08. Nov. 2025·8 Min
Wie kleine Teams mit KI schneller liefern als große Engineering-Organisationen
Erfahren Sie, warum kleine Teams mit KI schneller ausliefern als große Engineering-Organisationen: weniger Overhead, engere Feedbackschleifen, intelligentere Automatisierung und klarere Ownership.
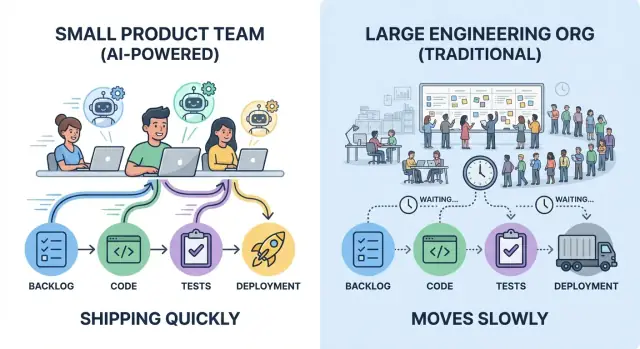
Was „Geschwindigkeit" in echter Produktlieferung bedeutet
„Schneller ausliefern" heißt nicht nur, Code schneller zu tippen. Echte Liefergeschwindigkeit ist die Zeit zwischen einer Idee, die zu einer verlässlichen Verbesserung für Nutzer wird — und dem Team, das lernt, ob sie funktioniert.
Die Metriken, die Geschwindigkeit wirklich beschreiben
Teams streiten über Geschwindigkeit, weil sie unterschiedliche Dinge messen. Ein praktischer Blick fokussiert auf eine kleine Menge Liefermetriken:
- Lead Time: wie lange es dauert von „wir haben beschlossen, das zu tun“ bis „es ist für Nutzer live“.
- Cycle Time: wie lange ein Arbeitspaket „in Arbeit" ist, sobald jemand damit anfängt.
- Deployment Frequency: wie oft Sie sicher ausliefern können (täglich, wöchentlich, on demand).
- Time-to-Learning: wie schnell Sie ein vertrauenswürdiges Signal (Nutzung, Supporttickets, Retention, Umsatz) erhalten, das Ihnen sagt, was als Nächstes zu tun ist.
Ein kleines Team, das fünf kleine Änderungen pro Woche ausliefert, lernt oft schneller als eine größere Organisation, die eine große Release pro Monat ausliefert — selbst wenn der Monats-Release mehr Code enthält.
Was „KI verwenden" bedeutet (und was nicht)
In der Praxis sieht „KI für Engineering" meist aus wie eine Reihe von Assistenten, die in die bestehende Arbeit eingebettet sind:
- Copilots zum Entwerfen von Code, Refactors und Dokumentation
- Test-Generierung und Helfer zur Testpflege
- Unterstützung bei Code Reviews (Erkennen von Edge Cases, Vorschläge zur Vereinfachung)
- Support- und Ops-Bots (Incidents zusammenfassen, Runbooks entwerfen, „wo ist das implementiert?“ beantworten)
KI hilft vor allem bei Durchsatz pro Person und Reduzierung von Nacharbeit — ersetzt aber nicht gutes Produkturteil, klare Anforderungen oder Ownership.
Die Kernidee: Overhead vs. Iterationsschleifen
Geschwindigkeit wird hauptsächlich von zwei Kräften begrenzt: Koordinations-Overhead (Übergaben, Genehmigungen, Warten) und Iterationsschleifen (bauen → ausliefern → beobachten → anpassen). KI verstärkt Teams, die Arbeit klein halten, Entscheidungen klar fällen und schnelles Feedback haben.
Ohne Gewohnheiten und Guardrails — Tests, Code Review und Release-Disziplin — kann KI auch falsch gerichtete Arbeit genauso effizient beschleunigen.
Die versteckte Steuer der Skalierung: Koordinations-Overhead
Große Engineering-Organisationen fügen nicht nur Leute hinzu — sie fügen Verbindungen hinzu. Jede neue Teamgrenze bringt Koordinationsarbeit, die keine Features ausliefert: Prioritäten abgleichen, Designs angleichen, Ownership verhandeln und Änderungen durch die „richtigen" Kanäle routen.
Wohin die Zeit wirklich geht
Koordinations-Overhead zeigt sich an vertrauten Stellen:
- Meetings, um „alle auf denselben Stand zu bringen" (Status, Planung, Roadmap-Alignment)
- Reviews, die mehrere Stakeholder benötigen (Security, Privacy, Architektur, Brand)
- Handoffs zwischen Rollen oder Teams (Product → Design → Engineering → Platform → SRE)
- Dokumentation, die geschrieben wird, um diese Übergaben zu ermöglichen und Entscheidungen später zu verteidigen
Keines davon ist per se schlecht. Das Problem ist, dass sie sich aufsummieren — und schneller wachsen als die Kopfzahl.
Abhängigkeiten erzeugen Warten, nicht Arbeit
In einer großen Organisation überquert eine einfache Änderung oft mehrere Abhängigkeitslinien: Ein Team besitzt das UI, ein anderes die API, ein Platform-Team das Deployment und ein Infosec-Team die Freigabe. Selbst wenn jede Gruppe effizient ist, dominiert die Queue-Zeit.
Typische Verzögerungen sehen so aus:
- Ein Feature blockiert durch ein quartalsweises Architektur-Review-Board
- Eine kleine API-Änderung, die zwei Wochen im Platform-Backlog wartet
- Ein Release, das gehalten wird, bis ein zentrales QA- oder Compliance-Fenster öffnet
- „Wir brauchen eine Unterschrift von Team X", die sich zu einer Dreier-Meeting-Kette entwickelt
Wie Overhead die Lead Time streckt
Lead Time ist nicht nur Coding-Zeit; sie ist verstrichene Zeit von Idee bis Produktion. Jede zusätzliche Übergabe fügt Latenz hinzu: Sie warten auf das nächste Meeting, den nächsten Reviewer, den nächsten Sprint, den nächsten Slot in jemandes Queue.
Kleine Teams gewinnen oft, weil sie Ownership eng halten und Entscheidungen lokal treffen können. Das eliminiert Reviews nicht — es reduziert die Anzahl der Hops zwischen „ready" und „shipped", und genau dort verlieren große Organisationen still Tage und Wochen.
Kleine Teams gewinnen mit klarer Ownership und weniger Handoffs
Geschwindigkeit bedeutet nicht nur schneller tippen — es bedeutet, weniger Leute warten zu lassen. Kleine Teams liefern schnell, wenn Arbeit single-threaded ownership hat: eine klar verantwortliche Person (oder ein Paar), die ein Feature von der Idee bis in Produktion treibt, mit einem benannten Entscheider, der Trade-offs klärt.
Single-threaded Ownership macht Entscheidungen billig
Wenn ein Owner für Ergebnisse verantwortlich ist, prallen Entscheidungen nicht zwischen Produkt, Design, Engineering und „dem Platform-Team" in einer Schleife hin und her. Der Owner sammelt Inputs, trifft die Entscheidung und macht weiter.
Das heißt nicht, dass man allein arbeitet. Es heißt, alle wissen, wer steuert, wer genehmigt und was „done" bedeutet.
Weniger Handoffs bedeutet weniger Nacharbeit
Jede Übergabe verursacht zwei Arten von Kosten:
- Kontextverlust: Details werden vereinfacht, Annahmen bleiben unausgesprochen und Edge Cases verschwinden.
- Nacharbeit: Die nächste Person entdeckt Einschränkungen zu spät und schickt die Arbeit zurück.
Kleine Teams vermeiden das, indem sie das Problem in einer engen Schleife halten: derselbe Owner ist an Anforderungen, Implementierung, Rollout und Nachverfolgung beteiligt. Das Ergebnis sind weniger „Moment, das habe ich nicht so gemeint"-Situationen.
Wie KI einem Owner hilft, mehr abzudecken
KI ersetzt Ownership nicht — sie erweitert sie. Ein einzelner Owner kann mit KI über mehr Aufgaben hinweg effektiv bleiben, indem er KI nutzt, um:
- Erstentwürfe für Specs, Release Notes und Kundenkommunikation zu verfassen
- Lange Threads, Incident-Historie oder frühere Entscheidungen in ein kurzes Briefing zu komprimieren
- Implementierung zu scaffolden: Boilerplate, Test-Outlines, Migration-Skripte oder API-Client-Stubs zu generieren
Der Owner validiert und entscheidet weiterhin, aber die Zeit von leerer Seite zu einem brauchbaren Entwurf sinkt deutlich.
Wenn Sie einen vibe-coding-Workflow verwenden (z. B. Koder.ai), wird dieses „ein Owner deckt die ganze Slice ab"-Modell noch einfacher: Sie können einen Plan entwerfen, ein React-UI plus Go/PostgreSQL-Backend-Skelett generieren und durch kleine Änderungen in derselben Chat-gesteuerten Schleife iterieren — und den Quellcode exportieren, wenn Sie engere Kontrolle wünschen.
Signale, dass Sie starke Ownership haben
Achten Sie auf diese operativen Signale:
- Ein Backlog pro Initiative (nicht verstreut über mehrere Tools oder Teams)
- Eine Definition of Done, inklusive Testing und Rollout (nicht „done in dev")
- Ein einzelner Entscheider für Priorität und Umfang
- Klare Schnittstellen zu anderen Teams: Anfragen sind explizit, zeitlich begrenzt und dokumentiert
Wenn diese Signale vorhanden sind, kann ein kleines Team mit Zuversicht vorgehen — und KI macht es leichter, diesen Schwung zu halten.
Engere Feedbackschleifen schlagen größere Pläne
Große Pläne wirken effizient, weil sie die Zahl der „Entscheidungsmomente" reduzieren. Oft verlagern sie das Lernen aber ans Ende — nach Wochen des Bauens — wenn Änderungen am teuersten sind. Kleine Teams bewegen sich schneller, indem sie die Distanz zwischen Idee und realem Feedback verkürzen.
Kurze Schleifen verhindern verschwendete Arbeit
Eine kurze Feedbackschleife ist simpel: Bauen Sie das kleinste Ding, das Ihnen etwas lehren kann, stellen Sie es Nutzern vor und entscheiden Sie, was als Nächstes zu tun ist.
Wenn Feedback in Tagen (nicht Quartalen) eintrifft, hören Sie auf, die falsche Lösung zu polieren. Sie vermeiden auch Over-Engineering von „just in case"-Anforderungen, die nie auftreten.
Wie schnelles Lernen aussieht
Kleine Teams können lightweight Zyklen fahren, die trotzdem starke Signale liefern:
- Schnelle Prototypen: klickbare Mockups oder dünne „Happy-Path"-Flows, um zu validieren, ob Nutzer den Wert verstehen.
- Frühe Nutzerinterviews: 5–8 Gespräche decken oft die wichtigsten Einwände und fehlenden Teile auf.
- Schnelle A/B-Iterationen: kleine UI- oder Onboarding-Änderungen, gemessen über ein kurzes Fenster, zeigen, welche Richtung Reibung reduziert.
Der Schlüssel ist, jeden Zyklus als Experiment zu behandeln, nicht als Mini-Projekt.
KI beschleunigt das Lernen, nicht nur das Bauen
Der größte Hebel der KI ist nicht, mehr Code zu schreiben — sondern die Zeit von „wir haben etwas gehört" zu „wir wissen, was wir als Nächstes versuchen" zu komprimieren. Beispielsweise können Sie KI nutzen, um:
- Feedback zusammenzufassen aus Interviews, Supporttickets, App-Reviews oder Sales-Notizen in klare Takeaways
- Themen zu clustern (z. B. Verwirrungspunkte, fehlende Features, Vertrauensfragen), damit Muster schnell sichtbar werden
- Experimente zu entwerfen: Hypothesen, Erfolgskriterien und den kleinsten Test vorschlagen, der sie bestätigt oder verwirft
Das bedeutet weniger Zeit in Synthese-Meetings und mehr Zeit, den nächsten Test durchzuführen.
Shipping-Speed vs. Learning-Speed
Teams feiern oft Shipping-Velocity — wie viele Features rausgegangen sind. Echte Geschwindigkeit ist aber Learning-Velocity: wie schnell Sie Unsicherheit reduzieren und bessere Entscheidungen treffen.
Eine große Organisation kann viel ausliefern und trotzdem langsam lernen. Ein kleines Team kann weniger „Volumen" ausliefern, aber schneller vorankommen, weil es früher lernt, schneller korrigiert und die Roadmap anhand von Evidenz statt Meinungen gestaltet.
KI als Verstärker, nicht als Ersatz
Häufige Deploys sicherer machen
Experimentiere öfter mit Snapshots und setze bei Bedarf ein Rollback ein, wenn ein Release einen schnellen Reset braucht.
KI macht ein kleines Team nicht „größer". Sie lässt das Urteil und die Ownership des Teams weiter wirken. Der Gewinn liegt nicht darin, dass KI Code schreibt, sondern darin, dass sie Reibung in den Teilen der Lieferung entfernt, die Zeit stehlen, ohne das Produkt zu verbessern.
Hebel mit kumulativem Effekt
Kleine Teams erzielen überproportionale Gewinne, wenn sie KI auf notwendige, aber selten differenzierende Arbeit richten:
- Boilerplate-Generierung: Scaffolding neuer Endpoints, Test-Dateien, Migration-Templates, CI-Config oder repetitiver UI-Komponenten
- Refactors mit Plan: Umbenennen, Extrahieren von Helfern, Musterkonversionen und Call-Site-Updates — besonders mit klaren Constraints („Verhalten nicht ändern", „öffentliche API stabil halten")
- Dokumentations-Erstentwürfe: Release Notes, ADR-Outlines, API-Doku, Onboarding-Guides und „Wie man lokal läuft"-Anleitungen
Das Muster ist konsistent: KI beschleunigt die ersten 80 %, sodass Menschen mehr Zeit für die letzten 20 % haben — den Teil, der Produktgespür erfordert.
Wo KI am meisten hilft (und wo nicht)
KI glänzt bei Routineaufgaben, „bekannten Problemen" und allem, was auf einem existierenden Codebase-Pattern basiert. Sie ist auch gut, um Optionen schnell zu explorieren: zwei Implementierungen vorschlagen, Trade-offs auflisten oder Edge Cases aufzeigen.
Sie hilft am wenigsten, wenn Anforderungen unklar sind, eine Architekturentscheidung langfristige Konsequenzen hat oder das Problem sehr domänenspezifisch ist und wenig dokumentierten Kontext bietet. Wenn das Team nicht erklären kann, was „done" bedeutet, kann KI nur schneller plausibel aussehenden Output liefern.
Geschwindigkeit ohne Abkürzungen: Validierung ist Pflicht
Behandeln Sie KI wie einen Junior-Collaborator: nützlich, schnell und manchmal falsch. Menschen sind weiterhin für das Ergebnis verantwortlich.
Das heißt, jede KI-unterstützte Änderung sollte weiterhin Review, Tests und grundlegende Sanity-Checks haben. Praktische Regel: Nutzen Sie KI zum Entwerfen und Transformieren; Menschen entscheiden und verifizieren. So liefern kleine Teams schneller, ohne dass Velocity in zukünftige Aufräumarbeiten kippt.
Kontextwechsel reduzieren mit KI-Unterstützung
Kontextwechsel sind einer der stillen Speed-Killer in kleinen Teams. Es geht nicht nur um Unterbrechungen — es ist das mentale Neustarten jedes Mal, wenn Sie zwischen Code, Tickets, Docs, Slack-Threads und unbekannten Teilen des Systems springen. KI hilft am meisten, wenn sie diese Neustarts in kurze Zwischenstopps verwandelt.
Wie KI die Switching-Kosten senkt
Anstatt 20 Minuten nach einer Antwort zu suchen, können Sie eine schnelle Zusammenfassung, einen Hinweis auf wahrscheinliche Dateien oder eine Plain-English-Erklärung anfordern. Gut eingesetzt wird KI zu einem „Erstentwurfs“-Generator fürs Verstehen: Sie kann eine lange PR zusammenfassen, einen vagen Bug-Report in Hypothesen verwandeln oder einen beängstigenden Stack-Trace in wahrscheinliche Ursachen übersetzen.
Der Gewinn ist nicht, dass KI immer recht hat — sondern dass sie Sie schneller orientiert, sodass Sie reale Entscheidungen treffen können.
Praktische Taktiken, die in echten Teams funktionieren
Einige Prompt-Pattern reduzieren ständig Thrash:
- Optionen anfordern: „Gib mir 3 Ansätze zur Behebung, mit Trade-offs und Risiken."
- Diesen Code erklären: „Erläutere, was diese Funktion macht, Edge Cases und was bricht, wenn wir X ändern."
- Einen Plan generieren: „Erstelle einen Schritt-für-Schritt-Plan, das in zwei kleinen PRs zu liefern, inklusive Tests."
- Eine Checkliste schreiben: „Checkliste für sicheres Release (Monitoring, Rollback, Validierung)."
Diese Prompts verschieben Sie vom Umherirren zum Ausführen.
Prompts wiederverwendbar machen, nicht heroisch
Geschwindigkeit potenziert sich, wenn Prompts zu Templates werden, die das ganze Team nutzt. Pflegen Sie ein kleines internes „Prompt-Kit" für gängige Aufgaben: PR-Reviews, Incident-Notizen, Migrationspläne, QA-Checklisten und Release-Runbooks. Konsistenz zählt: Nennen Sie Ziel, Constraints (Zeit, Scope, Risiko) und erwartetes Ausgabeformat.
Grenzen und Guardrails
Fügen Sie keine Secrets, Kundendaten oder anything ein, was Sie nicht in ein Ticket schreiben würden. Behandeln Sie Outputs als Vorschläge: verifizieren Sie kritische Aussagen, führen Sie Tests aus und prüfen Sie generierten Code sorgfältig — besonders bei Auth, Zahlungen und Datenlöschung. KI reduziert Kontextwechsel; sie ersetzt nicht das technische Urteil.
Klein ausliefern, oft ausliefern: Praktiken, die KI verstärkt
Schneller ausliefern bedeutet nicht heldenhafte Sprints — es bedeutet die Größe jeder Änderung so zu reduzieren, dass Lieferung Routine wird. Kleine Teams haben hier bereits einen Vorteil: weniger Abhängigkeiten erleichtern dünne Slices. KI verstärkt diesen Vorteil, indem sie die Zeit von „Idee" zu einer sicheren, auslieferbaren Änderung verkleinert.
Eine leichte Lieferpipeline (die gut runter skaliert)
Eine einfache Pipeline schlägt eine elaborate:
- Trunk-based Development: Häufig in main integrieren statt lange Branches.
- Kleine PRs: Änderungen, die in Minuten reviewbar sind, nicht Stunden.
- Häufige Deploys: Deploy whenever ready, nicht wenn ein Batch „groß genug" ist.
KI hilft, indem sie Release Notes entwirft, kleinere Commits vorschlägt und Dateien markiert, die wahrscheinlich zusammen berührt werden — und Sie so zu saubereren, engeren PRs nudgt.
KI-beschleunigte Tests: Coverage ohne Drag
Tests sind oft der Punkt, an dem „häufig ausliefern" scheitert. KI kann diese Reibung reduzieren, indem sie:
- Starter-Unit-/Integrationstests aus existierenden Code-Patterns generiert
- Edge Cases brainstormt, die Sie übersehen könnten (Zeitzonen, leere Zustände, Retries, Rate Limits)
- Testdaten und Mocks vorschlägt, die echten API-Formen entsprechen
Behandeln Sie KI-generierte Tests als Erstentwurf: Überprüfen Sie die Korrektheit und behalten Sie die Tests, die Verhalten sinnvoll schützen.
Release-Confidence: Monitoring, Alerts, Rollback
Häufige Deploys brauchen schnelle Erkennung und schnelle Erholung. Richten Sie ein:
- Grundlegende Health Checks und Dashboards für Kern-User-Flows
- Alerts an Symptomen orientiert (Error-Rate, Latenz, fehlgeschlagene Jobs), nicht an Vanity-Metriken
- Einen One-Command-Rollback (oder automatisierten Rollback), damit ein schlechter Release nur ein kurzes Stolpern ist
Wenn Ihre Delivery-Fundamente einen Auffrischer brauchen, verlinken Sie das in der Team-Reading-Liste: /blog/continuous-delivery-basics.
Mit diesen Praktiken macht KI Sie nicht „magisch schneller" — sie entfernt die kleinen Verzögerungen, die sich sonst zu Wochen-Zyklen aufsummieren.
Entscheidungs-Latenz: Genehmigungen vs. Guardrails
Schneller entwickeln mit einer verantwortlichen Person
Erstelle schnell ein React-UI und ein Go-Backend und iteriere dann in kleinen, prüfbaren Änderungen.
Große Engineering-Organisationen sind selten langsam, weil Leute faul sind. Sie sind langsam, weil Entscheidungen sich stauen. Architektur-Councils treffen sich monatlich. Security- und Privacy-Reviews sitzen hinter Ticket-Backlogs. Eine „einfache" Änderung kann eine Tech-Lead-Review, dann eine Staff-Engineer-Review, dann eine Platform-Sign-off und schließlich eine Release-Manager-Genehmigung erfordern. Jeder Hop fügt Wartezeit hinzu, nicht nur Arbeitszeit.
Kleine Teams können sich diese Entscheidungs-Latenz nicht leisten, deshalb sollten sie ein anderes Modell anstreben: weniger Genehmigungen, stärkere Guardrails.
Was Genehmigungen versuchen zu lösen (und warum sie stocken)
Genehmigungsketten sind ein Risikomanagement-Tool. Sie reduzieren die Chance auf schlechte Änderungen, zentralisieren aber Entscheidungen. Wenn dieselbe kleine Gruppe jede bedeutende Änderung absegnen muss, kollabiert der Durchsatz und Ingenieure optimieren dafür, „die Genehmigung zu bekommen" statt das Produkt zu verbessern.
Guardrails: die Alternative für kleine Teams
Guardrails verschieben Qualitätsprüfungen von Meetings in Defaults:
- Klare Coding-Standards und Definition of Done
- Leichtgewichtige Checklisten für riskante Bereiche (Auth, Zahlungen, Datenlöschung)
- Automatisierte Checks: Tests, Linting, Type-Checking, Dependency-Scanning
Statt „Wer hat das genehmigt?" lautet die Frage: „Hat das die vereinbarten Gates passiert?"
Wie KI die Kosten der Guardrails senkt
KI kann Qualität standardisieren, ohne mehr Menschen in die Schleife zu bringen:
- Lint- und Refactor-Vorschläge, um Code an Teamstandards anzupassen
- PR-Zusammenfassungen, die Absicht, Umfang und Risiko in Klartext erklären
- Review-Checklisten aus dem Diff generiert (z. B. „berührt PII: Retention-Policy bestätigen"), sodass Reviewer nicht aus dem Gedächtnis arbeiten
Das erhöht Konsistenz und macht Reviews schneller, weil Reviewer von einem strukturierten Briefing ausgehen statt von leerer Seite.
Compliance leichtgewichtig halten (ohne sie zu überspringen)
Compliance braucht kein Komitee. Machen Sie es wiederholbar:
- Definieren Sie „Requires Review"-Trigger (PII, Geldbewegungen, Berechtigungen)
- Nutzen Sie Templates für Nachweise (PR-Zusammenfassung + Checkliste + Testergebnisse)
- Speichern Sie Entscheidungen im PR-Thread, damit Audits durchsuchbar sind
Genehmigungen werden zur Ausnahme für Hochrisiko-Arbeit; Guardrails übernehmen den Rest. So bleiben kleine Teams schnell, ohne rücksichtslos zu sein.
Design-Arbeit als Thin Slices, um Momentum zu behalten
Große Teams designen oft das ganze System, bevor jemand ausliefert. Kleine Teams können schneller sein, indem sie Thin Slices designen: die kleinste End-to-End-Einheit von Wert, die von Idee → Code → Produktion gehen und (auch in einem kleinen Cohort) genutzt werden kann.
Was ein Thin Slice wirklich ist
Ein Thin Slice ist vertikale Ownership, nicht eine horizontale Phase. Er beinhaltet alles, was nötig ist über Design, Backend, Frontend und Ops, um ein Ergebnis real zu machen.
Statt „Onboarding neu designen" könnte ein Thin Slice sein: „Ein zusätzliches Signup-Feld erfassen, validieren, speichern, im Profil anzeigen und Completion tracken." Es ist klein genug, um schnell fertig zu werden, aber komplett genug, um davon zu lernen.
Wie KI Ihnen hilft, Arbeit zu slicen (ohne zu raten)
KI ist hier nützlich als strukturierter Denkpartner:
- Schlägt 2–4 Meilenstein-Optionen vor (kleinstes Viables, mittel, voll)
- Generiert eine Aufgabenaufteilung nach Layern (UI, API, Daten, Analytics, Rollout)
- Markiert versteckte Abhängigkeiten (Migrationen, Berechtigungen, Edge Cases)
- Schlägt einen Rollout-Plan vor (Feature Flag, begrenzte Kohorte, Fallback)
Das Ziel ist nicht mehr Aufgaben — sondern eine klare, auslieferbare Grenze.
„Done" für jeden Slice definieren
Momentum stirbt, wenn „fast fertig" sich hinzieht. Für jeden Slice schreiben Sie explizite Definition of Done-Punkte:
- Nutzer-sichtbares Verhalten (was sich ändert, für wen)
- Akzeptanzkriterien (Happy Path + Schlüssel-Edge-Cases)
- Instrumentierung (Event-Namen, Dashboards, Alerts falls nötig)
- Deployment/Rollback-Schritte (oder Feature-Flag-Regeln)
Beispiele für Thin Slices
- Ein Endpoint:
POST /checkout/quotereturning price + taxes - Ein Screen: eine Settings-Seite für Benachrichtigungspräferenzen
- Ein Workflow: Passwort-Reset von Anfrage → E-Mail → neues Passwort → Bestätigung
Thin Slices halten das Design ehrlich: Sie designen das, was Sie jetzt ausliefern können, lernen schnell und lassen das nächste Slice seine Komplexität verdienen.
Risiken beschleunigter KI-Geschwindigkeit (und wie man sie managt)
Im Loop bleiben
Verringere Kontextwechsel, indem du Planung, Code und Änderungen in einem geführten Workflow bündelst.
KI kann ein kleines Team schnell machen, verändert aber die Fehler-Modi. Das Ziel ist nicht „langsamer werden, um sicher zu sein" — sondern leichte Guardrails hinzuzufügen, damit Sie weiter ausliefern können, ohne unsichtbare Schulden aufzubauen.
Häufige Risiken, wenn KI in der Schleife ist
Wenn Sie schneller werden, steigt die Chance, dass rauhe Kanten in Produktion rutschen. Mit KI tauchen wiederkehrend einige Risiken auf:
- Inkonsistenter Code und Stil: KI-generierte Patches können Muster, Benennungen und Architektur variieren und Codebasis schwerer wartbar machen.
- Sicherheitsprobleme: Vorschläge können unsichere Defaults einführen (schwache Auth-Checks, fehlende Input-Validation, unsichere Deserialisierung).
- Halluzinierte Logik: Code kann plausibel aussehen, aber subtil falsch sein (Edge-Cases, falsche API-Annahmen, fehlerhafte Fehlerbehandlung).
- Dependency-Sprawl: KI zieht möglicherweise neue Bibliotheken hinzu, „um es einfach zu machen", und erhöht Angriffsfläche und Wartungskosten.
Guardrails, die Geschwindigkeit ohne Chaos erhalten
Halten Sie Regeln explizit und leicht anwendbar. Einige Praktiken zahlen sich schnell aus:
- Secure-Coding-Guidelines: kurze Checkliste für gängige Bereiche (Auth, Permissions, Validation, Logging, Encryption)
- Secret-Scanning in CI und Pre-Commit-Hooks sowie klare Regeln, wo Secrets leben
- Dependency-Policies: genehmigte Libraries-Liste, Version-Pinning und ein Standard „neue Dependency braucht Begründung"
Menschliche Prüfungen, die am meisten zählen
KI kann Code entwerfen; Menschen müssen das Ergebnis verantworten.
- Threat Modeling für Änderungen, die Daten, Auth, Zahlungen oder Admin-Flows betreffen. Schon eine 10-minütige Review fängt Hochrisiko-Szenarien.
- Code Review, das sich auf Verhalten konzentriert: Inputs/Outputs, Fehlerpfade, Berechtigungen und Datenbehandlung.
- Teststrategie: Unit-Tests für Logik, Integrationstests für kritische Flows und ein kleines Set hoch-signifikanter End-to-End-Checks.
KI im Alltag sicher nutzen
Behandeln Sie Prompts wie öffentlichen Text: keine Secrets, Tokens oder Kundendaten einfügen. Bitten Sie das Modell, Annahmen zu erklären, und verifizieren Sie mit Primärquellen (Docs) und Tests. Wenn etwas „zu bequem" wirkt, braucht es meist einen genaueren Blick.
Wenn Sie eine KI-getriebene Build-Umgebung wie Koder.ai verwenden, gelten dieselben Regeln: Sensitive Daten aus Prompts heraushalten, auf Tests und Review bestehen und Snapshots-/Rollback-Workflows nutzen, sodass „schnell" auch „wiederherstellbar" bedeutet.
Gewinne messen und ein reproduzierbares System aufbauen
Geschwindigkeit zählt nur, wenn Sie sie sehen, erklären und wiederholen können. Das Ziel ist nicht „mehr KI verwenden" — sondern ein einfaches System, in dem KI-unterstützte Praktiken zuverlässig Time-to-Value reduzieren, ohne Risiko zu erhöhen.
Metriken, die echte Liefergeschwindigkeit zeigen (nicht Aktivität)
Wählen Sie eine kleine Menge, die Sie wöchentlich tracken:
- Cycle Time: von „Arbeit gestartet" bis „in Produktion".
- PR-Größe: geänderte Zeilen/Dateien (kleiner heißt meist leichter reviewbar und sicherere Releases).
- Review Time: Median der Zeit, bis ein PR den ersten Review und den Merge erhält.
- Incidents/Regressions: Produktionsprobleme pro Woche (und Schwere), plus Mean Time to Recover.
- Kundenreaktionszeit: Zeit von Nutzerfeedback bis zur ausgelieferten Änderung.
Fügen Sie ein qualitatives Signal hinzu: „Was hat uns diese Woche am meisten gebremst?" Das hilft, Engpässe zu finden, die Metriken nicht zeigen.
Ein leichtgewichtiger Betriebsrhythmus
Halten Sie es konsistent und klein-team-freundlich:
- Wöchentliche Ziele (30 Minuten): 1–3 Outcomes, kein langer Task-List.
- Tägliche asynchrone Updates: gestern/heute/Blocker in Slack/Linear/GitHub.
- Demo-Cadence (wöchentlich oder zweiwöchentlich): zeige ausgelieferte Arbeit, nicht Folien. Das verstärkt „done heißt in den Händen der Nutzer".
30-Tage-Rollout-Plan für KI-Workflows
Woche 1: Baseline. Messen Sie die obigen Metriken für 5–10 Arbeitstage. Keine Änderungen.
Wochen 2–3: Wählen Sie 2–3 KI-Workflows. Beispiele: PR-Beschreibung + Risiko-Checklisten-Generierung, Test-Schreibunterstützung, Release Notes + Changelog-Entwurf.
Woche 4: Vorher/Nachher vergleichen und Gewohnheiten festigen. Wenn PR-Größe sinkt und Review-Zeit sich verbessert, ohne mehr Incidents, behalten Sie es. Steigen Incidents, fügen Sie Guardrails hinzu (kleinere Rollouts, bessere Tests, klarere Ownership).
Checkliste: Diese Woche starten
- Wählen Sie 3 Metriken, die Sie in einem wöchentlichen Thread posten.
- Setzen Sie ein Default-PR-Größenziel (und fördern Sie es mit sozialen Normen, nicht Bürokratie).
- Fügen Sie einen KI-unterstützten „Pre-Review"-Schritt hinzu: Änderungen zusammenfassen, Risiken und Testabdeckung aufführen.
- Planen Sie eine Demo im Kalender.
- Führen Sie ein „Bottleneck Retro"-Frage durch: Was hat die größte Verzögerung verursacht und was ändern wir nächste Woche?
FAQ
Was bedeutet „Geschwindigkeit“ eigentlich bei der Produktlieferung?
Liefergeschwindigkeit ist die verstrichene Zeit vom Entschluss zu einer Idee bis zu einer verlässlichen Änderung, die für Nutzer live ist und belastbares Feedback erzeugt. Es geht weniger ums „schnell coden“ und mehr darum, Wartezeiten (Queues, Genehmigungen, Übergaben) zu minimieren und den Build → Release → Observe → Adjust-Zyklus zu straffen.
Warum sollte man sich auf Lead Time, Cycle Time, Deployment Frequency und Time-to-Learning konzentrieren?
Sie erfassen unterschiedliche Engpässe:
- Lead Time zeigt die End-to-End-Latenz (inklusive Wartezeiten).
- Cycle Time zeigt, wie lange Arbeit im Status „in Arbeit“ steckt.
- Deployment Frequency zeigt, wie oft Sie sicher ausliefern können.
- Time-to-Learning zeigt, wie schnell Sie ein Signal bekommen, um die nächsten Schritte zu entscheiden.
Alle vier gemeinsam verhindern, dass Sie eine Kennzahl optimieren, während die eigentliche Verzögerung woanders versteckt bleibt.
Warum wirken große Engineering-Organisationen oft langsamer, obwohl mehr Personen vorhanden sind?
Koordinationsaufwand wächst mit Teamgrenzen und Abhängigkeiten. Mehr Übergaben bedeuten mehr:
- Wartezeit (Warten auf Reviews, Meetings, Backlogs anderer Teams)
- Kontextverlust (Missverständnisse, die Nacharbeit erzeugen)
- Entscheidungsverzögerungen (Genehmigungen, die nach jemandanders Rhythmus geplant werden)
Ein kleines Team mit klarer Ownership kann Entscheidungen lokal halten und in kleineren Inkrementen ausliefern.
Was ist „single-threaded ownership“ und wie beschleunigt es die Lieferung?
Es bedeutet, dass eine eindeutig verantwortliche Person eine Aufgabe von der Idee bis in die Produktion treibt, Inputs sammelt und Entscheidungen trifft, wenn Trade-offs auftauchen. Praktisch heißt das:
- Eine Person bzw. ein Paar ist für Ergebnisse verantwortlich
- „Done“ umfasst Tests + Rollout (nicht nur „gemerged“)
- Stakeholder beraten, aber der Owner entscheidet und führt aus
Das reduziert Hin- und Herschicken und hält die Arbeit in Bewegung.
Wie sieht „KI für Engineering“ in der Praxis wirklich aus?
KI funktioniert am besten als Beschleuniger für Entwürfe und Transformationen, zum Beispiel:
- Scaffolding von Code, Refactors und repetitiven Änderungen
- Entwurf von Tests und Vorschlägen zu Edge-Cases
- Zusammenfassungen von PRs, Incidents und langen Threads
- Entwurf von Specs, Release Notes und Runbooks
Sie erhöht den Output pro Person und reduziert Nacharbeit—ersetzt aber nicht Produkturteil oder Verifikation.
Wie nutzen kleine Teams KI, um Lernen zu beschleunigen und nicht nur das Coden?
KI kann das schnelle Ausliefern nutzlos beschleunigen, wenn Lernen nicht eng gehalten wird. Gute Praxis ist, KI-unterstütztes Bauen mit KI-unterstütztem Lernen zu koppeln:
- Supporttickets/Interviews zusammenfassen und Themen clustern
- Hypothesen für Experimente und Erfolgskriterien entwerfen
- Den kleinsten nächsten Test vorschlagen, um Unsicherheit zu reduzieren
Optimieren Sie für Learning Velocity, nicht bloß für Feature-Volumen.
Wie vermeiden wir Qualitätsregressionen, wenn KI den Durchsatz erhöht?
Behandeln Sie KI-Ausgaben wie einen schnellen Junior-Kollegen: hilfreich, aber manchmal falsch. Leichte, automatische Guardrails sind wichtig:
- Review + Tests für KI-unterstützte Änderungen vorschreiben
- Linter/Type-Checks/CI-Gates standardmäßig einsetzen
- Eine diff-basierte Risiko-Checkliste (Auth, Zahlungen, PII, Löschung) ergänzen
- Kleinere PRs bevorzugen, damit Fehler leichter zu erkennen und zurückzusetzen sind
Faustregel: KI entwirft; Menschen entscheiden und verifizieren.
Was ist der Unterschied zwischen Genehmigungen und Guardrails, und warum ist das wichtig?
Setzen Sie Guardrails, damit „sicher per Default“ der normale Pfad ist:
- Eine klare Definition of Done (Tests, Rollout, Monitoring)
- Automatisierte Checks (CI, Linting, Dependency-Scanning, Secret-Scanning)
- Templates für PR-Zusammenfassungen und Risiko-Notizen
Menschliche Genehmigungen bleiben für echte Hochrisiko-Änderungen vorbehalten, statt alles durch ein Komitee zu schleusen.
Was ist ein „Thin Slice“ und wie definieren wir ihn?
Ein Thin Slice ist eine kleine, End-to-End-Einheit von Wert (Design + Backend + Frontend + Ops, wie nötig), die auslieferbar ist und Erkenntnisse liefert. Beispiele:
- Ein Endpoint mit echter Validierung und Logging
- Eine Einstellungs-Seite mit Persistenz + Analytics
- Ein Workflow (z. B. Passwort-Zurücksetzen) mit messbarer Erfolgskategorie
Thin Slices erhalten Momentum, weil Sie schneller in Produktion gelangen und Feedback bekommen.
Wie messen wir, ob KI uns tatsächlich schneller macht?
Starten Sie mit einem Baseline-Messzeitraum und fokussieren Sie auf ein paar wöchentliche Signale:
- Cycle Time (Start → Produktion)
- Review Time (Wartezeit bis erster Review + Merge)
- PR-Größe (geänderte Zeilen/Dateien)
- Incidents/Regressions und Recovery-Zeit
- Zeit von Nutzerfeedback bis zur ausgelieferten Änderung
Führen Sie eine kurze wöchentliche Frage ein: „Was hat uns diese Woche am meisten aufgehalten?“ Wenn Ihre Delivery-Fundamentals fehlen, standardisieren Sie auf eine gemeinsame Referenz wie /blog/continuous-delivery-basics.