Definieren, was „Impact" bedeutet und welche Entscheidungen es steuern soll
Bevor Sie Berechnungen oder Dashboards bauen, legen Sie fest, was „Impact" in Ihrer Organisation tatsächlich bedeutet. Wenn Sie diesen Schritt überspringen, erhalten Sie am Ende eine Punktzahl, die wissenschaftlich aussieht, aber niemandem hilft zu handeln.
Was als „Impact" zählt (und was nicht)
Impact ist die messbare Folge eines Incidents auf etwas, das dem Business wichtig ist. Übliche Dimensionen sind:
- Nutzer: Anzahl der Nutzer, die sich nicht einloggen können, Fehler-Raten-Spikes in wichtigen Flows, degradierte Latenz in einer Region.
- Umsatz: fehlgeschlagene Checkouts, blockierte Verlängerungen, sinkende Ad-Impressions.
- SLA/SLO-Risiko: Ausfallminuten gegenüber einem Uptime-Ziel, Verbrauch des Error-Budgets.
- Interne Teams: Support-Ticket-Volumen, Belastung der Bereitschaft, blockierte Deploys.
Wählen Sie 2–4 primäre Dimensionen und definieren Sie sie explizit. Zum Beispiel: „Impact = betroffene zahlende Kunden + SLA-Minuten im Risiko", nicht „Impact = alles, was in Graphen schlecht aussieht."
Wer die App nutzt und was sie in den ersten 10 Minuten brauchen
Verschiedene Rollen treffen unterschiedliche Entscheidungen:
- Incident Commander braucht eine schnelle, verteidigungsfähige Zusammenfassung: was ist kaputt, wer ist betroffen und wie entwickelt es sich.
- Support benötigt customer-fokussierten Scope: welche Accounts, Regionen oder Pläne sind betroffen.
- Engineering braucht eine Blast-Radius-Hypothese, die Debugging und Mitigation leitet.
- Führungskräfte brauchen eine prägnante Business-Aussage: Schweregrad, Kundenimpact und ETA-Vertrauen.
Gestalten Sie „Impact"-Outputs so, dass jede Zielgruppe ihre wichtigste Frage ohne Metrik-Übersetzung beantworten kann.
Echtzeit vs. Near-Real-Time: Erwartungen früh setzen
Entscheiden Sie, welche Latenz akzeptabel ist. „Echtzeit" ist teuer und oft unnötig; Near-Real-Time (z. B. 1–5 Minuten) reicht häufig für Entscheidungsfindung.
Formulieren Sie dies als Produkt-Anforderung, weil es Ingestion, Caching und UI beeinflusst.
Entscheidungen, die die App während eines Incidents ermöglichen sollte
Ihr MVP sollte direkt Aktionen unterstützen wie:
- Schweregrad und Eskalationslevel deklarieren
- Kundenkommunikation auslösen (Statusseite, Support-Makros)
- Mitigation priorisieren (welcher Service/ welches Team zuerst)
- Über Rollbacks, Feature-Flags oder Traffic-Shifts entscheiden
- Identifizieren, welche Kunden proaktiv kontaktiert werden müssen
Wenn eine Metrik keine Entscheidung beeinflusst, ist sie wahrscheinlich nicht „Impact" — sie ist nur Telemetrie.
Bevor Sie Bildschirme entwerfen oder eine Datenbank wählen, notieren Sie, welche Fragen die „Impact-Analyse" während eines echten Incidents beantworten muss. Das Ziel ist nicht perfekte Präzision am ersten Tag — sondern konsistente, erklärbare Ergebnisse, denen Responders vertrauen können.
Erforderliche Eingaben (das Minimum)
Starten Sie mit den Daten, die Sie mindestens ingestieren oder referenzieren müssen, um Impact zu berechnen:
- Incidents: ID, Start/End-Zeiten, Status, verantwortliches Team, Zusammenfassung, Links zum Incident-Channel/Ticket.
- Services: kanonische Service-Liste (Name, Owner, Tier/Kritikalität, Runbook-Link).
- Dependencies: welche Services von welchen anderen abhängen (selbst wenn die erste Version grob ist).
- Telemetry-Signale: Alerts, SLO-Burn-Rates, Fehlerquote/Latenz, Deployment-Events — alles, was auf Degradation hinweist.
- Kunden-Accounts: Account-IDs, Plan/SLA, Region, wichtige Kontakte, plus wie Accounts auf Services abgebildet sind (direkt oder via Workloads).
Optional zum Launch (planen, aber nicht voraussetzen)
Die meisten Teams haben am ersten Tag keine perfekten Dependency- oder Kunden-Mappings. Entscheiden Sie, was Menschen manuell eingeben dürfen, damit die App trotzdem nützlich ist:
- Manuelle Auswahl betroffener Services/Kunden, wenn Daten fehlen
- Geschätzte Startzeit oder Scope, wenn Telemetrie verzögert ist
- Overrides mit Gründen (z. B. „false positive alert", „nur intern betroffen")
Gestalten Sie diese als explizite Felder (nicht als ad-hoc-Notizen), damit sie später abfragbar sind.
Schlüsselausgaben (was die App liefern muss)
Ihre erste Version sollte zuverlässig erzeugen:
- Betroffene Services und ein klares „Warum" (Signale + Dependencies)
- Kundenliste mit Zählungen nach Plan/Region und einer Ansicht der „Top Accounts"
- Severity/Impact-Score, der in Klartext erklärbar ist
- Timeline: wann der Impact wahrscheinlich begann, seinen Höhepunkt hatte und sich erholte
- Optional aber wertvoll: eine Kostenschätzung (SLA-Gutschriften, Support-Last, Umsatzrisiko) mit Konfidenzbereichen
Nicht-funktionale Constraints (was Vertrauen schafft)
Impact-Analyse ist ein Entscheidungstool, daher sind Constraints wichtig:
- Latenz: Dashboards sollten während eines Incidents in Sekunden laden
- Verfügbarkeit: Behandeln Sie es wie internes kritisches Tooling; definieren Sie ein Availability-Ziel
- Auditability: protokollieren Sie, wer ein Override wann gemacht hat und wie der vorherige Wert war
- Zugriffssteuerung: beschränken Sie sensible Kundendaten; trennen Sie Lese- und Schreibrechte
Formulieren Sie diese Anforderungen als testbare Aussagen. Wenn Sie es nicht verifizieren können, können Sie sich während eines Ausfalls nicht auf die App verlassen.
Datenmodell: Incidents, Services, Dependencies und Kunden
Ihr Datenmodell ist der Vertrag zwischen Ingestion, Berechnung und UI. Wenn Sie es richtig machen, können Sie Tooling-Quellen austauschen, Scoring verfeinern und trotzdem dieselben Fragen beantworten: „Was ist kaputt?", „Wer ist betroffen?" und „Wie lange?"
Kern-Entitäten (klein und verlinkbar halten)
Mindestens modellieren Sie diese als First-Class-Records:
- Incident: der narrative Container (Titel, Schweregrad, Status, Owner), plus Verweise auf Belege.
- Service: die Einheit, für die Sie Dependencies abbilden (API, Datenbank, Queue, Drittanbieter).
- Dependency: eine gerichtete Kante Service A → Service B mit Metadaten (Typ, Kritikalität).
- Signal: eine zeitgestempelte Beobachtung (Alert, SLO-Burn, Error-Spike, Synthetic-Check-Failure).
- Kunde: ein Account oder eine Organisation, die Services konsumiert.
- Subscription/SLA: was ein Kunde beanspruchen darf (Plan, SLA/SLO-Ziele, Reporting-Regeln).
Halten Sie IDs stabil und konsistent across Quellen. Wenn Sie bereits einen Service-Katalog haben, behandeln Sie ihn als Quelle der Wahrheit und mappen externe Tool-IDs darauf.
Zeitmodellierung (Impact ist ein Zeitfenster-Problem)
Speichern Sie mehrere Zeitstempel am Incident, um Reporting und Analyse zu unterstützen:
- start_time / end_time: tatsächliches Impact-Fenster (kann später verfeinert werden)
- detection_time: wann Sie es zuerst wussten
- mitigation_time: wann Fixes begonnen haben, Impact zu reduzieren
Speichern Sie außerdem berechnete Time-Windows für Impact-Scoring (z. B. 5-Minuten-Buckets). Das erleichtert Replay und Vergleiche.
Beziehungen, die „wer ist betroffen?“ antreiben
Modellieren Sie zwei Schlüssel-Graphen:
- Service-zu-Service-Dependencies (Blast Radius)
- Kunde-zu-Service-Nutzung (betroffener Scope)
Ein einfaches Pattern ist customer_service_usage(customer_id, service_id, weight, last_seen_at), damit Sie Impact nach „wie stark der Kunde darauf angewiesen ist" ranken können.
Versionierung und Historie (Dependencies ändern sich)
Dependencies entwickeln sich, und Impact-Berechnungen sollten widerspiegeln, was zum Zeitpunkt wahr war. Fügen Sie daher Effektiv-Daten zu Kanten hinzu:
dependency(valid_from, valid_to)
Dasselbe gilt für Kunden-Subscriptions und Nutzungs-Snapshots. Mit historischen Versionen können Sie vergangene Incidents akkurat nachberechnen und konsistente SLA-Reports erstellen.
Ihre Impact-Analyse ist nur so gut wie die eingespeisten Inputs. Das Ziel: Signale aus den Tools, die Sie bereits nutzen, streamen und in einen konsistenten Event-Stream konvertieren, den Ihre App verarbeiten kann.
Was zu ingestieren ist (und warum)
Starten Sie mit einer kurzen Liste von Quellen, die verlässlich „etwas hat sich geändert" während eines Incidents beschreiben:
- Monitoring-Alerts (PagerDuty, Opsgenie, CloudWatch-Alarme): schnelle Indikatoren für Symptome und Schwere
- Logs und Traces (ELK, Datadog, OpenTelemetry-Backends): Belege des Scopes (welche Endpoints, welche Kunden)
- Status-Page-Updates (Statuspage, Cachet): die offizielle Narrative und kundenrelevante Zeitstempel
- Ticketing/Incident-Tools (Jira, ServiceNow): Ownership, Zeitstempel und Post-Incident-Daten
Versuchen Sie nicht, alles auf einmal zu ingestieren. Wählen Sie Quellen, die Detection, Eskalation und Bestätigung abdecken.
Ingest-Methoden
Verschiedene Tools unterstützen unterschiedliche Integrationsmuster:
- Webhooks für Near-Real-Time-Updates (ideal für Alerts und Status-Seiten)
- Polling für APIs ohne Webhooks (mit Backoff und Rate-Limits)
- Batch-Imports für historische Backfills (nützlich für initiale Validierung)
- Manuelle Eingabe für „Last-Mile“-Korrekturen (Analysten können fehlende Service-Tags ergänzen)
Ein pragmatischer Ansatz: Webhooks für kritische Signale plus Batch-Imports, um Lücken zu schließen.
In ein gemeinsames Schema normalisieren
Normalisieren Sie jeden eingehenden Eintrag in eine einzige „Event"-Form, auch wenn die Quelle es Alert, Incident oder Annotation nennt. Mindestens standardisieren:
- Zeitstempel: occurred_at, detected_at, resolved_at (wenn verfügbar)
- Service-IDs: mappen Sie Quell-Tags/Namen auf Ihre kanonischen Service-IDs
- Schwere/Prio: konvertieren Sie toolspezifische Levels in Ihre Skala
- Quelle und Roh-Payload: behalten Sie das originale JSON für Audit und Debug
Datenhygiene: Duplikate, Ordering, fehlende Felder
Erwarten Sie unordentliche Daten. Nutzen Sie Idempotency-Keys (source + external_id) zur Dedublikation, tolerieren Sie Out-of-Order-Events durch Sortierung nach occurred_at (nicht Ankunftszeit) und wenden Sie sichere Defaults an, wenn Felder fehlen (und markieren Sie sie zur Überprüfung).
Eine kleine „unmatched service" Queue in der UI verhindert stille Fehler und hält Ihre Impact-Ergebnisse vertrauenswürdig.
Mapping von Service-Dependencies für akkuraten Blast Radius
Ohne Risiko experimentieren
Iteriere sicher an Regeln mit Snapshots und Rollback, falls eine Änderung Probleme macht.
Wenn Ihr Dependency-Map falsch ist, ist auch Ihr Blast Radius falsch — selbst wenn Signale und Scoring perfekt sind. Ziel ist ein Dependency-Graph, dem man während eines Incidents und danach vertrauen kann.
Mit einem Service-Katalog starten (Quelle der Wahrheit)
Bevor Sie Kanten abbilden, definieren Sie die Knoten. Erstellen Sie für jedes System, das in einem Incident referenziert werden könnte, einen Service-Katalog-Eintrag: APIs, Background-Worker, Datenspeicher, Drittanbieter und andere geteilte kritische Komponenten.
Jeder Service sollte mindestens enthalten: Owner/Team, Tier/Kritikalität (z. B. customer-facing vs. internal), SLA/SLO-Ziele und Links zu Runbooks und On-Call-Dokumenten (z. B. /runbooks/payments-timeouts).
Dependencies erfassen: statisch vs. gelernt
Nutzen Sie zwei komplementäre Quellen:
- Statische (deklarierte) Dependencies: was Teams sagen, worauf sie angewiesen sind (aus IaC, Config, Service-Manifests, ADRs). Stabil und einfach zu auditieren.
- Gelernte (beobachtete) Dependencies: was Ihre Systeme tatsächlich aufrufen (aus Traces, Service-Mesh-Telemetrie, API-Gateway-Logs, Egress-Proxys, DB-Audit-Logs). Diese fangen „unknown unknowns“ ein.
Behandeln Sie diese als verschiedene Kantentypen, damit Nutzer Vertrauen/Confidence sehen: „vom Team deklariert" vs. „in den letzten 7 Tagen beobachtet".
Richtung und Kritikalität sind wichtig
Dependencies sollten gerichtet sein: Checkout → Payments ist nicht gleich Payments → Checkout. Richtung bestimmt die Logik („wenn Payments degradiert ist, welche Upstreams könnten betroffen sein?").
Modellieren Sie außerdem harte vs. weiche Abhängigkeiten:
- Hart: Ausfall blockiert Kernfunktionalität (z. B. Auth-Service für Login).
- Weich: Degradation reduziert Qualität, es gibt Fallbacks (z. B. Empfehlungen).
Diese Unterscheidung verhindert Überschätzung des Impacts und hilft bei Priorisierung.
Graph schnappen für Replay und Post-Incident-Analyse
Ihre Architektur ändert sich regelmäßig. Wenn Sie keine Snapshots speichern, können Sie einen Incident von vor zwei Monaten nicht korrekt analysieren.
Persistieren Sie Dependency-Graph-Versionen über die Zeit (täglich, pro Deploy oder bei Änderung). Beim Berechnen des Blast Radius lösen Sie den Incident-Zeitstempel auf das nächste Graph-Snapshot auf, sodass „wer betroffen war" die Realität zum Zeitpunkt widerspiegelt — nicht die heutige Architektur.
Impact-Berechnung: Von Signalen zu Scores und betroffenem Scope
Sobald Sie Signale (Alerts, SLO-Burn, Synthetics, Kunden-Tickets) ingestieren, braucht die App eine konsistente Art, chaotische Inputs in eine klare Aussage zu übersetzen: was ist kaputt, wie schlimm ist es und wer ist betroffen?
Eine Scoring-Methode wählen (einfach anfangen)
Sie können ein brauchbares MVP mit einem der folgenden Muster erreichen:
- Regelbasiertes Scoring: „Wenn Checkout-Fehlerquote \u003e 5% für 10 Minuten, Impact = Hoch." Einfach zu erklären und zu debuggen.
- Gewichtete Formel: Normierte Metriken zu einem Score (z. B. 0–100) kombinieren. Nützlich bei vielen Signalen für einen glatten Verlauf.
- Tier-basiertes Mapping: Systeme in Business-Tiers (Tier 0–3) abbilden und Schwere je nach Tier begrenzen oder verstärken. Hält Ergebnisse an Geschäftsprioritäten ausgerichtet.
Egal welche Methode Sie wählen: speichern Sie Zwischenwerte (Thresholds, Gewichte, Tier), damit Nutzer nachvollziehen können, warum ein Score zustande kam.
Impact-Dimensionen definieren
Vermeiden Sie, alles zu früh in eine Zahl zu pressen. Verfolgen Sie einige Dimensionen separat und leiten Sie dann eine Gesamtschwere ab:
- Availability: Downtime, fehlgeschlagene Requests, unerreichbare Endpunkte
- Latency: p95/p99-Verschlechterung gegenüber Baseline oder SLO
- Errors: Error-Rate-Spikes, fehlgeschlagene Jobs, Timeouts
- Datenkorrektheit: fehlende/falsche Datensätze, verzögerte Verarbeitung
- Security-Risiko: verdächtige Zugriffs-Muster, Indikatoren für Datenexposition
Das hilft bei präziser Kommunikation (z. B. „verfügbar aber langsam" vs. „falsche Ergebnisse").
Betroffenen Umfang berechnen (Kunden/Nutzer)
Impact ist nicht nur Service-Gesundheit — es ist, wer es gespürt hat.
Nutzen Sie Nutzungs-Mappings (Tenant → Service, Kundenplan → Features, User-Traffic → Endpoint) und berechnen Sie betroffene Kunden innerhalb eines Zeitfensters, das zum Incident passt (Startzeit, Mitigation-Zeit und eventuelle Backfill-Perioden).
Seien Sie explizit zu Annahmen: Sampling in Logs, geschätzter Traffic oder partielle Telemetrie.
Manuelle Anpassungen — mit Verantwortlichkeit
Operatoren werden überschreiben müssen: false-positives, partielle Rollouts, bekannte Kundensegmente.
Erlauben Sie manuelle Änderungen an Schwere, Dimensionen und betroffenen Kunden, aber fordern Sie:
- Wer hat was geändert
- Wann
- Warum (kurzer Grund + optionaler Link zu Ticket/Runbook)
Diese Audit-Spur schützt das Vertrauen im Dashboard und beschleunigt Post-Incident-Reviews.
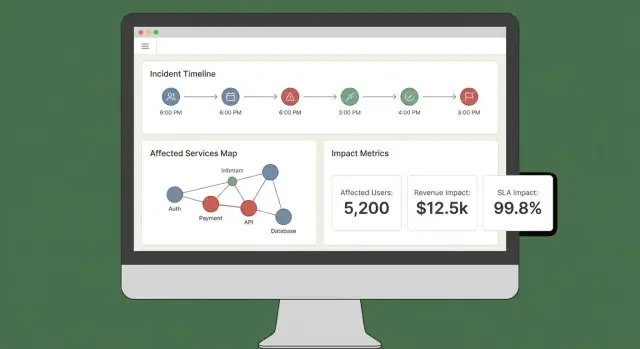
UX und Dashboards: Impact in Minuten verständlich machen
Ein gutes Impact-Dashboard beantwortet drei Fragen schnell: Was ist betroffen? Wer ist betroffen? Wie sicher sind wir? Wenn Nutzer fünf Tabs öffnen müssen, um das zusammenzupuzzeln, vertrauen sie dem Ergebnis nicht — und handeln nicht.
Kern-Views fürs MVP
Starten Sie mit wenigen „always-there" Views, die reale Incident-Workflows abbilden:
- Incident-Übersicht: Status, Startzeit, aktueller Impact-Score, Top betroffene Services/Kunden und die jüngsten Belege.
- Betroffene Services: ein geranktes Listing mit Schwere, Region und Dependency-Pfad (damit Engineers Interventionen erkennen).
- Betroffene Kunden: Zählungen und benannte Accounts nach Tier/Plan, plus geschätzter Nutzer-Impact wenn vorhanden.
- Timeline: ein chronologischer Stream mit Detections, Deploys, Alerts, Mitigations und Impact-Änderungen.
- Actions: vorgeschlagene nächste Schritte, Verantwortliche und Links zu Playbooks oder Tickets.
Das „Warum" sichtbar machen
Impact-Scores ohne Erklärung wirken willkürlich. Jeder Score sollte auf Inputs und Regeln zurückführbar sein:
- Zeigen Sie welche Signale beitrugen (Errors, Latenz, Health-Checks, Support-Volumen) und deren aktuelle Werte.
- Stellen Sie Regeln und Thresholds dar (z. B. „latency p95 \u003e 2s für 10 min = degraded").
- Fügen Sie einen leichten Konfidenz-Indikator hinzu (z. B. „Hohe Konfidenz: bestätigt durch 3 Quellen").
Ein einfaches „Explain impact"-Drawer kann das leisten, ohne das Haupt-View zu überfrachten.
Filter und Drilldowns, die echten Fragen entsprechen
Ermöglichen Sie schnelles Slicen nach Service, Region, Kundentier und Zeitraum. Lassen Sie Nutzer auf beliebige Diagrammpunkte oder Zeilen klicken, um die Roh-Belege zu sehen (exakte Monitore, Logs oder Events, die die Änderung ausgelöst haben).
Teilen und Exporte
Während eines aktiven Incidents brauchen Teams transportable Updates. Bauen Sie ein:
- Teilbare Links zur Incident-Ansicht (mit Berechtigungsprüfung)
- CSV-Export für Service-/Kundenlisten
- PDF-Export für Status-Updates und Post-Incident-Summaries
Wenn Sie bereits eine Statusseite haben, verlinken Sie sie über eine relative Route wie /status, damit Kommunikationsteams schnell cross-referencen können.
Sicherheit, Berechtigungen und Audit-Logging
Für das Team einsatzbereit machen
Stelle deine interne Impact-App schnell bereit, damit Einsatzkräfte sie in echten Incidents nutzen können.
Impact-Analyse ist nur nützlich, wenn Leute ihr vertrauen — das bedeutet, zu kontrollieren, wer was sehen kann, und eine klare Aufzeichnung von Änderungen zu haben.
Rollen und Berechtigungen (einfach starten)
Definieren Sie eine kleine Menge an Rollen, die zu Ihren Incident-Abläufen passen:
- Viewer: Lesezugriff auf Incident-Zusammenfassungen und High-Level-Impact
- Responder: kann Notizen hinzufügen, betroffene Services bestätigen und operationelle Felder aktualisieren
- Incident Commander: kann Impact-Overrides genehmigen, kundenaffine Status setzen und Incidents schließen
- Admin: verwaltet Integrationen, Rollenzuweisungen und Datenretention
Halten Sie Berechtigungen an Aktionen orientiert, nicht an Jobtiteln. Zum Beispiel ist „Kann Kunden-Impact-Report exportieren" eine Berechtigung, die Sie Commandern und einigen Admins geben können.
Sensible Kundendaten schützen
Impact-Analyse beinhaltet oft Kunden-IDs, Vertrags-Tiers und Kontaktinformationen. Wenden Sie Least Privilege standardmäßig an:
- Maskieren Sie sensitive Felder (z. B. nur die letzten 4 Zeichen einer Account-ID) außer bei explizitem Zugriff.
- Trennen Sie „wer ist betroffen" von „was ist kaputt". Viele Nutzer brauchen nur Service-Level-Impact, nicht Kundenlisten.
- Sichern Sie Exporte: Wasserzeichen in PDFs/CSVs, den anfordernden Nutzer angeben und Exporte auf genehmigte Rollen beschränken. Bevorzugen Sie kurzlebige, signierte Download-Links.
Audit-Logging, das „wer änderte was?" beantwortet
Loggen Sie Schlüsselaktionen mit genug Kontext, um Reviews zu unterstützen:
- Manuelle Änderungen an Impact-Inputs (betroffene Services/Kunden)
- Overrides des Impact-Scores (alter Wert, neuer Wert, Grund)
- Acknowledgements und Status-Transitions
- Report-Generierung und Exporte
Speichern Sie Audit-Logs append-only, mit Zeitstempel und Schauspieler-Identität. Machen Sie sie pro Incident durchsuchbar, damit sie in Post-Incident-Reviews nützlich sind.
Compliance-Bedürfnisse geplant, ohne zu viel zu versprechen
Dokumentieren Sie, was jetzt unterstützt wird — Aufbewahrungsfristen, Zugriffskontrollen, Verschlüsselung und Audit-Abdeckung — und was auf der Roadmap steht.
Eine kurze „Security & Audit"-Seite in Ihrer App (z. B. /security) hilft, Erwartungen zu setzen und reduziert ad-hoc-Fragen während kritischer Incidents.
Workflows und Notifications während eines aktiven Incidents
Impact-Analyse ist nur relevant, wenn sie zur nächsten Aktion führt. Ihre App sollte wie ein Co-Pilot für den Incident-Channel agieren: sie wandelt eingehende Signale in klare Updates um und stupst Leute an, wenn sich der Impact signifikant ändert.
Verbindung zu Chat- und Incident-Channels
Integrieren Sie zuerst die Plattform, in der Responders bereits arbeiten (häufig Slack, Microsoft Teams oder ein dediziertes Incident-Tool). Ziel ist nicht, den Channel zu ersetzen — sondern kontextbewusste Updates zu posten und ein gemeinsames Protokoll zu pflegen.
Ein praktisches Muster: Behandeln Sie den Incident-Channel als Input und Output:
- Input: Responders taggen die App (z. B. „/impact summarize", „/impact add affected customer Acme"), um Scope zu korrigieren oder zu ergänzen.
- Output: Die App postet prägnante, konsistente Updates (aktueller Impact-Score, betroffene Services/Kunden, Trend vs. letztem Update).
Wenn Sie schnell prototypen wollen, bauen Sie den Workflow end-to-end zuerst (Incident-View → Zusammenfassen → Benachrichtigen), bevor Sie das Scoring perfektionieren. Plattformen wie Koder.ai können hier helfen: Sie erlauben schnelles Iterieren an einer React-UI und einem Go/PostgreSQL-Backend durch einen chat-getriebenen Workflow und bieten Export des Quellcodes, sobald das Incident-Team die UX als passend ansieht.
Schwellenwert-basierte Benachrichtigungen (kein Rauschen)
Vermeiden Sie Alert-Spam, indem Sie Benachrichtigungen nur auslösen, wenn Impact explizite Schwellen überschreitet. Übliche Trigger:
- Scope: Anzahl betroffener Kunden springt (z. B. 10 → 100)
- Tier: ein Tier-1-Service wird betroffen
- Umsatz / SLA-Risiko: projizierte SLA-Verletzung oder hoher Vertragswert betroffen
- Blast-Radius-Expansion: neue abhängige Services werden part of the affected set
Wenn eine Schwelle überschritten wird, senden Sie eine Nachricht, die warum (was sich geändert hat), wer handeln sollte und was als Nächstes zu tun ist, erklärt.
Links zu Runbooks und Workflows
Jede Benachrichtigung sollte „Next-Step"-Links enthalten, damit Responders schnell handeln können:
- Runbooks: /blog/incident-runbook-template
- Eskalationspolicy: /pricing
- Service-Ownership-Seite: /services/payments
Halten Sie diese Links stabil und relativ, damit sie in verschiedenen Umgebungen funktionieren.
Stakeholder-Updates: intern und kundenorientiert
Erzeugen Sie zwei Zusammenfassungsformate aus denselben Daten:
- Internes Update: technische Details, vermutete Ursache, Mitigationsfortschritt, ETA-Vertrauen
- Kunden-Update: einfache Sprache, aktueller Nutzer-Impact, Workarounds, Zeitpunkt des nächsten Updates
Unterstützen Sie geplante Zusammenfassungen (z. B. alle 15–30 Minuten) und On-Demand-Generierung mit einem Freigabe-Schritt vor externem Versand.
Validierung: Tests, Replay und Genauigkeitschecks
Verbinde deine Signale
Entwirf Webhook- und Polling-Ingestion-Pfade und normalisiere Ereignisse in ein Schema.
Impact-Analyse ist nur nützlich, wenn Leute ihr während und nach Incidents vertrauen. Validierung sollte zwei Dinge beweisen: (1) das System liefert stabile, erklärbare Ergebnisse, und (2) diese Ergebnisse stimmen mit dem überein, was Ihre Organisation später als Fakt ansieht.
Teststrategie: Regeln und Pipelines
Starten Sie mit automatisierten Tests für die zwei fehleranfälligsten Bereiche: Scoring-Logik und Daten-Ingestion.
- Unit-Tests für Scoring-Regeln: Behandeln Sie jede Regel als Vertrag. Gegeben bestimmte Signale (Error-Rate, Latenz, Synthetic-Checks, Ticket-Volumen) sollte Ihr Test den erwarteten Impact-Score und betroffenen Scope asserten. Schließen Sie Boundary-Tests ein (knapp unter/über Thresholds), damit Metrik-Jitter Outcomes nicht unerwartet kippen.
- Integrationstests für Ingestion: Validieren Sie den kompletten Pfad von Webhook/Event-Input bis zu normalisierten Records und berechnetem Impact. Nutzen Sie aufgezeichnete Payloads aus Ihren Observability- und Incident-Tools, um Schema-Drift früh zu erkennen.
Halten Sie Test-Fixtures lesbar: Wenn jemand eine Regel ändert, sollte er verstehen, warum sich ein Score geändert hat.
Vergangene Incidents replayen
Ein Replay-Modus ist ein schneller Weg zu Vertrauen. Lassen Sie historische Incidents durch die App laufen und vergleichen Sie, was das System „in dem Moment" gezeigt hätte mit dem, was Responders später herausfanden.
Praktische Tipps:
- Rekonstruieren Sie Timelines mit Event-Timestamps (nicht Ingest-Zeit), um die Realität widerzuspiegeln.
- Frieren Sie Dependency-Graphs zum Incident-Datum ein, wenn Ihr Service-Katalog sich geändert hat.
- Speichern Sie Replay-Ergebnisse, damit Sie Versionen nach Regelanpassungen vergleichen können.
Edge-Cases, die naive Scoring-Modelle brechen
Echte Incidents sind selten saubere Ausfälle. Ihre Validierungs-Suite sollte Szenarien abdecken wie:
- Partielle Ausfälle (einige Endpoints oder Kundensegmente betroffen)
- Degradierte Performance (langsam aber nicht fehlerhaft), wo Geschäftsauswirkung trotzdem hoch sein kann
- Multi-Region-Failures, bei denen derselbe Service pro Region unterschiedliche Gesundheit aufweist
Prüfen Sie für jedes Szenario nicht nur den Score, sondern auch die Erklärung: welche Signale und welche Dependencies/Kunden das Ergebnis getrieben haben.
Genauigkeit gegen Post-Incident-Findings messen
Definieren Sie Genauigkeit operational und verfolgen Sie sie.
Vergleichen Sie berechneten Impact mit Post-Incident-Review-Ergebnissen: betroffene Services, Dauer, Kundenanzahl, SLA-Verletzung und Schweregrad. Loggen Sie Abweichungen als Validierungs-Items mit Kategorie (fehlende Daten, falsche Dependency, falscher Threshold, verzögertes Signal).
Im Laufe der Zeit ist das Ziel nicht Perfektion — sondern weniger Überraschungen und schnellere Einigung während Incidents.
Deployment, Skalierung und Iterieren nach dem MVP
Ein MVP für Incident-Impact-Analyse zu liefern bedeutet vor allem Zuverlässigkeit und Feedback-Loops. Ihre erste Deployment-Wahl sollte Geschwindigkeit der Veränderung optimieren, nicht hypothetische zukünftige Skalierung.
Deployment-Stil, den Sie weiterentwickeln können
Starten Sie mit einem modularen Monolithen, es sei denn, Sie haben schon ein starkes Plattform-Team und klare Service-Grenzen. Eine Deploy-Unit vereinfacht Migrationen, Debugging und End-to-End-Tests.
Teilen Sie erst auf, wenn echte Schmerzen auftreten:
- die Ingestion-Pipeline braucht unabhängiges Skalieren
- mehrere Teams müssen unabhängig deployen
- Fehlerdomänen sind in einer App schwer zu durchschauen
Eine pragmatische Mitte: eine App + Background-Worker (Queues) + bei Bedarf ein separates Ingestion-Edge.
Wenn Sie schnell vorankommen wollen, ohne sich an eine große Individual-Plattform zu binden, kann Koder.ai das MVP beschleunigen: Der chat-getriebene „vibe-coding"-Workflow eignet sich gut für eine React-UI, ein Go-API und ein PostgreSQL-Datenmodell, mit Snapshots/Rollback beim Iterieren von Scoring-Regeln und Workflows.
Storage basierend auf Zugriffsmustern wählen
Nutzen Sie relationale Speicherung (Postgres/MySQL) für Kern-Entitäten: Incidents, Services, Kunden, Ownership und berechnete Impact-Snapshots. Leicht abfragbar, auditierbar und evolvierbar.
Für hochvolumige Signale (Metriken, logs-derived events) fügen Sie eine Time-Series-Store (oder columnar store) hinzu, wenn Rohdaten-Retention und Rollups in SQL teuer werden.
Erwägen Sie eine Graph-DB nur, wenn Dependency-Queries zum Flaschenhals werden oder Ihr Dependency-Modell sehr dynamisch ist. Viele Teams kommen mit Adjazenz-Tabellen plus Caching weit.
Observability für die App selbst
Ihre Impact-Analyse-App wird Teil der Incident-Toolchain — instrumentieren Sie sie wie Produktivsoftware:
- Error-Rate und langsame Endpoints (besonders „recalculate impact")
- Worker-Queue-Depth/Lag und Retry-Raten
- Ingestion-Durchsatz und Failure-Counts pro Quelle
- Datenfrische (Zeit seit letztem erfolgreichen Pull/Push)
- Berechnungsdauer und Cache-Hit-Rate
Stellen Sie eine „Health + Freshness"-Ansicht in der UI bereit, damit Responders Zahlen vertrauen (oder anzweifeln) können.
Iterationen und Refactors geplant angehen
Definieren Sie MVP-Scope eng: kleine Tool-Menge zur Ingestion, klarer Impact-Score und ein Dashboard, das beantwortet „wer ist betroffen und wie sehr". Dann iterieren Sie:
- Nächste Features: bessere Dependency-Genauigkeit, kunden-spezifische Gewichtung, SLA-Reporting-Exporte, Replay für vergangene Incidents
- Refactor-Trigger: Sie fügen wöchentlich Spezialfälle hinzu, Neuberechnung ist zu langsam oder das Datenmodell kann Realität nur mit Hacks abbilden
Behandeln Sie das Modell als Produkt: versionieren Sie es, migrieren Sie sicher und dokumentieren Sie Änderungen für Post-Incident-Reviews.