06. Nov. 2025·8 Min
Wie man eine Web‑App für Vorfallverfolgung & Postmortems baut
Ein praxisorientierter Plan zum Entwerfen, Bauen und Starten einer Web‑App für Vorfallverfolgung und Postmortems — von Workflows über Datenmodellierung bis zur UX.
Ein praxisorientierter Plan zum Entwerfen, Bauen und Starten einer Web‑App für Vorfallverfolgung und Postmortems — von Workflows über Datenmodellierung bis zur UX.
Bevor Sie Bildschirme skizzieren oder eine Datenbank wählen, einigen Sie sich darauf, was Ihr Team unter einer Incident‑Tracking‑Web‑App versteht — und was „Postmortem‑Management“ erreichen soll. Teams verwenden dieselben Begriffe oft unterschiedlich: Für die einen ist ein Vorfall jedes kundenrelevante Problem; für andere ist es nur ein Sev‑1‑Ausfall mit On‑Call‑Esklation.
Schreiben Sie eine kurze Definition, die beantwortet:
Diese Definition steuert Ihren Incident‑Response‑Workflow und verhindert, dass die App entweder zu strikt (niemand nutzt sie) oder zu locker (inkonsistente Daten) wird.
Entscheiden Sie, was ein Postmortem in Ihrer Organisation ist: eine kurze Zusammenfassung für jeden Vorfall oder ein vollständiges RCA nur für hochkritische Ereignisse. Machen Sie klar, ob das Ziel Lernen, Compliance, Verringerung wiederkehrender Vorfälle oder alle drei ist.
Eine nützliche Regel: Wenn Sie erwarten, dass ein Postmortem Veränderung bewirkt, muss Ihr Tool Action‑Items‑Tracking unterstützen, nicht nur Dokumentenablage.
Die meisten Teams bauen diese App, um ein paar wiederkehrende Schmerzpunkte zu beheben:
Halten Sie die Liste kompakt. Jedes Feature sollte mindestens auf eines dieser Probleme einzahlen.
Wählen Sie einige Metriken, die Sie automatisch aus dem Datenmodell ableiten können:
Diese werden zu Ihren Betriebsmetriken und zur "Definition of Done" für das erste Release.
Die gleiche App bedient verschiedene Rollen im On‑Call‑Betrieb:
Wenn Sie für alle gleichzeitig designen, entsteht eine überladene UI. Wählen Sie stattdessen einen Primärnutzer für v1 — sorgen Sie aber dafür, dass alle anderen später über angepasste Views, Dashboards und Berechtigungen das Nötige bekommen.
Ein klarer Workflow verhindert zwei häufige Fehlermodi: Vorfälle, die stecken bleiben, weil niemand weiß „was als Nächstes“, und Vorfälle, die als „erledigt“ aussehen, aber kein Lernen erzeugen. Beginnen Sie mit einer vollständigen Lifecycle‑Abbildung und hängen Sie dann Rollen und Berechtigungen an jeden Schritt.
Die meisten Teams folgen einem einfachen Bogen: detect → triage → mitigate → resolve → learn. Ihre App sollte das mit einer kleinen Menge vorhersehbarer Schritte abbilden, nicht mit einem endlosen Menü.
Definieren Sie, was für jede Phase „done“ bedeutet. Beispiel: Mitigation kann bedeuten, dass der Kundenimpact gestoppt ist, obwohl die Root‑Cause noch unbekannt ist.
Halten Sie Rollen explizit, damit Menschen ohne Meetings handeln können:
Ihre UI sollte den „aktuellen Owner" sichtbar machen, und der Workflow sollte Delegation unterstützen (Umschreiben, weitere Responder hinzufügen, Commander rotieren).
Wählen Sie erforderliche Zustände und erlaubte Übergänge, z. B. Investigating → Mitigated → Resolved. Fügen Sie Guardrails hinzu:
Trennen Sie interne Updates (schnell, taktisch, können unordentlich sein) von stakeholder‑gerichteten Updates (klar, zeitgestempelt, kuratiert). Bauen Sie zwei Update‑Ströme mit unterschiedlichen Templates, Sichtbarkeiten und Freigaberegeln — oft ist der Commander der einzige, der Stakeholder‑Updates veröffentlicht.
Ein gutes Incident‑Tool wirkt im UI „einfach“, weil das zugrunde liegende Datenmodell konsistent ist. Entscheiden Sie vor den Bildschirmen, welche Objekte existieren, wie sie zusammenhängen und was historisch korrekt sein muss.
Beginnen Sie mit einer kleinen Menge erstklassiger Objekte:
Die meisten Beziehungen sind One‑to‑Many:
Verwenden Sie stabile Identifikatoren (UUIDs) für Incidents und Events. Menschen brauchen trotzdem einen freundlichen Key wie INC‑2025‑0042, den Sie aus einer Sequenz erzeugen können.
Modellieren Sie diese früh, damit Sie filtern, suchen und reporten können:
Vorfallsdaten sind sensibel und werden oft später geprüft. Behandeln Sie Änderungen als Daten — nicht als Überschreibungen:
Diese Struktur macht spätere Features — Suche, Metriken, Berechtigungen — leichter implementierbar, ohne großen Refactor.
Wenn etwas ausfällt, ist die Aufgabe der App, Tipparbeit zu reduzieren und Klarheit zu erhöhen. Dieser Abschnitt behandelt den „Write‑Path": wie Menschen einen Vorfall erstellen, aktuell halten und später rekonstruieren.
Halten Sie das Intake‑Formular kurz genug, dass es beim Troubleshooten ausgefüllt werden kann. Gute Standard‑Pflichtfelder sind:
Alles andere optional bei Erstellung (Impact, Kunden‑Ticket‑Links, vermutete Ursache). Nutzen Sie smarte Defaults: Start‑Zeit auf „jetzt“ setzen, das On‑Call‑Team des Nutzers vorwählen und eine Ein‑Tap‑Aktion „Erstellen & Incident‑Room öffnen“ anbieten.
Ihre Update‑UI sollte für wiederkehrende, kleine Änderungen optimiert sein. Bieten Sie ein kompaktes Update‑Panel mit:
Machen Sie Updates als Append‑friendly: jedes Update wird zu einem zeitgestempelten Eintrag, nicht zum Überschreiben des vorherigen Textes.
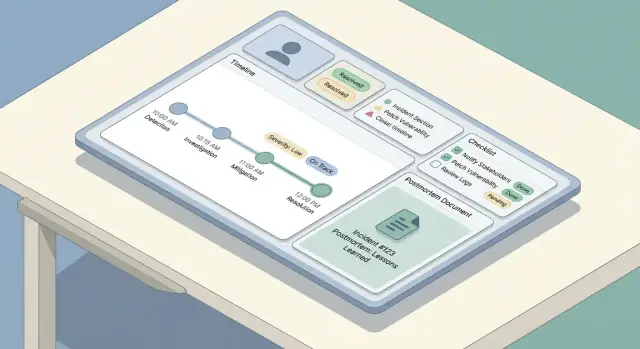
Bauen Sie eine Timeline, die mischt:
So entsteht eine verlässliche Erzählung, ohne dass Leute sich daran erinnern müssen, jeden Klick zu protokollieren.
Während eines Ausfalls laufen viele Updates vom Handy. Priorisieren Sie einen schnellen, wenig aufwändigen Screen: große Touch‑Targets, eine einzelne scrollbare Seite, offline‑fähige Entwürfe und Ein‑Tap‑Aktionen wie „Update posten“ und „Incident‑Link kopieren".
Severity ist der „Speed‑Dial“ der Incident‑Response: sie sagt, wie dringend gehandelt werden muss, wie breit kommuniziert wird und welche Trade‑offs akzeptabel sind.
Vermeiden Sie vage Labels wie „hoch/mittel/niedrig“. Lassen Sie jedes Severity‑Level klare operative Erwartungen abbilden — besonders Antwortzeit und Kommunikationsrhythmus.
Beispiel:
Machen Sie diese Regeln im UI sichtbar, wo immer die Severity gewählt wird, damit Responders nicht in Dokumenten suchen müssen.
Checklists reduzieren kognitive Belastung unter Stress. Halten Sie sie kurz, handlungsorientiert und rollenbezogen.
Ein nützliches Muster sind einige Sektionen:
Machen Sie Checklist‑Items zeitgestempelt und attribuierbar, so werden sie Teil des Incident‑Records.
Vorfälle leben selten in einem Tool. Ihre App sollte Respondern erlauben, Links anzuhängen zu:
Bevorzugen Sie „typisierte“ Links (z. B. Runbook, Ticket), damit sie später filterbar sind.
Wenn Ihre Organisation Zuverlässigkeitsziele verfolgt, fügen Sie leichte Felder hinzu wie SLO affected (ja/nein), geschätzter Error‑Budget‑Burn und Kunden‑SLA‑Risiko. Halten Sie sie optional — aber leicht ausfüllbar während oder kurz nach dem Vorfall, wenn Details frisch sind.
Ein gutes Postmortem ist leicht zu beginnen, schwer zu vergessen und konsistent über Teams. Der einfachste Weg: eine Standardvorlage (mit minimalen Pflichtfeldern) bereitstellen und aus dem Incident‑Record auto‑befüllen, sodass Menschen Zeit mit Denken statt Tippen verbringen.
Ihre eingebaute Vorlage sollte Struktur und Flexibilität ausbalancieren:
Machen Sie „Root Cause“ anfangs optional, wenn schnelleres Publizieren gewünscht ist, aber fordern Sie es vor der Final‑Freigabe.
Das Postmortem sollte kein separates, lose verknüpftes Dokument sein. Wenn ein Postmortem erstellt wird, hängen Sie automatisch an:
Nutzen Sie diese, um Postmortem‑Sektionen vorzufüllen. Beispiel: Der Abschnitt „Impact" kann mit Start/End‑Zeiten und aktueller Severity beginnen; „What we did" kann aus Timeline‑Einträgen gezogen werden.
Fügen Sie einen leichtgewichtigen Workflow hinzu, damit Postmortems nicht stocken:
Erfassen Sie bei jedem Schritt Entscheidungsnotizen: was geändert wurde, warum und wer es genehmigt hat. Das verhindert „stille Änderungen“ und erleichtert spätere Audits oder Lern‑Reviews.
Wenn Sie die UI simpel halten wollen, behandeln Sie Reviews wie Kommentare mit klaren Outcomes (Approve / Request changes) und speichern die finale Genehmigung als unveränderlichen Eintrag.
Für Teams, die es brauchen, koppeln Sie „Published“ an Ihren Status‑Updates‑Workflow (siehe /blog/integrations-status-updates), ohne Inhalte manuell zu duplizieren.
Postmortems reduzieren zukünftige Vorfälle nur, wenn Folgearbeit tatsächlich erledigt wird. Behandeln Sie Action Items als erstklassige Objekte in Ihrer App — nicht als Absatz am Dokumentenende.
Jedes Action Item sollte konsistente Felder haben, damit es verfolgt und gemessen werden kann:
Fügen Sie hilfreiche Metadaten hinzu: Tags (z. B. „monitoring“, „docs“), Komponente/Service und "created from" (Incident‑ID und Postmortem‑ID).
Fangen Sie Action Items nicht in einer einzelnen Postmortem‑Seite ein. Bieten Sie:
So wird Nacharbeit zu einer operativen Queue statt zu verstreuten Notizen.
Manche Tasks wiederholen sich (vierteljährliche Game Days, Runbook‑Reviews). Unterstützen Sie eine Recurring‑Vorlage, die neue Items nach Zeitplan erzeugt, während jede Instanz eigenständig nachverfolgbar bleibt.
Wenn Teams bereits ein anderes Ticket‑Tool nutzen, erlauben Sie, ein Action Item mit einer externen Referenz und externer ID zu versehen, während Ihre App die Source für Incident‑Verknüpfungen und Verifikation bleibt.
Bauen Sie leichte Erinnerungen ein: Benachrichtigungen, wenn Fälligkeit naht, Markierung überfälliger Items an Team‑Leads und Aufzeigen chronisch überfälliger Muster in Reports. Halten Sie Regeln konfigurierbar, damit Teams sie an ihren On‑Call‑Betrieb anpassen können.
Incidents und Postmortems enthalten oft sensible Details — Kunden‑IDs, interne IPs, Sicherheitsbefunde oder Vendor‑Probleme. Klare Zugriffsregeln halten das Tool kollaborativ, ohne es zur Datenquelle für Leaks zu machen.
Beginnen Sie mit einer kleinen, verständlichen Menge an Rollen:
Bei mehreren Teams sollten Sie Rollen nach Service/Team scopebar machen (z. B. „Payments Editors") statt globale Zugriffe zu vergeben.
Klassifizieren Sie Inhalte früh, bevor Nutzer Gewohnheiten bilden:
Ein praxisnahes Muster: Sektionen als Intern oder Teilbar markieren und das in Exporten und Status‑Seiten erzwingen. Sicherheitsvorfälle können einen eigenen Incident‑Typ mit strengeren Defaults benötigen.
Für jede Änderung an Incidents und Postmortems protokollieren Sie: wer hat geändert, was wurde geändert und wann. Schließen Sie Änderungen an Severity, Zeitstempeln, Impact und finalen Genehmigungen ein. Machen Sie Audit‑Logs durchsuchbar und nicht editierbar.
Bieten Sie starke Auth‑Optionen out of the box: E‑Mail + MFA oder Magic Link, und fügen Sie SSO (SAML/OIDC) hinzu, wenn Nutzer es erwarten. Nutzen Sie kurzlebige Sessions, sichere Cookies, CSRF‑Schutz und automatische Session‑Widerrufe bei Rollenänderungen. Für Rollout‑Überlegungen siehe /blog/testing-rollout-continuous-improvement.
Bei einem aktiven Vorfall wird gescannt — nicht gelesen. Ihre UX muss den aktuellen Zustand in Sekunden sichtbar machen und gleichzeitig Responders ermöglichen, ohne Verlorengehen ins Detail zu bohren.
Beginnen Sie mit drei Screens, die die meisten Workflows abdecken:
Regel: Die Incident‑Detail‑Seite sollte oben „Was passiert gerade?“ beantworten und darunter „Wie sind wir hierher gekommen?".
Incidents stapeln sich schnell — machen Sie Discovery flink und fehlertolerant:
Bieten Sie gespeicherte Views wie Meine offenen Incidents oder Sev‑1 diese Woche, damit On‑Call‑Engineers nicht bei jedem Shift Filter neu bauen.
Nutzen Sie konsistente, farbsichere Badges in der ganzen App (vermeiden Sie subtile Schattierungen, die unter Stress nicht unterscheiden). Halten Sie dieselbe Status‑Vokabel überall: Liste, Detail‑Header und Timeline‑Events.
Auf einen Blick sollten Responders sehen:
Priorisieren Sie Scannability:
Designen Sie für den schlimmsten Moment: wenn jemand schlaftrunken sein Telefon bedient, sollte die UI ihn trotzdem schnell zur richtigen Aktion führen.
Integrationen verwandeln ein Incident‑Tracker von „Notizablage" in das System, in dem Ihr Team Vorfälle tatsächlich managt. Listen Sie zuerst die Systeme, die Sie anbinden müssen: Monitoring/Observability (PagerDuty/Opsgenie, Datadog, CloudWatch), Chat (Slack/Teams), E‑Mail, Ticketing (Jira/ServiceNow) und eine Status‑Seite.
Meist entsteht eine Mischung:
Alarme sind laut, werden retried und kommen oft ungeordnet an. Definieren Sie einen stabilen Idempotency‑Key pro Provider‑Event (z. B. provider + alert_id + occurrence_id) und speichern Sie ihn mit einer Unique‑Constraint. Für Deduplication legen Sie Regeln fest wie „gleicher Service + gleiche Signatur innerhalb von 15 Minuten" → an bestehendes Incident anhängen.
Seien Sie explizit, was Ihre App übernimmt versus was im Quelltool bleibt:
Wenn eine Integration ausfällt, degrade gracil: retries in die Queue, Warnung im Incident anzeigen ("Slack‑Posting verzögert") und stets manuelle Fortführung erlauben.
Behandeln Sie Status‑Updates als erstklassiges Output: eine strukturierte "Update"‑Aktion im UI sollte in der Lage sein, in Chat zu posten, die Incident‑Timeline zu erweitern und optional auf der Status‑Seite zu synchronisieren — ohne die Antwortperson dreimal dasselbe schreiben zu lassen.
Ihr Incident‑Tool ist ein "during‑an‑outage"‑System — bevorzu̱gen Sie Einfachheit und Zuverlässigkeit vor Neuheiten. Der beste Stack ist oft der, den Ihr Team nachts um zwei Uhr debuggen und betreiben kann.
Starten Sie mit dem, was Ihre Engineers schon in Produktion einsetzen. Ein etabliertes Web‑Framework (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) ist meist sicherer als ein brandneues Framework, das nur eine Person versteht.
Für Datenspeicherung eignet sich eine relationale DB (PostgreSQL/MySQL): Incidents, Updates, Participants, Action Items und Postmortems profitieren von Transaktionen und klaren Relationen. Redis nur einsetzen, wenn Caching, Queues oder ephemere Locks nötig sind.
Hosting kann einfach als Managed‑Platform (Render/Fly/Heroku‑ähnlich) oder Ihre Cloud (AWS/GCP/Azure) erfolgen. Bevorzugen Sie managed Databases und Backups, wenn möglich.
Aktive Vorfälle profitieren von Echtzeit, aber Sie brauchen nicht immer WebSockets am ersten Tag.
Praktisch: API/Events so designen, dass Sie mit Polling starten und später auf WebSockets upgraden können, ohne die UI neu zu schreiben.
Wenn diese App während eines Vorfalls ausfällt, wird sie Teil des Vorfalls. Fügen Sie hinzu:
Behandeln Sie das wie ein Produktionssystem:
Wenn Sie Workflows und Screens validieren wollen, ohne sich festzulegen, kann ein Vibe‑Coding‑Ansatz gut funktionieren: Nutzen Sie ein Tool wie Koder.ai, um aus einer detaillierten Chat‑Spezifikation einen funktionierenden Prototyp zu generieren, und iterieren Sie mit Responders während Tabletop‑Übungen. Da Koder.ai echte React‑Frontends mit Go + PostgreSQL‑Backends erzeugen kann (und Source‑Code‑Export unterstützt), können frühe Versionen als "throwaway prototypes" oder als Ausgangspunkt genutzt werden — ohne die gewonnenen Erkenntnisse zu verlieren.
Die App ohne Generalprobe live zu schalten, ist ein Risiko. Die besten Teams behandeln das Tool wie jedes andere Betriebssystem: testen kritische Pfade, führen realistische Drills durch, rollen schrittweise aus und passen aufgrund echten Nutzungsverhaltens an.
Konzentrieren Sie sich zuerst auf Flows, auf die sich Menschen in Stress verlassen:
Fügen Sie Regressionstests hinzu, die unveränderliche Eigenschaften prüfen: Zeitstempel, Zeitzonen und Event‑Ordering. Incidents sind Erzählungen — wenn die Timeline falsch ist, ist Vertrauen weg.
Bugs bei Berechtigungen sind Betriebs‑ und Sicherheitsrisiken. Schreiben Sie Tests, die beweisen:
Testen Sie auch „Nahe‑Misses“, z. B. ein Nutzer verliert mitten im Vorfall den Zugriff oder ein Team‑Reorg ändert Gruppenzugehörigkeiten.
Vor breitem Rollout führen Sie Tabletop‑Simulationen durch, bei denen Ihre App die Quelle der Wahrheit ist. Wählen Sie Szenarien, die Ihre Org kennt (z. B. Partial‑Outage, Datenverzögerung, Drittanbieter‑Fehler). Achten Sie auf Reibungspunkte: verwirrende Felder, fehlender Kontext, zu viele Klicks, unklare Ownership.
Sammeln Sie Feedback sofort und verwandeln Sie es in kleine, schnelle Verbesserungen.
Starten Sie mit einem Pilot‑Team und ein paar vorgefertigten Templates (Incident‑Typen, Checklists, Postmortem‑Formate). Bieten Sie kurze Trainings und eine einseitige "How we run incidents"‑Anleitung aus der App verlinkt (z. B. /docs/incident-process).
Messen Sie Adoption‑Metriken und iterieren Sie an Reibungspunkten: Time‑to‑Create, % Incidents mit Updates, Postmortem‑Abschlussrate und Action‑Item‑Closure‑Time. Behandeln Sie diese als Produktmetriken — nicht nur Compliance‑Zahlen — und verbessern Sie kontinuierlich mit jedem Release.
Beginnen Sie damit, eine konkrete Definition zu verfassen, auf die sich Ihre Organisation einigt:
Diese Definition sollte direkt auf Ihre Workflow‑Zustände und Pflichtfelder abbilden, damit die Daten konsistent bleiben, ohne unnötig zu belasten.
Behandle Postmortems als einen Workflow, nicht als bloßes Dokument:
Wenn Sie echte Veränderung erwarten, brauchen Sie Action‑Item‑Tracking und Erinnerungen — nicht nur Ablage.
Ein praktisches V1-Set umfasst:
Fortgeschrittene Automatisierung kann warten, bis diese Flows unter Stress zuverlässig funktionieren.
Nutzen Sie eine kleine Anzahl vorhersehbarer Stadien, die dem tatsächlichen Vorgehen der Teams entsprechen:
Definieren Sie für jede Phase, was „done“ bedeutet, und fügen Sie Guardrails hinzu:
Das verhindert hängende Vorfälle und verbessert spätere Analysen.
Modellieren Sie wenige klare Rollen und koppeln Sie sie an Berechtigungen:
Machen Sie aktuellen Owner/Commander im UI deutlich sichtbar und ermöglichen Sie Delegation (Neuzuweisung, Commander‑Rotation).
Halten Sie das Datenmodell klein, aber strukturiert:
Verwenden Sie stabile Identifikatoren (UUIDs) plus einen menschenlesbaren Key (z. B. INC‑2025‑0042). Behandeln Sie Änderungen als Historie mit created_at/created_by und einem Audit‑Log für Änderungen.
Trennen Sie Update‑Ströme und wenden Sie unterschiedliche Regeln an:
Implementieren Sie unterschiedliche Templates/ Sichtbarkeiten und speichern Sie beides im Incident‑Datensatz, damit Entscheidungen später rekonstruiert werden können, ohne sensible Details zu leaken.
Definieren Sie Schweregrade mit klaren Erwartungen (Antwortgeschwindigkeit und Kommunikationsrhythmus). Beispiel:
Zeigen Sie die Regeln im UI dort an, wo die Severity gewählt wird, damit Responders während eines Ausfalls keine externen Docs suchen müssen.
Behandeln Sie Action Items als strukturierte Datensätze, nicht als Fließtext:
Bieten Sie globale Ansichten (überfällig, diese Woche fällig, nach Owner/Service) und leichte Erinnerungen/Eskalationen, damit Nachverfolgung nicht nach dem Review‑Meeting verschwindet.
Verwenden Sie anbieterspezifische Idempotency‑Keys und Dedup‑Regeln:
provider + alert_id + occurrence_idErmöglichen Sie immer manuelles Verknüpfen als Fallback, wenn APIs/Integrationen ausfallen.