Ziele und Scope für die Zuverlässigkeitsverfolgung festlegen
Bevor Sie Metriken wählen oder Dashboards bauen, entscheiden Sie, wofür Ihre Zuverlässigkeits‑App verantwortlich ist — und wofür nicht. Ein klarer Scope verhindert, dass das Tool zu einem alles‑auffangenden „Ops‑Portal“ wird, dem niemand vertraut.
Definieren, was Sie überwachen
Beginnen Sie mit einer Liste der internen Tools, die die App abdecken soll (z. B. Ticketing, Payroll, CRM‑Integrationen, Daten‑Pipelines) und der Teams, die sie besitzen oder darauf angewiesen sind. Seien Sie explizit bei Abgrenzungen: „Kunden‑Frontend“ kann out of scope sein, während „interne Admin‑Konsole“ inbegriffen ist.
Einigung darüber, was „Zuverlässigkeit“ hier bedeutet
Organisationen nutzen das Wort unterschiedlich. Schreiben Sie Ihre Arbeitsdefinition in einfacher Sprache nieder — typischerweise eine Mischung aus:
- Verfügbarkeit: können Leute bei Bedarf darauf zugreifen?
- Latenz: ist es schnell genug, um nutzbar zu sein?
- Fehler: schlägt es in einer für Nutzer wahrnehmbaren Weise fehl (Timeouts, Job‑Fehler, falsche Antworten)?
Wenn Teams uneins sind, vergleicht Ihre App am Ende Äpfel mit Birnen.
Entscheiden Sie die gewünschten Outcomes
Wählen Sie 1–3 primäre Outcomes, z. B.:
- Schnellere Erkennung von Problemen (kürzere „time to notice“)
- Klareres Reporting für Manager und Stakeholder
- Weniger wiederkehrende Incidents durch bessere Nachverfolgung
Diese Outcomes leiten später, was Sie messen und wie Sie es darstellen.
Nutzer und Rollen identifizieren
Listen Sie auf, wer die App nutzt und welche Entscheidungen diese Personen treffen: Ingenieure, die Incidents untersuchen; Support, der eskaliert; Manager, die Trends prüfen; Stakeholder, die Status‑Updates brauchen. Das prägt Terminologie, Berechtigungen und Detailebene in den Views.
Die relevanten Reliability‑Metriken wählen (SLIs/SLOs)
Zuverlässigkeitsverfolgung funktioniert nur, wenn alle wissen, was „gut“ bedeutet. Beginnen Sie damit, drei ähnlich klingende Begriffe zu trennen.
SLIs vs SLOs vs SLAs (einfach erklärt)
Ein SLI (Service Level Indicator) ist eine Messung: „Welcher Prozentsatz der Requests war erfolgreich?“ oder „Wie lange geladen haben Seiten?“
Ein SLO (Service Level Objective) ist das Ziel für diese Messung: „99,9 % Erfolg über 30 Tage.“
Ein SLA (Service Level Agreement) ist ein Versprechen mit Konsequenzen, üblicherweise extern‑gerichtet (Credits, Strafen). Für interne Tools setzen Sie oft SLOs ohne formelle SLAs — genug, um Erwartungen zu synchronisieren, ohne Zuverlässigkeit in Vertragsrecht zu verwandeln.
Halten Sie es vergleichbar und leicht zu erklären. Ein praktisches Minimum ist:
- Uptime/Verfügbarkeit: war das Tool erreichbar?
- Antwortzeit: wie schnell reagierten Schlüsselpages oder Endpunkte?
- Fehlerrate: welcher Anteil der Checks/Requests schlug fehl (5xx, Timeouts, bekannte Fehlerzustände)?
Fügen Sie nicht mehr hinzu, bis Sie beantworten können: „Welche Entscheidung würde diese Metrik treffen?“
Zeitfenster wählen, die zur Wahrnehmung passen
Nutzen Sie rollende Fenster, damit Scorecards kontinuierlich aktualisieren:
- 7 Tage: erkennt Regressionen schnell
- 30 Tage: Monatsreporting und Trends
- 90 Tage: Stabilität über Quartale
Incidents mit klaren Severity‑Stufen definieren
Die App sollte Metriken in Handlungen übersetzen. Definieren Sie Severity‑Stufen (z. B. Sev1–Sev3) und explizite Trigger wie:
- Sev1: Tool down oder kritischer Workflow blockiert für X Minuten
- Sev2: starke Verschlechterung (z. B. Fehlerrate über Y% für Z Minuten)
- Sev3: kleinere Probleme oder intermittierende Ausfälle
Diese Definitionen sorgen dafür, dass Alerting, Incident‑Timelines und Error‑Budget‑Verfolgung teamübergreifend konsistent sind.
Datenquellen und Ingest‑Ansatz planen
Eine Reliability‑Tracking‑App ist nur so glaubwürdig wie die Daten darunter. Bevor Sie Ingest‑Pipelines bauen, kartieren Sie jedes Signal, das Sie als „Wahrheit“ betrachten, und notieren Sie, welche Frage es beantwortet (Verfügbarkeit, Latenz, Fehler, Deploy‑Impact, Incident‑Response).
Vorhandene Datenquellen kartieren
Die meisten Teams können mit einer Mischung abdecken:
- Status‑Checks / synthetische Probes (Uptime und grundlegende Antwortzeit)
- Metriken (Latenz‑Percentiles, Fehlerraten, Sättigung)
- Logs (Fehlerzahlen, Top‑fehlerhafte Endpunkte)
- Traces (wo Latenz über Abhängigkeiten verteilt ist)
- Ticketing/Incident‑Tools (Incident‑Start/Ende, Severity, Owner, Postmortem‑Links)
Seien Sie klar, welche Systeme autoritativ sind. Beispielsweise könnte Ihr „Uptime‑SLI“ ausschließlich aus synthetischen Probes stammen, nicht aus Server‑Logs.
Push vs. Pull entscheiden (und wie oft)
- Pull eignet sich für APIs (Prometheus, Cloud‑Monitoring, Ticketing): Ihre App pollt im Zeitplan.
- Push ist besser für hochvolumige Events (Deploys, Incidents, Alerts): Systeme senden Webhooks/Events an Ihre App.
Legen Sie Update‑Frequenzen nach Use Case fest: Dashboards können alle 1–5 Minuten aktualisieren, Scorecards stündlich/täglich berechnet werden.
Identifikatoren und Ownership normalisieren
Erstellen Sie konsistente IDs für Tools/Services, Umgebungen (prod/stage) und Owner. Vereinbaren Sie Namensregeln früh, damit „Payments‑API“, „payments_api“ und „payments“ nicht zu drei verschiedenen Entitäten werden.
Retention und Privacy
Planen Sie, was Sie wie lange behalten (z. B. Roh‑Events 30–90 Tage, Tages‑Rollups 12–24 Monate). Vermeiden Sie das Ingesten sensibler Payloads; speichern Sie nur Metadaten, die für die Zuverlässigkeitsanalyse nötig sind (Timestamps, Statuscodes, Latenz‑Buckets, Incident‑Tags).
Datenmodell und DB‑Schema entwerfen
Ihr Schema sollte zwei Dinge einfach machen: Alltagsfragen beantworten („Ist dieses Tool healthy?“) und rekonstruieren, was während eines Incidents passiert ist („Wann begannen Symptome, wer hat was geändert, welche Alerts haben gefeuert?“). Starten Sie mit einer kleinen Menge Kern‑Entitäten und machen Sie Beziehungen explizit.
Kern‑Entitäten (minimal starten)
- Tool/Service: das überwachte interne Tool (Name, Beschreibung, Umgebung, Kritikalität).
- Check: ein spezifischer Uptime‑ oder synthetischer Check für ein Tool (Typ, Ziel‑URL, Schedule, Enabled).
- Metric: Time‑Series‑Datapoints (Latenz, Erfolgsrate, Fehleranzahl) verknüpft mit Tool oder Check.
- SLO: Ziel und Evaluationsfenster (z. B. 99,9 % über 30 Tage) plus Error‑Budget‑Settings.
- Incident: ein zuverlässigkeitsrelevantes Ereignis (Severity, Status, Start/Ende, Zusammenfassung).
- Event: ein Timeline‑Eintrag für Incidents (Statuswechsel, Notizen, Alert empfangen, Maßnahme angewandt).
- Owner: Team oder Person, die für das Tool verantwortlich ist.
Beziehungen, die Abfragen einfach halten
Ein praktisches Minimum ist:
- Tool hat viele Checks (und kann viele SLOs haben).
- Check hat viele Metrics (oder Metric‑Streams).
- Incident gehört zu Tool, und Incident hat viele Events für die Timeline.
- Tool gehört zu Owner (oder many‑to‑many, wenn gemeinsame Ownership üblich ist).
Diese Struktur unterstützt Dashboards („Tool → aktueller Status → jüngste Incidents“) und Drill‑downs („Incident → Events → zugehörige Checks und Metriken").
Audit‑Felder und Tagging
Fügen Sie Audit‑Felder überall dort hinzu, wo Verantwortlichkeit und Historie nötig sind:
created_by, created_at, updated_atstatus plus Status‑Change‑Tracking (entweder in der Event‑Tabelle oder in einer eigenen History‑Tabelle)
Außerdem flexible Tags für Filterung und Reporting (z. B. Team, Kritikalität, System, Compliance). Eine tool_tags‑Join‑Tabelle (tool_id, key, value) hält Tags konsistent und vereinfacht spätere Scorecards und Rollups.
Tech‑Stack und Deployment‑Modell auswählen
Ihr Reliability‑Tracker sollte im besten Sinn langweilig sein: einfach zu betreiben, leicht zu ändern und gut zu supporten. Der „richtige“ Stack ist meist der, den Ihr Team ohne Heldentaten betreiben kann.
Mit dem starten, was Ihr Team bereits ausliefert
Wählen Sie ein Mainstream‑Webframework, das Ihr Team gut kennt — Node/Express, Django oder Rails sind solide Optionen. Priorisieren Sie:
- Klare Konventionen (damit neue Beitragende sich zurechtfinden)
- Gute Bibliotheken für Auth, Background‑Jobs und Charts
- Vorhersehbare Upgrade‑Pfade
Wenn Sie interne Integrationen (SSO, Ticketing, Chat) planen, wählen Sie das Ökosystem, in dem diese Integrationen am einfachsten sind.
Wenn Sie die erste Iteration beschleunigen wollen, kann eine Low‑Code/No‑Code‑Plattform wie Koder.ai ein praktischer Startpunkt sein: Sie beschreiben Entitäten (Tools, Checks, SLOs, Incidents), Workflows (Alert → Incident → Postmortem) und Dashboards im Chat und generieren schnell ein funktionierendes Web‑App‑Gerüst. Koder.ai zielt oft auf React im Frontend und Go + PostgreSQL im Backend, was gut zum „langweilig wartbaren“ Default‑Stack vieler Teams passt — und Sie können den Quellcode exportieren, wenn Sie später vollständig manuell weiterentwickeln.
Zuerst DB, dann unterstützende Komponenten
Für die meisten internen Reliability‑Apps ist PostgreSQL die richtige Default‑Wahl: es eignet sich für relationale Reports, zeitbasierte Abfragen und Auditing.
Fügen Sie zusätzliche Komponenten nur hinzu, wenn sie ein echtes Problem lösen:
- Cache (z. B. Redis), wenn Dashboards langsam sind oder Sie von Upstream‑APIs rate‑limitiert werden
- Queue/Background‑Jobs (Redis + Worker, Sidekiq, Celery, BullMQ) für Polling, Benachrichtigungen und Reportgenerierung
Hosting und Deployment
Entscheiden Sie zwischen:
- Interner Cloud/Kubernetes, wenn enger Netzwerkzugang zu internen Diensten nötig ist
- PaaS, wenn Sie einfachere Ops und schnelles Iterieren bevorzugen
Standardisieren Sie dev/staging/prod und automatisieren Sie Deploys (CI/CD), damit Änderungen nicht heimlich Zuverlässigkeitszahlen verändern. Wenn Sie eine Plattform‑Lösung (inkl. Koder.ai) nutzen, achten Sie auf Environment‑Separation, Deployment/Hosting und schnelle Rollbacks (Snapshots), damit Sie gefahrlos iterieren können.
Konfigurationsmanagement, dem man traut
Dokumentieren Sie Konfiguration an einem Ort: Environment‑Variablen, Secrets und Feature‑Flags. Halten Sie eine klare „How to run locally“‑Anleitung und ein minimales Runbook (Was tun, wenn Ingest stoppt, Queue vollläuft oder DB Limits erreicht). Eine kurze Seite in /docs reicht oft aus.
UX‑Design: Dashboards, Drill‑downs und Workflows
SLOs in Dashboards verwandeln
Erzeuge React‑Ansichten für Scorecards und Drilldowns; Go und PostgreSQL werden für dich generiert.
Eine Reliability‑Tracking‑App ist dann erfolgreich, wenn Menschen zwei Fragen in Sekunden beantworten können: „Sind wir okay?“ und „Was ist zu tun?“ Gestalten Sie Bildschirme um diese Entscheidungen herum, mit klarer Navigation Overview → spezifisches Tool → spezifischer Incident.
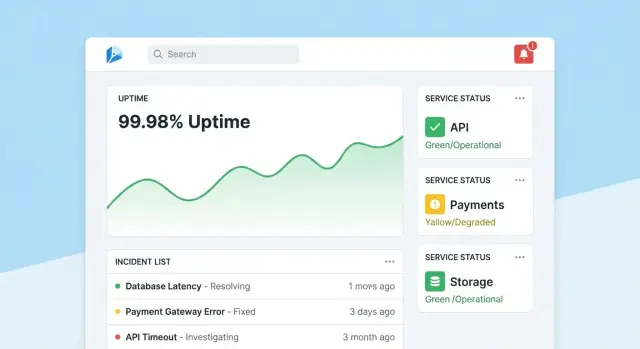
Homepage: schnelle Gesundheitsübersicht
Machen Sie die Startseite zu einem kompakten Kommandozentrum. Führen Sie mit einer Gesamtgesundheits‑Zusammenfassung (z. B. Anzahl Tools, die SLOs erfüllen, aktive Incidents, größte aktuelle Risiken), dann zeigen Sie jüngste Incidents und Alerts mit Statusbadges.
Halten Sie die Default‑Ansicht ruhig: heben Sie nur das hervor, was Aufmerksamkeit braucht. Jeder Tile sollte einen direkten Drill‑down zum betroffenen Tool oder Incident haben.
Jede Tool‑Seite sollte beantworten „Ist dieses Tool zuverlässig genug?“ und „Warum/warum nicht?“. Einschließlich:
- Aktueller SLO‑Status mit einfachem Pass/Fail und verbleibendem Error‑Budget
- Charts für Uptime, Latenz oder Fehlerrate über auswählbare Zeiträume
- Jüngste Änderungen (Deploys, Config‑Edits, Check‑Updates), damit Muster sichtbar werden
- Runbooks und Owners: prominenter „Was tun“‑Bereich mit Links und Kontakten
Gestalten Sie Charts für Nicht‑Experten: Einheiten beschriften, SLO‑Schwellen markieren und kleine Erklärungen (Tooltips) statt dichter technischer Controls.
Incident‑Seite: gemeinsamer Kontext und Timeline
Eine Incident‑Seite ist ein lebendiges Dokument. Enthalten Sie eine Timeline (auto‑erfasste Events wie Alert gefeuert, acknowledged, mitigiert), menschliche Updates, betroffene Nutzer und ergriffene Maßnahmen.
Machen Sie Updates leicht veröffentlichbar: ein Textfeld, vordefinierte Status (Investigating/Identified/Monitoring/Resolved) und optionale interne Notizen. Beim Schließen eines Incidents sollte eine „Postmortem starten“‑Aktion Fakten aus der Timeline vorbefüllen.
Admin‑Pages: Ownership und Konsistenz
Admins brauchen einfache Screens zur Verwaltung von Tools, Checks, SLO‑Zielen und Owners. Optimieren Sie auf Korrektheit: sinnvolle Defaults, Validierung und Warnungen, wenn Änderungen Reporting beeinflussen. Zeigen Sie eine sichtbare „zuletzt bearbeitet“‑Spur, damit Leute den Zahlen vertrauen.
Authentifizierung, Berechtigungen und Audit‑Trails umsetzen
Zuverlässigkeitsdaten bleiben nur nützlich, wenn Leute ihnen vertrauen. Das bedeutet: jede Änderung einer Identität zuordnen, beschränken, wer hochwirksame Änderungen macht, und eine klare Historie führen, auf die Sie in Reviews verweisen können.
Authentifizierung: das Identity System der Firma nutzen
Für ein internes Tool standardmäßig SSO (SAML) oder OAuth/OIDC via IdP (Okta, Azure AD, Google Workspace). Das reduziert Passwort‑Management und macht On/Offboarding automatisch.
Praktische Details:
- Erzwingen Sie MFA über den IdP (nicht selbst neu implementieren).
- Map IdP‑Gruppen beim Login auf App‑Rollen.
- Kurze Session‑Lifetimes und manuelles Sign‑out unterstützen.
Berechtigungen: rollenbasiert mit „geschützten Aktionen“
Starten Sie mit einfachen Rollen und fügen Sie feinere Regeln nur bei Bedarf hinzu:
- Viewer: read‑only Dashboards und Scorecards für Stakeholder.
- Editor: Checks, Incidents und Notizen erstellen/aktualisieren.
- Admin: SLO‑Definitionen, Thresholds, Integrationen, User/Role‑Mapping verwalten.
Schützen Sie Aktionen, die Reliabilitätsoutcomes oder Reporting‑Narrative ändern:
- Nur Admins dürfen SLO‑Ziele, Alert‑Thresholds oder Data‑Source‑Mappings ändern.
- Beschränken Sie, wer Incidents schließen oder als „resolved“ markieren darf, und verlangen Sie eine Resolutions‑Zusammenfassung.
Audit‑Trails: unveränderliche Änderungs‑Historie
Protokollieren Sie jede Änderung an SLOs, Checks und Incident‑Feldern mit:
- wer (User + Rolle)
- wann (Timestamp)
- was sich änderte (vorher/nachher)
- woher es kam (UI, API, Automation)
Machen Sie Audit‑Logs durchsuchbar und sichtbar von den Detailseiten aus (z. B. eine Incident‑Seite zeigt ihre komplette Änderungshistorie). Das macht Reviews faktisch und reduziert Hin‑und‑Her in Postmortems.
Monitoring‑Checks und Uptime‑Erfassung bauen
Monitoring ist die „Sensor‑Schicht“ Ihrer Reliability‑App: sie verwandelt reales Verhalten in vertrauenswürdige Daten. Für interne Tools sind synthetische Checks oft der schnellste Weg, weil Sie definieren, was „healthy“ bedeutet.
Starten Sie mit einem kleinen Satz Check‑Typen, die die meisten internen Apps abdecken:
- HTTP Ping: prüfen, ob der Service antwortet (Statuscode, TLS, Basis‑Header).
- Endpoint‑Validation: eine bekannte URL aufrufen und etwas Sinnvolles validieren (erwarteter JSON‑Shape, ein Schlüsselstring im HTML oder Payload eines Health‑Endpoints).
- Login‑freier „Smoke“‑Pfad: falls möglich, einen read‑only Flow testen, der die User‑Experience widerspiegelt (z. B. Dashboard laden und prüfen, ob es rendert).
Halten Sie Checks deterministisch. Wenn eine Validierung wegen sich ändernder Inhalte fehlschlagen kann, erzeugen Sie Rauschen und mindern Vertrauen.
Uptime und Latenz sammeln (und sinnvoll speichern)
Für jeden Check‑Run erfassen Sie:
- Timestamp (Start und Ende)
- Result: up/down/unknown
- Latency: Gesamtdauer (optional DNS/connect/TTFB, falls gemessen)
- Reason: Fehlercode, Timeout, Validierungsfehler oder Exception‑Meldung
Speichern Sie Daten als Time‑Series‑Events (eine Zeile pro Check‑Run) oder als aggregierte Intervalle (z. B. Minutentransaktionen mit Zählungen und p95‑Latenzen). Events sind gut zum Debuggen; Rollups für schnelle Dashboards. Viele Teams machen beides: Roh‑Events 7–30 Tage behalten und Rollups für langfristiges Reporting.
Ausfälle vs. fehlende Daten explizit behandeln
Ein fehlendes Check‑Result darf nicht automatisch „down“ bedeuten. Fügen Sie einen expliziten unknown‑Status für Fälle wie:
- Checker‑Worker gestoppt
- Netzwerkpartition zwischen Checker und Ziel
- Konfiguration während Lauf entfernt
Das verhindert aufgeblähte Downtime‑Werte und macht Monitoring‑Lücken selbst zu einem operativen Thema.
Checks per Background‑Jobs planen
Nutzen Sie Background‑Worker (cron‑like Scheduling, Queues), um Checks in festen Intervallen auszuführen (z. B. alle 30–60 Sekunden für kritische Tools). Bauen Sie Timeouts, Retries mit Backoff und Concurrency‑Limits ein, damit Ihr Checker interne Services nicht überlastet. Persistieren Sie jedes Run‑Result — auch Fehler — damit Ihr Uptime‑Dashboard aktuellen Status und verlässliche Historie zeigt.
Alerting und Benachrichtigungs‑Flows erstellen
Starte mit Go und Postgres
Generiere ein wartbares Backend mit PostgreSQL‑Schemas, die auf Tools, Checks, SLOs und Incidents abgestimmt sind.
Alerts sind der Punkt, an dem Zuverlässigkeitsverfolgung zu Handlung wird. Ziel: die richtigen Personen mit dem richtigen Kontext zur richtigen Zeit informieren — ohne alle zu überfluten.
Alerts an SLOs koppeln (nicht nur an Thresholds)
Definieren Sie Alert‑Regeln, die direkt zu Ihren SLIs/SLOs passen. Zwei praktische Muster:
- Burn‑Rate Alerts: page, wenn das Error‑Budget so schnell verbraucht wird, dass das SLO verfehlt wird, falls nichts passiert.
- Threshold‑Breaches: warnen, wenn eine Metrik eine klare Grenze überschreitet (z. B. Verfügbarkeit < 99,5 % über 15 Minuten).
Speichern Sie für jede Regel das „Warum“ zusammen mit dem „Was“: welches SLO betroffen ist, das Evaluationsfenster und die vorgesehene Severity.
Benachrichtigungen handlungsorientiert machen
Schicken Sie Nachrichten über Kanäle, in denen Teams bereits arbeiten (Email, Slack, MS Teams). Jede Nachricht sollte enthalten:
- Eine Einzeiler‑Zusammenfassung (Service + Symptom + Severity)
- Einen direkten Link zur zuständigen Dashboard‑Ansicht (z. B. /services/payments?window=1h)
- Einen Link zur Incident‑Seite, falls erstellt (z. B. /incidents/123)
Vermeiden Sie rohe Metrik‑Dumps. Geben Sie einen kurzen „Next Step“ wie „Check recent deploys“ oder „Open logs“ mit.
Rauschen reduzieren: Dedupe, Grouping, Quiet‑Hours
Implementieren Sie:
- Deduplizierung (gleicher Alert‑Fingerprint → bestehender Thread wird aktualisiert)
- Grouping (ein Incident sammelt mehrere verwandte Alerts)
- Quiet Hours und Routing‑Regeln, damit Low‑Severity Alerts nicht On‑Call wecken
Eskalation und On‑Call‑Routing unterstützen
Auch intern brauchen Leute Kontrolle. Fügen Sie manuelle Eskalation (Button auf Alert/Incident‑Seite) hinzu und integrieren Sie mit On‑Call‑Tools, falls vorhanden (PagerDuty/Opsgenie), oder zumindest eine konfigurierbare Rotation, die in der App gespeichert ist.
Incident‑Management und Postmortem‑Funktionen
Incident‑Management verwandelt „wir haben ein Alert“ in eine gemeinsame, nachverfolgbare Antwort. Bauen Sie das in Ihre App, damit Leute vom Signal zur Koordination kommen, ohne zwischen Tools zu springen.
One‑Click Incident‑Erstellung
Ermöglichen Sie, einen Incident direkt aus einem Alert, einer Service‑Seite oder einem Uptime‑Chart zu erstellen. Befüllen Sie Schlüsselfelder vor (Service, Umgebung, Alert‑Source, first seen time) und vergeben Sie eine eindeutige Incident‑ID.
Ein guter Default‑Satz Felder hält das leichtgewichtig: Severity, betroffener Nutzerkreis (interne Teams), aktueller Owner und Links zum auslösenden Alert.
Status‑Lifecycle und Zusammenarbeit
Verwenden Sie einen einfachen Lifecycle, der zu realer Teamarbeit passt:
- Open → Investigating → Mitigated → Resolved
Jeder Statuswechsel sollte erfassen, wer ihn wann gemacht hat. Fügen Sie Timeline‑Updates (kurze, timestampete Notizen), Anhänge und Links zu Runbooks/Tickets hinzu (z. B. /runbooks/payments-retries oder /tickets/INC-1234). Das wird der Single‑Thread für „was passiert ist und was wir getan haben“.
Postmortems mit Action‑Items
Postmortems sollten schnell startbar und konsistent prüfbar sein. Bieten Sie Templates mit:
- Zusammenfassung, Impact, Detection und Root Cause
- Beitragsfaktoren (inkl. Prozesslücken)
- Was funktionierte / was nicht
- Follow‑Ups mit Ownern und Fälligkeitsdaten
Verknüpfen Sie Action‑Items zurück zum Incident, verfolgen Sie den Abschluss und zeigen Sie überfällige Items in Team‑Dashboards an. Wenn Sie „Learning Reviews“ unterstützen, bieten Sie einen „blameless“ Modus, der System‑ und Prozessänderungen statt individuelle Fehler in den Fokus rückt.
Reporting und Reliability‑Scorecards
Entwirf dein MVP für einen Zuverlässigkeits‑Tracker
Beschreibe Tools, SLIs und Workflows im Chat und erhalte schnell ein funktionierendes App-Gerüst.
Reporting ist der Punkt, an dem Zuverlässigkeitsverfolgung zu Entscheidungsgrundlage wird. Dashboards helfen Operatoren; Scorecards helfen Führungskräften zu verstehen, ob interne Tools besser werden, wo investiert werden muss und wie „gut“ aussieht.
Was in eine Scorecard gehört
Bauen Sie eine konsistente, wiederholbare Ansicht pro Tool (und optional pro Team), die schnell Fragen beantwortet:
- SLO‑Compliance über Zeit: aktueller Zeitraum (Woche/Monat/Quartal) und Trendlinie gegen das SLO‑Ziel.
- Top‑unzuverlässige Tools: Rangliste nach verfehlten SLOs, höchsten Downtime‑Minuten oder stärkstem Error‑Budget‑Burn.
- MTTR: Median und p90 Time‑to‑Restore, damit ein einzelner langer Incident kein Muster verdeckt.
- Incident‑Anzahl: Gesamtanzahl plus Severity‑Breakdown (Sev1–Sev3) mit Vergleich zum Vorzeitraum.
Fügen Sie, wo möglich, leichten Kontext hinzu: „SLO verfehlt wegen 2 Deploys“ oder „Meiste Downtime durch Dependency X“, ohne das Report in einen vollständigen Incident‑Review zu verwandeln.
Filter, die Führungskreise nutzen
Führungskräfte wollen selten „alles“. Fügen Sie Filter für Team, Tool‑Kritikalität (Tier 0–3) und Zeitfenster hinzu. Stellen Sie sicher, dass dasselbe Tool in mehreren Rollups erscheinen kann (z. B. Plattformteam besitzt es, Finance nutzt es).
Zusammenfassungen und Exporte
Bieten Sie wöchentliche und monatliche Zusammenfassungen, die außerhalb der App geteilt werden können:
- One‑Click CSV‑Export für Tabellen
- Sauberer PDF‑Export für Status‑Reviews
Halten Sie die Narrative konsistent („Was hat sich seit letztem Zeitraum geändert?“ „Wo sind wir über Budget?“). Wenn Stakeholder einen Primer brauchen, verlinken Sie eine kurze Einführung wie /blog/sli-slo-basics.
Sicherheit, Datenqualität und operatives Härtung
Ein Reliability‑Tracker wird schnell zur Quelle der Wahrheit. Behandeln Sie ihn wie ein Produktionssystem: secure by default, resistent gegen schlechte Daten und leicht wiederherstellbar, wenn etwas schiefgeht.
Oberfläche der App schützen
Sperren Sie alle Endpoints — auch „internal‑only“:
- Validieren Sie Eingaben an der Grenze (Typen, Bereiche, erlaubte Enums, Max‑Payload) und lehnen Sie unbekannte Felder ab.
- Fügen Sie Rate‑Limiting pro User/Service‑Token hinzu, um laute Clients von Ingest oder Dashboards fernzuhalten.
- Nutzen Sie parameterisierte Queries und sichere ORM‑Pattern, um Injections zu vermeiden.
Secrets und Access Control
Halten Sie Credentials aus dem Code und aus Logs heraus.
Speichern Sie Secrets im Secret‑Manager und rotieren Sie sie. Geben Sie der Web‑App Least‑Privilege DB‑Zugriff: getrennte Read/Write‑Rollen, Zugriff nur auf benötigte Tabellen und, wo möglich, kurzlebige Credentials. Verschlüsseln Sie Daten in Transit (TLS) zwischen Browser↔App und App↔DB.
Datenqualitäts‑Guardrails
Reliability‑Metriken sind nur nützlich, wenn die zugrundeliegenden Events vertrauenswürdig sind.
Fügen Sie serverseitige Prüfungen für Timestamps (Timezone/Clock‑Skew), Pflichtfelder und Idempotency‑Keys hinzu, um Retries zu deduplizieren. Verfolgen Sie Ingest‑Fehler in einer Dead‑Letter‑Queue oder Tabelle „Quarantine“, damit schlechte Events Dashboards nicht vergiften.
Operationale Basics (nicht überspringen)
Automatisieren Sie DB‑Migrations und Test‑Rollbacks. Planen Sie Backups, testen Sie regelmäßige Restore‑Prozeduren und dokumentieren Sie einen minimalen Disaster‑Recovery‑Plan (wer, was, wie lange).
Machen Sie die Reliability‑App selbst zuverlässig: Health‑Checks, Basis‑Monitoring für Queue‑Lag und DB‑Latenz und Alerts, wenn Ingest still auf Null fällt.
Rollout‑Plan und Iterations‑Roadmap
Eine Reliability‑Tracking‑App ist erfolgreich, wenn die Leute ihr vertrauen und sie wirklich nutzen. Behandeln Sie den ersten Release als Lernschleife, nicht als „Big‑Bang“ Launch.
Mit einem fokussierten Pilot starten
Wählen Sie 2–3 interne Tools, die breit genutzt werden und klare Owner haben. Implementieren Sie eine kleine Menge Checks (z. B. Homepage‑Verfügbarkeit, Login‑Success und einen Schlüssel‑API‑Endpoint) und veröffentlichen Sie ein Dashboard, das beantwortet: „Ist es up? Wenn nein, was hat sich geändert und wer ist zuständig?“
Halten Sie den Pilot sichtbar, aber begrenzt: ein Team oder kleine Gruppe Power‑User reicht, um den Flow zu validieren.
Feedback dort sammeln, wo es weh tut
Sammeln Sie in den ersten 1–2 Wochen aktiv Feedback zu:
- Was verwirrend ist (Metrik‑Namen, Charts, Filter, Definitionen)
- Was laut ist (Alerts, die keinen Nutzerimpact widerspiegeln)
- Was fehlt (Ownership, Runbooks, Links zu Incidents)
Machen Sie aus Feedback konkrete Backlog‑Items. Ein einfacher „Report an issue with this metric“‑Button auf jedem Chart fördert oft die schnellsten Einsichten zutage.
Iterieren mit Integrationen und Automatisierung
Fügen Sie Wert schrittweise hinzu: verbinden Sie zunächst Ihr Chat‑Tool für Notifications, dann Ihr Incident‑Tool für automatische Ticket‑Erstellung, dann CI/CD für Deploy‑Marker. Jede Integration sollte manuelle Arbeit reduzieren oder Time‑to‑Diagnosis verkürzen — sonst ist es nur Komplexität.
Wenn Sie schnell prototypen, erwägen Sie Koder.ai’s Planning‑Mode, um den Initialscope (Entitäten, Rollen, Workflows) zu skizzieren, bevor Sie den ersten Build generieren. Das hilft, das MVP schlank zu halten — und weil Sie Snapshots und Rollbacks nutzen können, iterieren Sie Dashboards und Ingest sicher, während Teams Definitionen verfeinern.
Erfolgsmetriken definieren und ausrollen
Bevor Sie auf mehr Teams ausrollen, definieren Sie Erfolgskriterien wie wöchentliche aktive Dashboard‑Nutzer, reduzierte Time‑to‑Detect, weniger doppelte Alerts oder konsistente SLO‑Reviews. Veröffentlichen Sie eine leichte Roadmap in /blog/reliability-tracking-roadmap und erweitern Sie Tool‑für‑Tool mit klaren Ownern und Trainingssessions.