Web‑App erstellen zur Verwaltung von Berechtigungen interner Tools
Schritt‑für‑Schritt‑Anleitung zum Entwerfen und Erstellen einer Web‑App zur Verwaltung von internen Tool‑Zugriffen mit Rollen, Genehmigungen, Audit‑Logs und sicheren Abläufen.
Problem und Umfang definieren
Bevor Sie RBAC‑Rollen und Berechtigungen wählen oder Bildschirme entwerfen, klären Sie konkret, was „Berechtigungen für interne Tools“ in Ihrer Organisation bedeutet. Für einige Teams ist es ein einfaches „wer darf welche App nutzen“; für andere umfasst es fein granulare Aktionen innerhalb jedes Tools, temporäre Erhöhungen und Nachweis für Audits.
Was zählt als Berechtigung?
Schreiben Sie die genauen Aktionen auf, die Sie kontrollieren müssen, und verwenden Sie Verben, die zur Arbeitsweise der Leute passen:
- View (Read‑Only-Zugriff auf Dashboards, Tickets, Kundendaten)
- Edit (Konfigurationen ändern, Daten aktualisieren, Anfragen schließen)
- Admin (Benutzer verwalten, Abrechnung ändern, Sicherheitseinstellungen anpassen)
- Export (Berichte herunterladen, Kundendaten ziehen, API‑Zugriff)
Diese Liste wird zur Grundlage Ihrer Access‑Management‑Web‑App: sie bestimmt, was Sie speichern, was Sie genehmigen und was Sie auditieren.
Inventarisieren Sie Tools und wo durchgesetzt wird
Erstellen Sie ein Inventar interner Systeme und Tools: SaaS‑Apps, interne Admin‑Panels, Data‑Warehouses, geteilte Ordner, CI/CD und alle „Shadow‑Admin“-Tabellen. Notieren Sie für jedes, ob Berechtigungen durchgesetzt werden:
- Inside the tool (native Rollen)
- At your gateway (Reverse Proxy, API‑Layer)
- By process (manuelle Schritte, geteilte Credentials)
Wenn die Durchsetzung „by process“ ist, ist das ein Risiko, das Sie entweder beseitigen oder ausdrücklich akzeptieren sollten.
Stakeholder und Erfolgskennzahlen
Identifizieren Sie Entscheidungsträger und Betreiber: IT, Security/Compliance, Team Leads und Endbenutzer, die Zugriff anfragen. Stimmen Sie messbare Erfolgskennzahlen ab:
- Medianzeit bis zur Gewährung von Zugriff
- Anzahl berechtigungsbezogener Vorfälle
- Anteil des Zugriffs mit Owner und geschäftlicher Begründung
- Audit‑Bereitschaft (können Sie beantworten: „Wer hatte wann warum Zugriff auf was?“)
Den Umfang richtig zu setzen verhindert, dass Sie ein System bauen, das entweder zu komplex zu betreiben oder zu simpel ist, um Least Privilege zu gewährleisten.
Wählen Sie Ihr Autorisierungsmodell (Rollen, Policies, Ausnahmen)
Ihr Autorisierungsmodell ist die „Form“ Ihres Berechtigungssystems. Wenn Sie es früh richtig machen, bleiben UI, Genehmigungen, Audits und Durchsetzung deutlich einfacher.
Beginnen Sie mit dem einfachsten Modell, das die Realität aushält
Für die meisten internen Tools reicht role‑based access control (RBAC) als Startpunkt:
- Einfache Rollen: Benutzer erhalten eine oder mehrere Rollen (z. B. Viewer, Operator, Admin).
- Rolle + Overrides: Rollen decken 90 % ab; für Specials gibt es explizite Grants/Deny pro Benutzer.
- Attribute‑basierte Regeln (ABAC): Berechtigungen hängen von Attributen wie Abteilung, Standort, Datenklassifizierung oder Umgebung ab.
RBAC ist am leichtesten zu erklären und zu prüfen. Fügen Sie Overrides nur hinzu, wenn häufig „Special Case“-Anfragen auftreten. Wechseln Sie zu ABAC, wenn konsistente Regeln sonst Ihre Rollenzahl explodieren lassen (z. B. „Tool X nur für ihre Region zugänglich“).
Machen Sie Least Privilege zur Standardeinstellung
Entwerfen Sie Rollen so, dass die Voreinstellung minimal ist und Privilegien explizit vergeben werden:
- Beginnen Sie mit „kein Zugriff“ oder „nur lesen“
- Trennen Sie „ansehen“ von „ändern“ (und „genehmigen“ von „anfordern“)
- Vermeiden Sie pauschale „Admin“-Rollen; machen Sie hochwirksame Aktionen sichtbar
Entscheiden Sie, was global vs. toolspezifisch ist
Definieren Sie Berechtigungen auf zwei Ebenen:
- Globale Berechtigungen: organisationsweite Fähigkeiten wie „Benutzer verwalten“, „Audit‑Logs ansehen“ oder „Zugriff genehmigen“
- Tool‑spezifische Berechtigungen: Aktionen innerhalb jedes Tools (z. B. deploy, configs bearbeiten, Secrets ansehen)
So verhindern Sie, dass die Anforderungen eines Tools jede andere Anwendung zwingen, dieselbe Rollenstruktur zu übernehmen.
Planen Sie Ausnahmen, ohne Ihr Modell zu sprengen
Ausnahmen sind unvermeidlich; machen Sie sie explizit:
- Temporärer Zugriff: zeitbegrenzte Grants, die automatisch auslaufen
- Break‑glass Admin: ein Notfall‑Rolle mit zusätzlichen Schutzmaßnahmen (begrenzte Dauer, zwingender Grund, erhöhte Protokollierung)
Wenn Ausnahmen zur Regel werden, ist das ein Signal, Rollen anzupassen oder Policy‑Regeln einzuführen — ohne dass „One‑Offs“ dauerhaft und ungeprüft Privilegien erzeugen.
Entwerfen Sie das Datenmodell
Eine Berechtigungs‑App lebt und stirbt mit ihrem Datenmodell. Wenn Sie nicht schnell und konsistent beantworten können „Wer hat Zugriff auf was und warum?“, werden Funktionen wie Genehmigungen, Audits und UI brüchig.
Kern‑Entitäten (explizit halten)
Fangen Sie mit einer kleinen Menge an Tabellen/Collections an, die klar realweltliche Konzepte abbilden:
- Users (Personen, die Zugriff brauchen)
- Teams (Gruppen, für die Sie Zugriff verwalten)
- Tools/Apps (Worauf Zugriff gewährt wird)
- Roles (benannte Bündel wie „Billing Admin“)
- Permissions (fein granulare Fähigkeiten wie
export_invoices) - Assignments (die Tatsache, dass ein User/Team eine Rolle für ein bestimmtes Tool hat)
Rollen sollten nicht global „herumschwimmen“ ohne Kontext. In den meisten internen Umgebungen ist eine Rolle nur innerhalb eines Tools sinnvoll (z. B. „Admin“ in Jira vs. „Admin“ in AWS).
Beziehungen und Vererbungsregeln
Erwarten Sie Many‑to‑Many‑Beziehungen:
- Ein User kann vielen Teams angehören; ein Team hat viele Benutzer.
- Eine Role enthält viele Permissions; eine Permission kann in vielen Rollen liegen.
- Eine Assignment verknüpft typischerweise: (Subject = User oder Team) → (Role) → (Tool/App).
Wenn Sie teambasierte Vererbung unterstützen, legen Sie die Regeln vorher fest: Effective Access = direkte Benutzer‑Zuweisungen plus Team‑Zuweisungen mit klarem Konfliktverhalten (z. B. „deny schlägt allow“ falls Sie Deny modellieren).
Lifecycle‑Felder, die Audits erleichtern
Fügen Sie Felder hinzu, die Änderungen über Zeit erklären:
created_by(wer hat es vergeben)expires_at(temporärer Zugriff)disabled_at(soft‑Disable ohne Historie zu verlieren)
Diese Felder helfen zu beantworten: „War dieser Zugriff letzten Dienstag gültig?“ — kritisch für Untersuchungen und Compliance.
Indexierung für schnelle Permission‑Checks
Die häufigste Abfrage ist meist: „Hat User X Permission Y in Tool Z?“ Indexieren Sie Assignments nach (user_id, tool_id) und berechnen Sie „effective permissions“ vor, wenn Checks sofort erfolgen müssen. Halten Sie Write‑Pfade einfach, optimieren Sie aber Read‑Pfade, wo Durchsetzung darauf angewiesen ist.
Authentifizierung und SSO‑Integration
Authentifizierung ist, wie sich Menschen identifizieren. Für eine interne Berechtigungs‑App ist das Ziel, das Anmelden für Mitarbeitende einfach zu machen und Admin‑Aktionen stark zu schützen.
Wählen Sie Ihre Login‑Methode
Üblicherweise haben Sie drei Optionen:
- SSO (empfohlen für die meisten Firmen): Mitarbeitende melden sich mit ihrer Unternehmensidentität an (Google Workspace, Microsoft Entra ID/ADFS, Okta, Ping).
- Email Magic Link (passwordless): Nutzer geben ihre E‑Mail ein und erhalten einen zeitlich begrenzten Link. Einfach, aber schwächer, wenn Postfach‑Sicherheit stark variiert.
- Passwörter: normalerweise letzte Wahl, weil Passwort‑Reset und Richtlinienaufwand entstehen.
Wenn Sie mehrere Methoden unterstützen, wählen Sie eine als Default und machen andere explizite Ausnahmen — sonst wird’s für Admins schwer, vorherzusagen, wie Konten entstehen.
Integration mit SAML oder OIDC (SSO)
Die meisten modernen Integrationen nutzen OIDC; viele Unternehmen benötigen weiterhin SAML.
- OIDC: Sie validieren ein ID‑Token, mappen einen stabilen User‑Identifier (subject/issuer) und lesen optional Gruppen/Role‑Claims.
- SAML: Sie validieren signierte Assertions, mappen NameID (oder ein dediziertes Attribut) und behandeln Metadaten/Zertifikatsrotation.
Unabhängig vom Protokoll entscheiden Sie, was Sie dem IdP vertrauen:
- Identity only (wer der User ist), während Ihre App die Berechtigungen speichert.
- Identity + groups (wer der User ist und in welchen Gruppen), was Baseline‑Rollen automatisch zuweisen kann.
Sessions: Ablauf, Refresh und Gerätevertrauen
Definieren Sie Session‑Regeln vorher:
- Kurzlebige Zugriffs‑Session (z. B. 8–12 Stunden) mit klarer Re‑Auth‑Anforderung
- Refresh‑Strategie: Silent‑Refresh über IdP (OIDC) oder Re‑Login nach Ablauf (einfacher, sicherer)
- Device Trust: Optional Geräte merken für risikoarme Aktionen, aber Re‑Auth für Admin‑Änderungen verlangen. Sessions pro Gerät tracken, damit Admins sie widerrufen können.
MFA für sensible Admin‑Aktionen
Auch wenn der IdP MFA beim Login verlangt, fügen Sie Step‑Up‑Authentifizierung für hochwirksame Aktionen hinzu (Admin‑Rechte vergeben, Genehmigungsregeln ändern, Audit‑Logs exportieren). Praktisch heißt das: prüfen, ob MFA „kürzlich durchgeführt“ wurde oder Re‑Auth erzwingen, bevor die Aktion abgeschlossen wird.
Zugriffsanfragen und Genehmigungsworkflows
Eine Berechtigungs‑App steht oder fällt damit, ob Leute den Zugriff bekommen, den sie brauchen, ohne versteckte Risiken zu schaffen. Ein klarer Request‑/Approval‑Workflow hält Zugriffe konsistent, nachvollziehbar und auditierbar.
Grundflow: request → decision → grant
Starten Sie mit einem einfachen, wiederholbaren Pfad:
- User beantragt Zugriff auf ein konkretes Tool, eine Umgebung (prod vs. staging) und ein Berechtigungsset.
- Genehmiger prüfen die Anfrage (mit Kontext wie geschäftlicher Begründung und Dauer).
- System gewährt Zugriff automatisch nach Freigabe (oder erstellt eine Admin‑Aufgabe, wenn Automatisierung fehlt).
- User wird benachrichtigt, und das Grant wird im Audit‑Log aufgezeichnet.
Halten Sie Anfragen strukturiert: vermeiden Sie Freitext‑„Bitte gebt mir Admin“. Lassen Sie stattdessen die Auswahl einer vordefinierten Rolle/Bündel zu und verlangen Sie eine kurze Begründung.
Wer darf was genehmigen
Definieren Sie Genehmigungsregeln im Voraus, damit Genehmigungen nicht zu Diskussionen werden:
- Manager‑Genehmigung bestätigt, dass die Anfrage zur Rolle passt
- App‑Owner‑Genehmigung bestätigt, dass das Berechtigungslevel für das Tool/Umgebung angemessen ist
- Security‑Genehmigung ist reserviert für hochwirksame Zugriffe (Admin‑Rollen, Prod‑Write, sensible Daten)
Verwenden Sie z. B. „Manager + App Owner“ für Standardzugriffe und fügen Sie Security für privilegierte Rollen hinzu.
Zeitlich begrenzter Zugriff mit automatischem Ablauf
Standardmäßig zeitlich begrenzen (z. B. 7–30 Tage) und „bis Widerruf“ nur für eine kurze Liste stabiler Rollen erlauben. Ablauf automatisch planen: derselbe Workflow, der den Zugriff vergibt, sollte auch die Entfernung terminieren und den User vor Ablauf benachrichtigen.
Dringender Zugriff ohne Kontrollverlust
Unterstützen Sie einen „Dringend“-Pfad für Incident‑Response, aber mit Schutzmaßnahmen:
- Pflicht für einen Reason‑Code (Incident‑Ticket, Outage‑Referenz)
- Kürzere Default‑Dauer (Stunden statt Tage)
- Zusätzliche Protokollierung und Alerts an App‑Owner und Security
So bleibt schneller Zugriff sichtbar und nachvollziehbar.
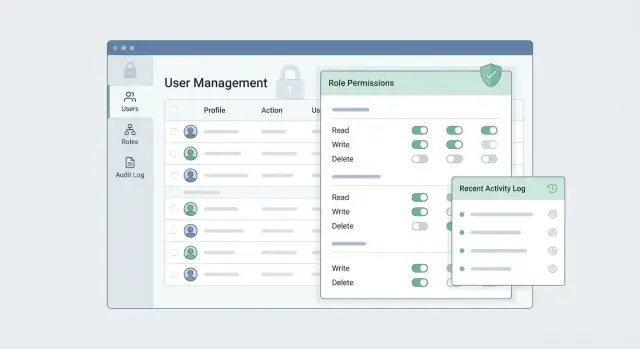
Admin‑Dashboard UX, die Fehler verhindert
Ihr Admin‑Dashboard ist der Ort, an dem „ein Klick“ Zugriffe auf Payroll oder Prod‑Rechte gewähren kann. Gute UX behandelt jede Berechtigungsänderung als heikle Aktion: klar, reversibel und leicht zu prüfen.
Beginnen Sie mit einer admin‑freundlichen Struktur
Nutzen Sie eine Navigation, die so denkt wie Admins:
- Users: wer hat Zugriff und warum
- Roles: wiederverwendbare Berechtigungsbündel
- Apps/Resources: was zugänglich ist
- Requests: ausstehende Genehmigungen und Historie
- Audit: wer was wann geändert hat
Diese Struktur reduziert „Wohin gehe ich?“‑Fehler und erschwert das Verändern des falschen Elements.
Machen Sie Berechtigungen lesbar (nicht nur technisch korrekt)
Namen von Berechtigungen sollten zuerst in klarem Alltagssprache stehen, technische Details dahinter:
- „View invoices“ (Scope: Billing → Invoices:read)
- „Deploy to production“ (Scope: CI/CD → prod:deploy)
Zeigen Sie die Auswirkung einer Rolle in einer kurzen Zusammenfassung („Vergibt Zugriff auf 12 Ressourcen, einschließlich Production“) und verlinken Sie zur vollständigen Aufschlüsselung.
Schützen Sie riskante Aktionen mit Guardrails
Setzen Sie bewusste Reibung ein:
- Vorschau vor Anwendung: „Das fügt 3 Berechtigungen hinzu und entfernt 1.“
- Bestätigungsdialoge für sensible Bereiche (prod, Finance, HR)
- Bulk‑Änderungen vorsichtig: CSV‑Vorschau, ungültige Zeilen hervorheben, „Ich habe verstanden“‑Checkbox
- Einfache Rücknahme: „Diese Änderung rückgängig machen“ auf der Detailseite
Für große Organisationen optimieren
Admins brauchen Geschwindigkeit ohne Sicherheitsverluste. Bieten Sie Suche, Filter (App, Rolle, Abteilung, Status) und Pagination überall für Users, Roles, Requests und Audit‑Einträge. Bewahren Sie Filterzustand in der URL, damit Seiten teilbar und reproduzierbar sind.
Durchsetzungsschicht: wie Berechtigungen tatsächlich geprüft werden
Die Durchsetzungsschicht macht Ihr Modell real. Sie sollte langweilig, konsistent und schwer umgehbar sein.
Eine Permission‑Check‑Funktion, überall
Erstellen Sie eine einzelne Funktion (oder ein kleines Modul), das eine Frage beantwortet: „Kann Nutzer X Aktion Y auf Ressource Z durchführen?“ Jede UI‑Gate, jeder API‑Handler, jeder Background‑Job und jedes Admin‑Tool muss diese prüfen.
Das verhindert, dass sich unterschiedliche Implementierungen im Laufe der Zeit entfernen. Halten Sie Inputs explizit (user id, action, resource type/id, context) und Outputs strikt (allow/deny plus Grund für Audit).
Routen und APIs schützen (nicht nur die UI)
Buttons verbergen ist keine Sicherheit. Durchsetzen müssen Sie serverseitig für:
- Jeden API‑Endpoint (inkl. interner/admin Endpoints)
- Server‑gerenderte Routen
- Hintergrundjobs (Exports, Syncs, geplante Jobs)
Ein bewährtes Muster ist Middleware, die das Subjekt lädt, die Permission‑Check‑Funktion aufruft und bei „deny“ geschlossen (403) fehlschlägt. Wenn Ihr UI /api/reports/export aufruft, muss der Endpoint dieselbe Regel erzwingen, auch wenn der Button im UI deaktiviert ist.
Vorsichtig cachen, damit Entscheidungen aktuell bleiben
Caching kann Performance verbessern, aber auch Zugriff nach einer Rollenänderung am Leben erhalten.
Bevorzugen Sie das Caching von Inputs, die sich langsam ändern (Rollen‑Definitionen, Policy‑Regeln) und halten Sie Decision‑Caches kurzlebig. Invalidieren Sie Caches bei Events wie Rollenupdates, Zuweisungsänderungen oder Deprovisioning. Wenn Sie pro‑User‑Entscheidungen cachen müssen, fügen Sie einen „permissions version“‑Counter hinzu und erhöhen ihn bei jeder Änderung.
Häufige Fallstricke
Vermeiden Sie:
- Impliziten Admin: „isEmployee=true“ oder „hat den Workspace erstellt“ gewährt stillschweigend alles
- Vergessene Endpoints: alte v1‑Routen, CSV‑Exports, Webhooks, GraphQL‑Felder, interne Tools
- „Deny“-Lücken: fehlende Policy = allow. Standard sollte deny sein, sofern nicht explizit erlaubt
Dokumentieren Sie ein Referenz‑Implementations‑Pattern im Engineering‑Runbook (z. B. /docs/authorization), damit neue Endpoints den gleichen Durchsetzungsweg nutzen.
Audit‑Logs und Reporting
Audit‑Logs sind Ihr „Kassenbon“ für Berechtigungen. Wenn jemand fragt: „Warum hat Alex Zugriff auf Payroll?“, sollten Sie binnen Minuten antworten können — ohne zu raten oder Chats zu durchsuchen.
Was zu loggen ist (und wie man es nützlich macht)
Für jede Berechtigungsänderung protokollieren Sie wer was wann und warum. „Warum“ sollte nicht nur Freitext sein; es sollte auf den Workflow verweisen, der die Änderung gerechtfertigt hat.
Mindestens erfassen:
- Actor (Admin/Service), Ziel‑User oder Gruppe und Ressource (Tool, Umgebung, Dataset)
- Old value → New value (z. B.
Finance-Read→Finance-Admin) - Timestamp (UTC) und Quelle (UI, API, automatischer Job)
- Request ID und Approval ID (oder Ticket ID), damit sich die Entscheidungsspur rekonstruieren lässt
- Optional: geschäftliche Begründung, Ablaufdatum und Policy, die es erlaubt
Verwenden Sie ein konsistentes Event‑Schema, damit Reporting zuverlässig bleibt. Selbst wenn sich die UI ändert, bleibt die Audit‑Story lesbar.
Lesezugriffe auf sensible Daten protokollieren
Nicht jeder Lesezugriff muss geloggt werden, aber hochriskante Datenzugriffe oft schon (Payroll, PII‑Exporte, API‑Key‑Ansichten, „Download all“-Aktionen).
Halten Sie Lese‑Logging praktikabel:
- Loggen Sie Ereignisse, nicht vollständige Payloads (vermeiden Sie sensible Werte in Logs)
- Erfassen Sie Ressourcen‑IDs, verwendete Filter und ggf. Volumen (z. B. „exportierte 2.431 Reihen“)
- Sampling nur wenn Compliance es erlaubt — und dokumentieren Sie die Wahl
Reporting und Exporte (mit Schutzmaßnahmen)
Bieten Sie Admins gebräuchliche Reports: „Berechtigungen pro Person“, „Wer kann auf X zugreifen?“ und „Änderungen der letzten 30 Tage“. Exportoptionen (CSV/JSON) für Prüfer sind nützlich, behandeln Sie Exporte aber als sensibel:
- Explizite Berechtigung zum Audit‑Export verlangen
- Exporte mit Erzeuger und Zeitstempel wasserzeichen
- Das Export‑Ereignis selbst protokollieren (inkl. Filter und Dateiformat)
Aufbewahrung und wer Audit‑Spuren sehen darf
Legen Sie Aufbewahrungsfristen fest (z. B. 1–7 Jahre je nach regulatorischem Bedarf) und trennen Sie Aufgaben:
- Nur eine begrenzte Rolle kann Audit‑Logs einsehen
- Unterstützen Sie read‑only Auditor‑Zugänge
- Machen Sie Logs append‑only und manipulationssicher (z. B. immutable Storage oder signierte Event‑Ketten)
Wenn Sie einen dedizierten „Audit“‑Bereich im Admin UI hinzufügen, verlinken Sie ihn von /admin mit klaren Warnhinweisen und einer Suchzentrierten Oberfläche.
User‑Lifecycle und Provisioning
Berechtigungsdrift entsteht, wenn Leute anfangen, Teams wechseln, sich freinehmen oder das Unternehmen verlassen. Ein solides Access‑Management behandelt User‑Lifecycle als First‑Class‑Feature.
Provisioning: wie neue Nutzer den richtigen Zugriff bekommen
Beginnen Sie mit einer klaren Quelle der Wahrheit für Identität: Ihr HR‑System, Ihr IdP (Okta, Azure AD, Google) oder beides. Ihre App sollte:
- Einen User‑Datensatz automatisch anlegen, wenn ein Mitarbeiter im IdP auftaucht
- Baseline‑Zugriffe per Least Privilege zuweisen (z. B. Default „Employee“-Rolle plus team‑spezifische Rollen)
Wenn Ihr IdP SCIM unterstützt, nutzen Sie es. SCIM synchronisiert Nutzer, Gruppen und Statusänderungen automatisch und reduziert manuelle Admin‑Arbeit. Wenn SCIM nicht verfügbar ist, planen Sie periodische Importe (API oder CSV) und verlangen Owner‑Reviews für Ausnahmen.
Rollenänderungen: Team‑Wechsel ohne Chaos
Teamwechsel sind ein häufiger Ort für Berechtigungschaos. Modellieren Sie „Team“ als verwaltetes Attribut (aus HR/IdP synchronisiert) und behandeln Sie Rollen‑Zuweisungen, wo möglich, als abgeleitete Regeln (z. B. „Wenn department = Finance, grant Finance Analyst role").
Bei Teamwechseln sollte Ihre App:
- Alte team‑basierte Rollen automatisch entfernen
- Explizit genehmigte Ausnahmen bewahren und zur Re‑Genehmigung markieren
Deprovisioning: schnelles Offboarding über alle Tools
Offboarding muss Zugriffe schnell und vorhersehbar entfernen. Triggern Sie Deprovisioning vom IdP (User deaktivieren) und sorgen Sie, dass Ihre App sofort:
- Aktive Sessions und API‑Token widerruft
- Tool‑Access Grants entfernt und Tool‑Owner benachrichtigt
Wenn Ihre App auch Zugriff in Downstream‑Tools provisioniert, reihen Sie diese Removals in Tasks ein und zeigen Sie Fehler im Admin‑Dashboard an, damit nichts unentdeckt bleibt.
Sicherheitskontrollen und Threat‑Checks
Eine Berechtigungs‑App ist ein attraktives Ziel, weil sie Zugriff auf viele interne Systeme gewähren kann. Sicherheit ist hier keine einzelne Funktion, sondern eine Sammlung kleiner, konsistenter Kontrollen, die das Risiko reduzieren.
Eingaben validieren und gängige Web‑Angriffe blocken
Behandeln Sie jedes Formularfeld, Query‑Parameter und API‑Payload als untrusted:
- Validieren Sie Typen und zulässige Werte (z. B. Rollennamen aus einer festen Liste, kein Freitext)
- Sanitizen Sie nutzergenerierte Texte, die später angezeigt werden, um XSS zu verhindern
- Nutzen Sie CSRF‑Schutz für Cookie‑basierte Sessions, besonders bei Grant/Revoke‑Aktionen
Setzen Sie zudem sichere UI‑Defaults: „kein Zugriff“ vorauswählen und explizite Bestätigung für hochwirksame Änderungen verlangen.
Autorisierung serverseitig erzwingen — jedes Mal
Die UI reduziert Fehler, kann aber nicht Ihre Sicherheitsgrenze sein. Jeder Endpoint, der Berechtigungen ändert oder sensible Daten zeigt, braucht einen serverseitigen Autorisierungscheck:
- Erstellen/Ändern von Rollen und Policies
- Gewähren/Entziehen von Zugriffen oder Ändern von Ausnahmen
- Ansicht von Audit‑Logs und Reports
Behandeln Sie das als Engineering‑Regel: Kein sensibler Endpoint ohne Autorisierungscheck und Audit‑Event.
Ratenbegrenzung und Missbrauchskontrollen
Admin‑Endpoints und Auth‑Flows sind häufige Ziele für Brute‑Force und Automatisierung:
- Rate‑Limit für Login‑Versuche und Passwort‑Resets
- Rate‑Limit für Admin‑Aktionen wie Bulk‑Grants/Exports
- Alerts bei verdächtigen Spitzen (z. B. viele Berechtigungsänderungen in kurzer Zeit)
Erzwingen Sie Step‑Up‑Verification für riskante Aktionen, z. B. Re‑Auth oder zusätzliche Genehmigungen.
Geheimnisse, Verschlüsselung und Least Privilege
Speichern Sie Secrets (SSO‑Client‑Secrets, API‑Tokens) in einem Secret‑Manager, nicht im Sourcecode oder in Konfigurationsdateien:
- Verschlüsseln Sie sensible Daten im Ruhezustand und in Transit (TLS überall)
- Nutzen Sie least‑privileged DB‑ und Service‑Konten: die Web‑App sollte nur minimale Rechte haben
- Trennen Sie „read“ und „write“ Credentials, wo sinnvoll, besonders für Reporting/Audit‑Exports
Schnelle Threat‑Checks (was zu testen ist)
Führen Sie regelmäßige Checks aus für:
- Privilege Escalation (User, der sich selbst oder seinem Team Rechte gibt)
- IDOR‑Probleme (ID in der URL ändern, um auf fremde Daten zuzugreifen)
- Fehlende Autorisierung auf „internen“ Endpoints
- Gefährliche Defaults (neue Integrationen erhalten automatisch breite Rechte)
Diese Checks sind kostengünstig und fangen die häufigsten Arten von Fehlern in Berechtigungssystemen ein.
Teststrategie für berechtigungsintensive Apps
Berechtigungsfehler sind selten „Die App ist kaputt“ — es sind „Die falsche Person kann das Falsche tun“‑Probleme. Behandeln Sie Autorisierungsregeln wie Business‑Logik mit klaren Inputs und erwarteten Outcomes.
1) Unit‑Tests für die Regeln (schnelles Feedback)
Fangen Sie an, indem Sie Ihren Permission‑Evaluator unittesten. Benennen Sie Tests als Szenarien:
- Testen Sie Allow‑ und Deny‑Fälle, inkl. Edge‑Cases (z. B. User gesperrt, Tool archiviert, Rolle während Session entfernt)
- Schließen Sie Ausnahmepfade ein: temporärer Zugriff, Break‑glass, Self‑service mit Genehmigung
Ein gutes Pattern ist eine kleine Tabelle von Fällen (User‑State, Rolle, Resource, Action → erwartete Entscheidung), sodass neue Regeln nicht die Suite umkrempeln.
2) Integrationstests für risikoreiche Journeys
Unit‑Tests fangen Wiring‑Fehler nicht ein — etwa wenn ein Controller vergisst, den Autorisierungscheck aufzurufen. Fügen Sie Integrationstests für die wichtigsten Flows hinzu:
- Request Access → Approver genehmigt/lehnt → User gewinnt/verliert Zugriff
- Rollenänderung → sofortige Wirkung auf Zugriff
- Deprovisioning → Zugriff überall entfernt
Diese Tests sollten die gleichen Endpoints wie die UI treffen und sowohl API‑Antworten als auch DB‑Änderungen validieren.
3) Verlässliche Test‑Fixtures
Erstellen Sie stabile Fixtures für Rollen, Teams, Tools und Beispiel‑User (Employee, Contractor, Admin). Versionieren und teilen Sie sie, damit alle gegen dieselbe Bedeutung von „Finance Admin“ oder „Support Read‑Only“ testen.
4) Regressions‑Checklist vor jedem Release
Führen Sie eine leichte Checkliste für Berechtigungsänderungen: neue Rollen, Default‑Rollenänderungen, Migrationen, die Grants betreffen, und UI‑Änderungen auf Admin‑Screens. Verknüpfen Sie die Checkliste mit dem Release‑Prozess, wenn möglich (z. B. /blog/release-checklist).
Deployment, Monitoring und laufender Betrieb
Ein Berechtigungssystem ist nie „fertig“. Der echte Test beginnt nach dem Start: neue Teams, Tool‑Änderungen und dringende Zugriffsbedürfnisse treten auf. Behandeln Sie Betrieb als Produktaufgabe.
Planen Sie Ihre Umgebungen (dev, staging, prod)
Halten Sie dev, staging und production isoliert — besonders deren Daten. Staging sollte Production‑Konfigurationen (SSO, Policy‑Toggles, Feature Flags) spiegeln, aber mit separaten Identity‑Gruppen und nicht‑sensiblen Testkonten.
Trennen Sie außerdem:
- Audit‑Logs (Test‑Noise darf Compliance‑Reporting nicht verschmutzen)
- Approval‑Workflows (Staging‑Approvals sollen reale Genehmiger nicht benachrichtigen)
- Secrets und Keys (keine Produktions‑Signing‑Keys in niedrigeren Umgebungen)
Monitoring, das Berechtigungsprobleme früh erkennt
Überwachen Sie Basis‑Metriken (Uptime, Latenz) und fügen Sie berechtigungsspezifische Signale hinzu:
- Auth‑Failures nach Typ: abgelaufene Session vs. SSO‑Fehler vs. fehlende Berechtigung
- Authorization Denials‑Spikes für ein Tool/Team (oft Sign für kaputte Rollenzuordnung)
- Verdächtige Muster: viele Zugriffsanfragen, schnelle Roll‑Änderungen, ungewöhnliche Admin‑Aktivität
Machen Sie Alerts handlungsfähig: User, Tool, Rolle/Policy, Request‑ID und Link zum Audit‑Event im Admin UI mitliefern.
Runbooks: Was um 2 Uhr morgens zu tun ist
Schreiben Sie kurze Runbooks für Notfälle:
- Schnell Zugriff entziehen (User deaktivieren, Role‑Bindings entfernen, Sessions invalidieren)
- Service wiederherstellen (Policy‑Rollback, Fail Closed vs. Fail Open entscheiden, Keys rotieren)
- SSO‑Ausfall (Break‑glass‑Zugriff mit zeitbegrenzter Genehmigung)
Bewahren Sie Runbooks im Repo und Ops‑Wiki auf und testen Sie sie in Drills.
Schneller bauen (ohne Governance zu überspringen)
Wenn Sie das als neue interne App implementieren, ist das größte Risiko, Monate in Infrastruktur (Auth‑Flows, Admin‑UI, Audit‑Tables, Request‑Screens) zu investieren, bevor Sie das Modell mit echten Teams validiert haben. Ein praktischer Ansatz: eine minimal lauffähige Version schnell ausrollen und dann mit Policies, Logging und Automatisierung härten.
Eine Möglichkeit, schneller zu starten, ist der Einsatz von Koder.ai, einer vibe‑coding Plattform, die Web‑ und Backend‑Anwendungen per Chat‑Interface erstellen lässt. Für berechtigungsintensive Apps ist sie nützlich, um initial das Admin‑Dashboard, Request/Approval‑Flows und das CRUD‑Datenmodell zu generieren — dabei behalten Sie Kontrolle über Architektur (häufig React im Frontend, Go + PostgreSQL im Backend) und können Quellcode exportieren, wenn Sie in Ihren Standard‑Review‑/Deploy‑Prozess übergehen. Features wie Snapshots/Rollback und Planning‑Mode helfen, Autorisierungsregeln sicherer zu iterieren.
Nächste Schritte
Wenn Sie eine klarere Grundlage für Rollen‑Design wollen, bevor Sie Operationen skalieren, sehen Sie /blog/role-based-access-control-basics. Für Packaging‑ und Rollout‑Optionen prüfen Sie /pricing.
FAQ
Was zählt als „Berechtigung“ in einer Zugriffsanwendung für interne Tools?
Eine Berechtigung ist eine konkrete Aktion, die Sie kontrollieren möchten, formuliert als Verb, das dem Arbeitsablauf der Menschen entspricht — z. B. view, edit, admin oder export.
Eine praktische Vorgehensweise ist, Aktionen pro Tool und Umgebung (Prod vs. Staging) aufzulisten und die Namen zu standardisieren, sodass sie überprüfbar und auditierbar sind.
Wie erstelle ich ein Inventar von Tools und entscheide, wo Berechtigungen durchgesetzt werden sollen?
Führen Sie ein Inventar aller Systeme, bei denen Zugriff relevant ist — SaaS-Apps, interne Admin-Panels, Data Warehouses, CI/CD, geteilte Ordner und alle „Shadow-Admin“-Tabellen.
Notieren Sie für jedes Tool, wo die Durchsetzung passiert:
- Inside the tool (native Rollen)
- At a gateway (Reverse Proxy / API-Layer)
- By process (manuelle Schritte / geteilte Zugangsdaten)
Alles, was „by process“ durchgesetzt wird, sollte entweder als bewusstes Risiko behandelt oder priorisiert entfernt werden.
Welche Erfolgsmessgrößen sollten wir für das interne Berechtigungsmanagement verwenden?
Messen Sie sowohl Geschwindigkeit als auch Sicherheit:
- Medianzeit bis zur Gewährung von Zugriff
- Anzahl berechtigungsbezogener Vorfälle
- Anteil des Zugriffs mit einem Owner und einer geschäftlichen Begründung
- Audit-Bereitschaft: „Wer hatte wann und warum Zugriff auf was?“
Diese Kennzahlen zeigen, ob das System die Abläufe verbessert und Risiken reduziert.
Wann soll ich RBAC vs. RBAC mit Overrides vs. ABAC verwenden?
Beginnen Sie mit dem einfachsten Modell, das die Realität aushält:
- RBAC wenn die meisten Zugriffe als Rollen wie Viewer/Operator/Admin ausgedrückt werden können
- RBAC + Overrides wenn vereinzelt Spezialfälle auftreten
- ABAC wenn attributbasierte Regeln sonst zu vielen Rollen führen (z. B. region-/department-basierte Regeln)
Wählen Sie das einfachste Modell, das bei Reviews und Audits verständlich bleibt.
Wie setzen wir Least Privilege als Standard, ohne Teams zu verlangsamen?
Machen Sie Least Privilege zur Standardeinstellung, ohne Teams auszubremsen:
- Starten Sie mit „kein Zugriff“ oder „nur Lesen“
- Trennen Sie „ansehen“ von „ändern“ und „anfordern“ von „genehmigen“
- Vermeiden Sie „Admin heißt alles“-Bündel; machen Sie hochwirksame Aktionen sichtbar
Least Privilege funktioniert am besten, wenn es leicht zu erklären und zu prüfen ist.
Was ist der Unterschied zwischen globalen Berechtigungen und toolspezifischen Berechtigungen?
Definieren Sie globale Berechtigungen für organisationsweite Fähigkeiten (z. B. Benutzer verwalten, Audit-Logs ansehen, Zugriffe genehmigen) und tool-spezifische Berechtigungen für Aktionen innerhalb jedes Tools (z. B. deployen, Secrets ansehen).
Das verhindert, dass die Komplexität eines Tools alle anderen Tools in dieselbe Rollenstruktur zwingt.
Welches Datenmodell benötigen wir, um die Frage „Wer hat Zugriff auf was und warum?“ zu beantworten?
Modellieren Sie mindestens:
- Users, Teams
- Tools/Apps
- Roles, Permissions
- Assignments (Subject → Role → Tool)
Fügen Sie Lifecycle-Felder wie created_by, expires_at und disabled_at hinzu, damit Sie historische Fragen („War dieser Zugriff letzten Dienstag gültig?“) ohne Rätsel beantworten können.
Wie sollten wir Authentifizierung und SSO (OIDC vs SAML) integrieren?
Bevorzugen Sie SSO für interne Apps, damit Mitarbeitende ihren Unternehmens-Identitätsanbieter nutzen.
- OIDC ist im modernen Umfeld üblich (ID-Token + stabile Identifizierer)
- SAML wird in vielen Unternehmen weiterhin benötigt (signierte Assertions + Metadaten/Zertifikatrotation)
Entscheiden Sie, ob Sie dem IdP nur Identität vertrauen oder Identität plus Gruppen (um Basiszugriffe automatisch zuzuweisen).
Wie sollte ein Access-Request- und Genehmigungs-Workflow aussehen?
Nutzen Sie einen strukturierten Ablauf: request → decision → grant → notify → audit.
Lassen Sie Anfragen vordefinierte Rollen/Bundles wählen (keinen Freitext), verlangen Sie eine kurze geschäftliche Begründung und definieren Sie Genehmigungsregeln wie:
- Manager + App Owner für Standardzugriffe
- Security zusätzlich für privilegierte/produktive/sensible Rollen
Standardmäßig zeitlich begrenzen und automatische Ablaufmechanismen einplanen.
Was sollten wir in Audit-Logs erfassen und wer darf sie sehen?
Protokollieren Sie Änderungen als unveränderbare Spur: wer hat was wann und warum geändert, inkl. Alt → Neu-Werte und Verknüpfung zur Anfrage/Genehmigung oder Ticket-ID.
Außerdem:
- Loggen Sie Lesezugriffe für hochriskante Aktionen (Exporte, API-Key-Ansichten)
- Behandeln Sie Audit-Exporte als sensibel (explizite Berechtigung, Wasserzeichen, Export-Ereignis protokolliert)
- Legen Sie Aufbewahrungsfristen fest (häufig 1–7 Jahre) und beschränken Sie, wer Logs sehen darf (z. B. read-only Auditor-Rollen)