und eine Liste quarantänisierter Datensätze mit Gründen.
Fügen Sie „Replay“‑Kontrollen und sichere Bulk‑Aktionen hinzu (z. B. alle Provider‑Timeouts wiederholen, nur Matching erneut ausführen).
Nachvollziehbarkeit mit Logs
Nutzen Sie strukturierte Logs und eine Correlation‑ID, die einen Datensatz von Anfang bis Ende begleitet (Ingest → Match → Enrichment → Merge).
Das beschleunigt Support und Incident‑Debugging erheblich.
Incident‑Playbooks und Rollback
Schreiben Sie kurze Playbooks: was zu tun ist, wenn ein Provider ausfällt, wenn die Match‑Rate einbricht oder wenn Duplikate durchrutschen.
Halten Sie eine Rollback‑Option bereit (z. B. Merges innerhalb eines Zeitfensters zurückrollen) und dokumentieren Sie sie unter /runbooks.
Testen, Rollout und Iterationsplan
Testing und Rollout sind die Schritte, in denen eine Anreicherungsapp vertrauenswürdig wird. Ziel ist nicht „mehr Tests“, sondern Vertrauen, dass Matching, Merging und Validierung vorhersehbar mit realen, unordentlichen Daten umgehen.
Risikoreiche Bereiche zuerst testen
Priorisieren Sie Tests für Logik, die Datensätze stillschweigend beschädigen kann:
- Matching‑Regeln: Unit‑Tests für exakte, fuzzy und kombinierte Matches (z. B. E‑Mail + Firmen‑Domain). Schließen Sie Near‑Duplicates und vertauschte Felder ein.
- Merge‑Ergebnisse: Tests für Feld‑Präzedenz (Source‑Priority), Konflikt‑Behandlung und „nicht überschreiben“‑Regeln.
- Validation‑Edgecases: fehlerhafte E‑Mails, internationale Telefonformate, fehlendes Land, doppelte Identifier und „unknown“‑Werte.
Nutzen Sie synthetische Datensätze (generierte Namen, Domains, Adressen), um Genauigkeit zu validieren, ohne echte Kundendaten zu verwenden.
Halten Sie ein versioniertes „Golden Set“ mit erwarteten Match/Merge‑Ergebnissen, damit Regressionen schnell auffallen.
Rollout stufenweise durchführen
Reduzieren Sie den Blast Radius:
- Pilot: eine Team‑Segmente oder ein Segment (z. B. nur SMB‑Leads)
- Limitierte Aktionen: beginnen Sie mit „Vorschläge“, die eine Genehmigung erfordern, bevor sie ins CRM zurückgeschrieben werden
- Hochfahren: Volumen erhöhen, dann automatisierte Writes für risikoarme Felder aktivieren
Definieren Sie Erfolgsmetriken vorab (Match‑Precision, Genehmigungsrate, Reduktion manueller Änderungen, Time‑to‑Enrich).
Workflows und Integrations‑Checklist dokumentieren
Erstellen Sie kurze Dokumente für Nutzer und Integratoren (verlinken Sie aus Ihrem Produktbereich oder /pricing wenn Features gekapselt sind). Enthalten Sie eine Integrations‑Checkliste:
- API‑Auth‑Methode, Rate Limits und Retry‑Verhalten
- Erforderliche Felder für Anreicherungsrequests
- Webhook/Event‑Payloads (und Versionierung)
- Fehlercodes und „partielle Anreicherung“‑Regeln
- Audit‑Log‑Erwartungen und Datenaufbewahrung
Für kontinuierliche Verbesserung planen Sie regelmäßige Reviews: fehlgeschlagene Validierungen, häufige manuelle Overrides und Mismatches analysieren, Regeln anpassen und Tests ergänzen.
Eine praktische Referenz zum Schärfen von Regeln: /blog/data-quality-checklist.
Build vs. beschleunigen: ein praktischer Hinweis
Wenn Sie Workflows kennen, aber die Zeit bis zu einer funktionierenden App verkürzen wollen, ziehen Sie in Betracht, Koder.ai zu nutzen, um eine erste Implementierung (React UI, Go‑Services, PostgreSQL‑Storage) aus einem strukturierten Chat‑Plan zu generieren.
Teams nutzen diesen Ansatz oft, um Review‑UI, Job‑Processing und Audit‑Historie schnell aufzusetzen und anschließend mit Planning‑Mode, Snapshots und Rollback iterativ weiterzuentwickeln. Wenn volle Kontrolle erforderlich ist, können Sie den Quellcode exportieren und in Ihre bestehende Pipeline integrieren. Koder.ai bietet Free, Pro, Business und Enterprise Pläne, um Experimentier‑ vs. Produktionsbedürfnisse abzudecken.