21. Sept. 2025·8 Min
Wie C und C++ weiterhin Betriebssysteme, Datenbanken und Game‑Engines antreiben
Erfahre, wie C und C++ durch Speichersteuerung, Geschwindigkeit und direkten Hardwarezugriff weiterhin den Kern von Betriebssystemen, Datenbanken und Game‑Engines bilden.
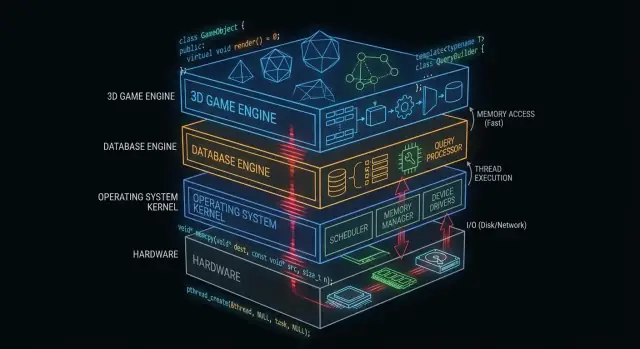
Warum C und C++ hinter den Kulissen noch wichtig sind
„Unter der Haube“ ist alles, wovon deine App abhängt, das sie aber selten direkt berührt: Betriebssystemkerne, Gerätetreiber, Speicher-Engines von Datenbanken, Netzwerkstacks, Laufzeitumgebungen und performance-kritische Bibliotheken.
Dagegen sehen viele Anwendungsentwickler im Alltag vor allem die Oberfläche: Frameworks, APIs, verwaltete Laufzeiten, Paketmanager und Cloud-Dienste. Diese Schichten sind auf Sicherheit und Produktivität ausgelegt — auch wenn sie bewusst Komplexität verbergen.
Warum manche Schichten nah an der Hardware bleiben müssen
Einige Softwarekomponenten haben Anforderungen, die sich nur schwer ohne direkte Kontrolle erfüllen lassen:
- Vorhersagbare Performance und Latenz (z. B. CPU-Scheduling, Interrupt-Verarbeitung, Streaming von Assets)
- Präzise Speichersteuerung (Layout, Alignment, Cache-Verhalten, Vermeidung von Pausen)
- Direkter Hardwarezugriff (Register, DMA, Treiber, Dateisysteme und Blockgeräte)
- Kleine, portable Binärdateien, die früh im Boot oder in beschränkten Umgebungen laufen können
C und C++ sind hier weiterhin verbreitet, weil sie in nativen Code ohne großen Laufzeit-Overhead übersetzt werden und Entwicklern feingranulare Kontrolle über Speicher und Systemaufrufe geben.
Wo C und C++ heute am häufigsten eingesetzt werden
Auf hoher Ebene findest du C und C++ in:
- Kernen von Betriebssystemen und low-level Bibliotheken
- Treibern und Embedded-Firmware
- Datenbank-Engines (Abfrageausführung, Speicherung, Indexierung)
- Game-Engines und Echtzeit-Subsystemen (Rendering, Physik, Audio)
- Compilern, Toolchains und Laufzeiten, auf die andere Sprachen bauen
Was dieser Beitrag behandelt (und was nicht)
Dieser Artikel konzentriert sich auf die Mechanik: Was diese „hinter den Kulissen“ liegenden Komponenten tun, warum sie von nativem Code profitieren und welche Trade-offs diese Macht mit sich bringt.
Er behauptet nicht, dass C/C++ immer die beste Wahl sind, und wird nicht zu einem Sprachkrieg. Ziel ist ein praktisches Verständnis, wo diese Sprachen weiterhin ihren Platz haben — und warum moderne Software-Stacks auf ihnen aufbauen.
Warum C und C++ für Systemsoftware geeignet sind
C und C++ werden häufig für Systemsoftware verwendet, weil sie Programme «nah an der Hardware» ermöglichen: klein, schnell und eng in OS und Hardware integriert.
Kompilierung zu nativen Code (einfach gesagt)
Wenn C/C++-Code kompiliert wird, entstehen Maschineninstruktionen, die die CPU direkt ausführen kann. Es gibt keine notwendige Laufzeit, die während der Ausführung etwas übersetzt.
Das ist wichtig für Infrastrukturkomponenten — Kernel, Datenbank-Engines, Game-Engines — wo selbst kleine Overheads unter Last addieren.
Vorhersagbare Performance für zentrale Infrastruktur
Systemsoftware braucht oft konsistente Timing-Eigenschaften, nicht nur gute mittlere Geschwindigkeit. Beispielsweise:
- Ein OS-Scheduler muss unter Last schnell reagieren.
- Eine Datenbank muss Latenzen stabil halten, während viele Nutzer gleichzeitig abfragen.
- Eine Game-Engine muss ein Frame-Budget treffen (z. B. ~16 ms für 60 FPS).
C/C++ erlauben Kontrolle über CPU-Nutzung, Speicherlayout und Datenstrukturen — das hilft, vorhersehbare Performance zu erreichen.
Direkter Speicher- und Pointer-Zugriff
Pointer erlauben die direkte Arbeit mit Speicheradressen. Diese Macht klingt einschüchternd, eröffnet aber Fähigkeiten, die viele höherwertige Sprachen abstrahieren:
- Angepasste Allocatoren, fein auf Workloads abgestimmt
- Kompakte In-Memory-Formate (nützlich in Datenbanken und Caches)
- Zero-copy-I/O-Muster, bei denen Daten nicht ständig dupliziert werden
Bei vorsichtiger Anwendung liefern solche Möglichkeiten erhebliche Effizienzgewinne.
Trade-offs: Sicherheit, Komplexität und Entwicklungszeit
Die gleiche Freiheit bringt Risiken mit sich. Häufige Trade-offs sind:
- Sicherheit: Fehler können Abstürze, Datenkorruption oder Sicherheitslücken verursachen.
- Komplexität: Manuelles Speichermanagement und undefiniertes Verhalten erfordern Disziplin.
- Entwicklungszeit: Tests, Reviews und Tooling sind für Zuverlässigkeit unverzichtbar.
Ein gängiger Ansatz ist, den performance-kritischen Kern in C/C++ zu halten und ihn mit sichereren Sprachen für Produktfunktionen und UX zu umgeben.
C/C++ in Betriebssystemkernen
Der Betriebssystemkern sitzt der Hardware am nächsten. Wenn dein Laptop aufwacht, dein Browser startet oder ein Programm mehr RAM anfordert, koordiniert der Kernel diese Anfragen und trifft die Entscheidungen.
Was ein Kernel praktisch macht
Kerne übernehmen einige zentrale Aufgaben:
- Scheduling: Entscheiden, welches Programm (welcher Thread) CPU-Zeit bekommt und wie lange.
- Speicherverwaltung: Prozessen Speicher zuteilen, Isolation sicherstellen und Speicher sicher zurückgewinnen.
- Geräteverwaltung: Mit Hardware über Treiber kommunizieren (Disk, Netzwerk, Tastatur, GPU usw.).
- Sicherheitsgrenzen: Berechtigungen durchsetzen, damit ein Programm nicht das eines anderen lesen oder korrumpieren kann.
Weil diese Zuständigkeiten zentral sind, ist Kernel-Code sowohl performance- als auch korrektheitssensitiv.
Warum enge Kontrolle C (und manchmal C++) begünstigt
Kernel-Entwickler brauchen präzise Kontrolle über:
- Speicherlayout: feste Strukturen, Alignment und vorhersehbares Allokationsverhalten.
- CPU-Instruktionen und Aufrufkonventionen: Interaktion mit Interrupts, Kontextwechseln und low-level Synchronisation.
- Hardware-Register: Lesen/Schreiben spezifischer Adressen und Umgang mit speziellen CPU-Modi.
C bleibt eine verbreitete „Kernsprache“, weil sie Maschinenkonzepte klar abbildet und gleichzeitig lesbar und portabel über Architekturen hinweg ist. Viele Kernel nutzen Assembly für die kleinsten, hardware-spezifischen Teile, während C den Großteil der Arbeit übernimmt.
C++ kann in Kernen auftauchen, meist jedoch in eingeschränktem Stil (begrenzte Laufzeitfeatures, vorsichtige Exception-Policies und strikte Regeln beim Allokieren). Wo es eingesetzt wird, dient es oft der Verbesserung von Abstraktion ohne Verlust von Kontrolle.
Kernel-nahe Komponenten oft in C/C++
Selbst wenn der Kernel konservativ bleibt, sind viele angrenzende Komponenten C/C++:
- Gerätetreiber (insbesondere performance-kritische)
- Standardbibliotheken und Laufzeiten (Teile von libc, low-level Threading)
- Bootloader und frühe Startsequenzen
- Systemdienste, die native Geschwindigkeit benötigen (z. B. Netzwerk- oder Speicherhilfen)
Mehr dazu, wie Treiber Software und Hardware verbinden, unter /blog/device-drivers-and-hardware-access.
Gerätetreiber und Hardwarezugang
Gerätetreiber übersetzen zwischen Betriebssystem und physischer Hardware — Netzwerkkarten, GPUs, SSD-Controller, Audiogeräte und mehr. Wenn du „Play“ klickst, eine Datei kopierst oder dich mit WLAN verbindest, ist ein Treiber oft der erste Code, der reagieren muss.
Da Treiber auf dem Hot Path für I/O liegen, sind sie extrem performance-sensitiv. Ein paar Mikrosekunden pro Paket oder Festplattenanfrage summieren sich auf stark belasteten Systemen schnell. C und C++ sind hier weiterhin verbreitet, weil sie direkte Aufrufe von Kernel-APIs, präzises Speicherlayout und minimalen Overhead erlauben.
Interrupts, DMA und warum low-level APIs wichtig sind
Hardware wartet nicht geduldig. Geräte signalisieren der CPU via Interrupts — dringende Benachrichtigungen, dass etwas passiert ist (Paket angekommen, Transfer abgeschlossen). Treiber müssen diese Ereignisse schnell und korrekt behandeln, oft unter strikten Timing- und Threading-Bedingungen.
Für hohen Durchsatz nutzen Treiber DMA (Direct Memory Access), bei dem Geräte Systemmemory lesen/schreiben, ohne dass die CPU jedes Byte kopiert. DMA-Aufsetzen umfasst typischerweise:
- Puffer in korrektem Format und Alignment vorbereiten
- Dem Gerät physische Adressen oder gemappte Deskriptoren übergeben
- Besitz des Speichers zwischen Gerät und CPU synchronisieren
Solche Aufgaben erfordern low-level Schnittstellen: memory-mapped Registers, Bitflags und sorgfältige Reihenfolge von Lese-/Schreibzugriffen. C/C++ machen es praktikabel, diese Nähe zur Hardware auszudrücken und dennoch über Compiler/Plattformen portabel zu bleiben.
Stabilität ist nicht verhandelbar
Im Gegensatz zu normalen Apps kann ein Treiberfehler das ganze System abstürzen, Daten korruptieren oder Sicherheitslücken öffnen. Dieses Risiko prägt, wie Treibercode geschrieben und geprüft wird.
Teams reduzieren Gefahr durch strikte Coding-Standards, defensive Checks und gestaffelte Reviews. Gängige Praktiken sind eingeschränkter Pointer-Einsatz, Validierung von Hardware-/Firmware-Eingaben und statische Analyse in CI.
Speicherverwaltung: Macht und Fallstricke
Mobile Oberfläche erstellen
Erstelle eine Flutter-Mobile-App und trenne Produktiteration von Low-Level-Optimierung.
Speicherverwaltung ist einer der Hauptgründe, warum C und C++ weiterhin Teile von Betriebssystemen, Datenbanken und Game-Engines dominieren. Gleichzeitig ist sie eine der leichtesten Stellen, subtile Bugs einzuführen.
Was „Speicherverwaltung“ praktisch bedeutet
Praktisch umfasst Speicherverwaltung:
- Allokieren von Speicher (einen Bereich zum Speichern von Daten bekommen)
- Freigeben (zurückgeben, wenn er nicht mehr gebraucht wird)
- Umgang mit Fragmentierung (verbliebene Lücken, die zukünftige Allokationen erschweren)
In C geschieht das oft explizit (malloc/free). In C++ kann es explizit sein (new/delete) oder durch sicherere Patterns gekapselt.
Warum manuelle Kontrolle ein Vorteil sein kann
In performance-kritischen Komponenten ist manuelle Kontrolle oft ein Feature:
- Unvorhersehbare Pausen durch Garbage Collection vermeiden
- Entscheiden, wo und wie Speicher allokiert wird (z. B. Pooled- oder Arena-Allocator), für bessere Konsistenz
- Allokationsmuster an reale Workloads anpassen (viele kleine Objekte vs. große zusammenhängende Puffer)
Das ist wichtig, wenn eine Datenbank konstante Latenz halten oder eine Game-Engine ein Frame-Time-Budget einhalten muss.
Häufige Fehlerarten (und warum sie ernst sind)
Die gleiche Freiheit schafft klassische Probleme:
- Memory Leaks: Vergessen, Speicher freizugeben, was Nutzung wachsen lässt bis Performance leidet oder der Prozess abstürzt.
- Buffer Overflows: Überschreiben eines Arrays-Endes, Daten korruptieren oder Exploits ermöglichen.
- Use-after-free: Einen Pointer nach der Freigabe verwenden, was zu schwer reproduzierbaren Abstürzen führt.
Diese Bugs sind oft subtil, weil das Programm „scheinbar in Ordnung“ ist, bis eine bestimmte Workload Fehler auslöst.
Wie moderne Praktiken helfen
Modernes C++ verringert Risiken ohne Kontrolle aufzugeben:
- RAII (Resource Acquisition Is Initialization) koppelt Ressourcen-Lifetime an Scope, sodass Aufräumen automatisch passiert.
- Smart Pointer (wie
std::unique_ptrundstd::shared_ptr) machen Besitz klar und verhindern viele Leaks. - Sanitizer (AddressSanitizer, UndefinedBehaviorSanitizer) und statische Analyse finden Probleme früh, oft in CI.
Richtig eingesetzt bleiben C/C++ schnell und machen Speicherbugs weniger wahrscheinlich im Produktivbetrieb.
Nebenläufigkeit und Multi-Core-Performance
Moderne CPUs werden pro Kern nicht dramatisch schneller — sie bekommen mehr Kerne. Die Frage verschiebt sich von „Wie schnell ist mein Code?“ zu „Wie gut läuft mein Code parallel, ohne sich selbst ins Bein zu schießen?“ C und C++ sind beliebt, weil sie low-level Kontrolle über Threading, Synchronisation und Speicherverhalten mit sehr geringem Overhead erlauben.
Threads, Kerne und Scheduling
Ein Thread ist die Einheit, mit der ein Programm Arbeit verrichtet; ein CPU-Kern ist der Ort, wo diese Arbeit läuft. Der OS-Scheduler mappt laufbare Threads auf verfügbare Kerne und trifft ständig Abwägungen.
Feine Scheduling-Details zählen in performance-kritischem Code: Das Pausieren eines Threads zum falschen Zeitpunkt kann eine Pipeline ins Stocken bringen, Warteschlangen aufbauen oder Stop-and-Go-Verhalten erzeugen. Bei CPU-gebundener Arbeit reduziert es oft Thrashing, aktive Threads grob an der Kernanzahl auszurichten.
Locking-Basics: Mutexes, Atomics und Contention
- Mutexes sind einfach zu verstehen, aber starke gemeinsame Nutzung erzeugt Contention — Zeit, die auf das Warten statt auf Arbeit verwendet wird.
- Atomics können für kleine gemeinsame Zustandsupdates schneller sein, erfordern aber sorgfältige Gestaltung, um subtile Korrektheitsfehler zu vermeiden.
Das praktische Ziel ist nicht „nie sperren“, sondern: weniger sperren, schlauer sperren — kritische Abschnitte klein halten, globale Locks vermeiden und gemeinsame veränderliche Zustände reduzieren.
Warum Latenzspitzen wichtig sind
Datenbanken und Game-Engines interessieren sich nicht nur für Durchschnittsgeschwindigkeit — sie achten auf Worst-Case-Pausen. Eine Lock-Convoy, ein Page-Fault oder ein gestoppter Worker kann sichtbares Stottern oder eine langsame Abfrage erzeugen, die ein SLA verletzt.
Übliche C/C++-Patterns
Viele Hochleistungs-Systeme nutzen:
- Threadpools zur Wiederverwendung von Arbeitern und für vorhersehbares Scheduling
- Work-stealing-Queues zur Lastverteilung über Kerne
- Lock-free-Queues (in ausgesuchten Hot-Paths) zur Reduktion von Blockaden — aber nur, weil Korrektheit hier schwerer zu belegen ist
Diese Patterns zielen auf stabilen Durchsatz und konsistente Latenz unter Last ab.
Datenbank-Engines: Wo C/C++ Geschwindigkeit liefern
Eine Datenbank-Engine speichert nicht einfach nur Zeilen. Sie ist eine enge Schleife aus CPU- und I/O-Arbeit, die Millionen von Malen pro Sekunde laufen kann — kleine Ineffizienzen summieren sich schnell. Deshalb sind viele Engines und Kernkomponenten immer noch größtenteils in C oder C++ geschrieben.
Die Hauptaufgabe der Engine: parsen, planen, ausführen
Wenn du SQL schickst, macht die Engine:
- Parsen (Text in eine strukturierte Darstellung umwandeln)
- Planen (eine effiziente Ausführungsstrategie wählen)
- Ausführen (Scans, Index-Lookups, Joins, Sorts, Aggregationen und Zeilenausgabe)
Jede Phase profitiert von sorgfältiger Kontrolle über Speicher und CPU-Zeit. C/C++ ermöglichen schnelle Parser, weniger Allokationen während des Plannings und einen schlanken Ausführungshotpath — oft mit maßgeschneiderten Datenstrukturen.
Storage-Engines: Pages, Indizes, Buffering
Unter der SQL-Schicht kümmert sich die Storage-Engine um die unglamourösen, aber essentiellen Details:
- Pages: Daten werden in festen Blöcken gelesen/geschrieben, nicht zeilenweise.
- Indizes: B-Bäume, LSM-Bäume und verwandte Strukturen müssen effizient aktualisiert werden.
- Buffering: Ein Buffer-Pool entscheidet, was im RAM bleibt, was verdrängt wird und wie Reads/Writes gebündelt werden.
C/C++ passen hier gut, weil diese Komponenten auf vorhersagbares Speicherlayout und direkten Zugriff auf I/O-Grenzen angewiesen sind.
Cache-freundliche Datenstrukturen (warum das zählt)
Moderne Performance hängt oft mehr von CPU-Caches als von roher CPU-Geschwindigkeit ab. Mit C/C++ können Entwickler häufig genutzte Felder zusammenpacken, Spalten in zusammenhängenden Arrays speichern und Pointer-Chasing minimieren — Muster, die Daten nah an der CPU halten und Wartezeiten reduzieren.
Wo höherwertige Sprachen trotzdem auftauchen
Auch in C/C++-dominierten Datenbanken treiben höherwertige Sprachen oft Admin-Tools, Backups, Monitoring, Migrationen und Orchestrierung voran. Der performance-kritische Kern bleibt nativ; das umgebende Ökosystem priorisiert Iterationsgeschwindigkeit und Usability.
Speicherung, Caching und I/O in Datenbanken
Schnell die erste Version veröffentlichen
Verwandle deine Idee in eine funktionierende Web-App, ohne zuerst eine vollständige Toolchain einzurichten.
Datenbanken wirken sofort, weil sie hart daran arbeiten, Festplattenzugriffe zu vermeiden. Selbst auf schnellen SSDs ist Lesen von Storage magnituden langsamer als Lesen aus RAM. Eine in C oder C++ geschriebene Engine kann jeden Schritt dieser Wartezeiten kontrollieren — und oft vermeiden.
Buffer-Pool und Page-Cache in einfachen Worten
Denk an Daten auf der Festplatte wie Kisten im Lager. Eine Kiste zu holen (Disk-Read) dauert, also hält man die meistgenutzten Dinge auf dem Schreibtisch (RAM).
- Buffer-Pool: Die Datenbank-eigene „Schreibtisch“-Fläche, die kürzlich genutzte Pages (feste Daten- und Indexblöcke) hält.
- Page-Cache: Der OS-eigene „Schreibtisch“, der zuletzt gelesene Dateidaten cached.
Viele Datenbanken verwalten ihren eigenen Buffer-Pool, um vorhersehbar zu bleiben und nicht mit dem OS um Speicher zu kämpfen.
Warum Disk langsam ist — und wie Caching das versteckt
Storage ist nicht nur langsam, sondern unvorhersehbar. Latenzspitzen, Queuing und zufälliger Zugriff fügen Verzögerungen hinzu. Caching mildert das, indem es:
- Reads meist aus RAM bedient
- Writes in weniger, größere I/O-Operationen bündelt
- Prefetching betreibt für Pages, die wahrscheinlich als Nächstes gebraucht werden (z. B. bei Index-Scans)
Designentscheidungen, die von Low-Level-Kontrolle profitieren
C/C++ erlauben Engines, Details zu optimieren, die bei hohem Durchsatz zählen: ausgerichtete Reads, Direct I/O vs. buffered I/O, maßgeschneiderte Eviction-Policies und sorgfältig strukturierte In-Memory-Layouts für Indizes und Log-Puffer. Solche Entscheidungen reduzieren Kopien, vermeiden Contention und halten CPU-Caches mit nützlichen Daten gefüttert.
Kompression und Checksummen können CPU-bound sein
Caching reduziert I/O, erhöht aber CPU-Arbeit. Dekomprimieren von Pages, Berechnen von Checksummen, Verschlüsseln von Logs und Validieren von Datensätzen können zu Flaschenhälsen werden. Da C und C++ Kontrolle über Speicherzugriffsmuster und SIMD-freundliche Schleifen bieten, werden sie oft eingesetzt, um mehr Arbeit pro Kern herauszuholen.
Game-Engines: Echtzeit-Anforderungen
Game-Engines haben strikte Echtzeitanforderungen: Der Spieler bewegt die Kamera, drückt eine Taste und die Welt muss sofort reagieren. Gemessen wird in Frame-Zeit, nicht in durchschnittlichem Durchsatz.
Frame-Budgets: warum Millisekunden zählen
Bei 60 FPS stehen etwa 16,7 ms zur Verfügung, um ein Frame zu erzeugen: Simulation, Animation, Physik, Audio-Mixing, Culling, Rendering-Submission und häufig Asset-Streaming. Bei 120 FPS schrumpft das Budget auf 8,3 ms. Wird das Budget verfehlt, nimmt der Spieler Stottern, Eingabeverzögerung oder inkonsistente Abläufe wahr.
Deshalb bleiben C-Programmierung und C++-Programmierung in Engine-Kernen verbreitet: vorhersagbare Performance, geringer Overhead und feine Kontrolle über Speicher und CPU.
Kernsubsysteme oft in C/C++
Die schwere Arbeit läuft meist in nativen Komponenten:
- Rendering (Szenen-Traversal, Draw-Call-Building, GPU-Resource-Management)
- Physik (Kollisionserkennung, Constraints, Rigid Bodies)
- Animation (Skeletal Blending, IK, Pose-Evaluation)
- Audio (Echtzeit-Mixing, Spatialization)
Diese Systeme laufen in jedem Frame, daher multiplizieren sich kleine Ineffizienzen.
Enge Schleifen und Datenlayout
Viel Game-Performance resultiert aus engen Schleifen: Entities iterieren, Transformupdates, Kollisionsprüfungen, Vertex-Skinning. C/C++ erleichtern es, Speicher für Cache-Effizienz zu strukturieren (zusammenhängende Arrays, weniger Allokationen, weniger virtuelle Indirektionen). Datenlayout kann ebenso wichtig sein wie die Algorithmuswahl.
Wo Scripting passt (und wo nicht)
Viele Studios nutzen Skriptsprachen für Gameplay-Logik — Quests, UI-Regeln, Trigger — weil Iterationsgeschwindigkeit wichtig ist. Der Engine-Kern bleibt typischerweise nativ, und Skripte rufen C/C++-Systeme über Bindings an. Ein übliches Muster: Skripte orchestrieren; C/C++ führen die teuren Teile aus.
Compiler, Toolchains und Interoperabilität
Native Code isoliert halten
Prototypisiere eine FFI-Schnittstelle und verbinde deine App mit bestehendem C- oder C++-Code.
C und C++ werden nicht einfach „ausgeführt“ — sie werden zu nativen Binärdateien gebaut, die zu einer bestimmten CPU und OS passen. Diese Build-Pipeline ist ein Hauptgrund, warum diese Sprachen zentral für OS, Datenbanken und Game-Engines bleiben.
Was beim Build tatsächlich passiert
Ein typischer Build hat mehrere Stufen:
- Compiler: Wandelt C/C++-Quelltext in maschinenspezifische Objektdateien um.
- Linker: Verknüpft Objekte mit Bibliotheken zu einer ausführbaren Datei oder Shared Library.
- Binäroutput: Das finale Artefakt, das das OS direkt laden kann (oft mit separaten Debug-Symbolen).
Vor allem im Linker treten viele reale Probleme auf: fehlende Symbole, inkompatible Bibliotheksversionen oder unterschiedliche Build-Settings.
Warum Toolchains und Plattformunterstützung zählen
Eine Toolchain ist das komplette Set: Compiler, Linker, Standardbibliothek und Build-Tools. Für Systemsoftware ist Plattformabdeckung oft entscheidend:
- Konsolen- und Mobil-SDKs verlangen spezifische Compiler/Linker.
- Datenbanken und Backend-Software brauchen stabile Builds über Linux-Distributionen und CPU-Typen.
- OS- und Treiberarbeit kann Cross-Compiler, strikte Flags und ABI-Disziplin erfordern.
Teams wählen C/C++ teilweise, weil Toolchains ausgereift und überall verfügbar sind — von Embedded-Geräten bis zu Servern.
Schnittstellen zu anderen Sprachen (FFI)
C wird oft als „universeller Adapter“ behandelt. Viele Sprachen können C-Funktionen via FFI aufrufen, daher legen Teams performance-kritische Logik in C/C++-Bibliotheken und exponieren eine kleine API an höherwertigen Code. Deshalb umhüllen Python, Rust, Java und andere häufig bestehende C/C++-Komponenten, statt sie neu zu schreiben.
Debugging und Profiling: Was Teams messen
C/C++-Teams messen typischerweise:
- CPU-Zeit (Hot-Functions, Callstacks)
- Speichernutzung (Allokationen, Leaks, Fragmentierung)
- Latenz (Frame-Time in Spielen, Query-Time in Datenbanken)
- I/O-Verhalten (Cache-Misses, Festplattenzugriffe, Syscalls)
Der Workflow ist konstant: Engstelle finden, mit Daten bestätigen, dann das kleinstmögliche Stück optimieren, das Wirkung zeigt.
Heute C/C++ wählen: Praktischer Entscheidungsleitfaden
C und C++ sind weiterhin exzellente Werkzeuge — wenn du Software baust, bei der wenige Millisekunden, wenige Bytes oder eine bestimmte CPU-Instruktion wirklich zählen. Sie sind nicht die Default-Wahl für jedes Feature oder Team.
Wann C/C++ die richtige Wahl sind
Wähle C/C++ wenn die Komponente performance-kritisch ist, enge Speichersteuerung braucht oder eng mit OS/Hardware integriert sein muss.
Typische Fälle:
- Hot-Paths mit sichtbarer Latenz (Parsing, Kompression, Rendering, Query-Ausführung)
- Low-Level-Module, die vorhersagbar sein müssen (Allocator, Scheduler, Netzwerk-Primitiven)
- Cross-Plattform-Bibliotheken, bei denen nativer Code das Produkt ist (SDKs, Engines, Embedded)
- Situationen, in denen Portabilität über Compiler/Toolchains eine harte Voraussetzung ist
Wann andere Sprachen vorzuziehen sind
Wähle eine höherwertige Sprache, wenn Priorität auf Sicherheit, Iterationsgeschwindigkeit oder Wartbarkeit im großen Maßstab liegt.
Rust, Go, Java, C#, Python oder TypeScript sind oft sinnvoll, wenn:
- Das Team groß ist und Fluktuation zu erwarten ist (weniger Fußangeln ist wichtig)
- Die Funktion sich häufig ändert und Korrektheit wichtiger ist als jede Zyklus-Ersparnis
- Du starke Speicher-Sicherheitsgarantien brauchst
- Entwicklerproduktivität und Einstellungsmarkt wichtiger sind als rohe Geschwindigkeit
In der Praxis sind viele Produkte gemischt: native Bibliotheken für den kritischen Pfad, höherwertige Services und UIs fürs Drumherum.
Ein praktischer Hinweis für App-Teams (wo Koder.ai passt)
Wenn du hauptsächlich Web-, Backend- oder Mobile-Features baust, musst du meist kein C/C++ schreiben, um davon zu profitieren — du nutzt es über OS, Datenbank, Laufzeit und Abhängigkeiten. Plattformen wie Koder.ai nutzen diese Trennung: Du kannst schnell React-Webapps, Go+PostgreSQL-Backends oder Flutter-Apps per Chat-Workflow erstellen und trotzdem native Komponenten integrieren (z. B. durch Aufrufe einer bestehenden C/C++-Bibliothek über eine FFI-Grenze). So bleibt der Produktkern in schnell iterierbarem Code, ohne native Rechenpfade auszuschließen.
Praktische Checkliste (Komponente für Komponente)
Stelle diese Fragen, bevor du dich verpflichtest:
- Ist das auf dem kritischen Pfad? Messe zuerst; raten ist teuer.
- Was sind die Ausfallmodi? Speicherkorruption in C/C++ kann katastrophal sein.
- Wie sieht die Schnittstelle aus? Lässt sich nativer Code hinter einer kleinen API isolieren?
- Habt ihr das Know-how? Review, Testing und Profiling sind unverhandelbar.
- Was ist das Deployment-Ziel? Konsolen, Embedded, Kernel und Treiber favorisieren oft C/C++.
- Wie testet und profiliert ihr es? Plane Tooling und CI von Tag eins.
Weiterführende Lektüre
- /blog/performance-profiling-basics
- /blog/memory-leaks-and-how-to-find-them
- /pricing