Was “ACID” für alltägliche Transaktionen bedeutet
Wenn Sie für Lebensmittel bezahlen, einen Flug buchen oder Geld zwischen Konten verschieben, erwarten Sie ein eindeutiges Ergebnis: entweder es hat funktioniert oder nicht. Datenbanken wollen dieselbe Gewissheit bieten — selbst wenn viele Nutzer gleichzeitig im System sind, Server abstürzen oder Netzwerke schwächeln.
Eine Transaktion, einfach gesagt
Eine Transaktion ist eine einzelne Arbeitseinheit, die die Datenbank als ein „Paket“ behandelt. Sie kann mehrere Schritte enthalten — Lagerbestand verringern, Bestellung anlegen, Karte belasten und eine Quittung schreiben — soll aber als eine zusammenhängende Aktion funktionieren.
Wenn ein Schritt fehlschlägt, sollte das System lieber auf einen sicheren Zustand zurückrollen, statt einen halb fertigen Zustand zu hinterlassen.
Warum partielle Updates echte Geschäftsprobleme verursachen
Partielle Updates sind nicht nur technische Fehler; sie werden zu Support-Fällen und finanziellen Risiken. Zum Beispiel:
- Eine Zahlung wird belastet, aber die Bestellung wird nicht angelegt — Kunden werden belastet ohne Bestätigung.
- Eine Bestellung wird angelegt, aber der Bestand wird nicht reduziert — Ihr Shop verkauft mehr, als verfügbar ist, und muss später stornieren.
- Eine Überweisung bucht von einem Konto ab, schreibt dem anderen aber nicht gut — Salden stimmen nicht mehr.
Solche Fehler sind schwer zu debuggen, weil alles „meistens korrekt“ aussieht, aber die Zahlen nicht stimmen.
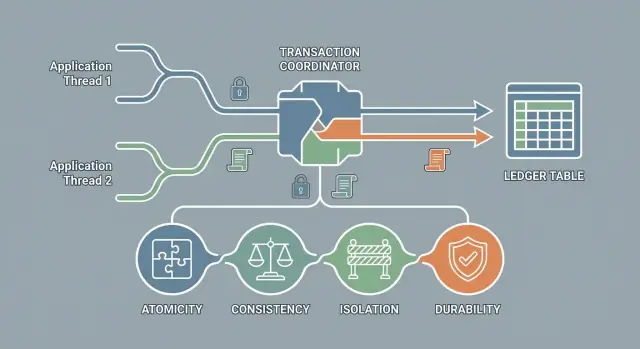
ACID ist ein Satz von Garantien (kein Produkt)
ACID steht für vier Garantien, die viele Datenbanken für Transaktionen bieten können:
- Atomarität: alles-oder-nichts-Ausführung
- Konsistenz: Daten bleiben innerhalb gültiger Regeln
- Isolation: parallele Transaktionen stören sich nicht auf unsichere Weise
- Dauerhaftigkeit: einmal bestätigt, bleiben Änderungen erhalten
Es ist keine spezifische Datenbankmarke oder ein einzelner Schalter; es ist ein Versprechen über das Verhalten.
Vorteile — und die Kosten, die Sie erwarten sollten
Stärkere Garantien bedeuten meist mehr Arbeit für die Datenbank: zusätzliche Koordination, Warten auf Sperren, Versionsverfolgung und Schreiben in Logs. Das kann Durchsatz verringern oder Latenz unter hoher Last erhöhen. Das Ziel ist nicht „überall maximale ACID“, sondern Garantien zu wählen, die zu Ihren echten Geschäftsrisiken passen.
Atomarität: Alles-oder-Nichts-Updates
Atomarität bedeutet, dass eine Transaktion als eine einzige Arbeitseinheit behandelt wird: sie wird entweder vollständig ausgeführt oder hat keinerlei Effekt. Sie sehen niemals ein „halb aktualisiertes" Ergebnis in der Datenbank.
Ein einfaches Beispiel: Banküberweisung
Stellen Sie sich vor, Sie transferieren 50 $ von Alice zu Bob. Unter der Haube beinhaltet das typischerweise mindestens zwei Änderungen:
- 50 $ vom Guthaben von Alice abziehen
- 50 $ zum Guthaben von Bob hinzufügen
Mit Atomarität gelingen beide Änderungen zusammen oder keine von beiden. Wenn das System nicht beide sicher durchführen kann, muss es keine ausführen. Das verhindert den Albtraum, dass Alice belastet wird, Bob aber das Geld nicht erhält (oder Bob erhält es, ohne dass Alice belastet wurde).
Commit vs. Rollback (in einfachen Worten)
Datenbanken geben Transaktionen zwei Ausgänge:
- Commit: „Alle Schritte sind erfolgreich; mache die Ergebnisse offiziell.“
- Rollback: „Etwas ist schiefgelaufen; mache alles aus dieser Transaktion rückgängig.“
Ein hilfreiches Modell ist „Entwurf vs. Veröffentlichen“. Solange die Transaktion läuft, sind die Änderungen vorläufig. Nur ein Commit veröffentlicht sie.
Was mitten in einer Transaktion schiefgehen kann
Atomarität ist wichtig, weil Fehler normal sind:
- App-Absturz: Ihr Service stoppt nach dem Update einer Tabelle, bevor die nächste aktualisiert wurde.
- Netzwerkausfall: Die App erreicht die Datenbank nicht oder der Client erhält die „Erfolg“-Antwort nie.
- Stromausfall: Der Datenbankserver stoppt unerwartet.
Wenn eines davon passiert, bevor der Commit abgeschlossen ist, sorgt Atomarität dafür, dass die Datenbank zurückrollen kann, damit keine Teilarbeit in echte Salden einfließt.
Atomarität plus Idempotenz und Retries
Atomarität schützt den Datenbankzustand, aber Ihre Anwendung muss weiterhin mit Unsicherheit umgehen — besonders wenn ein Netzwerkabbruch unklar lässt, ob ein Commit stattgefunden hat.
Zwei praktische Ergänzungen:
- Retries: Anfragen wiederholen, wenn Sie keine Antwort bekommen.
- Idempotenz: das Wiederholen derselben Anfrage sicher machen (z. B. mit einem Idempotenzschlüssel, sodass „Transfer #123" höchstens einmal ausgeführt wird).
Zusammen helfen atomare Transaktionen und idempotente Retries, sowohl partielle Updates als auch versehentliche Doppelbelastungen zu vermeiden.
Konsistenz: Daten innerhalb gültiger Regeln halten
Konsistenz in ACID bedeutet nicht „die Daten sehen sinnvoll aus“ oder „alle Replikate stimmen überein“. Es bedeutet, dass jede Transaktion die Datenbank von einem gültigen Zustand in einen anderen gültigen Zustand überführt — gemäß den Regeln, die Sie festlegen.
Konsistenz wird durch Ihre Regeln definiert
Eine Datenbank kann Daten nur relativ zu expliziten Constraints, Triggern und Invarianten konsistent halten, die beschreiben, was „gültig“ für Ihr System ist. ACID erfindet diese Regeln nicht; es setzt sie während Transaktionen durch.
Gängige Beispiele sind:
- Foreign Keys: jede
order.customer_id muss auf einen existierenden Kunden zeigen.
- Unique-Constraints: keine zwei Nutzer dürfen dieselbe E‑Mail teilen.
- Check-Constraints / Invarianten: ein Kontostand darf nicht negativ sein, oder die Menge eines Artikels darf nicht negativ sein.
Wenn diese Regeln gesetzt sind, wird die Datenbank jede Transaktion ablehnen, die sie verletzen würde — so entstehen keine „halbgültigen“ Daten.
Anwendungsvalidierung vs. Datenbank-Constraints
App-Level-Validierung ist wichtig, reicht aber allein nicht aus.
- App-Validierung verbessert die Nutzererfahrung (klare Fehlermeldungen, frühes Feedback) und kann komplexe Geschäftsregeln prüfen.
- Datenbank-Constraints fungieren als endgültiger Türsteher — besonders wenn mehrere Services, Hintergrundjobs, Importe oder Admin-Tools dieselben Tabellen schreiben.
Ein klassisches Ausfallmuster ist: die App prüft „E‑Mail ist verfügbar“ und führt dann ein Insert aus. Unter Nebenläufigkeit können zwei Requests die Prüfung gleichzeitig bestehen. Ein Unique-Constraint in der Datenbank garantiert, dass nur ein Insert erfolgreich ist.
Wie Konsistenz in der Praxis aussieht
Wenn Sie „keine negativen Salden“ als Constraint kodieren (oder es zuverlässig innerhalb einer Transaktion durchsetzen), muss jede Überweisung, die ein Konto überziehen würde, als Ganzes fehlschlagen. Wenn Sie diese Regel nirgendwo kodieren, kann ACID sie nicht schützen — weil es nichts gibt, das durchgesetzt werden könnte.
Konsistenz bedeutet letztlich: machen Sie die Regeln explizit, und lassen Sie Transaktionen dafür sorgen, dass sie nie gebrochen werden.
Isolation: Sicheres Arbeiten unter Nebenläufigkeit
Isolation sorgt dafür, dass Transaktionen sich nicht gegenseitig in die Quere kommen. Während eine Transaktion läuft, sollen andere Transaktionen keine halb abgeschlossenen Arbeiten sehen oder sie aus Versehen überschreiben. Das Ziel ist einfach: jede Transaktion soll sich so verhalten, als ob sie allein läuft, auch wenn viele Nutzer gleichzeitig aktiv sind.
Warum Nebenläufigkeit das schwer macht
Echte Systeme sind beschäftigt: Kunden bestellen, Support-Mitarbeiter aktualisieren Profile, Hintergrundjobs gleichen Zahlungen ab — gleichzeitig. Diese Aktionen überschneiden sich zeitlich und betreffen oft dieselben Zeilen (Kontostand, Lagerbestand oder Buchungsplatz).
Ohne Isolation wird Timing Teil Ihrer Geschäftslogik. Ein „Bestand abziehen“-Update kann mit einem anderen Checkout konkurrieren, oder ein Report liest Daten mitten in einer Änderung und zeigt Zahlen, die nie in einem stabilen Zustand existiert haben.
Isolation ist meist konfigurierbar
Volle „so tun, als wäre man allein“ Isolation kann teuer sein. Sie kann Durchsatz reduzieren, Wartezeiten (Sperren) erhöhen oder zu Transaktionsretries führen. Viele Workflows brauchen nicht den strengsten Schutz — für Analytics etwa sind leicht veraltete Daten oft akzeptabel.
Deshalb bieten Datenbanken konfigurierbare Isolationsstufen: Sie wählen, welches Nebenläufigkeitsrisiko Sie im Tausch gegen bessere Performance und weniger Konflikte akzeptieren.
Ein kurzer Überblick: Anomalien, die Isolation verhindert (oder erlaubt)
Wenn die Isolation für Ihre Workload zu schwach ist, stoßen Sie auf klassische Anomalien:
- Dirty Reads: Lesen von Änderungen, die eine andere Transaktion noch nicht committed hat.
- Lost Updates: Zwei Transaktionen überschreiben sich und eine Änderung geht verloren.
- Phantom Reads: Eine Abfrage liefert beim zweiten Lauf andere Zeilen, weil eine andere Transaktion passende Zeilen eingefügt oder gelöscht hat.
Diese Fehlermodi zu verstehen erleichtert die Auswahl einer Isolationsstufe, die zu Ihren Produktversprechen passt.
Häufige Anomalien, die Isolation verhindert (oder zulässt)
Den vollständigen Quellcode erhalten
Exportieren Sie den Quellcode, um Transaktionen, Abfragen und Constraints in Ihrem eigenen Workflow zu prüfen.
Isolation bestimmt, was andere Transaktionen sehen dürfen, während Ihre noch läuft. Ist sie zu schwach, können Anomalien auftreten — technisch möglich, für Nutzer aber überraschend.
Lese-Anomalien
Dirty Read tritt auf, wenn Sie Daten lesen, die eine andere Transaktion geschrieben, aber noch nicht committed hat.
Szenario: Alex überweist 500 $, der Saldo fällt vorübergehend auf 200 $, und Sie lesen diese 200 $, bevor Alex’ Transfer später fehlschlägt und zurückgerollt wird.
Nutzerfolge: Ein Kunde sieht ein fälschlich niedriges Guthaben, eine Betrugsregel feuert fälschlich, oder ein Support-Mitarbeiter gibt die falsche Auskunft.
Non-repeatable Read bedeutet, Sie lesen dieselbe Zeile zweimal und erhalten unterschiedliche Werte, weil eine andere Transaktion dazwischen committed hat.
Szenario: Sie laden einen Bestellbetrag (49,00 $) und sehen bei einem erneuten Abruf kurz darauf 54,00 $, weil eine Rabattposition entfernt wurde.
Nutzerfolge: „Mein Gesamtbetrag hat sich während des Bezahlens geändert“ — Misstrauen oder abgebrochene Warenkörbe.
Phantom Read ähnelt non-repeatable read, betrifft aber eine Zeilenmenge: Eine zweite Abfrage liefert zusätzliche (oder fehlende) Zeilen, weil eine andere Transaktion passende Datensätze eingefügt/gelöscht hat.
Szenario: Eine Hotelsuche zeigt „3 Zimmer verfügbar“, beim Buchen prüft das System erneut und findet keine mehr, weil neue Reservierungen hinzugekommen sind.
Nutzerfolge: Doppelte Buchungsversuche, inkonsistente Verfügbarkeitsanzeigen oder Überverkauf.
Schreib-Anomalien (häufige reale Fehler)
Lost Update entsteht, wenn zwei Transaktionen denselben Wert lesen und beide Updates zurückschreiben, wobei das spätere das frühere überschreibt.
Szenario: Zwei Admins bearbeiten denselben Produktpreis. Beide starten bei 10 $; einer speichert 12 $, der andere speichert zuletzt 11 $.
Nutzerfolge: Eine Änderung verschwindet; Summen und Reports sind falsch.
Write Skew passiert, wenn zwei Transaktionen jeweils eine Änderung vornehmen, die einzeln gültig ist, zusammen aber eine Regel verletzen.
Szenario: Regel: „Mindestens ein diensthabender Arzt muss geplant sein.“ Zwei Ärzte setzen unabhängig voneinander sich selbst als dienstfrei, nachdem sie gesehen haben, dass der andere noch eingetragen ist.
Nutzerfolge: Am Ende gibt es keine Abdeckung mehr, obwohl jede Transaktion für sich die Prüfung bestanden hat.
Warum nicht immer die strengste Isolation verwenden?
Stärkere Isolation reduziert Anomalien, kann aber Wartezeiten, Retries und Kosten unter hoher Nebenläufigkeit erhöhen. Viele Systeme wählen schwächere Isolation für leselastige Analytics und strengere Einstellungen für Geldbewegungen, Buchungen und andere korrektheitskritische Abläufe.
Isolationsstufen: Die richtige Sicherheitsstufe wählen
Isolation definiert, was Ihre Transaktion „sehen“ darf, während andere laufen. Datenbanken stellen das über Isolationsstufen bereit: höhere Stufen reduzieren überraschendes Verhalten, können aber Durchsatz oder Wartezeiten kosten.
Die gängigen Isolationsstufen
- Read Uncommitted: Sie können Änderungen lesen, die eine andere Transaktion noch nicht committed hat („dirty reads“). Fast nichts wird verhindert.
- Read Committed: Sie lesen nur committete Daten, also dirty reads werden verhindert. Wenn Sie dieselbe Abfrage zweimal ausführen, können Sie dennoch unterschiedliche Ergebnisse sehen, weil jemand dazwischen committed hat („non-repeatable reads").
- Repeatable Read: Bereits gelesene Daten bleiben innerhalb der Transaktion stabil, sodass non-repeatable reads generell verhindert werden. Je nach Engine können Sie jedoch weiterhin „Phantome“ sehen oder nicht.
- Serializable: Transaktionen verhalten sich, als wären sie nacheinander ausgeführt worden. Dies ist die stärkste Einstellung und verhindert in der Regel dirty reads, non-repeatable reads und phantoms und reduziert viele subtile Schreib-Anomalien.
Auswahl einer Stufe: Durchsatz vs. Korrektheit
Teams wählen oft Read Committed als Default für nutzerorientierte Apps: gute Performance und „keine dirty reads“ entspricht den meisten Erwartungen.
Nutzen Sie Repeatable Read, wenn Sie innerhalb einer Transaktion stabile Ergebnisse brauchen (z. B. Rechnungserstellung) und etwas Overhead tolerieren.
Nutzen Sie Serializable, wenn Korrektheit wichtiger ist als Nebenläufigkeit (z. B. komplexe Invarianten wie „niemals Überverkauf“) oder wenn Sie Race-Conditions im App-Code schwer analysieren können.
Read Uncommitted ist in OLTP-Systemen selten; es wird manchmal für Monitoring oder ungefähre Reports genutzt, wo falsche Reads akzeptabel sind.
Wichtiger Hinweis: Verhalten variiert
Die Namen sind standardisiert, aber genaue Garantien unterscheiden sich je nach Datenbank-Engine (und manchmal per Konfiguration). Prüfen Sie die Dokumentation Ihrer DB und testen die für Ihr Geschäft relevanten Anomalien.
Dauerhaftigkeit: Commits festhalten
Dauerhaftigkeit bedeutet, dass einmal committete Transaktionen ihre Ergebnisse über einen Absturz hinweg behalten — Stromausfall, Prozessneustart oder plötzlicher Reboot. Wenn Ihre App einem Kunden „Zahlung erfolgreich“ meldet, ist Dauerhaftigkeit das Versprechen, dass die Datenbank diese Tatsache nach einem Ausfall nicht „vergisst".
Wie Datenbanken Commits gegen Abstürze absichern
Die meisten relationalen Datenbanken erreichen Dauerhaftigkeit mit Write-Ahead Logging (WAL). Grob gesagt schreibt die Datenbank eine sequentielle „Quittung“ der Änderungen in ein Log auf die Festplatte, bevor sie die Transaktion als committed betrachtet. Nach einem Crash kann die DB das Log beim Start replayen, um die committeten Änderungen wiederherzustellen.
Um die Wiederherstellungszeit begrenzt zu halten, erstellen Datenbanken auch Checkpoints. Ein Checkpoint ist ein Moment, in dem die DB sicherstellt, dass genügend der jüngsten Änderungen in die Hauptdatendateien geschrieben wurden, sodass die Recovery nicht eine unbeschränkte Log-Historie abspielen muss.
Dauerhaftigkeit hängt von Storage und Konfiguration ab
Dauerhaftigkeit ist kein Ein/Aus-Schalter; sie hängt davon ab, wie aggressiv die DB Daten auf stabilem Speicher erzwingt.
- Bei synchronen Einstellungen wartet die DB, bis das Log geflusht ist (oft per
fsync) bevor sie Commit bestätigt. Das ist sicherer, kann aber Latenz hinzufügen.
- Bei asynchronen Einstellungen kann die DB den Commit bestätigen, bevor das Log vollständig auf dauerhaftem Speicher liegt. Performance verbessert sich, aber bei einem Crash können die jüngsten „committeden" Transaktionen verloren gehen.
Auch die zugrunde liegende Hardware spielt eine Rolle: SSDs, RAID-Controller mit Schreibcache und Cloud-Volumes verhalten sich bei Ausfällen unterschiedlich.
Backups und Replikation sind verwandt — aber anders
Backups und Replikation helfen bei Wiederherstellung oder Reduzierung der Ausfallzeit, sind aber nicht dasselbe wie Dauerhaftigkeit. Eine Transaktion kann auf dem Primary dauerhaft sein, auch wenn sie noch nicht an eine Replica übertragen wurde. Backups sind typischerweise point-in-time Schnappschüsse und keine Commit-für-Commit-Garantien.
Wie Datenbanken ACID intern durchsetzen
Nebenläufigkeit früh testen
Deadlocks, Wiederholungen und kurze Transaktionen schnell in einem lauffähigen Projekt modellieren.
Wenn Sie BEGIN und später COMMIT ausführen, koordiniert die Datenbank viele Komponenten: wer welche Zeilen lesen darf, wer sie ändern darf und was passiert, wenn zwei Leute dieselbe Zeile ändern wollen.
Pessimistische vs. optimistische Nebenläufigkeitskontrolle
Eine wesentliche „unter der Haube“ Entscheidung ist, wie Konflikte gehandhabt werden:
- Pessimistische Sperren gehen davon aus, dass Konflikte wahrscheinlich sind. Wenn eine Transaktion eine Zeile ändert, sperrt die DB sie, sodass andere Transaktionen warten müssen. Das verhindert viele Anomalien, kann aber zu Blocking führen.
- Optimistische Ansätze gehen davon aus, Konflikte seien selten. Transaktionen laufen mit weniger Sperren, die DB erkennt Konflikte beim Commit (oder per Checks) und lehnt ggf. eine Transaktion ab, so dass sie erneut versucht werden muss.
Viele Systeme mischen beide Ideen, abhängig von Workload und Isolationsstufe.
MVCC: Leser blockieren Schreiber nicht
Moderne Datenbanken verwenden oft MVCC (Multi-Version Concurrency Control): statt nur eine Kopie einer Zeile zu halten, verwaltet die DB mehrere Versionen.
- Leser sehen einen konsistenten Snapshot (eine ältere Version) ohne zu warten.
- Schreiber erzeugen eine neue Version, während Lesevorgänge weitergehen können.
Das ist ein Hauptgrund, warum manche DBs viele Reads und Writes gleichzeitig mit weniger Blocking verarbeiten können — obwohl Write/Write-Konflikte weiterhin gelöst werden müssen.
Deadlocks: wenn Warten in einer Schleife endet
Sperren können zu Deadlocks führen: Transaktion A wartet auf eine Sperre von B, während B auf eine Sperre von A wartet.
Datenbanken erkennen typischerweise den Zyklus und brechen eine Transaktion ab (ein „Deadlock-Victim“) und geben einen Fehler zurück, sodass die Anwendung einen Retry versuchen kann.
Praktische Anzeichen dafür, dass etwas schief läuft
Wenn ACID-Durchsetzung Reibung erzeugt, sehen Sie oft:
- Lock-Waits steigen während Spitzenbelastung
- Timeouts (Abfragen schlagen fehl nach langem Warten)
- Contention Hotspots (einige wenige Zeilen/Tabellen werden ständig aktualisiert, z. B. Zähler oder „last seen“-Felder)
Diese Symptome deuten oft darauf hin, Transaktionsgröße, Indexierung oder die passende Isolation/Sperrstrategie zu überdenken.
Wie ACID Anwendungsdesignentscheidungen prägt
ACID-Garantien sind nicht nur Theorie — sie beeinflussen, wie Sie APIs, Hintergrundjobs und sogar UI-Flows gestalten. Die Kernidee: entscheiden Sie, welche Schritte zusammen erfolgreich sein müssen, und packen Sie nur diese Schritte in eine Transaktion.
APIs um „eine Geschäftsänderung" herum designen
Eine gute transaktionale API bildet gewöhnlich eine einzelne Geschäftsaktion ab, auch wenn sie mehrere Tabellen berührt. Ein /checkout-Endpunkt könnte z. B. eine Bestellung anlegen, Inventar reservieren und eine Zahlungsabsicht aufzeichnen. Diese Datenbankschreibvorgänge sollten typischerweise in einer Transaktion liegen, sodass sie zusammen committen (oder zusammen zurückrollen), wenn eine Validierung fehlschlägt.
Ein gängiges Muster ist:
- Eingaben validieren, bevor die Transaktion geöffnet wird.
- Transaktion öffnen.
- Die minimal notwendigen Reads/Writes ausführen.
- Commit.
So erhalten Sie Atomarität und Konsistenz, vermeiden aber langsame, fragile Transaktionen.
Transaktionsgrenzen in Requests, Services und Jobs
Wo Sie Transaktionsgrenzen ziehen, hängt davon ab, was „eine Arbeitseinheit“ bedeutet:
- User-Requests: Halten Sie Transaktionen kurz — idealerweise nur ein paar Abfragen. Halten Sie keine Sperren, während Sie Views rendern oder auf externe Antworten warten.
- Background-Jobs: Behandeln Sie jeden Job-Versuch als eine Arbeitseinheit. Wenn ein Job 10.000 Datensätze verarbeitet, committen Sie in Batches, damit ein Neustart sicher ist.
- Service-Grenzen: Bevorzugen Sie, eine Transaktion innerhalb der Datenbank eines einzelnen Services zu halten. Über Services hinweg benötigt man meist andere Ansätze (z. B. Outbox), weil eine ACID-Transaktion nicht leicht mehrere Datenbanken abdecken kann.
Fehlerbehandlung: Rollback, Retries und sichere Replays
ACID hilft, aber Ihre Anwendung muss Fehler korrekt behandeln:
- Rollback bei Fehlern: Wenn ein Schritt fehlschlägt, brechen Sie die Transaktion ab, damit keine Teilupdates durchdringen.
- Retry bei transienten Fehlern: Serialisierungsfehler und Deadlocks sind unter Nebenläufigkeit normal. Die Wiederholung der gesamten Transaktion ist oft der richtige Weg.
- Operationen idempotent gestalten: Wird eine Anfrage erneut (vom Client oder Job-Runner) gesendet, sollte sie sicher wiederholbar sein — nutzen Sie Idempotenzschlüssel und Unique-Constraints.
Häufige Anti-Pattern
Vermeiden Sie lange Transaktionen, aufrufe externer APIs innerhalb einer Transaktion und Nutzersprechzeiten innerhalb einer Transaktion (z. B. „Warenkorb sperren, Nutzer um Bestätigung bitten"). Diese erhöhen Contentions und machen Isolationskonflikte wahrscheinlicher.
Wenn Sie schnell ein transaktionales System bauen, ist das größte Risiko selten, „ACID nicht zu kennen“ — es ist vielmehr, eine Geschäftsaktion über mehrere Endpunkte, Jobs oder Tabellen zu verteilen, ohne klare Transaktionsgrenzen.
Plattformen wie Koder.ai können Ihnen helfen, schneller zu werden und trotzdem um ACID herum zu designen: Sie können einen Workflow beschreiben (z. B. „Checkout mit Inventarreservierung und Zahlungsabsicht“), eine React-UI plus Go + PostgreSQL Backend generieren und mit Snapshots/Rollbacks iterieren, falls Schema oder Transaktionsgrenzen geändert werden müssen. Die Datenbank erzwingt weiterhin die Garantien; der Wert liegt im schnelleren Weg von einem korrekten Entwurf zu einer funktionierenden Implementierung.
ACID in verteilten und Multi-Service-Systemen
Transaktionen klar planen
Nutzen Sie einen planungsorientierten Chat, um Invarianten, Tabellen und Transaktionsgrenzen vor dem Codieren festzulegen.
Eine einzelne Datenbank liefert normalerweise ACID-Garantien innerhalb einer Transaktionsgrenze. Sobald Sie Arbeit über mehrere Services (und oft mehrere Datenbanken) verteilen, sind diese Garantien schwerer zu halten — und teurer, wenn Sie sie durchsetzen.
Konsistenz vs. Verfügbarkeit: die Trade-offs, die Sie in Produktion spüren
Strikte Konsistenz bedeutet, jeder Read sieht die „aktuellste committe Wahrheit“. Hohe Verfügbarkeit bedeutet, das System antwortet weiterhin, selbst wenn Teile langsam oder unerreichbar sind.
In einer Multi-Service-Architektur kann ein temporäres Netzwerkproblem eine Wahl erzwingen: warten/fehlschlagen, bis alle Teilnehmer zustimmen (mehr Konsistenz, weniger Verfügbarkeit), oder akzeptieren, dass Services kurz inkonsistent sind (mehr Verfügbarkeit, weniger Konsistenz). Keines davon ist immer richtig — es hängt davon ab, welche Fehler Ihr Business tolerieren kann.
Warum verteilte Transaktionen schwierig sind
Verteilte Transaktionen erfordern Koordination über Grenzen, die Sie nicht vollständig kontrollieren: Netzwerkverzögerungen, Retries, Timeouts, Service-Abstürze und partielle Fehler.
Selbst wenn jeder Service korrekt arbeitet, kann das Netzwerk Mehrdeutigkeiten schaffen: Hat der Zahlungsservice committed, aber der Bestellservice die Bestätigung nie erhalten? Um das sicher zu lösen, nutzen Systeme Koordinationsprotokolle (z. B. Two-Phase Commit), die langsam sein, Verfügbarkeit bei Fehlern reduzieren und operative Komplexität erhöhen können.
Praktische Muster, die „eine große Transaktion" ersetzen
Sagas teilen einen Workflow in Schritte, die jeweils lokal committed werden. Schlägt ein späterer Schritt fehl, werden frühere Schritte mit Kompensationsaktionen rückgängig gemacht (z. B. Rückerstattung einer Zahlung).
Outbox/Inbox-Pattern machen das Publizieren und Konsumieren von Events zuverlässig. Ein Service schreibt die Geschäftsdaten und einen „zu publishenden Event“-Datensatz in derselben lokalen Transaktion (Outbox). Konsumenten protokollieren verarbeitete Nachrichten-IDs (Inbox), um Retries ohne Duplikate zu handhaben.
Eventual Consistency akzeptiert kurze Zeitfenster, in denen Daten zwischen Services abweichen, und hat einen klaren Plan zur Nachbearbeitung.
Wann Sie Garantien lockern können — und wie Sie Risiken kontrollieren
Lockern Sie Garantien, wenn:
- Sie temporäre Abweichungen tolerieren können (z. B. Versandstatus hinkt der Bestellerstellung hinterher).
- Sie Fehler mit Kompensationen korrigieren können (Rückerstattungen, Stornierungen).
- Latenz und Uptime wichtiger sind als sofortige globale Korrektheit.
Kontrollieren Sie Risiken, indem Sie Invarianten definieren (was niemals verletzt werden darf), idempotente Operationen gestalten, Timeouts und Retries mit Backoff verwenden und Drift überwachen (hängende Sagas, wiederholte Kompensationen, wachsende Outbox-Tabellen). Für wirklich kritische Invarianten (z. B. „nie ein Konto überziehen") halten Sie diese möglichst innerhalb eines einzelnen Services und einer einzigen Datenbanktransaktion.
Praktische Checkliste: ACID-Systeme entwerfen, testen und überwachen
Eine Transaktion kann im Unit-Test „korrekt“ sein und dennoch unter realem Traffic, Neustarts und Nebenläufigkeit versagen. Nutzen Sie diese Checkliste, damit ACID-Garantien mit dem Verhalten Ihres Systems in Produktion übereinstimmen.
1) Design: Invarianten und Transaktionsgrenzen definieren
Beginnen Sie damit, aufzuschreiben, was immer wahr sein muss (Ihre Dateninvarianten). Beispiele: „Kontostand wird nie negativ“, „Bestelltotal = Summe der Positionen“, „Bestand darf nicht unter Null fallen“, „eine Zahlung ist genau einer Bestellung zugeordnet“. Betrachten Sie diese als Produktregeln, nicht als DB-Trivia.
Entscheiden Sie dann, was innerhalb einer Transaktion sein muss und was verzögert werden kann.
- Dateninvarianten: listen Sie die Tabellen/Zeilen und die exakte Regel auf.
- Ausfallszenarien: Prozessabsturz mitten in der Anfrage, Netzwerk-Timeout nach Commit, Retry verursacht Duplikate, Replica-Failover, volles Laufwerk.
- Nebenläufigkeitsprofil: welche Operationen laufen parallel (Checkout-Spitzen, Batch-Updates, geplante Jobs), erwartete Kontentions-Hotspots und ob Reads „jetzt“ sein müssen oder leicht veraltet sein dürfen.
Halten Sie Transaktionen klein: weniger Zeilen berühren, weniger Arbeit tun (keine externen API-Aufrufe) und schnell committen.
2) Test: Verhalten unter Rennen und Fehlern beweisen
Machen Sie Nebenläufigkeit zu einer erstklassigen Testdimension.
- Race-Condition-Tests: führen Sie dieselbe kritische Operation parallel aus (z. B. zwei Checkouts für das letzte Stück) und prüfen Sie, dass Invarianten nie gebrochen werden.
- Fault Injection: beenden Sie den App-Prozess mitten in einer Transaktion; injizieren Sie Timeouts; simulieren Sie Retries; erzwingen Sie einen DB-Neustart; verifizieren Sie, dass Ergebnisse entweder einmal commitet oder sicher zurückgerollt wurden.
- Load-Tests mit Korrektheitsprüfungen: validieren Sie unter Spitzenlast nicht nur Latenzen, sondern auch Summen, Counts und „keine Duplikate"-Constraints.
Wenn Sie Retries unterstützen, fügen Sie einen expliziten Idempotenz-Schlüssel hinzu und testen Sie „Anfrage wiederholt nach Erfolg".
3) Monitoring: ACID-Schmerzen erkennen, bevor Nutzer es tun
Beobachten Sie Indikatoren, dass Ihre Garantien teuer oder fragil werden:
- Lock-Waits und Queue-Zeiten (steigende Kontention)
- Deadlocks (Häufigkeit, betroffene Queries)
- Lang laufende Transaktionen (oft die Wurzel)
- Replikations-Lag (veraltete Reads und verzögertes Failover)
- Commit/fsync-Zeiten (Storage-Druck; Kosten der Dauerhaftigkeit)
Alarmieren Sie auf Trends, nicht nur auf Peaks, und verknüpfen Sie Metriken mit den Endpunkten oder Jobs, die sie verursachen.
Faustregeln: Isolation und Transaktionsumfang
Verwenden Sie die schwächste Isolation, die Ihre Invarianten noch schützt; setzen Sie sie nicht standardmäßig auf Maximum. Wenn Sie strikte Korrektheit für einen kleinen kritischen Abschnitt benötigen (Geldbewegung, Bestandsreduzierung), begrenzen Sie die Transaktion auf genau diesen Abschnitt und halten Sie alles andere außen vor.