Problemstellung und wie Erfolg aussieht
Wenn Leute sagen, sie müssten Berechtigungen über „mehrere Produkte“ verwalten, meinen sie meistens eines von drei Szenarien:
- Getrennte Anwendungen (z. B. Billing, Analytics, Support), die jeweils ihr eigenes Nutzer‑ und Rollen‑System entwickelt haben.
- Module innerhalb einer Plattform, die sich wie separate Produkte verhalten (unterschiedliche Daten, Aktionen und Teams).
- Tenants oder Workspaces, in denen dasselbe Produkt für verschiedene Kunden, Regionen oder Geschäftseinheiten wiederholt wird.
In allen Fällen ist das Kernproblem dasselbe: Zugriffsentscheidungen werden an zu vielen Stellen getroffen, mit zu vielen widersprüchlichen Definitionen von Rollen wie „Admin“, „Manager“ oder „Nur‑Lesen“.
Die häufigsten Schmerzpunkte
Teams merken die Probleme oft, bevor sie sie klar benennen können.
Inkonsistente Rollen und Policies. In Produkt A kann ein „Editor“ Datensätze löschen; in Produkt B nicht. Nutzer fordern zu viele Zugriffe an, weil sie nicht wissen, was sie brauchen werden.
Manuelle Provisionierung und Deprovisionierung. Zugriffsänderungen passieren per Slack, Tabellenkalkulation oder Tickets. Offboarding ist besonders riskant: Nutzer verlieren Zugang in einem Tool, behalten ihn aber in einem anderen.
Unklare Verantwortlichkeiten. Niemand weiß, wer Zugang genehmigen kann, wer ihn überprüfen sollte oder wer haftbar ist, wenn eine Berechtigungsfehler zu einem Vorfall führt.
Wie Erfolg aussehen sollte
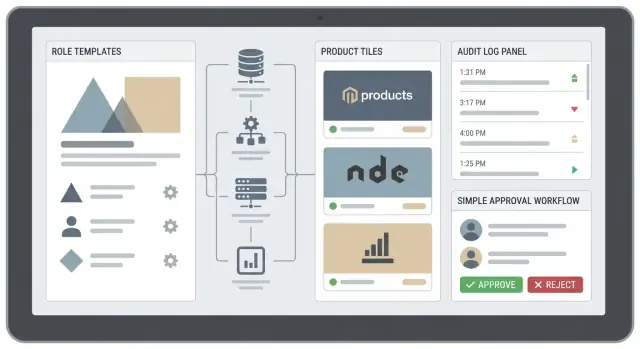
Eine gute Berechtigungs‑Management‑Web‑App ist mehr als ein Control‑Panel — sie schafft Klarheit.
Zentrales Admin mit konsistenten Definitionen. Rollen sind verständlich, wiederverwendbar und lassen sich über Produkte abbilden (bzw. machen Unterschiede explizit).
Self‑Service mit Schutzmechanismen. Benutzer können Zugriffe anfordern, ohne den richtigen Ansprechpartner suchen zu müssen; sensible Berechtigungen erfordern weiterhin Genehmigungen.
Genehmigungsabläufe und Verantwortlichkeit. Jede Änderung hat einen Owner: Wer hat sie angefordert, wer genehmigt und warum.
Auditbarkeit von Haus aus. Du kannst beantworten: „Wer hatte wann Zugriff auf was?“ ohne Logs aus fünf Systemen zusammenzukleben.
Metriken, die zeigen, dass es funktioniert
Messbare Ergebnisse, die Geschwindigkeit und Sicherheit abbilden:\n
- Zeit bis zur Zugriffsgewährung (Median und 95. Perzentil)\n- Weniger Support‑Tickets zu Zugriffen („Ich sehe X nicht“, „Bitte fügt mich zu Y hinzu“)\n- Weniger zugriffsbedingte Vorfälle (Überberechtigungen, fehlende Deprovisionierung)\n- Abschlussraten bei Reviews (periodische Zugangszertifizierung, falls vorhanden)\n
Wenn du Zugriffsänderungen schneller und vorhersehbarer machst, bist du auf dem richtigen Weg.
Anforderungen und Scope‑Checkliste
Bevor du Rollen entwirfst oder einen Tech‑Stack auswählst, kläre, was deine Berechtigungs‑App am ersten Tag abdecken muss — und was ausdrücklich nicht. Ein enger Scope verhindert, dass du halb fertig wieder alles neu baust.
1) Inventarisiere die Produkte, die du zuerst integrieren wirst
Beginne mit einer kurzen Liste (häufig 1–3 Produkte) und halte fest, wie jedes aktuell Zugriff ausdrückt:
- Nutzt es Rollen, Gruppen, ressourcenbasierte Grants oder
is_admin‑Flags?\n- Sind Berechtigungen global (produktweit) oder an Entitäten gebunden (Projekte, Workspaces, Konten)?\n- Wo werden Berechtigungen heute durchgesetzt (Frontend, Backend, beides)?
Wenn zwei Produkte grundlegend verschiedene Modelle haben, notiere das früh — du brauchst möglicherweise eine Übersetzungsschicht, statt sie sofort in eine einzige Form zu pressen.
2) Identifiziere Nutzer‑Typen und betriebliche Realitäten
Dein Berechtigungs‑System muss mehr als „Endnutzer“ abdecken. Definiere mindestens:\n
- Interne Admins und Support‑Mitarbeiter (brauchen oft breite, zeitlich begrenzte Zugriffe)\n- Kunden‑Admins und reguläre Nutzer\n- Partner/Reseller (können mehrere Kundenkonten überspannen)\n- Service‑Accounts und API‑Clients (Automatisierung braucht stabile, least‑privilege Zugriffe)
Erfasse Edge‑Fälle: Subunternehmer, Shared‑Inbox‑Konten und Nutzer, die mehreren Organisationen angehören.
3) Entscheide, welche Aktionen Permission‑Checks brauchen
Liste Aktionen auf, die für das Business und die Nutzer wichtig sind. Gängige Kategorien sind:\n
- Ansicht vs. Bearbeitung (read/write)\n- Abrechnung und Subscription‑Änderungen\n- Nutzerverwaltung (Einladen, Deaktivieren, MFA‑Zurücksetzen)\n- Hochrisiko‑Admin‑Aktionen (Datenexport, Key‑Rotation, destructive deletes)
Formuliere sie als Verben an Objekten (z. B. „workspace settings edit“ oder „edit workspace settings“), nicht als vage Labels.
4) Dokumentiere Quellen der Wahrheit und Ownership
Kläre, wo Identitäten und Attribute herkommen:\n
- HRIS für Mitarbeiter, CRM für Kunden, bestehende Verzeichnisse für SSO‑Gruppen\n- Produktdatenbanken für Memberships und Ressourcen
Für jede Quelle entscheide, was deine Berechtigungs‑App besitzen soll vs. nur spiegelt, und wie Konflikte gelöst werden.
Architektur auswählen: Zentralisiert, Föderiert oder Hybrid
Die erste große Entscheidung ist: Wo lebt Authorization? Diese Wahl prägt Integrationsaufwand, Admin‑Erlebnis und wie sicher du Berechtigungen im Lauf der Zeit ändern kannst.
Option 1: Zentralisieren (ein Autorisierungsdienst)
Bei einem zentralisierten Modell bewertet ein dedizierter Autorisierungsdienst den Zugriff für alle Produkte. Produkte rufen ihn an (oder validieren zentral ausgestellte Entscheidungen), bevor Aktionen erlaubt werden.
Das ist attraktiv bei Bedarf an konsistentem Policy‑Verhalten, cross‑product Rollen und einem Ort für Auditing. Der Hauptkostenpunkt ist die Integration: jedes Produkt muss von Verfügbarkeit, Latenz und Entscheidungsformat des Shared Service abhängig sein.
Option 2: Föderieren (jedes Produkt besitzt eigene Regeln)
Im föderierten Modell implementiert und bewertet jedes Produkt seine eigenen Berechtigungen. Deine „Manager‑App“ kümmert sich primär um Zuweisungs‑Workflows und synced dann die Ergebnisse in jedes Produkt.
Das maximiert Produkt‑Autonomie und reduziert geteilte Laufzeitabhängigkeiten. Der Nachteil ist Drift: Namen, Semantik und Edge‑Cases können auseinanderlaufen, was Administration und Reporting erschwert.
Option 3: Hybrid (Control‑Plane + lokale Durchsetzung)
Ein praktischer Mittelweg ist, die Berechtigungsverwaltung als Control‑Plane (ein Admin‑Console) zu behandeln, während Produkte die Enforcement‑Points bleiben.
Du pflegst einen gemeinsamen Berechtigungs‑Katalog für Konzepte, die über Produkte hinweg übereinstimmen müssen (z. B. „Billing Admin“, „Reports Lesen“), und lässt Raum für produkt‑spezifische Berechtigungen, wo Teams Flexibilität brauchen. Produkte ziehen oder empfangen Updates (Rollen, Grants, Gruppen‑Mappings) und setzen sie lokal durch.
Wichtige Trade‑offs, die du früh klären solltest
- Integrationsgeschwindigkeit: Zentralisierte Evaluation kann Standardisierung schneller liefern, ist aber schwerer in Legacy‑Systeme zu rollen; föderiertes Syncen kann klein starten, normalisiert aber langsamer.\n- Autonomie: Föderiert/Hybrid erlaubt Produktteams, unabhängig zu deployen; zentralisiert erfordert engere Koordination.\n- Risiko von Breaking‑Changes: Ein geteilter Katalog und Decision‑API brauchen Versionierung und Rückwärtskompatibilität, sonst kann eine Änderung mehrere Produkte treffen.
Wenn du schnellen Produktzuwachs erwartest, ist Hybrid oft der beste Ausgangspunkt: es liefert ein zentrales Admin‑Erlebnis, ohne jedes Produkt sofort auf denselben Laufzeit‑Authorizer zu zwingen.
Das Berechtigungsmodell entwerfen (zuerst RBAC, dann ABAC)
Ein Berechtigungs‑System steht und fällt mit seinem Datenmodell. Starte einfach mit RBAC (Role‑Based Access Control), damit es erklärbar, administrierbar und auditierbar bleibt. Füge Attribute (ABAC) nur dort hinzu, wo RBAC zu grob ist.
Kern‑Entitäten, die du fast immer brauchst
Mindestens sollten diese Konzepte modelliert werden:\n
- Users: Personen (oder Service‑Accounts), die Zugriff anfordern.\n- Groups: Sammlungen von Nutzern (Team, Abteilung, Environment‑Owner).\n- Products: Die Apps/Services, für die du Zugriff kontrollierst.\n- Resources: Dinge innerhalb eines Produkts (Projekt, Workspace, Repo, Kundenkonto).\n- Permissions: Atomare Aktionen (z. B.
project.read, project.write, billing.manage).\n- Roles: Benannte Mengen von Permissions.
Ein praktisches Muster: Rollen‑Zuweisungen binden ein Principal (User oder Group) an eine Role innerhalb eines Scopes (produktweit, resource‑level oder beides).
RBAC zuerst: mache Rollen zur primären Oberfläche
Definiere Rollen pro Produkt, damit jedes Produkt‑Vokabular klar bleibt (z. B. ist „Analyst“ in Produkt A nicht gezwungen, „Analyst“ in Produkt B zu entsprechen).
Füge Rollen‑Vorlagen hinzu: standardisierte Rollen, die über Tenants, Environments oder Kunden wiederverwendbar sind. Obendrauf kannst du Bundles für häufige Job‑Funktionen erstellen (z. B. „Support Agent Bundle“ = Rollen in Produkt A + B + C). Bundles reduzieren Admin‑Aufwand, ohne alles in eine Mega‑Rolle aufzulösen.
Least Privilege: vermeide „Admin == Alles"
Mach die Default‑Erfahrung sicher:\n
- Neue Nutzer sollten mit keinem Zugriff (oder minimalem „Viewer“) starten.\n- Behandle „Admin“ als gescoped (Produkt‑Admin, Workspace‑Admin, Tenant‑Admin), nicht als globalen All‑Macht‑Status.\n- Bevorzuge separate Hoch‑Risiko‑Permissions wie
billing.manage, user.invite, audit.export, statt sie unter „Admin“ zu verstecken.
Wann ABAC sinnvoll ist
Füge ABAC hinzu, wenn du Regeln brauchst wie „darf Tickets nur für seine Region sehen“ oder „darf nur in Staging deployen“. Nutze Attribute für Constraints (Region, Environment, Datenklassifikation), während RBAC die Hauptsprache für Menschen bleibt.
Wenn du detailliertere Guides zu Rollennamen und Scoping‑Konventionen brauchst, verlinke auf interne Docs oder eine Referenzseite wie /docs/authorization-model.
Identity, Authentication und Token‑Strategie
Deine Berechtigungs‑App sitzt zwischen Personen, Produkten und Policies — daher brauchst du einen klaren Plan, wie jede Anfrage wer ist, welches Produkt anfragt und welche Permissions angewendet werden.
Wie sich Produkte identifizieren
Behandle jedes Produkt (und jede Umgebung) als Client mit eigener Identität:\n
- Client‑IDs + Secrets / API‑Keys für serverseitige Integrationen. Regelmäßig rotieren und auf bestimmte APIs einschränken.\n- mTLS für hochvertrauenswürdigen internen Traffic: Das Produkt präsentiert ein Client‑Zertifikat, das du am Gateway prüfst.
Logge die Produkt‑Identität bei jedem Authorization/Audit‑Event, damit du später „welches System hat das angefragt?“ beantworten kannst.
Wie sich Benutzer anmelden und Sessions funktionieren
Unterstütze zwei Einstiegspunkte:\n
- E‑Mail / Passwort (nur wenn unbedingt nötig): mit MFA, Rate‑Limiting und Breach‑Checks schützen.\n- SSO (SAML/OIDC): bevorzugt für Unternehmen, weil Lifecycle und MFA im Kunden‑IdP leben.
Für Sessions nutze kurzlebige Access‑Tokens plus serverseitige Sessions oder Refresh‑Tokens mit Rotation. Halte Logout und Session‑Widerruf vorhersehbar (insbesondere für Admins).
Token‑Strategie: JWT‑Claims vs. Introspection
Zwei gängige Muster:\n
- JWT mit Permissions‑Claims: schnell, offline validerbar, aber Berechtigungen können bis zum Token‑Ablauf veraltet sein.\n- Token‑Introspection / Permission‑Lookup: Produkte rufen deinen Auth‑Service an (oder cachen kurz). Aktueller und leichter widerrufbar, aber zusätzliche Latenz und hohe Verfügbarkeit nötig.
Ein praktischer Hybrid: JWT enthält Identity + Tenant + Roles, und Produkte rufen für feingranulare Checks ein Endpoint an.
Service‑zu‑Service und nicht‑menschliche Identities
Verwende nicht Benutzer‑Tokens für Hintergrundjobs. Erstelle Service‑Accounts mit expliziten Scopes (least privilege), issue Client‑Credential Tokens und halte Audit‑Logs von menschlichen Aktionen getrennt.
APIs und Integrationsmuster für mehrere Produkte
Sicherere Änderungen mit Rollback
Erstellen Sie Snapshots vor Änderungen an Rollenvorlagen und rollen Sie schnell zurück, falls etwas schiefgeht.
Eine Berechtigungs‑App funktioniert nur, wenn jedes Produkt die gleichen Fragen stellen und konsistente Antworten erhalten kann. Ziel ist ein kleiner Satz stabiler APIs, die jedes Produkt einmal implementiert und dann wiederverwendet.
Definiere die „stabile Core“ API
Konzentriere die Kernendpunkte auf wenige, notwendige Operationen:\n
- Check access: „Darf Benutzer X Aktion Y auf Ressource Z ausführen?“ (Hot‑Path)\n- List entitlements: „Welche Rollen/Permissions hat Benutzer X in Produkt P?“\n- Grant / Revoke: Admin‑Aktionen und automatisierte Provisionierung\n- Audit export: „Was hat sich geändert, wann, durch wen und warum?“
Vermeide produkt‑spezifische Logik in diesen Endpunkten. Standardisiere stattdessen die gemeinsame Vokabel: subject (User/Service), action, resource, scope (tenant/org/project) und context (Attribute für spätere Nutzung).
Wähle ein Integrationsmuster pro Produkt
Die meisten Teams nutzen eine Kombination:\n
- Runtime Authorization Checks (sync): Produkt ruft
POST /authz/check (oder benutzt ein lokales SDK) bei sensiblen Requests.\n- Lokale Durchsetzung (async Replikation): Produkt hält ein Read‑Model der Entitlements für schnelle UI‑Gating und Offline‑Entscheidungen.
Praktische Regel: Mach die zentrale Prüfung zur Quelle der Wahrheit für hochrisiko Aktionen und nutze replizierte Daten für UX (Menüs, Feature‑Flags, „Sie haben Zugriff“ Badges), wo gelegentliche Staleness akzeptabel ist.
Event‑getriebene Updates: Produkte synchron halten
Wenn sich Berechtigungen ändern, verlasse dich nicht auf Polling.
Publiziere Events wie role.granted, role.revoked, membership.changed und policy.updated an eine Queue oder Webhook‑System. Produkte abonnieren und aktualisieren ihre lokalen Caches/Read‑Models.
Design‑Prinzipien für Events:\n
- Idempotent (sicher mehrfach zu verarbeiten)\n- Geordnet pro subject+tenant, wenn möglich\n- Selbstbeschreibend genug, um Zustand wiederherzustellen (oder mit einem Follow‑Up „fetch current state“ Endpoint koppeln)
Caching und Invalidierung für schnelle Checks
Access‑Checks müssen schnell sein; Caching kann aber Sicherheitslücken erzeugen, wenn Invalidierung schwach ist.
Gängiges Muster:\n
- Cache Allow/Deny‑Ergebnisse kurz (Sekunden) nach subject/action/resource/scope.\n- Cache Entitlement‑Snapshots (Rollen, Gruppenmitgliedschaften) länger, aber invalidiere aggressiv bei Events.
Wenn du JWTs mit eingebetteten Rollen nutzt, halte Token‑Lifetimes kurz und kombiniere sie mit serverseitigen Widerrufsstrategien (z. B. ein „token version“ Claim), damit Widerrufe schnell wirksam werden.
Versionierung und Abwärtskompatibilität
Berechtigungen entwickeln sich mit Produktfeatures. Plane dafür:\n
- Versioniere API‑Verträge (
/v1/authz/check) und Event‑Schemata.\n- Behandle Permissions möglichst als additiv (füge Aktionen hinzu statt Bedeutungen zu ändern).\n- Depreziere mit Zeitplänen und Telemetrie: Messe, welche Produkte noch alte Endpunkte nutzen.
Eine geringe Investition in Kompatibilität verhindert, dass das Berechtigungs‑System zum Flaschenhals für neue Produkt‑Funktionen wird.
Admin‑ und Self‑Service‑UX gestalten
Ein Berechtigungs‑System kann technisch korrekt sein und trotzdem scheitern, wenn Admins die Frage „Wer hat Zugriff auf was und warum?“ nicht schnell beantworten können. Die UX soll Rate‑Mechansimen reduzieren, versehentliche Überberechtigungen verhindern und gängige Aufgaben beschleunigen.
Kernseiten der Admin‑Konsole
Starte mit wenigen Seiten, die 80 % der täglichen Arbeit abdecken:\n
- User Lookup: Suche nach Name, Email, Mitarbeiter‑ID oder externen Ids. Zeige eine klare Zusammenfassung: Produkte, Rollen, Gruppen und „zuletzt geändert von“.\n- Role Assignment: Einheitlicher Flow zum Hinzufügen/Entfernen von Rollen über Produkte hinweg. Unterstütze Wirksamkeitsdaten, wenn zeitlich begrenzter Zugriff erlaubt ist.\n- Group Management: Gruppen erstellen (Teams, Abteilungen, Projekte) und Rollen an Gruppen zuweisen, damit Admins nicht Nutzer‑für‑Nutzer pflegen müssen.
Bei jeder Rolle zeige eine Klartext‑Erklärung: „Was diese Rolle erlaubt“ plus konkrete Beispiele („Kann Rechnungen bis $10k genehmigen“ ist besser als „invoice:write“). Verlinke zu tieferen Docs bei Bedarf (z. B. /help/roles).
Bulk‑Operationen ohne Massenfehler
Bulk‑Tools sparen Zeit, vervielfachen aber Fehler — mache sie deshalb sicher:\n
- CSV Import/Export für Onboarding oder Audits mit strikter Validierung und herunterladbarer Vorlage.\n- Mass Role Changes mit Review‑Schritt: zeige ein Diff („+ Billing Admin, − Viewer“) bevor du anwendest.\n- Geplante Access‑Reviews: Admins können Reviews terminiert starten, Reviewer benachrichtigen und Abschluss tracken.
Füge Guardrails wie „Dry run“, Rate‑Limits und klare Rollback‑Anweisungen hinzu, falls ein Import schiefgeht.
Ein einfacher Genehmigungsablauf
Viele Organisationen brauchen einen leichtgewichtigen Prozess:\n
Request → Approve → Provision → Notify
Requests sollten den Business‑Kontext erfassen („Benötigt für Q4 Abschluss“) und Dauer. Genehmigungen sollten rollen‑ und produktbewusst sein (der richtige Approver für die richtige Aktion). Die Provisionierung muss einen Audit‑Eintrag erzeugen und sowohl Antragsteller als auch Genehmiger benachrichtigen.
Barrierefreiheit und Klarheit
Nutze konsistente Benennungen, vermeide Akronyme in der UI und biete Inline‑Warnungen („Dies gewährt Zugriff auf Kunden‑PII“). Sorge für Tastaturnavigation, ausreichend Kontrast und klare Empty‑States („Noch keine Rollen zugewiesen — füge eine hinzu, um Zugriff zu erlauben").
Auditing, Reporting und Compliance‑Basics
Stabile Core‑APIs bereitstellen
Erzeugen Sie zentrale Autorisierungsprüfungen und Berechtigungs‑APIs und iterieren Sie dann im Team.
Auditing ist der Unterschied zwischen „wir denken, der Zugriff ist korrekt“ und „wir können es beweisen“. Wenn deine App Berechtigungen über Produkte verwaltet, muss jede Änderung nachvollziehbar sein — besonders Rollen‑Grants, Policy‑Änderungen und Admin‑Aktionen.
Was das Audit‑Log erfassen muss
Mindestens sollte protokolliert werden: wer hat was wann wo warum geändert:\n
- Actor: User‑ID, Admin‑ID, Service‑Account oder Automation (inkl. Impersonator, falls „on behalf of“).\n- Action + Object: z. B. „assigned role template X“, „revoked product Y access“, „edited policy Z“ inkl. Vorher/Nachher.\n- Timestamp: in UTC mit Millisekunden‑Genauigkeit.\n- Source: IP‑Adresse, User‑Agent, Device/Session‑ID und das genutzte Produkt/UI/API.\n- Reason: ein verpflichtendes „Änderungsgrund“ Feld für sensible Aktionen (Admin‑Grants, Edit von Rollen‑Vorlagen, MFA‑Deaktivierung).
Unveränderlichkeit, Aufbewahrung und SIEM‑Export
Behandle Audit‑Events als append‑only. Erlaube keine Updates oder Deletes über Anwendungscode; wenn Korrekturen nötig sind, schreibe ein kompensierendes Event.
Definiere Retention nach Risiko und Regulierung: Viele Teams halten „heiße“ durchsuchbare Logs 30–90 Tage und archivieren 1–7 Jahre. Ermögliche Exporte: zeitgesteuerte Lieferungen (z. B. täglich) und Streaming zu SIEM‑Tools. Mindestens unterstütze den Export als newline‑delimited JSON und liefere stabile IDs zur Deduplizierung.
Risikoreiche Verhaltensweisen früh erkennen
Baue einfache Detectoren, die flaggen:\n
- Privilege Escalation (plötzliche Sprünge zu hohen Rechten, neue globale Admins, Policy‑Weitstellungen)\n- Ungewöhnliche Admin‑Aktivität (Änderungsspitzen außerhalb der Arbeitszeit, viele Änderungen in kurzer Zeit, Änderungen über viele Tenants/Produkte)\n- Verdächtige Zugriffsmuster (neue IP/Geografie, wiederholte fehlgeschlagene Admin‑Aktionen)
Zeige diese in einer „Admin Activity“‑Ansicht und sende optional Alerts.
Reports, die Stakeholder fordern werden
Mach Reporting praktikabel und exportierbar:\n
- Zugriff nach Produkt (wer hat was, gruppiert nach Rollen‑Vorlage und Tenant)\n- Dormante Accounts (kein Login oder Nutzung seit N Tagen, aber noch provisioniert)\n- Hochprivilegierte Nutzer (globale Admins, Policy‑Editoren, Break‑Glass Accounts) mit Last‑Used‑Timestamps
Wenn du später Genehmigungsworkflows hinzufügst, verknüpfe Audit‑Events mit Request‑IDs, damit Compliance‑Reviews schnell und nachvollziehbar sind.
Sicherheitskontrollen und typische Ausfallmodi
Eine Berechtigungs‑Management‑App ist selbst ein hochattraktives Ziel: eine schlechte Entscheidung kann breiten Zugriff über alle Produkte gewähren. Behandle die Admin‑Oberfläche und Authorization‑Checks als „Tier‑0“ Systeme.
Privilege Escalation verhindern
Beginne mit Least Privilege und mache Eskalation absichtlich schwer:\n
- Separation of Duties: Teile Rollen so auf, dass keine Einzelperson sowohl Zugriff gewähren als auch sensible Änderungen genehmigen kann (z. B. „Role Editor“ vs. „Role Approver“).\n- Geschützte Rollen: Markiere Break‑Glass/Admin‑Rollen als unveränderliche Vorlagen (nicht editierbar, nur zuweisbar). Erfordere stärkere Verifikation und zusätzliche Genehmigung zur Zuweisung.\n- Zwei‑Personen‑Regel für riskante Aktionen: Zuweisung einer geschützten Rolle, Änderung einer Rollen‑Vorlage oder Anpassung der Policy‑Evaluation sollten sekundäre Genehmigung und vollständige Protokollierung erfordern.
Typischer Ausfallmodus: Ein „Role Editor“ kann die Admin‑Rolle editieren und sich diese dann selbst zuweisen.
Admin‑Endpoints härten
Admin‑APIs sollten nicht so erreichbar sein wie End‑User‑APIs:\n
- Rate‑Limiting auf Role/Permission‑Mutations‑Endpoints, um Brute‑Force und Missbrauch zu reduzieren.\n- IP‑Allowlists (oder private Netzwerkzugänge) für Admin‑Aktionen, wo möglich.\n- Sichere Defaults: Standardmäßig deny, explizite Grants erforderlich, und vermeide temporäre Wildcard‑Permissions, die nie entfernt werden.
Typischer Ausfallmodus: Eine Convenience‑API (z. B. „grant all for support“) wird ohne Guardrails in Produktion ausgeliefert.
Geheimnisse und Sessions schützen
- Nutze einen echten Secrets Manager (nicht Klartext‑Env‑Variablen über viele Systeme).\n- Verschlüssele in Transit (TLS überall) und verschlüssele ruhende Daten für Policy‑Daten, Audit‑Logs und PII.\n- Harde Cookie‑Einstellungen:
HttpOnly, Secure, SameSite, kurze Session‑Lifetimes und CSRF‑Schutz für Browser‑Flows.
Typischer Ausfallmodus: Leckende Service‑Credentials, die Policy‑Schreibzugriff erlauben.
Authorization so testen, wie du es meinst
Authorization‑Bugs sind oft „fehlende Deny“‑Szenarien:\n
- Schreibe negative Tests („Benutzer darf X NICHT zugreifen“).\n- Pflege eine Rollenmatrix‑Test‑Suite (Rollen × Aktionen × Ressourcen), um unbeabsichtigte Zugriffe bei Template‑Änderungen zu finden.\n- Ergänze Regressionstests für gemeldete Vorfälle und Edge‑Cases (gelöschte Nutzer, veraltete Tokens, Cross‑Tenant Zugriffe).
Rollout‑Plan: Pilot, Migrieren und Ausweiten
Ein Berechtigungs‑System ist bei Launch nie „fertig“ — Vertrauen erarbeitest du durch sichere Rollouts. Ziel ist, Zugriffsentscheidungen zu validieren, Support‑Abläufe zur schnellen Fehlerbehebung zu haben und Änderungen rückgängig machen zu können, ohne Teams zu blockieren.
1) Pilot mit einem Produkt (End‑to‑End)
Starte mit einem Produkt, das klare Rollen und aktive Nutzer hat. Mappe vorhandene Rollen/Gruppen in eine kleine Menge kanonischer Rollen im neuen System und baue einen Adapter, der „neue Berechtigungen“ in das übersetzt, was das Produkt heute durchsetzt (API‑Scopes, Feature‑Toggles, DB‑Flags usw.).
Während des Pilots validiere die komplette Schleife:\n
- Admin ändert eine Rollen‑Zuweisung\n- Das Produkt empfängt das Update (Push oder Pull)\n- Reale Nutzer können erwartete Aktionen ausführen\n- Audit‑Events erfassen, wer was wann geändert hat
Definiere Erfolgskriterien vorab: weniger Support‑Tickets, keine kritischen Überberechtigungs‑Vorfälle und Time‑to‑Revoke in Minuten gemessen.
2) Datenmigration sorgfältig (und reversibel)
Legacy‑Berechtigungen sind chaotisch. Plane einen Übersetzungsschritt, der bestehende Gruppen, Ausnahmen und produkt‑spezifische Rollen in das neue Modell konvertiert. Halte eine Mapping‑Tabelle, damit du jede migrierte Zuweisung erklären kannst.
Führe einen Dry‑Run in Staging durch und migriere dann in Wellen (nach Organisation, Region oder Kundentyp). Für anspruchsvolle Kunden migriere in einen „Shadow‑Mode“, sodass du alte vs. neue Entscheidungen vergleichen kannst, bevor du durchsetzt.
3) Feature‑Flags und schrittweise Durchsetzung
Feature‑Flags trennen „Write‑Pfad“ von „Enforce‑Pfad“. Typische Phasen:\n
- Read‑only UI (nur Reporting)\n- Writes enabled, nicht enforced (nur Sync)\n- Teilweise Durchsetzung (spezifische Aktionen)\n- Volle Durchsetzung
Wenn etwas schiefgeht, kannst du die Durchsetzung abschalten und trotzdem Audit‑Sichtbarkeit behalten.
4) Runbooks für Support und Emergency‑Revokes
Dokumentiere Runbooks für gängige Vorfälle: Nutzer hat keinen Zugriff, Nutzer hat zu viel Zugriff, Admin hat Mist gebaut, Emergency‑Revoke. Nenne wer on‑call ist, wo Logs zu prüfen sind, wie man effektive Berechtigungen verifiziert und wie man ein Break‑Glass‑Revoke durchführt, das schnell propagiert.
Sobald der Pilot stabil ist, wiederhole das Playbook Produkt‑für‑Produkt. Jede neue Integration sollte sich wie Integrationsarbeit anfühlen — nicht wie eine Neuerschaffung deines Modells.
Implementierungs‑Hinweise: Tech‑Stack und Betrieb
Pilot‑Berechtigungs‑App erstellen
Prototypen Sie eine Berechtigungs‑Admin‑App schneller mit chatgesteuertem React‑, Go‑ und Postgres‑Gerüst.
Du brauchst keine exotische Technologie, um eine solide Berechtigungs‑App zu bauen. Priorisiere Korrektheit, Vorhersehbarkeit und Operabilität — dann optimiere.
Ein praktischer, unspektakulärer Stack
Ein übliches Basisset:\n
- API‑Service: Node.js (NestJS/Fastify) oder Go (Gin/chi)\n- Datenbank: Postgres (starke Konsistenz und gutes Indexing für Policy‑Queries)\n- Cache: Redis (Cache für Rollenausfaltungen, Tenant‑Configs und „can user X do Y“ Entscheidungen)\n- Queue: Redis‑basierte Queue (BullMQ) oder Managed Queue (SQS/ Pub/Sub)
Halte die Entscheidungslogik für Authorization in einem Service/Library, um Divergenz zwischen Produkten zu vermeiden.
Wenn du schnell eine interne Admin‑Konsole und APIs für einen Pilot brauchst, können Plattformen wie Koder.ai helfen, Web‑Apps schneller zu prototypen und zu liefern. In der Praxis kann das nützlich sein, um eine React‑Admin‑UI, ein Go + PostgreSQL‑Backend und das Grundgerüst für Audit‑Logs und Genehmigungen zu generieren — du musst die Autorisierungslogik aber weiterhin rigoros prüfen.
Background‑Jobs (Provisioning und Sync)
Permissions‑Systeme sammeln schnell Arbeit an, die Benutzeranfragen nicht blockieren sollte:\n
- Import/Sync von Nutzern und Gruppen aus externen IdPs\n- Provision entitlements zu Downstream‑Produkten\n- Neuberechnung abgeleiteter Grants nach Template‑Änderungen\n- Periodische Konsistenzchecks (z. B. „verwaiste“ Zuweisungen)
Mache Jobs idempotent und retrybar, und speichere Job‑Status pro Tenant für Support‑Zwecke.
Betrieb: Observability, die wirklich hilft
Mindestens instrumentiere:\n
- Logs: strukturierte Logs mit Request‑ID, Tenant‑ID, Actor‑ID und Entscheidungsoutcome\n- Metriken: Authorisierungslatenz, Error‑Rate, Cache‑Hit‑Rate, DB‑Query‑Zeit\n- Traces: End‑to‑End Pfade für „permission check“ und „admin change“ Flows
Alarmiere bei Anstiegen in deny‑by‑error (z. B. DB‑Timeouts) und bei ungewöhnlichen p95/p99‑Latenzen für Permission‑Checks.
Load‑Testing und Kapazitätsprüfungen
Vor dem Rollout lastteste den permission‑check Endpoint mit realistischen Mustern:\n
- Hot‑Keys (gleicher User/Projekt wird wiederholt geprüft)\n- Gemischte Reads/Writes (Admin‑Updates während Traffic)\n- Unterschiedliche Tenant‑Größen
Mess Durchsatz, p95 Latenz und Redis‑Hit‑Rate; verifiziere, dass die Performance kontrolliert einbricht, wenn der Cache kalt ist.
Erweiterte Features: SSO, SCIM und Multi‑Tenant Support
Wenn dein Kernmodell steht, können ein paar „Enterprise“ Features das System bei Skalierung deutlich vereinfachen — ohne das Durchsetzungsmodell in den Produkten zu ändern.
SSO: SAML/OIDC und Mapping von IdP‑Gruppen zu Rollen
Single Sign‑On bedeutet meist SAML 2.0 (ältere Enterprise‑IdPs) oder OpenID Connect (OIDC) (moderne Stacks). Entscheide, was du vom Identity Provider (IdP) vertraust.
Ein praktisches Muster: Akzeptiere Identity und hohe Gruppenmitgliedschaft aus dem IdP und mappe diese Gruppen auf interne Rollen‑Vorlagen pro Tenant. Beispiel: IdP‑Gruppe Acme-App-Admins mappt auf deine Rolle Workspace Admin im Tenant acme. Halte dieses Mapping explizit und editierbar durch Tenant‑Admins, nicht hard‑codiert.
Vermeide, IdP‑Gruppen direkt als Permissions zu verwenden. Gruppen ändern sich aus organisatorischen Gründen; deine Rollen sollten stabil bleiben. Behandle den IdP als Quelle für „wer ist der Nutzer“ und „in welchen Org‑Gruppe ist er“, nicht als Quelle für „was er in jedem Produkt tun darf“.
SCIM‑Provisioning für automatisiertes Nutzer‑Lifecycle
SCIM erlaubt Kunden, Kontenlebenszyklen zu automatisieren: Nutzer anlegen, deaktivieren und Gruppenmitgliedschaften synchronisieren. Das reduziert manuelle Einladungen und schließt Sicherheitslücken beim Mitarbeiterabgang.
Implementierungs‑Tipps:\n
- Behandle Deaktivierung als erstklassiges Ereignis (sofortige Session/Token‑Widerrufe und Produkt‑Zugriffsentzug).\n- Mach Group‑Sync idempotent und auditierbar: SCIM‑Updates sollten deterministische Änderungen an Rollen‑Zuweisungen erzeugen.
Multi‑Tenant Support: Isolation und Admin‑Grenzen
Multi‑Tenant Access Control muss Tenant‑Isolation überall durchsetzen: Token‑Identifier, DB‑Row‑Level‑Filter, Cache‑Keys und Audit‑Logs.
Definiere klare Admin‑Grenzen: Tenant‑Admins dürfen nur Nutzer und Rollen innerhalb ihres Tenants verwalten; Plattform‑Admins dürfen Troubleshooting durchführen, ohne sich selbst Produktzugriff zu geben.
Für tiefere Implementierungs‑Guides und Packaging‑Optionen siehe /blog. Wenn du entscheiden musst, welche Features in welches Plan‑Level gehören, richte es an /pricing aus.