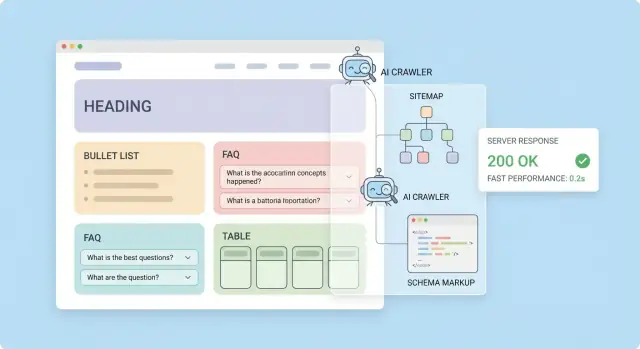
Was „AI‑optimiert“ wirklich bedeutet
„AI‑optimiert“ ist oft ein Schlagwort. Praktisch heißt es: Ihre Website ist für automatisierte Systeme leicht auffindbar, lesbar und korrekt wiederverwendbar.
Wenn man von KI‑Crawlern spricht, meint man meist Bots von Suchmaschinen, KI‑Produkten oder Datenanbietern, die Webseiten abrufen, um Funktionen wie Zusammenfassungen, Antworten, Trainingsdatensätze oder Retrieval‑Systeme zu betreiben. LLM‑Indexierung bezeichnet üblicherweise das Umwandeln Ihrer Seiten in einen durchsuchbaren Wissensspeicher (oft „gechunkter“ Text mit Metadaten), damit ein KI‑Assistent die richtige Passage abrufen und zitieren oder wiedergeben kann.
Die wirklichen Ziele
AI‑Optimierung zielt weniger auf „Ranking“ und mehr auf vier Ergebnisse ab:
- Discovery: Crawler erreichen Ihre wichtigen URLs zuverlässig.
- Parsing: Ihr Inhalt ist ohne Rätselraten lesbar (sauberes HTML, vorhersehbare Struktur).
- Attribution/Zitation: Es ist klar, wer es geschrieben hat, wann es aktualisiert wurde und welche Quellen es stützen.
- Retrieval‑Qualität: Passagen sind eigenständig, spezifisch und leicht an eine Anfrage anpassbar.
Erwartungen setzen (und was Sie kontrollieren können)
Niemand kann garantieren, dass Inhalte in einem bestimmten AI‑Index oder Modell erscheinen. Anbieter crawlen unterschiedlich, respektieren verschiedene Richtlinien und aktualisieren in unterschiedlichen Rhythmen.
Was Sie kontrollieren können, ist, Ihre Inhalte so zu gestalten, dass sie leicht zugänglich, extrahierbar und zuordenbar sind — sodass, falls sie verwendet werden, sie korrekt genutzt werden.
Was Sie bis zum Ende umsetzen werden
- Eine crawlbare Website mit klaren Zugriffsregeln (robots und Meta‑Direktiven)
- Saubere URL‑ und Canonical‑Praktiken zur Reduktion von Duplikaten
- Sitemaps und interne Links, die zentrale Seiten schnell sichtbar machen
- Inhalte, die in für Maschinen interpretierbare „Chunks“ formatiert sind
- Strukturierte Daten, die beschreiben, worum jede Seite geht
- Eine einfache
llms.txt‑Datei zur LLM‑orientierten Entdeckung
- Performance und Serverantworten, die Crawler‑Timeouts vermeiden
- Vertrauenssignale (Autoren, Daten, Quellen, Eigentum), die Zitation unterstützen
- Eine Test‑Routine, um zu verifizieren, was Bots tatsächlich sehen
Wenn Sie schnell neue Seiten und Flows bauen, hilft es, Tools zu wählen, die nicht gegen diese Anforderungen arbeiten. Teams, die z. B. Koder.ai nutzen (eine chatgetriebene Vibe‑Coding‑Plattform, die React‑Frontends und Go/PostgreSQL‑Backends erzeugt), integrieren oft SSR/SSG‑freundliche Templates, stabile Routen und konsistente Metadaten früh — so wird „AI‑ready“ zur Standardpraxis, nicht zur Nachrüstung.
Inhaltsstruktur, die LLMs leicht parsen können
LLMs und KI‑Crawler interpretieren eine Seite nicht wie ein Mensch. Sie extrahieren Text, schließen Beziehungen zwischen Ideen und versuchen, Ihre Seite einem einzelnen, klaren Intent zuzuordnen. Je vorhersehbarer Ihre Struktur, desto weniger falsche Annahmen müssen sie treffen.
Wie eine „ideale“ Seite aussieht
Starten Sie damit, die Seite im Plain‑Text leicht scanbar zu machen:
- Ein klares H1, das das Hauptversprechen der Seite wiedergibt
- Kurze Abschnitte mit beschreibenden Überschriften
- Minimales Sidebar‑Rauschen und weniger „schwebende“ Callouts, die die Hauptnarrative unterbrechen
Ein nützliches Muster: Versprechen → Zusammenfassung → Erklärung → Beleg → Nächste Schritte.
Fügen Sie ein TL;DR für schnelles Verständnis hinzu
Platzieren Sie eine kurze Zusammenfassung nah am Anfang (2–5 Zeilen). Das hilft KI‑Systemen, die Seite schnell zu klassifizieren und die Kernbehauptungen zu erfassen.
Beispiel TL;DR:
TL;DR: Diese Seite erklärt, wie man Inhalte so strukturiert, dass KI‑Crawler das Hauptthema, Definitionen und zentrale Erkenntnisse zuverlässig extrahieren können.
Pro Seite ein Hauptthema
LLM‑Indexierung funktioniert am besten, wenn jede URL einen Intent beantwortet. Wenn Sie nicht zusammenhängende Ziele mischen (z. B. „Preise“, „Integrations‑Docs“ und „Firmengeschichte“ auf einer Seite), wird die Seite schwerer zu kategorisieren und kann für falsche Anfragen auftauchen.
Wenn verwandte, aber unterschiedliche Intents abgedeckt werden müssen, teilen Sie sie auf separate Seiten auf und verbinden Sie sie per interner Verlinkung (z. B. /pricing, /docs/integrations).
Definieren Sie mehrdeutige Begriffe und fügen Sie Kontext hinzu
Wenn Ihr Publikum einen Begriff unterschiedlich interpretieren könnte, definieren Sie ihn früh.
Beispiel:
AI‑Crawler‑Optimierung: Vorbereitung von Seiteninhalten und Zugriffsregeln, sodass automatisierte Systeme Seiten zuverlässig finden, lesen und interpretieren können.
Verwenden Sie konsistente Bezeichnungen für Entitäten
Wählen Sie einen Namen für jedes Produkt, Feature, Tarif und Schlüsselkonzept — und verwenden Sie ihn überall. Konsistenz verbessert die Extraktion („Feature X“ bezieht sich immer auf dasselbe) und reduziert Entitätsverwirrung, wenn Modelle Ihre Seiten zusammenfassen oder vergleichen.
Überschriften, Listen und Tabellen: Machen Sie Seiten Chunk‑freundlich
Die meisten LLM‑Indexing‑Pipelines zerlegen Seiten in Chunks und speichern/ruft später die bestpassenden Stücke ab. Ihre Aufgabe ist, diese Chunks offensichtlich, eigenständig und leicht zitierbar zu machen.
Verwenden Sie eine klare H1–H3‑Hierarchie
Behalten Sie ein H1 pro Seite (das Versprechen der Seite), verwenden Sie H2 für die Hauptabschnitte, die jemand suchen könnte, und H3 für Unterthemen.
Eine einfache Regel: Wenn Sie aus Ihren H2s ein Inhaltsverzeichnis machen könnten, das die ganze Seite beschreibt, sind Sie auf dem richtigen Weg. Diese Struktur hilft Retrieval‑Systemen, den passenden Kontext an jeden Chunk zu binden.
Schreiben Sie Überschriften, die für sich stehen
Vermeiden Sie vage Bezeichnungen wie „Überblick“ oder „Mehr Infos“. Formulieren Sie Überschriften so, dass sie die Absicht des Nutzers beantworten:
- „Preisgestaltung und was enthalten ist“
- „Unterstützte Dateiformate und Größenlimits“
- „Wie lange die Einrichtung dauert (typische Zeitrahmen)"
Wenn ein Chunk aus dem Kontext gezogen wird, wird die Überschrift oft sein „Titel“. Machen Sie ihn aussagekräftig.
Bevorzugen Sie kurze Absätze, Listen und Tabellen
Nutzen Sie kurze Absätze (1–3 Sätze) für bessere Lesbarkeit und fokussierte Chunks.
Aufzählungen eignen sich gut für Anforderungen, Schritte und Feature‑Übersichten. Tabellen sind großartig für Vergleiche, weil sie Struktur bewahren.
| Plan | Am besten für | Wichtiges Limit |
|---|
| Starter | Ausprobieren | 1 Projekt |
| Team | Zusammenarbeit | 10 Projekte |
FAQ für direkte Antworten hinzufügen
Ein kleines FAQ mit klaren, vollständigen Antworten verbessert die Extrahierbarkeit:
F: Unterstützen Sie CSV‑Uploads?
A: Ja — CSVs bis 50 MB pro Datei.
„Nächste Schritte“ und „Weiterführende Lektüre“ einfügen
Schließen Sie zentrale Seiten mit Navigationsblöcken ab, sodass Nutzer und Crawler intentbasierte Pfade folgen können:
- Nächste Schritte: /pricing, /signup
- Weiterführende Lektüre: /blog/technical-seo-for-ai, /docs/sitemaps
Rendering: Stellen Sie sicher, dass Inhalte ohne JavaScript existieren
Nicht alle KI‑Crawler verhalten sich wie ein kompletter Browser. Viele können das rohe HTML sofort abrufen und lesen, haben aber Probleme damit, JavaScript auszuführen, auf API‑Aufrufe zu warten oder die Seite nach Hydration zusammenzusetzen. Wenn Ihr Schlüsselinhalt erst nach clientseitigem Rendering erscheint, riskieren Sie, von Systemen übersehen zu werden, die LLM‑Indexierung durchführen.
HTML‑Crawling vs. JavaScript‑gerenderte Seiten
Bei einer traditionellen HTML‑Seite lädt der Crawler das Dokument und kann Überschriften, Absätze, Links und Metadaten sofort extrahieren.
Bei einer stark JS‑basierten Seite kann die erste Antwort eine dünne Shell sein (einige divs und Skripte). Der sinnvolle Text erscheint erst, wenn Skripte laufen, Daten geladen und Komponenten gerendert sind. Bei diesem zweiten Schritt sinkt die Abdeckung: manche Crawler führen kein JS aus; andere tun es nur mit Timeouts oder Teilunterstützung.
Für kritische Inhalte serverseitig rendern (oder hybrid)
Für Seiten, die Sie indexiert haben möchten — Produktbeschreibungen, Preise, FAQs, Docs — bevorzugen Sie:
- Server‑Side Rendering (SSR): Inhalt ist in der initialen HTML‑Antwort enthalten
- Static Generation (SSG/ISR): vorgefertigtes HTML mit periodischen Aktualisierungen
- Hybrides Rendering: rendern Sie den Hauptinhalt serverseitig und verbessern Sie ihn mit JS für Interaktivität
Ziel ist nicht „kein JavaScript“, sondern sinnvolles HTML zuerst, JS danach.
Verstecken Sie wichtigen Text nicht hinter „unsichtbarer“ UI
Tabs, Akkordeons und „Mehr lesen“‑Kontrollen sind in Ordnung, wenn der Text im DOM enthalten ist. Problematisch wird es, wenn Tab‑Inhalte erst nach einem Klick geladen oder nachträglich durch eine clientseitige Anfrage eingefügt werden. Wenn dieser Inhalt für die KI‑Discovery wichtig ist, nehmen Sie ihn in das initiale HTML auf und steuern Sichtbarkeit über CSS/ARIA.
Schnelle Tests, um Rendering‑Lücken zu erkennen
Führen Sie beide Prüfungen durch:
- Seitenquelle anzeigen (View Source): zeigt das vom Server gelieferte HTML (was viele Crawler sehen)
- Inspect Element: zeigt das post‑JS DOM (was ein echter Browser am Ende hat)
Wenn Ihre Überschriften, Haupttexte, internen Links oder FAQ‑Antworten nur in Inspect Element und nicht in View Source erscheinen, behandeln Sie das als Rendering‑Risiko und verschieben Sie diesen Inhalt in servergerendertes HTML.
KI‑Crawler und traditionelle Suchbots benötigen klare, konsistente Zugriffsregeln. Wenn Sie versehentlich wichtige Inhalte blockieren — oder Crawler in private bzw. „unsaubere“ Bereiche lassen — verschwenden Sie Crawl‑Budget und verschlechtern, was indexiert wird.
robots.txt: der siteweite Verkehrsregler
Verwenden Sie robots.txt für breit angelegte Regeln: welche Ordner oder URL‑Muster gecrawlt oder vermieden werden sollten.
Eine praktische Basis:
- Allow/Disallow: blockieren Sie nicht‑öffentliche Bereiche wie
/admin/, /account/, interne Suchergebnisse oder parameterintensive URLs, die nahezu unendliche Kombinationen erzeugen.
- Crawl‑Delay: nur hinzufügen, wenn Ihr Server Probleme mit Bot‑Traffic hat. Viele große Bots ignorieren es; verlassen Sie sich nicht darauf als Hauptratebegrenzung.
- Sitemap‑Direktive: verweisen Sie Crawler auf Ihren kanonischen Sitemap‑Ort, damit Discovery vorhersehbar ist.
Beispiel:
User-agent: *
Disallow: /admin/
Disallow: /account/
Disallow: /internal-search/
Sitemap: /sitemap.xml
Wichtig: Das Blockieren per robots.txt verhindert Crawling, garantiert aber nicht, dass eine URL nicht in einem Index auftaucht, wenn sie anderswo referenziert wird. Für Index‑Kontrolle verwenden Sie Seiten‑Level‑Direktiven.
Nutzen Sie meta name="robots" in HTML‑Seiten und X‑Robots‑Tag‑Header für Nicht‑HTML‑Dateien (PDFs, Feeds, generierte Exporte).
Gängige Muster:
- Dünne oder Utility‑Seiten (Filter, Sort‑Varianten, Druckansichten):
noindex,follow, damit Links weitergegeben werden, die Seite selbst aber aus Indizes bleibt.
- Private oder sensitive Bereiche: verlassen Sie sich nicht nur auf
noindex — schützen Sie mit Authentifizierung und ziehen Sie zusätzliches Disallow in Betracht.
- Duplikat‑Versionen (z. B. Preview‑URLs):
noindex plus richtige Canonicalisierung.
Ein einfaches Umfeld‑Regelwerk (Prod vs. Staging)
Dokumentieren und erzwingen Sie Regeln pro Umgebung:
- Produktion: standardmäßig crawlbar; nur klar nicht‑öffentliche oder wenig wertvolle Bereiche blocken.
- Staging/Preview: Login erforderlich; außerdem global
noindex (Header‑basierte Lösung ist am einfachsten), um versehentliches Indexieren zu vermeiden.
Wenn Ihre Zugriffsregeln Nutzerdaten betreffen, stellen Sie sicher, dass die öffentlich kommunizierten Richtlinien der Realität entsprechen (siehe /privacy und /terms, wenn relevant).
Kanonische URLs, Duplikate und Redirect‑Hygiene
Dokumentation veröffentlichen, die Bots lesen können
Starte ein Docs‑ oder FAQ‑Portal, das Bots ohne JavaScript parsen können.
Wenn Sie möchten, dass KI‑Systeme (und Suchcrawler) Ihre Seiten zuverlässig verstehen und zitieren, müssen Sie Situationen mit „gleichem Inhalt, vielen URLs“ reduzieren. Duplikate verschwenden Crawl‑Budget, teilen Signale und können dazu führen, dass eine falsche Version einer Seite indexiert oder referenziert wird.
Saubere, stabile URLs erstellen
Zielen Sie auf URLs, die jahrelang gültig bleiben. Vermeiden Sie das Offenlegen unnötiger Parameter wie Session‑IDs, Sortieroptionen oder Tracking‑Codes in indexierbaren URLs (z. B.: ?utm_source=..., ?sort=price, ?ref=). Wenn Parameter für Funktionalität nötig sind (Filter, Paginierung, interne Suche), stellen Sie sicher, dass die „Haupt“‑Version über eine stabile, saubere URL erreichbar bleibt.
Stabile URLs verbessern langfristige Zitate: wenn ein LLM eine Referenz lernt oder speichert, verweist es eher auf dieselbe Seite, wenn Ihre URL‑Struktur bei jedem Redesign nicht bricht.
Fügen Sie ein \u003clink rel=\"canonical\"\u003e auf Seiten hinzu, wo Duplikate erwartet werden:
- Produktvarianten mit überwiegend gleichem Inhalt
- Gefilterte Kategoriesichten
- Tracking‑Parameter‑Versionen
Canonical‑Tags sollten auf die bevorzugte, indexierbare URL verweisen (und idealerweise sollte diese kanonische URL einen 200‑Status zurückgeben).
Redirect‑Hygiene: einfach und vorhersehbar
Wenn eine Seite dauerhaft verschoben wird, nutzen Sie einen 301 Redirect. Vermeiden Sie Redirect‑Ketten (A → B → C) und Schleifen; sie verlangsamen Crawler und können zu teilweiser Indexierung führen. Leiten Sie alte URLs direkt zur endgültigen Zielseite weiter und halten Sie Redirects konsistent über HTTP/HTTPS und www/non‑www.
hreflang nur für echte Äquivalente einsetzen
Implementieren Sie hreflang nur, wenn Sie tatsächlich lokalisierte Entsprechungen haben (nicht nur übersetzte Fragmente). Falsches hreflang kann Verwirrung darüber schaffen, welche Seite für welches Publikum zitiert werden sollte.
Sitemaps und interne Verlinkung für zuverlässige Discovery
Sitemaps und interne Links sind Ihr „Zustellsystem“ für Discovery: sie sagen den Crawlern, was existiert, was wichtig ist und was ignoriert werden sollte. Für KI‑Crawler und LLM‑Indexierung ist das Ziel einfach — machen Sie Ihre besten, sauberen URLs leicht auffindbar und schwer zu übersehen.
XML‑Sitemaps bauen, die nur die richtigen URLs listen
Ihre Sitemap sollte nur indexierbare, kanonische URLs enthalten. Wenn eine Seite von robots.txt blockiert wird, noindex markiert ist, weitergeleitet wird oder nicht die kanonische Version ist, gehört sie nicht in die Sitemap. Das fokussiert Crawl‑Budget und verringert die Chance, dass ein LLM eine Duplikat‑ oder veraltete Version aufnimmt.
Seien Sie konsistent mit URL‑Formaten (Trailing Slashes, Kleinschreibung, HTTPS), sodass die Sitemap Ihre Canonical‑Regeln spiegelt.
Große Sitemaps aufteilen und ein Sitemap‑Index verwenden
Bei vielen URLs teilen Sie Sitemaps in mehrere Dateien (übliches Limit: 50.000 URLs pro Datei) und veröffentlichen einen Sitemap‑Index, der jede Sitemap auflistet. Gliedern Sie nach Inhaltstyp, wenn es hilft, z. B.:
/sitemaps/pages.xml/sitemaps/blog.xml/sitemaps/docs.xml
Das erleichtert die Pflege und hilft beim Monitoring dessen, was entdeckt wird.
lastmod als Vertrauenssignal nutzen, nicht als Deploy‑Timestamp
Aktualisieren Sie lastmod bedacht — nur wenn sich die Seite inhaltlich erheblich ändert (Inhalt, Preise, Richtlinien, wichtige Metadaten). Wenn jede URL bei jedem Deploy aktualisiert wird, lernen Crawler, das Feld zu ignorieren, und wirklich wichtige Änderungen werden möglicherweise später erneut geprüft als gewünscht.
Interne Links: machen Sie Ihre Seite navigierbar wie eine Karte
Eine starke Hub‑und‑Spoke‑Struktur hilft Nutzern und Maschinen. Erstellen Sie Hubs (Kategorie‑, Produkt‑ oder Topic‑Seiten), die zu den wichtigsten „Spoke“‑Seiten verlinken, und sorgen Sie dafür, dass jeder Spoke zurück zum Hub verlinkt. Fügen Sie kontextuelle Links in den Fließtext ein, nicht nur in Menüs.
Wenn Sie edukative Inhalte publizieren, halten Sie Ihre Haupteinstiegspunkte offensichtlich — leiten Sie Nutzer zu /blog für Artikel und zu /docs für tiefergehende Referenzen.
Strukturierte Daten: Helfen Sie Maschinen, Ihre Seiten zu verstehen
Standardmäßig stabile URLs erstellen
Erzeuge React-, Go‑ und PostgreSQL‑Apps und halte Canonical‑Tags und Weiterleitungen vorhersehbar.
Strukturierte Daten sind eine Möglichkeit, zu kennzeichnen, was eine Seite ist (ein Artikel, Produkt, FAQ, Organisation) in einem Format, das Maschinen zuverlässig lesen können. Suchmaschinen und KI‑Systeme müssen nicht raten, welcher Text der Titel ist, wer ihn geschrieben hat oder welches die Hauptentität ist — sie können es direkt parsen.
Wählen Sie den richtigen Schema.org‑Typ
Nutzen Sie Schema.org‑Typen, die zu Ihrem Inhalt passen:
- Article (Blogposts, Guides, Nachrichten)
- FAQPage (Frage/Antwort‑Abschnitte)
- HowTo (Schritt‑für‑Schritt‑Anleitungen)
- Product (Preis‑ und Produktdetailseiten)
- Organization (Ihre Unternehmensidentität)
Wählen Sie einen primären Typ pro Seite und ergänzen Sie unterstützende Properties (z. B. kann ein Article eine Organization als Publisher referenzieren).
Markup mit sichtbarem Inhalt abgleichen
Crawler und Suchmaschinen vergleichen strukturierte Daten mit dem sichtbaren Seiteninhalt. Wenn Ihr Markup eine FAQ behauptet, die nicht wirklich auf der Seite steht, oder einen Autor nennt, der nicht sichtbar ist, erzeugen Sie Verwirrung und riskieren, dass das Markup ignoriert wird.
Fügen Sie für Inhaltsseiten Autor sowie datePublished und dateModified hinzu, wenn diese echt und sinnvoll sind. Das macht Aktualität und Verantwortlichkeit klar — zwei Dinge, die LLMs oft betrachten, wenn sie entscheiden, ob etwas vertrauenswürdig ist.
Wenn Sie offizielle Profile haben, fügen Sie in der Organization‑Schema sameAs‑Links hinzu (z. B. verifizierte Social‑Profile).
Beispiel: Article JSON‑LD
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Build a Website Ready for AI Crawlers and LLM Indexing",
"author": { "@type": "Person", "name": "Jane Doe" },
"datePublished": "2025-01-10",
"dateModified": "2025-02-02",
"publisher": {
"@type": "Organization",
"name": "Acme",
"sameAs": ["https://www.linkedin.com/company/acme"]
}
}
Validieren Sie abschließend mit gängigen Prüfwerkzeugen (Google Rich Results Test, Schema Markup Validator). Beheben Sie Fehler und behandeln Sie Warnungen pragmatisch: priorisieren Sie die, die zu Ihrem gewählten Typ und den Schlüssel‑Properties (Titel, Autor, Daten, Produktinfos) gehören.
llms.txt: Ein einfacher Leitfaden für LLM‑orientierte Discovery
Eine llms.txt‑Datei ist eine kleine, menschenlesbare „Merkkarte“ für Ihre Site, die sprachmodellorientierte Crawler (und die Menschen, die sie konfigurieren) zu den wichtigsten Einstiegspunkten führt: Ihre Docs, zentrale Produktseiten und Referenzmaterial, das Ihre Terminologie erklärt.
Es ist kein Standard mit garantierten Verhaltensweisen bei allen Crawlern und ersetzt nicht Sitemaps, Canonicals oder Robots‑Kontrollen. Sehen Sie es als hilfreiche Abkürzung für Discovery und Kontext.
Wo platzieren
Legen Sie sie im Site‑Root ab, damit sie leicht zu finden ist:
Das gleiche Prinzip wie bei robots.txt: vorhersehbarer Ort, schneller Abruf.
Was enthalten (und vermeiden)
Halten Sie es kurz und kuratiert. Gute Kandidaten:
- Primäre Einstiegspunkte: Produktübersicht, Preise, Getting‑Started
- Dokumentations‑Hubs: Docs‑Home, API‑Reference, SDK‑Guides, Tutorials
- Glossar / Terminologie: Seite, die Domain‑Begriffe und bevorzugte Benennungen definiert
- Richtlinien, die Wiederverwendung betreffen: Lizenzierung, Attributionserwartungen, Hinweise zur Datennutzung
Erwägen Sie auch kurze Style‑Notes, die Ambiguität reduzieren (z. B. „Wir nennen Kunden in der UI ‚workspaces‘“). Vermeiden Sie langen Marketing‑Text, vollständige URL‑Dumps oder alles, was mit Ihren kanonischen URLs in Konflikt steht.
Hier ein einfaches Beispiel:
# llms.txt
# Purpose: curated entry points for understanding and navigating this site.
## Key pages
- / (Homepage)
- /pricing
- /docs
- /docs/getting-started
- /docs/api
- /blog
## Terminology and style
- Prefer “workspace” over “account”.
- Product name is “Acme Cloud” (capitalized).
- API objects: “Project”, “User”, “Token”.
## Policies
- /terms
- /privacy
Mit Sitemaps und Canonicals in Einklang halten
Konsistenz ist wichtiger als Volumen:
- Listen Sie nur URLs, die Sie entdeckt und zitiert sehen möchten.
- Stellen Sie sicher, dass gelistete Seiten 200 zurückgeben und die korrekte Canonical haben.
- Wenn eine Seite ersetzt wird, aktualisieren Sie den Link, statt auf Redirects zu vertrauen.
- Führen Sie keine URLs auf, die von
robots.txt blockiert sind (das erzeugt gemischte Signale).
Leichter Pflegeprozess (quartalsweise)
Eine praktikable Routine, die überschaubar bleibt:
- Quartalsweise Prüfung (15 Minuten): klicken Sie jeden Link in
llms.txt und bestätigen Sie, dass es noch der beste Einstiegspunkt ist.
- Nach größeren Releases: fügen Sie Doc‑Hubs hinzu/entfernen Sie sie, wenn Sie die Navigation umstrukturieren.
- An bestehende Checks binden: aktualisieren Sie
llms.txt, wenn Sie Ihre Sitemap oder Canonicals ändern.
Richtig gepflegt bleibt llms.txt klein, akkurat und wirklich nützlich — ohne Versprechungen darüber zu machen, wie sich ein bestimmter Crawler verhält.
Crawler (einschließlich KI‑orientierter) verhalten sich oft wie ungeduldige Nutzer: ist Ihre Seite langsam oder fehlerhaft, rufen sie weniger Seiten ab, versuchen seltener erneut und aktualisieren ihren Index seltener. Gute Performance und verlässliche Serverantworten erhöhen die Wahrscheinlichkeit, dass Ihr Inhalt entdeckt, erneut gecrawlt und aktuell gehalten wird.
Geschwindigkeit und Verfügbarkeit: was Crawler „spüren"
Wenn Ihr Server häufig timeouts oder Fehler liefert, kann ein Crawler automatisch zurückfahren. Neue Seiten erscheinen dann langsamer, und Aktualisierungen werden nicht schnell reflektiert.
Zielen Sie auf konstante Verfügbarkeit und vorhersehbare Antwortzeiten in Spitzenzeiten — nicht nur auf gute Laborwerte.
TTFB verbessern und Payload reduzieren
Time to First Byte (TTFB) ist ein starkes Signal für Servergesundheit. Einige wirkungsvolle Maßnahmen:
- CDN‑Caching für öffentliche Seiten und Origin‑Caching, wo möglich.
- Aktivieren Sie Kompression (Brotli oder gzip) für HTML, CSS und JS.
- Halten Sie HTML schlank: vermeiden Sie große Inline‑Skripte oder exzessive Tracking‑Tags.
- Bilder skalieren und komprimieren, damit Seiten nicht große Downloads benötigen, nur um den Inhalt zu verstehen.
Auch wenn Crawler Bilder nicht wie Menschen „sehen“, verschwenden große Dateien doch Crawl‑Zeit und Bandbreite.
Die richtigen HTTP‑Statuscodes zurückgeben
Crawler verlassen sich auf Statuscodes, um zu entscheiden, was behalten und was verworfen wird:
- 200 für gültige Seiten mit Inhalt.
- 301 für dauerhafte Verschiebungen (und Redirect‑Ketten kurz halten).
- 404 wenn eine Seite nicht existiert.
- 410 wenn eine Seite bewusst entfernt wurde und schneller fallen gelassen werden soll.
- Behandeln Sie 5xx‑Fehler sorgfältig: Ursachen schnell beheben und ein leichtes Fallback nur anbieten, wenn der korrekte Fehlercode erhalten bleibt.
Kerninhalte nicht hinter Logins verstecken
Wenn der Hauptartikeltext Authentifizierung erfordert, indexieren viele Crawler nur die Shell. Halten Sie Kernlesezugriffe öffentlich oder bieten Sie eine crawlbare Vorschau an, die den Schlüsselinhalte enthält.
Rate‑Limiting ohne legitime Crawls zu blockieren
Schützen Sie Ihre Seite vor Missbrauch, aber vermeiden Sie pauschale Sperren. Bevorzugen Sie:
- Token‑Bucket‑Rate‑Limits mit angemessenen Bursts
- Allowlists für bekannte Crawler‑IP‑Bereiche (wenn verfügbar)
- Klare 429‑Antworten mit
Retry‑After‑Headern
So bleibt Ihre Seite geschützt und verantwortungsbewusste Crawler können trotzdem arbeiten.
Vertrauenssignale: Quellen, Autoren und klare Verantwortlichkeit
Seiten schnell für Crawler optimieren
Erstelle von Anfang an KI-fähige Seiten mit serverseitig gerendertem HTML, sauberen Routen und einheitlichen Metadaten.
„E‑E‑A‑T“ erfordert keine großen Behauptungen oder Auszeichnungen. Für KI‑Crawler und LLMs bedeutet es vor allem, dass Ihre Seite klar ausweist, wer etwas geschrieben hat, woher Fakten stammen und wer dafür verantwortlich ist, sie zu pflegen.
Quellenangaben sichtbar und verifizierbar machen
Wenn Sie eine Tatsache nennen, binden Sie die Quelle so nah wie möglich an die Aussage. Priorisieren Sie Primär‑ und offizielle Referenzen (Gesetze, Normungsorganisationen, Vendor‑Dokumentation, peer‑reviewte Arbeiten) vor zweit‑/drittverwendeten Zusammenfassungen.
Wenn Sie z. B. strukturiertes Datenverhalten erwähnen, verlinken Sie auf Googles Dokumentation („Google Search Central — Structured Data“) und, wenn passend, auf die Schema‑Definitionen („Schema.org vocabulary"). Wenn Sie Robots‑Direktiven diskutieren, referenzieren Sie relevante Standards und offizielle Crawler‑Docs (z. B. „RFC 9309: Robots Exclusion Protocol“). Auch wenn Sie nicht bei jeder Erwähnung extern verlinken, geben Sie genug Detail, damit Leser das genaue Dokument finden können.
Autoren‑ und redaktionelle Verantwortung zeigen
Fügen Sie eine Autorenzeile mit kurzer Bio, Credentials und Verantwortungsbereich hinzu. Machen Sie anschließend Eigentümerschaft deutlich:
- Eine klare Seiten‑Eigentümerin (Firma/rechtliche Einheit) im Footer
- Eine Kontaktseite mit realen Kanälen (nicht nur ein Formular)
- Eine About‑Seite, die Ihre Mission und redaktionellen Prozess erklärt (siehe /about)
Behauptungen spezifisch halten — und Belege aufbewahren
Vermeiden Sie „beste“ und „garantiert“‑Sprache. Beschreiben Sie stattdessen, was Sie getestet haben, was sich geändert hat und was die Grenzen sind. Fügen Sie Update‑Hinweise oben oder unten auf wichtigen Seiten hinzu (z. B. „Aktualisiert 2025‑12‑10: Klarstellungen zur Canonical‑Handhabung bei Redirects“). Das schafft eine Pflegehistorie, die Menschen und Maschinen interpretieren können.
Ein konsistentes Glossar pflegen
Definieren Sie Ihre Kernbegriffe einmal und verwenden Sie sie dann konsistent über die Seite hinweg (z. B. „AI Crawler“, „LLM‑Indexierung“, „gerendertes HTML"). Eine leichtgewichtige Glossar‑Seite (z. B. /glossary) reduziert Mehrdeutigkeit und erleichtert Zusammenfassungen.
Tests, Monitoring und kontinuierliche Verbesserungen
Eine AI‑bereite Seite ist kein Einmalprojekt. Kleine Änderungen — ein CMS‑Update, ein neuer Redirect oder ein redesignetes Navigations‑Template — können Discovery und Indexierung stillschweigend beschädigen. Eine einfache Test‑Routine verhindert Ratenraten, wenn Sichtbarkeit oder Traffic sich ändern.
Signale beobachten, die auf Discovery‑Probleme hinweisen
Beginnen Sie mit den Grundlagen: überwachen Sie Crawl‑Fehler, Index‑Coverage und Ihre am besten verlinkten Seiten. Wenn Crawler wichtige URLs nicht abrufen können (Timeouts, 404s, blockierte Ressourcen), verschlechtert sich die LLM‑Indexierung schnell.
Beobachten Sie außerdem:
- Seiten, die plötzlich aus der Index‑Coverage fallen
- Wichtige URLs, die keine internen Links mehr erhalten
- Unerwartete Anstiege bei „Duplikaten“ oder „ausgeschlossenen“ Seiten
Releases wie ein Reliability Engineer prüfen
Nach Deploys (auch „kleinen“) prüfen Sie, was sich geändert hat:
- Redirects: leiten alte URLs korrekt zu neuen Zielen für Nutzer und Bots?
- Canonicals: haben Templates geändert und fangen jetzt an, falsche Canonicals zu setzen?
- Sitemaps: sind sie noch gültig, aktuell und frei von gebrochenen URLs?
Ein 15‑minütiger Post‑Release‑Audit fängt oft Probleme, bevor sie zu langfristigen Sichtbarkeitsverlusten werden.
Testen, wie Ihre Seiten zusammengefasst werden
Wählen Sie einige wichtige Seiten und testen Sie, wie sie von KI‑Tools oder internen Summarisierungs‑Skripten zusammengefasst werden. Achten Sie auf:
- Fehlende Definitionen (der „Was ist das?“‑Satz fehlt)
- Überschriften, die nicht zu den tatsächlichen Abschnitten passen
- Schlüsseldetails, die in langen Absätzen ohne Labels verborgen sind
Wenn Zusammenfassungen vage sind, ist die Lösung meist redaktionell: stärkere H2/H3‑Überschriften, klarere Einstiegsabsätze und explizitere Terminologie.
Eine wiederkehrende „AI‑Readiness“‑Checkliste erstellen
Machen Sie aus dem Gelernten eine periodische Checkliste und weisen Sie einen Besitzer zu (ein realer Name, nicht „Marketing“). Halten Sie sie lebendig und umsetzbar — und verlinken Sie die aktuellste Version intern, damit das ganze Team dieselbe Anleitung nutzt. Veröffentlichen Sie eine leichtgewichtige Referenz wie /blog/ai-seo-checklist und aktualisieren Sie sie, wenn sich Site und Tools weiterentwickeln.
Wenn Ihr Team schnell ausliefert (insbesondere mit AI‑gestützter Entwicklung), überlegen Sie, „AI‑Readiness“‑Checks direkt in Ihren Build/Release‑Workflow zu integrieren: Templates, die immer Canonical‑Tags, konsistente Autor/Datum‑Felder und servergerenderten Kerninhalt ausgeben. Plattformen wie Koder.ai können hier helfen, indem solche Defaults für neue React‑Seiten und App‑Oberflächen wiederholbar gemacht werden und durch Plan‑Mode, Snapshot und Rollback schnelle Iteration möglich wird, wenn eine Änderung die Crawlability beeinträchtigt.
Kleine, stetige Verbesserungen summieren sich: weniger Crawl‑Fehler, sauberere Indexierung und Inhalte, die für Menschen und Maschinen leichter zu verstehen sind.