Ziele und Adoption‑Signale definieren
Bevor Sie einen Customer‑Adoption‑Health‑Score bauen, entscheiden Sie, was der Score für das Business tun soll. Ein Score, der Churn‑Alarm auslösen soll, sieht anders aus als einer, der Onboarding, Kundenbildung oder Produktverbesserungen steuern soll.
Definieren Sie, was „Adoption“ für Ihr Produkt bedeutet
Adoption ist nicht nur „kürzlich eingeloggt“. Schreiben Sie die wenigen Verhaltensweisen auf, die wirklich anzeigen, dass Kunden Wert erreichen:
- Activation: der erste Moment, in dem ein Nutzer ein sinnvolles Ergebnis erreicht (z. B. „einen Teamkollegen eingeladen“, „eine Datenquelle verbunden“, „einen Bericht veröffentlicht“).
- Core actions: wiederholbare, hochsignifikante Verhaltensweisen, die mit erfolgreichen Accounts korrelieren (z. B. wöchentliche Exporte, automatisierte Abläufe, Dashboards, die von mehreren Nutzern angesehen werden).
- Retention: fortgesetzte Nutzung in der für Ihr Produkt relevanten Kadenz (täglich, wöchentlich, monatlich), idealerweise über mehr als einen Nutzer im Account.
Diese werden Ihre initialen Adoption‑Signale für Feature‑Usage‑Analytics und spätere Kohortenanalysen.
Listen Sie die Entscheidungen auf, die Ihre App ermöglichen soll
Seien Sie explizit darüber, was passiert, wenn sich der Score ändert:
- Wer wird benachrichtigt, wenn ein Account unter einen Schwellenwert fällt?
- Welche Playbooks sollen gestartet werden (Outreach, Training, Support‑Check‑in)?
- Welche Insights sollen die Produkt‑Adoption‑Überwachung informieren (Friction‑Points, wenig genutzte Features, Time‑to‑Value)?
Wenn Sie keine Entscheidung benennen können, verfolgen Sie die Metrik noch nicht.
Identifizieren Sie Nutzer, Rollen und Zeitfenster
Klären Sie, wer das Customer‑Success‑Dashboard nutzen wird:
- CS‑Manager brauchen Priorisierung und Account‑Kontext.
- Product braucht Muster, Kohorten und Feature‑Level‑Bewegungen.
- Support braucht jüngste Aktivität im Zusammenhang mit Tickets und Incidents.
- Leadership braucht eine verständliche Rollup‑Ansicht und Trends.
Wählen Sie Standard‑Fenster — letzte 7/30/90 Tage — und berücksichtigen Sie Lifecycle‑Phasen (Trial, Onboarding, Steady‑State, Renewal). So vermeiden Sie, einen brandneuen Account mit einem reifen zu vergleichen.
Setzen Sie Erfolgskriterien
Definieren Sie „fertig“ für Ihr Health‑Score‑Modell:
- Accuracy: sagt es Risiko und Expansion besser voraus als Ihr aktueller Ansatz?
- Explainability: kann ein CSM in einer Minute erklären, warum der Score hoch/niedrig ist?
- Ease of use: spart es Zeit und führt zu konsistenten Aktionen?
Diese Ziele prägen alles Weitere: Event‑Tracking, Scoring‑Logik und die Workflows rund um den Score.
Metriken für Ihren Health‑Score auswählen
Die Auswahl der Metriken entscheidet, ob Ihr Health‑Score ein hilfreiches Signal oder eine laute Zahl wird. Streben Sie eine kleine Menge Indikatoren an, die echte Adoption widerspiegeln — nicht nur Aktivität.
Beginnen Sie mit Produkt‑Adoption‑Signalen
Wählen Sie Metriken, die zeigen, ob Nutzer wiederholt Wert erhalten:
- Logins / aktive Nutzer: z. B. Weekly Active Users (WAU) und der Trend über die letzten 4–8 Wochen.
- Active days: wie viele verschiedene Tage der Account in einer Woche/einem Monat aktiv war (vermeidet „eine große Sitzung“‑False‑Positives).
- Feature depth: Nutzung Ihrer „Value‑Features“ (die Aktionen, die mit Erfolg korrelieren), nicht jeder Button‑Klick.
- Verbundenen Integrationen: besonders wenn Integrationen Switching‑Kosten erhöhen oder wichtige Workflows freischalten.
- Seat‑Nutzung: Anteil der gekauften Seats, die eingeladen, aktiviert und tatsächlich aktiv sind.
Halten Sie die Liste fokussiert. Wenn Sie nicht in einem Satz erklären können, warum eine Metrik wichtig ist, ist sie wahrscheinlich kein Kerninput.
Geschäftskontext hinzufügen (damit Scores fair sind)
Adoption muss im Kontext interpretiert werden. Ein 3‑Seat‑Team verhält sich anders als ein Rollout mit 500 Seats.
Gängige Kontext‑Signale:
- Plan‑Tier und Feature‑Entitlements
- Contract‑Größe / ARR‑Band
- Lifecycle‑Stage: Trial vs. neu bezahlt vs. Renewal‑Fenster
Diese müssen nicht unbedingt „Punkte hinzufügen“, aber sie helfen, realistische Erwartungen und Schwellen nach Segment zu setzen.
Leading vs. Lagging‑Indikatoren entscheiden
Ein nützlicher Score mischt:
- Leading Indikatoren (sagen zukünftigen Erfolg voraus): steigende Active Days, Onboarding‑Abschluss, erste Integration verbunden.
- Lagging Indikatoren (bestätigen Resultate): Renewal, Expansion, langfristige Retention.
Vermeiden Sie eine Übergewichtung von Lagging‑Metriken; sie sagen Ihnen, was bereits passiert ist.
Wenn vorhanden, können NPS/CSAT, Support‑Ticket‑Volumen und CSM‑Notizen Nuancen hinzufügen. Nutzen Sie diese als Modifikatoren oder Flags — nicht als Grundlage — weil qualitative Daten dünn und subjektiv sein können.
Erstellen Sie ein einfaches Datenwörterbuch
Bevor Sie Diagramme bauen, stimmen Sie Namen und Definitionen ab. Ein leichtgewichtiges Datenwörterbuch sollte enthalten:
- Metrikname (z. B.
active_days_28d)
- Klare Definition (was zählt, was nicht)
- Zeitfenster und Aktualisierungsfrequenz
- Quellsystem (Produkt‑Events, CRM, Support)
Das verhindert später Verwirrung durch „gleiche Metrik, andere Bedeutung“ beim Implementieren von Dashboards und Alerts.
Ein erklärbares Health‑Score‑Modell entwerfen
Ein Adoption‑Score funktioniert nur, wenn Ihr Team ihm vertraut. Zielen Sie auf ein Modell, das Sie in einer Minute einem CSM und in fünf Minuten einem Kunden erklären können.
Einfach anfangen: gewichtete Punkte (vor ML)
Beginnen Sie mit einem transparenten, regelbasierten Score. Wählen Sie eine kleine Menge Adoption‑Signale (z. B. aktive Nutzer, Nutzung wichtiger Features, aktivierte Integrationen) und weisen Sie Gewichte zu, die die „Aha“‑Momente Ihres Produkts widerspiegeln.
Beispielgewichtung:
- Weekly active users per seat: 0–40 Punkte
- Häufigkeit der Nutzung wichtiger Features: 0–35 Punkte
- Breite der genutzten Features: 0–15 Punkte
- Zeit seit letzter bedeutender Aktivität: 0–10 Punkte
Halten Sie Gewichte leicht verteidigbar. Sie können sie später anpassen — warten Sie nicht auf ein perfektes Modell.
Normalisieren, um Bias zu reduzieren
Rohzählungen bestrafen kleine Accounts und glätten große. Normalisieren Sie Metriken, wo es Sinn macht:
- Pro Seat (Nutzung / lizenzierte Seats)
- Nach Account‑Alter (neu vs. reif)
- Nach Plan‑Tier (Feature‑Verfügbarkeit)
Das hilft, dass Ihr Customer‑Adoption‑Health‑Score Verhalten widerspiegelt, nicht nur Größe.
Grün/Gelb/Rot mit klarer Begründung definieren
Setzen Sie Schwellen (z. B. Green ≥ 75, Yellow 50–74, Red < 50) und dokumentieren Sie, warum jeder Cutoff existiert. Verknüpfen Sie Schwellen mit erwarteten Ergebnissen (Renewal‑Risiko, Onboarding‑Abschluss, Expansion‑Bereitschaft) und halten Sie die Notizen in Ihren internen Docs oder /blog/health-score-playbook.
Erklärbar machen: Contributors und Trend
Jeder Score sollte zeigen:
- Die Top 3 Contributors (was geholfen/geschadet hat)
- Die Veränderung über die Zeit (letzte 7/30 Tage)
- Eine zusammenfassende Plain‑Language‑Beschreibung („Feature X Nutzung ist wochenübergreifend um 35 % gefallen“)
Iteration planen: Versionieren des Modells
Behandeln Sie Scoring wie ein Produkt. Versionieren Sie es (v1, v2) und messen Sie Auswirkungen: Wurden Churn‑Alarme genauer? Handelten CSMs schneller? Speichern Sie die Score‑Version mit jeder Berechnung, damit Sie Ergebnisse über die Zeit vergleichen können.
Produkt‑Events und Datenquellen instrumentieren
Ein Health‑Score ist nur so vertrauenswürdig wie die Aktivitätsdaten dahinter. Bevor Sie die Scoring‑Logik bauen, stellen Sie sicher, dass die richtigen Signale konsistent über Systeme erfasst werden.
Wählen Sie Ihre Event‑Quellen
Die meisten Adoption‑Programme ziehen aus einer Mischung von:
- Frontend‑Events (Pageviews, Klicks, Feature‑Interaktionen)
- Backend‑Aktionen (API‑Aufrufe, Jobs abgeschlossen, Datensätze erstellt)
- Billing (Plan, Renewals, Zahlungsstatus, Seat‑Zahlen)
- Support und Success‑Tools (Tickets, CSAT, Onboarding‑Milestones)
Praktische Regel: kritische Aktionen serverseitig tracken (schwerer zu fälschen, weniger von Ad‑Blockern betroffen) und Frontend‑Events für UI‑Engagement und Discovery verwenden.
Definieren Sie ein klares Event‑Schema
Behalten Sie einen konsistenten Vertrag, damit Events leicht joinbar, abfragbar und für Stakeholder erklärbar sind. Eine verbreitete Basis ist:
event_nameuser_idaccount_idtimestamp (UTC)properties (feature, plan, device, workspace_id etc.)
Verwenden Sie ein kontrolliertes Vokabular für event_name (z. B. project_created, report_exported) und dokumentieren Sie es in einem einfachen Tracking‑Plan.
SDK vs. serverseitig (oder beides) entscheiden
- SDK‑Tracking ist schnell zu liefern und gut für UI‑Events.
- Serverseitiges Tracking ist besser für System‑of‑Record‑Aktionen.
Viele Teams machen beides, stellen aber sicher, dass dieselbe reale Aktion nicht doppelt gezählt wird.
Identity korrekt handhaben
Health‑Scores werden normalerweise auf Account‑Ebene aggregiert, daher benötigen Sie eine verlässliche User→Account‑Zuordnung. Planen Sie für:
- Nutzer, die zu mehreren Accounts gehören
- Account‑Merges (Akquisitionen, Workspace‑Konsolidierung)
- Anonymisierte IDs für Pre‑Login‑Verhalten (mit sicherem Merge nach Signup)
Data Quality Checks einbauen
Überwachen Sie mindestens fehlende Events, doppelte Burst‑Events und Zeitzonen‑Konsistenz (UTC speichern; für Anzeige konvertieren). Markieren Sie Anomalien früh, damit Ihre Churn‑Alarme nicht feuern, weil das Tracking gebrochen ist.
Datenmodellierung und Speicherung planen
Eine Customer‑Adoption‑Health‑Score‑App lebt oder stirbt daran, wie gut Sie „wer hat was und wann getan“ modellieren. Ziel ist, häufige Fragen schnell beantworten zu können: Wie geht es diesem Account diese Woche? Welche Features liegen im Trend? Gute Datenmodellierung hält Scoring, Dashboards und Alerts einfach.
Kernentitäten modellieren
Starten Sie mit einer kleinen Menge „Source‑of‑Truth“‑Tabellen:
- Accounts:
account_id, Plan, Segment, Lifecycle‑Stage, CSM‑Owner
- Users:
user_id, account_id, Rolle/Persona, created_at, Status
- Subscriptions (oder Verträge):
account_id, Start/Ende, Seats, MRR, Renewal‑Datum
- Features:
feature_id, Name, Kategorie (Activation, Collaboration, Admin, etc.)
- Events:
event_id, account_id, user_id, feature_id (nullable), event_name, timestamp, properties
- Scores:
account_id, score_date (oder computed_at), overall_score, Komponenten‑Scores, Erklärungsfelder
Halten Sie diese Entitäten konsistent, indem Sie überall stabile IDs (account_id, user_id) verwenden.
Getrennte Speicherung: relational + analytics
Nutzen Sie eine relationale DB (z. B. Postgres) für Accounts/Users/Subscriptions/Scores — Dinge, die Sie häufig aktualisieren und joinen.
Speichern Sie hochvolumige Events in einem Warehouse/Analytics‑Store (z. B. BigQuery/Snowflake/ClickHouse). Das hält Dashboards und Kohortenanalysen reaktionsschnell, ohne Ihre transaktionale DB zu belasten.
Aggregate für Geschwindigkeit speichern
Anstatt alles aus Roh‑Events neu zu berechnen, behalten Sie:
- Tägliche Account‑Summaries (eine Zeile pro Account pro Tag): aktive Nutzer, Key‑Event‑Counts, letzte Aktivität, Adoption‑Milestones
- Feature‑Counter: pro Account/Tag/Feature Nutzungszahlen, unique users, ggf. verbrachte Zeit
Diese Tabellen treiben Trend‑Charts, „Was hat sich geändert“‑Insights und Score‑Komponenten an.
Für große Event‑Tabellen planen Sie Retention (z. B. 13 Monate Rohdaten, länger für Aggregates) und Partitionierung nach Datum. Cluster/Indexieren Sie nach account_id und timestamp/date, um „Account über Zeit“‑Abfragen zu beschleunigen.
In relationalen Tabellen indexieren Sie gängige Filter und Joins: account_id, (account_id, date) auf Summaries und Foreign Keys, um Daten sauber zu halten.
Web‑App‑Architektur planen
Build-Kosten senken
Erhalte Credits, indem du deinen Build-Prozess teilst oder Kollegen an Koder.ai empfiehlst.
Ihre Architektur sollte es einfach machen, ein vertrauenswürdiges v1 zu liefern und dann zu wachsen, ohne einen Rewrite. Beginnen Sie mit so wenigen beweglichen Teilen wie nötig.
Monolith vs. Services (v1 einfach halten)
Für die meisten Teams ist ein modularer Monolith der schnellste Weg: ein Code‑Repo mit klaren Grenzen (Ingestion, Scoring, API, UI), ein Deployable und weniger Betriebsüberraschungen.
Wechseln Sie zu Services nur, wenn ein klarer Bedarf besteht — unabhängiges Skalieren, strikte Datenisolation oder separate Teams, die Komponenten verwalten. Andernfalls erhöhen premature Services Fehlerquellen und verlangsamen Iteration.
Kernkomponenten definieren
Mindestens sollten diese Verantwortlichkeiten geplant sein (auch wenn sie zunächst in einer App leben):
- Ingestion: empfängt Produkt‑Events (SDK, Segment, Webhook, Batch‑Importe).
- Aggregation: verwandelt Roh‑Events in tägliche/wöchentliche Nutzungsfakten pro Account/User.
- Scoring: berechnet den Customer‑Adoption‑Health‑Score und erklärende Felder.
- API: liefert Scores, Trends und „Warum“‑Insights an UI und Integrationen.
- UI: Customer‑Success‑Dashboard mit Account‑Ansichten, Kohorten und Drilldowns.
Wenn Sie schnell prototypen wollen, kann ein vibe‑coding‑Ansatz helfen, ein funktionierendes Dashboard zu erstellen, ohne zuviel Infrastruktur zu bauen. Beispielsweise kann Koder.ai eine React‑UI und ein Go + PostgreSQL‑Backend aus einer einfachen Chat‑Beschreibung Ihrer Entitäten (Accounts, Events, Scores), Endpunkte und Screens generieren — nützlich, um ein v1 für das CS‑Team früh greifbar zu machen.
Geplante Jobs vs. Streaming
Batch‑Scoring (z. B. stündlich / nachts) reicht meist für Adoption‑Monitoring und ist deutlich einfacher zu betreiben. Streaming macht Sinn, wenn Sie Near‑Realtime‑Alarme benötigen (z. B. plötzlicher Nutzungsabfall) oder sehr hohes Event‑Volumen haben.
Ein praktischer Hybrid: Events kontinuierlich ingestieren, Aggregation/Scoring nach Zeitplan laufen lassen und Streaming nur für eine kleine Menge dringender Signale reservieren.
Umgebungen, Secrets und nicht‑funktionale Anforderungen
Richten Sie früh dev/stage/prod ein, mit Beispiel‑Accounts in Stage, um Dashboards zu validieren. Verwenden Sie einen verwalteten Secrets‑Store und rotieren Sie Credentials.
Dokumentieren Sie Anforderungen vorab: erwartetes Event‑Volumen, Score‑Freshness (SLA), API‑Latenzziele, Verfügbarkeit, Datenaufbewahrung und Datenschutzanforderungen (PII‑Handling und Zugriffskontrollen). So werden Architekturentscheidungen nicht unter Zeitdruck getroffen.
Datenpipeline und Scoring‑Jobs bauen
Behandeln Sie Scoring wie ein Produktionssystem: reproduzierbar, beobachtbar und leicht zu erklären, wenn jemand fragt: „Warum ist dieser Account heute gefallen?"
Eine einfache Pipeline: raw → validated → aggregates
Starten Sie mit einem gestuften Fluss, der die Daten in etwas verwandelt, das Sie sicher bewerten können:
- Raw events: append‑only Ingestion aus App, Mobile, Integrationen und Billing/CRM‑Exports.
- Validated events: Events, die Schema‑Checks (erforderliche Felder, Typen), Identity‑Checks (User→Account‑Mapping) und Deduplikation bestehen.
- Daily aggregates: Rollups nach Account (und optional Workspace/Team) wie aktive Nutzer, Key‑Event‑Counts, Time‑to‑Value‑Milestones und Trend‑Deltas.
Diese Struktur hält Scoring‑Jobs schnell und stabil, weil sie auf sauberen, kompakten Tabellen statt auf Milliarden Rohzeilen arbeiten.
Rechenpläne und Backfills
Entscheiden Sie, wie „frisch“ der Score sein muss:
- Stündliches Scoring eignet sich für High‑Touch‑Motions, wo CSMs schnell handeln.
- Tägliches Scoring reicht oft für SMB/Self‑Serve und senkt Kosten.
Bauen Sie den Scheduler so, dass er Backfills unterstützt (z. B. Reprocessing der letzten 30/90 Tage), wenn Sie Tracking fixen, Gewichtungen ändern oder neue Signale hinzufügen. Backfills sollten ein First‑Class‑Feature sein, kein Notfallskript.
Idempotenz: Doppelzählung vermeiden
Scoring‑Jobs werden retried. Importe werden neu ausgeführt. Webhooks werden doppelt geliefert. Designen Sie dafür:
Verwenden Sie einen Idempotency‑Key für Events (event_id oder ein stabiler Hash aus timestamp + user_id + event_name + properties) und erzwingen Sie Einzigartigkeit auf Validated‑Ebene. Für Aggregates upserten Sie nach (account_id, date), sodass Rekalkulationen vorherige Ergebnisse ersetzen statt addieren.
Monitoring und Anomalie‑Checks
Fügen Sie betriebliches Monitoring hinzu für:
- Job success/failure und Retry‑Counts
- Data lag (wie hinter „now“ Ihre neuesten Aggregates sind)
- Volume‑Anomalien (plötzliche Drops/Spikes in Events, Active Users, Key‑Actions)
Schon einfache Schwellen (z. B. „Events 40 % unter 7‑Tage‑Durchschnitt“) verhindern stille Fehler, die das CS‑Dashboard in die Irre führen.
Audit‑Trails für jeden Score
Speichern Sie pro Account und Scoring‑Run einen Audit‑Datensatz: Input‑Metriken, abgeleitete Features (z. B. WoW‑Änderung), Modellversion und finaler Score. Wenn ein CSM auf „Warum?“ klickt, können Sie genau zeigen, was sich geändert hat und wann — ohne Logs zu rekonstruieren.
Sichere API für Health und Insights erstellen
App-Grundgerüst erstellen
Beschreibe deine Entitäten und Bildschirme und lass Koder.ai die React-UI und das Go-Backend generieren.
Die API ist der Vertrag zwischen Ihren Scoring‑Jobs, der UI und allen downstream Tools (CS‑Plattformen, BI, Datenexports). Zielen Sie auf eine API, die schnell, vorhersehbar und sicher ist.
Kernendpunkte für reale Workflows
Designen Sie Endpunkte rund um die Art, wie Customer Success Adoption tatsächlich erkundet:
- Account health:
GET /api/accounts/{id}/health liefert den neuesten Score, Status‑Band (z. B. Green/Yellow/Red) und die letzte Berechnungszeit.
- Trends:
GET /api/accounts/{id}/health/trends?from=&to= für Score über Zeit und Key‑Metric‑Deltas.
- Drivers („why“):
GET /api/accounts/{id}/health/drivers zeigt Top‑positive/negative Faktoren (z. B. „wöchentliche aktive Seats um 35 % gefallen").
- Cohorts:
GET /api/cohorts/health?definition= für Kohortenanalyse und Peer‑Benchmarks.
- Exports:
POST /api/exports/health um CSV/Parquet mit konsistenten Schemas zu erzeugen.
Machen Sie List‑Endpoints leicht slicbar:
- Filter:
plan, segment, csm_owner, lifecycle_stage und date_range sind essenziell.
- Pagination: nutzen Sie Cursor‑basierte Pagination (
cursor, limit) für Stabilität beim Datenwandel.
- Caching: cachen Sie schwere Abfragen (Kohorten‑Rollups, Trend‑Serien) und unterstützen Sie
ETag/If‑None‑Match, um wiederholte Lasten zu reduzieren. Achten Sie darauf, Cache‑Keys filter‑ und berechtigungsbewusst zu gestalten.
Sicherheit mit rollenbasierter Zugriffskontrolle
Schützen Sie Daten auf Account‑Ebene. Implementieren Sie RBAC (z. B. Admin, CSM, Read‑Only) und erzwingen Sie diese serverseitig bei jedem Endpoint. Ein CSM sollte nur Accounts sehen, die er/sie besitzt; Finance‑Rollen sehen vielleicht Plan‑Aggregates, aber nicht Nutzer‑Details.
Erklärbarkeit immer zurückgeben
Neben der numerischen Customer‑Adoption‑Health‑Score liefern Sie Felder für „Warum“: Top‑Treiber, betroffene Metriken und die Vergleichs‑Baseline (vorheriger Zeitraum, Kohortenmedian). Das macht Produkt‑Adoption‑Monitoring zu Handeln und nicht nur Reporting und erhöht Vertrauen in Ihr Customer‑Success‑Dashboard.
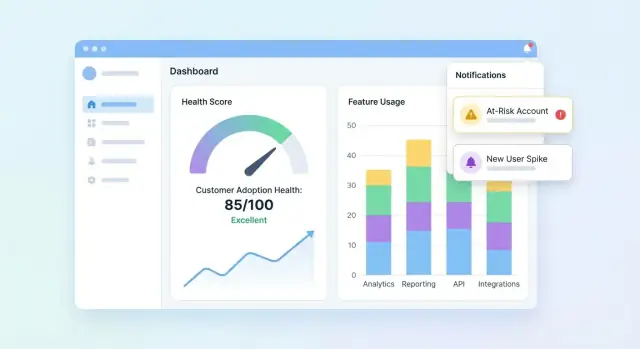
Dashboards und Account‑Ansichten gestalten
Ihre UI sollte drei Fragen schnell beantworten: Wer ist gesund? Wer rutscht ab? Warum? Beginnen Sie mit einem Portfolio‑Dashboard, dann erlauben Sie Drilldowns in Accounts, um die Geschichte hinter dem Score zu verstehen.
Portfolio‑Dashboard: das Nötigste
Beinhaltet kompakte Kacheln und Charts, die CS‑Teams in Sekunden scannen können:
- Score‑Verteilung (Histogramm oder Buckets wie Healthy / Watch / At‑Risk)
- At‑Risk‑Liste mit den wenigen Feldern, die zum Handeln nötig sind (Account, Owner, Score, letzte Aktivität, Top‑Driver)
- Score‑Trend über Zeit (Liniendiagramm) mit Filteroption nach Segment
Machen Sie die At‑Risk‑Liste klickbar, sodass ein Nutzer ein Account‑Detail öffnet und sofort sieht, was sich geändert hat.
Account‑Ansicht: den Score erklären
Die Account‑Seite sollte wie eine Adoption‑Timeline lesen:
- Timeline wichtiger Events (Onboarding‑Schritte abgeschlossen, Integrationen verbunden, Admin‑Änderungen, Major‑Feature‑First‑Use)
- Key‑Metriken (Active Users, Key Feature Actions, Zeit seit letzter bedeutender Aktivität)
- Feature‑Adoption‑Breakdown zeigt, welche Features adoptiert, ignoriert oder rückläufig sind
Fügen Sie ein „Warum dieser Score?“‑Panel hinzu: Klickt man den Score, werden die beitragenden Signale (positiv und negativ) mit Klartext‑Erklärungen angezeigt.
Kohorten‑ und Segment‑Ansichten
Bieten Sie Kohortenfilter an, die der Account‑Verwaltung entsprechen: Onboarding‑Kohorten, Plan‑Tiers und Branchen. Kombinieren Sie jede Kohorte mit Trendlinien und einer kleinen Tabelle der Top‑Mover, damit Teams Ergebnisse vergleichen und Muster entdecken können.
Zugängliche, vertrauenswürdige Visuals
Nutzen Sie klare Labels und Einheiten, vermeiden Sie zweideutige Icons und bieten Sie farbsichere Statusindikatoren (z. B. Textlabels + Formen). Behandeln Sie Charts als Entscheidungshilfen: annotieren Sie Spitzen, zeigen Sie Datumsbereiche und machen Sie Drilldowns konsistent über Seiten hinweg.
Alerts, Tasks und Workflows hinzufügen
Ein Health‑Score ist nur nützlich, wenn er zu Aktionen führt. Alerts und Workflows verwandeln „interessante Daten“ in zeitnahes Outreach, Onboarding‑Fixes oder Produktnudges — ohne dass Ihr Team den ganzen Tag Dashboards beobachten muss.
Alert‑Regeln definieren, die echten Risk abbilden
Starten Sie mit einer kleinen Menge hochsignifikanter Trigger:
- Score‑Drops (z. B. Abfall um 15 Punkte WoW)
- Red‑Status (Überschreiten eines kritischen Schwellenwerts)
- Plötzlicher Nutzungsabfall (Key‑Feature‑Nutzung fällt unter Basis)
- Fehlgeschlagener Onboarding‑Step (stagnierende Checkliste, Integration nicht abgeschlossen)
Machen Sie jede Regel explizit und erklärbar. Statt „schlechte Gesundheit“ zu alerten, formulieren Sie z. B.: „Keine Aktivität in Feature X für 7 Tage + Onboarding unvollständig.“
Kanäle wählen und konfigurierbar halten
Verschiedene Teams arbeiten anders — bieten Sie Kanalunterstützung und Präferenzen an:
- E‑Mail für Account‑Owner und Manager
- Slack für Team‑Sichtbarkeit und schnelle Reaktion
- In‑App‑Tasks im Customer‑Success‑Dashboard, damit Arbeit nicht verloren geht
Lassen Sie jedes Team konfigurieren: wer benachrichtigt wird, welche Regeln aktiv sind und welche Schwellen „dringend“ bedeuten.
Rauschreduzierung mit Guardrails
Alert‑Fatigue tötet Adoption‑Monitoring. Fügen Sie Kontrollen hinzu wie:
- Cooldown‑Fenster (nicht erneut für denselben Account N Stunden/Tage alarmieren)
- Mindest‑Daten‑Schwellen (Alerts überspringen, wenn zu wenig aktuelle Daten vorliegen)
- Batching/Digests für nicht‑dringende Signale (täglich/wöchentlich)
Kontext und nächste Schritte hinzufügen
Jeder Alert sollte beantworten: Was hat sich geändert, warum ist es wichtig und was ist der nächste Schritt?. Fügen Sie aktuelle Score‑Treiber, eine kurze Timeline (z. B. letzte 14 Tage) und vorgeschlagene Tasks wie „Onboarding‑Call planen“ oder „Integrations‑Guide senden“ hinzu. Verlinken Sie zur Account‑Ansicht (z. B. /accounts/{id}).
Ergebnisse tracken, um den Kreis zu schließen
Behandeln Sie Alerts wie Arbeitspakete mit Status: acknowledged, contacted, recovered, churned. Reporting zu Outcomes hilft, Regeln zu verfeinern, Playbooks zu verbessern und zu belegen, dass der Health‑Score messbare Retention‑Auswirkungen hat.
Datenqualität, Datenschutz und Governance sicherstellen
Gemeinsam bauen
Arbeite mit Produkt und CS in derselben App zusammen, während ihr Treiber und Schwellenwerte verfeinert.
Wenn Ihr Health‑Score auf unzuverlässigen Daten basiert, verliert das Team Vertrauen — und handelt nicht mehr. Behandeln Sie Qualität, Datenschutz und Governance als Produktfeatures, nicht als Nachgedanken.
Automatisierte Datenchecks implementieren
Starten Sie mit leichter Validierung an jedem Übergabepunkt (Ingest → Warehouse → Scoring‑Output). Einige hochsignifikante Tests fangen die meisten Probleme früh:
- Schema‑Checks: erwartete Spalten existieren, Typen haben sich nicht geändert, Enums sind valide.
- Range‑Checks: unmögliche Werte (negative Sessions, Zeitstempel in der Zukunft) schlagen fehl.
- Null‑Checks: erforderliche Felder (
account_id, event_name, occurred_at) dürfen nicht leer sein.
Wenn Tests fehlschlagen, blockieren Sie den Scoring‑Job (oder markieren Ergebnisse als „stale“), damit eine kaputte Pipeline nicht still falsche Churn‑Alarme erzeugt.
Häufige Edge‑Cases explizit behandeln
Scoring bricht bei „komischen aber normalen“ Szenarien zusammen. Definieren Sie Regeln für:
- Neue Accounts mit wenig Daten: zeigen Sie „unzureichende Daten“ oder verwenden Sie eine Ramp‑Baseline statt eines niedrigen Scores.
- Saisonale Nutzung: vergleichen Sie mit dem vorherigen Account‑Zeitraum oder Kohortenbenchmarks statt mit einem universellen Schwellenwert.
- Ausfälle und Tracking‑Gaps: markieren Sie betroffene Fenster und bestrafen Kunden nicht für Ihre Downtime.
Berechtigungen und Datenschutzkontrollen
Minimieren Sie PII standardmäßig: speichern Sie nur, was für Adoption‑Monitoring nötig ist. Wenden Sie rollenbasierte Zugriffe in der Web‑App an, protokollieren Sie, wer Daten angesehen/exportiert hat, und redigieren Sie Exporte, wenn Felder nicht erforderlich sind (z. B. E‑Mails in CSVs verbergen).
Runbooks und Governance‑Gewohnheiten erstellen
Schreiben Sie kurze Runbooks für Incident Response: wie man Scoring pausiert, Daten backfillt und historische Jobs neu ausführt. Überprüfen Sie Customer‑Success‑Metriken und Score‑Gewichte regelmäßig — monatlich oder quartalsweise — um Drift zu vermeiden, während Ihr Produkt sich weiterentwickelt. Für Prozess‑Abstimmung verlinken Sie Ihr internes Checklist‑Dokument von /blog/health-score-governance.
Validieren, iterieren und den Health‑Score skalieren
Validierung ist der Punkt, an dem ein Health‑Score aufhört, nur eine „nett aussehende Grafik“ zu sein, und anfängt, genug Vertrauen zu erzeugen, um zu handeln. Behandeln Sie Ihre erste Version als Hypothese, nicht als endgültige Antwort.
Pilot durchführen und gegen menschliches Urteil kalibrieren
Starten Sie mit einer Pilotgruppe von Accounts (z. B. 20–50 über Segmente verteilt). Vergleichen Sie für jeden Account Score und Risiko‑Gründe mit der Einschätzung Ihres CSM.
Suchen Sie nach Mustern:
- Scores, die konsequent höher/niedriger als das CSM‑Urteil sind (Kalibrierung)
- „False‑Alarms“ (hohes Risiko, aber Account stabil) vs. „Misses“ (gesund, aber churnt)
- Gründe, die nicht mit der Realität übereinstimmen (Erklärbarkeitslücken)
Messen, ob es tatsächlich nützlich ist
Accuracy ist wichtig, aber Nützlichkeit zahlt aus. Tracken Sie operative Outcomes wie:
- Time‑to‑detect Risk (wie früh Sie ein Problem flaggen)
- Outreach‑Erfolgsrate (Anteil der riskanten Accounts, die sich nach Intervention verbessern)
- Churn‑Reduktions‑Proxys (Bewegungen in Renewal‑Wahrscheinlichkeit, Expansion‑Signale, Support‑Belastung)
Änderungen sicher mit Versionierung testen
Wenn Sie Schwellen, Gewichte oder Signale anpassen, behandeln Sie das als neue Modellversion. A/B‑testen Sie Versionen auf vergleichbaren Kohorten oder Segmenten und behalten Sie historische Versionen, um zu erklären, warum Scores sich verändern.
Feedback in der UI sammeln
Fügen Sie eine leichte Kontrolle wie „Score fühlt sich falsch an“ plus einen Grund hinzu (z. B. „aktueller Onboarding‑Abschluss nicht reflektiert“, „Nutzung ist saisonal“, „falsches Account‑Mapping“). Leiten Sie dieses Feedback ins Backlog und taggen Sie es mit Account und Score‑Version für schnellere Fehlerbehebung.
Skalieren mit einer Roadmap
Sobald der Pilot stabil ist, planen Sie Skalierungsarbeiten: tiefere Integrationen (CRM, Billing, Support), Segmentierung (nach Plan, Branche, Lifecycle), Automatisierung (Tasks und Playbooks) und Self‑Serve‑Setup, damit Teams Views ohne Engineering anpassen können.
Während Sie skalieren, halten Sie die Build/Iterate‑Schleife kurz. Teams nutzen oft Koder.ai, um neue Dashboard‑Seiten zu erstellen, API‑Shapes zu verfeinern oder Workflow‑Features (Tasks, Exports, rollback‑fähige Releases) direkt aus dem Chat zu liefern — besonders hilfreich, wenn Sie Ihr Health‑Score‑Modell versionieren und UI + Backend‑Änderungen schnell ausliefern müssen.