Was Sie bauen: Die IDP‑Web‑App in einfachen Worten
Eine IDP‑Web‑App ist die interne „Vordertür“ zu eurem Engineering‑System. Hier finden Entwickler, was bereits existiert (Services, Bibliotheken, Umgebungen), folgen dem empfohlenen Weg zum Bauen und Betreiben von Software und fordern Änderungen an, ohne sich durch ein Dutzend Tools zu wühlen.
Genauso wichtig: sie ist nicht noch ein All‑in‑One‑Ersatz für Git, CI, Cloud‑Konsolen oder Ticketing. Das Ziel ist, Reibung zu reduzieren, indem ihr das orchestriert, was ihr bereits nutzt — den richtigen Pfad zum einfachsten Pfad macht.
Die Probleme, die sie lösen soll
Die meisten Teams bauen eine IDP‑Web‑App, weil der Alltag verlangsamt wird durch:
- Tool‑Sprawl: das Wissen „wo man klicken muss“ lebt in tribal memory.
- Langsames Onboarding: neue Ingenieure verbringen Wochen damit, Prozesse zu lernen statt Features zu liefern.
- Inkonsistente Standards: Services werden unterschiedlich erstellt und betrieben, was Zuverlässigkeit und Sicherheit erschwert.
Die Web‑App sollte das in wiederholbare Workflows und klare, durchsuchbare Informationen verwandeln.
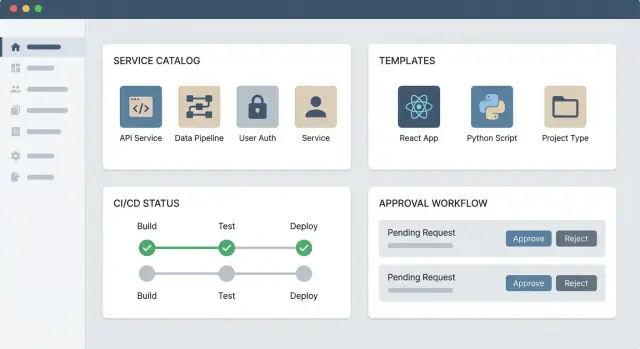
Kernbausteine
Eine praktische IDP‑Web‑App hat üblicherweise drei Teile:
- Portal‑UI: ein Service‑Katalog, Einstiegspunkte für Dokumentation und Self‑Service‑Formulare (z. B. „Service erstellen“, „Zugriff anfordern“, „Datenbank provisionieren“).
- Backend‑APIs: die Business‑Logik, die Anfragen validiert, Richtlinien anwendet und Aktionen protokolliert.
- Integrationen: Connectoren zu eurer Toolchain (Git‑Hosting, CI/CD, Infrastruktur‑Tools, Secrets, Incident‑Management), damit Aktionen in den Systemen der Wahrheit stattfinden.
Wer es besitzt (und wer nicht)
Das Platform‑Team besitzt typischerweise das Portal‑Produkt: Experience, APIs, Templates und Guardrails.
Product‑Teams besitzen ihre Services: Metadaten aktuell halten, Docs/Runbooks pflegen und die bereitgestellten Templates übernehmen. Ein gesundes Modell ist Shared Responsibility: das Platform‑Team baut die gepflasterte Straße; Product‑Teams fahren darauf und helfen, sie zu verbessern.
Nutzer, Use Cases und Erfolgsmessung
Eine IDP‑Web‑App wird daran gemessen, ob sie die richtigen Personen mit den richtigen „Happy Paths“ bedient. Bevor ihr Tools oder Architekturdiagramme auswählt, klärt, wer das Portal nutzt, was diese Personen erreichen wollen und wie ihr Fortschritt messen werdet.
Primäre Nutzer (und was ihnen wichtig ist)
Die meisten IDP‑Portale haben vier Kernzielgruppen:
- Application Developers: wollen schnelle, sichere Defaults, um Services ohne Tickets zu erstellen und zu betreiben.
- SRE / Ops: wollen Standardisierung, weniger überraschende Änderungen und klare Ownership bei Incidents.
- Security / Compliance: wollen konsistente Kontrollen (Zugriffsüberprüfungen, Umgang mit Secrets, Audit‑Spuren) ohne Delivery zu blockieren.
- Engineering Manager / Product Leads: wollen Sichtbarkeit—was existiert, wer besitzt es, und ob Teams zuverlässig ausliefern.
Wenn ihr nicht in einem Satz beschreiben könnt, wie jede Gruppe profitiert, baut ihr wahrscheinlich ein Portal, das optional wirkt.
5–10 Schlüssel‑Journeys abbilden
Wählt Journeys, die wöchentlich stattfinden (nicht jährlich) und macht sie wirklich End‑to‑End:
- Neuen Service erstellen aus einem Template (Repo + CI + Ownership + Tags).
- Environment anfordern (dev/stage) mit Guardrails.
- Service‑Health ansehen (Deploy‑Status, Alerts, Abhängigkeiten).
- Keys/Secrets rotieren mit auditierbarem Workflow.
- Zugriff anfordern auf ein System oder Dataset mit Genehmigungen.
Schreibt jede Journey als: Trigger → Schritte → berührte Systeme → erwartetes Ergebnis → Fehlermodi. Das wird euer Product‑Backlog und eure Akzeptanzkriterien.
Definiert Erfolgsmessgrößen, die ihr tatsächlich tracken könnt
Gute Metriken hängen direkt mit eingesparter Zeit und entfernter Reibung zusammen:
- Time‑to‑first‑deploy für einen neuen Service (Median, p90).
- Manuelle Ticket‑Menge für gängige Anfragen (und Time‑to‑Resolution).
- Adoption‑Rate: % der registrierten Services, % Teams, die Templates nutzen.
- Change failure rate und mean time to restore, falls das Portal die Delivery standardisiert.
Schreibt eine „Version 1“ Scope‑Aussage
Kurz und sichtbar halten:
V1‑Scope: „Ein Portal, das Entwicklern erlaubt, einen Service aus genehmigten Templates zu erstellen, ihn im Service‑Katalog mit einem Owner zu registrieren und Deploy‑ + Health‑Status anzuzeigen. Einschließlich grundlegender RBAC und Audit‑Logs. Schließt custom Dashboards, vollständigen CMDB‑Ersatz und maßgeschneiderte Workflows aus."
Diese Aussage ist euer Filter gegen Feature‑Creep und euer Roadmap‑Anker.
MVP‑Scope und Roadmap für ein internes Portal
Ein internes Portal ist erfolgreich, wenn es ein schmerzhaftes Problem End‑to‑End löst und sich dann das Recht verdient, zu wachsen. Der schnellste Weg ist ein enges MVP, das in Wochen — nicht Quartalen — an ein echtes Team geliefert wird.
Ein schmales MVP, das sich „vollständig“ anfühlt
Startet mit drei Bausteinen:
- Service‑Katalog: ein Ort, um zu entdecken, was existiert, wer es besitzt und wo die operationalen Links liegen.
- Ein Self‑Service‑Workflow: wählt eine hochfrequente Anfrage (z. B. „Service‑Repo erstellen“ oder „Standard‑Environment provisionieren“) und automatisiert sie.
- Docs/Links‑Hub: migriert nicht alles — verlinkt zu bestehenden Quellen der Wahrheit (CI/CD, Incident‑Tools, Runbooks), während ihr lernt, was Leute tatsächlich nutzen.
Dieses MVP ist klein, liefert aber ein klares Ergebnis: „Ich finde meinen Service und kann eine wichtige Aktion durchführen, ohne in Slack zu fragen."
Wenn ihr UX und Workflow schnell validieren wollt, kann eine vibe‑coding‑Plattform wie Koder.ai nützlich sein, um die Portal‑UI und Orchestrierungsbildschirme aus einer geschriebenen Workflow‑Spec zu prototypen. Koder.ai kann eine React‑basierte Web‑App mit einem Go + PostgreSQL‑Backend generieren und unterstützt Source‑Code‑Export, sodass Teams schnell iterieren und dennoch langfristige Besitzrechte am Code behalten.
Backlog‑Struktur: Discover, Create, Operate, Govern
Um die Roadmap organisiert zu halten, gruppiert Arbeit in vier Buckets:
- Discover: Suche, Tags, Ownership, Team‑Seiten, Dependency‑Views.
- Create: Templates, Scaffolding, Environment‑Provisioning, Standard‑Konfigurationen.
- Operate: Links zu Dashboards/Runbooks, On‑Call‑Info, SLO‑Summaries, gängige Aktionen.
- Govern: RBAC, Genehmigungsschritte, Audit‑Logs, Policy‑Checks.
Diese Struktur verhindert ein Portal, das „nur Katalog“ oder „nur Automation“ ist, ohne Verbindung zwischen beidem.
Jetzt automatisieren vs. verlinken
Automatisiert nur, was mindestens eines der Kriterien erfüllt: (1) tritt wöchentlich auf, (2) ist fehleranfällig bei manueller Ausführung, (3) erfordert Multi‑Team‑Koordination. Alles andere kann ein gut kuratierter Link zum richtigen Tool mit klaren Anweisungen und Ownership sein.
Progressive Erweiterung ohne Redesign
Entwerft das Portal so, dass neue Workflows sich als zusätzliche „Aktionen“ auf einer Service‑ oder Environment‑Seite einhängen lassen. Wenn jedes neue Workflow ein Navigations‑Umdenken erfordert, stockt die Adoption. Behandelt Workflows wie Module: konsistente Eingaben, konsistenter Status, konsistente Historie — so fügt ihr mehr hinzu, ohne das mentale Modell zu ändern.
Referenzarchitektur: UI, APIs und Integrationen
Eine praktische IDP‑Portal‑Architektur hält die User‑Experience simpel, während sie die „schmutzige“ Integrationsarbeit zuverlässig im Hintergrund erledigt. Ziel ist eine einzelne Web‑App für Entwickler – auch wenn Aktionen oft Git, CI/CD, Cloud‑Accounts, Ticketing und Kubernetes übergreifen.
Wählt ein Deployment‑Modell
Es gibt drei gängige Muster, die richtige Wahl hängt davon ab, wie schnell ihr liefern müsst und wie viele Teams das Portal erweitern werden:
- Single App (Monolith): schnellstes MVP. UI, API und Integrationslogik werden gemeinsam deployed. Gut, wenn das Platform‑Team die meisten Features besitzt.
- Modulare Services: UI, Core‑API und einige Integrations‑Services getrennt. Einfacheres Skalieren und klarere Ownership, wenn das Portal wächst.
- Plugin‑basiert: ein stabiler „Core“ plus Plugins für Katalogquellen, Scaffolding, Docs und Workflows. Am besten, wenn viele Teams Features beisteuern.
Kernkomponenten (was wo läuft)
Mindestens erwartet ihr diese Bausteine:
- Web‑UI (Developer Portal): Katalog‑Browsing, Golden Paths, Formulare, Statusseiten.
- Backend‑API (oft hinter einem API‑Gateway): Auth, RBAC‑Checks, Validierung, Orchestrierung.
- Integration‑Worker: lang laufende Tasks (Repo‑Erstellung, Environment‑Provisioning, CI‑Setup) asynchron ausgeführt.
- Datenbank: Portal‑Konfiguration, gecachte Katalog‑Views, Workflow‑Historie, Audit‑Events.
Wo Zustand liegen sollte
Entscheidet früh, was das Portal „besitzt“ vs. nur darstellt:
- Behaltet Source‑of‑Truth in bestehenden Systemen (Git, Cloud‑IAM, CI/CD, Kubernetes, Ticketing).
- Speichert in der Portal‑DB: Workflow‑Anfragen, Status, Genehmigungen, Audit‑Logs und gecachte Indizes, die die UI schnell machen.
Zuverlässigkeit bei Integrationen
Integrationen scheitern aus normalen Gründen (Rate‑Limits, transient outages, partielle Erfolge). Designt für:
- Retries mit Backoff und klare Fehlermeldungen
- Idempotenz (ein erneuter Lauf darf keine Duplikate erzeugen)
- Timeouts und Abbruchmöglichkeiten
- Dauerhafte Workflow‑Historie, damit Nutzer sehen können, was passiert ist und sicher wiederherstellen können
Datenmodell: Service‑Katalog und Ownership
Euer Service‑Katalog ist die Quelle der Wahrheit dafür, was existiert, wer es besitzt und wie es in das restliche System passt. Ein klares Datenmodell verhindert „Mystery‑Services“, doppelte Einträge und gebrochene Automationen.
Definiert die Kern‑Entität „Service"
Einigt euch darauf, was ein „Service“ in eurer Organisation bedeutet. Für die meisten Teams ist es eine deploybare Einheit (API, Worker, Website) mit Lifecycle.
Modelliert mindestens folgende Felder:
- Name + Beschreibung (menschlich lesbar)
- Owner: primäres Team plus optionale sekundäre Kontakte (On‑Call‑Gruppe, Tech‑Lead)
- Source‑Repositories: ein oder mehrere Repo‑Links/IDs
- Runtime‑Environments: dev/stage/prod oder regionspezifische Varianten
- Dependencies: upstream/downstream Services und geteilte Bibliotheken
Fügt praktikable Metadaten hinzu, die das Portal antreiben:
- Lifecycle (experimental, active, deprecated)
- Kritikalität/Tier (für Support‑Erwartungen und Governance)
- Links (Runbooks, Dashboards, SLOs, Incident‑Channel)
Beziehungen explizit modellieren
Behandelt Beziehungen als First‑Class, nicht nur als Textfelder:
- Services ↔ Teams: viele Services pro Team; manchmal geteilte Ownership (nutzt
primary_owner_team_id plus additional_owner_team_ids).
- Services ↔ Ressourcen: verbindet zu Cloud‑Ressourcen (Kubernetes‑Namespaces, Queues, Datenbanken), damit man beantworten kann „was nutzt dieser Service?“.
- Service‑Tiers: speichert Tier als strukturiertes Enum und verknüpft es mit Policies (z. B. Tier‑0 erfordert On‑Call und Audit‑Logs).
Diese relationale Struktur ermöglicht Seiten wie „Alles, was Team X besitzt“ oder „Alle Services, die diese Datenbank nutzen".
Identifier und Namensregeln
Entscheidet früh über die kanonische ID, damit keine Duplikate nach Importen entstehen. Übliche Muster:
- Ein stabler Slug (z. B.
payments‑api) mit Unique‑Constraint
- Eine immutable UUID plus human‑freundlicher Slug
- Optional: ein repo‑abgeleiteter Key (
github_org/repo) wenn Repos 1:1 mit Services sind
Dokumentiert Namensregeln (erlaubte Zeichen, Uniqueness, Rename‑Policy) und validiert sie bei der Erstellung.
Plant, wie Daten frisch bleiben
Ein Katalog scheitert, wenn er stale wird. Wählt eine oder kombiniert:
- Geplante Importe (nächtliche Syncs von Git, CI/CD, Cloud‑Inventar)
- Webhooks (Update bei Repo‑Änderungen, Deploys, Ownership‑Änderungen)
- Event‑Streams (publish Events wie
service.created oder dependency.updated)
Behaltet ein last_seen_at und data_source Feld pro Record, damit ihr Frische anzeigen und Konflikte debuggen könnt.
Authentifizierung, Autorisierung und Auditierbarkeit
Prototypen Sie Ihr IDP‑MVP
Verwandeln Sie den Umfang Ihres V1‑Portals in eine funktionierende App, indem Sie Workflows im Chat beschreiben.
Wenn euer IDP‑Portal vertraut werden soll, braucht es drei zusammenwirkende Dinge: Authentication (Wer bist du?), Authorization (Was darfst du?) und Auditability (Was ist passiert und wer hat es getan?). Richtet das früh richtig ein, um späteren Rework zu vermeiden — besonders wenn das Portal Produktionsänderungen handhabt.
Default: SSO mit Gruppenmapping
Die meisten Firmen haben Identity‑Infrastruktur. Nutzt sie.
Macht SSO via OIDC oder SAML zum Standard‑Login‑Weg und zieht Gruppenmitgliedschaften aus eurem IdP (Okta, Azure AD, Google Workspace usw.). Mapped dann Gruppen auf Portal‑Rollen und Team‑Membership.
Das vereinfacht Onboarding („einloggen und schon in den richtigen Teams sein“), vermeidet Passwortspeicherung und lässt IT globale Policies wie MFA und Session‑Timeouts durchsetzen.
Klare Rollen definieren (und ihre Rechte)
Vermeidet ein vages „Admin vs Everyone“ Modell. Ein praktisches Set an Rollen ist:
- Developer: Portal browsen, Templates und Self‑Service‑Workflows innerhalb erlaubter Bereiche nutzen.
- Service Owner: Service‑Katalog‑Eintrag verwalten (Metadaten, On‑Call, Links), service‑spezifische Historie sehen.
- Approver: sensible Anfragen (Prod‑Zugriff, neue Environments, kostenrelevante Ressourcen) genehmigen oder ablehnen.
- Platform Admin: Templates, Integrationen, globale Einstellungen und Policy‑Defaults verwalten.
- Auditor: Read‑Only‑Zugriff auf Audit‑Logs, Genehmigungen und Konfigurationshistorie.
Haltet Rollen klein und verständlich. Ihr könnt später erweitern, aber ein verwirrendes Modell senkt die Adoption.
RBAC plus Ressourcen‑Level‑Berechtigungen
RBAC ist nötig, aber nicht ausreichend. Das Portal braucht resource‑level permissions: Zugriff sollte auf ein Team, einen Service oder eine Environment eingeschränkt werden.
Beispiele:
- Ein Entwickler kann den Workflow „Sandbox‑Environment erstellen" für Services seines Teams auslösen, nicht für andere.
- Ein Service Owner kann den Service‑Katalog‑Eintrag für seine Services bearbeiten.
- Ein Approver kann nur Anfragen für bestimmte Kostenstellen oder Produktions‑Namespaces genehmigen.
Implementiert dies mit einem einfachen Policy‑Pattern: (Principal) can (Action) on (Resource) if (Condition). Startet mit Team/Service‑Scope und erweitert schrittweise.
Audit‑Trails für sensible Aktionen
Behandelt Audit‑Logs als Produkt‑Feature, nicht als Backend‑Detail. Das Portal sollte protokollieren:
- Wer einen Self‑Service‑Workflow initiiert hat (und woher)
- Übermittelte Parameter (Secrets redigiert)
- Wer genehmigt/abgelehnt hat und Kommentare
- Resultierende Änderungen (Links zu CI/CD‑Runs, Tickets oder Infrastrukturänderungen)
- Änderungen an Templates, Berechtigungen und Integrationen
Macht Audit‑Trails leicht zugänglich: auf der Service‑Seite, in einem Workflow‑„History“‑Tab und in einer Admin‑Ansicht für Compliance. Das beschleunigt Incident‑Reviews erheblich.
UX‑Design für Entwickler: Den richtigen Weg leicht machen
Gute IDP‑UX ist nicht auf Optik reduziert — es geht darum, die Reibung beim Shippen zu minimieren. Entwickler sollten schnell drei Fragen beantworten können: Was existiert? Was kann ich erstellen? Was braucht aktuell Aufmerksamkeit?
Navigation um reale Aufgaben herum gestalten
Statt Menüs nach Backend‑Systemen zu ordnen („Kubernetes“, „Jira“, „Terraform“), strukturiert das Portal um die Arbeit, die Entwickler tatsächlich tun:
- Discover: Services, APIs, Docs, Owner, Runbooks finden
- Create: neuen Service starten, Endpoint hinzufügen, Datenbank anfordern
- Operate: Health, Incidents, Deploy‑Status, letzte Änderungen sehen
- Govern: Berechtigungen, Compliance‑Checks, Policy‑Ausnahmen
Diese aufgabenorientierte Navigation erleichtert auch Onboarding: neue Kollegen müssen eure Toolchain nicht kennen, um loszulegen.
Ownership sichtbar machen
Jede Service‑Seite sollte deutlich zeigen:
- Verantwortliches Team und Team‑Channel
- On‑Call‑Rotation und Eskalationspfad
- Primäres Repo(s) und Deployment‑Ziel
Platziert dieses „Who owns this?“ Panel weit oben, nicht in einem Tab. Bei Incidents zählt jede Sekunde.
Suche, Filter und Status nach Denkweisen der Nutzer
Schnelle Suche ist die Power‑Funktion des Portals. Unterstützt Filter, die Entwickler natürlich nutzen: Team, Lifecycle (experimental/production), Tier, Sprache, Plattform und „owned by me“. Fügt klare Statusindikatoren hinzu (healthy/degraded, SLO at risk, blocked by approval), sodass Nutzer Listen scannen und entscheiden können.
Fragt beim Erstellen nur nach dem, was jetzt wirklich nötig ist. Nutzt Templates („Golden Paths") und Defaults, um vermeidbare Fehler zu verhindern — Namenskonventionen, Logging/Monitoring‑Hooks und Standard‑CI‑Einstellungen sollten vorausgefüllt sein. Versteckt optionale Felder unter „Advanced options“, damit der Happy Path schnell bleibt.
Self‑Service‑Workflows: Templates, Genehmigungen und Historie
Regionale Compliance‑Anforderungen erfüllen
Betreiben Sie Ihre App im Land, das Sie zur Einhaltung von Datenschutzanforderungen benötigen.
Self‑Service ist der Punkt, an dem ein internes Portal Vertrauen verdient: Entwickler sollten häufige Aufgaben End‑to‑End ohne Ticket erledigen können, während Platform‑Teams Kontrolle über Sicherheit, Compliance und Kosten behalten.
Wählt die Workflow‑Typen, die zuerst wichtig sind
Startet mit einer kleinen Menge Workflows, die häufig und friktionsbehaftet sind. Typische „erste vier“:
- Service erstellen: Repo scaffolden, im Katalog registrieren, Ownership setzen und CI/CD bootstrappen.
- Environment provisionieren: Dev/Stage‑Environment mit standardisiertem Networking, Logging und Budgets spinnen.
- Zugriff anfordern: Least‑Privilege‑Zugriff zu einem System (DB, Queue, Dritt‑API) mit Ablaufoption gewähren.
- Secrets rotieren: Rotation auslösen, Downstream‑Configs aktualisieren und Anwendungen validieren.
Diese Workflows sollten meinungsstark sein und euren Golden Path widerspiegeln, aber kontrollierte Wahlmöglichkeiten zulassen (Sprache/Runtime, Region, Tier, Datenklassifikation).
Definiert einen Workflow‑Contract (damit Templates vorhersehbar bleiben)
Behandelt jeden Workflow wie eine Produkt‑API. Ein klarer Contract macht Workflows wiederverwendbar, testbar und leichter integrierbar in eure Toolchain.
Ein praktischer Contract beinhaltet:
- Inputs: typisierte Felder mit Defaults (z. B. Service‑Name, Owner‑Team, Environment, Data‑Sensitivity).
- Validation: Namensregeln, erlaubte Regionen, Quota‑Checks und „existiert das schon?“ Prüfungen.
- Steps: eine Sequenz von Aktionen (Template ausführen, CI/CD aufrufen, Cloud‑Ressourcen erstellen, Service‑Katalog aktualisieren).
- Outputs: Artefakte und Links, die Entwickler brauchen (Repo‑URL, Deployment‑URL, Runbook‑Link, erstellte Ressourcen).
Haltet die UX fokussiert: zeigt nur die Inputs an, über die der Entwickler tatsächlich entscheiden kann, und leitet den Rest aus dem Service‑Katalog und der Policy ab.
Genehmigungen, die schnell, klar und durchsetzbar sind
Genehmigungen sind für bestimmte Aktionen unvermeidbar (Produktionszugriff, sensible Daten, Kostensteigerungen). Das Portal sollte Genehmigungen vorhersehbar machen:
- Wer genehmigt was: regelbasierte Genehmiger definieren (Team‑Owner, System‑Owner, Security) statt ad‑hoc Pings.
- Zeitlimits: SLA für Genehmigungen setzen und veraltete Anfragen automatisch auslaufen lassen.
- Eskalation: wenn der Primary Approver nicht verfügbar ist, an eine Backup‑Gruppe oder On‑Call‑Rotation weiterleiten.
Wichtig: Genehmigungen gehören in die Workflow‑Engine, nicht als manuelle Nebenkommunikation. Der Entwickler sollte Status, nächste Schritte und den Grund für die Genehmigung sehen.
Historie und Ergebnisse speichern, damit Teams selbst debuggen
Jeder Workflow‑Run sollte eine permanente Aufzeichnung liefern:
- Eingesetzte Inputs, Validierungsergebnisse und Genehmiger‑Entscheidungen
- Schritt‑für‑Schritt‑Logs (Secrets redigiert)
- Finale Outputs, erstellte Ressourcen und etwaige Rollback‑Aktionen
Diese Historie ist eure „Paper Trail“ und euer Support‑System: wenn etwas fehlschlägt, sehen Entwickler genau, wo und warum — oft lösen sie Probleme ohne Ticket. Es gibt Platform‑Teams außerdem Daten, um Templates zu verbessern und wiederkehrende Fehler zu erkennen.
Ein IDP‑Portal fühlt sich nur dann „real“ an, wenn es Systeme lesen und Aktionen in ihnen auslösen kann. Integrationen verwandeln einen Katalog‑Eintrag in etwas, das ihr deployen, beobachten und supporten könnt.
Beginnt mit einer klaren Integrations‑Checklist
Die meisten Portale brauchen eine Basisausstattung an Verbindungen:
- Git (Repos, Default‑Branches, CODEOWNERS, Pull Requests)
- CI/CD (Pipelines, Build‑Status, Artefakte, Promotionen)
- Kubernetes (Clusters, Namespaces, Workloads, Rollouts)
- Cloud (Accounts/Projects, Networking, Managed Services)
- IAM (Teams, Groups, SSO, Role‑Mappings)
- Secrets (Vaults, Secret‑References, Rotation‑Status)
Seid explizit, welche Daten read‑only sind (z. B. Pipeline‑Status) und welche write (z. B. Deployment auslösen).
API‑First bevorzugen; Webhooks oder Sync wenn nötig
API‑first Integrationen sind leichter zu testen und zu verstehen: Auth, Schemas und Fehlerbehandlung lassen sich validieren.
Nutzt Webhooks für near‑real‑time Events (PR gemerged, Pipeline fertig). Nutzt scheduled sync für Systeme, die keine Push‑Events liefern oder wo Eventual‑Consistency ok ist (z. B. nächtlicher Import von Cloud‑Accounts).
Baut eine Connector‑Schicht (bindet Vendoren nicht ins Core)
Erstellt einen dünnen Connector/Integration‑Service, der vendor‑spezifische Details in einen stabilen internen Vertrag normalisiert (z. B. Repository, PipelineRun, Cluster). Das isoliert Änderungen beim Tool‑Wechsel und hält eure Portal‑API sauber.
Praktisches Pattern:
- Portal ruft den Connector auf
- Connector handelt Auth, Rate‑Limits, Retries, Mapping
- Connector liefert normalisierte Daten + actionale Links (z. B.
/deployments/123)
Fehlermodi und Benutzeranweisungen dokumentieren
Jede Integration sollte ein kurzes Runbook haben: wie „degraded“ aussieht, wie es in der UI dargestellt wird und was zu tun ist.
Beispiele:
- Git API rate‑limitiert: Portal zeigt gecachte Repo‑Daten; „Create from template“ deaktiviert.
- CI/CD down: Portal bietet einen manuellen Fallback (Link zur Pipeline‑UI) und erklärt Retry‑Timing.
- Secrets‑Manager nicht verfügbar: blockiert Änderungen, die neue Secrets brauchen; erlaubt read‑only Metadatenzugriff.
Haltet diese Docs nahe am Produkt (z. B. /docs/integrations), damit Entwickler nicht raten müssen.
Observability: Portal und seine Automationen überwachen
Euer IDP‑Portal ist nicht nur UI — es ist eine Orchestrierungsschicht, die CI/CD Jobs triggert, Cloud‑Ressourcen erstellt, den Service‑Katalog aktualisiert und Genehmigungen durchsetzt. Observability erlaubt schnelle Antworten auf: „Was ist passiert?“, „Wo ist es fehlgeschlagen?“, „Wer muss handeln?"
Jede Anfrage über Schritte verfolgen
Instrumentiert jeden Workflow‑Run mit einer Correlation‑ID, die die Anfrage von der Portal‑UI über Backend‑APIs, Genehmigungschecks und externe Tools (Git, CI, Cloud, Ticketing) verfolgt. Fügt Request Tracing hinzu, sodass eine Ansicht den vollen Pfad und die Timings jedes Schritts zeigt.
Ergänzt Traces mit strukturierten Logs (JSON) mit Feldern: Workflow‑Name, Run‑ID, Step‑Name, Ziel‑Service, Environment, Actor und Outcome. So filtert ihr einfach nach „alle fehlgeschlagenen deploy‑template Runs" oder „alles, was Service X betrifft".
Metriken, die Entwickler‑Schmerz widerspiegeln
Basis‑Infra‑Metriken reichen nicht. Fügt Workflow‑Metriken hinzu, die echte Outcomes widerspiegeln:
- Run‑Counts, Success‑Rate und Dauer pro Workflow und Schritt
- Approval‑Wait‑Time vs. Execution‑Time (zeigt Engpässe)
- Retries, Timeouts und Rate‑Limits aus Connectors
Operative Views im Portal
Gebt Platform‑Teams Übersichtsseiten:
- Workflow‑Queue: running, queued, failed, awaiting approval
- Connector‑Health: Token‑Validity, letzte erfolgreiche Call, Error‑Rate
- Sync‑Status: letzte Katalog‑Sync, erkannter Drift, Backlog‑Größe
Verlinkt jeden Status zu Drill‑Down‑Details und den exakten Logs/Traces für den jeweiligen Run.
Alerts, Retention und Audit
Setzt Alerts für gebrochene Integrationen (z. B. wiederholte 401/403), feststeckende Genehmigungen (kein Action für N Stunden) und Sync‑Fehler. Plant Daten‑Retention: hochfrequente Logs kürzer behalten, aber Audit‑Events länger für Compliance und Untersuchungen, mit klaren Zugriffsregeln und Exportoptionen.
Sicherheit und Governance ohne Teams zu verlangsamen
Integrationen mit weniger Risiko entwerfen
Entwerfen Sie Connector‑Screens und Orchestrierungsabläufe, bevor Sie jede Vendor‑API anbinden.
Sicherheit in einem IDP‑Portal funktioniert am besten, wenn sie wie „Guardrails“ wirkt, nicht wie Schranken. Ziel ist, riskante Entscheidungen zu reduzieren, indem der sichere Pfad der einfachste ist — gleichzeitig Teams Autonomie lässt.
Governance sollte beim Request‑Moment passieren (neuer Service, Repo, Environment, Cloud‑Ressource). Behandelt jedes Formular und jeden API‑Call als untrusted Input.
Durchsetzt Standards in Code, nicht nur in Docs:
- Ownership (Team, On‑Call, Eskalationskontakt) verlangen und Erstellung blockieren, wenn fehlt.
- Namenskonventionen validieren (Service‑Names, Repo‑Names, Environments) um Kollisionen zu vermeiden.
- Tags/Metadaten für Kostenallokation, Compliance und Discovery verlangen.
- Requests ablehnen, die Mindestpolicy nicht erfüllen (z. B. „öffentliche Exposition“ benötigt Extra‑Review).
Das hält den Service‑Katalog sauber und macht Audits einfacher.
Secrets von vornherein schützen
Ein Portal berührt oft Credentials (CI‑Tokens, Cloud‑Keys, API‑Keys). Behandelt Secrets wie radioaktiv:
- Nie Secrets loggen oder in Fehlermeldungen ausgeben.
- Kurzlebige Tokens bevorzugen (OIDC, federated access, zeitbegrenzte Credentials) gegenüber langlebigen Keys.
- Secrets nur in einem dedizierten Secret‑Manager speichern; das Portal referenziert sie, kopiert sie nicht.
Stellt außerdem sicher, dass Audit‑Logs erfassen, wer was wann getan hat — ohne Secret‑Werte zu protokollieren.
Threat‑Modeling realistischer Fehler
Konzentriert euch auf realistische Risiken:
- Privilege‑Escalation durch falsch konfigurierte RBAC und zu breite Rechte
- Gefälschte Webhooks oder Callbacks, die Aktionen ohne Verifikation auslösen
- Datenleaks über Debug‑Endpoints, verbose Logs oder zu permissive Suche
Mildern durch signierte Webhook‑Verifikation, Least‑Privilege‑Rollen und strikte Trennung zwischen Read‑ und Change‑Operationen.
Checks nach links verschieben mit CI und Berechtigungsreviews
Führt Security‑Checks in CI für euren Portal‑Code und die generierten Templates aus (Linting, Policy‑Checks, Dependency‑Scanning). Plant regelmäßige Reviews von:
- RBAC‑Rollen und Gruppenmappings
- Template‑Permissions (wer kann was erstellen)
- „Break‑glass“ Admin‑Zugriff und Rotationsverfahren
Governance ist nachhaltig, wenn sie routinemäßig, automatisiert und sichtbar ist — nicht ein Einmalprojekt.
Rollout, Adoption und langfristige Wartung
Ein Entwicklerportal bringt nur Wert, wenn Teams es tatsächlich nutzen. Behandelt Rollout wie einen Produkt‑Launch: klein starten, schnell lernen, dann anhand von Evidenz skalieren.
Mit einem fokussierten Pilot starten
Pilott mit 1–3 motivierten, repräsentativen Teams (ein „Greenfield“ Team, ein legacy‑schweres Team, eins mit strikteren Compliance‑Anforderungen). Beobachtet, wie sie reale Aufgaben erledigen — Service registrieren, Infrastruktur anfordern, Deploys triggern — und beseitigt Reibung sofort. Ziel ist nicht Feature‑Vollständigkeit, sondern zu beweisen, dass das Portal Zeit spart und Fehler reduziert.
Migration langweilig und vorhersehbar machen
Bietet Migrationsschritte, die in einen normalen Sprint passen. Beispiel:
- einen existierenden Service im Katalog registrieren,
- Ownership und On‑Call hinzufügen,
- CI/CD verbinden,
- für die nächste neue Komponente ein Template (Repo, Pipeline oder Infra) übernehmen.
Haltet „Day‑2“ Upgrades simpel: Teams schrittweise Metadaten hinzufügen und bespoke Scripts durch Portal‑Workflows ersetzen.
Docs und In‑Product‑Hilfe, die Leute lesen werden
Schreibt prägnante Docs für die wichtigen Workflows: „Service registrieren“, „Datenbank anfordern“, „Deploy zurückrollen“. Fügt In‑Product‑Hilfe neben Formularfeldern hinzu und verlinkt zu /docs/portal und /support für tieferen Kontext. Behandelt Docs wie Code: versioniert, reviewt und prune sie.
Ownership ist eine langfristige Verpflichtung
Plant fortlaufende Ownership von Anfang an: jemand muss das Backlog triagieren, Connectoren zu externen Tools pflegen und Nutzer supporten, wenn Automationen fehlschlagen. Definiert SLAs für Portal‑Incidents, legt eine regelmäßige Cadence für Connector‑Updates fest und reviewt Audit‑Logs, um wiederkehrende Schmerzen und Policy‑Lücken zu erkennen.
Mit zunehmender Reife wollt ihr Funktionen wie Snapshots/Rollback für Portal‑Konfiguration, vorhersehbare Deployments und einfache Environment‑Promotion über Regionen hinweg. Wenn ihr schnell baut oder experimentiert, kann Koder.ai Teams helfen, interne Apps mit Planungsmodus, Deployment/Hosting und Code‑Export aufzusetzen — nützlich, um Portal‑Features zu pilotieren, bevor sie in langfristige Platform‑Komponenten überführt werden.