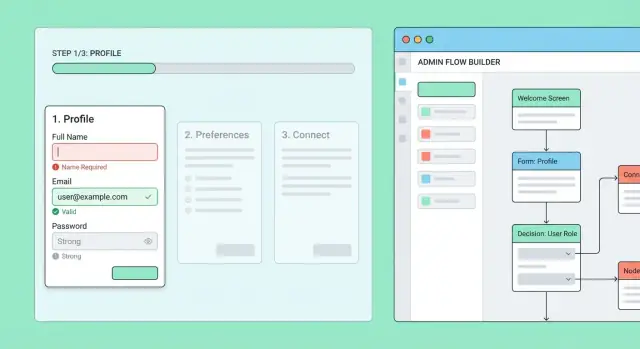
Was ein mehrstufiger Onboarding‑Flow leisten muss
Ein mehrstufiger Onboarding‑Flow ist eine geführte Abfolge von Bildschirmen, die einem neuen Nutzer hilft, vom „angemeldet“‑Zustand zum „bereit, das Produkt zu nutzen“ zu kommen. Statt alles auf einmal zu verlangen, teilen Sie die Einrichtung in kleinere Schritte, die in einer Sitzung oder über die Zeit erledigt werden können.
Ein mehrstufiges Onboarding ist nötig, wenn die Einrichtung mehr als ein einzelnes Formular ist — besonders wenn es Entscheidungen, Voraussetzungen oder Compliance‑Checks enthält. Wenn Ihr Produkt Kontext benötigt (Branche, Rolle, Präferenzen), Verifikation (E‑Mail/Telefon/Identität) oder Initialkonfiguration (Workspaces, Abrechnung, Integrationen), sorgt ein schrittbasierter Flow für Verständlichkeit und reduziert Fehler.
Übliche Onboarding‑Flows, die Sie schon gesehen haben
Mehrstufiges Onboarding ist weit verbreitet, weil es Aufgaben unterstützt, die natürlich in Etappen passieren, wie:
- Konto‑Einrichtung: Workspace erstellen, Team einladen, Plan wählen
- Profil vervollständigen: Name, Rolle, Ziele, Präferenzen
- Verifikation: E‑Mail/Telefon‑Bestätigung, KYC/ID‑Checks, 2FA einrichten
- Tutorials und Erste‑Schritte‑Guides: Produkt‑Tour, Beispielprojekt erstellen, „Mach das zuerst“‑Checkliste
Wie „Erfolg“ aussehen sollte
Gutes Onboarding sind nicht „nur fertige Screens“, sondern Nutzer, die schnell Wert erreichen. Definieren Sie Erfolg in Begriffen, die zu Ihrem Produkt passen:
- Activation: Der Nutzer führt die Schlüsselaktion aus, die langfristige Bindung vorhersagt (z. B. erstes Projekt erstellen, Datenquelle verbinden)
- Completion‑Rate: Welcher Prozentsatz der Nutzer beendet erforderliche Schritte (und evtl. optionale Schritte)
- Time‑to‑value: Wie lange braucht ein neuer Nutzer bis zum ersten sinnvollen Ergebnis
Der Flow sollte außerdem Resume und Kontinuität unterstützen: Nutzer können pausieren und zurückkehren, ohne Fortschritt zu verlieren, und sollten zum nächsten logischen Schritt geführt werden.
Typische Risiken im Design
Mehrstufiges Onboarding scheitert auf vorhersehbare Weise:
- Drop‑offs: zu viele Schritte, unklare Vorteile oder sensible Daten zu früh abfragen
- Verwirrende Schritte: vage Labels („Setup“), versteckte Voraussetzungen oder inkonsistente Navigation
- Datenverlust: Probleme bei Refresh/Zurück, Session‑Timeouts, unvollständige Speicherung nicht gehandhabt
Ziel ist, dass Onboarding sich wie ein geführter Weg anfühlt, nicht wie eine Prüfung: klarer Zweck pro Schritt, verlässliche Fortschrittsverfolgung und einfache Wiederaufnahme.
Ziele, Nutzer und „Done“‑Kriterien definieren
Bevor Sie Bildschirme zeichnen oder Code schreiben, entscheiden Sie, was Ihr Onboarding erreichen soll — und für wen. Ein mehrstufiger Flow ist nur dann „gut“, wenn er zuverlässig die richtigen Leute in den passenden Endzustand bringt bei minimaler Verwirrung.
Benennen Sie Ihre wichtigen Nutzertypen
Verschiedene Nutzer kommen mit unterschiedlichem Kontext, Berechtigungen und Dringlichkeit. Beginnen Sie damit, Ihre primären Einstiegspersonas zu benennen und was bereits über sie bekannt ist:
- Neuer Nutzer (Self‑Serve Signup): braucht in der Regel Kontoerstellung, E‑Mail‑Verifikation, Basisprofil und erste Wert‑Aktionen.
- Eingeladener Nutzer: gehört oft bereits zu einer Organisation und sollte die Organisationserstellung überspringen; muss ggf. Bedingungen akzeptieren, Passwort setzen und Rolle bestätigen.
- Admin‑erstelltes Konto: kann vorausgefüllte Felder und verpflichtende Sicherheitsmaßnahmen (MFA, Passwort zurücksetzen beim ersten Login) haben.
Für jeden Typ listen Sie Einschränkungen (z. B. „Firma kann nicht bearbeitet werden“), benötigte Daten (z. B. „muss Workspace wählen“) und mögliche Abkürzungen (z. B. „bereits via SSO verifiziert“).
Definieren Sie, wie „done“ aussieht
Ihr Endzustand des Onboardings sollte explizit und messbar sein. „Done“ ist nicht „alle Screens durchlaufen“; es ist ein business‑bereiter Status, z. B.:
- Profil erreicht Mindestvollständigkeit
- Organisation/Workspace ist konfiguriert
- Abrechnung ist gesetzt (oder bewusst zurückgestellt)
- Nutzer erreicht die erste sinnvolle Aktion (z. B. erstellt ein Projekt)
Schreiben Sie die Abschlusskriterien als Checkliste, die das Backend auswerten kann, nicht als vages Ziel.
Pflicht‑ vs. optionale Schritte, Abhängigkeiten und Skip‑Regeln
Ordnen Sie, welche Schritte erforderlich für den Endzustand sind und welche optionale Verbesserungen darstellen. Dokumentieren Sie Abhängigkeiten („kann Team nicht einladen, bevor Workspace existiert“).
Definieren Sie abschließend Skip‑Regeln präzise: welche Schritte übersprungen werden können, für welchen Nutzertyp, unter welchen Bedingungen (z. B. „skip email verification if authenticated via SSO“), und ob übersprungene Schritte später in den Einstellungen wieder aufrufbar sind.
Flow‑Map entwerfen: Schritte, Verzweigungen und Einstiegspunkte
Bevor Sie Screens oder APIs bauen, zeichnen Sie das Onboarding als Flow‑Map: ein kleines Diagramm, das jeden Schritt, die möglichen nächsten Schritte und wie man später zurückkommt, zeigt.
1) Beginnen Sie mit einer konkreten Schrittliste
Schreiben Sie Schritte als kurze, handlungsorientierte Namen (Verben helfen): „Passwort erstellen“, „E‑Mail bestätigen“, „Firmendaten hinzufügen“, „Team einladen“, „Abrechnung verbinden“, „Fertig“. Halten Sie die erste Version einfach, fügen Sie dann Details wie Pflichtfelder und Abhängigkeiten hinzu (z. B. Abrechnung kann nicht vor Planwahl erfolgen).
Eine hilfreiche Prüfung: Jeder Schritt sollte eine Frage beantworten — „Wer sind Sie?“, „Was brauchen Sie?“, oder „Wie soll das Produkt konfiguriert werden?“ Wenn ein Schritt alle drei versucht, teilen Sie ihn.
2) Linear vs. bedingte Verzweigungen entscheiden
Die meisten Produkte profitieren von einem überwiegend linearen Rückgrat mit bedingten Verzweigungen nur wenn das Erlebnis wirklich anders ist. Typische Branch‑Regeln:
- Rolle: Admin vs. Mitglied
- Plan: Free vs. Paid
- Region: Umsatzsteuer‑/Datenschutzanforderungen
- Use‑Case: privat vs. geschäftlich
Dokumentieren Sie diese als „if/then“‑Notizen auf der Karte (z. B. „If region = EU → show VAT step“). Das hält den Flow verständlich und vermeidet ein Labyrinth.
3) Einstiegspunkte definieren (wie Onboarding startet)
Listen Sie jede Stelle auf, an der Nutzer in den Flow einsteigen können:
- Erster Login nach der Registrierung
- Annahme eines Einladungslinks
- „Setup abschließen“‑Erinnerung aus den Einstellungen (
/settings/onboarding)
Jeder Einstieg sollte den Nutzer auf den richtigen nächsten Schritt bringen, nicht immer auf Schritt eins.
4) Re‑Entry (Resume‑Verhalten) planen
Nehmen Sie an, Nutzer verlassen den Flow mitten im Schritt. Entscheiden Sie, was geschieht, wenn sie zurückkommen:
- Wiederaufnahme am letzten unvollständigen Schritt
- Teilfelder (Drafts) erhalten vs. bei Exit löschen
- Umgang mit „veralteten“ Schritten, wenn sich der Flow später ändert
Ihre Map sollte einen klaren „Resume“‑Pfad zeigen, sodass das Erlebnis verlässlich wirkt, nicht fragil.
UX‑Muster für klares, niedrigschwelliges Onboarding
Gutes Onboarding fühlt sich wie ein geführter Weg an, nicht wie ein Test. Ziel ist, Entscheidungs‑Müdigkeit zu reduzieren, Erwartungen deutlich zu machen und Nutzern zu helfen, schnell zu recovern, wenn etwas schiefgeht.
Wählen Sie ein Muster, das zur Aufgabe passt
Ein Wizard eignet sich, wenn Schritte in Reihenfolge abgeschlossen werden müssen (z. B. Identität → Abrechnung → Berechtigungen). Eine Checkliste passt, wenn Aufgaben in beliebiger Reihenfolge erledigt werden können (z. B. „Logo hinzufügen“, „Team einladen“, „Kalender verbinden“). Guided tasks (eingebettete Hinweise und Callouts im Produkt) sind ideal, wenn Lernen durch Tun statt durch Formulare stattfindet.
Wenn Sie unsicher sind, starten Sie mit einer Checkliste + Deep‑Links zu den Aufgaben und sperren nur das, was wirklich erforderlich ist.
Fortschritt zeigen, ohne Druck zu erzeugen
Fortschrittsfeedback sollte die Frage „Wie viel ist noch übrig?“ beantworten. Nutzen Sie eine der folgenden Varianten:
- Schrittanzahl (z. B. Schritt 2 von 5) für lineare Wizards
- Meilensteine (z. B. Konto → Team → Integrationen) für gruppierte Aufgaben
- Prozentangabe nur, wenn sie ehrlich und stabil ist (Sprünge vermeiden)
Fügen Sie außerdem eine „Speichern und später fertigstellen“‑Hinweis hinzu, besonders bei längeren Flows.
Labels, Microcopy und freundliche Defaults
Nutzen Sie einfache Labels („Firmenname“ statt „Entity identifier“). Erklären Sie in Microcopy, warum Sie etwas erfragen („Wir verwenden das, um Rechnungen zu personalisieren“). Prefillen Sie Daten, wo möglich, und wählen Sie sichere Defaults.
Fehlerzustände und Wiederherstellung
Gestalten Sie Fehler als Weg nach vorne: Feld hervorheben, erklären, was zu tun ist, Nutzereingaben behalten und das erste fehlerhafte Feld fokussieren. Bei serverseitigen Fehlern anzeigen, dass ein Retry möglich ist und den Fortschritt erhalten, damit Nutzer abgeschlossene Schritte nicht wiederholen müssen.
Mobile und Barrierefreiheit von Anfang an
Machen Sie Tap‑Targets groß, vermeiden Sie mehrspaltige Formulare und halten Sie primäre Aktionen sichtbar. Stellen Sie vollständige Tastaturnavigation, sichtbare Fokuszustände, beschriftete Eingabefelder und screen‑reader‑freundliche Fortschrittsanzeigen sicher (nicht nur eine visuelle Leiste).
Datenmodell: Nutzer, Schritte, Fortschritt und Versionen
Ein reibungsloser mehrstufiger Onboarding‑Flow hängt von einem Datenmodell ab, das zuverlässig drei Fragen beantworten kann: was der Nutzer als Nächstes sehen soll, was er bereits angegeben hat, und welcher Flow‑Definition er folgt.
Kerntabellen/-entitäten (was zu speichern ist)
Beginnen Sie mit einer kleinen Menge von Tabellen/Collections und erweitern Sie nur bei Bedarf:
- User: Ihr bestehender Nutzer‑Datensatz.
- OnboardingFlow: ein benannter Flow (z. B. „Default onboarding“, „Enterprise onboarding").
- Step: eine einzelne Schrittdefinition (Titel, Typ, Reihenfolge, Pflichtfelder, Hilfetext). Schritte sollten zu einer bestimmten Flow‑Version gehören.
- StepResponse: die vom Nutzer gespeicherten Daten für einen Schritt (Antworten) plus Validierungsstatus.
- Completion (oder OnboardingProgress): eine Zusammenfassungs‑Tabelle, die einen Nutzer mit einer Flow‑Version verbindet und den Gesamtstatus verfolgt.
Diese Trennung hält „Konfiguration“ (Flow/Step) sauber getrennt von „Nutzerdaten“ (StepResponse/Progress).
Versionen: in‑progress Nutzer nicht zerstören
Entscheiden Sie früh, ob Flows versioniert werden. In den meisten Produkten lautet die Antwort ja.
Wenn Sie Schritte bearbeiten (umbenennen, neu anordnen, Pflichtfelder hinzufügen), wollen Sie nicht, dass in‑progress Nutzer plötzlich Validierungsfehler bekommen oder ihren Platz verlieren. Ein einfacher Ansatz:
- Flow hat
id und version (oder eine unveränderliche flow_version_id).
- Progress verweist dauerhaft auf ein spezifisches
flow_version_id.
- Neue Nutzer bekommen die neueste Version; bestehende Nutzer bleiben auf ihrer zugewiesenen Version, es sei denn, sie werden bewusst migriert.
Teilfortschritt und Zeitstempel
Zur Speicherung von Fortschritt wählen Sie zwischen Autosave (speichert während der Eingabe) und explizitem „Weiter“. Viele Teams kombinieren beides: Entwürfe automatisch speichern, einen Schritt aber erst bei „Weiter“ als „complete“ markieren.
Verfolgen Sie Zeitstempel für Reporting und Troubleshooting: started_at, completed_at und last_seen_at (plus pro Schritt saved_at). Diese Felder treiben Onboarding‑Analytics und helfen dem Support zu verstehen, wo jemand hängen geblieben ist.
Workflow‑Logik: Zustand und Transitionen
Admin-Flow-Editor erstellen
Einen einfachen Flow-Editor mit Versionierung, Rollouts und Override-Möglichkeiten erstellen – ohne von vorn zu beginnen.
Ein mehrstufiger Onboarding‑Flow ist am einfachsten zu verstehen, wenn Sie ihn wie eine Zustandsmaschine behandeln: die Onboarding‑Session eines Nutzers befindet sich immer in einem „State“ (aktueller Schritt + Status) und erlaubt nur bestimmte Transitionen zwischen Zuständen.
Modellieren Sie den Flow als erlaubte Transitionen
Anstatt dem Frontend zu erlauben, beliebig zu einer URL zu springen, definieren Sie eine kleine Menge von Status pro Schritt (z. B. not_started → in_progress → completed) und eine klare Menge von Transitionen (z. B. start_step, save_draft, submit_step, go_back, reset_step).
Das ergibt vorhersehbares Verhalten:
- Nutzer können Pflichtschritte nicht überspringen, sofern die Flow‑Regeln das nicht erlauben.
- „Resume onboarding“ ist einfach das Laden des letzten bekannten Zustands.
- Verzweigungen sind explizit: eine Transition kann abhängig von gespeicherten Antworten zu unterschiedlichen nächsten Schritten führen.
Regeln zur Schrittabschlussprüfung (Validation + Server‑Checks)
Ein Schritt gilt nur dann als „completed“, wenn beide Bedingungen erfüllt sind:
- Client‑Validation stimmt (Pflichtfelder, Formate, etc.).
- Server‑Checks stimmen (Business‑Regeln und externe Verifikationen), z. B. „diese E‑Mail ist noch nicht vergeben“, „Steuer‑ID passt zum Land“ oder „Firmenname ist zulässig“.
Speichern Sie die Server‑Entscheidung zusammen mit dem Schritt, inklusive Fehlercodes. So vermeiden Sie Fälle, in denen die UI denkt, ein Schritt sei abgeschlossen, das Backend aber widerspricht.
Ungültigmachung, wenn frühere Antworten sich ändern
Ein leicht zu übersehender Randfall: ein Nutzer ändert einen früheren Schritt und macht spätere Schritte ungültig. Beispiel: Änderung des „Landes“ kann „Steuerdetails“ oder „verfügbare Pläne“ ungültig machen.
Gehen Sie damit um, indem Sie Abhängigkeiten nachverfolgen und nach jedem Submit downstream Schritte neu auswerten. Übliche Resultate:
- Betroffene Schritte als
needs_review markieren (oder auf in_progress zurücksetzen).
- Bestimmte Felder löschen, die nicht mehr gültig sind.
- Den nächsten Schritt auf Basis der neuen Bedingung neu berechnen.
Zurück‑Navigation und Re‑Validierung
„Zurück“ sollte unterstützt werden, muss aber sicher sein:
- Erlauben Sie Navigation zu vorherigen Schritten ohne Datenverlust.
- Wenn der Nutzer zu einem späteren Schritt zurückkehrt, führen Sie die Validierung erneut mit den aktuellen Antworten und aktuellen Server‑Regeln durch.
So bleibt das Erlebnis flexibel, während der Sitzungszustand konsistent und durchsetzbar bleibt.
Backend‑API‑Design für schrittbasiertes Onboarding
Ihr Backend‑API ist die „Single Source of Truth“ dafür, wo sich ein Nutzer im Onboarding befindet, was er bereits eingegeben hat und was er als Nächstes tun darf. Eine gute API hält das Frontend simpel: sie liefert den aktuellen Schritt, erlaubt sicheres Abschicken von Daten und erholt sich nach Refreshes oder Netzwerkproblemen.
Kernendpunkte, die Sie gewöhnlich brauchen
Mindestens sollten Sie für diese Aktionen designen:
- Get current step (and progress)
GET /api/onboarding → liefert aktuellen Schritt‑Key, Completion‑% und gespeicherte Draft‑Werte, die zum Rendern nötig sind.
- Save step data (draft or final)
PUT /api/onboarding/steps/{stepKey} mit { "data": {…}, "mode": "draft" | "submit" }
- Move next / previous (optional, wenn Sie das Nächste aus dem gespeicherten Zustand ableiten)
POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previous
- Complete onboarding
POST /api/onboarding/complete (Server verifiziert, dass alle erforderlichen Schritte erfüllt sind)
Halten Sie Antworten konsistent. Beispielsweise nach dem Speichern die aktualisierten Fortschritte plus serverseitig entschiedenen nächsten Schritt zurückgeben:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
Idempotenz: Fortschritt vor doppelten Submits schützen
Nutzer klicken doppelt, retryen bei schlechter Verbindung oder Ihr Frontend sendet Requests nach Timeout erneut. Machen Sie „Speichern“ sicher durch:
- Akzeptieren eines
Idempotency-Key Headers für PUT/POST Requests und Deduplikation anhand (userId, endpoint, key).
- Behandeln von
PUT /steps/{stepKey} als vollständiges Überschreiben der gespeicherten Nutzlast (oder dokumentieren Sie klar Partielle‑Merge‑Regeln).
- Optional: Hinzufügen einer
version (oder etag), um zu verhindern, dass neuere Daten durch veraltete Retries überschrieben werden.
Klare Fehler und feldweise Validierung
Geben Sie aussagekräftige Meldungen zurück, die die UI neben den Feldern anzeigen kann:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
Unterscheiden Sie außerdem 403 (not allowed) von 409 (conflict / wrong step) und 422 (validation), damit das Frontend korrekt reagieren kann.
Authentifizierung und Autorisierung
Trennen Sie Nutzer‑ und Admin‑Fähigkeiten:
- Nutzerendpunkte erfordern eine eingeloggte Session und dürfen nur den Onboarding‑Zustand des Aufrufers lesen/ändern.
- Admin‑Endpunkte (z. B.
GET /api/admin/onboarding/users/{userId} oder Overrides) müssen rollenbasiert gesichert und auditiert sein.
Diese Grenze verhindert versehentliche Privilegienlecks und ermöglicht trotzdem Support/Operations, festhängende Nutzer zu unterstützen.
Frontend‑Implementierung: Routing, Resume und Zuverlässigkeit
Die Aufgabe des Frontends ist, Onboarding glatt wirken zu lassen, selbst bei Netzwerkproblemen. Das heißt: vorhersehbares Routing, verlässliches Resume‑Verhalten und klare Rückmeldung beim Speichern.
Routing: eine URL pro Schritt vs. Single‑Page
Eine URL pro Schritt (z. B. /onboarding/profile, /onboarding/billing) ist meist am einfachsten. Es unterstützt Browser‑Back/Forward, Deep‑Linking aus E‑Mails und macht Refreshes sicher.
Ein Single‑Page‑Ansatz kann für sehr kurze Flows okay sein, erhöht aber das Risiko bei Refreshes, Abstürzen und „Link kopieren, um weiterzumachen“‑Szenarien. Wenn Sie diesen Weg wählen, benötigen Sie starke Persistenz (siehe unten) und sorgfältiges History‑Management.
Persistenz des Fortschritts: Server als Source of Truth
Speichern Sie Schrittabschlüsse und die neuesten Daten auf dem Server, nicht nur in localStorage. Beim Laden die aktuelle Onboarding‑State (aktueller Schritt, abgeschlossene Schritte, Draft‑Werte) abfragen und daraus rendern.
Das ermöglicht:
- Refresh‑Sicherheit
- Geräteübergreifende Fortsetzung
- Konsistenz, selbst wenn Admins den Flow ändern
Optimistisches UI, aber ohne Verwirrung
Optimistische UIs können Reibung reduzieren, benötigen aber Leitplanken:
- Zeigen Sie einen klaren Speichern… / Gespeichert / Fehler‑Status in der Nähe der primären Aktion an.
- Deaktivieren Sie die Submit‑Taste während eines laufenden Requests, um Doppel‑Submits zu verhindern.
- Wenn Sie automatisch speichern, debouncen Sie Änderungen und zeigen Fehler an („Konnte nicht speichern. Wiederholen“).
Resume‑Onboarding, höflich
Wenn ein Nutzer zurückkommt, setzen Sie ihn nicht einfach auf Schritt eins. Bieten Sie z. B. an: „Sie sind zu 60% fertig — dort weitermachen, wo Sie aufgehört haben?“ mit zwei Aktionen:
- Weiter (verlinkt zum nächsten erforderlichen Schritt)
- Später fertigstellen (bringt ihn ins Produkt, mit persistentem Banner, das zurück zu
/onboarding verlinkt)
Diese kleine Geste reduziert Abbrüche und respektiert Nutzer, die nicht sofort alles erledigen wollen.
Validierungsstrategie und Umgang mit unvollständigen Daten
Schritte aus einem Ablaufplan erstellen
Wandeln Sie Ihre Ablaufkarte in Routen, APIs und gespeicherten Fortschritt – per chatgesteuertem Build.
Validierung entscheidet, ob Onboarding reibungslos oder frustrierend ist. Ziel: Fehler früh erkennen, Nutzer in Bewegung halten und Ihr System trotzdem schützen, wenn Daten unvollständig oder verdächtig sind.
Client‑seitig validieren (schnelles Feedback)
Nutzen Sie Client‑Validation, um offensichtliche Fehler vor einem Network‑Request zu verhindern. Das reduziert Friktion und macht Schritte reaktiver.
Typische Checks: Pflichtfelder, Längenlimits, Basis‑Formate (E‑Mail/Telefon), einfache Cross‑Field‑Regeln (Passwort‑Bestätigung). Halten Sie die Meldungen spezifisch („Geben Sie eine gültige Arbeits‑E‑Mail ein“) und neben dem Feld.
Server‑seitig validieren (Korrektheit & Sicherheit)
Betrachten Sie Server‑Validation als die Wahrheit. Nutzer können Client‑Checks umgehen.
Server‑Validation sollte erzwingen:
- Autorisierung (Nutzer darf nur eigenes Onboarding ändern)
- Zulässige Werte (Enums, Ländercodes, Dokumenttypen)
- Datenintegrität (Unique Constraints, Foreign Keys)
- Sicherheitskontrollen (Rate Limits, Input‑Sanitization)
Geben Sie strukturierte Feldfehler zurück, damit das Frontend exakt hervorheben kann, was zu korrigieren ist.
Asynchrone Prüfungen unterstützen
Einige Validierungen hängen von externen oder verzögerten Signalen ab: E‑Mail‑Einzigartigkeit, Einladungscodes, Fraud‑Signals oder Dokumentenverifikation.
Behandeln Sie diese mit expliziten Status (z. B. pending, verified, rejected) und einem klaren UI‑Zustand. Wenn ein Check pending ist, erlauben Sie dem Nutzer ggf. weiterzumachen und zeigen Sie an, wann/ob er benachrichtigt wird oder welcher Schritt danach freigeschaltet wird.
Umgang mit partiellen Fehlern entscheiden
Mehrstufiges Onboarding bedeutet oft, dass partielle Daten normal sind. Entscheiden Sie pro Schritt, ob Sie:
- Draft speichern: partielle Eingaben sichern und Navigation erlauben; Schritt als „in progress“ markieren
- Fortschritt blocken: eine Mindestmenge an Feldern verlangen, bevor der Nutzer weitergeht
Praktischer Ansatz: „Immer Draft speichern, nur beim Abschluss strikt blocken.“ Das unterstützt Resume, ohne die Datenqualität zu senken.
Analytics: Abschluss messen und Drop‑Offs finden
Analytics sollten zwei Fragen beantworten: „Wo bleiben Leute stecken?“ und „Welche Änderung würde die Completion verbessern?“ Wichtig ist, eine kleine Menge konsistenter Events über alle Schritte zu tracken und sie vergleichbar zu halten, auch wenn der Flow über die Zeit geändert wird.
Verlässliches Event‑Tracking
Tracken Sie dieselben Kernereignisse für jeden Schritt:
step_viewed (Nutzer hat den Schritt gesehen)step_completed (Nutzer hat abgeschickt und Validierung bestanden)step_failed (Versuch gescheitert: Validierung oder Server‑Checks)flow_completed (Nutzer hat den finalen Erfolgszustand erreicht)
Fügen Sie jedem Event ein minimales, stabiles Kontext‑Payload hinzu: user_id, flow_id, flow_version, step_id, step_index und eine session_id (um „in einer Sitzung“ vs. „über mehrere Tage“ zu unterscheiden). Wenn Sie Resume unterstützen, fügen Sie resume=true/false bei step_viewed hinzu.
Drop‑off und Zeit pro Schritt
Um Drop‑off pro Schritt zu messen, vergleichen Sie step_viewed vs. step_completed für dieselbe flow_version. Zur Zeitmessung erfassen Sie Zeitstempel und berechnen:
- Zeit von
step_viewed → step_completed
- Zeit von
step_viewed → nächster step_viewed (nützlich, wenn Nutzer überspringen)
Behalten Sie Zeitmetriken nach Version gruppiert; sonst werden Verbesserungen durch Mischen alter und neuer Flows verschleiert.
Experiment‑Hooks ohne Metriken zu brechen
Wenn Sie A/B‑Tests für Copy oder Reihenfolge durchführen, behandeln Sie das als Teil der Analytics‑Identity:
- fügen Sie
experiment_id und variant_id zu jedem Event hinzu
- behalten Sie
step_id stabil, auch wenn Anzeigetext sich ändert
- bei Umordnungen
step_id gleich lassen und step_index für die Position nutzen
Dashboards und Exporte für Stakeholder
Bauen Sie ein einfaches Dashboard mit Completion‑Rate, Drop‑off pro Schritt, Median‑Zeit pro Schritt und „Top failed fields“ (aus step_failed Metadaten). Bieten Sie CSV‑Exporte an, damit Teams Fortschritt in Tabellen prüfen und Berichte teilen können, ohne direkten Zugriff auf das Analytics‑Tool zu benötigen.
Fortsetzverhalten zuverlässig machen
Speichern Sie Schrittdaten serverseitig, damit Nutzer aktualisieren, Geräte wechseln und nahtlos weitermachen können.
Ein mehrstufiges Onboarding‑System braucht irgendwann operativen Zugriff: Produktänderungen, Support‑Ausnahmen und sicheres Experimentieren. Ein kleines internes Admin‑Panel verhindert, dass Engineering zur Bottleneck wird.
Flow‑Builder: Schritte erstellen und editieren ohne Deploys
Starten Sie mit einem einfachen „Flow‑Builder“, der autorisiertem Personal erlaubt, Onboarding‑Flows und ihre Schritte zu erstellen/zu bearbeiten.
Jeder Schritt sollte editierbar sein mit:
- Titel und kurzem Hilfetext
- Schritt‑Typ (Form, Checklist, Dokumentupload, Terminplanung etc.)
- Pflichtfelder und Validierungsregeln
- Optionale Branching‑Regeln (z. B. „If user selects Company, show VAT step")
Fügen Sie einen Vorschau‑Modus hinzu, der den Schritt so rendert, wie ein Endnutzer ihn sieht. Das fängt verwirrende Copy, fehlende Felder und kaputte Branches, bevor echte Nutzer betroffen sind.
Versionierung und sichere Rollouts
Vermeiden Sie das direkte Editieren eines Live‑Flows. Veröffentlichen Sie stattdessen Versionen:
- Draft: editierbar, in Vorschau
- Published: unveränderliche Definition, genutzt von Nutzern
- Archived: für Support und Audits erhalten
Rollouts konfigurierbar machen:
- Nur neue Nutzer: bestehende Nutzer behalten ihre Version
- Schrittweise Prozentweise: mit 5–10% beginnen und erhöhen, wenn Metriken stabil sind
- Targeting (optional): nach Plan, Region, Partner oder Invite‑Kampagne
Das reduziert Risiko und ermöglicht saubere Vergleiche beim Messen von Completion und Drop‑off.
Overrides für Support und Ops
Support braucht Tools, um Nutzer zu entblocken ohne direkte DB‑Edits:
- Einen Schritt als komplett markieren (mit Grund)
- Den Flow eines Nutzers auf Anfang oder einen bestimmten Schritt zurücksetzen
- Einen Nutzer einen Schritt zurückbewegen nach Fehler
- Einladung/magic link/verifikations‑E‑Mail erneut senden, die an Onboarding gebunden ist
Audit‑Logs und Berechtigungen
Jede Admin‑Aktion sollte geloggt werden: wer was wann geändert hat und Vorher/Nachher. Beschränken Sie Zugriff mit Rollen (nur lesen, Editor, Publisher, Support‑Override), sodass sensible Aktionen kontrolliert und nachvollziehbar bleiben.
Testen, Sicherheit und Monitoring vor dem Launch
Bevor Sie einen mehrstufigen Onboarding‑Flow veröffentlichen, gehen Sie davon aus: Nutzer werden unerwartete Wege nehmen und etwas wird mitten im Prozess fehlschlagen (Netzwerk, Validierung, Berechtigungen). Eine gute Launch‑Checkliste beweist, dass der Flow korrekt ist, schützt Nutzerdaten und liefert frühe Warnsignale, wenn die Realität von der Planung abweicht.
Testen Sie die Flow‑Map, nicht nur die UI
Starten Sie mit Unit‑Tests für Ihre Workflow‑Logik (Zustände und Transitionen). Diese Tests sollten verifizieren, dass jeder Schritt:
- nur von erlaubten vorherigen Schritten betreten werden kann
- den erwarteten nächsten Schritt liefert für eine gegebene Antwort/Rolle/Plan
- Randfälle handhabt (Skips, Back‑Navigation, abgelaufene Sessions)
Fügen Sie dann Integrationstests hinzu, die Ihre API durchspielen: Schrittpayloads speichern, Fortschritt wiederaufnehmen und ungültige Transitionen ablehnen. Integrationstests fangen „funktioniert lokal, aber nicht in Produktion“‑Probleme wie fehlende Indexe, Serialisierungsfehler oder Version‑Mismatch zwischen Frontend und Backend.
End‑to‑End‑Tests für kritische Pfade
E2E‑Tests sollten mindestens abdecken:
- den Happy‑Path von Start → Completion
- häufige Fehler: Validierungsfehler, Server 500, Timeout/Retry und Wiederaufnahme nach Browser‑Schließen
Halten Sie E2E‑Szenarien klein, aber aussagekräftig—konzentrieren Sie sich auf die Pfade, die die meisten Nutzer und den größten Umsatz/Activation‑Impact repräsentieren.
Sensible Daten standardmäßig schützen
Wenden Sie das Prinzip der geringstmöglichen Berechtigung an: Onboarding‑Admins sollten nicht automatisch vollständigen Zugriff auf Nutzerrecords haben und Service‑Accounts nur die Tabellen/Endpoints berühren dürfen, die sie brauchen.
Verschlüsseln Sie, wo es nötig ist (Tokens, sensible IDs, regulierte Felder) und behandeln Sie Logs als potenzielles Datenleck. Vermeiden Sie das Protokollieren roher Formular‑Payloads; loggen Sie stattdessen Schritt‑IDs, Fehlercodes und Timings. Wenn Sie Payload‑Ausschnitte zur Fehlersuche loggen müssen, redigieren Sie Felder konsistent.
Monitoring, das Probleme früh erkennt
Instrumentieren Sie Onboarding wie einen Produkttrichter und wie eine API.
Tracken Sie Fehler nach Schritt, Speichern‑Latenz (p95/p99) und Resume‑Fehler. Setzen Sie Alerts für plötzliche Einbrüche in der Completion‑Rate, plötzliche Anstiege von Validierungsfehlern in einem Schritt oder erhöhte API‑Fehlerraten nach Release. So können Sie den kaputten Schritt reparieren, bevor Support‑Tickets sich stapeln.
Wo Koder.ai passt (wenn Sie das schneller bauen wollen)
Wenn Sie ein schrittbasiertes Onboarding‑System von Grund auf bauen, fließt die meiste Zeit in dieselben Bausteine wie oben: Schritt‑Routing, Persistenz, Validierungen, Progress/State‑Logik und ein Admin‑Interface für Versionierung und Rollouts. Koder.ai kann dabei helfen, diese Teile schneller zu prototypen und auszuliefern, indem es vollständige Fullstack‑Webapps aus einer Chat‑getriebenen Spezifikation generiert — typischerweise mit einem React‑Frontend, einem Go‑Backend und einem PostgreSQL‑Datenmodell, das sauber zu Flows, Steps und StepResponses passt.
Da Koder.ai Source‑Code‑Export, Hosting/Deployment und Snapshots mit Rollback unterstützt, ist es auch nützlich, wenn Sie Onboarding‑Versionen sicher iterieren (und schnell wiederherstellen, falls ein Rollout die Completion verschlechtert).