Warum Backend‑Frameworks mehr sind als „nur Stack‑Wahl"
Ein Backend‑Framework ist mehr als ein Bündel Bibliotheken. Bibliotheken helfen bei Einzelaufgaben (Routing, Validierung, ORM, Logging). Ein Framework fügt eine meinungsstarke „Arbeitsweise“ hinzu: eine voreingestellte Projektstruktur, gängige Muster, integrierte Werkzeuge und Regeln dafür, wie die Teile zusammenhängen.
Frameworks prägen alltägliche Entscheidungen
Ist ein Framework einmal eingeführt, gibt es hunderte kleine Entscheidungen vor:
- Wo neuer Code leben soll (Features, Module, Services)
- Wie Requests durch die App laufen (Controller, Middleware, Handler)
- Wie Querschnittsbelange wie Auth, Validierung und Fehler gehandhabt werden
- Wie Teams Dinge benennen, Tests schreiben und Pull Requests reviewen
Deshalb können zwei Teams, die „die gleiche API“ bauen, sehr unterschiedliche Codebasen haben — selbst wenn Sprache und Datenbank gleich sind. Die Konventionen des Frameworks werden zur Standardantwort auf „Wie machen wir das hier?"
Geschwindigkeit und Konsistenz vs. Flexibilität
Frameworks tauschen oft Flexibilität gegen vorhersehbare Struktur. Der Vorteil: schnelleres Onboarding, weniger Debatten und wiederverwendbare Muster, die zufällige Komplexität reduzieren. Der Nachteil: Framework‑Konventionen können einschränkend wirken, wenn euer Produkt unübliche Workflows, Performance‑Tuning oder nicht‑standardmäßige Architekturen braucht.
Die bessere Frage ist nicht „Framework oder nicht“, sondern wie viel Konvention ihr wollt — und ob das Team die Kosten der fortlaufenden Anpassung tragen will.
Wer sollte sich dafür interessieren
- Entwickler: weniger Muster neu erfinden, mehr Zeit für Features
- Tech‑Leads: klarere Standards für Architektur, Tests und Reviews
- Product‑Teams: vorhersehbarere Lieferung und weniger Qualitäts‑Regressionen, wenn die Codebasis wächst
Framework‑Defaults, die eure Projektstruktur bestimmen
Die meisten Teams starten nicht mit einem leeren Ordner, sondern mit dem „empfohlenen“ Layout eines Frameworks. Diese Defaults bestimmen, wohin Leute Code legen, wie sie Dinge benennen und was sich in Reviews „normal“ anfühlt.
Zwei gängige Default‑Denkrichtungen
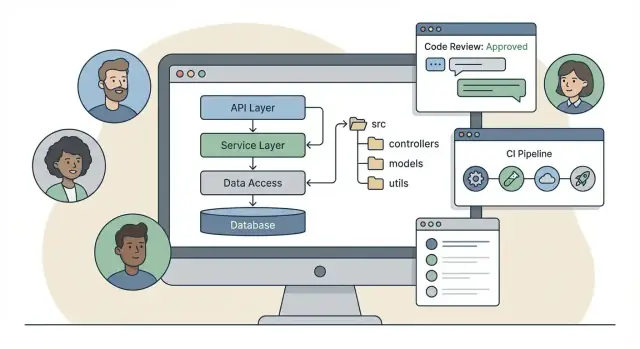
Einige Frameworks fördern die klassische geschichtete Struktur: controllers / services / models. Sie ist leicht zu lernen und passt gut zur Request‑Verarbeitung:
/src
/controllers
/services
/models
/repositories
Andere Frameworks neigen zu Feature‑Modulen: alles zu einer Funktionalität gruppiert (HTTP‑Handler, Domain‑Regeln, Persistenz). Das fördert lokales Denken — bei „Billing“ öffnet man einen Ordner:
/src
/modules
/billing
/http
/domain
/data
Keines ist automatisch besser, aber beide prägen Gewohnheiten. Geschichtete Strukturen erleichtern die Zentralisierung von Querschnittsstandards (Logging, Validierung, Fehlerbehandlung). Modul‑zuerst‑Strukturen reduzieren horizontales Scrollen im wachsenden Codebestand.
CLI‑Generatoren sind klebrig. Wenn der Generator für jeden Endpoint ein Controller+Service‑Paar erstellt, werden Leute das weiter tun — selbst wenn eine einfache Funktion ausgereicht hätte. Wenn er ein Modul mit klaren Grenzen erzeugt, respektieren Teams diese Grenzen eher unter Zeitdruck.
Dasselbe zeigt sich in „Vibe‑Coding“‑Workflows: Produzieren die Plattform‑Defaults ein vorhersehbares Layout und klare Modul‑Nähte, bleibt die Codebasis beim Wachsen kohärent. Zum Beispiel erzeugt Koder.ai Full‑Stack‑Apps aus Chat‑Prompts; der praktische Nutzen (neben Geschwindigkeit) ist, dass Teams früh auf konsistente Strukturen standardisieren können — und diese wie jeden anderen Code iterativ weiterentwickeln (inklusive Export des Quellcodes, wenn volle Kontrolle gewünscht ist).
„Fette Controller“ vermeiden
Frameworks, die Controller in den Mittelpunkt stellen, verleiten dazu, Geschäftsregeln in Request‑Handler zu stopfen. Eine nützliche Faustregel: Controller übersetzen HTTP → Anwendungsaufruf und nicht mehr. Geschäftslogik gehört in eine Service/Use‑Case‑Schicht (oder Domain‑Schicht eines Moduls), sodass sie ohne HTTP getestet und von Hintergrundjobs oder CLI‑Tasks wiederverwendet werden kann.
Schnellcheck für eure Struktur
Wenn du nicht in einem Satz beantworten kannst „Wo liegt die Preislogik?“, kämpfen eure Framework‑Defaults vielleicht gegen euer Domain‑Modell. Passt früh an — Ordner lassen sich leicht ändern; Gewohnheiten nicht.
Request‑Flow: Routing, Controller und Middleware‑Konventionen
Ein Backend‑Framework definiert, wie eine Anfrage durch euren Code laufen sollte. Wenn alle dem gleichen Request‑Pfad folgen, werden Features schneller geliefert und Reviews drehen sich eher um Korrektheit als um Stil.
Routing: die öffentliche Inhaltsübersicht eures Systems
Routen sollten wie ein Inhaltsverzeichnis eurer API lesbar sein. Gute Frameworks fördern Routen, die:
- Deklarativ sind (man kann scannen, was exponiert ist)
- Konsistent sind (gleiche URL‑Patterns und HTTP‑Verben im ganzen Codebestand)
- Nahe an der Peripherie bleiben (Routing‑Konfiguration sollte keine Geschäftsregeln enthalten)
Eine praktische Konvention: Route‑Dateien fokussieren auf Mapping: GET /orders/:id -> OrdersController.getById, nicht „wenn Nutzer VIP, dann X tun“.
Controller/Handler: dünne Request‑Übersetzer
Controller funktionieren am besten als Übersetzer zwischen HTTP und eurer Kernlogik:
- Eingaben lesen (params, headers, body)
- Einen Service/Use‑Case aufrufen
- Eine Antwort zurückgeben
Wenn Frameworks Helfer für Parsing, Validierung und Antwort‑Formatierung bereitstellen, besteht die Versuchung, Logik in Controller zu packen. Das gesündere Muster ist „dünne Controller, dicke Services“: HTTP‑Belange in Controller, Geschäftsentscheidungen in einer Schicht, die nichts von HTTP weiß.
Middleware/Filter: ein Ort für Querschnittsbelange
Middleware (oder Filter/Interceptors) bestimmt, wo wiederkehrende Verhaltensweisen wie Auth, Logging, Rate‑Limiting und Request‑IDs leben. Die Schlüsselkonvention: Middleware soll die Anfrage bereichern oder schützen, aber keine Produktregeln implementieren.
Zum Beispiel kann Auth‑Middleware req.user anhängen, und Controller geben diese Identität an die Kernlogik weiter. Logging‑Middleware standardisiert, was geloggt wird, ohne dass jeder Controller es neu erfindet.
Namenskonventionen, die Review‑Reibung reduzieren
Einigt euch auf vorhersehbare Namen:
OrdersController, OrdersService, CreateOrder (Use‑Case)authMiddleware, requestIdMiddlewarevalidateCreateOrder (Schema/Validator)
Wenn Namen die Absicht kodieren, konzentrieren sich Code‑Reviews auf Verhalten, nicht darauf, wo etwas „hingehört".
Schichten und Grenzen: Wo Geschäftslogik lebt
Ein Backend‑Framework hilft nicht nur beim Bereitstellen von Endpunkten — es drängt euer Team in eine bestimmte „Form“ von Code. Ohne frühzeitige Grenzdefinition ist die Default‑Gravitation oft: Controller rufen das ORM, das ORM ruft die DB, und Geschäftsregeln landen überall.
Eine praktische geschichtete Architektur
Eine einfache, dauerhafte Aufteilung sieht so aus:
- Presentation Layer: HTTP‑Belange (Routing, Controller, Auth‑Middleware). Wandelt Requests in App‑Befehle und Antworten zurück.
- Application Layer: Use‑Cases (z. B.
CreateInvoice, CancelSubscription). Orchestriert Arbeit und Transaktionen, bleibt framework‑arm.
- Domain Layer: Kern‑Geschäftsregeln und Konzepte (Entities, Policies, Domain‑Services). Sollte wie die Fachsprache lesbar sein, nicht wie SQL.
- Data Layer: Repositories, ORM‑Modelle/Mapper, Queries, Migrations.
Frameworks, die „controller + services + repositories“ erzeugen, sind hilfreich — wenn ihr es als Richtung seht und nicht als Pflicht, dass jedes Feature jede Schicht braucht.
Wie ORM und Repositories Grenzen beeinflussen
Ein ORM verleitet dazu, Datenbankmodelle überall hin zu reichen, weil sie bequem und teilweise validiert sind. Repositories helfen, indem sie ein engeres Interface bieten („get customer by id“, „save invoice“), sodass Application‑ und Domain‑Code nicht von ORM‑Details abhängen.
Um „alles hängt von der DB ab“ zu vermeiden:
- Gebt ORM‑Entitäten nicht direkt aus Controller zurück.
- Haltet Query‑Shapes in der Data‑Layer; Regeln bleiben in der Domain.
- Bevorzugt domain‑freundliche Ein‑ und Ausgaben für Use‑Cases.
Wann eine Service‑Schicht einführen (und wann nicht)
Führt eine Service/Application‑Use‑Case‑Schicht ein, wenn Logik zwischen Endpunkten wiederverwendet wird, Transaktionen nötig sind oder Regeln konsistent durchgesetzt werden müssen. Bei einfachem CRUD ohne Geschäftsverhalten kann eine zusätzliche Schicht Zeremonie ohne Klarheit bringen — dann weglassen.
Dependency Injection und modulare Design‑Gewohnheiten
Dependency Injection (DI) ist ein Framework‑Default, der euer ganzes Team prägt. Wenn DI ins Framework eingebaut ist, vermeidet ihr das „new‑ing up“ von Services überall und beginnt, Abhängigkeiten deklarativ, verdrahtbar und austauschbar zu behandeln.
Was DI fördert (und komplizieren kann)
DI schiebt Teams zu kleinen, fokussierten Komponenten: Ein Controller hängt von einem Service ab, ein Service von einem Repository, und jede Komponente hat eine klare Rolle. Das verbessert Testbarkeit und erleichtert das Ersetzen von Implementierungen (z. B. echtes Zahlungs‑Gateway vs. Mock).
Der Nachteil: DI kann Komplexität verbergen. Haben alle Klassen fünf Abhängigkeiten, wird schwerer nachzuvollziehen, was bei einer Anfrage tatsächlich läuft. Fehlkonfigurierte Container erzeugen Fehler, die weit entfernt von dem Code erscheinen, den man gerade ändert.
Konstruktorinjektion und interface‑orientiertes Design
Die meisten Frameworks fördern Konstruktorinjektion, weil sie Abhängigkeiten explizit macht und Service‑Locator‑Anti‑Patterns verhindert.
Eine hilfreiche Gewohnheit ist, Konstruktorinjektion mit interface‑getriebenem Design zu koppeln: Code hängt an einem stabilen Vertrag (z. B. EmailSender) statt an einem spezifischen Vendor‑Client. Das hält Änderungen lokal, wenn ihr Provider wechselt oder refaktoriert.
Kohäsive Module ohne zirkuläre Abhängigkeiten
DI funktioniert am besten, wenn Module kohäsiv sind: Ein Modul besitzt eine Funktionalitäts‑Scheibe (Orders, Billing, Auth) und exponiert eine kleine öffentliche Oberfläche.
Zirkuläre Abhängigkeiten sind ein typischer Fehlerfall. Sie zeigen oft, dass Grenzen unklar sind — zwei Module teilen Konzepte, die ein eigenes Modul verdienen, oder ein Modul tut zu viel.
Übereinkunft, wo das Wiring passiert
Teams sollten sich einigen, wo Abhängigkeiten registriert werden: ein einzelner Composition‑Root (Startup/Bootstrap) plus Modul‑lokales Wiring für interne Verdrahtung.
Zentralisiertes Wiring erleichtert Reviews: Reviewer sehen neue Abhängigkeiten, prüfen deren Berechtigung und verhindern ein „Container‑Sprawl“, das DI vom Werkzeug zum Rätsel macht.
Projektlayout standardisieren
Generiere eine Full-Stack-App mit vorhersehbarer Struktur, die dein Team konsistent halten kann.
Ein Backend‑Framework beeinflusst, was euer Team unter einer „guten API“ versteht. Wenn Validierung eine erstklassige Rolle spielt (Decoratoren, Schemas, Pipes, Guards), entwerfen Entwickler Endpunkte anhand klarer Eingaben und vorhersehbarer Ausgaben — weil das richtige Tun einfacher ist als es wegzulassen.
Wenn Validierung an der Grenze liegt (vor der Geschäftslogik), behandeln Teams Request‑Payloads als Verträge, nicht als „was der Client halt schickt“. Das führt meist zu:
- Expliziten required vs. optional Feldern (weniger Diskussionen über „null bedeutet unbekannt“)
- Klaren Regeln für Formate (Dates, IDs, Enums) und Constraints (min/max, Länge)
- Früher Ablehnung schlechter Requests, sodass Service‑Code sich auf Geschäftsregeln konzentriert
Frameworks fördern dabei gemeinsame Konventionen: wo Validierung definiert wird, wie Fehler dargestellt werden und ob unbekannte Felder erlaubt sind.
Zentralisierte Fehler sorgen für konsistente Client‑Erwartungen
Frameworks mit globalen Exception‑Filtern/Handlern machen Konsistenz erreichbar. Anstatt dass jeder Controller eigene Antworten erfindet, könnt ihr standardisieren:
- Fehler‑Envelope (z. B.
code, message, details, traceId)
- Mapping auf HTTP‑Statuscodes (Validation → 400, Auth → 401/403, Not Found → 404)
- Logging und Korrelations‑IDs, damit Support eine einzelne fehlgeschlagene Anfrage debuggen kann
Ein konsistentes Fehlerformat reduziert Client‑Branching‑Logik und macht API‑Docs verlässlicher.
DTOs und View‑Modelle schützen euer Innenleben
Viele Frameworks treiben euch zu DTOs (Input) und View‑Modellen (Output). Das ist gesund: es verhindert das versehentliche Offenlegen interner Felder, vermeidet Kopplung der Clients an DB‑Schemata und macht Refactoring sicherer. Praktische Regel: Controller sprechen DTOs; Services sprechen Domain‑Modelle.
Versionierung und Backward‑Compatibility‑Basics
Auch kleine APIs entwickeln sich. Routing‑Konventionen bestimmen oft, ob Versionierung URL‑basiert (/v1/...) oder header‑basiert erfolgt. Was auch immer ihr wählt: legt die Grundregeln früh fest: Felder niemals ohne Deprecation‑Window entfernen, Felder abwärtskompatibel hinzufügen und Änderungen an einer Stelle dokumentieren (z. B. /docs oder /changelog).
Ein Backend‑Framework bestimmt nicht nur, wie ihr Features ausliefert; es legt fest, wie ihr sie testet. Der eingebaute Test‑Runner, Bootstrapping‑Utilities und der DI‑Container machen oft aus, was einfach ist — und damit, was das Team tatsächlich macht.
Framework‑Helfer: Unit vs Integration vs End‑to‑End
Viele Frameworks bieten einen „Test‑App“ Bootstrapper, der Container hochfährt, Routen registriert und Requests im Speicher ausführt. Das schiebt Teams leicht zu Integrationstests — weil sie nur ein paar Zeilen mehr Aufwand als ein Unit‑Test sind.
Eine praktische Aufteilung:
- Unit‑Tests für reine Geschäftslogik (kein Framework‑Boot, keine DB).
- Integrationstests für Module/Services, die über den Framework‑Container verdrahtet sind.
- End‑to‑End‑Tests für echtes HTTP‑Verhalten (Routing, Middleware, Auth, Fehlermapping).
Eine Testpyramide, die auf Backend‑Services passt
Für die meisten Services zählt Geschwindigkeit mehr als perfekte Pyramiden‑Reinheit. Gute Regel: viele kleine Unit‑Tests, ein fokussierter Satz Integrationstests an den Grenzen (DB, Queues) und eine dünne E2E‑Schicht, die den Vertrag beweist.
Wenn euer Framework Request‑Simulation günstig macht, könnt ihr etwas stärker auf Integrationstests setzen — ohne Domain‑Logik zu vermischen, damit Unit‑Tests stabil bleiben.
Mocking passend zu DI und Laufzeit
Die Mocking‑Strategie sollte dem entsprechen, wie euer Framework Abhängigkeiten löst:
- Bevorzugt Überschreiben von DI‑Bindings (echten Email‑Client gegen Fake tauschen) statt Monkey‑Patching von Imports.
- Nutzt In‑Memory‑Adapter wo möglich (z. B. In‑Memory‑Repositories), um fragile Mocks zu vermeiden.
- Mockt an der Modulgrenze, nicht innerhalb der Geschäftslogik, damit Refactorings Tests nicht unnötig brechen.
Schnelle, zuverlässige Tests für CI
Framework‑Boot‑Zeit kann die CI dominieren. Haltet Tests schnell, indem ihr teures Setup cached, DB‑Migrationen einmal pro Suite laufen lasst und Parallelisierung nur dort nutzt, wo Isolation garantiert ist. Macht Fehlerdiagnosen einfach: konsistente Seeding, deterministische Uhren und strikte Cleanup‑Hooks sind besser als „retry on fail".
Skalierung des Codebestands: Module, Packages und Shared Code
Auch später flexibel bleiben
Exportiere den kompletten Quellcode, wenn du volle Kontrolle über Refactorings und Upgrades möchtest.
Frameworks helfen nicht nur beim ersten API; sie prägen, wie euer Code wächst, wenn aus „einem Service" Dutzende Features, Teams und Integrationen werden. Die Mechanik für Module und Packages, die ein Framework vereinfacht, wird oft zur Langzeit‑Architektur.
Modularitätsmuster, die Frameworks fördern
Die meisten Backend‑Frameworks treiben Modularität per Design voran: Apps, Plugins, Blueprints, Module, Feature‑Ordner oder Packages. Wenn das Default ist, fügen Teams neue Fähigkeiten meist als „ein weiteres Modul“ hinzu, statt Dateien über das ganze Projekt zu verstreuen.
Praktische Regel: Behandle jedes Modul wie ein Mini‑Produkt mit eigener öffentlicher Oberfläche (Routes/Handler, Service‑Interfaces), privaten Interna und Tests. Wenn Auto‑Discovery (z. B. Module‑Scanning) unterstützt wird, nutze sie mit Bedacht — explizite Imports machen Abhängigkeiten oft leichter nachvollziehbar.
Kerndomain vs Infrastrukturmodule
Mit wachsendem Codebestand wird das Vermischen von Geschäftsregeln und Adaptern teuer. Nützliche Trennung:
- Core‑Domain‑Module: Geschäftsregeln, Policies, Domain‑Services und Domain‑Modelle (sollten einen DB‑Swap überleben)
- Infrastruktur‑Module: DB‑Clients, ORM‑Modelle, Message‑Broker, HTTP‑Clients, Caches, Auth‑Provider
Framework‑Konventionen beeinflussen das: Fördert das Framework „Service‑Klassen“, platziert Domain‑Services in Core‑Modulen und Framework‑spezifisches Wiring (Controller, Middleware, Provider) an den Rändern.
Shared‑Libraries vs Copy‑Paste: Entscheidungsregeln
Teams teilen oft zu früh. Kopiere kleinen Code, bis er stabil ist; extrahiere erst, wenn:
- Zwei oder mehr Teams dieselbe Logik pflegen
- Ein Bugfix an mehreren Stellen nötig ist
- Du eine klare API definieren und versionieren kannst
Wenn ihr extrahiert, veröffentlicht interne Pakete (oder Workspace‑Libraries) mit strikter Ownership und Changelog‑Disziplin.
Vorbereitung auf modularen Monolith → Microservices (später)
Ein modularer Monolith ist oft die beste Zwischenlösung. Wenn Module klare Grenzen und minimale Cross‑Imports haben, lässt sich ein Modul später leichter in einen Service heben. Entwerft Module um Business‑Fähigkeiten, nicht um technische Schichten. Für eine tiefere Strategie siehe /blog/modular-monolith.
Konfiguration, Umgebungen und Betriebsbereitschaft
Das Konfigurationsmodell eines Frameworks bestimmt, wie konsistent (oder chaotisch) Deployments sind. Wenn Config über verstreute Dateien, zufällige Environment‑Variablen und „nur diese eine Konstante“ verteilt ist, debuggt das Team Unterschiede statt neue Features zu bauen.
Konfigurationsstil = Konsistenz
Die meisten Frameworks treiben euch zu einer primären Quelle der Wahrheit: Konfigurationsdateien, Environment‑Variablen oder code‑basierte Konfiguration (Module/Plugins). Was ihr auch wählt, standardisiert es früh:
- Dateien sind gut für lokale Entwicklung und klare Defaults (z. B.
config/default.yml).
- Environment‑Variablen sind ideal für Deployment‑Unterschiede und Container‑Plattformen.
- Code‑basierte Config ist mächtig, aber sie versteckt leicht wichtige Einstellungen hinter Logik.
Gute Konvention: Defaults in versionierten Config‑Dateien, Env‑Vars überschreiben pro Umgebung, und Code liest aus einem typisierten Config‑Objekt. So ist „wo ändert man einen Wert“ im Incident klar.
Secrets: als eigene Kategorie behandeln
Frameworks bieten oft Helfer für Env‑Vars, Secret‑Stores oder Startup‑Validierung. Nutzt das, damit Secrets schwer falsch zu handhaben sind:
- Keine Secrets ins Repo (auch keine „temporären“ Keys)
- Secrets nicht in Logs oder Fehlerseiten ausgeben
- Laufzeitinjektion (CI/CD, Orchestrator, Secret‑Manager) statt lokaler
.env‑Wildnis
Habt das Ziel: Entwickler können lokal mit sicheren Platzhaltern laufen, während echte Credentials nur in der Umgebung existieren, die sie braucht.
Environment Parity: dev, staging, production
Framework‑Defaults fördern entweder Parität (gleicher Boot‑Prozess überall) oder Spezialfälle („Production hat anderen Server‑Entrypoint"). Ziel: gleicher Startbefehl und gleiche Config‑Schemata in allen Umgebungen, nur andere Werte.
Staging ist Generalprobe: gleiche Feature‑Flags, gleiche Migrations‑Pfad, gleiche Background‑Jobs — nur kleineres Scale.
Konfiguration wie eine API dokumentieren
Wenn Config nicht dokumentiert ist, raten Teammitglieder — und Raten wird zu Ausfällen. Haltet im Repo eine kurze Referenz (z. B. /docs/configuration) mit:
- jedem Config‑Key und seiner Wirkung
- erwartetem Typ/Format (string, URL, integer)
- Default‑Wert und sicheren Beispielen
- welchen Umgebungen er gesetzt werden sollte
Viele Frameworks validieren Config beim Boot. Kombiniert das mit Dokumentation und ihr reduziert „works on my machine“ zu einer seltenen Ausnahme.
Observability‑Standards, gesetzt vom Framework
Ein Framework legt die Basis dafür, wie ihr das System in Produktion versteht. Wenn Observability integriert oder stark empfohlen ist, behandeln Teams Logs und Metriken nicht als „späteres“ Thema, sondern gestalten sie als Teil der API.
Logging, Tracing und Metriken: was ihr „gratis“ bekommt
Viele Frameworks integrieren strukturiertes Logging, verteiltes Tracing und Metrik‑Erfassung. Das beeinflusst Code‑Organisation: Querschnittsbelange werden zentral (Logging‑Middleware, Tracing‑Interceptors, Metrik‑Collector) statt mit print‑Statements in Controllern verteilt.
Gute Mindestfelder für jede request‑bezogene Logzeile:
correlation_id (oder request_id) um Logs across Services zu verbindenroute und method um den betroffenen Endpoint zu kennenuser_id oder account_id (wenn verfügbar) für Support‑Analysenduration_ms und status_code für Performance und Reliability
Framework‑Konventionen (Request‑Context‑Objekte, Middleware‑Pipelines) machen das Generieren und Weiterreichen von Correlation‑IDs einfach, sodass Entwickler dieses Muster nicht für jedes Feature neu erfinden.
Healthchecks und Readiness‑Endpoints
Framework‑Defaults bestimmen oft, ob Healthchecks First‑Class sind oder eine Nachgedanke. Standardendpoints wie /health (Liveness) und /ready (Readiness) gehören idealerweise zur Definition von „Done“ und zwingen zu saubereren Grenzen:
- liveness: „läuft der Prozess?“
- readiness: „kann er Traffic bedienen?“ (z. B. DB‑Connection, Migrations angewendet)
Sind diese Endpoints früh Standard, lecken betriebliche Anforderungen nicht in beliebigen Feature‑Code.
Observability als Motor für Refactoring
Observability‑Daten sind ein Entscheidungswerkzeug. Wenn Traces zeigen, dass ein Endpoint wiederholt Zeit in derselben Abhängigkeit verbringt, ist das ein Signal, ein Modul zu extrahieren, Caching hinzuzufügen oder eine Query zu überarbeiten. Wenn Logs inkonsistente Fehlerformen zeigen, ist das ein Anlass, Fehlerbehandlung zu zentralisieren. Kurz: Framework‑Observability‑Hooks helfen nicht nur beim Debuggen — sie geben Vertrauen für Reorganisation.
Plane zuerst deine Architektur
Skizziere Module, Grenzen und den Anfragefluss, bevor du mit Koder.ai Planning Mode Code erzeugst.
Ein Backend‑Framework organisiert nicht nur Code — es setzt die Hausregeln für Teamarbeit. Wenn alle dieselben Konventionen (Dateiablage, Namensgebung, wie Abhängigkeiten verdrahtet werden) befolgen, werden Reviews schneller und Onboarding leichter.
Code‑Generierung und Scaffolds: nutzen, nicht vergöttern
Scaffolds standardisieren neue Endpunkte, Module und Tests in Minuten. Die Gefahr: Generatoren diktieren euer Domain‑Modell.
Nutzt Scaffolds für konsistente Gerüste, bearbeitet die Ausgabe sofort, sodass der Code wie ein durchdachtes Design wirkt — nicht wie ein Template‑Dump. Wenn ihr AI‑unterstützte Workflows nutzt, behandelt generierten Code mit derselben Disziplin: Review‑Gates für Modulgrenzen, DI‑Patterns, Fehlerformen.
Styleguides im Einklang mit Framework‑Idiomen
Frameworks implizieren oft idiomatische Strukturen: wo Validierung lebt, wie Fehler geworfen werden, wie Services benannt sind. Fasst diese Erwartungen in einem kurzen Team‑Styleguide zusammen:
- Namenskonventionen passend zu Framework‑Primitiven (z. B. Controller, Service, Module)
- Ordnergrenzen (was gehört in einen Controller vs. Domain/Service‑Layer)
- Beispiele für „gute“ Endpoint‑Implementationen
Haltet es leichtgewichtig und handlungsorientiert; verlinkt im Repo unter /contributing.
Macht Standards automatisch. Konfiguriert Formatter und Linter nach Framework‑Konventionen (Imports, Decorators/Annotations, Async‑Patterns). Erzwingt sie mit Pre‑Commit‑Hooks und CI, damit Reviews sich auf Design statt Whitespace konzentrieren.
PR‑Templates und Review‑Checklisten, abgestimmt auf Architektur
Ein Framework‑basierter Checklist verhindert schleichende Inkonsistenzen. Fügt ein PR‑Template hinzu, das Reviewer fragt, ob z. B.:
- neue Endpunkte Routing/Controller‑Konventionen folgen
- Validierung und Fehlerantworten dem Team‑Standard entsprechen
- Abhängigkeitsgrenzen respektiert werden (keine direkten DB‑Aufrufe aus Controllern)
- Tests dem Framework‑Muster folgen
Solche Workflow‑Guardrails halten Code wartbar, wenn das Team wächst.
Ein Framework wählen und weiterentwickeln, ohne schmerzhafte Rewrites
Framework‑Wahl prägt Muster — Ordnerlayout, Controller‑Stil, DI und sogar Test‑Praktiken. Ziel ist nicht das perfekte Framework, sondern eines, das zu eurer Art zu liefern passt und das Wechseln möglich hält, wenn Anforderungen sich ändern.
Passung an Teamgröße und Ziele evaluieren
Startet mit euren Delivery‑Beschränkungen, nicht mit einer Feature‑Checkliste. Ein kleines Team profitiert meist von starken Konventionen, Batteries‑included‑Tooling und schnellem Onboarding. Größere Teams brauchen klarere Modulgrenzen, stabile Extension‑Points und Muster, die versteckte Kopplung verhindern.
Stellt pragmatische Fragen:
- Lässt sich eine konsistente Struktur mit minimalem Review‑Policing durchsetzen?
- Macht das Framework das Richtige einfach (Validierung, Fehler, Logging) oder erfindet jedes Team seine eigene Lösung?
- Sind Upgrades vorhersehbar (Changelogs, Deprecation‑Pfade) und ist das Ökosystem reif genug?
Warnsignale, die Rewrites voraussagen
Ein Rewrite ist oft das Endergebnis ignorierter kleinerer Schmerzen. Achtet auf:
- Unklare Grenzen: Geschäftslogik driftet in Controller, Middleware oder ORM‑Modelle
- Langsame Tests: Integrationstests dauern Minuten, Teams überspringen sie
- Brittle Upgrades: häufige Breaking Changes, Abhängigkeit von internen APIs oder Community‑Workarounds
Inkrementelle Refactoring‑Muster, die Delivery erhalten
Ihr könnt euch entwickeln, ohne Feature‑Arbeit zu stoppen, indem ihr Nähte einführt:
- Strangler‑Pattern: leitet eine kleine Menge Endpunkte über ein neues Modul, während das alte System weiterläuft
- Adapter‑Layer: kapselt framework‑spezifische Primitiven hinter eigenen Interfaces (Request‑Context, Logger, Repositories)
- Ports‑und‑Adapters: bewegt Domain‑Logik in Plain‑Module mit minimalen Framework‑Imports und verbindet sie an den Rändern
Adoptions‑Checkliste und nächste Schritte
Bevor ihr euch festlegt (oder vor dem nächsten Major‑Upgrade), macht einen kurzen Trial:
- Baut einen echten Endpoint durch: Auth, Validierung, Fehlerantworten und Logging.
- Schreibt zwei Tests: einen schnellen Unit‑Test für Domain‑Logik und einen Integrationstest für die HTTP‑Schicht.
- Simuliert eine Änderung: Feld hinzufügen, Response versionieren und ein Modul refactoren.
- Lest die Release‑Notes der letzten Major‑Version: Hätte euch das geschadet?
Wenn ihr eine strukturierte Bewertung wollt, legt ein leichtgewichtiges RFC‑Dokument im Repo ab (z. B. /docs/decisions), damit zukünftige Teams verstehen, warum ihr gewählt habt — und wie man sicher wechselt.
Ein weiterer Blickwinkel: Wenn euer Team schnellere Build‑Loops (inkl. Chat‑gesteuerte Entwicklung) ausprobiert, prüft, ob der Workflow die gleichen architektonischen Artefakte liefert — klare Module, durchsetzbare Verträge und operable Defaults. Die besten Beschleuniger (CLI‑Tools oder Plattformen wie Koder.ai) verkürzen den Zyklus, ohne die Konventionen zu unterminieren, die ein Backend wartbar halten.