Ziel und Umfang der App klären
Bevor Sie Bildschirme entwerfen oder einen Tech-Stack wählen, legen Sie genau fest, was „betriebliches Risiko“ in Ihrer Organisation bedeutet. Manche Teams verstehen darunter Prozessfehler und menschliches Versagen; andere schließen IT-Ausfälle, Lieferantenprobleme, Betrug oder externe Ereignisse ein. Ist die Definition schwammig, wird die App zum Abladeplatz — und das Reporting unzuverlässig.
Definieren, was Sie nachverfolgen wollen
Formulieren Sie eine klare Aussage, was als betriebliches Risiko zählt und was nicht. Sie können es in vier Bereiche aufteilen (Prozess, Personen, Systeme, externe Ereignisse) und 3–5 Beispiele pro Bereich ergänzen. Dieser Schritt reduziert spätere Debatten und hält die Daten konsistent.
Einigkeit über die Ziele erzielen
Seien Sie konkret, was die App erreichen muss. Häufige Ziele sind:
- Sichtbarkeit: ein zentraler Ort für Risiken, Kontrollen, Vorfälle und Maßnahmen
- Verantwortlichkeit: jedes Element hat einen benannten Owner und ein Fälligkeitsdatum
- Nachverfolgung von Maßnahmen: Aufgaben wandern von „offen“ zu „verifiziert“ mit Evidenz
- Reporting und Prüfbereitschaft: Sie können erklären, was sich wann und warum geändert hat
Wenn Sie das Ergebnis nicht beschreiben können, ist es wahrscheinlich eine Feature-Anfrage – nicht eine Anforderung.
Primäre Nutzer identifizieren
Listen Sie die Rollen auf, die die App verwenden, und was sie am dringendsten benötigen:
- Risiko-Eigentümer (identifizieren und aktualisieren Risiken)
- Kontroll-Eigentümer (bestätigen Kontrollen, hängen Evidenz an)
- Reviewer (genehmigen Änderungen, fordern Updates an)
- Prüfer (nur-Lese-Zugriff, Nachvollziehbarkeit)
- Admins (Benutzerzugriff, Konfiguration)
Das verhindert, dass Sie „für alle“ bauen und am Ende niemanden zufriedenstellen.
Realistischen v1-Umfang festlegen
Ein praktisches V1 für die Nachverfolgung betrieblicher Risiken konzentriert sich meist auf: ein Risikoregister, Basis-Scoring, Maßnahmen-Tracking und einfache Berichte. Tiefere Fähigkeiten (erweiterte Integrationen, komplexes Taxonomie-Management, individuelle Workflow-Builder) sparen Sie sich für spätere Phasen auf.
Erfolgsmessungen definieren
Wählen Sie messbare Signale wie: Prozentsatz der Risiken mit Eigentümer, Vollständigkeit des Registers, Zeit bis zum Schließen von Maßnahmen, Anteil überfälliger Maßnahmen und termingerechte Prüfungen. Diese Kennzahlen erleichtern die Beurteilung, ob die App funktioniert — und was als Nächstes verbessert werden muss.
Anforderungen von Stakeholdern einholen
Ein Risikoregister-Webapp funktioniert nur, wenn es zu den tatsächlichen Prozessen passt, mit denen Menschen Risiken identifizieren, bewerten und nachverfolgen. Bevor Sie über Features sprechen, sprechen Sie mit den Personen, die die App nutzen werden (oder an deren Ergebnissen gemessen werden).
Wen einbinden (und warum)
Beginnen Sie mit einer kleinen, repräsentativen Gruppe:
- Business-Unit-Owner, die Risiken täglich melden und managen
- Risiko/Compliance, die Terminologie, Bewertungs-Erwartungen und Reporting-Bedürfnisse definieren
- Interne Revision, die auf Evidenz, Genehmigungen und vollständige Audit-Trails achtet
- IT/Security, die Zugriffskontrolle, Datenaufbewahrung und Integrationen prüfen
- Führungskräfte/Board-Ansprechpartner, die Zusammenfassungen und Trendberichte konsumieren
Den aktuellen Prozess Ende-zu-Ende abbilden
Erarbeiten Sie in Workshops den realen Workflow Schritt für Schritt: Risk Identification → Assessment → Treatment → Monitoring → Review. Erfassen Sie, wo Entscheidungen getroffen werden (wer genehmigt was), wie „fertig“ aussieht und was eine Prüfung auslöst (zeitbasiert, incident-basiert oder schwellengesteuert).
Schmerzpunkte dokumentieren, die behoben werden müssen
Lassen Sie Stakeholder die aktuelle Tabelle oder den E-Mail-Verlauf zeigen. Dokumentieren Sie konkrete Probleme wie:
- Fehlende Verantwortlichkeit (unklarer Risiko-Owner vs. Kontroll-Owner vs. Action-Owner)
- Inkonsistentes Scoring (Teams interpretieren Wahrscheinlichkeit/Auswirkung unterschiedlich)
- Schwache Audit-Trails (kein Nachweis, wer was warum geändert hat)
- Versionsverwirrung (mehrere Kopien der vermeintlich „aktuellen“ Liste)
Erforderliche Workflows und Ereignisse festhalten
Schreiben Sie die Mindest-Workflows auf, die Ihre App unterstützen muss:
- Neues Risiko anlegen (mit Pflichtfeldern und Genehmigungsregeln)
- Risiko aktualisieren (Neubewertung, Statuswechsel, Notizen hinzufügen)
- Vorfälle protokollieren und mit Risiken/Kontrollen verknüpfen
- Kontrollen testen und Ergebnisse/Evidenz dokumentieren
- Maßnahmenpläne erstellen und nachverfolgen (Fälligkeit, Erinnerungen, Eskalation)
Reports definieren, die Menschen brauchen
Einigen Sie sich früh auf Outputs, um Nacharbeit zu vermeiden. Häufige Bedürfnisse sind Board-Zusammenfassungen, Business-Unit-spezifische Ansichten, überfällige Maßnahmen und Top-Risiken nach Score oder Trend.
Compliance-Einschränkungen notieren (ohne Zertifizierungen zu versprechen)
Listen Sie Regeln auf, die Anforderungen prägen — z. B. Aufbewahrungsfristen, Datenschutzvorgaben für Vorfalldaten, Trennung der Aufgaben, Genehmigungsnachweise und Zugriffsrestriktionen nach Region/Entität. Fassen Sie das faktisch zusammen: Sie sammeln Zwänge, nicht behaupten Sie wären automatisch compliant.
Ihr Risiko-Framework und die Terminologie entwerfen
Bevor Sie Bildschirme oder Workflows bauen, stimmen Sie die Sprache ab, die Ihre App durchsetzen wird. Klare Terminologie verhindert „gleiches Risiko, andere Worte“ und macht das Reporting belastbar.
Mit einer praktischen Risikotaxonomie starten
Definieren Sie, wie Risiken im Register gruppiert und gefiltert werden. Halten Sie es nützlich für den täglichen Betrieb sowie für Dashboards und Berichte.
Typische Ebenen: Kategorie → Subkategorie, zugeordnet zu Business Units und (wo sinnvoll) Prozessen, Produkten oder Standorten. Vermeiden Sie eine so feingranulare Taxonomie, dass Anwender nicht konsistent wählen können; verfeinern Sie später, wenn Muster sichtbar werden.
Einigen Sie sich auf eine konsistente Risikoformulierung (z. B. „Aufgrund von Ursache, kann Ereignis eintreten, was zu Auswirkung führt“). Legen Sie fest, was Pflicht ist:
- Ursache, Ereignis, Auswirkung
- Risiko-Eigentümer und verantwortliches Team
- Status (Entwurf, aktiv, in Prüfung, eingestellt)
- Daten (erkannt, zuletzt bewertet, nächste Prüfung)
Diese Struktur verknüpft Kontrollen und Vorfälle mit einer einheitlichen Erzählung statt verstreuter Notizen.
Bewertungsdimensionen und Scoring definieren
Wählen Sie die Dimensionen, die Ihr Bewertungsmodell unterstützt. Mindestanforderung: Wahrscheinlichkeit und Auswirkung; Geschwindigkeit (Velocity) und Auffindbarkeit (Detectability) können zusätzlichen Wert bringen, wenn Teams diese zuverlässig bewerten.
Entscheiden Sie, wie Sie mit inherentem vs. residualem Risiko umgehen. Ein gängiger Ansatz: inherent vor Kontrollen bewerten; residual ist der Post-Control-Score, wobei Kontrollen explizit verknüpft werden, damit die Logik während Reviews und Prüfungen erklärbar bleibt.
Schließlich: Einfache Skala (häufig 1–5) und sprachliche Definitionen für jede Stufe. Wenn „3 = mittel“ für verschiedene Teams unterschiedliche Bedeutungen hat, erzeugt Ihr Bewertungs-Workflow Rauschen statt Einsicht.
Datenmodell erstellen (Risikoregister, Kontrollen, Maßnahmen)
Ein klares Datenmodell macht aus einer Spreadsheet-Liste ein System, dem Sie vertrauen können. Zielen Sie auf wenige Kernentitäten, saubere Beziehungen und konsistente Referenzlisten, damit Reports zuverlässig bleiben, auch wenn die Nutzung wächst.
Kern-Entitäten (minimales Schema)
Starten Sie mit Tabellen, die direkt abbilden, wie Menschen arbeiten:
- Users und Roles: wer im System ist und was er tun darf
- Risks: Eintrag im Register (Titel, Beschreibung, Owner, Geschäftsbereich, inherent/residual Ratings, Status)
- Assessments: punktuelle Bewertungen (Datum, Bewerter, Score-Inputs, Notizen). Getrennte Assessments verhindern das Überschreiben des „aktuellen Zustands“.
- Controls: Kontrollen, die Risiken mindern (Design-/Operating-Effektivität, Testfrequenz, Control-Owner)
- Incidents/Events: was passiert ist (Datum, Auswirkung, Root Cause, verknüpfte Risiko(s), verknüpfte Kontrollfehler)
- Actions: Maßnahmen verknüpft mit Risiko, Kontrolle oder Vorfall
- Comments: Diskussionen und Entscheidungen, idealerweise mit @Mentions und Timestamps
Beziehungen, die für Nachvollziehbarkeit wichtig sind
Modellieren Sie wichtige Many-to-Many-Links explizit:
- Risk ↔ Controls (über eine Join-Tabelle) zeigt, welche Kontrollen welche Risiken mindern
- Risk ↔ Incidents um reale Verluste/Near-Misses dem Register zuzuordnen
- Actions → Risk/Control/Incident (polymorpher Link oder drei nullable Foreign Keys) damit jede Maßnahme verankert ist
Damit beantworten Sie Fragen wie „Welche Kontrollen reduzieren unsere Top-Risiken?“ oder „Welche Vorfälle führten zu einer Bewertungsänderung?“
History-Tabellen und „Warum wurde das geändert?“
Betriebliche Risikoverfolgung braucht oft eine belastbare Änderungs-Historie. Ergänzen Sie History-/Audit-Tabellen für Risks, Controls, Assessments, Incidents und Actions mit:
- wer es geändert hat, wann und welche Felder betroffen waren
- optionaler Änderungsgrund (Freitext oder Codes)
Vermeiden Sie nur „zuletzt aktualisiert“ zu speichern, wenn Genehmigungen und Prüfungen erwartet werden.
Referenztabellen für Konsistenz
Nutzen Sie Referenztabellen (statt hartkodierter Strings) für Taxonomie, Status, Schwere-/Wahrscheinlichkeits-Skalen, Kontrolltypen und Action-States. So verhindern Sie Reporting-Probleme durch Tippfehler („High“ vs. „HIGH").
Anhänge (Evidenz) mit Aufbewahrung im Blick
Behandeln Sie Evidenz als erstklassige Daten: eine Attachments-Tabelle mit Dateimetadaten (Name, Typ, Größe, Uploader, verknüpftes Objekt, Upload-Datum) plus Felder für Aufbewahrungs-/Löschdatum und Zugriffsklassifikation. Dateien im Object-Storage ablegen, Governance-Regeln aber in der Datenbank pflegen.
Workflows, Genehmigungen und Verantwortlichkeiten planen
Eine Risiko-App scheitert schnell, wenn „wer macht was“ unklar ist. Definieren Sie vor dem Bau Workflow-Zustände, wer Items zwischen Zuständen verschieben darf und was in jedem Schritt erfasst werden muss.
Rollen und Berechtigungen (einfach halten)
Beginnen Sie mit wenigen Rollen und erweitern Sie nur bei Bedarf:
- Creator: kann neue Risiken, Kontrollen, Vorfälle und Maßnahmen entwerfen
- Risk Owner: verantwortlich für die Genauigkeit und laufende Prüfung
- Approver: validiert Einträge und kann sie als „offiziell“ markieren
- Auditor / Read-only: kann ansehen, exportieren und (optional) kommentieren, aber nicht editieren
- Admin: verwaltet Konfiguration, Benutzer und Berechtigungen
Machen Sie Berechtigungen explizit pro Objekttyp (Risk, Control, Action) und pro Fähigkeit (erstellen, bearbeiten, genehmigen, schließen, wiederöffnen).
Genehmigungsfluss: Draft → Review → Approved → Re-review
Verwenden Sie einen klaren Lebenszyklus mit vorhersehbaren Gates:
- Draft: editierbar; unvollständige Felder erlaubt
- In review: Änderungen eingeschränkt; Reviewer-Kommentare erforderlich
- Approved: Kerndaten sperren; Änderungen brauchen formalen Änderungsantrag
- Periodic re-review: geplante Kontrollpunkte (z. B. quartalsweise) zur Bestätigung
SLAs, Erinnerungen und Überfälligkeitslogik
Hängen Sie SLAs an Review-Zyklen, Kontrolltests und Action-Fälligkeitsdaten. Versenden Sie Erinnerungen vor Fälligkeit, eskalieren Sie nach verpassten SLAs und zeigen Sie überfällige Items prominent an (für Owner und deren Vorgesetzte).
Delegation, Neuzuweisung und Verantwortlichkeit
Jedes Element sollte einen eindeutigen verantwortlichen Owner haben plus optionale Mitwirkende. Delegation und Neuzuweisung unterstützen, erfordern aber einen Grund (und optional ein wirksames Datum), damit Leser verstehen, warum und wann die Verantwortung gewechselt wurde.
User Experience und zentrale Bildschirme gestalten
Deine Codebasis kontrollieren
Behalte die Kontrolle, indem du den Quellcode jederzeit für interne Prüfungen oder kundenspezifische Erweiterungen exportierst.
Eine Risiko-App funktioniert, wenn Menschen sie tatsächlich nutzen. Für nicht-technische Anwender ist die beste UX vorhersehbar, low-friction und konsistent: klare Bezeichnungen, wenig Jargon und genug Hilfetexte, um vage „Miscellaneous“-Einträge zu vermeiden.
1) Risikoaufnahme: gute Daten standardmäßig erzwingen
Ihr Intake-Formular sollte sich wie ein geführtes Gespräch anfühlen. Kurze Hilfetexte unter Feldern, nicht lange Anleitungen; wirklich verpflichtende Felder als solche markieren.
Essentials: Titel, Kategorie, Prozess/Bereich, Owner, aktueller Status, Anfangs-Score und „Warum das wichtig ist“ (Impact-Narrativ). Bei Scoring Tooltips neben jedem Faktor einblenden, damit Nutzer Definitionen ohne Kontextwechsel sehen.
2) Listenansicht: Triage und Nachverfolgung an einem Ort
Die meisten Nutzer verbringen Zeit in der Listenansicht — machen Sie sie schnell, um zu beantworten: „Was braucht Aufmerksamkeit?“
Bieten Sie Filter und Sortierung nach Status, Owner, Kategorie, Score, letztem Review-Datum und überfälligen Maßnahmen. Heben Sie Ausnahmen hervor (überfällige Reviews, past-due Actions) mit dezenten Badges — nicht überall Alarmfarben — damit die Aufmerksamkeit auf den richtigen Items liegt.
3) Detailansicht: eine Story, verknüpfte Datensätze
Die Detailseite sollte zuerst eine Zusammenfassung zeigen, dann unterstützende Details. Fokus oben: Beschreibung, aktueller Score, letztes Review, nächstes Review-Datum und Owner.
Darunter: verknüpfte Kontrollen, Vorfälle und Maßnahmen als separate Abschnitte. Fügen Sie Kommentare für Kontext hinzu („warum wir die Bewertung geändert haben“) und Anhänge als Evidenz.
4) Action-Tracker: Entscheidungen in Abschluss überführen
Maßnahmen brauchen Zuweisung, Fälligkeitsdaten, Fortschritt, Evidenz-Uploads und klare Abschlusskriterien. Machen Sie den Abschluss explizit: wer schließt ab und welche Nachweise sind erforderlich.
Wenn Sie ein Referenzlayout brauchen, halten Sie die Navigation einfach und konsistent (/risks, /risks/new, /risks/{id}, /actions).
Risiko-Scoring und Review-Logik implementieren
Scoring macht die App handlungsfähig. Ziel ist nicht, Teams zu „benoten“, sondern standardisiert zu vergleichen, was vorrangig ist, und Items aktuell zu halten.
Ein Scoring-Modell wählen (und dokumentieren)
Starten Sie mit einem einfachen, erklärbaren Modell, das für die meisten Teams funktioniert. Häufiger Default: 1–5 Skala für Wahrscheinlichkeit und Auswirkung, mit berechnetem Score:
- Score = Wahrscheinlichkeit × Auswirkung
Schreiben Sie klare Definitionen für jede Stufe (was „3“ bedeutet, nicht nur die Zahl). Stellen Sie diese Dokumentation in der UI bereit (Tooltips oder ein „How scoring works“-Drawer).
Schwellen sinnvoll definieren und an Aktionen knüpfen
Zahlen allein steuern Verhalten nicht — Schwellen tun es. Definieren Sie Grenzen für Niedrig / Mittel / Hoch (und optional Kritisch) und legen Sie fest, was jede Stufe auslöst.
Beispiele:
- Hoch: erfordert Owner, Zieltermin und Management-Genehmigung vor dem Schließen
- Mittel: erfordert einen Minderungsplan, benötigt aber ggf. keine Genehmigung
- Niedrig: beobachten und prüfen; keine unmittelbare Aktion erforderlich
Halten Sie Schwellen konfigurierbar, da „Hoch“ je Business Unit unterschiedlich sein kann.
Inherent vs. Residual risk nachverfolgen
Trennen Sie:
- Inherent risk: Risiko vor Kontrollen
- Residual risk: Risiko nach Berücksichtigung bestehender Kontrollen
Zeigen Sie beide Scores nebeneinander in der UI und machen Sie sichtbar, wie Kontrollen den residualen Score beeinflussen (z. B. reduziert eine Kontrolle Wahrscheinlichkeit um 1 oder Auswirkung um 1). Verstecken Sie die Logik nicht hinter automatischen Anpassungen, die Nutzer nicht erklären können.
Konfigurierbare Review-Regeln bauen
Fügen Sie zeitbasierte Review-Logik hinzu, damit Risiken nicht veralten. Ein praktikabler Baseline-Vorschlag:
- Hohe Risiken: quartalsweise Review
- Mittlere Risiken: halbjährlich
- Niedrige Risiken: jährlich
Review-Frequenz pro Business Unit konfigurierbar machen und Ausnahmen pro Risiko erlauben. Automatisieren Sie Erinnerungen und „Review overdue“-Status basierend auf dem letzten Review-Datum.
Black-Box-Scoring vermeiden
Zeigen Sie Berechnungsschritte: Wahrscheinlichkeit, Auswirkung, Control-Anpassungen und finalen residual Score. Nutzer sollen auf einen Blick beantworten können: „Warum ist das High?".
Audit-Trail, Versionierung und Evidenz-Handling bauen
UX mit echter UI validieren
Stelle Intake-, Listen- und Detailseiten bereit, damit Nutzer den Workflow testen statt darüber zu diskutieren.
Eine Risiko-Tool ist nur so glaubwürdig wie seine Historie. Wenn ein Score sich ändert, eine Kontrolle „getestet“ markiert wird oder ein Vorfall neu klassifiziert wird, brauchen Sie eine Aufzeichnung, die beantwortet: wer, wann und warum.
Entscheiden, was auditiert wird (und explizit machen)
Beginnen Sie mit einer klaren Ereignisliste, damit Sie nicht wichtige Aktionen übersehen oder das Log mit Rauschen füllen. Übliche Audit-Ereignisse:
- Create/Update/Delete auf Kernobjekten (Risks, Controls, Incidents, Actions)
- Genehmigungsentscheidungen (eingereicht, genehmigt, abgelehnt) und Eigentümerwechsel
- Exporte (CSV/PDF), besonders für regulierte Teams
- Authentifizierungsereignisse (Login-Versuche, Passwort-Resets) und Berechtigungsänderungen
„Wer/Wann/Was“ plus Kontext erfassen
Mindestens speichern Sie Actor, Timestamp, Objekt-Typ/ID und die geänderten Felder (alt → neu). Fügen Sie optional ein Feld „Grund für Änderung“ hinzu — das verhindert später verwirrende Ping-Pong-Änderungen.
Halten Sie das Audit-Log append-only. Vermeiden Sie Edit-Möglichkeiten, auch für Admins; wenn Korrekturen nötig sind, erzeugen Sie ein neues Ereignis, das sich auf das vorherige bezieht.
Schreibgeschützte Audit-Ansicht bereitstellen
Prüfer und Admins brauchen typischerweise eine dedizierte, filterbare Ansicht: nach Datum, Objekt, Nutzer und Ereignistyp. Exportieren Sie einfach von diesem Bildschirm, protokollieren Sie aber auch das Export-Ereignis. Verweisen Sie ggf. auf /admin/audit-log.
Evidenz versionieren und stilles Überschreiben verhindern
Evidenzdateien (Screenshots, Testergebnisse, Richtlinien) sollten versioniert werden. Jeder Upload ist eine neue Version mit Timestamp und Uploader; vorherige Dateien bleiben erhalten. Wenn Ersetzungen erlaubt sind, verlangen Sie einen Grund und behalten Sie beide Versionen.
Aufbewahrung und Zugriff für sensible Evidenz definieren
Legen Sie Aufbewahrungsregeln fest (z. B. Audit-Events X Jahre, Evidenz Y Jahre löschen, außer bei Legal Hold). Schützen Sie Evidenz mit strengeren Rechten als den Risiko-Datensatz selbst, wenn sie personenbezogene Daten oder Sicherheitsdetails enthält.
Sicherheit, Datenschutz und Zugriffskontrolle angehen
Sicherheit und Datenschutz sind keine Extras — sie bestimmen, wie wohl sich Menschen fühlen, Vorfälle zu protokollieren, Evidenz anzuhängen und Zuständigkeiten zu vergeben. Beginnen Sie mit der Abbildung, wer Zugriff braucht, was er sehen darf und was eingeschränkt werden muss.
Authentifizierung: SSO vs. E-Mail/Passwort
Wenn Ihre Organisation bereits einen Identity-Provider nutzt (Okta, Azure AD, Google Workspace), priorisieren Sie Single Sign-On via SAML oder OIDC. Das reduziert Passwort-Risiken, vereinfacht On-/Offboarding und passt zu Unternehmensrichtlinien.
Für kleinere Teams oder externe Nutzer kann E-Mail/Passwort funktionieren — dann aber mit starken Passwortregeln, sicherer Kontowiederherstellung und, wo möglich, MFA.
Rollenbasierte Zugriffskontrolle (RBAC), die zur Arbeit passt
Definieren Sie Rollen, die reale Verantwortlichkeiten abbilden: Admin, Risiko-Eigentümer, Reviewer/Approver, Contributor, Read-only, Auditor.
Betriebliche Risiken erfordern oft engere Grenzen als typische interne Tools. Erwägen Sie RBAC, das einschränken kann:
- Nach Business Unit/Abteilung (z. B. Finance sieht keine HR-Vorfälle)
- Auf Record-Ebene (z. B. nur ein Untersuchungsteam sieht einen sensiblen Vorfall)
Machen Sie Berechtigungen nachvollziehbar — Nutzer sollten schnell verstehen, warum sie einen Datensatz sehen oder nicht.
Grundlegender Datenschutz, unverhandelbar
Nutzen Sie Verschlüsselung in Transit (HTTPS/TLS) überall und folgen Sie Least-Privilege-Prinzipien für App-Services und Datenbanken. Sessions schützen Sie mit sicheren Cookies, kurzen Idle-Timeouts und serverseitiger Invalidierung beim Logout.
Feldspezifische Sensitivität und Redaction
Nicht jedes Feld hat gleiches Risiko. Vorfallsbeschreibungen, Kunden- oder Mitarbeiterdetails brauchen strengere Kontrollen. Unterstützen Sie Feld-Level-Visibility (oder zumindest Redaction), damit Teams kooperieren können, ohne sensible Inhalte breit offenzulegen.
Administrative Schutzmaßnahmen
Fügen Sie pragmatische Guardrails hinzu:
- Admin-Aktivitätslogs (wer änderte Berechtigungen, Exporte, Konfigurationen)
- Optionale IP-Allowlists für Hochrisiko-Umgebungen
- MFA für Admins (auch wenn andere Nutzer es nicht zwingend nutzen)
Gut umgesetzt schützen diese Controls Daten und halten Reporting-/Remediation-Workflows flüssig.
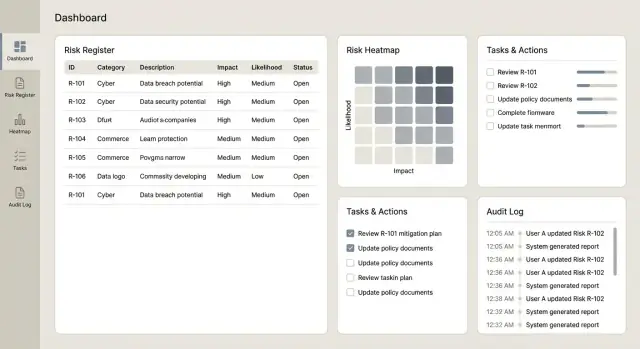
Dashboards, Reporting und Exporte liefern
Dashboards und Reports sind der Ort, an dem die App ihren Wert beweist: Sie verwandeln ein langes Register in klare Entscheidungen für Owner, Manager und Gremien. Wichtig ist, dass Zahlen auf die zugrundeliegenden Regeln und Datensätze zurückführbar sind.
Dashboards, die Menschen tatsächlich nutzen
Starten Sie mit wenigen, hochsignifikanten Ansichten, die häufige Fragen schnell beantworten:
- Top-Risiken nach residual Score (umschaltbar auf inherent)
- Trends über Zeit (residual-Score pro Monat/Quartal)
- Residual vs. Inherent Verteilung, inkl. „before vs. after controls“-Ansicht
- Risiko-Heatmap (Wahrscheinlichkeit × Auswirkung) mit Link von jeder Zelle zur Liste der zugrundeliegenden Risiken
Machen Sie jedes Dashboard-Element klickbar, damit Nutzer auf die genauen Risiken, Kontrollen, Vorfälle und Maßnahmen dahinter bohren können.
Operative Ansichten für das Tagesgeschäft
Entscheidungs-Dashboards unterscheiden sich von operativen Ansichten. Fügen Sie Screens hinzu, die das Wochengeschäft fokussieren:
- Überfällige Maßnahmen (nach Owner/Team, mit Tagen überfällig)
- Anstehende Reviews (Risiken/Kontrollen, fällig zur Prüfung)
- Fehlgeschlagene Kontrolltests (kürzliche Ausfälle, Schwere, offene Remediations)
- Vorfallfrequenz (Anzahlen und Raten über Zeit, filterbar nach Prozess/Kategorie)
Diese Ansichten zusammen mit Erinnerungen und Aufgabenverantwortung lassen die App wie ein Arbeitswerkzeug wirken, nicht nur wie eine Datenbank.
Exporte für Gremien und Audits
Planen Sie Exporte früh, denn Komitees arbeiten oft mit Offline-Paketen. Unterstützen Sie CSV für Analysen und PDF für Read-only-Verteilungen, mit:
- Filtern (Business Unit, Kategorie, Owner, Status)
- Datumsbereichen (Vorfälle in Periode, Maßnahmen erstellt/geschlossen in Periode)
- Klaren Bezeichnungen (inherent vs. residual, Versionsdaten, angewandte Filter)
Wenn Sie bereits ein Governance-Pack-Template haben, spiegeln Sie es, damit die Übernahme leichtfällt.
Stellen Sie sicher, dass jede Report-Definition mit Ihren Scoring-Regeln übereinstimmt. Wenn das Dashboard „Top-Risiken“ nach residual Score rankt, muss dieselbe Berechnung auch auf dem Datensatz und in Exporten verwendet werden.
Für große Register planen Sie Performance: Paginierung in Listen, Caching für häufige Aggregationen und asynchrone Report-Generierung (Bericht im Hintergrund erstellen und benachrichtigen, wenn er fertig ist). Gespeicherte Report-Konfigurationen sollten intern wieder aufrufbar sein (/reports).
Integrationen und Datenmigration planen
Risk-App schnell prototypen
Beschreibe im Chat die Screens deines Risikoregisters und erhalte ein funktionierendes V1 zur Abstimmung mit Stakeholdern.
Integrationen und Migration entscheiden, ob Ihre App das System of Record wird — oder nur noch ein weiterer Ort, den Leute vergessen. Planen Sie früh, aber implementieren Sie inkrementell, um das Kernprodukt stabil zu halten.
An die bestehenden Workflows anschließen
Die meisten Teams wollen keine „neue To‑Do‑Liste“. Sie wollen, dass die App mit den Tools verbunden ist, in denen Arbeit passiert:
- Jira oder ServiceNow für Remediation-Actions (Tickets erstellen und Status zurücksynchronisieren)
- Slack oder Microsoft Teams für Alerts bei Eskalationen, anstehenden Reviews oder angeforderter Evidenz
- E-Mail-Erinnerungen für periodische Reviews und Genehmigungen (nützlich für Gelegenheitsnutzer)
Praxis: Die Risiko-App bleibt der Owner der Risikodaten, externe Tools managen Execution-Details (Tickets, Assignees, Fälligkeitsdaten) und melden Fortschritt zurück.
Risiko-Register sicher aus Tabellen befüllen
Viele Organisationen starten mit Excel. Bieten Sie einen Import an, aber mit Schutzmechanismen:
- Validierungsregeln (Pflichtfelder, Datumsformate, numerische Bereiche)
- Duplikaterkennung (z. B. gleicher Risk-Titel + Prozess + Owner) mit Merge/Skip-Option
- Taxonomie-Erzwingung (Business Unit, Prozess, Risikokategorie) um chaotisches Reporting zu verhindern
Zeigen Sie eine Vorschau: was erstellt wird, was abgelehnt wird und warum. Dieser eine Bildschirm spart oft Stunden Abstimmungsaufwand.
API-Grundlagen, die spätere Schmerzen reduzieren
Auch wenn Sie nur eine Integration planen, designen Sie die API so, als würden es mehrere werden:
- Konsistente Endpunkte und Namensgebung (z. B. /risks, /controls, /actions)
- Audit-Logging bei Schreibvorgängen (wer änderte was, wann, und von wo)
- Rate-Limiting und klare Fehlercodes, damit Integrationen elegant scheitern
Fehlerbehandlung mit Retries und sichtbarlichem Status
Integrationen fallen aus normalen Gründen aus: Berechtigungsänderungen, Netzwerk-Timeouts, gelöschte Tickets. Bauen Sie dafür:
- Outbound-Queues mit Retry und Backoff
- Integrationsstatus pro verlinktem Item („Synced“, „Pending“, „Failed“)
- Handlungsorientierte Fehlermeldungen („ServiceNow-Token abgelaufen — neu verbinden“) und einen manuellen „Jetzt erneut versuchen“-Button
So bleibt das Vertrauen hoch und es entsteht kein stiller Drift zwischen Register und Execution-Tools.
Testen, Rollout und kontinuierliche Verbesserung
Eine Risiko-Tracking-App wird wertvoll, wenn Menschen ihr vertrauen und sie regelmäßig nutzen. Betrachten Sie Testing und Rollout als Produktarbeit, nicht als abschließenden Haken.
Praktische Teststrategie aufbauen
Beginnen Sie mit automatisierten Tests für Teile, die deterministisch sein müssen — besonders Scoring und Berechtigungen:
- Unit-Tests für Scoring: Wahrscheinlichkeit/Auswirkung-Berechnungen, Schwellen, Rundungen und Edge-Cases (z. B. „N/A“, fehlende Felder, Overrides)
- Workflow-Tests für Genehmigungen: sicherstellen, dass Zustandsänderungen den Regeln folgen (Draft → Submitted → Approved), inkl. Reassign- und Reject-Pfade
- Permission-Tests: Viewer können nicht editieren, Owner dürfen ggf. nicht ihre eigenen Einreichungen genehmigen (wenn Policy), Admins können auditieren ohne Segregation-of-Duties zu verletzen
User Acceptance Testing (UAT) mit echten Szenarien
UAT funktioniert am besten, wenn es reale Arbeit simuliert. Bitten Sie jede Business Unit um eine kleine Menge Sample-Risiken, Kontrollen, Vorfälle und Maßnahmen und führen typische Abläufe durch:
- Risiko erstellen, Kontrollen verknüpfen und zur Genehmigung einreichen
- Nach einem Vorfall aktualisieren und Evidenz anhängen
- Maßnahme abschließen und Reportingänderungen prüfen
Sammeln Sie nicht nur Bugs, sondern auch verwirrende Labels, fehlende Stati und Felder, die nicht zur Teamsprache passen.
Pilot vor dem unternehmensweiten Rollout
Starten Sie mit einem Team oder einer Region für 2–4 Wochen. Halten Sie den Umfang kontrolliert: ein Workflow, wenige Felder und eine klare Erfolgsmetrik (z. B. % Risiken, die termingerecht geprüft wurden). Nutzen Sie Feedback, um anzupassen:
- Feldnamen und Pflichtfelder
- Genehmigungsschritte und Verantwortlichkeiten
- Erinnerungs-Timing und Eskalationen
Schulung, Dokumentation und Adoption
Stellen Sie kurze How‑To-Guides und ein einseitiges Glossar bereit: was jeder Score bedeutet, wann welcher Status genutzt wird und wie Evidenz angehängt wird. Eine 30‑minütige Live‑Session plus Aufzeichnungen schlägt oft ein langes Handbuch.
Schnellere Entwicklung mit Koder.ai (optional)
Wenn Sie schnell zu einer glaubwürdigen V1 kommen wollen, kann eine Vibe‑Coding-Plattform wie Koder.ai helfen, Workflows zu prototypen und iterativ zu verfeinern. Sie beschreiben Screens und Regeln (Risk Intake, Approvals, Scoring, Reminders, Audit-Log-Views) im Chat und verfeinern die generierte App, während Stakeholder direkt am UI reagieren.
Koder.ai unterstützt End-to-End-Delivery: Web-Frontends (häufig React), Backend-Services (z. B. Go + PostgreSQL), Export des Source-Codes, Deployment/Hosting, Custom-Domains und Snapshots mit Rollback — nützlich bei Änderungen an Taxonomien, Scoring-Skalen oder Approval-Flows, wenn sicheres Iterieren nötig ist. Teams können auf einem Free-Tier starten und je nach Governance- und Skalierungsanforderungen zu Pro/Business/Enterprise wechseln.
App nach dem Launch gesund halten
Planen Sie fortlaufenden Betrieb früh: automatisierte Backups, Grund-Uptime/Error‑Monitoring und einen schlanken Änderungsprozess für Taxonomie- und Scoring‑Änderungen, damit Updates konsistent und prüfbar bleiben.