Was zentrale Benachrichtigungsverwaltung löst
Zentrale Benachrichtigungsverwaltung bedeutet, jede Nachricht, die Ihr Produkt sendet — E‑Mails, SMS, Push, In‑App‑Banner, Slack/Teams‑Nachrichten, Webhook‑Callbacks — als Teil eines koordinierten Systems zu behandeln.
Anstatt dass jedes Feature‑Team seine eigene „sende eine Nachricht“-Logik baut, schaffen Sie einen einzigen Ort, an dem Events eingehen, Regeln entscheiden, was passiert, und Zustellungen Ende‑zu‑Ende nachverfolgt werden.
Welches Problem dadurch verschwindet
Wenn Benachrichtigungen über Services und Codebasen verstreut sind, treten dieselben Probleme immer wieder auf:
- Duplizierte Logik: mehrere Teams implementieren Retries, Rate‑Limits, Abmeldungen und Formatierung neu.\n- Inkonsistente Nachrichten: dieselbe „Passwort zurücksetzen“‑ oder „Rechnung fertig“‑Nachricht unterscheidet sich je nach Kanal oder Produktbereich und verwirrt Nutzer und Support.\n- Fehlende Audit‑Spuren: wenn ein Kunde sagt „Ich habe das nie bekommen“, ist es schwer zu beantworten, was gesendet wurde, an wen, wann und warum.
Zentralisierung ersetzt ad‑hoc‑Senden durch einen konsistenten Workflow: Event erstellen, Präferenzen und Regeln anwenden, Vorlagen wählen, über Kanäle liefern und Ergebnisse protokollieren.
Wer profitiert
Ein Notification‑Hub dient typischerweise:
- Admins: konfigurieren Kanäle, Vorlagen, Routing und Compliance‑Regeln ohne Deploys.\n- Support‑Teams: suchen und verifizieren Zustellversuche, beheben Fehler und antworten mit Sicherheit.\n- Produktteams: liefern Features schneller, indem sie Events emittieren statt neue Notification‑Pipelines zu bauen.\n- Endnutzer: steuern Präferenzen (Opt‑in/Opt‑out, Ruhezeiten, Kanäle) mit vorhersehbarem Ergebnis.
Woran Sie Erfolg erkennen
Die Methode funktioniert, wenn:
- Vorfallvolumen sinkt, weil Retries, Throttling und Fallback‑Kanäle standardisiert sind.\n- Änderungen (Textänderungen, Routing‑Anpassungen, neue Empfänger) Minuten dauern — nicht einen Release‑Zyklus.\n- Reporting klar ist: Zustellraten nach Kanal, Time‑to‑deliver, Fehlergründe und wer was geändert hat.
Anforderungen und Scope: Kanäle, Use Cases, Einschränkungen
Bevor Sie Architektur skizzieren, klären Sie, was „zentrale Benachrichtigungssteuerung“ für Ihre Organisation bedeutet. Klare Anforderungen halten die erste Version fokussiert und verhindern, dass der Hub zu einem halbgebauten CRM wird.
Definieren Sie Ihre Nachrichtentypen (und warum sie sich unterscheiden)
Beginnen Sie mit einer Auflistung der Kategorien, die Sie unterstützen wollen, denn sie bestimmen Regeln, Vorlagen und Compliance:
- Transaktional: Passwort‑Resets, Belege, Kontoänderungen. Meist verpflichtend und zeitkritisch.\n- Marketing: Promotions, Newsletter, Produktankündigungen. Immer opt‑in/opt‑out relevant.\n- Alerts: Sicherheitswarnungen, Ausfälle, verdächtige Aktivitäten. Oft dringlich und können manche Präferenzen umgehen.\n- Erinnerungen: Termine, Verlängerungen, unvollständige Aufgaben. Zeitfenster und Throttling sind wichtig.
Seien Sie explizit, welcher Kategorie jede Nachricht angehört — das verhindert später „Marketing als Transaktionales“.
Kanäle wählen: jetzt unterstützen vs. später
Wählen Sie eine kleine Menge, die Sie vom ersten Tag an zuverlässig betreiben können, und dokumentieren Sie „spätere“ Kanäle, damit Ihr Datenmodell sie nicht blockiert.
Jetzt unterstützen (typisches MVP): E‑Mail + einen Echtzeitkanal (Push oder In‑App) oder SMS, wenn Ihr Produkt darauf angewiesen ist.
Später unterstützen: Chat‑Tools (Slack/Teams), WhatsApp, Sprache, Post, Partner‑Webhooks.
Notieren Sie auch Kanal‑Einschränkungen: Rate‑Limits, Zustellbarkeitsanforderungen, Sender‑Identitäten (Domains, Telefonnummern) und Kosten pro Send.
Nicht‑Ziele zur Wahrung des Scopes
Zentrale Benachrichtigungsverwaltung ist nicht „alles, was mit Kunden zu tun hat“. Häufige Nicht‑Ziele:
- Keine vollständige Kontaktdatenanreicherung (halten Sie Nutzer/Empfänger minimal).\n- Kein Kampagnen‑Builder mit Segmentierung, A/B‑Tests oder Analytics‑Dashboards.\n- Keine Ticketing/Eskalations‑Workflows (integrieren Sie bestehende Tools stattdessen).
Compliance‑ und Aufbewahrungsanforderungen
Erfassen Sie Regeln früh, damit Sie sie nicht nachträglich einbauen müssen:
- Opt‑in/Einwilligung pro Kanal und Nachrichtentyp (besonders Marketing).\n- Abmelde‑Handhabung (One‑Click, wo erforderlich) und Suppression‑Listen.\n- Aufbewahrung: wie lange Nachrichtentexte vs. Metadaten gespeichert werden (z. B. 30/90/365 Tage).\n- Auditierbarkeit: wer Vorlagen, Routing oder Präferenzen geändert hat — und wann.
Wenn Sie bereits Richtlinien haben, verlinken Sie intern (z. B. /security, /privacy) und nehmen Sie sie als Akzeptanzkriterien für das MVP.
Architektur‑Übersicht eines Notification‑Hubs
Ein Notification‑Hub ist am einfachsten als Pipeline zu verstehen: Events gehen rein, Nachrichten kommen raus, und jeder Schritt ist beobachtbar. Verantwortlichkeiten zu trennen macht es einfacher, später Kanäle (SMS, WhatsApp, Push) hinzuzufügen, ohne alles neu zu schreiben.
Kernkomponenten
1) Event‑Intake (API + Connectoren). Ihre App, Services oder externe Partner senden „something happened“ Events an einen einzigen Einstiegspunkt. Übliche Intake‑Wege sind REST‑Endpoints, Webhooks oder direkte SDK‑Aufrufe.
2) Routing‑Engine. Der Hub entscheidet wen zu benachrichtigen ist, über welchen Kanal/ welche Kanäle und wann. Diese Schicht liest Empfängerdaten und Präferenzen, wertet Regeln aus und erzeugt einen Delivery‑Plan.
3) Templating + Personalisierung. Ausgehend vom Delivery‑Plan rendert der Hub eine kanal‑spezifische Nachricht (E‑Mail‑HTML, SMS‑Text, Push‑Payload) mit Vorlagen und Variablen.
4) Delivery‑Worker. Diese integrieren sich mit Providern (SendGrid, Twilio, Slack usw.), handhaben Retries und respektieren Rate‑Limits.
5) Tracking + Reporting. Jeder Versuch wird protokolliert: accepted, sent, delivered, failed, opened/clicked (wenn verfügbar). Das treibt Admin‑Dashboards und Audit‑Trails an.
Sync vs. Async Verarbeitung
Nutzen Sie synchrone Verarbeitung nur für leichte Intake‑Arbeit (z. B. validieren und 202 Accepted zurückgeben). In den meisten realen Systemen sollten Sie asynchron routen und liefern:
- Queue nach Intake schützt Ihre App vor Provider‑Ausfällen und Traffic‑Spitzen.\n- Separate Queues pro Kanal oder Priorität (transactional vs. marketing), damit ein Strom den anderen nicht ausdurstet.
Umgebungen und Konfiguration
Planen Sie früh für dev/staging/prod. Speichern Sie Provider‑Credentials, Rate‑Limits und Feature‑Flags in umgebungspezifischer Konfiguration (nicht in Vorlagen). Versionieren Sie Vorlagen, damit Sie Änderungen in Staging testen können, bevor sie Produktion beeinflussen.
Wer besitzt Regeln und Inhalte?
Eine sinnvolle Aufteilung ist:
- Ingenieure verantworten Event‑Schemas, Integrationen und Guardrails (Timeouts, Retries, Idempotenz).\n- Admins/ops verantworten Routing‑Regeln und Vorlagen‑Texte, mit Freigabeprozessen für risikobehaftete Kanäle.
Diese Architektur gibt eine stabile Basis und hält Alltagsnachrichten außerhalb von Deploy‑Zyklen.
Event‑Modell und Datenverträge
Ein Notification‑Hub lebt oder stirbt mit der Qualität seiner Events. Wenn verschiedene Teile Ihres Produkts „dasselbe“ unterschiedlich beschreiben, wird Ihr Hub seine Zeit mit Übersetzen, Raten und Brechen verbringen.
Definieren Sie ein klares Event‑Schema
Starten Sie mit einem kleinen, expliziten Vertrag, den jeder Producer befolgen kann. Eine praktische Basis sieht so aus:
- event_name: stabiler Identifier (z. B.
invoice.paid, comment.mentioned)\n- actor: wer es ausgelöst hat (User‑ID, Service‑Name)\n- recipient: für wen es ist (User‑ID, Team‑ID oder Liste)\n- payload: die geschäftlichen Felder zum Zusammensetzen der Nachricht (Betrag, invoice_id, comment_excerpt)\n- metadata: Kontext für Routing und Betrieb (tenant/workspace ID, timestamp, source, locale hints)
Diese Struktur hält eventgesteuerte Notifications verständlich und unterstützt Routing‑Regeln, Vorlagen und Zustell‑Tracking.
Versionieren Sie Ihre Contracts (Änderungen sind ok)
Events entwickeln sich. Vermeiden Sie Brüche durch Versionierung, z. B. schema_version: 1. Bei Breaking Changes veröffentlichen Sie eine neue Version (oder einen neuen Event‑Namen) und unterstützen eine Übergangszeit beide Versionen. Das ist wichtig, wenn mehrere Producer (Backends, Webhooks, Scheduled Jobs) einen Hub speisen.
Validieren, säubern und idempotent machen
Behandeln Sie eingehende Events als untrusted Input, selbst aus eigenen Systemen:
- Validieren Sie erforderliche Felder und Typen; lehnen Sie malformed Events ab oder quarantänen Sie sie.\n- Säubern Sie Payload‑Strings, um Injektionen oder Formatierungsprobleme beim Rendern von Vorlagen zu verhindern (HTML‑E‑Mails, Slack/Teams‑Markdown, SMS).\n- Fügen Sie einen Idempotency‑Key hinzu (z. B.
idempotency_key: invoice_123_paid), damit Retries keine doppelten Sends erzeugen.
Starke Datenverträge reduzieren Support‑Tickets, beschleunigen Integrationen und machen Reporting/Audit‑Logs verlässlicher.
Benutzer, Empfänger und Benachrichtigungspräferenzen
Ein Hub funktioniert nur, wenn er weiß wer jemand ist, wie man ihn erreicht und was er zu empfangen zugestimmt hat. Behandeln Sie Identität, Kontaktdaten und Präferenzen als erstklassige Objekte — nicht als beiläufige Felder im User‑Record.
Empfänger vs. Benutzer
Trennen Sie User (Account, der sich einloggt) von Recipient (Entität, die Nachrichten empfangen kann):
- Ein User kann mehrere Recipients haben (Arbeits‑E‑Mail, private E‑Mail, SMS‑Nummer, Slack‑Handle).\n- Ein Recipient kann ein gemeinsames Ziel sein, z. B. ein Team‑Postfach oder eine On‑Call‑Rotation.
Für jeden Kontaktpunkt speichern Sie: Wert (z. B. E‑Mail), Kanaltyp, Label, Besitzer und Verifizierungsstatus (unverified/verified/blocked). Ebenfalls Metadaten wie zuletzt verifiziertes Datum und Verifikationsmethode (Link, Code, OAuth).
Präferenzen: Kanal, Thema und Zeit
Präferenzen sollten aussagekräftig, aber vorhersehbar sein:
- Nach Thema (z. B. Billing, Security, Deployments)\n- Nach Kanal (E‑Mail, SMS, Push, Slack)\n- Ruhezeiten (Empfänger‑lokale Zeitzone), mit Ausnahmen für kritische Alerts
Modellieren Sie geschichtete Defaults: Organisation → Team → User → Recipient, wobei niedrigere Ebenen höhere überschreiben. So können Admins sinnvolle Basiseinstellungen machen, während Individuen persönliche Lieferung steuern.
Einwilligung, Abmeldungen und Nachweis
Consent ist mehr als ein Häkchen. Speichern Sie:
- Opt‑in/Opt‑out Zeitstempel pro Kanal und Thema\n- Quelle der Einwilligung (UI, API, Import) sowie Akteur (User/Admin/System)\n- Abmeldegründe (Freitext oder Enum) und Suppression‑Ablauf, wenn temporär\n- Nachweise, wenn erforderlich (Double‑Opt‑In‑Token, Webhook‑Callback, signierter Eintrag)
Machen Sie Consent‑Änderungen auditierbar und leicht exportierbar (z. B. /settings/notifications), denn Support braucht das, wenn Nutzer fragen „Warum habe ich das bekommen?“ oder „Warum nicht?"
Routing‑Regeln: wer bekommt was, wo und wann
Zur Live-Umgebung gelangen
Setze und hoste deine Benachrichtigungs-App, wenn du bereit bist, und iteriere ohne lange Release-Zyklen.
Routing‑Regeln sind das „Gehirn“ eines Notification‑Hubs: sie entscheiden, welche Recipients benachrichtigt werden, über welche Kanäle und unter welchen Bedingungen. Gutes Routing reduziert Lärm, ohne kritische Alerts zu verpassen.
Definieren Sie die Eingaben, die Ihre Regeln bewerten können. Halten Sie die erste Version klein, aber aussagekräftig:
- Event‑Typ (z. B.
invoice.overdue, deployment.failed, comment.mentioned)\n- User‑Segment (Rolle, Plan, Team, Region, Ownership — wer empfänglich ist)\n- Severity/Priority (info, warning, critical)\n- Zeitfenster (Geschäftszeiten vs. nach Feierabend; Ruhezeiten)\n- Locale (zur Auswahl der richtigen Template‑Sprache und Formatierung)
Diese Inputs sollten aus Ihrem Event‑Contract abgeleitet werden, nicht von Admins pro Notification manuell eingetippt.
Rule‑Actions (das „wie“)
Actions legen das Lieferverhalten fest:
- Kanäle wählen: E‑Mail, SMS, Push, Slack/Teams, Webhook, In‑App Inbox\n- Throttling/Digest: Wiederholungen begrenzen (z. B. „max 1 pro 30 min“) oder nicht‑dringliche Nachrichten bündeln\n- Esklatieren: wenn nicht bestätigt innerhalb X Minuten, an eine On‑Call‑Rotation schicken\n- An On‑Call routen: Zeitpläne integrieren, damit außerhalb der Geschäftszeiten richtige Personen erreicht werden
Priorität, Fallback und Fehlerbehandlung
Definieren Sie eine explizite Prioritäts‑ und Fallbackreihenfolge pro Regel. Beispiel: zuerst Push, falls Push fehlschlägt SMS, zuletzt E‑Mail.
Binden Sie Fallback an reale Zustellsignale (bounced, provider error, device unreachable) und stoppen Sie Retry‑Schleifen mit klaren Caps.
Sicheres Editieren und Review‑Workflow
Regeln sollten über eine geführte UI editierbar sein (Dropdowns, Vorschauen, Warnungen), mit:
- Draft vs. Published Zuständen\n- Peer Review/Genehmigung für weitreichende Änderungen\n- Simulationsmodus (zeige „wer würde das bekommen?“ bei Beispiel‑Events)\n- Audit‑Trail der jede Änderung mit Admin und Zeitstempel verknüpft
Vorlagen und Lokalisierung für konsistente Nachrichten
Vorlagen sind der Punkt, an dem zentrale Verwaltung aus „vielen Nachrichten“ eine kohärente Produkt‑Erfahrung macht. Ein gutes Template‑System hält Tonfall über Teams hinweg konsistent, reduziert Fehler und lässt Multikanal‑Zustellung bewusst wirken.
Template‑Struktur: vorhersehbar und kanalbewusst
Behandeln Sie eine Vorlage als strukturiertes Asset, nicht als Text‑Blob. Mindestens speichern Sie:
- Subject/Title (E‑Mail‑Betreff, Push‑Titel, In‑App‑Header)\n- Body (HTML + Plaintext für E‑Mail; Kurz/Lang‑Varianten für Push/SMS)\n- Variablen (typed Platzhalter wie
{{first_name}}, {{order_id}}, {{amount}})\n- Formatierungsregeln (erlaubte Markups pro Kanal, Max‑Längen, Link‑Policy)
Halten Sie Variablen explizit mit Schema, damit das System validieren kann, ob ein Event‑Payload alles liefert, was nötig ist. Das verhindert halbgerenderte Nachrichten wie „Hi {{name}}".
Lokalisierung: Locale‑Auswahl und fehlende Übersetzungen
Definieren Sie, wie die Locale des Empfängers gewählt wird: Nutzerpräferenz zuerst, dann Account/Org‑Setting, dann Default (oft en). Speichern Sie pro Vorlage Übersetzungen pro Locale mit klarer Fallback‑Policy:
- Wenn
fr-CA fehlt, auf fr zurückfallen.\n- Wenn fr fehlt, auf die Default‑Locale der Vorlage zurückfallen.\n- Wenn eine erforderliche Übersetzung fehlt, Senden blockieren für diese Locale oder auf Default umschalten und die Fallback im Zustellungs‑Metadaten loggen.
So werden fehlende Übersetzungen in Reporting sichtbar statt stillschweigend degradierend.
Vorschau und Test‑Sende‑Flow (Admins + QA)
Bieten Sie eine Template‑Vorschau, die Admins erlaubt:
- Kanal wählen (E‑Mail/SMS/Push)\n- Locale wählen\n- Beispiel‑Event‑Payload (echtes captured Event oder gemocktes JSON)
Rendern Sie die finale Nachricht genau so, wie die Pipeline sie senden wird, inklusive Link‑Rewriting und Trunkierungsregeln. Fügen Sie ein Test‑Senden hinzu, das eine sichere „Sandbox‑Empfängerliste“ nutzt, um versehentliche Kunden‑Mails zu vermeiden.
Versionierung und Freigaben, um Unfälle zu vermeiden
Vorlagen sollten wie Code versioniert werden: jede Änderung erzeugt eine neue unveränderliche Version. Verwenden Sie Stati wie Draft → In review → Approved → Active, mit optionalen rollenbasierten Freigaben. Rollbacks sollten mit einem Klick möglich sein.
Für Auditierbarkeit speichern Sie, wer was geändert hat, wann und warum, und verknüpfen das mit Zustellungs‑Outcomes, damit Sie Anstiege in Fehlern mit Template‑Änderungen korrelieren können (siehe auch /blog/audit-logs-for-notifications).
Kanal‑Integrationen und Zustellpipeline
Sicher ausliefern mit Snapshots
Teste Routing-Änderungen und rolle schnell zurück, wenn eine Anpassung Störungen verursacht oder Ergebnisse verfehlt.
Ein Hub ist nur so zuverlässig wie seine Last‑Mile: die Channel‑Provider, die tatsächlich E‑Mail, SMS und Push zustellen. Ziel ist, jede Provider‑Integration wie ein „Plug‑in“ zu behandeln, dabei aber Zustellverhalten kanalübergreifend konsistent zu halten.
Zuerst je Kanal ein Provider integrieren
Starten Sie mit einem gut unterstützten Provider pro Kanal — z. B. SMTP oder E‑Mail‑API, ein SMS‑Gateway und ein Push‑Service (APNs/FCM via Vendor). Kapseln Sie Integrationen hinter einem gemeinsamen Interface, damit Sie Provider später ohne große Änderungen austauschen können.
Jede Integration sollte handeln:
- Authentifizierung und Request‑Signing\n- Payload‑Mapping (Ihre Nachricht → Provider‑Format)\n- Provider‑spezifische Einschränkungen (Attachment‑Limits, Sender‑IDs, Opt‑out‑Header)
Bauen Sie eine Zustellpipeline, nicht nur API‑Calls
Behandeln Sie „sende Benachrichtigung“ als Pipeline mit klaren Stufen: enqueue → prepare → send → record. Selbst wenn Ihre App klein ist, verhindert ein Queue‑basiertes Worker‑Modell, dass langsame Provider‑Aufrufe Ihre Web‑App blockieren, und bietet einen Ort für sichere Retries.
Praktischer Ansatz:
- Die Web‑App schreibt einen "delivery job" in eine Queue\n- Worker ziehen Jobs, rufen den Provider auf und speichern das Ergebnis\n- Optionale Webhooks aktualisieren den Status asynchron
Standardisieren Sie Status und Fehlerbehandlung
Provider antworten sehr heterogen. Normalisieren Sie in ein internes Statusmodell wie: queued, sent, delivered, failed, bounced, suppressed, throttled.
Speichern Sie die rohe Provider‑Antwort zum Debugging, bauen Sie Dashboards und Alerts jedoch auf den normalisierten Zuständen auf.
Retries, Backoff, Rate‑Limits und Batching
Implementieren Sie Retries mit exponentiellem Backoff und einer maximalen Anzahl von Versuchen. Retrieren Sie nur transient Errors (Timeouts, 5xx, Throttling), nicht permanente Fehler (ungültige Nummer, Hard‑Bounce).
Respektieren Sie Provider‑Rate‑Limits durch pro‑Provider Throttling. Bei hohem Volumen batchen Sie, wo möglich (z. B. Bulk‑E‑Mail APIs), um Kosten zu senken und Durchsatz zu erhöhen.
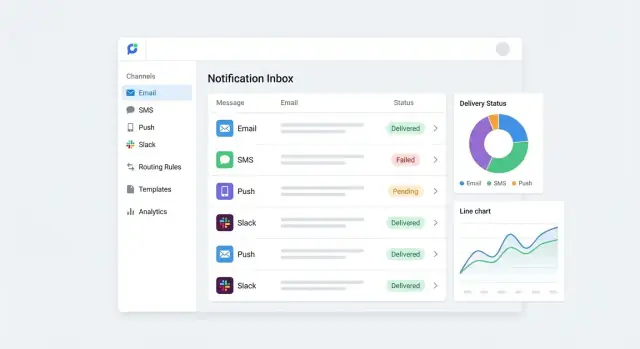
Tracking, Status und Reporting‑Dashboards
Ein Hub ist nur so vertrauenswürdig wie seine Sichtbarkeit. Wenn ein Kunde sagt „Ich habe diese E‑Mail nie bekommen“, brauchen Sie einen schnellen Weg: Was wurde gesendet, über welchen Kanal, und was ist danach passiert?
Definieren Sie klare Zustandsdefinitionen
Standardisieren Sie eine kleine Menge an Zuständen kanalübergreifend, damit Reporting konsistent bleibt. Praktische Basis:
- queued (angenommen und wartet auf Versand)\n- sent (an Provider übergeben)\n- delivered (geliefert, wenn Kanal das unterstützt)\n- bounced (permanenter Zustellfehler, meist E‑Mail)\n- failed (konnte nicht gesendet werden aufgrund von Fehlern oder Provider‑Ablehnung)\n- opened (falls verfügbar) (bei manchen E‑Mail‑Providern; oft nicht für SMS/Push)
Behandeln Sie diese als Timeline, nicht als Einzelwert — jede Nachricht kann mehrere Status‑Updates emittieren.
Suchbares Nachrichten‑Log bauen
Erstellen Sie ein Nachrichtenlog, das Support und Betrieb leicht nutzen können. Mindestens suchbar nach:
- Recipient (User‑ID, E‑Mail, Telefon)\n- Event (z. B.
invoice.paid, password.reset)\n- Zeitbereich (heute, letzte 7 Tage)
Zeigen Sie Schlüssel‑Details: Kanal, Template‑Name/Version, Locale, Provider, Fehlercodes und Retry‑Count. Standardmäßig sicher: maskieren Sie sensible Felder (teilweise Redaction von E‑Mail/Telefon) und schränken Sie Zugriff per Rollen ein.
Nachrichten mit upstream Events korrelieren
Fügen Sie Trace‑IDs hinzu, um jede Notification mit der auslösenden Aktion zu verbinden (Checkout, Admin‑Update, Webhook). Verwenden Sie dieselbe Trace‑ID in:
- dem ursprünglichen Event‑Record\n- der Notification‑Anfrage\n- allen Zustellversuchen und Status‑Updates
Das verwandelt „Was ist passiert?“ in eine gefilterte Ansicht statt in eine Suche über Systeme hinweg.
Dashboards, die wirklich helfen
Fokussieren Sie Dashboards auf Entscheidungen, nicht Vanity‑Metriken:
- Volumen nach Kanal und Event (Spitzen erkennen)\n- Fehler nach Provider, Template und Grund (Ausfälle und schlechte Daten finden)\n- Top‑Templates nach Send‑Anzahl und Fehlerquote (Prioritäten ableiten)
Fügen Sie Drill‑downs aus Diagrammen in das zugrundeliegende Nachrichtenlog hinzu, damit jede Metrik erklärbar ist.
Sicherheit, Zugriffskontrolle und Auditierbarkeit
Ein Hub berührt Kundendaten, Provider‑Credentials und Nachrichteninhalte — Security muss eingebaut sein, nicht nachträglich. Ziel: nur die richtigen Personen ändern Verhalten, Geheimnisse bleiben geheim und jede Änderung ist nachvollziehbar.
Rollenbasierte Zugriffskontrolle (RBAC)
Starten Sie mit einer kleinen Menge an Rollen und ordnen Sie sie den relevanten Aktionen zu:
- Admin: Organisationseinstellungen, Nutzer und Aufbewahrungsrichtlinien verwalten.\n- Notification Manager: Routing‑Regeln, Vorlagen und Lokalisierungen bearbeiten.\n- Integration Manager: Channel‑Provider‑Keys (E‑Mail/SMS/Push), Webhooks und Callback‑URLs hinzufügen/aktualisieren.\n- Viewer/Auditor: Read‑only Zugriff auf Dashboards und Audit‑Trails.
Nutzen Sie Prinzipien der geringsten Rechte: neue Nutzer sollten standardmäßig nicht Regeln oder Credentials editieren können.
Umgang mit Geheimnissen und Rotation
Provider‑Keys, Webhook‑Signing‑Secrets und API‑Tokens sind sensible Daten:
- Verschlüsseln Sie Secrets at‑rest (KMS/Managed Key Vault) und beschränken Sie Entschlüsselung auf den Delivery‑Service.\n- Unterstützen Sie Rotation ohne Downtime (mehrere aktive Keys, Versionierung, gestufte Cutovers).\n- Redacten Sie sensible Felder in Logs; vermeiden Sie Logging von Nachrichtentexten, wenn sie PII enthalten können.
Verlässliche Audit‑Logs
Jede Konfigurationsänderung sollte ein unveränderbares Audit‑Event schreiben: wer hat was wann geändert, von wo (IP/Device) und vorher/nachher‑Werte (geheime Felder maskiert). Verfolgen Sie Änderungen an Routing‑Regeln, Vorlagen, Provider‑Keys und Berechtigungszuweisungen. Bieten Sie einfachen Export (CSV/JSON) für Compliance‑Reviews.
Aufbewahrung und Löschanfragen
Definieren Sie Aufbewahrung pro Datentyp (Events, Zustellversuche, Inhalte, Audit‑Logs) und dokumentieren Sie das in der UI. Unterstützen Sie Löschanfragen, indem Sie Empfänger‑Identifier entfernen oder anonymisieren, während Sie aggregierte Metriken und maskierte Audit‑Records behalten, wenn nötig.
UX für Admins und Endnutzer
Starte die Admin-Konsole
Erstelle die React-Admin-Konsole und eine Go-API mit PostgreSQL-Anbindung, ohne alles manuell zu verdrahten.
Ein Hub steht oder fällt mit Benutzbarkeit. Die meisten Teams verwalten Benachrichtigungen nur selten — bis etwas schiefgeht. Designen Sie die UI für schnelles Scannen, sichere Änderungen und klare Ergebnisse.
Admin‑Console: die Seiten, die zählen
Regeln sollten wie Policies lesbar sein, nicht wie Code. Nutzen Sie eine Tabelle mit „IF event… THEN send…“‑Formulierungen, sowie Chips für Kanäle (E‑Mail/SMS/Push/Slack) und Empfänger. Integrieren Sie einen Simulator: Event auswählen und genau sehen, wer was wann erhalten würde.
Vorlagen profitieren von einem Side‑by‑Side‑Editor und Vorschau. Admins sollen Locale, Kanal und Beispieldaten umschalten können. Bieten Sie Versionierung mit „Publish“‑Schritt und Ein‑Klick‑Rollback.
Empfänger sollten Individuen und Gruppen (Teams, Rollen, Segmente) unterstützen. Mitgliedschaften sichtbar machen („Warum ist Alex im On‑Call?“) und zeigen, wo ein Empfänger in Regeln referenziert wird.
Provider‑Health braucht eine Kurzansicht: Zustelllatenz, Fehlerquote, Queue‑Tiefe und letzter Vorfall. Verknüpfen Sie jedes Problem mit einer menschenlesbaren Erklärung und nächsten Schritten (z. B. „Twilio Auth fehlgeschlagen — API‑Key‑Berechtigungen prüfen").
Endnutzer‑Einstellungen: Kontrolle ohne Verwirrung
Halten Sie Präferenzen leichtgewichtig: Kanal‑Opt‑ins, Ruhezeiten und Themen‑/Kategorien‑Schalter (z. B. „Billing“, „Security“, „Produktupdates“). Zeigen Sie eine Klartext‑Zusammenfassung oben („Sie erhalten Sicherheits‑Alerts per SMS, jederzeit").
Bieten Sie respektvolle und konforme Unsubscribe‑Flows: One‑Click für Marketing und klare Hinweise, wenn kritische Alerts nicht abgeschaltet werden können ("Erforderlich für Kontosicherheit"). Wenn ein Nutzer einen Kanal deaktiviert, bestätigen Sie die Änderung („Keine SMS mehr; E‑Mail bleibt aktiviert").
Operatoren brauchen sichere Tools unter Druck:
- Re‑Send mit Guardrails (Ratenlimits, Bestätigung, Standard: an ursprüngliche Empfänger)\n- Cancel geplante Notifications mit Audit‑Trail\n- Suppress laute Event‑Quellen temporär (zeitlich begrenzt)\n- Incident Mode um Routing zu überschreiben (z. B. Eskalation an On‑Call) und nicht‑essentielle Nachrichten zu pausieren
Leere Zustände und handlungsfähige Fehler
Leere Zustände sollen beim Setup führen („Noch keine Regeln — erstellen Sie Ihre erste Routing‑Regel“) und zum nächsten Schritt verlinken (z. B. /rules/new). Fehlermeldungen sollen sagen, was passiert ist, was betroffen ist und was zu tun ist — ohne internes Jargon. Bieten Sie, wenn möglich, eine schnelle Korrekturoption („Provider neu verbinden") und einen „Details kopieren“‑Button für Support‑Tickets.
MVP‑Plan, Tests und Rollout‑Strategie
Ein Hub kann zu einer großen Plattform werden, sollte aber klein starten. Ziel des MVP ist, die End‑to‑End‑Fluss (Event → Routing → Template → Send → Track) mit möglichst wenigen Teilen zu beweisen und dann sicher zu erweitern.
Wenn Sie das erste lauffähige System beschleunigen wollen, kann eine Low‑Code/assistierte Plattform wie Koder.ai helfen, Admin‑Console und Core‑API schnell aufzubauen: React‑UI, ein Go‑Backend mit PostgreSQL und iteratives Arbeiten in einem Chat‑getriebenen Workflow — nutzen Sie Planung, Snapshots und Rollback, um Änderungen sicher zu halten, während Sie Regeln, Vorlagen und Audit‑Logs verfeinern.
Ein minimal brauchbares MVP
Halten Sie den ersten Release bewusst eng:
- Ein Event‑Typ (z. B. „password reset requested“ oder „invoice paid").\n- Ein Kanal (meist E‑Mail) mit einer Provider‑Integration.\n- Einfache Vorlagen mit wenigen Variablen (Name, Datum, Betrag) und Plain‑Fallback.\n- Kleine Admin‑UI zum Anzeigen von Sends und Status (
queued/sent/failed).
Dieses MVP soll beantworten: „Können wir zuverlässig die richtige Nachricht an den richtigen Empfänger senden und sehen, was passiert ist?"
Tests, die Zustellung und Vertrauen schützen
Notifications sind user‑sichtbar und zeitkritisch; automatisierte Tests zahlen sich daher schnell aus. Konzentrieren Sie sich auf drei Bereiche:
- Routing‑Tests: Bei gegebenem Event und Empfängerpräferenzen asserten, welcher Kanal und welche Unterdrückungen gelten.\n2. Templating‑Tests: Templates mit Beispieldaten rendern, erforderliche Variablen validieren und Escaping prüfen (kein kaputtes HTML oder fehlerhaften SMS‑Text).\n3. Retry‑ und Fehler‑Tests: Provider‑Timeouts und Fehler simulieren, Retry‑Policy, Idempotenz (keine Duplikate) und Dead‑Letter‑Handling prüfen.
Fügen Sie ein kleines Set End‑to‑End‑Tests hinzu, das an ein Sandbox‑Provider‑Konto in CI sendet.
Rollout ohne Überraschungen
Verwenden Sie gestufte Deployments:
- Shadow‑Mode: Events verarbeiten und „would‑send“‑Datensätze erzeugen, aber nicht ausliefern.\n- Gradueller Traffic: intern beginnen, dann kleinen Prozentsatz der Produktion.\n- Fallback auf Legacy: wenn der Hub ausfällt, automatisch zurück zum vorherigen Versandpfad routen, bis Probleme behoben sind.
Roadmap nach dem MVP
Sobald stabil, erweitern Sie schrittweise: weitere Kanäle (SMS, Push, In‑App), reichhaltigeres Routing, bessere Template‑Werkzeuge und tiefere Analytics (Zustellraten, Time‑to‑deliver, Opt‑out‑Trends).