Was Sharding ist (und was nicht)
Sharding (auch horizontale Partitionierung genannt) bedeutet, dass das, was für Ihre Anwendung wie eine Datenbank aussieht, in mehrere Maschinen aufgeteilt wird—sogenannte Shards. Jeder Shard hält nur einen Teil der Zeilen, zusammen repräsentieren sie jedoch den gesamten Datensatz.
Eine logische Tabelle, viele physische Orte
Ein hilfreiches Denkmodell ist der Unterschied zwischen logischer Struktur und physischer Platzierung.
- Logisch: Sie haben immer noch eine „Users“-Tabelle (gleiche Spalten, gleiche Bedeutung).
- Physisch: Die Zeilen dieser Tabelle liegen an verschiedenen Orten—vielleicht sind Nutzer mit IDs 1–1.000.000 auf Shard A und die nächsten Millionen auf Shard B.
Aus Sicht der App möchten Sie Queries laufen lassen, als wäre es eine Tabelle. Unter der Haube muss das System entscheiden, mit welchem(e) Shard(s) es reden soll.
Nicht Replikation, nicht „kaufe eine größere Maschine“
Sharding unterscheidet sich von Replikation. Replikation erzeugt Kopien derselben Daten auf mehreren Knoten, hauptsächlich für Hochverfügbarkeit und Leseskalierung. Sharding teilt die Daten, sodass jeder Knoten andere Datensätze hält.
Es unterscheidet sich auch von vertikaler Skalierung, bei der Sie eine Datenbank auf eine größere Maschine verlagern (mehr CPU/RAM/schnellere Platten). Vertikale Skalierung kann einfacher sein, hat aber praktische Grenzen und wird schnell teuer.
Was Sharding nicht automatisch löst
Sharding erhöht Kapazität, macht Ihre Datenbank aber nicht automatisch „einfach“ oder jede Abfrage schneller.
- Joins können teuer werden, wenn zusammengehörige Zeilen auf unterschiedlichen Shards liegen.
- Transaktionen über Shards sind schwerer; "Alles‑oder‑Nichts"‑Updates erfordern oft Koordination.
- Operative Komplexität steigt: Routing, Rebalancing, Debugging und Fehlerbehandlung werden Teil des Systems.
Sharding ist also am besten als Mittel zum Skalieren von Speicher und Durchsatz zu verstehen—nicht als kostenlose Verbesserung aller Datenbankeigenschaften.
Warum Teams shardieren: Die Probleme, die es lösen will
Sharding ist selten die erste Wahl. Teams greifen normalerweise erst dann danach, wenn ein erfolgreiches System physische Grenzen erreicht hat—oder wenn operative Schmerzen zu häufig auftreten, um sie zu ignorieren. Die Motivation ist weniger „wir wollen sharden“ als vielmehr „wir müssen weiterwachsen, ohne dass eine Datenbank zum Single Point of Failure und Kostentreiber wird."
Die Schmerzpunkte, die Teams zum Sharding treiben
Ein einzelner Datenbankknoten kann auf verschiedene Weisen knapp werden:
- Speicherlimits: Tabellen und Indizes wachsen, Platten werden knapp, Backups werden langsam und Wartungsarbeiten riskant.
- Schreibdurchsatzlimits: CPU, WAL/Redo oder Sperrkonflikte begrenzen, wie viele Writes pro Sekunde sie durchhalten.
- Lesedurchsatzlimits: Selbst mit Caching und Replikaten überfordert manche Workloads den Primary (oder Replikate werden teuer zu skalieren).
- Noisy neighbors: Ein Mandant, Kunde oder Workload‑Muster monopolisiert Ressourcen und verschlechtert die Performance für alle anderen.
Wenn diese Probleme regelmäßig auftreten, ist die Ursache oft nicht eine einzelne schlechte Abfrage—sondern, dass eine Maschine zu viel Verantwortung trägt.
Die Ziele: Scale‑out, Isolation und Kostenkontrolle
Datenbank‑Sharding verteilt Daten und Traffic über mehrere Knoten, sodass Kapazität durch Hinzufügen von Maschinen wächst statt durch aufwendige vertikale Upgrades. Richtig gemacht kann es auch Workloads isolieren (ein Spike eines Tenants beeinträchtigt nicht die Latenz anderer) und Kosten kontrollieren, indem man sehr große Premium‑Instanzen vermeidet.
Frühe Warnzeichen, dass Sie an die Decke stoßen
Wiederkehrende Muster sind stetig steigende p95/p99‑Latenzen während Spitzen, längere Replikationsverzögerungen, Backups/Restores, die Ihre akzeptablen Fenster überschreiten, und „kleine“ Schemaänderungen, die zu Großereignissen werden.
Warum Sharding meist ein letzter Schritt ist
Bevor Teams sich binden, erschöpfen sie normalerweise einfachere Optionen: Indizierung und Query‑Fixes, Caching, Read‑Replicas, Partitionierung innerhalb einer Datenbank, Archivierung alter Daten und Hardware‑Upgrades. Sharding kann Skalierung bringen, aber es erhöht auch Koordination, operative Komplexität und neue Fehlermodi—die Hürde sollte deshalb hoch sein.
Eine sharded Datenbank ist nicht nur eine Sache—sie ist ein kleines System zusammenarbeitender Teile. Der Grund, warum Sharding sich „schwer zu durchschauen“ anfühlen kann, ist, dass Korrektheit und Performance davon abhängen, wie diese Teile interagieren, nicht nur vom Datenbank‑Motor.
Shards: unabhängige Partitionen (mit eigenen Indizes)
Ein Shard ist ein Datensubset, meist auf einem eigenen Server oder Cluster. Jeder Shard hat typischerweise seine eigenen:
- Speicherung (Datenfiles)
- Indizes (damit Abfragen innerhalb dieses Shards schnell sind)
- lokale Limits (CPU, Speicher, Platte, Verbindungen)
Aus Sicht der Anwendung versucht ein sharded Setup oft, wie eine logische Datenbank auszusehen. Unter der Haube kann eine Abfrage, die auf einem Single‑Node eine „Index‑Lookup“ wäre, zu „finde den richtigen Shard, dann Lookup“ werden.
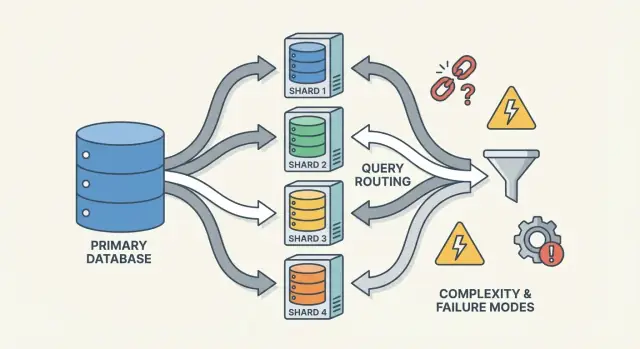
Router/Koordinatoren: wie Requests den richtigen Shard erreichen
Ein Router (manchmal Koordinator, Query‑Router oder Proxy genannt) ist der Verkehrsleiter. Er beantwortet die praktische Frage: Welche(r) Shard(s) soll(en) diese Anfrage bearbeiten?
Zwei gängige Muster:
- Client‑seitiges Routing: Ihre Anwendungslibrary kennt die Shard‑Map und verbindet sich direkt mit dem richtigen Shard.
- Proxy‑Routing: Die App verbindet sich mit einem Router‑Service, der die Anfrage weiterleitet.
Router reduzieren Komplexität in der App, können aber selbst zum Flaschenhals oder neuen Ausfallpunkt werden, wenn sie nicht sorgfältig entworfen sind.
Sharding beruht auf Metadaten—einer Quelle der Wahrheit, die beschreibt:
- die Shard‑Map (welcher Shard besitzt welche Bereiche/Hash‑Buckets/IDs)
- Besitz (insbesondere während Migrationen, wenn Besitz temporär überlappen kann)
- Health und Mitgliedschaft (welche Knoten up sind, Primary/Replica‑Rollen, Draining‑Status)
Diese Informationen leben oft in einem Konfigurationsdienst (oder einer kleinen Control‑Plane‑Datenbank). Wenn Metadaten veraltet oder inkonsistent sind, können Router Traffic an den falschen Ort senden—selbst wenn alle Shards eigentlich gesund sind.
Hintergrundjobs: Balancing, Migrationen und Backups
Schließlich hängt Sharding von Hintergrundprozessen ab, die das System im Laufe der Zeit lebbar halten:
- Rebalancing der Daten, wenn ein Shard schneller wächst als andere
- Migrationen, wenn Besitz zwischen Shards verschoben wird
- Backup/Restore‑Prozeduren, die über viele Shards hinweg funktionieren und zu Ihren Recovery‑Zielen passen
Diese Jobs werden leicht früh übersehen, aber genau dort passieren viele Überraschungen in Produktion—weil sie die Form des Systems ändern, während es noch Traffic bedient.
Auswahl des Shard‑Keys: Der erste große Trade‑off
Ein Shard‑Key ist das Feld (oder die Kombination von Feldern), das Ihr System nutzt, um zu entscheiden, welcher Shard eine Zeile/dokument speichern soll. Diese eine Wahl bestimmt stillschweigend Performance, Kosten und sogar welche Features später „einfach“ erscheinen—weil sie kontrolliert, ob Requests zu einem Shard geroutet werden können oder an viele fächern müssen.
Was einen guten Shard‑Key ausmacht
Ein guter Key hat typischerweise:
- Hohe Kardinalität: viele mögliche Werte (z. B.
user_id statt country).
- Gleichmäßige Verteilung: Werte verteilen Writes und Reads über Shards, statt alles auf einen zu lenken.
- Stabile Zugriffsmuster: er passt zu den Abfragen, die Sie heute und im nächsten Quartal erwarten.
Ein häufiges Beispiel ist Sharding nach tenant_id in einer Multi‑Tenant‑App: die meisten Lese‑ und Schreibvorgänge eines Tenants bleiben auf einem Shard, und viele Tenants verteilen die Last.
Was einen Shard‑Key „schlecht“ macht (und warum es weh tut)
Einige Keys garantieren fast Schmerz:
- Zeitbasierte monotone Keys (Timestamps, Auto‑Increment‑IDs): neue Daten gehäufen auf dem „letzten“ Shard → Schreib‑Hotspot.
- Felder mit niedriger Kardinalität (Status, Plan‑Tier, Country): zu wenige verschiedene Werte bedeuten, einige Shards machen die meiste Arbeit.
- Änderbare Identifier (E‑Mail, veränderliche Usernames): wenn der Key wechselt, wird das Verschieben von Daten teuer und riskant.
Selbst wenn ein Low‑Cardinality‑Key bequem zum Filtern ist, verwandelt er routinemäßige Abfragen oft in Scatter‑Gather‑Queries, weil passende Zeilen überall liegen.
Der eigentliche Trade‑off: Query‑Bequemlichkeit vs. Verteilungsqualität
Der beste Shard‑Key für Load‑Balancing ist nicht immer der beste für Produktabfragen.
- Wählen Sie einen Key, der zu Ihrem primären Zugriffsmuster passt (z. B.
user_id), und einige „globale“ Abfragen (z. B. Admin‑Reports) werden langsamer oder benötigen separate Pipelines.
- Wählen Sie einen Key, der zu Reporting passt (z. B.
region), und Sie riskieren Hotspots und ungleiche Kapazität.
Die meisten Teams optimieren den Shard‑Key für die häufigsten, Latenz‑sensitiven Operationen—und behandeln den Rest mit Indizes, Denormalisierung, Replikaten oder dedizierten Analytics‑Tabellen.
Gängige Sharding‑Strategien (Range, Hash, Directory)
Es gibt keinen einzelnen „besten“ Weg, eine Datenbank zu shardieren. Die gewählte Strategie prägt, wie einfach Routing ist, wie gleichmäßig Daten verteilt werden und welche Zugriffsmuster problematisch sind.
Range‑Sharding
Beim Range‑Sharding besitzt jeder Shard einen zusammenhängenden Abschnitt des Key‑Raums, z. B.:
- Shard A: customer_id 1–1.000.000
- Shard B: customer_id 1.000.001–2.000.000
Routing ist einfach: Key anschauen, Shard wählen.
Der Haken sind Hotspots. Wenn neue Nutzer immer steigende IDs bekommen, wird der „letzte“ Shard zum Schreibflaschenhals. Range‑Sharding ist auch empfindlich gegenüber ungleichmäßigem Wachstum. Der Vorteil: Range‑Abfragen ("alle Orders vom 1.–31. Okt") können effizient sein, weil Daten physisch gruppiert sind.
Hash‑Sharding
Hash‑Sharding führt den Shard‑Key durch eine Hash‑Funktion und nutzt das Ergebnis zur Shard‑Auswahl. Das verteilt Daten meist gleichmäßiger und vermeidet das Problem, dass alles in den neuesten Shard fließt.
Trade‑off: Range‑Abfragen werden unangenehm. Eine Abfrage wie „Kunden mit IDs zwischen X und Y“ mappt nicht mehr auf wenige Shards, sondern kann viele betreffen.
Eine praktische Nuance ist konsistentes Hashing. Statt direkt auf die Shard‑Anzahl zu mappen (was beim Hinzufügen von Shards alles umverteilen würde), nutzen viele Systeme einen Hash‑Ring mit "virtuellen Knoten", sodass beim Hinzufügen von Kapazität nur ein Teil der Keys verschoben wird.
Directory (Lookup)‑Sharding
Directory‑Sharding speichert ein explizites Mapping (Lookup‑Tabelle/-Service) von Key → Shard‑Ort. Das ist am flexibelsten: Sie können bestimmte Tenants auf dedizierten Shards platzieren, einen Kunden verschieben ohne alle anderen zu bewegen und ungleiche Shard‑Größen unterstützen.
Nachteil ist eine zusätzliche Abhängigkeit. Ist das Directory langsam, veraltet oder nicht verfügbar, leidet das Routing—selbst wenn die Shards gesund sind.
Composite Keys und Sub‑Sharding
Reale Systeme mischen oft Ansätze. Ein zusammengesetzter Shard‑Key (z. B. tenant_id + user_id) isoliert Tenants und verteilt gleichzeitig Last innerhalb eines Tenants. Sub‑Sharding ist ähnlich: zuerst nach Tenant routen, dann innerhalb der Tenant‑Gruppe hashen, um zu verhindern, dass ein sehr großer Tenant einen Shard dominiert.
Wie Abfragen funktionieren: Routing vs. Scatter‑Gather
Shard-Gesundheit visualisieren
Starte eine React-Admin-Oberfläche, um Latenz, Skew und Hotspots pro Shard zu prüfen.
Eine sharded Datenbank hat zwei sehr unterschiedliche „Query‑Pfade“. Zu verstehen, auf welchem Pfad Sie sind, erklärt die meisten Performance‑Überraschungen—und warum Sharding unvorhersehbar wirken kann.
Single‑Shard‑Queries: der schnelle Pfad
Das ideale Ergebnis ist, eine Abfrage genau an einen Shard zu routen. Wenn die Anfrage den Shard‑Key (oder etwas, das darauf mapped) enthält, kann das System sie direkt an den richtigen Ort senden.
Deshalb optimieren Teams so sehr darauf, häufige Reads "Shard‑Key‑aware" zu machen. Ein Shard bedeutet weniger Netzwerkrunden, einfachere Ausführung, weniger Sperren und deutlich weniger Koordination. Die Latenz besteht größtenteils aus der Datenbankarbeit, nicht aus internem Cluster‑Gerangel.
Scatter‑Gather‑Reads: Fan‑Out und Tail‑Latenz
Wenn eine Abfrage nicht präzise geroutet werden kann (z. B. Filter auf einem Nicht‑Shard‑Key), kann das System sie an viele oder alle Shards broadcasten. Jeder Shard führt die Abfrage lokal aus, dann werden die Ergebnisse vom Router (oder einem Koordinator) zusammengeführt—Sortieren, Deduplizieren, Limits anwenden und partielle Aggregationen kombinieren.
Dieses Fan‑Out verstärkt Tail‑Latenz: selbst wenn 9 Shards schnell antworten, kann ein langsamer Shard die gesamte Anfrage blockieren. Es multipliziert auch die Last: eine Benutzeranfrage kann N Shard‑Anfragen erzeugen.
Cross‑Shard‑Joins und Aggregationen
Joins über Shards sind teuer, weil Daten, die früher intern zusammengeführt wurden, nun zwischen Shards verschoben werden müssen (oder an einen Koordinator). Selbst einfache Aggregationen (COUNT, SUM, GROUP BY) erfordern oft einen Zwei‑Phasen‑Plan: partielle Ergebnisse auf jedem Shard berechnen, dann zusammenführen.
Index‑Einschränkungen: lokal vs. global
Die meisten Systeme nutzen lokale Indizes: jeder Shard indiziert nur seine eigenen Daten. Sie sind billig zu pflegen, helfen aber nicht beim Routing—Queries können trotzdem scattern.
Globale Indizes ermöglichen gezieltes Routing auf Nicht‑Shard‑Key‑Felder, fügen aber Schreib‑Overhead, zusätzliche Koordination und eigene Skalierungs‑ und Konsistenzprobleme hinzu.
Writes und Transaktionen über Shards
Writes sind der Punkt, an dem Sharding aufhört, sich wie „nur Skalierung“ anzufühlen, und anfängt, wie ein anderes Designparadigma zu wirken. Ein Write, der einen Shard berührt, kann schnell und einfach sein. Ein Write, der mehrere Shards betrifft, kann langsam, fehleranfällig und überraschend schwer korrekt zu gestalten sein.
Single‑Shard‑Writes: der glückliche Pfad
Wenn jede Anfrage auf genau einen Shard geroutet werden kann (typischerweise über den Shard‑Key), kann die Datenbank ihre normalen Transaktionsmechanismen verwenden. Sie bekommen Atomizität und Isolation innerhalb dieses Shards—die meisten operativen Probleme sehen dann aus wie vertraute Single‑Node‑Probleme, nur N‑fach vorhanden.
Multi‑Shard‑Writes: wo die Komplexität explodiert
Sobald Sie Daten auf zwei Shards in einer "logischen Aktion" ändern müssen (z. B. Geld übertragen, eine Bestellung zwischen Kunden verschieben, ein an anderer Stelle gespeichertes Aggregat aktualisieren), betreten Sie Gebiet verteilter Transaktionen.
Verteilte Transaktionen sind schwierig, weil sie Koordination zwischen Maschinen erfordern, die langsam, partitioniert oder neugestartet sein können. Two‑Phase‑Commit‑artige Protokolle fügen zusätzliche Roundtrips hinzu, können auf Timeouts blockieren und machen Fehler mehrdeutig: Hat Shard B die Änderung angewendet, bevor der Koordinator gestorben ist? Wenn der Client erneut versucht, wenden Sie die Änderung doppelt an? Wenn nicht, geht sie verloren?
Muster, um Cross‑Shard‑Writes zu vermeiden
Einige Taktiken reduzieren, wie oft Sie Multi‑Shard‑Transaktionen brauchen:
- Datenlokalität: zusammengehörige Datensätze auf demselben Shard ablegen (z. B. alles für einen Kunden)
- Request‑Routing: stellen Sie sicher, dass eine Operation von einem Shard „besessen“ wird und andere nur als Lesequellen behandelt werden
- Denormalisierung: kleine Datenstücke duplizieren, sodass Updates nicht fan‑out müssen
Idempotenz und Retry‑Sicherheit
In sharded Systemen sind Retries unvermeidlich. Machen Sie Writes idempotent durch stabile Operations‑IDs (z. B. einen Idempotency‑Key) und speichern Sie in der Datenbank Marker für "bereits angewendet". So wird ein Timeout‑Retry zur No‑Op statt zu doppelter Buchung, doppelter Bestellung oder inkonsistenten Zählern.
Konsistenz und Replikation: Daten korrekt halten
Shard-Schlüssel wählen
Nutze den Planungsmodus, um Shard-Schlüssel, Abfragepfade und Migrationsschritte vor dem Programmieren zu planen.
Sharding teilt Ihre Daten auf Maschinen auf, nimmt Ihnen aber nicht die Notwendigkeit von Redundanz ab. Replikation ist das, was einen Shard verfügbar hält, wenn ein Knoten ausfällt—und sie macht zugleich die Frage "Was ist jetzt wahr?" schwerer zu beantworten.
Replikation innerhalb jedes Shards
Die meisten Systeme replizieren innerhalb jedes Shards: ein Primary (Leader) akzeptiert Writes, und ein oder mehrere Replikate kopieren diese Änderungen. Fällt der Primary aus, promotet das System ein Replica (Failover). Replikate können auch Reads bedienen, um Last zu reduzieren.
Der Trade‑off ist Zeit. Ein Read‑Replica kann Millisekunden oder Sekunden hinterherhinken. Diese Lücke ist normal, aber wichtig, wenn Nutzer erwarten: „Ich habe gerade aktualisiert, also sollte ich es gleich sehen.“
Konsistenzmodelle in einfachen Worten
- Starke Konsistenz: nachdem ein Write erfolgreich war, zeigen Reads das Ergebnis (so wie das System es verspricht). Das bedeutet oft, vom Leader zu lesen oder auf Replikate‑Bestätigungen zu warten.
- Eventuelle Konsistenz: das System konvergiert; ein Read kann temporär ältere Daten liefern.
In sharded Setups hat man oft starke Konsistenz innerhalb eines Shards und schwächere Garantien über Shards hinweg, besonders bei Multi‑Shard‑Operationen.
„Single Source of Truth“, wenn Daten verteilt sind
Bei Sharding bedeutet „Single Source of Truth“ typischerweise: für jedes einzelne Datum gibt es einen autoritativen Schreibort (normalerweise der Shard‑Leader). Global gesehen gibt es aber keine Maschine, die instantan den neuesten Zustand von allen Dingen bestätigen kann. Sie haben viele lokale Wahrheiten, die per Replikation synchron gehalten werden müssen.
Globale Constraints: Einzigartigkeit, Fremdschlüssel, Zähler
Constraints sind schwierig, wenn die zu prüfenden Daten auf unterschiedlichen Shards liegen:
- Einzigartigkeit (z. B. Benutzername): "keine Duplikate irgendwo" erfordert einen zentralen Index, einen dedizierten Constraint‑Shard oder einen application‑level Reservierungs‑Workflow.
- Fremdschlüssel: liegen Eltern‑ und Kindzeilen auf verschiedenen Shards, kann die DB referentielle Integrität nicht leicht ohne Cross‑Shard‑Koordination erzwingen.
- Zähler (globale Summen, sequentielle IDs): naive Ansätze erzeugen einen Engpass. Übliche Lösungen: pro‑Shard‑Bereiche, Batching oder ungefähre Zähler akzeptieren.
Diese Entscheidungen definieren, was Ihr Produkt als „korrekt“ ansieht.
Rebalancing und Resharding ohne Downtime
Rebalancing hält eine sharded Datenbank nutzbar, während sich die Realität ändert. Daten wachsen ungleichmäßig, ein vormals guter Shard‑Key driftet in Skew, Sie fügen neue Knoten hinzu oder müssen Hardware außer Dienst stellen. Jede dieser Situationen kann einen Shard zum Flaschenhals machen—selbst wenn das ursprüngliche Design perfekt schien.
Warum es schwer ist
Anders als bei einer Single‑DB verankert Sharding die Datenlokation ins Routing. Wenn Sie Daten verschieben, kopieren Sie nicht nur Bytes—Sie ändern, wohin Anfragen gehen müssen. Rebalancing betrifft also ebenso Metadaten und Clients wie Speicherung.
Das Online‑Migrationsmuster (copy → overlap → cutover)
Die meisten Teams zielen auf einen Online‑Workflow ohne großes "Stop‑the‑World":
- Copy: Ziel‑Shards aus dem Quell‑Shard hinterfüllen, während das System live ist.
- Dual‑write (manchmal dual‑read): Während der Transition werden neue Änderungen in beide Orte geschrieben. Reads konsultieren ggf. beide (oder nutzen eine "new wins"‑Regel), bis Vertrauen besteht.
- Cutover: Shard‑Map updaten, sodass Router/Clients Traffic zur neuen Location senden.
- Cleanup: Dual‑Writes stoppen, alte Kopie entfernen und Platz reclaimen.
Shard‑Maps und Client‑Verhalten
Ein Shard‑Map‑Wechsel ist ein brechendes Ereignis, wenn Clients Routing‑Entscheidungen cachen. Gute Systeme behandeln Routing‑Metadaten wie Konfiguration: versionieren sie, aktualisieren sie häufig und seien explizit, was passiert, wenn ein Client auf einen verschobenen Key trifft (Redirect, Retry oder Proxy).
Operative Risiken, für die geplant werden muss
Rebalancing verursacht oft temporäre Performance‑Einbrüche (zusätzliche Writes, Cache‑Churn, Hintergrundkopierlast). Teilumzüge sind üblich—einige Ranges migrieren vor anderen—deshalb brauchen Sie klare Observability und einen Rollback‑Plan (z. B. Map zurückflippen und Dual‑Writes auslaufen lassen), bevor Sie cutovern.
Hotspots und Skew: Wenn „gleichmäßige Aufteilung“ versagt
Sharding setzt voraus, dass Arbeit sich verteilt. Die Überraschung ist, dass ein Cluster auf dem Papier „gleich“ aussehen kann (gleiche Zeilenanzahl pro Shard), in Produktion aber sehr ungleich arbeitet.
Heiße Partitionen (Hot Keys)
Ein Hotspot entsteht, wenn ein kleiner Teil des Key‑Raums den Großteil des Traffics erhält—z. B. ein Promi‑Account, ein beliebtes Produkt, ein Tenant mit schweren Batch‑Jobs oder ein zeitbasierter Key, bei dem "heute" alle Writes anzieht. Liegen diese Keys auf einem Shard, wird dieser Shard zum Flaschenhals, selbst wenn andere Shards idle sind.
Skew: Datenmenge vs. Traffic
"Skew" ist nicht nur eines:
- Data Skew: ein Shard hält mehr Bytes/Zeilen (Speicherdruck, längere Backups, langsamere Scans).
- Traffic Skew: ein Shard verarbeitet mehr QPS oder schwerere Queries (CPU‑Sättigung, Queueing, Latenzspitzen).
Sie stimmen nicht immer überein. Ein Shard mit weniger Daten kann am heißesten sein, wenn er die am meisten nachgefragten Keys besitzt.
Wie man es schnell erkennt
Sie brauchen kein ausgefeiltes Tracing, um Skew zu bemerken. Beginnen Sie mit per‑Shard Dashboards:
- p95‑Latenz pro Shard (wenn ein Shard abweicht, Alarm)
- QPS (und Write‑QPS) pro Shard
- Genutzter Speicher / Tabellen‑Größe pro Shard
Steigt die Latenz eines Shards mit seiner QPS, während andere flach bleiben, haben Sie wahrscheinlich einen Hotspot.
Gegenmaßnahmen
Fixes tauschen Einfachheit gegen Balance:
- Wählen Sie einen Shard‑Key, der Traffic verteilt, nicht nur Datensätze.
- Fügen Sie Bucketing/Salting für heiße Keys hinzu (teilen Sie einen logischen Key auf mehrere physische Buckets auf).
- Nutzen Sie Caching für leseintensive heiße Objekte.
- Setzen Sie Rate Limits oder Tenants‑Quotas, um den Cluster zu schützen.
- Splitten Sie heiße Shards (oder verschieben Sie heiße Ranges), wenn ein Shard nicht mehr heruntergekühlt werden kann.
Ausfallmodi und Debugging in einem sharded System
Multi-Tenant-Shards modellieren
Baue eine kleine Multi-Tenant-App und sieh, wie sich tenant_id-Sharding auf deine Abfragen auswirkt.
Sharding fügt nicht nur mehr Server hinzu—es fügt mehr Arten von Fehlern und mehr Orte zum Nachschauen hinzu. Viele Vorfälle sind nicht "die Datenbank ist down", sondern "ein Shard ist down" oder "das System ist sich nicht einig, wo Daten liegen".
Häufige Ausfallmuster
Wiederkehrende Muster sind:
- Ein Shard ist nicht verfügbar (Crash, Platte voll, lange GC‑Pauses), was partielle Ausfälle verursacht: einige Kunden funktionieren, andere nicht.
- Router misrouten Traffic, oft nach einer Konfigurationsänderung oder einem schlechten Deploy. Reads können still leer zurückgeben, wenn sie an den falschen Shard gesendet werden.
- Veraltete oder inkonsistente Metadaten (z. B. Shard‑Map). Während Moves oder Splits können verschiedene Komponenten denselben Key unterschiedlich routen.
- Teilweise Netzwerkprobleme: Timeouts zwischen Routern und einer Teilmenge von Shards erscheinen als „zufällige“ Fehler und triggern Retries, die die Last verstärken.
Wie sich Debugging ändert
Bei einer Single‑Node‑DB tailen Sie ein Log und schauen ein Metrics‑Set. In einem sharded System brauchen Sie Observability, die eine Anfrage über Shards nachverfolgt.
Verwenden Sie Correlation IDs in jeder Anfrage und propagieren Sie sie von der API‑Schicht durch Router zu jedem Shard. Kombinieren Sie das mit distributed tracing, sodass eine Scatter‑Gather‑Abfrage zeigt, welcher Shard langsam oder fehlgeschlagen ist. Metriken sollten pro Shard aufgebrochen sein (Latenz, Queue‑Tiefe, Fehlerquote), sonst verschwindet ein heißer Shard in Flotten‑Durchschnitten.
Datenkorrektheitsvorfälle
Sharding‑Fehler erscheinen oft als Korrektheitsbugs:
- Duplikate nach Retries oder nicht‑idempotenten Writes.
- Fehlende Zeilen, wenn eine Migration Daten verschoben hat, das Routing aber noch auf den alten Ort zeigt.
- Split‑Brain‑Writes, wenn zwei Metadatenansichten Writes für denselben Key‑Bereich akzeptieren.
Backup, Restore und Disaster Recovery
"Die Datenbank wiederherstellen" wird zu "viele Teile in der richtigen Reihenfolge wiederherstellen". Möglicherweise müssen Sie zuerst Metadaten wiederherstellen, dann jeden Shard und anschließend Shard‑Grenzen und Routing‑Regeln verifizieren, damit sie zum wiederhergestellten Point‑in‑Time passen. DR‑Pläne sollten Übungen enthalten, die beweisen, dass Sie einen konsistenten Cluster zusammensetzen können—nicht nur einzelne Maschinen wiederherstellen.
Wann nicht sharden: praktische Alternativen und eine Entscheidungs‑Checkliste
Sharding wird oft als „Schalter“ zum Skalieren behandelt, ist aber auch eine dauerhafte Erhöhung der Systemkomplexität. Wenn Sie Ihre Performance‑ und Zuverlässigkeitsziele ohne Datenverteilung über Knoten erreichen können, haben Sie in der Regel eine einfachere Architektur, leichteres Debugging und weniger operative Randfälle.
Praktische Alternativen, die oft viel Spielraum schaffen
Bevor Sie shardieren, versuchen Sie Optionen, die eine einzelne logische Datenbank erhalten:
- Bessere Indizierung + Query‑Tuning: Beheben Sie langsame Pfade zuerst—fehlende Indizes, unbeschränkte Queries, teure Joins, N+1‑Muster.
- Caching: Legen Sie leseintensive, stabile Antworten vor einen Cache (App‑Level Cache, CDN für öffentliche Inhalte oder In‑Memory‑Cache für heiße Keys).
- Read‑Replicas: Entlasten Sie Lesetraffic ohne den Write‑Pfad zu ändern (und akzeptieren Sie Replica‑Lag, wo es OK ist).
- Partitionierte Tabellen auf einem Knoten: Viele DBMS unterstützen Table‑Partitioning, das Wartung und Abfragen verbessert ohne Cross‑Node‑Routing.
Eine praktische Art, das Risiko zu verringern, ist das Prototypen der Plumbing (Routing‑Boundaries, Idempotenz, Migrations‑Workflows und Observability), bevor Sie Ihre Produktionsdatenbank darauf verpflichten.
Zum Beispiel können Sie mit Koder.ai schnell einen kleinen, realistischen Service aus einem Chat erstellen—oft ein React‑Admin‑UI plus Go‑Backend mit PostgreSQL—und shard‑key‑aware APIs, Idempotency Keys und „Cutover“‑Verhalten in einer sicheren Sandbox ausprobieren. Da Koder.ai Planungsmodus, Snapshots/Rollback und Source‑Code‑Export unterstützt, können Sie Sharding‑Designentscheidungen (wie Routing und Metadaten‑Form) iterieren und dann den resultierenden Code und Runbooks in Ihren Haupt‑Stack übernehmen, wenn Sie sicher sind.
Wann Sharding passt (und wann nicht)
Sharding passt besser, wenn Ihr Datensatz oder Schreibdurchsatz deutlich die Grenzen eines einzelnen Knotens überschreitet und Ihre Abfragemuster zuverlässig einen Shard‑Key nutzen können (wenige Cross‑Shard‑Joins, minimale Scatter‑Gather‑Abfragen).
Es passt schlecht, wenn Ihr Produkt viele Ad‑hoc‑Queries, häufige Multi‑Entity‑Transaktionen, globale Uniqueness‑Constraints benötigt oder das Team die operative Last (Rebalancing, Resharding, Incident Response) nicht tragen kann.
Kurze Entscheidungs‑Checkliste
Fragen Sie:
- Workload: Ist der Engpass CPU, I/O, Speicher oder Sperrkonflikte—und lässt sich das ohne Sharding beheben?
- Query‑Pattern: Können 90%+ der kritischen Abfragen per Shard‑Key geroutet werden?
- Teamkapazität: Wer verantwortet Shard‑Mapping, On‑Call‑Runbooks und Cross‑Shard‑Transaktionsverhalten?
- SLOs: Können Sie partielle Degradationen (ein Shard down) und längere Tail‑Latenzen tolerieren?
Plane für Wachstum, nicht nur ein Diagramm
Selbst wenn Sie Sharding verschieben, entwerfen Sie einen Migrationspfad: wählen Sie Identifier, die zukünftigen Shard‑Keys nicht im Weg stehen, vermeiden Sie hardcodierte Single‑Node‑Annahmen und proben Sie, wie Sie Daten mit minimaler Downtime verschieben würden. Die beste Zeit, Resharding zu planen, ist bevor Sie es brauchen.